Format Parquet dans Azure Data Factory et Azure Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Suivez cet article si vous souhaitez analyser des fichiers Parquet ou écrire des données au format Parquet.
Le format Parquet est pris en charge pour les connecteurs suivants :
- Amazon S3
- Stockage compatible Amazon S3
- Blob Azure
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- Système de fichiers
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Pour obtenir la liste des fonctionnalités prises en charge pour tous les connecteurs disponibles, consultez l’article Vue d’ensemble des connecteurs.
Utilisation du runtime d’intégration auto-hébergé
Important
Dans le cas de copies permises par Microsoft Integration Runtime auto-hébergé, par exemple, entre des magasins de données locaux et cloud, si vous ne copiez pas les fichiers Parquet en l’état, vous devez installer JRE 8 64 bits (Java Runtime Environment), JDK 23 (Java Development Kit) ou OpenJDK sur votre machine de runtime d’intégration. Pour plus de détails, consultez le paragraphe suivant.
Dans le cas de copies s’exécutant sur l’IR auto-hébergé avec sérialisation/désérialisation des fichiers Parquet, le service localise le runtime Java en vérifiant d’abord le registre (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) pour JRE puis, s’il ne le trouve pas, en vérifiant la variable système JAVA_HOME pour OpenJDK.
- Pour utiliser JRE : Le runtime d’intégration de 64 bits requiert la version 64 bits de JRE. Vous pouvez la récupérer ici.
-
Pour utiliser JDK : le runtime d’intégration 64 bits nécessite JDK 23 64 bits. Vous pouvez la récupérer ici. Veillez à mettre à jour la variable système
JAVA_HOMEvers le dossier racine de l’installation JDK 23, c’est-à-direC:\Program Files\Java\jdk-23, et ajoutez le chemin des dossiersC:\Program Files\Java\jdk-23\binetC:\Program Files\Java\jdk-23\bin\serverà la variable systèmePath. - Pour utiliser OpenJDK : il est pris en charge à compter de la version 3.13 du runtime d’intégration. Empaquetez jvm.dll avec tous les autres assemblys requis d’OpenJDK dans la machine équipée du runtime d’intégration auto-hébergé et définissez la variable d’environnement système JAVA_HOME en conséquence, puis redémarrez le runtime d'intégration auto-hébergé pour un effet immédiat. Pour télécharger la build Microsoft de OpenJDK, consultez Microsoft Build de OpenJDK™.
Conseil
Si, en copiant des données au format Parquet avec le runtime d’intégration auto-hébergé, vous obtenez une erreur indiquant « An error occurred when invoking java, message: java.lang.OutOfMemoryError:Java heap space », vous pouvez ajouter une variable d’environnement _JAVA_OPTIONS sur l’ordinateur qui héberge le runtime d’intégration auto-hébergé afin d’ajuster la taille de segment de mémoire minimale/maximale nécessaire pour que la machine virtuelle Java puisse effectuer une copie de ce type, puis réexécuter le pipeline.
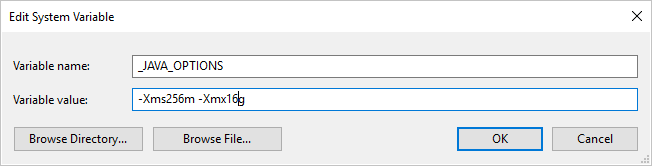
Exemple : donnez la valeur -Xms256m -Xmx16g à la variable _JAVA_OPTIONS. L’indicateur Xms spécifie le pool d’allocation de mémoire initial pour une Machine virtuelle Java (JVM), tandis que Xmx spécifie le pool d’allocation de mémoire maximal. En d’autres termes, JVM démarrera avec la quantité de mémoire Xms et pourra au maximum utiliser la quantité de mémoire Xmx. Par défaut, le service utilise min 64 Mo et max 1 Go.
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article Jeux de données. Cette section donne la liste des propriétés prises en charge par le jeu de données Parquet.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur Parquet. | Oui |
| location | Paramètres d’emplacement du ou des fichiers. Chaque connecteur basé sur un fichier possède ses propres type d’emplacement et propriétés prises en charge sous location.
Consultez les détails dans l’article du connecteur -> section des propriétés du jeu de données. |
Oui |
| compressionCodec | Codec de compression à utiliser lors de l’écriture dans des fichiers Parquet. Lors de la lecture de fichiers Parquet, les fabriques de données déterminent automatiquement le codec de compression sur la base des métadonnées de fichier. Les types pris en charge sont « none », « gzip », « snappy » (valeur par défaut) et « lzo ». Notez que l’activité de copie ne prend pas en charge LZO lors de la lecture ou de l’écriture des fichiers Parquet. |
Non |
Notes
Les espaces blancs dans le nom de colonne ne sont pas pris en charge pour les fichiers Parquet.
Voici un exemple de jeu de données Parquet sur Stockage Blob Azure :
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par Parquet en tant que source et récepteur.
Parquet en tant que source
Les propriétés prises en charge dans la section *source* de l’activité de copie sont les suivantes.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source de l’activité de copie doit être définie sur ParquetSource. | Oui |
| storeSettings | Un groupe de propriétés sur la façon de lire les données d’un magasin de données. Chaque connecteur basé sur un fichier possède ses propres paramètres de lecture pris en charge sous storeSettings.
Consultez les détails dans l’article du connecteur -> section des propriétés de l’activité de copie. |
Non |
Parquet en tant que récepteur
Les propriétés prises en charge dans la section *récepteur* de l’activité de copie sont les suivantes.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du récepteur de l’activité de copie doit être définie sur ParquetSink. | Oui |
| formatSettings | Un groupe de propriétés. Reportez-vous au tableau Paramètres d’écriture Parquet ci-dessous. | Non |
| storeSettings | Groupe de propriétés sur la méthode d’écriture de données dans un magasin de données. Chaque connecteur basé sur un fichier possède ses propres paramètres d’écriture pris en charge sous storeSettings.
Consultez les détails dans l’article du connecteur -> section des propriétés de l’activité de copie. |
Non |
Paramètres d’écriture Parquet pris en charge sous formatSettings :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | Le type de formatSettings doit être défini sur ParquetWriteSettings. | Oui |
| maxRowsPerFile | Lorsque vous écrivez des données dans un dossier, vous pouvez choisir d’écrire dans plusieurs fichiers et de spécifier le nombre maximal de lignes par fichier. | Non |
| fileNamePrefix | Applicable lorsque maxRowsPerFile est configuré.Spécifiez le préfixe du nom de fichier lors de l’écriture de données dans plusieurs fichiers, ce qui a généré ce modèle : <fileNamePrefix>_00000.<fileExtension>. S’il n’est pas spécifié, le préfixe du nom de fichier est généré automatiquement. Cette propriété ne s’applique pas lorsque la source est un magasin basé sur des fichiers ou un magasin de données partition-option-enabled. |
Non |
Propriétés du mappage de flux de données
Dans les flux de données de mappage, vous pouvez lire et écrire des données au format parquet dans les magasins de données suivants : Stockage Blob Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 et SFTP, et vous pouvez lire le format parquet dans Amazon S3.
Propriétés sources
Le tableau ci-dessous liste les propriétés prises en charge par une source Parquet. Vous pouvez modifier ces propriétés sous l’onglet Options de la source.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Format | Le format doit être parquet. |
Oui | parquet |
format |
| Chemins génériques | Tous les fichiers correspondant au chemin générique seront traités. Remplace le chemin du dossier et du fichier défini dans le jeu de données. | non | String[] | wildcardPaths |
| Chemin racine de la partition | Pour les données de fichier qui sont partitionnées, vous pouvez entrer le chemin racine d’une partition pour pouvoir lire les dossiers partitionnés comme des colonnes. | non | String | partitionRootPath |
| Liste de fichiers | Si votre source pointe ou non vers un fichier texte qui liste les fichiers à traiter | non |
true ou false |
fileList |
| Colonne où stocker le nom du fichier | Crée une colonne avec le nom et le chemin du fichier source | non | String | rowUrlColumn |
| Après l’exécution | Supprime ou déplace les fichiers après le traitement. Le chemin du fichier commence à la racine du conteneur | non | Supprimer : true ou false Déplacer : [<from>, <to>] |
purgeFiles moveFiles |
| Filtrer par date de dernière modification | Pour filtrer les fichiers en fonction de leur date de dernière modification | non | Timestamp | modifiedAfter modifiedBefore |
| N’autoriser aucun fichier trouvé | Si la valeur est true, aucune erreur n’est levée si aucun fichier n’est trouvé | non |
true ou false |
ignoreNoFilesFound |
Exemple de source
L’image ci-dessous est un exemple de configuration de source Parquet dans des flux de données de mappage.
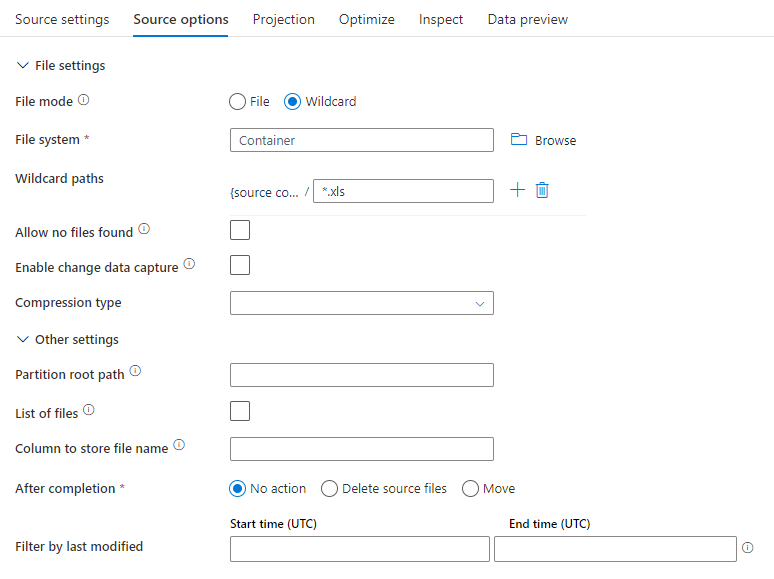
Le script de flux de données associé est le suivant :
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
Propriétés du récepteur
Le tableau ci-dessous liste les propriétés prises en charge par un récepteur Parquet. Vous pouvez modifier ces propriétés sous l’onglet Paramètres.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Format | Le format doit être parquet. |
Oui | parquet |
format |
| Effacer le contenu du dossier | Si le dossier de destination est vidé avant l’écriture | non |
true ou false |
truncate |
| Option de nom de fichier | Format de nommage des données écrites. Par défaut, un fichier par partition au format part-#####-tid-<guid> |
non | Modèle : Chaîne Par partition : Chaîne[] Comme des données d’une colonne : Chaîne Sortie dans un fichier unique : ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Exemple de récepteur
L’image ci-dessous est un exemple de configuration de récepteur Parquet dans des flux de données de mappage.
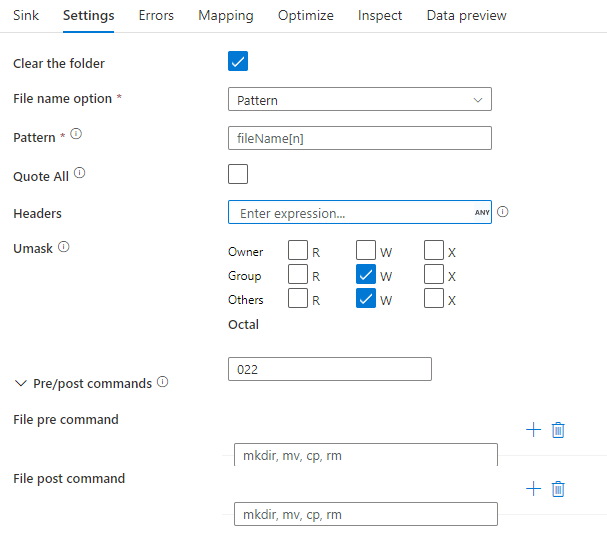
Le script de flux de données associé est le suivant :
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Prise en charge des types de données
Les types de données complexes Parquet (par exemple, MAP, LIST, STRUCT) ne sont actuellement pris en charge que dans des Data Flows, et non dans l’activité de copie. Pour utiliser des types complexes dans des flux de données, n’importez pas le schéma de fichier dans le jeu de données, en laissant ainsi le schéma vide dans le jeu de données. Ensuite, dans la transformation de la source, importez la projection.