Utilisation des fonctions définies par l’utilisateur C# avec Apache Hive et Apache Pig sur Apache Hadoop dans HDInsight
Découvrez comment utiliser des fonctions définies par l’utilisateur C# avec Apache Hive et Apache Pig sur HDInsight.
Important
Les étapes décrites dans ce document fonctionnent avec des clusters HDInsight Linux. Linux est le seul système d’exploitation utilisé sur HDInsight version 3.4 ou supérieure. Pour plus d’informations, consultez Contrôle de version des composants HDInsight.
Hive et Pig permettent de transmettre des données vers des applications externes pour le traitement. Ce processus est appelé diffusion en continu (streaming). Lorsque vous utilisez une application .NET, les données sont transmises à l’application sur STDIN, et l’application retourne les résultats sur STDOUT. Pour lire et écrire à partir de STDIN et STDOUT, vous pouvez utiliser Console.ReadLine() et Console.WriteLine() à partir d’une application console.
Prérequis
Des connaissances en écriture et en génération de code C# qui cible .NET Framework 4.5.
Utilisez n’importe quel IDE souhaité. Nous vous conseillons d’utiliser Visual Studio ou Visual Studio Code. Dans le cadre de ce document, Visual Studio 2019 a été utilisé.
Permet de télécharger les fichiers .exe dans le cluster et d’exécuter des tâches Pig et Hive. Nous vous recommandons d’utiliser Data Lake Tools pour Visual Studio, Azure PowerShell et Azure CLI. La procédure décrite dans ce document utilise les outils Data Lake pour Visual Studio pour charger les fichiers et exécuter l’exemple de requête Hive.
Pour plus d’informations sur les autres façons d’exécuter des requêtes Hive, consultez Présentation d’Apache Hive et HiveQL sur Azure HDInsight.
Un cluster Hadoop sur HDInsight. Pour plus d’informations sur la création d’un cluster, consultez Créer un cluster HDInsight.
.NET sur HDInsight
Clusters HDInsight Linux utilisant Mono (https://mono-project.com) pour exécuter les applications .NET. La version 4.2.1 de Mono est incluse dans la version 3.6 de HDInsight.
Pour plus d’informations sur la compatibilité Mono avec les versions de .NET Framework, consultez Compatibilité Mono.
Pour plus d’informations sur la version de .NET Framework et Mono fournie avec les versions de HDInsight, consultez Versions des composants HDInsight.
Création des projets C#
Les sections suivantes décrivent comment créer un projet C# dans Visual Studio pour une fonction définie par l’utilisateur Apache Pig ou Apache Hive.
Fonction définie par l’utilisateur Apache Hive
Pour créer un projet C# pour une fonction définie par l’utilisateur Apache Hive :
Lancez Visual Studio.
Sélectionnez Créer un projet.
Dans la fenêtre Créer un projet, choisissez le modèle Application console (.NET Framework) (version C#). Sélectionnez ensuite Suivant.
Dans la fenêtre Configurer votre nouveau projet, entrez le Nom de projetHiveCSharp, puis accédez à ou créez un Emplacement auquel enregistrer le nouveau projet. Sélectionnez ensuite Créer.
Dans l’IDE Visual Studio, remplacez le contenu de Program.cs par le code suivant :
using System; using System.Security.Cryptography; using System.Text; using System.Threading.Tasks; namespace HiveCSharp { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Parse the string, trimming line feeds // and splitting fields at tabs line = line.TrimEnd('\n'); string[] field = line.Split('\t'); string phoneLabel = field[1] + ' ' + field[2]; // Emit new data to stdout, delimited by tabs Console.WriteLine("{0}\t{1}\t{2}", field[0], phoneLabel, GetMD5Hash(phoneLabel)); } } /// <summary> /// Returns an MD5 hash for the given string /// </summary> /// <param name="input">string value</param> /// <returns>an MD5 hash</returns> static string GetMD5Hash(string input) { // Step 1, calculate MD5 hash from input MD5 md5 = System.Security.Cryptography.MD5.Create(); byte[] inputBytes = System.Text.Encoding.ASCII.GetBytes(input); byte[] hash = md5.ComputeHash(inputBytes); // Step 2, convert byte array to hex string StringBuilder sb = new StringBuilder(); for (int i = 0; i < hash.Length; i++) { sb.Append(hash[i].ToString("x2")); } return sb.ToString(); } } }Dans la barre de menus, sélectionnez Générer>Générer la solution pour générer le projet.
Fermez la solution.
Fonction définie par l’utilisateur Apache Pig
Pour créer un projet C# pour une fonction définie par l’utilisateur Apache Hive :
Ouvrez Visual Studio.
Dans la fenêtre Démarrer, sélectionnez Créer un projet.
Dans la fenêtre Créer un projet, choisissez le modèle Application console (.NET Framework) (version C#). Sélectionnez ensuite Suivant.
Dans la fenêtre Configurer votre nouveau projet, entrez le Nom de projetPigUDF, puis accédez à ou créez un Emplacement auquel enregistrer le nouveau projet. Sélectionnez ensuite Créer.
Dans l’IDE Visual Studio, remplacez le contenu de Program.cs par le code suivant :
using System; namespace PigUDF { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Fix formatting on lines that begin with an exception if(line.StartsWith("java.lang.Exception")) { // Trim the error info off the beginning and add a note to the end of the line line = line.Remove(0, 21) + " - java.lang.Exception"; } // Split the fields apart at tab characters string[] field = line.Split('\t'); // Put fields back together for writing Console.WriteLine(String.Join("\t",field)); } } } }Ce code analyse les lignes envoyées à partir de Pig et reformate les lignes qui commencent par
java.lang.Exception.Dans la barre de menus, choisissez Générer>Générer la solution pour générer le projet.
Laissez la solution ouverte.
Téléchargement vers le stockage
Ensuite, chargez les applications de fonction définie par l’utilisateur Hive et Pig dans le stockage sur un cluster HDInsight.
Dans Visual Studio, accédez à Affichage>Explorateur de serveurs.
À partir de l’Explorateur de serveurs, cliquez avec le bouton droit sur Azure, sélectionnez Se connecter à un abonnement Microsoft Azure, puis effectuez le processus de connexion.
Développez le cluster HDInsight sur lequel vous souhaitez déployer cette application. Une entrée avec le texte (compte de stockage par défaut) est répertoriée.
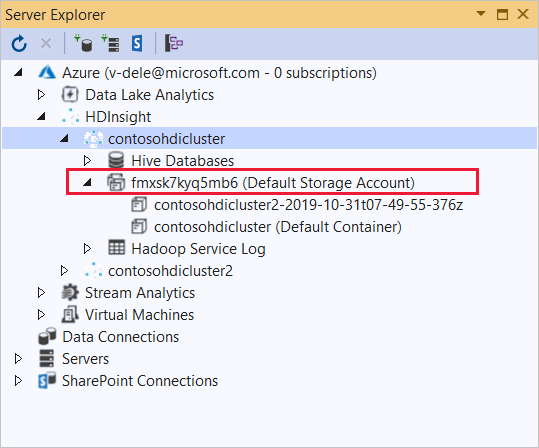
Si cette entrée peut être développée, vous utilisez un compte de stockage Azure en tant que stockage par défaut pour le cluster. Pour afficher les fichiers sur le stockage par défaut pour le cluster, développez l’entrée et double-cliquez sur le (conteneur par défaut).
Si cette entrée ne peut pas être développée, vous utilisez Azure Data Lake Storage comme stockage par défaut pour le cluster. Pour afficher les fichiers sur le stockage par défaut pour le cluster, double-cliquez sur l’entrée (compte de stockage par défaut) .
Pour charger les fichiers .exe, appliquez l’une des méthodes suivantes :
Si vous utilisez un compte de stockage Azure, sélectionnez l’icône Télécharger un objet Blob.

Dans la boîte de dialogue Télécharger un nouveau fichier, sous Nom de fichier, sélectionnez Parcourir. Dans la boîte de dialogue Charger un objet Blob, accédez au dossier
bin\debugpour le projet HiveCSharp, puis choisissez le fichier HiveCSharp.exe. Enfin, sélectionnez Ouvrir, puis OK pour terminer le téléchargement.Si vous utilisez Azure Data Lake Storage, cliquez avec le bouton droit sur une zone vide de la liste des fichiers, puis sélectionnez Charger. Enfin, sélectionnez le fichier HiveCSharp.exe et sélectionnez Ouvrir.
Une fois le chargement de HiveCSharp.exe terminé, répétez le processus de chargement pour le fichier PigUDF.exe.
Exécuter une requête Apache Hive
Vous pouvez maintenant exécuter une requête Hive qui utilise votre application de fonction définie par l’utilisateur Hive.
Dans Visual Studio, accédez à Affichage>Explorateur de serveurs.
Développez Azure, puis HDInsight.
Cliquez avec le bouton droit sur le cluster dans lequel vous avez déployé l’application HiveCSharp, puis sélectionnez Écrire une requête Hive.
Pour la requête Hive, utilisez le texte suivant :
-- Uncomment the following if you are using Azure Storage -- add file wasbs:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen1 -- add file adl:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen2 -- add file abfs:///HiveCSharp.exe; SELECT TRANSFORM (clientid, devicemake, devicemodel) USING 'HiveCSharp.exe' AS (clientid string, phoneLabel string, phoneHash string) FROM hivesampletable ORDER BY clientid LIMIT 50;Important
Supprimez les commentaires de l’instruction
add filequi correspond au type de stockage par défaut utilisé pour votre cluster.Cette requête permet de sélectionner les champs
clientid,devicemakeetdevicemodeldanshivesampletable, puis de les transmettre à l’application HiveCSharp.exe. La requête s’attend à ce que l’application renvoie les trois champs, qui sont stockés en tant queclientid,phoneLabeletphoneHash. Elle s’attend également à trouver HiveCSharp.exe à la racine du conteneur de stockage par défaut.Basculez du mode Interactif par défaut vers le mode Batch, puis sélectionnez Envoyer pour envoyer le travail au cluster HDInsight. La fenêtre Résumé de la tâche Hive s’ouvre.
Sélectionnez Actualiser pour actualiser le résumé jusqu’à ce que État du travail soit défini sur Terminé. Pour afficher le résultat de la tâche, sélectionnez Sortie de la tâche.
Exécuter un travail Apache Pig
Vous pouvez également exécuter une tâche Pig qui utilise votre application de fonction définie par l’utilisateur Pig.
Utilisez SSH pour vous connecter à votre cluster HDInsight. (Par exemple, exécutez la commande
ssh sshuser@<clustername>-ssh.azurehdinsight.net.) Pour plus d’informations, consultez la rubrique Utilisation de SSH avec HDInsight.Utilisez la commande suivante pour lancer la ligne de commande Pig :
pigUne invite
grunt>s’affiche.Entrez la commande suivante pour exécuter une tâche Pig qui utilise l’application .NET Framework :
DEFINE streamer `PigUDF.exe` CACHE('/PigUDF.exe'); LOGS = LOAD '/example/data/sample.log' as (LINE:chararray); LOG = FILTER LOGS by LINE is not null; DETAILS = STREAM LOG through streamer as (col1, col2, col3, col4, col5); DUMP DETAILS;L’instruction
DEFINEcrée l’aliasstreamerpour les applications PigUDF.exe etCACHEle charge à partir du stockage par défaut pour le cluster. Plus tard,streamerest utilisé avec l’opérateurSTREAMpour traiter les lignes uniques contenues dansLOGet renvoyer les données sous forme de colonnes.Notes
Le nom d’application utilisé pour la diffusion en continu doit être entouré du caractère
`(accent grave) s’il s’agit d’un alias ou du caractère'(apostrophe) en cas d’utilisation avecSHIP.Une fois que vous entrez la dernière ligne, le travail devrait démarrer. Elle retourne un résultat semblable au texte suivant :
(2019-07-15 16:43:25 SampleClass5 [WARN] problem finding id 1358451042 - java.lang.Exception) (2019-07-15 16:43:25 SampleClass5 [DEBUG] detail for id 1976092771) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1317358561) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1737534798) (2019-07-15 16:43:25 SampleClass7 [DEBUG] detail for id 1475865947)Utilisez
exitpour quitter Pig.
Étapes suivantes
Dans ce document, vous avez appris à utiliser une application .NET Framework à partir de Hive et Pig sur HDInsight. Si vous voulez apprendre à utiliser Python avec Hive et Pig, consultez Utiliser Python avec Apache Hive et Apache Pig dans HDInsight.
Pour connaître d’autres façons d’utiliser Hive et en savoir plus sur l’utilisation de MapReduce, consultez les articles suivants :