Envoyer et gérer des travaux sur un cluster Apache Spark™ dans HDInsight sur AKS
Remarque
Nous allons mettre hors service Azure HDInsight sur AKS le 31 janvier 2025. Avant le 31 janvier 2025, vous devrez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent afin d’éviter leur arrêt brutal. Les clusters restants de votre abonnement seront arrêtés et supprimés de l’hôte.
Seul le support de base est disponible jusqu’à la date de mise hors service.
Important
Cette fonctionnalité est disponible actuellement en mode Aperçu. Les Conditions d’utilisation supplémentaires pour les préversions de Microsoft Azure contiennent davantage de conditions légales qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou ne se trouvant pas encore en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les Informations sur la préversion d’Azure HDInsight sur AKS. Pour toute question ou pour des suggestions à propos des fonctionnalités, veuillez envoyer vos requêtes et leurs détails sur AskHDInsight, et suivez-nous sur la Communauté Azure HDInsight pour plus de mises à jour.
Une fois le cluster créé, l’utilisateur peut utiliser différentes interfaces pour envoyer et gérer des travaux
- en utilisation Jupyter
- en utilisant Zeppelin
- en utilisant ssh (spark-submit)
Utilisation de Jupyter
Prérequis
Un cluster Apache Spark™ dans HDInsight sur AKS. Pour plus d’informations, consultez Créer un cluster Apache Spark.
Jupyter Notebook est un environnement de bloc-notes interactif qui prend en charge divers langages de programmation.
Créer un bloc-notes Jupyter Notebook
Accédez à la page du cluster Apache Spark™ et ouvrez l’onglet Vue d’ensemble. Cliquez sur Jupyter, il vous demandera de vous authentifier et d’ouvrir la page web Jupyter.

Sur la page web de Jupyter, sélectionnez Nouveau > PySpark pour créer un notebook.
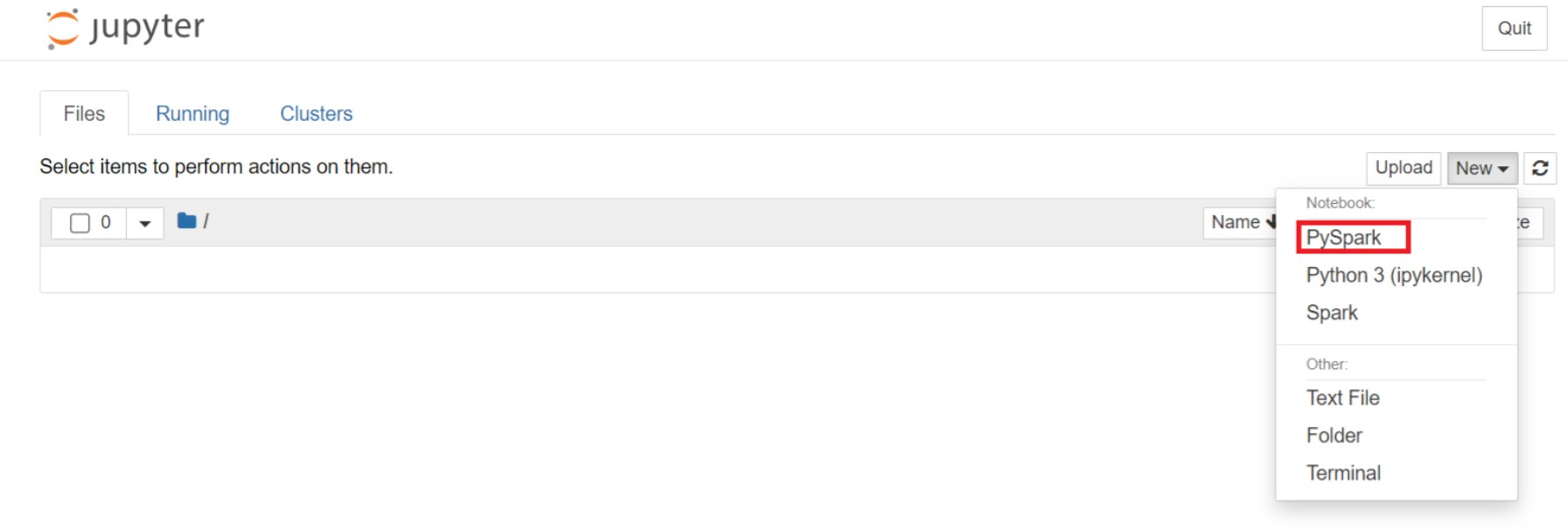
Un nouveau notebook est créé et ouvert avec le nom
Untitled(Untitled.ipynb).Remarque
En utilisant le noyau PySpark ou Python 3 pour créer un notebook, la session Spark est automatiquement créée lorsque vous exécutez la première cellule de code. Vous n’avez pas besoin de créer explicitement la session.
Collez l’exemple de code suivant dans une cellule vide du notebook Jupyter, puis appuyez sur MAJ + ENTRÉE pour exécuter le code. Voir ici pour plus de contrôles sur Jupyter.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Tracer un graphique avec Salaire et âge comme axes X et Y
Dans le même notebook, collez l’exemple de code suivant dans une cellule vide du Jupyter Notebook, puis appuyez sur MAJ + ENTRÉE pour exécuter le code.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()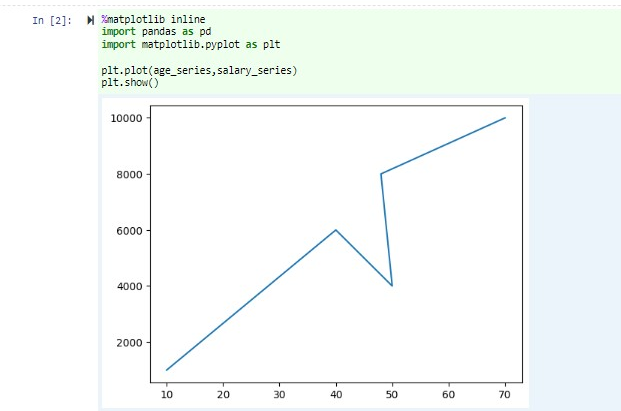




Enregistrer le Notebook
Dans la barre de menus du notebook, accédez à Fichier > Enregistrer et Point de contrôle.
Arrêtez le notebook pour libérer les ressources de cluster : dans la barre de menus, accédez à Fichier > Fermer et Arrêter. Vous pouvez également exécuter l’un des notebooks sous le dossier exemples.


Utilisation des notebooks Apache Zeppelin
Les clusters Apache Spark dans HDInsight sur AKS incluent des notebooks Apache Zeppelin. Utilisez les notebooks pour exécuter des travaux Apache Spark. Dans cet article, vous allez apprendre à utiliser le notebook Zeppelin sur un cluster HDInsight sur AKS.
Prérequis
Un cluster Apache Spark de HDInsight sur AKS. Pour en savoir plus, consultez Créer un cluster Apache Spark.
Lancer un bloc-notes Apache Zeppelin
Accédez à la page Vue d’ensemble du cluster Apache Spark et sélectionnez le notebook Zeppelin dans les tableaux de bord du cluster. Il demande à s’authentifier et à ouvrir la page Zeppelin.
Créez un nouveau bloc-notes. Dans le volet d'en-tête, accédez à Notebook > Créer une nouvelle note. Vérifiez que l'en-tête du bloc-notes indique un état connecté. Il désigne un point vert dans le coin supérieur droit.
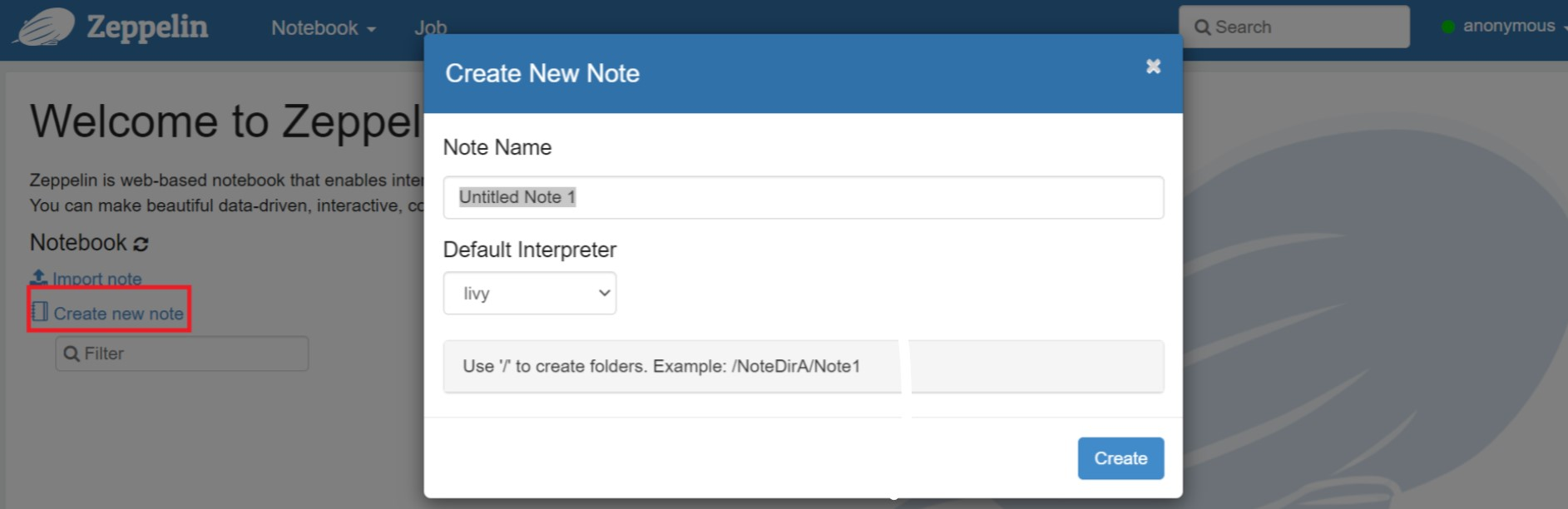
Exécutez le code suivant dans Zeppelin Notebook :
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Sélectionnez le bouton Lire pour que le paragraphe exécute l’extrait de code. L’état indiqué dans le coin supérieur droit du paragraphe doit progresser de READY, PENDING, RUNNING à FINISHED. Le résultat s’affiche au bas du même paragraphe. La capture d’écran ressemble à l’image suivante :

Sortie :





Utilisation des travaux d’envoi Spark
Créez un fichier à l’aide de la commande suivante « #vim samplefile.py »
Cette commande ouvre le fichier vim
Collez le code suivant dans le fichier vim
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Enregistrez le fichier avec la méthode suivante.
- Appuyez sur le bouton Échapper
- Entrez la commande
:wq
Exécutez la commande suivante pour exécuter le travail.
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

Monitorer des requêtes sur un cluster Apache Spark dans HDInsight sur AKS
Interface utilisateur de l’historique Spark
Cliquez sur l’interface utilisateur du serveur d’historique Spark dans l’onglet Vue d’ensemble.

Sélectionnez l’exécution récente à partir de l’interface utilisateur à l’aide du même ID d’application.
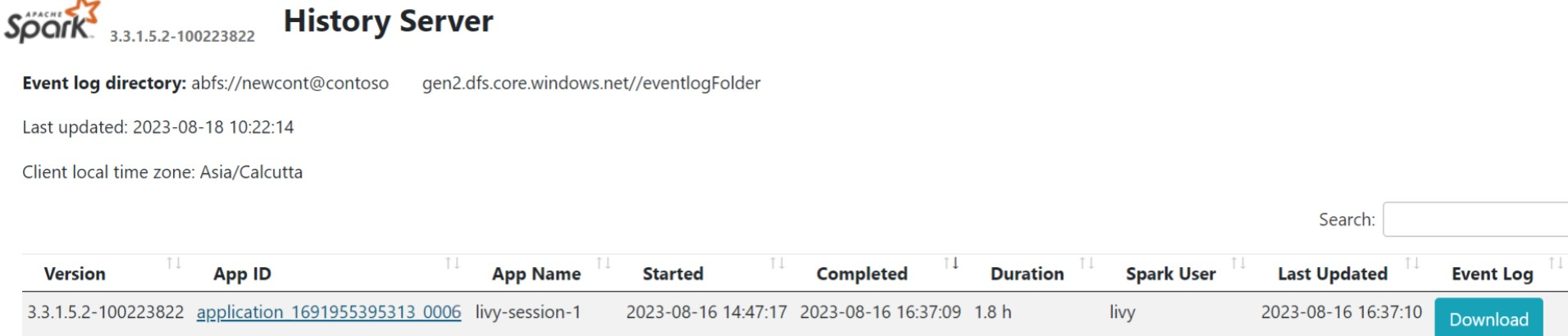
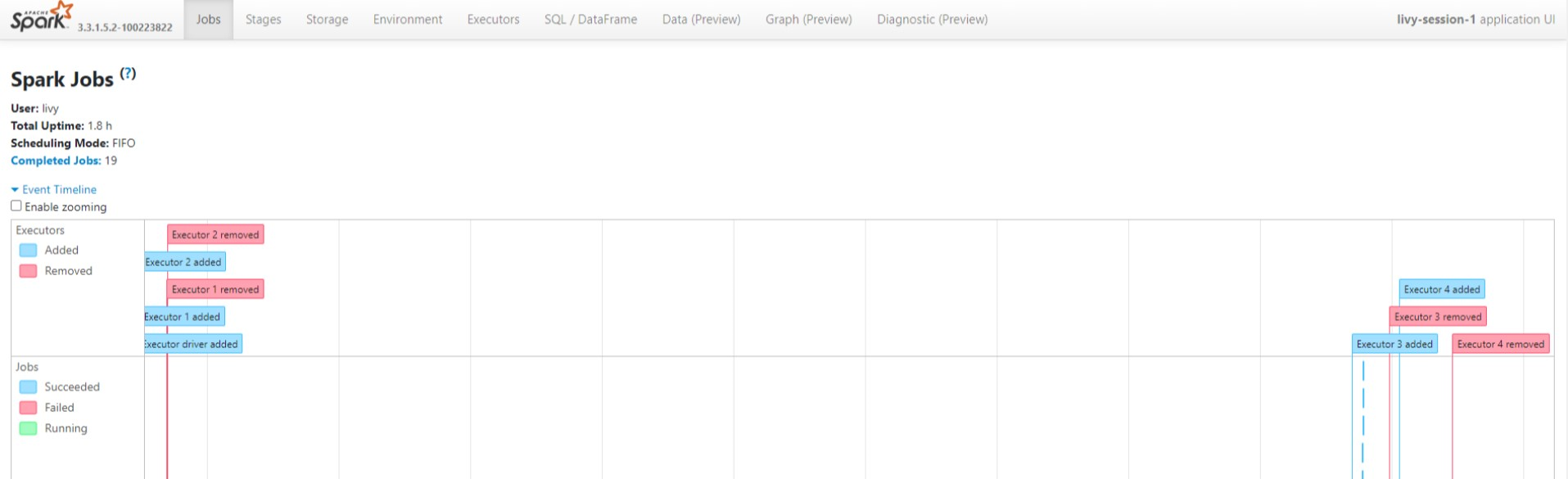
Affichez les cycles de graphe orienté acyclique et les étapes du travail dans l’interface utilisateur du serveur d’historique Spark.



Interface utilisateur de la session Livy
Pour ouvrir l’interface utilisateur de la session Livy, tapez la commande suivante dans votre navigateur
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui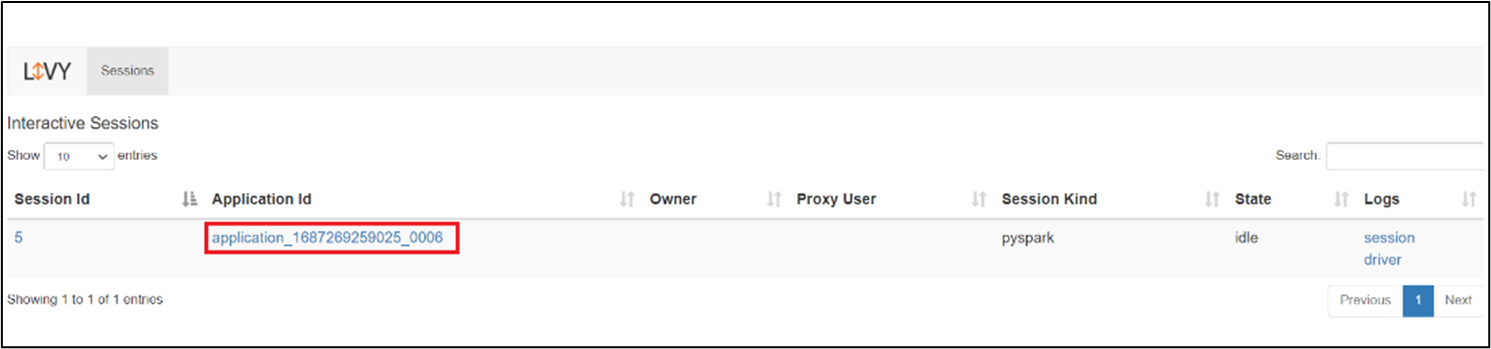
Affichez les journaux du pilote en cliquant sur l’option de pilote sous journaux.

Interface utilisateur YARN
Dans l’onglet Vue d’ensemble, cliquez sur Yarn et ouvrez l’interface utilisateur Yarn.
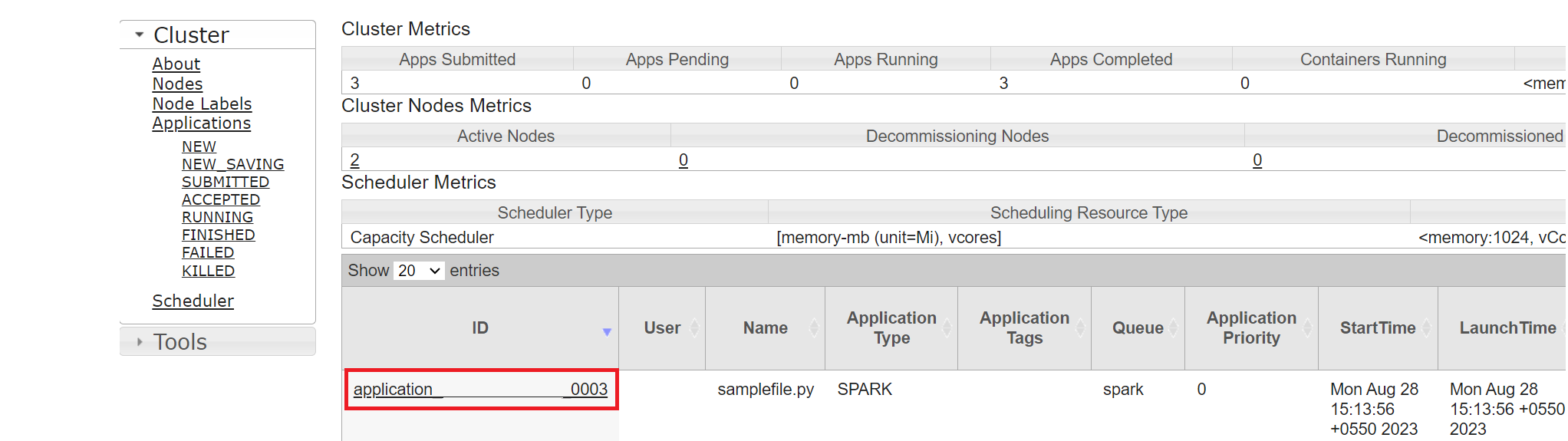
Vous pouvez suivre le travail que vous avez récemment exécuté par le même ID d’application.
Cliquez sur l’ID d’application dans Yarn pour afficher les journaux détaillés du travail.


Référence
- Apache, Apache Spark, Spark et les noms de projet open source associés sont des marques de commerce d’Apache Software Foundation (ASF).