Format Delta dans Azure Data Factory
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article explique comment copier des données vers et depuis un lac Delta stocké dans Azure Data Lake Store Gen2 ou Stockage Blob Azure à l’aide du format Delta. Ce connecteur est disponible sous forme de jeu de données inline dans le flux de données de mappage, en tant que source et récepteur.
Propriétés du mappage de flux de données
Ce connecteur est disponible sous forme de jeu de données inline dans le flux de données de mappage, en tant que source et récepteur.
Propriétés de source
Le tableau ci-dessous répertorie les propriétés prises en charge par une source Delta. Vous pouvez modifier ces propriétés sous l’onglet Options de la source.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Format | Le format doit être delta. |
Oui | delta |
format |
| Système de fichiers | Conteneur/système de fichiers du lac Delta | Oui | String | fileSystem |
| Chemin d’accès du dossier | L’annuaire du lac Delta | Oui | String | folderPath |
| Type de compression | Type de compression de la table Delta | non | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| Niveau de compression | Indiquez si la compression doit se terminer le plus rapidement possible ou si le fichier obtenu doit être compressé de façon optimale. | Obligatoire si compressedType est spécifié. |
Optimal ou Fastest |
compressionLevel |
| Voyage dans le temps | Indiquez si vous souhaitez interroger un instantané plus ancien de table Delta | non | Interroger par timestamp : Timestamp Interroger par version : Integer |
timestampAsOf versionAsOf |
| N’autoriser aucun fichier trouvé | Si la valeur est true, aucune erreur n’est levée si aucun fichier n’est trouvé | non | true ou false |
ignoreNoFilesFound |
Importer un schéma
Delta est uniquement disponible en tant que jeu de données inline et, par défaut, ne dispose pas de schéma associé. Pour récupérer les métadonnées des colonnes, cliquez sur le bouton Importer le schéma sous l’onglet Projection. Cela vous permet de référencer les noms de colonnes et les types de données spécifiés par le corpus. Pour importer le schéma, une session de débogage de flux de données doit être active et vous devez disposer d’un fichier de définition d’entité CDM vers lequel pointer.
Exemple de script source Delta
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
Propriétés du récepteur
Le tableau ci-dessous répertorie les propriétés prises en charge par un récepteur Delta. Vous pouvez modifier ces propriétés sous l’onglet Paramètres.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Format | Le format doit être delta. |
Oui | delta |
format |
| Système de fichiers | Conteneur/système de fichiers du lac Delta | Oui | String | fileSystem |
| Chemin d’accès du dossier | L’annuaire du lac Delta | Oui | String | folderPath |
| Type de compression | Type de compression de la table Delta | non | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| Niveau de compression | Indiquez si la compression doit se terminer le plus rapidement possible ou si le fichier obtenu doit être compressé de façon optimale. | Obligatoire si compressedType est spécifié. |
Optimal ou Fastest |
compressionLevel |
| Nettoyer | Supprime les fichiers antérieurs à la durée spécifiée qui ne sont plus pertinents pour la version actuelle de la table. Lorsqu’une valeur inférieure ou égal à 0 est spécifiée, l’opération de nettoyage n’est pas effectuée. | Oui | Integer | vacuum |
| Action table | Indique à ADF que faire avec la table Delta cible dans votre récepteur. Vous pouvez la laisser telle quelle et ajouter de nouvelles lignes, écraser la définition et les données de la table existante avec de nouvelles métadonnées et données, ou conserver la structure de la table existante après avoir tronqué toutes les lignes, puis insérer les nouvelles lignes. | non | Aucun, tronquer, remplacer | deltaTruncate, remplacer |
| Mettre à jour la méthode | Lorsque vous sélectionnez « Autoriser l’insertion » seul ou lorsque vous écrivez dans une nouvelle table delta, la cible reçoit toutes les lignes entrantes, quelles que soient les stratégies de ligne définies. Si vos données contiennent des lignes d’autres stratégies de ligne, elles doivent être exclues à l’aide d’une transformation de filtre précédente. Lorsque toutes les méthodes De mise à jour sont sélectionnées, une fusion est effectuée, où les lignes sont insérées/supprimées/upserted/mises à jour conformément à l’ensemble de stratégies de ligne à l’aide d’une transformation Alter Row précédente. |
Oui | true ou false |
insertable deletable upsertable updateable |
| Écriture optimisée | Obtenez un débit plus élevé pour l’opération d’écriture par le biais de l’optimisation de la lecture aléatoire interne dans les exécuteurs Spark. Il peut en résulter moins de partitions et de fichiers de plus grande taille. | non | true ou false |
optimizedWrite : true |
| Compactage automatique | Une fois qu’une opération d’écriture est terminée, Spark exécute automatiquement la commande OPTIMIZE pour réorganiser les données, ce qui entraîne davantage de partitions si nécessaire, pour une meilleure lecture des performances à l’avenir. |
non | true ou false |
autoCompact : true |
Exemple de script de récepteur Delta
Le script de flux de données associé est le suivant :
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
Récepteur Delta avec nettoyage de partition
Avec cette option sous Mettre à jour la méthode ci-dessus (c’est-à-dire update/upsert/delete), vous pouvez limiter le nombre de partitions inspectées. Seules les partitions remplissant cette condition seront extraites du magasin cible. Vous pouvez spécifier un ensemble fixe de valeurs qu’une colonne de partition peut prendre.
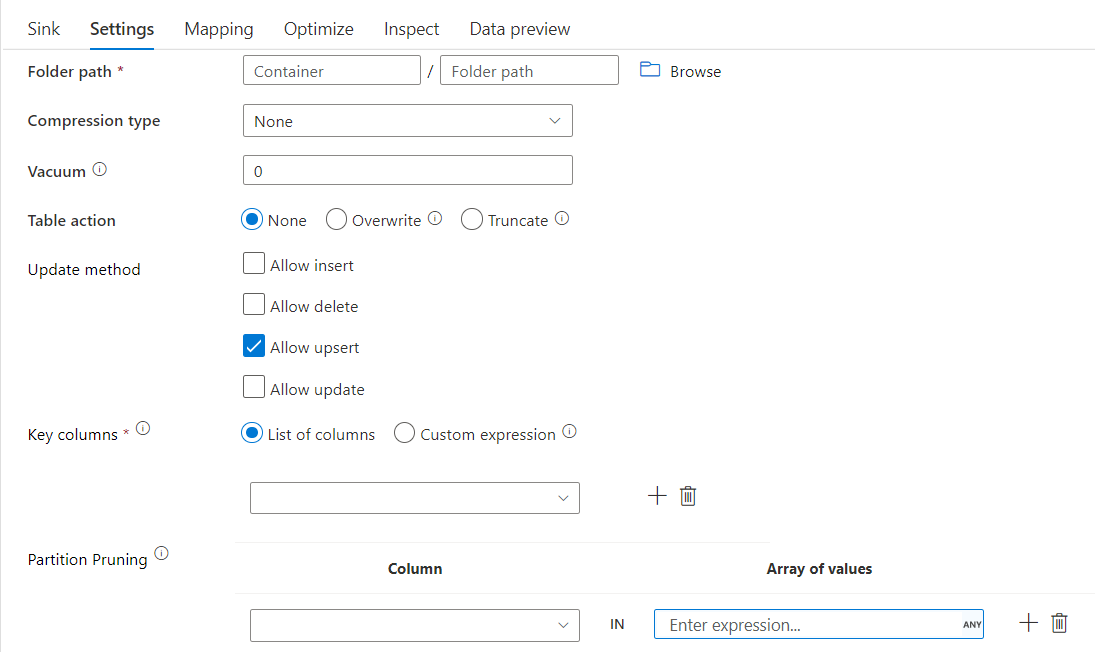
Exemple de script de récepteur Delta avec nettoyage de partition
Un exemple de script est proposé ci-dessous.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
Delta lit uniquement 2 partitions où part_col == 5 et 8 à partir du magasin delta cible au lieu de toutes les partitions. part_col est une colonne par laquelle les données Delta cibles sont partitionnées. Elle ne doit pas nécessairement être présente dans les données sources.
Options d’optimisation du récepteur Delta
Sous l’onglet Paramètres, vous trouverez trois options supplémentaires pour optimiser la transformation du récepteur Delta.
Lorsque l’option Fusionner le schéma est activée, cela permet une évolution du schéma, par exemple toutes les colonnes présentes dans le présent flux suivant, mais pas dans la table Delta cible, sont automatiquement ajoutées à son schéma. Cette option est prise en charge pour toutes les méthodes de mise à jour.
Lorsque l’option Compactage automatique est activée, après une écriture individuelle, la transformation vérifie si les fichiers peuvent encore être compactés et exécute un travail d'optimisation rapide (avec des tailles de fichier de 128 Mo au lieu de 1 Go) afin de compacter davantage les fichiers pour les partitions qui ont le plus grand nombre de petits fichiers. Le compactage automatique permet de fusionner un grand nombre de petits fichiers en un plus petit nombre de fichiers volumineux. Le compactage automatique démarre uniquement lorsqu’il y a au moins 50 fichiers. Une fois qu’une opération de compactage est effectuée, elle crée une nouvelle version de la table et écrit un nouveau fichier contenant les données de plusieurs fichiers précédents sous une forme compressée compacte.
Lorsque l’option Optimiser l’écriture est activée, la transformation du récepteur optimise dynamiquement les tailles de partition en fonction des données réelles en tentant d’écrire des fichiers de 128 Mo pour chaque partition de table. Il s’agit d’une taille approximative qui peut varier en fonction des caractéristiques du jeu de données. Les écritures optimisées améliorent l’efficacité globale des écritures et des lectures suivantes. Les partitions sont organisées de sorte que les performances des lectures suivantes soient améliorées.
Conseil
Le processus d’écriture optimisé ralentit votre travail ETL global, car le récepteur émet la commande Spark Delta Lake Optimize une fois vos données traitées. Nous vous recommandons d’utiliser l’écriture optimisée avec parcimonie. Par exemple, si vous disposez d’un pipeline de données horaire, exécutez un flux de données avec l’écriture optimisée tous les jours.
Limitations connues
Lors de l’écriture dans un récepteur Delta, il existe une limitation connue au-delà de laquelle le nombre de lignes écrites ne sera pas retourné dans la sortie de la surveillance.
Contenu connexe
- Créer une transformation de source dans le flux de données de mappage.
- Créer une transformation de récepteur dans le flux de données de mappage.
- Créer une transformation de modification de ligne pour marquer des lignes comme insert, update, upsert ou delete.