Démarrer l’interface CLI client SQL en mode passerelle
Remarque
Nous allons mettre hors service Azure HDInsight sur AKS le 31 janvier 2025. Avant le 31 janvier 2025, vous devrez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent afin d’éviter leur arrêt brutal. Les clusters restants de votre abonnement seront arrêtés et supprimés de l’hôte.
Seul le support de base est disponible jusqu’à la date de mise hors service.
Important
Cette fonctionnalité est disponible actuellement en mode Aperçu. Les Conditions d’utilisation supplémentaires pour les préversions de Microsoft Azure contiennent davantage de conditions légales qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou ne se trouvant pas encore en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les Informations sur la préversion d’Azure HDInsight sur AKS. Pour toute question ou pour des suggestions à propos des fonctionnalités, veuillez envoyer vos requêtes et leurs détails sur AskHDInsight, et suivez-nous sur la Communauté Azure HDInsight pour plus de mises à jour.
Ce tutoriel vous explique comment démarrer l’interface CLI client SQL en mode passerelle dans Apache Flink Cluster 1.17.0 sur HDInsight sur AKS. En mode passerelle, l’interface CLI envoie le code SQL à la passerelle distante spécifiée pour exécuter des instructions.
./bin/sql-client.sh gateway --endpoint <gateway address>
Remarque
Dans Apache Flink Cluster sur HDInsight sur AKS, toute connexion externe passe par le port 443. Mais en interne, il redirige la requête vers le service sql-gateway à l’écoute du port 8083.
Vérifier le service sql-gateway côté AKS :

Qu’est-ce que le client SQL dans Flink ?
L’API Table & SQL de Flink permet d’utiliser des requêtes écrites dans le langage SQL, mais ces requêtes ont besoin d’être incorporées dans un programme de table écrit en Java ou Scala. De plus, ces programmes doivent être empaquetés avec un outil de génération avant d’être soumis à un cluster. Cette fonctionnalité limite l’utilisation de Flink aux programmeurs Java/Scala.
Le client SQL vise à fournir un moyen simple d’écrire, de déboguer et d’envoyer des programmes de table à un cluster Flink sans une seule ligne de code Java ou Scala. L’interface CLI client SQL permet de récupérer et de visualiser les résultats en temps réel de l’application distribuée en cours d’exécution sur la ligne de commande.
Pour plus d’informations, consultez comment entrer l’interface CLI client CLI SQL Flink sur webssh.
Qu’est-ce que la passerelle SQL dans Flink ?
La passerelle SQL est un service qui permet à plusieurs clients de l’instance distante d’exécuter simultanément du code SQL. Il offre un moyen simple d’envoyer le travail Flink, de rechercher les métadonnées et d’analyser les données en ligne.
Pour plus d’informations, consultez la section Passerelle SQL.
Démarrer l’interface CLI client SQL en mode passerelle dans Flink-cli
Dans Apache Flink Cluster sur HDInsight sur AKS, démarrez l’interface CLI client SQL en mode passerelle en exécutant la commande :
./bin/sql-client.sh gateway --endpoint host:port
or
./bin/sql-client.sh gateway --endpoint https://fqdn/sql-gateway
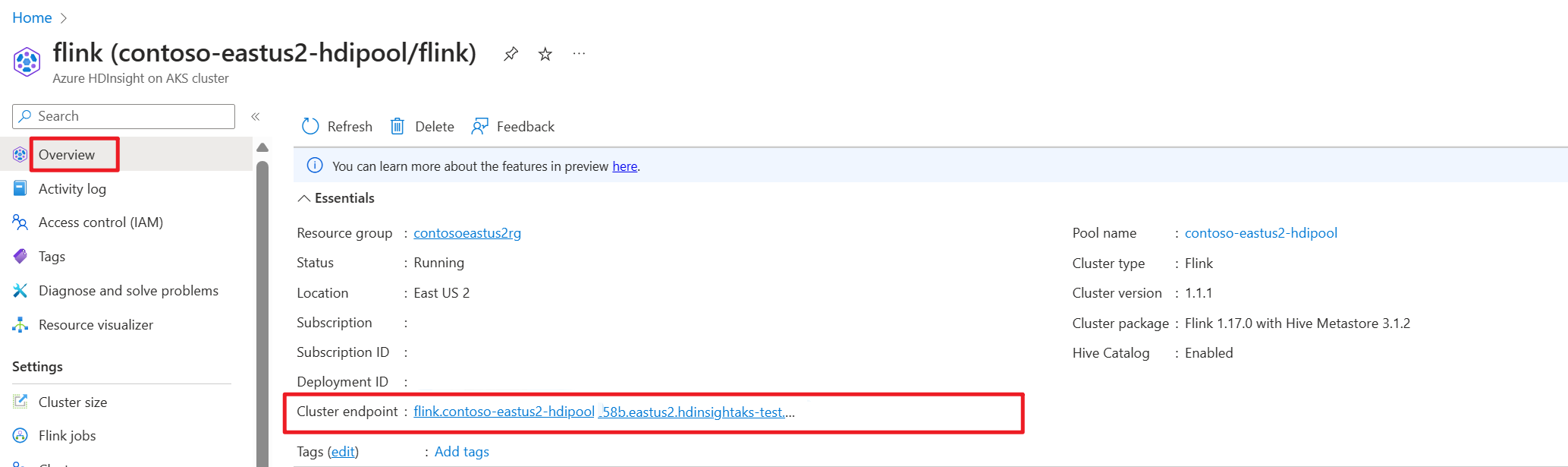
Obtenir le point de terminaison de cluster (hôte ou fqdn) sur le portail Azure.

Test
Préparation
Télécharger l’interface CLI Flink
- Téléchargez l’interface CLI Flink à partir de https://aka.ms/hdionaksflink117clilinux sur l’ordinateur Windows local.
Installez le sous-système Windows pour Linux pour que cela fonctionne sur une machine Windows locale.
Ouvrez la commande Windows et exécutez (remplacez JAVA_HOME et le chemin flink-cli par votre propre chemin) pour télécharger flink-cli :
Windows Subsystem for Linux --distribution Ubuntu export JAVA_HOME=/mnt/c/Work/99_tools/zulu11.56.19-ca-jdk11.0.15-linux_x64 cd <folder> wget https://hdiconfigactions.blob.core.windows.net/hiloflink17blob/flink-cli.tgz tar -xvf flink-cli.tgzDéfinir le point de terminaison, l’ID de locataire et le port 443 dans flink-conf.yaml
user@MININT-481C9TJ:/mnt/c/Users/user/flink-cli$ cd conf user@MININT-481C9TJ:/mnt/c/Users/user/flink-cli/conf$ ls -l total 8 -rwxrwxrwx 1 user user 2451 Feb 26 20:33 flink-conf.yaml -rwxrwxrwx 1 user user 2946 Feb 23 14:13 log4j-cli.properties user@MININT-481C9TJ:/mnt/c/Users/user/flink-cli/conf$ cat flink-conf.yaml rest.address: <flink cluster endpoint on Azure portal> azure.tenant.id: <tenant ID> rest.port: 443Autoriser l’adresse IP publique Windows locale avec le port 443 avec VPN activé dans HDInsight sur la sécurité réseau du sous-réseau du cluster AKS entrante.
Exécutez sql-client.sh en mode passerelle sur Flink-cli vers Flink SQL.
bin/sql-client.sh gateway --endpoint https://fqdn/sql-gatewayExemple
user@MININT-481C9TJ:/mnt/c/Users/user/flink-cli$ bin/sql-client.sh gateway --endpoint https://fqdn/sql-gateway ▒▓██▓██▒ ▓████▒▒█▓▒▓███▓▒ ▓███▓░░ ▒▒▒▓██▒ ▒ ░██▒ ▒▒▓▓█▓▓▒░ ▒████ ██▒ ░▒▓███▒ ▒█▒█▒ ░▓█ ███ ▓░▒██ ▓█ ▒▒▒▒▒▓██▓░▒░▓▓█ █░ █ ▒▒░ ███▓▓█ ▒█▒▒▒ ████░ ▒▓█▓ ██▒▒▒ ▓███▒ ░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░ ▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒ ███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒ ░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒ ███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░ ██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓ ▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒ ▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒ ▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█ ██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █ ▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓ █▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓ ██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓ ▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒ ██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒ ▓█ ▒█▓ ░ █░ ▒█ █▓ █▓ ██ █░ ▓▓ ▒█▓▓▓▒█░ █▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█ ██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓ ▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██ ░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓ ░▓██▒ ▓░ ▒█▓█ ░░▒▒▒ ▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░ ______ _ _ _ _____ ____ _ _____ _ _ _ BETA | ____| (_) | | / ____|/ __ \| | / ____| (_) | | | |__ | |_ _ __ | | __ | (___ | | | | | | | | |_ ___ _ __ | |_ | __| | | | '_ \| |/ / \___ \| | | | | | | | | |/ _ \ '_ \| __| | | | | | | | | < ____) | |__| | |____ | |____| | | __/ | | | |_ |_| |_|_|_| |_|_|\_\ |_____/ \___\_\______| \_____|_|_|\___|_| |_|\__| Welcome! Enter 'HELP;' to list all available commands. 'QUIT;' to exit. Command history file path: /home/user/.flink-sql-historyAvant d’interroger une table avec une source externe, préparez les fichiers jar associés. Les exemples suivants interrogent la table kafka, la table mysql dans Flink SQL. Téléchargez le fichier jar et placez-le dans le stockage Azure Data Lake Storage gen2 attaché au cluster Flink.
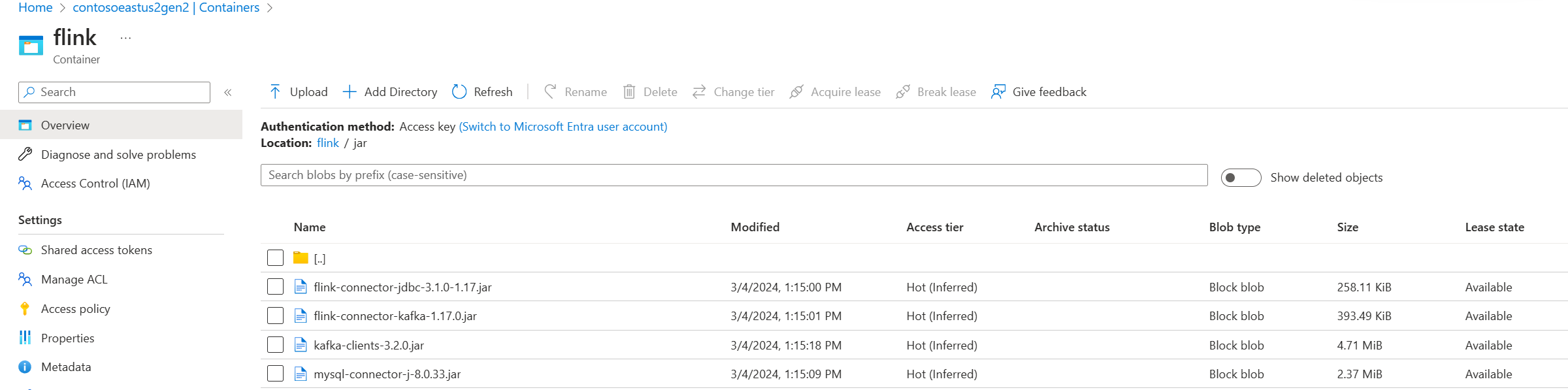
Fichiers jar dans Azure Data Lake Storage gen2 dans le portail Azure :
Utilisez la table déjà créée et placez-la dans le metastore Hive pour la gestion, puis exécutez la requête.
Remarque
Dans cet exemple, tous les bocaux de HDInsight on AKS utilisent par défaut Azure Data Lake Storage Gen2. Le conteneur et le compte de stockage ne doivent pas nécessairement être identiques à ceux spécifiés lors de la création du cluster. Si nécessaire, vous pouvez spécifier un autre compte de stockage et accorder à l'identité gérée par l'utilisateur du cluster le rôle de propriétaire des données du blob de stockage du côté d'Azure Data Lake Storage Gen2.
CREATE CATALOG myhive WITH ( 'type' = 'hive' ); USE CATALOG myhive; // ADD jar into environment ADD JAR 'abfs://<container>@<storage name>.dfs.core.windows.net/jar/flink-connector-jdbc-3.1.0-1.17.jar'; ADD JAR 'abfs://<container>@<storage name>.dfs.core.windows.net/jar/mysql-connector-j-8.0.33.jar'; ADD JAR 'abfs://<container>@<storage name>.dfs.core.windows.net/jar/kafka-clients-3.2.0.jar'; ADD JAR 'abfs://<container>@<storage name>.dfs.core.windows.net/jar/flink-connector-kafka-1.17.0.jar'; Flink SQL> show jars; ----------------------------------------------------------------------------------------------+ | jars | +----------------------------------------------------------------------------------------------+ | abfs://<container>@<storage name>.dfs.core.windows.net/jar/flink-connector-kafka-1.17.0.jar | | abfs://<container>@<storage name>.dfs.core.windows.net/jar/flink-connector-jdbc-3.1.0-1.17.jar | | abfs://<container>@<storage name>.dfs.core.windows.net/jar/kafka-clients-3.2.0.jar | | abfs://<container>@<storage name>.dfs.core.windows.net/jar/mysql-connector-j-8.0.33.jar | +----------------------------------------------------------------------------------------------+ 4 rows in set Flink SQL> SET 'sql-client.execution.result-mode' = 'tableau'; [INFO] Execute statement succeed. Flink SQL> show tables; +----------------------+ | table name | +----------------------+ | flightsintervaldata1 | | kafka_user_orders | | kafkatable | | mysql_user_orders | | orders | +----------------------+ 5 rows in set // mysql cdc table Flink SQL> select * from mysql_user_orders; +----+-------------+----------------------------+-------------+--------------------------------+--------------+-------------+--------------+ | op | order_id | order_date | customer_id | customer_name | price | product_id | order_status | +----+-------------+----------------------------+-------------+--------------------------------+--------------+-------------+--------------+ | +I | 10001 | 2023-07-16 10:08:22.000000 | 1 | Jark | 50.00000 | 102 | FALSE | | +I | 10002 | 2023-07-16 10:11:09.000000 | 2 | Sally | 15.00000 | 105 | FALSE | | +I | 10003 | 2023-07-16 10:11:09.000000 | 3 | Sally | 25.00000 |


Référence
Interface CLI Apache Flink® sur HDInsight sur des clusters AKS