Comment utiliser Azure Pipelines avec Apache Flink® pour HDInsight sur AKS
Remarque
Nous allons mettre hors service Azure HDInsight sur AKS le 31 janvier 2025. Avant le 31 janvier 2025, vous devrez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent afin d’éviter leur arrêt brutal. Les clusters restants de votre abonnement seront arrêtés et supprimés de l’hôte.
Seul le support de base est disponible jusqu’à la date de mise hors service.
Important
Cette fonctionnalité est disponible actuellement en mode Aperçu. Les Conditions d’utilisation supplémentaires pour les préversions de Microsoft Azure contiennent davantage de conditions légales qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou ne se trouvant pas encore en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les Informations sur la préversion d’Azure HDInsight sur AKS. Pour toute question ou pour des suggestions à propos des fonctionnalités, veuillez envoyer vos requêtes et leurs détails sur AskHDInsight, et suivez-nous sur la Communauté Azure HDInsight pour plus de mises à jour.
Dans cet article, vous allez apprendre à utiliser Azure Pipelines avec HDInsight sur AKS pour soumettre des travaux Flink avec l’API REST du cluster. Nous vous guidons tout au long du processus à l'aide d'un exemple de pipeline YAML et d'un script PowerShell, qui rationalisent tous deux l'automatisation des interactions de l'API REST.
Prérequis
Abonnement Azure. Si vous n'avez pas d'abonnement Azure, créez un compte gratuit.
Un compte GitHub dans lequel vous pouvez créer un référentiel. Créez-en un gratuitement.
Créez un répertoire
.pipeline, copiez flink-azure-pipelines.yml et flink-job-azure-pipeline.ps1Organisation Azure DevOps. Créez-en un gratuitement. Si votre équipe en possède déjà un, assurez-vous que vous êtes administrateur du projet Azure DevOps que vous souhaitez utiliser.
Possibilité d'exécuter des pipelines sur des agents hébergés par Microsoft. Pour utiliser des agents hébergés par Microsoft, votre organisation Azure DevOps doit avoir accès aux travaux parallèles hébergés par Microsoft. Vous pouvez acheter un travail parallèle ou demander un octroi gratuit.
Un cluster Flink. Si vous n'en avez pas, Créez un cluster Flink dans HDInsight sur AKS.
Créez un répertoire dans le compte de stockage du cluster pour copier le fichier jar de travail. Plus tard, vous devrez configurer ce répertoire dans le pipeline YAML pour l'emplacement du fichier jar de travail (<JOB_JAR_STORAGE_PATH>).
Étapes pour configurer le pipeline
Créer un principal de service pour Azure Pipelines
Créez un principal de service Microsoft Entra pour accéder à Azure – Accordez l’autorisation d’accéder à HDInsight sur le cluster AKS avec le rôle de contributeur, notez l’ID d’application, le mot de passe et le locataire dans la réponse.
az ad sp create-for-rbac -n <service_principal_name> --role Contributor --scopes <Flink Cluster Resource ID>`
Exemple :
az ad sp create-for-rbac -n azure-flink-pipeline --role Contributor --scopes /subscriptions/abdc-1234-abcd-1234-abcd-1234/resourceGroups/myResourceGroupName/providers/Microsoft.HDInsight/clusterpools/hiloclusterpool/clusters/flinkcluster`
Référence
Remarque
Apache, Apache Flink, Flink et les noms de projet open source associés sont des marques de commerce d’Apache Software Foundation (ASF).
Création d’un coffre de clés
Créez Azure Key Vault, vous pouvez suivre ce tutoriel pour créer un nouveau Azure Key Vault.
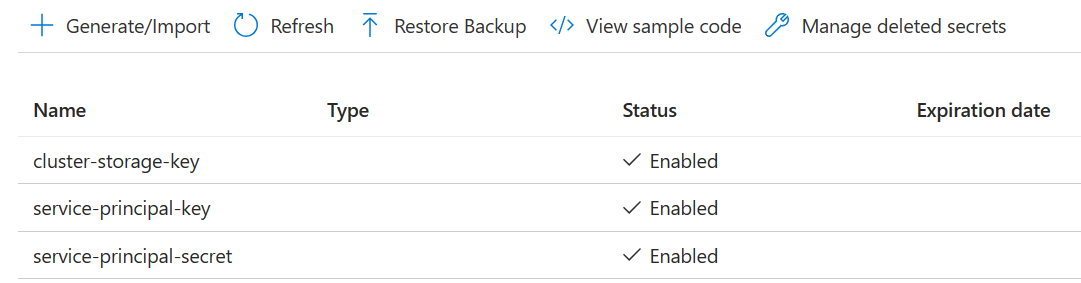
Créez trois Secrets
cluster-storage-key pour clé de rangement.
service-principal-key pour le clientId principal ou l’appId.
service-principal-secret pour secret principal.
Accordez l’autorisation d’accéder à Azure Key Vault avec le rôle « Key Vault Secrets Officer » au principal du service.

Configurer le pipeline
Accédez à votre projet et cliquez sur Paramètres du projet.
Faites défiler vers le bas et sélectionnez Connexions de service, puis Nouvelle connexion de service.
Sélectionnez Azure Resource Manager.
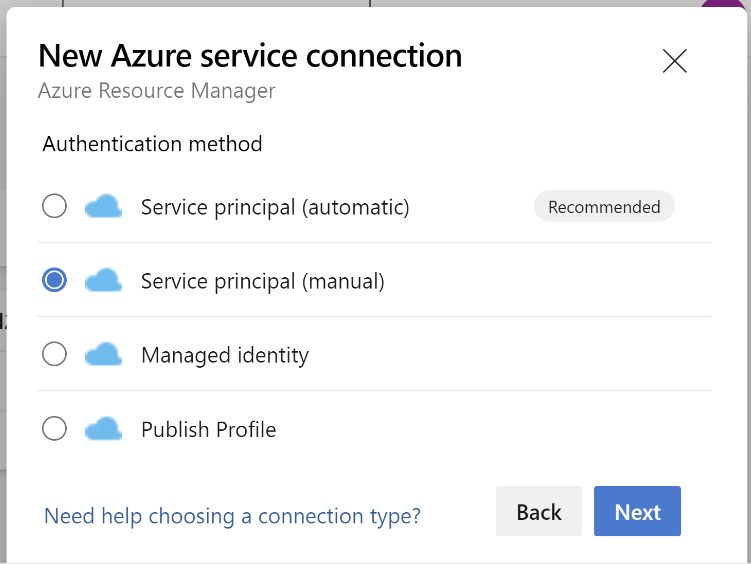
Dans la méthode d'authentification, sélectionnez Service Principal (manuel).
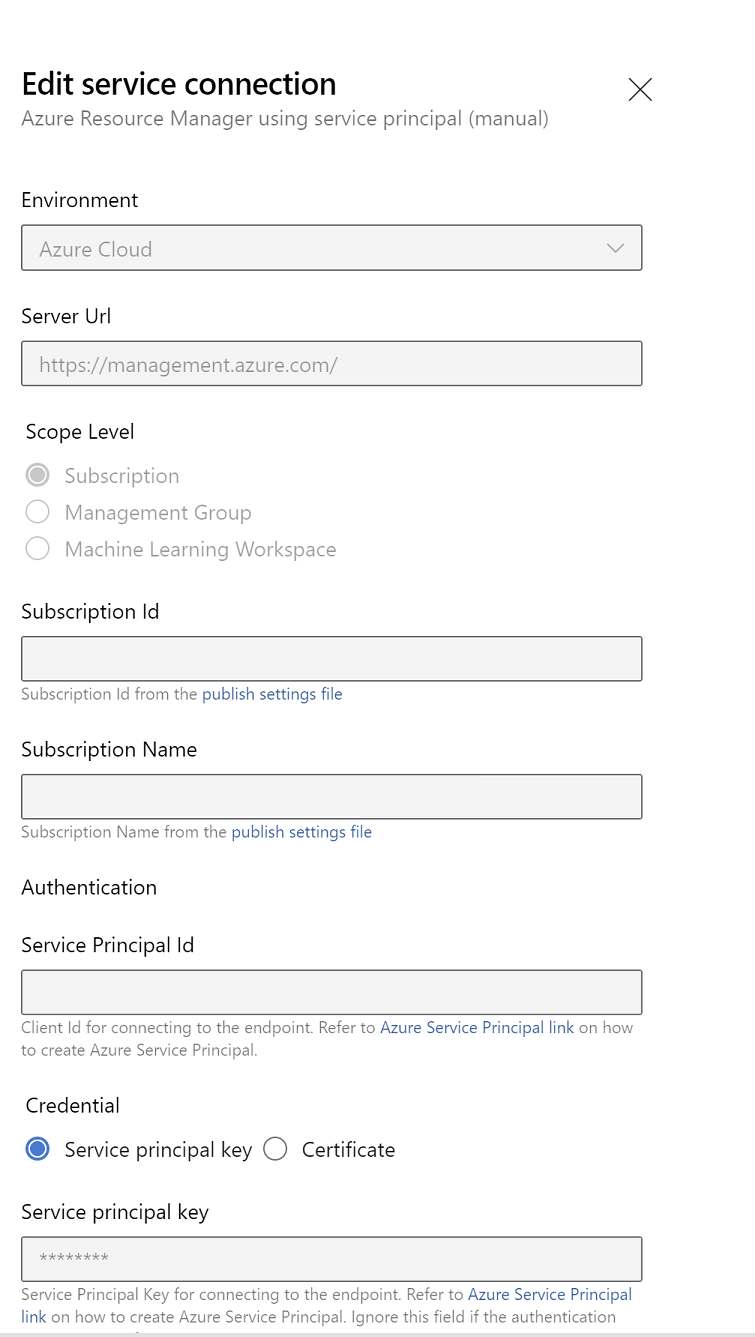
Modifiez les propriétés de connexion au service. Sélectionnez le principal de service que vous avez récemment créé.
Cliquez sur Vérifier pour vérifier si la connexion a été correctement configurée. Si vous rencontrez l'erreur suivante :

Ensuite, vous devez attribuer le rôle Lecteur à la souscription.
Après cela, la vérification devrait réussir.
Enregistrez la connexion de service.

Accédez aux pipelines et cliquez sur Nouveau pipeline.

Sélectionnez GitHub comme emplacement de votre code.
Sélectionnez le référentiel . Découvrez comment créer un référentiel dans GitHub. image select-github-repo.
Sélectionnez le référentiel . Pour plus d'informations, consultez Comment créer un référentiel dans GitHub.
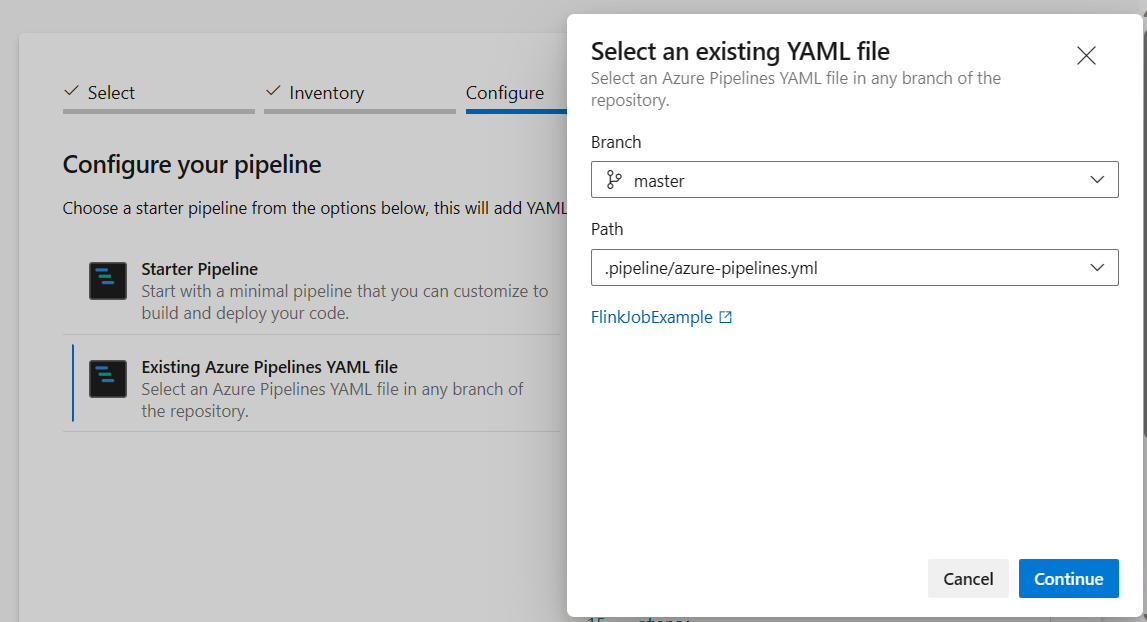
Dans la configuration de votre option de pipeline, vous pouvez choisir Fichier YAML Azure Pipelines existant. Sélectionnez le script de branche et de pipeline que vous avez copié précédemment. (.pipeline/flink-azure-pipelines.yml)
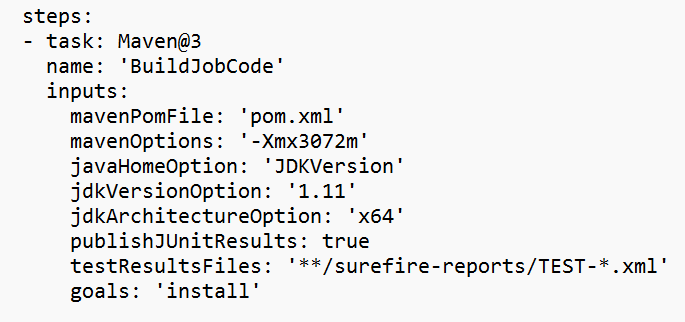
Remplacez la valeur dans la section variable.

Corrigez la section de construction de code en fonction de vos besoins et configurez <JOB_JAR_LOCAL_PATH> dans la section variable pour le chemin local du job jar.
Ajoutez la variable de pipeline « action » et configurez la valeur « RUN. »
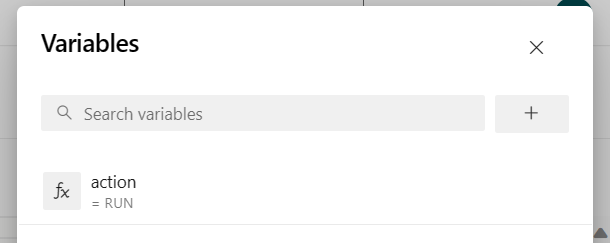
vous pouvez modifier les valeurs de la variable avant d'exécuter le pipeline.
NOUVEAU : Cette valeur est par défaut. Il lance un nouveau travail et si le travail est déjà en cours d'exécution, il met à jour le travail en cours avec le dernier fichier jar.
POINT DE SAUVEGARDE : Cette valeur prend le point de sauvegarde pour l’exécution du travail.
SUPPRIMER : Annuler ou supprimer le travail en cours.
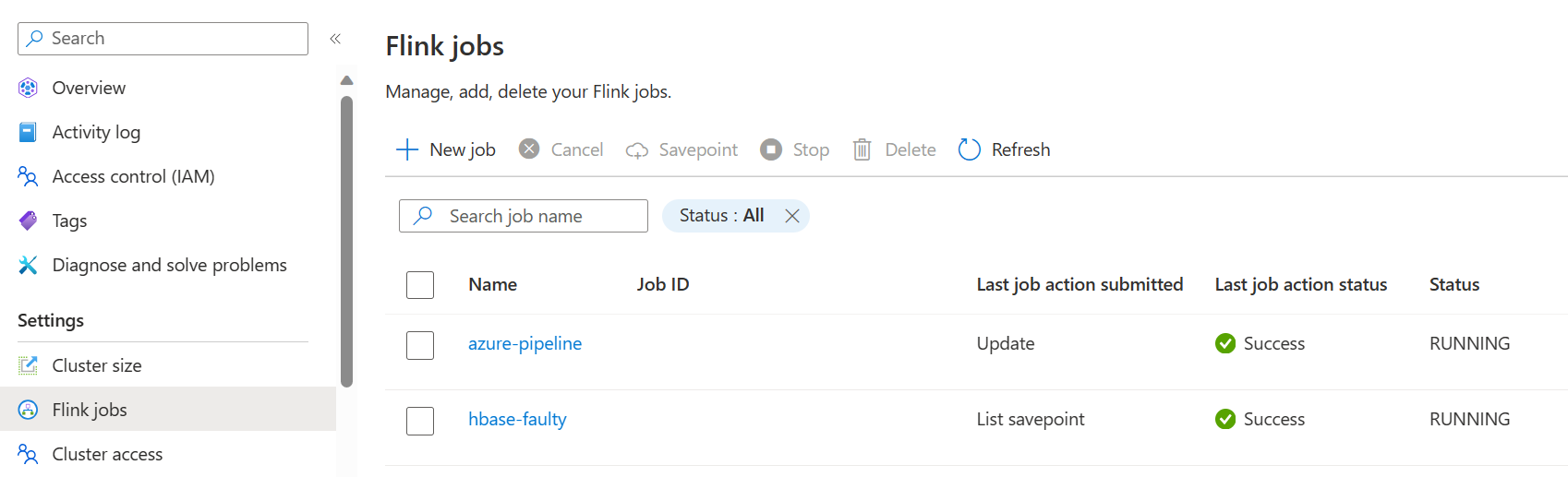
Enregistrez et exécutez le pipeline. Vous pouvez voir le travail en cours sur le portail dans la section Flink Job.








Remarque
Il s'agit d'un exemple pour soumettre le travail à l'aide d'un pipeline. Vous pouvez suivre la documentation de l'API Flink REST pour écrire votre propre code afin de soumettre le travail.