Qu’est-ce qu’Apache Flink® dans Azure HDInsight sur AKS ? (Aperçu)
Important
Azure HDInsight sur AKS a été mis hors service le 31 janvier 2025. En savoir plus avec cette annonce.
Vous devez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent pour éviter l’arrêt brusque de vos charges de travail.
Important
Cette fonctionnalité est actuellement en préversion. Les Conditions d’utilisation supplémentaires pour les préversions Microsoft Azure incluent des termes juridiques supplémentaires qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou qui ne sont pas encore publiées en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les informations sur la préversion de Azure HDInsight sur AKS. Pour des questions ou des suggestions de fonctionnalités, envoyez une demande sur AskHDInsight avec les détails et suivez-nous pour plus de mises à jour sur Communauté Azure HDInsight.
Apache Flink est un moteur de traitement distribué et framework pour les calculs avec état sur des flux de données non liés et délimités. Flink a été conçu pour s'exécuter dans tous les environnements de cluster courants, effectuer des calculs et des applications de diffusion en continu avec gestion d'état à une vitesse comparable à celle de la mémoire vive et à toute échelle. Les applications sont parallélisées dans des milliers de tâches qui sont distribuées et exécutées simultanément dans un cluster. Par conséquent, une application peut utiliser des quantités illimitées de processeurs virtuels, de mémoire principale, de disque et d’E/S réseau. En outre, Flink gère facilement de grands états d'application. Son algorithme de point de contrôle asynchrone et incrémentiel garantit une influence minimale sur les latences de traitement tout en garantissant exactement une fois la cohérence de l’état.
Apache Flink est un moteur d’analytique massivement évolutif pour le traitement de flux.
Voici quelques-unes des principales fonctionnalités proposées par Flink :
- Opérations sur des flux limités et non liés
- La performance en mémoire
- Possibilité de diffusion en continu et de calculs par lots
- Faible latence, opérations à débit élevé
- Traitement exactement une fois
- Haute disponibilité
- Tolérance d’état et de panne
- Entièrement compatible avec l’écosystème Hadoop
- API SQL unifiées pour les flux et les lots
Pourquoi Apache Flink ?
Apache Flink est un excellent choix pour développer et exécuter de nombreux types d’applications différents en raison de son ensemble de fonctionnalités étendues. Les fonctionnalités de Flink incluent la prise en charge du traitement de flux et de lots, la gestion sophistiquée de l’état, la sémantique de traitement au moment des événements, et des garanties de cohérence exactement une fois pour l'état. Flink n’a pas de point de défaillance unique. Flink a prouvé sa capacité à monter en charge jusqu'à des milliers de cœurs et des téraoctets d'état applicatif, fournit un débit élevé et une faible latence, et alimente certaines des applications de traitement des flux les plus exigeantes au monde.
- détection des fraudes: Flink peut être utilisé pour détecter des transactions frauduleuses ou des activités en temps réel en appliquant des règles complexes et des modèles Machine Learning sur les données de streaming.
- détection d’anomalies: Flink peut être utilisé pour identifier les valeurs hors norme ou les modèles anormaux dans les données de streaming, telles que les lectures de capteur, le trafic réseau ou le comportement de l’utilisateur.
- Alertes basées sur des règles: Flink peut être utilisé pour déclencher des alertes ou des notifications à partir de conditions ou de seuils prédéfinis sur les données de diffusion en continu, telles que la température, la pression ou les cours des actions.
- surveillance des processus métier: Flink peut être utilisé pour suivre et analyser l’état et les performances des processus métier ou des flux de travail en temps réel, tels que le traitement des commandes, la livraison ou le service client.
- application web (réseau social): Flink peut être utilisé pour alimenter les applications web qui nécessitent un traitement en temps réel des données générées par l’utilisateur, telles que des messages, des likes, des commentaires ou des recommandations.
En savoir plus sur les cas d’usage courants décrits dans cas d’usage d'Apache Flink
Les clusters Apache Flink dans HDInsight sur AKS sont un service entièrement managé. Les avantages de la création d’un cluster Flink dans HDInsight sur AKS sont répertoriés ici.
| Caractéristique | Description |
|---|---|
| Facilité de création | Vous pouvez créer un cluster Flink dans HDInsight en quelques minutes à l’aide du portail Azure, d’Azure PowerShell ou du Kit de développement logiciel (SDK). Voir Prise en main d'un cluster Apache Flink avec HDInsight sur AKS. |
| Facilité d’utilisation | Les clusters Flink dans HDInsight sur AKS incluent la gestion de la configuration basée sur le portail et la mise à l’échelle. En plus de cela, avec l’API de gestion des travaux, vous utilisez l’API REST ou le portail Azure pour la gestion des travaux. |
| API REST | Les clusters Flink dans HDInsight sur AKS incluent 'API de gestion des travaux, une méthode de soumission de travaux Flink basée sur l’API REST pour envoyer et surveiller à distance des travaux sur le portail Azure. |
| Type de déploiement | Flink peut exécuter des applications en mode Session ou en mode Application. Actuellement, HDInsight sur AKS prend uniquement en charge les clusters de session. Vous pouvez exécuter plusieurs travaux Flink sur un cluster de session. Le mode application est sur la feuille de route pour HDInsight sur les clusters AKS |
| Prise en charge du metastore | Les clusters Flink dans HDInsight sur AKS peuvent prendre en charge les catalogues avec metastore Hive dans différents formats de fichiers ouverts avec des points de contrôle distants vers Azure Data Lake Storage Gen2. |
| Prise en charge du stockage Azure | Les clusters Flink dans HDInsight peuvent utiliser Azure Data Lake Storage Gen2 comme récepteur de fichiers. Pour plus d’informations sur Data Lake Storage Gen2, consultez azure Data Lake Storage Gen2. |
| Intégration avec les services Azure | Le cluster Flink dans HDInsight sur AKS est fourni avec une intégration à Kafka ainsi que Azure Event Hubs et Azure HDInsight. Vous pouvez créer des applications de diffusion en continu à l’aide d’Event Hubs ou HDInsight. |
| Adaptabilité | HDInsight sur AKS vous permet de mettre à l’échelle les nœuds de cluster Flink en fonction de la planification avec la fonctionnalité de mise à l’échelle automatique. Consultez mettre automatiquement à l’échelle Azure HDInsight sur des clusters AKS. |
| Backend de l'état | HDInsight sur AKS utilise la base de données RocksDB comme StateBackend par défaut. RocksDB est un magasin de clés-valeur persistant pouvant être incorporé pour un stockage rapide. |
| Points de contrôle | Les points de contrôle sont activés par défaut dans HDInsight sur les clusters AKS. Les paramètres par défaut sur HDInsight sur AKS conservent les cinq derniers points de contrôle dans le stockage persistant. En cas d’échec de votre travail, le travail peut être redémarré à partir du dernier point de contrôle. |
| Points de contrôle incrémentiels | RocksDB prend en charge les points de contrôle incrémentiels. Nous encourageons l’utilisation de points de contrôle incrémentiels pour un état de grande taille ; vous devez activer cette fonctionnalité manuellement. La définition d’une valeur par défaut dans votre flink-conf.yaml: state.backend.incremental: true active les points de contrôle incrémentiels, sauf si l’application remplace ce paramètre dans le code. Cette instruction est vraie par défaut. Vous pouvez également configurer cette valeur directement dans le code (remplace la configuration par défaut) EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true); . Par défaut, nous conservons les cinq derniers points de contrôle dans le répertoire des points de contrôle qui a été configuré. Cette valeur peut être modifiée en modifiant la configuration de la section gestion de la configuration state.checkpoints.num-retained: 5 |
Les clusters Apache Flink dans HDInsight sur AKS incluent les composants suivants, ils sont disponibles sur les clusters par défaut.
- DataStreamAPI
- TableAPI & SQL.
Reportez-vous à la feuille de route pour découvrir ce qui sera bientôt disponible !
Gestion des jobs Apache Flink
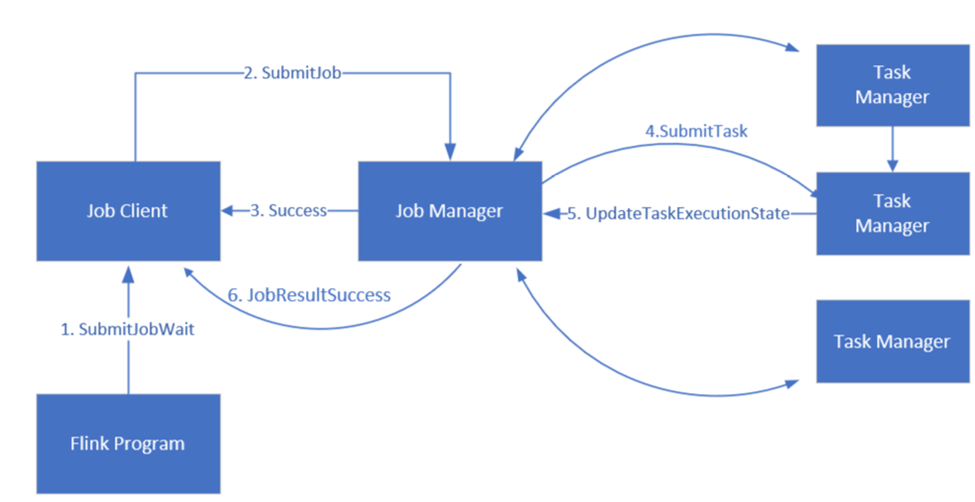
Flink planifie des travaux à l’aide de trois composants distribués, gestionnaire de travaux, gestionnaire de tâches et client de travail, qui sont définis dans un modèle Leader-Follower.
Tâche Flink: une tâche ou un programme Flink se compose de plusieurs tâches. Les tâches sont l’unité de base de l’exécution dans Flink. Chaque tâche Flink a plusieurs instances en fonction du niveau de parallélisme et chaque instance est exécutée sur un TaskManager.
gestionnaire de travaux: le gestionnaire de travaux agit en tant que planificateur et planifie les tâches sur les gestionnaires de tâches.
gestionnaire de tâches: les gestionnaires de tâches sont fournis avec un ou plusieurs emplacements pour exécuter des tâches en parallèle.
client de job: le client de job communique avec le gestionnaire de travaux pour envoyer des travaux Flink
'interface utilisateur web Flink: Flink propose une interface utilisateur web pour inspecter, surveiller et déboguer les applications en cours d’exécution.
Référence
- Site Web Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink et les noms de projet open source associés sont marques déposées de la Apache Software Foundation (ASF).