Extraire, transformer et charger (ETL) à l’échelle
L’extraction, la transformation et le chargement (ETL) est le processus par lequel les données sont acquises à partir de différentes sources, Les sonnées sont collectées dans un emplacement standard, nettoyées et traitées. Finalement, elles sont chargées dans un magasin de données à partir duquel il est possible de les interroger. Les processus ETL hérités importent des données, les nettoient sur place, puis les stockent dans un moteur de données relationnelles. Avec Azure HDInsight, un vaste de composants d’environnement Apache Hadoop prennent en charge l’ETL à grande échelle.
L’utilisation de HDInsight dans le processus d’ETL peut être résumée par ce pipeline :
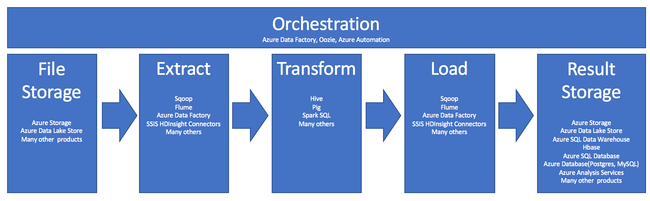
Les sections qui suivent décrivent chacune des phases ETL et les composants associés.
Orchestration
L’orchestration s’étend sur toutes les phases du pipeline ETL. Les travaux ETL dans HDInsight impliquent souvent plusieurs produits travaillant les uns avec les autres. Par exemple :
- Vous pouvez utiliser Apache Hive pour nettoyer une partie des données, et Apache Pig pour en nettoyer une autre partie.
- Vous pouvez utiliser Azure Data Factory pour charger des données dans Azure SQL Database à partir d’Azure Data Lake Store.
L’orchestration est nécessaire pour exécuter le travail approprié au moment opportun.
Apache Oozie
Apache Oozie est un système de coordination de flux de travail qui gère les tâches Hadoop. Oozie s’exécute dans un cluster HDInsight et est intégré à la pile Hadoop. Oozie prend en charge les travaux Hadoop pour Apache Hadoop MapReduce, Pig, Hive et Sqoop. Vous pouvez utiliser Oozie pour planifier des travaux spécifiques d’un système, comme des programmes Java ou des scripts de l’interpréteur de commandes.
Pour plus d’informations, consultez Utiliser Apache Oozie avec Apache Hadoop pour définir et exécuter un workflow sur HDInsight. Consultez également Faire fonctionner le pipeline de données.
Azure Data Factory
Azure Data Factory fournit des capacités d’orchestration sous la forme d’une plateforme en tant que service (PaaS, Platform as a Service). Azure Data Factory est un service d’intégration de données basé sur le cloud. Il vous permet de créer des flux de travail basés sur les données afin d’orchestrer et d’automatiser le déplacement et la transformation des données.
Utilisez Azure Data Factory pour effectuer les opérations suivantes :
- Créer et planifier des flux de travail pilotés par les données. Ces pipelines ingèrent des données provenant de magasins de données disparates.
- Traiter et transformer les données à l’aide de services de calcul tels que HDInsight et Hadoop. Vous pouvez également utiliser Spark, Azure Data Lake Analytics, Azure Batch ou Azure Machine Learning pour cette étape.
- Publier des données de sortie sur des magasins de données comme Azure Synapse Analytics pour que des applications décisionnelles puissent les utiliser.
Pour plus d’informations sur Azure Data Factory, consultez la documentation.
Ingérer le stockage de fichiers et le stockage des résultats
Les fichiers de données sources sont généralement chargés dans un emplacement sur Stockage Azure ou Azure Data Lake Storage. Les fichiers ont généralement un format plat, comme CSV. Ils peuvent cependant être de n’importe quel format.
Stockage Azure
Stockage Azure a des cibles d’adaptabilité spécifiques. Pour plus d’informations, consultez Objectifs d’extensibilité et de performances du Stockage Blob. Pour la plupart des nœuds d’analytique, Stockage Azure propose une meilleure mise à l’échelle avec de nombreux petits fichiers. Tant que vous restez dans les limites de votre compte, le Stockage Azure garantit des performances identiques, quelle que soit la taille des fichiers. Vous pouvez stocker des téraoctets de données tout en conservant des performances cohérentes. Cette instruction est vraie, que vous utilisiez un sous-ensemble ou l’ensemble des données.
Stockage Azure a plusieurs types de blobs. Un blob d’ajout est idéal pour le stockage de fichiers journaux d’activité web ou de données de capteur.
Plusieurs blobs peuvent être répartis sur plusieurs serveurs afin d’offrir un accès évolutif. Toutefois, un blob n’est servi que par un serveur. Si des blobs peuvent être regroupés de manière logique dans des conteneurs, ce regroupement n’a aucune incidence sur le partitionnement.
Stockage Azure comprend une couche API WebHDFS pour le stockage d’objets blob. Tous les services de HDInsight peuvent accéder aux fichiers dans Stockage Blob Azure pour le nettoyage et le traitement des données. Ce processus est similaire à la manière dont ces services utiliseraient Hadoop Distributed Files System (HDFS).
Les données sont généralement ingérées dans Stockage Azure à l’aide de PowerShell, du kit SDK Stockage Azure ou d’AzCopy.
Azure Data Lake Storage
Azure Data Lake Storage est un référentiel hyperscale managé pour les données Analytics. Il est compatible avec un paradigme de conception similaire à HDFS, et l’utilise. Data Lake Storage offre une adaptabilité illimitée en matière de capacité totale et taille des fichiers individuels. Il s’agit d’un bon choix si vous travaillez avec des fichiers volumineux, car ceux-ci peuvent être stockés sur plusieurs nœuds. Le partitionnement de données dans Data Lake Storage est effectué en coulisses. Vous bénéficiez d’un débit suffisamment important pour exécuter des travaux d’analyse avec des milliers d’exécuteurs simultanés lisant et écrivant de façon efficace des centaines de téraoctets de données.
Les données sont généralement ingérées dans Data Lake Storage via Azure Data Factory. Vous pouvez également utiliser des kits de développement logiciel (SDK) Data Lake Storage, le service AdlCopy, Apache DistCp ou Apache Sqoop. Le service que vous choisissez dépend de l’emplacement des données. Si c’est dans un cluster Hadoop existant, vous pouvez utiliser Apache DistCp, le service AdlCopy ou Azure Data Factory. Pour des données stockées dans Stockage Blob Azure, vous pouvez utiliser le Kit de développement logiciel (SDK) .NET Azure Data Lake Storage, Azure PowerShell ou Azure Data Factory.
Data Lake Storage est optimisé pour l’ingestion d’événements via Azure Event Hubs.
Considérations relatives aux deux options de stockage
Pour le chargement de jeux de données de plusieurs téraoctets, la latence du réseau peut constituer un problème majeur. C’est particulièrement vrai si les données proviennent d’un emplacement local. Dans ce cas, vous pouvez utiliser les options suivantes :
Azure ExpressRoute : créez des connexions privées entre des centres de données Azure et votre infrastructure locale. Ces connexions constituent une option fiable pour le transfert de grandes quantités de données. Pour plus d’informations, consultez la Documentation Azure ExpressRoute.
Chargement de données à partir de lecteurs de disque dur : vous pouvez utiliser le service Azure Import/Export pour expédier des disques durs contenant vos données à un centre de données Azure. Vos données sont d’abord chargées vers le Stockage Blob Azure. Vous pouvez ensuite utiliser Azure Data Factory ou l’outil AdlCopy pour copier des données de Stockage Blob Azure vers Data Lake Storage.
Azure Synapse Analytics
Azure Synapse Analytics est approprié pour stocker des résultats préparés. Vous pouvez utiliser Azure HDInsight pour exécuter ces services pour Azure Synapse Analytics.
Azure Synapse Analytics est un magasin de bases de données relationnelles optimisé pour les charges de travail analytiques. Il se met à l’échelle en fonction de tables partitionnées. Les tables peuvent être partitionnées entre plusieurs nœuds. Les nœuds sont sélectionnés au moment de la création. Ils peuvent être mis à l’échelle après coup, mais il s’agit alors d’un processus actif qui peut nécessiter le déplacement de données. Pour plus d’informations, consultez Gérer le calcul dans Azure Synapse Analytics.
Apache HBase
Apache HBase est un magasin de clés-valeurs disponible dans Azure HDInsight. Il s’agit d’une base de données NoSQL open source, basée sur Hadoop et modélisée d’après Google BigTable. HBase fournit un accès aléatoire performant et une forte cohérence pour de vastes quantités de données non structurées et semi-structurées.
HBase étant une base de données sans schéma, vous n’avez pas besoin de définir des colonnes et des types de données avant de les utiliser. Les données sont stockées dans les lignes d’une table, et regroupées par familles de colonnes.
Le code open source peut être mis à l'échelle de façon linéaire pour gérer des pétaoctets de données dans des milliers de nœuds. HBase s’appuie sur une redondance des données, un traitement par lots et d’autres fonctionnalités qui fournies par des applications distribuées dans l’environnement Hadoop.
HBase est une excellente destination pour des données de capteur et de journal à des fins d’analyse future.
L’adaptabilité de HBase est déterminée par le nombre de nœuds contenus dans le cluster HDInsight.
Bases de données Azure SQL
Azure propose trois bases de données relationnelles PaaS :
- Azure SQL Database est une implémentation de Microsoft SQL Server. Pour en savoir plus sur les performances, consultez Paramétrage des performances dans Azure SQL Database.
- Azure Database pour MySQL est une implémentation d’Oracle MySQL.
- Azure Database pour PostgreSQL est une implémentation de PostgreSQL.
Ajoutez de la capacité de traitement et de mémoire pour mettre à l’échelle ces produits. Vous pouvez également choisir d’utiliser des disques Premium avec les produits pour bénéficier de meilleures performances d’E/S.
Azure Analysis Services
Azure Analysis Services est un moteur de données analytiques utilisé pour l’aide à la décision et l’analyse commerciale. Il fournit les données analytiques nécessaires pour des rapports commerciaux et des applications clientes telles que Power BI. Les données analytiques fonctionnent également avec Excel, SQL Server Reporting Services et d’autres outils de visualisation de données.
Mettez à l’échelle les cubes d’analyse en modifiant le niveau de chaque cube individuel. Pour en savoir plus, consultez Tarification d’Azure Analysis Services.
Extraire et charger
Une fois que les données existent dans Azure, vous pouvez utiliser de nombreux services pour les extraire et les charger dans d’autres produits. HDInsight prend en charge Sqoop et Flume.
Apache Sqoop
Apache Sqoop est un outil conçu pour transférer efficacement des données entre des sources de données structurées, semi-structurées et non structurées.
Sqoop utilise MapReduce pour importer et exporter les données, fournir une tolérance de panne et un fonctionnement parallèle.
Apache Flume
Apache Flume est un service distribué, fiable et disponible pour la collecte, l’agrégation et le déplacement efficaces de grandes quantités de données de journal. Son architecture flexible basée est sur des flux de données de diffusion en continu. Flume est robuste et tolérant aux pannes, et intègre des mécanismes de fiabilité réglables. Il possède de nombreux mécanismes de basculement et de récupération. Flume utilise un simple modèle de données extensible qui autorise l’application analytique en ligne.
Apache Flume ne peut pas être utilisé avec Azure HDInsight. Cependant, une installation Hadoop locale peut utiliser Flume pour envoyer des données à Stockage Blob Azure ou à Azure Data Lake Storage. Pour plus d’informations, consultez Utilisation d’Apache Flume avec HDInsight.
Transformer
Une fois les données présentes dans l’emplacement choisi, vous devez les nettoyer, les combiner ou les préparer pour un modèle d’utilisation spécifique. Hive, Pig et Spark SQL sont des choix adéquats pour ce type de travail. Ils sont tous pris en charge sur HDInsight.