Comment utiliser le metastore Hive avec un cluster Apache Spark™
Remarque
Nous allons mettre hors service Azure HDInsight sur AKS le 31 janvier 2025. Avant le 31 janvier 2025, vous devrez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent afin d’éviter leur arrêt brutal. Les clusters restants de votre abonnement seront arrêtés et supprimés de l’hôte.
Seul le support de base est disponible jusqu’à la date de mise hors service.
Important
Cette fonctionnalité est disponible actuellement en mode Aperçu. Les Conditions d’utilisation supplémentaires pour les préversions de Microsoft Azure contiennent davantage de conditions légales qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou ne se trouvant pas encore en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les Informations sur la préversion d’Azure HDInsight sur AKS. Pour toute question ou pour des suggestions à propos des fonctionnalités, veuillez envoyer vos requêtes et leurs détails sur AskHDInsight, et suivez-nous sur la Communauté Azure HDInsight pour plus de mises à jour.
Il est essentiel de partager les données et le metastore sur plusieurs services. L'un des metastores couramment utilisés dans le metastore HIVE. HDInsight sur AKS permet aux utilisateurs de se connecter à un metastore externe. Cette étape permet aux utilisateurs de HDInsight de se connecter de manière transparente à d'autres services de l'écosystème.
Azure HDInsight sur AKS prend en charge les metastores personnalisés, recommandés pour les clusters de production. Les étapes clés impliquées sont
- Créer une base de données Azure SQL Database
- Créer un coffre de clés pour stocker les informations d'identification
- Configurez un Metastore pendant que vous créez un HDInsight sur un cluster AKS avec Apache Spark™
- Opérer sur un metastore externe (affiche les bases de données et effectue une sélection de limite 1).
Pendant que vous créez le cluster, le service HDInsight doit se connecter au metastore externe et vérifier vos informations d'identification.
Créer une base de données Azure SQL Database
Créez ou disposez d'une base de données Azure SQL existante avant de configurer un metastore Hive personnalisé pour un cluster HDInsight.
Remarque
Actuellement, nous prenons en charge uniquement Azure SQL Database pour le metastore HIVE. En raison des limitations de Hive, le caractère « – » (trait d'union) dans le nom de la base de données Metastore n'est pas pris en charge.
Créer un coffre de clés pour stocker les informations d'identification
Créez un coffre de clés Azure.
Le but de Key Vault est de vous permettre de stocker le mot de passe administrateur SQL Server défini lors de la création de la base de données SQL. HDInsight sur la plateforme AKS ne gère pas directement les informations d'identification. Par conséquent, il est nécessaire de stocker vos informations d’identification importantes dans Azure Key Vault. Découvrez les étapes pour créer un Azure Key Vault.
Publier la création d'Azure Key Vault attribuer les rôles suivants
Objet Role Notes Identité managée attribuée par l'utilisateur (le même UAMI que celui utilisé par le cluster HDInsight) Utilisateur des secrets Key Vault Découvrez comment Attribuer un rôle à UAMI Utilisateur (qui crée un secret dans Azure Key Vault) Administrateur Key Vault Découvrez comment Attribuer un rôle à l'utilisateur. Remarque
Sans ce rôle, l'utilisateur ne peut pas créer de secret.
-
Cette étape vous permet de conserver le mot de passe administrateur de votre serveur SQL comme secret dans Azure Key Vault. Ajoutez votre mot de passe (même mot de passe que celui fourni dans la base de données SQL pour l'administrateur) dans le champ « Valeur » tout en ajoutant un secret.
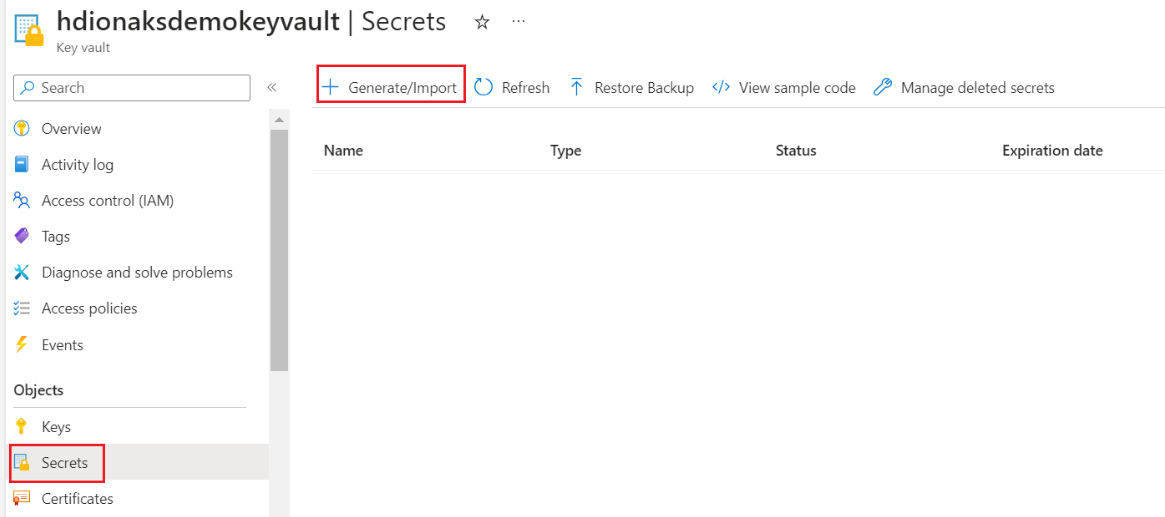

Remarque
Assurez-vous de noter le nom du secret, car vous en aurez besoin lors de la création du cluster.


Configurez Metastore pendant que vous créez un cluster HDInsight Spark
Accédez à HDInsight sur le pool de clusters AKS pour créer des clusters.
Activez le bouton bascule pour ajouter un metastore Hive externe et remplissez les détails suivants.
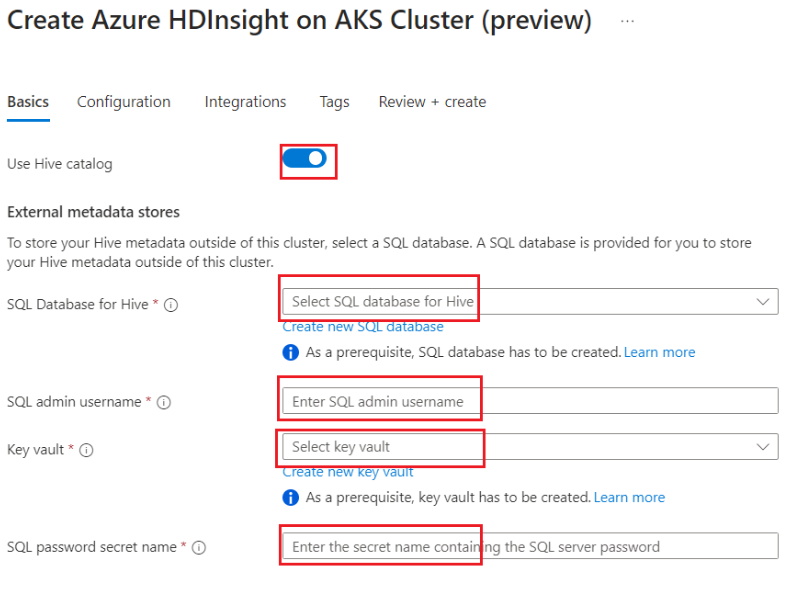
Les détails restant doivent être renseignés conformément aux règles de création de cluster pour le cluster Apache Spark dans HDInsight sur AKS.
Cliquez sur Vérifier et créer.
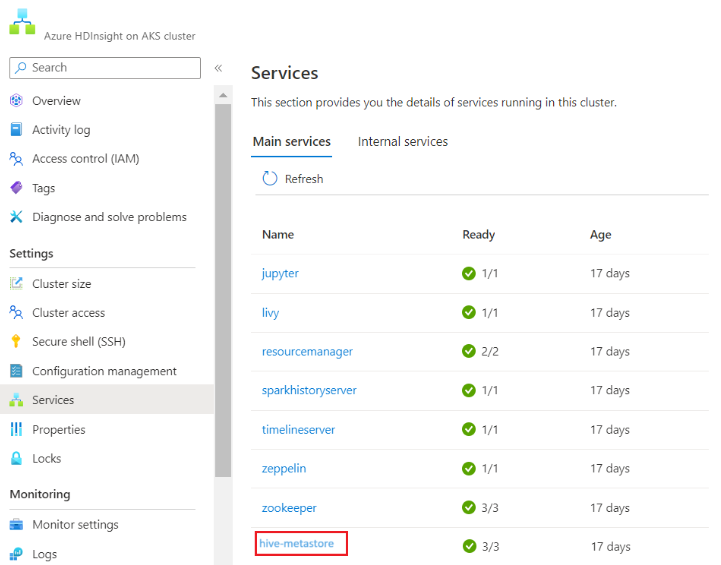
Remarque
- Le cycle de vie du metastore n’est pas lié à un cycle de vie de cluster. Vous pouvez donc créer et supprimer des clusters sans perdre les métadonnées. Les métadonnées telles que vos schémas Hive persistent même après la suppression et la recréation du cluster HDInsight.
- Un metastore personnalisé vous permet d’attacher plusieurs clusters et types de cluster à ce metastore.



Fonctionner sur un Metastore externe
Créer une table
>> spark.sql("CREATE TABLE sampleTable (number Int, word String)")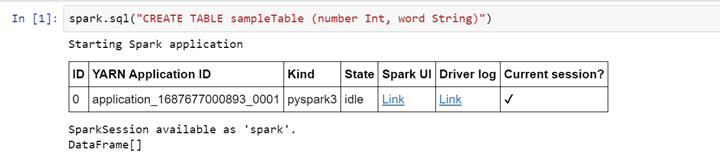
Ajouter des données sur la table
>> spark.sql("INSERT INTO sampleTable VALUES (123, \"HDIonAKS\")");\
Lire le tableau
>> spark.sql("select * from sampleTable").show()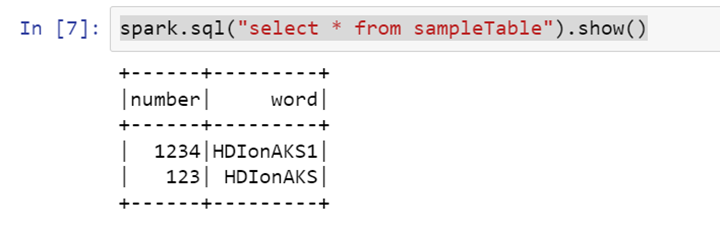



Référence
- Apache, Apache Spark, Spark et les noms de projet open source associés sont des marques de commerce d’Apache Software Foundation (ASF).