Écrire des messages dans Apache HBase® avec l’API DataStream d’Apache Flink®
Remarque
Nous allons mettre hors service Azure HDInsight sur AKS le 31 janvier 2025. Avant le 31 janvier 2025, vous devrez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent afin d’éviter leur arrêt brutal. Les clusters restants de votre abonnement seront arrêtés et supprimés de l’hôte.
Seul le support de base est disponible jusqu’à la date de mise hors service.
Important
Cette fonctionnalité est disponible actuellement en mode Aperçu. Les Conditions d’utilisation supplémentaires pour les préversions de Microsoft Azure contiennent davantage de conditions légales qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou ne se trouvant pas encore en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les Informations sur la préversion d’Azure HDInsight sur AKS. Pour toute question ou pour des suggestions à propos des fonctionnalités, veuillez envoyer vos requêtes et leurs détails sur AskHDInsight, et suivez-nous sur la Communauté Azure HDInsight pour plus de mises à jour.
Dans cet article, découvrez comment écrire des messages dans HBase avec l’API Apache Flink DataStream.
Vue d’ensemble
Apache Flink propose un connecteur HBase en tant que récepteur. Grâce à ce connecteur, Flink peut stocker la sortie d’une application de traitement en temps réel dans HBase. Découvrez comment traiter des données en continu sur HDInsight Kafka en tant que source, effectuer des transformations, puis plonger dans la table HDInsight HBase.
Dans un scénario réel, cet exemple est une couche d’analyse de flux permettant de valoriser les analyses de l’Internet des objets (IOT), qui utilisent des données de capteurs dynamiques. Le flux Flink peut lire les données de l’article Kafka et l’écrire dans la table HBase. S’il existe une application IOT de streaming en temps réel, les informations peuvent être collectées, transformées et optimisées.
Prérequis
- Cluster Apache Flink sur HDInsight sur AKS
- Cluster Apache Kafka sur HDInsight
- Cluster Apache HBase 2.4.11 sur HDInsight
- Vous devez vérifier que HDInsight sur un cluster AKS peut se connecter à un cluster HDInsight avec le même réseau virtuel.
- Projet Maven sur IntelliJ IDEA pour le développement sur une machine virtuelle Azure dans le même réseau virtuel (VNet)
Étapes d’implémentation
Utiliser le pipeline pour produire une rubrique Kafka (rubrique d’événement click de l’utilisateur)
weblog.py
import json
import random
import time
from datetime import datetime
user_set = [
'John',
'XiaoMing',
'Mike',
'Tom',
'Machael',
'Zheng Hu',
'Zark',
'Tim',
'Andrew',
'Pick',
'Sean',
'Luke',
'Chunck'
]
web_set = [
'https://github.com',
'https://www.bing.com/new',
'https://kafka.apache.org',
'https://hbase.apache.org',
'https://flink.apache.org',
'https://spark.apache.org',
'https://trino.io',
'https://hadoop.apache.org',
'https://stackoverflow.com',
'https://docs.python.org',
'https://azure.microsoft.com/products/category/storage',
'/azure/hdinsight/hdinsight-overview',
'https://azure.microsoft.com/products/category/storage'
]
def main():
while True:
if random.randrange(13) < 4:
url = random.choice(web_set[:3])
else:
url = random.choice(web_set)
log_entry = {
'userName': random.choice(user_set),
'visitURL': url,
'ts': datetime.now().strftime("%m/%d/%Y %H:%M:%S")
}
print(json.dumps(log_entry))
time.sleep(0.05)
if __name__ == "__main__":
main()
Utiliser un pipeline pour produire une rubrique Apache Kafka
Nous allons utiliser click_events pour la rubrique Kafka
python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
Exemples de commandes sur Kafka
-- create topic (replace with your Kafka bootstrap server)
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 3 --topic click_events --bootstrap-server wn0-contsk:9092
-- delete topic (replace with your Kafka bootstrap server)
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic click_events --bootstrap-server wn0-contsk:9092
-- produce topic (replace with your Kafka bootstrap server)
python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
-- consume topic
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server wn0-contsk:9092 --topic click_events --from-beginning
{"userName": "Luke", "visitURL": "https://azure.microsoft.com/products/category/storage", "ts": "07/11/2023 06:39:43"}
{"userName": "Sean", "visitURL": "https://www.bing.com/new", "ts": "07/11/2023 06:39:43"}
{"userName": "XiaoMing", "visitURL": "https://hbase.apache.org", "ts": "07/11/2023 06:39:43"}
{"userName": "Machael", "visitURL": "https://www.bing.com/new", "ts": "07/11/2023 06:39:43"}
{"userName": "Andrew", "visitURL": "https://github.com", "ts": "07/11/2023 06:39:43"}
{"userName": "Zark", "visitURL": "https://kafka.apache.org", "ts": "07/11/2023 06:39:43"}
{"userName": "XiaoMing", "visitURL": "https://trino.io", "ts": "07/11/2023 06:39:43"}
{"userName": "Zark", "visitURL": "https://flink.apache.org", "ts": "07/11/2023 06:39:43"}
{"userName": "Mike", "visitURL": "https://kafka.apache.org", "ts": "07/11/2023 06:39:43"}
{"userName": "Zark", "visitURL": "https://docs.python.org", "ts": "07/11/2023 06:39:44"}
{"userName": "John", "visitURL": "https://www.bing.com/new", "ts": "07/11/2023 06:39:44"}
{"userName": "Mike", "visitURL": "https://hadoop.apache.org", "ts": "07/11/2023 06:39:44"}
{"userName": "Tim", "visitURL": "https://www.bing.com/new", "ts": "07/11/2023 06:39:44"}
.....
Créer une table HBase sur un cluster HDInsight
root@hn0-contos:/home/sshuser# hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/hdp/5.1.1.3/hadoop/lib/slf4j-reload4j-1.7.35.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hdp/5.1.1.3/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Reload4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For more information, see, http://hbase.apache.org/2.0/book.html#shell
Version 2.4.11.5.1.1.3, rUnknown, Thu Apr 20 12:31:07 UTC 2023
Took 0.0032 seconds
hbase:001:0> create 'user_click_events','user_info'
Created table user_click_events
Took 5.1399 seconds
=> Hbase::Table - user_click_events
hbase:002:0>
Développer le projet pour envoyer un fichier jar sur Flink
créer un projet maven avec les pom.xml suivantes
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>contoso.example</groupId>
<artifactId>FlinkHbaseDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<hbase.version>2.4.11</hbase.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-hbase-base -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-base</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-base -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Code source
Écrire le programme HBase Sink
HBaseWriterSink
package contoso.example;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseWriterSink extends RichSinkFunction<Tuple3<String,String,String>> {
String hbase_zk = "<update-hbasezk-ip>:2181,<update-hbasezk-ip>:2181,<update-hbasezk-ip>:2181";
Connection hbase_conn;
Table tb;
int i = 0;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
org.apache.hadoop.conf.Configuration hbase_conf = HBaseConfiguration.create();
hbase_conf.set("hbase.zookeeper.quorum", hbase_zk);
hbase_conf.set("zookeeper.znode.parent", "/hbase-unsecure");
hbase_conn = ConnectionFactory.createConnection(hbase_conf);
tb = hbase_conn.getTable(TableName.valueOf("user_click_events"));
}
@Override
public void invoke(Tuple3<String,String,String> value, Context context) throws Exception {
byte[] rowKey = Bytes.toBytes(String.format("%010d", i++));
Put put = new Put(rowKey);
put.addColumn(Bytes.toBytes("user_info"), Bytes.toBytes("userName"), Bytes.toBytes(value.f0));
put.addColumn(Bytes.toBytes("user_info"), Bytes.toBytes("visitURL"), Bytes.toBytes(value.f1));
put.addColumn(Bytes.toBytes("user_info"), Bytes.toBytes("ts"), Bytes.toBytes(value.f2));
tb.put(put);
};
public void close() throws Exception {
if (null != tb) tb.close();
if (null != hbase_conn) hbase_conn.close();
}
}
main:KafkaSinkToHbase
Écrire un programme Kafka Sink vers HBase
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class KafkaSinkToHbase {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
String kafka_brokers = "10.0.0.38:9092,10.0.0.39:9092,10.0.0.40:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(kafka_brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafka = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source").setParallelism(1);
DataStream<Tuple3<String,String,String>> dataStream = kafka.map(line-> {
String[] fields = line.toString().replace("{","").replace("}","").
replace("\"","").split(",");
Tuple3<String, String,String> tuple3 = Tuple3.of(fields[0].substring(10),fields[1].substring(11),fields[2].substring(5));
return tuple3;
}).returns(Types.TUPLE(Types.STRING,Types.STRING,Types.STRING));
dataStream.addSink(new HBaseWriterSink());
env.execute("Kafka Sink To Hbase");
}
}
Envoi du travail
Chargez le fichier jar du travail dans le compte de stockage associé au cluster.
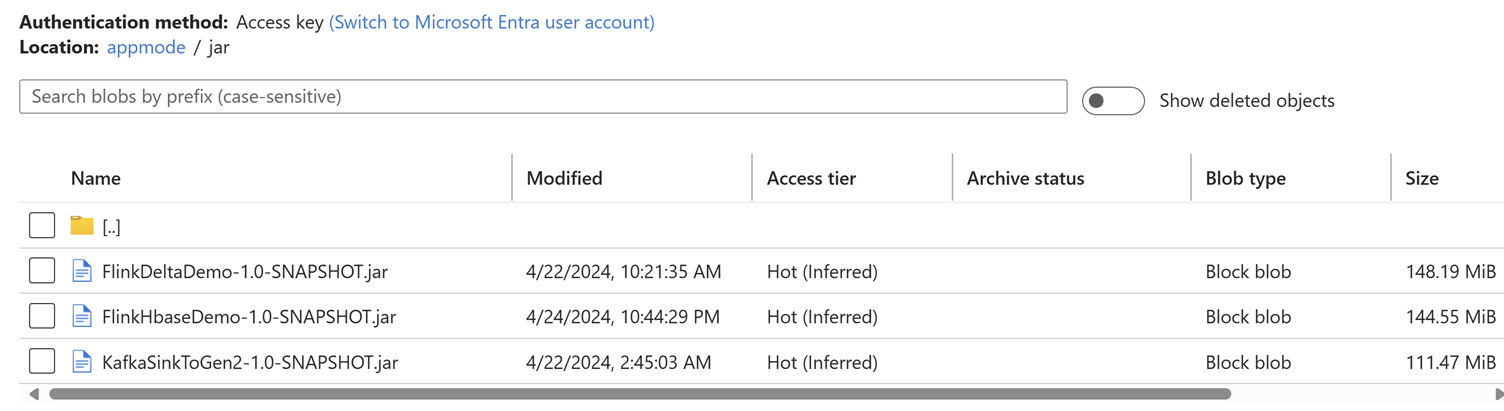
Ajoutez les détails du travail sous l’onglet Mode Application.
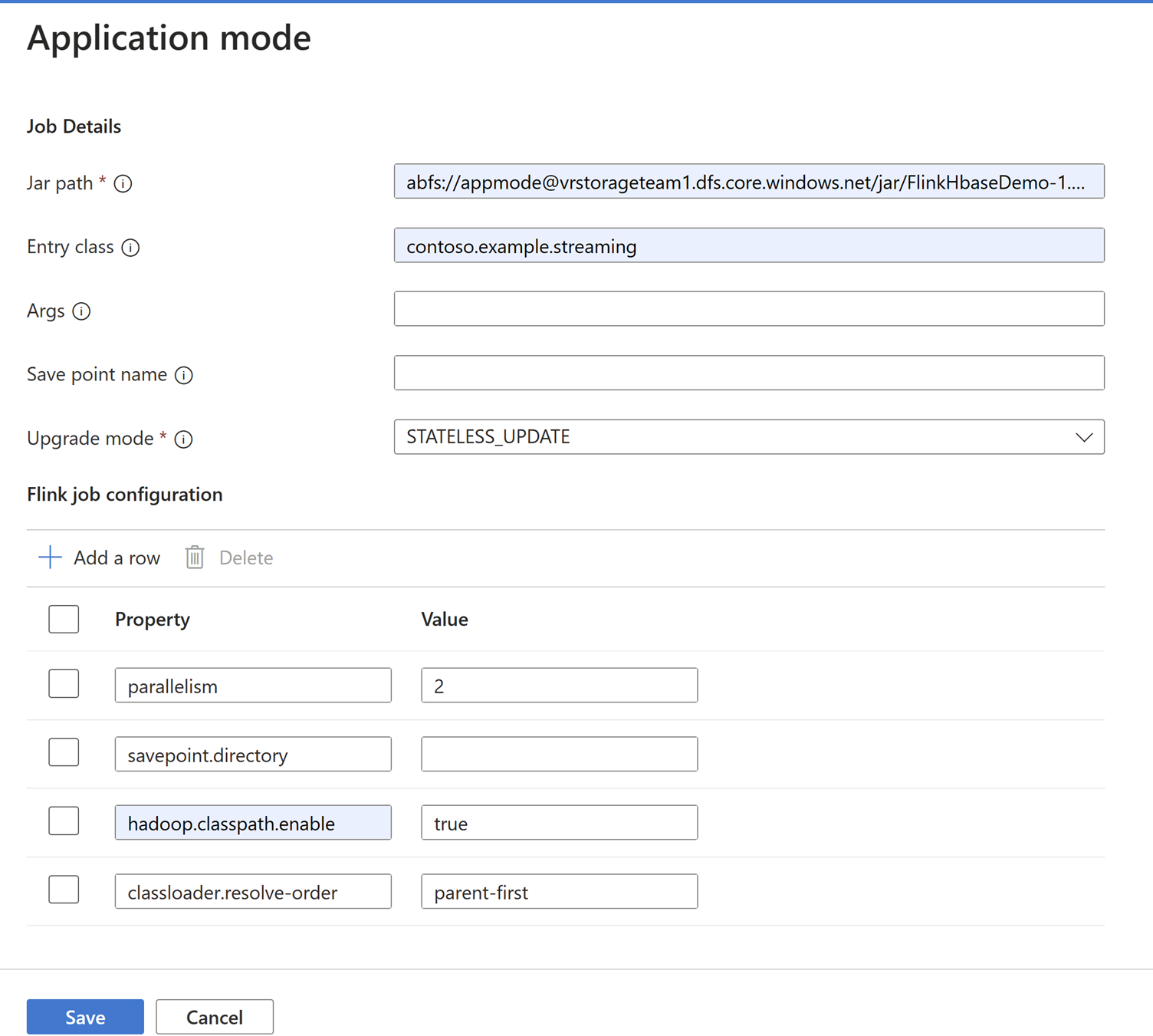
Remarque
Veillez à ajouter
Hadoop.class.enableetclassloader.resolve-orderparamètre.Sélectionnez agrégation de journaux de travaux pour stocker les journaux d’activité dans ABFS.
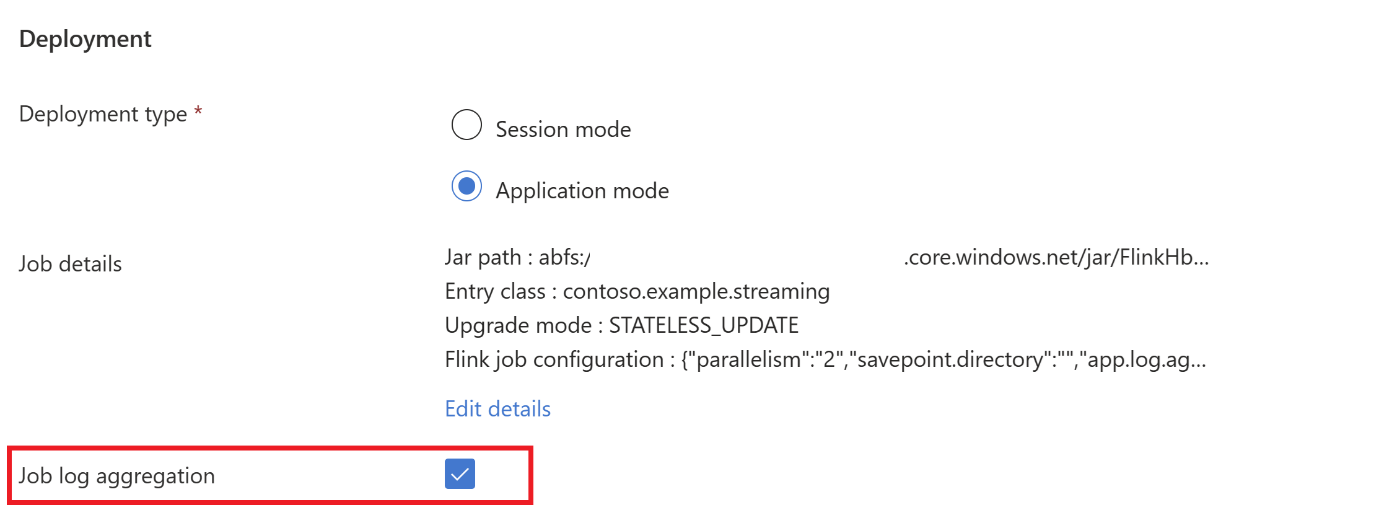
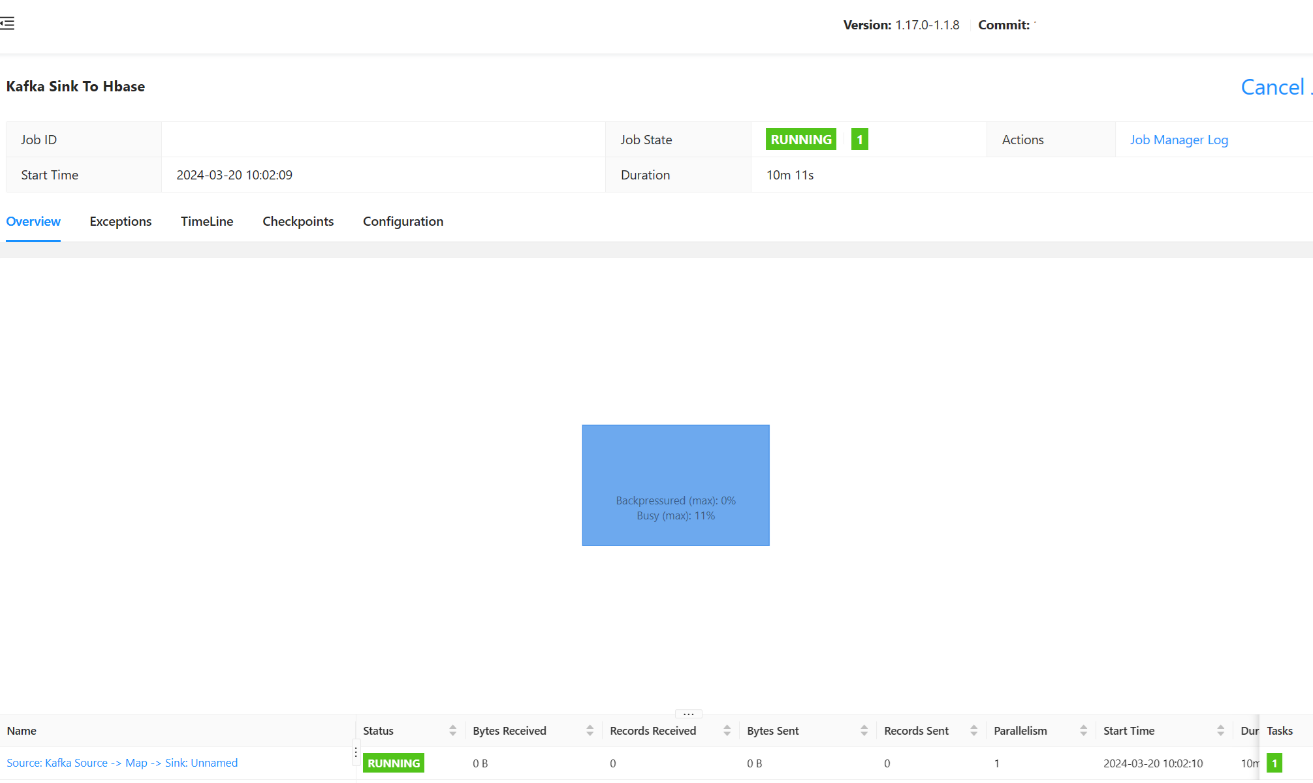
Envoyez le travail.
Vous devriez être en mesure de voir l’état envoyé par le travail ici.




Valider les données des tables HBase
hbase:001:0> scan 'user_click_events',{LIMIT=>5}
ROW COLUMN+CELL
0000000000 column=user_info:ts, timestamp=2024-03-20T02:02:46.932, value=03/20/2024 02:02:43
0000000000 column=user_info:userName, timestamp=2024-03-20T02:02:46.932, value=Pick
0000000000 column=user_info:visitURL, timestamp=2024-03-20T02:02:46.932, value=
https://hadoop.apache.org
0000000001 column=user_info:ts, timestamp=2024-03-20T02:02:46.991, value=03/20/2024 02:02:43
0000000001 column=user_info:userName, timestamp=2024-03-20T02:02:46.991, value=Zheng Hu
0000000001 column=user_info:visitURL, timestamp=2024-03-20T02:02:46.991, value=/azure/hdinsight/hdinsight-overview
0000000002 column=user_info:ts, timestamp=2024-03-20T02:02:47.001, value=03/20/2024 02:02:43
0000000002 column=user_info:userName, timestamp=2024-03-20T02:02:47.001, value=Sean
0000000002 column=user_info:visitURL, timestamp=2024-03-20T02:02:47.001, value=
https://spark.apache.org
0000000003 column=user_info:ts, timestamp=2024-03-20T02:02:47.008, value=03/20/2024 02:02:43
0000000003 column=user_info:userName, timestamp=2024-03-20T02:02:47.008, value=Zheng Hu
0000000003 column=user_info:visitURL, timestamp=2024-03-20T02:02:47.008, value=
https://kafka.apache.org
0000000004 column=user_info:ts, timestamp=2024-03-20T02:02:47.017, value=03/20/2024 02:02:43
0000000004 column=user_info:userName, timestamp=2024-03-20T02:02:47.017, value=Chunck
0000000004 column=user_info:visitURL, timestamp=2024-03-20T02:02:47.017, value=
https://github.com
5 row(s)
Took 0.9269 seconds
Remarque
- FlinkKafkaConsumer est déconseillé et supprimé avec Flink 1.17. Utilisez KafkaSource à la place.
- FlinkKafkaConsumer est déconseillé et supprimé avec Flink 1.15. Utilisez KafkaSink à la place.
Références
- Connecteur Apache Kafka
- Télécharger IntelliJ IDEA
- Apache, Apache Kafka, Kafka, Apache HBase, HBase, Apache Flink, Flink et les noms de projet open source associés sont des marques d’Apache Software Foundation (ASF).