Utiliser des paramètres personnalisés avec le modèle Resource Manager
S’APPLIQUE À : Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Si votre instance de développement dispose d’un dépôt Git associé, vous pouvez remplacer les paramètres du modèle Resource Manager par défaut du modèle Resource Manager généré en publiant ou exportant le modèle. Vous souhaiterez peut-être remplacer la configuration de paramètre Resource Manager par défaut dans les scénarios suivants :
Vous utilisez CI/CD automatisé et souhaitez modifier certaines propriétés pendant le déploiement de Resource Manager, mais les propriétés ne sont pas paramétrables par défaut.
Votre fabrique est si volumineuse que le modèle Resource Manager par défaut n’est pas valide car il dépasse le nombre maximum autorisé de paramètres (256).
Pour gérer la limite de 256 paramètres personnalisés, il existe trois possibilités :
- Utilisez le fichier de paramètres personnalisés et supprimez les propriétés qui n’ont pas besoin de paramétrage, c’est-à-dire celles qui peuvent conserver une valeur par défaut, et diminuez ainsi le nombre de paramètres.
- Refactorisez la logique dans le flux de données pour réduire les paramètres ; par exemple, les paramètres de pipeline ont tous la même valeur. Vous pouvez simplement utiliser à la place des paramètres globaux.
- Divisez une fabrique de données en plusieurs fabriques de données.
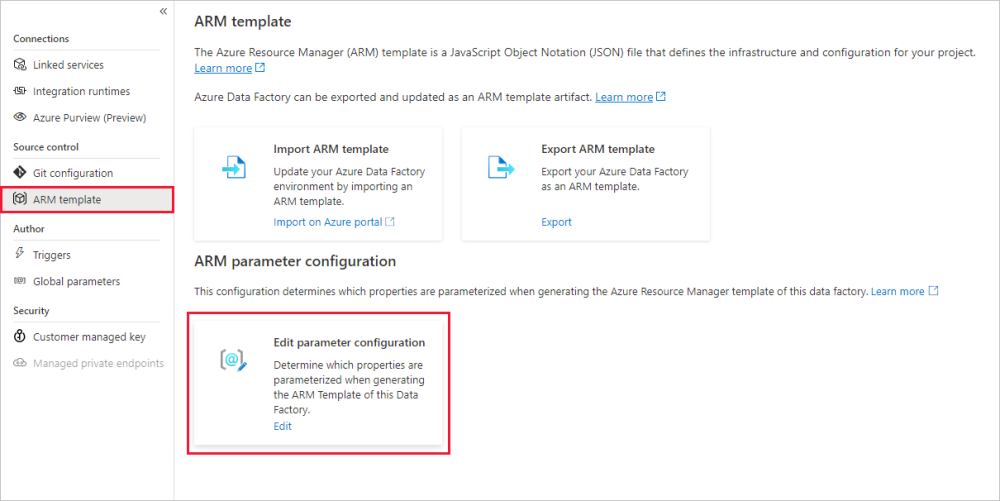
Pour remplacer la configuration de paramètre Resource Manager par défaut, accédez au hub Gérer et sélectionnez Modèle ARM dans la section « Contrôle de code source ». Sous la section Configuration des paramètres ARM, sélectionnez l’icône Modifier dans « Modifier la configuration des paramètres » pour ouvrir l’éditeur de code de configuration des paramètres Resource Manager.
Notes
La configuration de paramètre ARM est uniquement activée en « mode GIT ». Actuellement, il est désactivé en « mode direct » ou en mode « Data Factory ».
La création d’une configuration de paramètre Resource Manager personnalisée crée un fichier nommé arm-template-parameters-definition.json dans le dossier racine de votre branche git. Vous devez utiliser ce nom de fichier exact.
Lors de la publication depuis la branche de collaboration, Data Factory lit ce fichier et utilise sa configuration pour générer les propriétés qui sont paramétrées. Si aucun fichier n’est trouvé, le modèle par défaut est utilisé.
Lors de l’exportation d’un modèle Resource Manager, Data Factory lit ce fichier à partir de la branche sur laquelle vous travaillez actuellement, et pas de la branche de collaboration. Vous pouvez créer ou modifier le fichier à partir d’une branche privée, dans laquelle vous pouvez tester vos modifications en sélectionnant Exporter le modèle ARM dans l’interface utilisateur. Vous pouvez ensuite fusionner le fichier dans la branche de collaboration.
Notes
Une configuration de paramètre Resource Manager personnalisée ne change pas la limite de 256 caractères du modèle ARM. Il vous permet de choisir et de diminuer le nombre de propriétés paramétrées.
Syntaxe de paramètre personnalisé
Vous trouverez ci-dessous quelques recommandations à suivre lorsque vous créez le fichier de paramètres personnalisés arm-template-parameters-definition.json. Le fichier comprend une section pour chaque type d’entité : déclencheur, pipeline, service lié, jeu de données, runtime d’intégration et flux de données.
- Entrez le chemin d’accès de propriété sous le type d’entité correspondant.
- Définir un nom de propriété sur
*indique que vous souhaitez paramétrer toutes les propriétés dans celle-ci (uniquement jusqu’au premier niveau, pas de manière récursive). Vous pouvez également fournir des exceptions à cette configuration. - Définir la valeur d’une propriété sous forme de chaîne indique que vous souhaitez paramétrer la propriété. Utilisez le format
<action>:<name>:<stype>.-
<action>peut être l’un des caractères suivants :-
=permet de conserver la valeur actuelle en tant que valeur par défaut pour le paramètre. -
-permet de ne pas conserver la valeur par défaut pour le paramètre. -
|est un cas particulier pour les secrets Azure Key Vault pour les chaînes de connexion ou les clés.
-
-
<name>correspond au nom du paramètre. S’il est vide, il prend le nom du Si la valeur commence par un caractère-, le nom est abrégé. Par exemple,AzureStorage1_properties_typeProperties_connectionStringserait abrégé enAzureStorage1_connectionString. -
<stype>correspond au type de paramètre. Si<stype>est vide, le type par défaut eststring. Valeurs prises en charge :string,securestring,int,bool,object,secureobjectetarray.
-
- La spécification d’un tableau dans le fichier de définition indique que la propriété correspondante dans le modèle est un tableau. Data Factory effectue une itération sur tous les objets du tableau en utilisant la définition spécifiée dans l’objet de runtime d’intégration du tableau. Le second objet, une chaîne, correspond alors au nom de la propriété et sert de nom au paramètre pour chaque itération.
- Une définition ne peut pas être spécifique à une instance de ressource. Toute définition s’applique à toutes les ressources de ce type.
- Par défaut, toutes les chaînes sécurisées, telles que les secrets Key Vault, et les chaînes sécurisées, telles que les chaînes de connexion, les clés et les jetons, sont paramétrables.
Exemple de modèle de paramétrage
Voici un exemple de ce à quoi peut ressembler la configuration des paramètres Resource Manager. Il contient des exemples de nombreuses utilisations possibles, notamment le paramétrage d’activités imbriquées dans un pipeline et la modification de la valeur par défaut (defaultValue) d’un paramètre de service lié.
{
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"activities": [{
"typeProperties": {
"waitTimeInSeconds": "-::int",
"headers": "=::object",
"activities": [
{
"typeProperties": {
"url": "-:-webUrl:string"
}
}
]
}
}]
}
},
"Microsoft.DataFactory/factories/integrationRuntimes": {
"properties": {
"typeProperties": {
"*": "="
}
}
},
"Microsoft.DataFactory/factories/triggers": {
"properties": {
"typeProperties": {
"recurrence": {
"*": "=",
"interval": "=:triggerSuffix:int",
"frequency": "=:-freq"
},
"maxConcurrency": "="
}
}
},
"Microsoft.DataFactory/factories/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
"username": "=",
"connectionString": "|:-connectionString:secureString",
"secretAccessKey": "|"
}
}
},
"AzureDataLakeStore": {
"properties": {
"typeProperties": {
"dataLakeStoreUri": "="
}
}
},
"AzureKeyVault": {
"properties": {
"typeProperties": {
"baseUrl": "|:baseUrl:secureString"
},
"parameters": {
"KeyVaultURL": {
"type": "=",
"defaultValue": "|:defaultValue:secureString"
}
}
}
}
},
"Microsoft.DataFactory/factories/datasets": {
"*": {
"properties": {
"typeProperties": {
"folderPath": "=",
"fileName": "="
}
}
}
},
"Microsoft.DataFactory/factories/credentials" : {
"properties": {
"typeProperties": {
"resourceId": "="
}
}
}
}
Voici une explication de la façon dont le modèle précédent est construit, décomposé par type de ressource.
Pipelines
- Toute propriété du chemin
activities/typeProperties/waitTimeInSecondsest paramétrable. Toute activité dans un pipeline qui a une propriété au niveau du code nomméewaitTimeInSeconds(par exemple, l’activitéWait) est paramétrable en tant que nombre, avec un nom par défaut. Mais elle n’a pas de valeur par défaut dans le modèle Resource Manager. Il s’agit d’une entrée obligatoire lors du déploiement de Resource Manager. - De même, une propriété appelée
headers(par exemple, dans une activitéWeb) est paramétrable avec le typeobject(JObject). Elle a une valeur par défaut, qui est la même que celle de la fabrique source.
IntegrationRuntimes
- Toutes les propriétés, sous le chemin
typePropertiessont paramétrables avec des valeurs par défaut respectives. Par exemple, deux propriétés existent sous les propriétés de typeIntegrationRuntimes:computePropertiesetssisProperties. Les deux types de propriété sont créés avec leurs valeurs et types (objet) par défaut respectifs.
Déclencheurs
- Sous
typeProperties, deux propriétés sont paramétrables. Le premier estmaxConcurrency, qui est spécifié avec une valeur par défaut et qui est de typestring. Elle porte le nom de paramètre par défaut<entityName>_properties_typeProperties_maxConcurrency. - La propriété
recurrenceest également paramétrable. Sous celle-ci, toutes les propriétés à ce niveau sont spécifiées pour être paramétrables sous forme de chaînes, avec des valeurs et noms de paramètres par défaut. La propriétéintervalest une exception, qui est paramétrée en tant que typeint. Le nom du paramètre a pour suffixe<entityName>_properties_typeProperties_recurrence_triggerSuffix. De même, la propriétéfreqest une chaîne et peut être paramétrée en tant que chaîne. La propriétéfreqest toutefois paramétrable sans valeur par défaut. Le nom est abrégé et suivi d’un suffixe. Par exemple :<entityName>_freq.
LinkedServices
- Les services liés sont uniques. Étant donné que les services liés et les jeux de données sont de types différents, vous pouvez fournir une personnalisation spécifique au type. Dans cet exemple, pour tous les services liés de type
AzureDataLakeStore, un modèle spécifique est appliqué. Pour tous les autres (via*), un autre modèle est appliqué. - La propriété
connectionStringest paramétrisée en tant que valeursecurestring. Elle n’a pas de valeur par défaut. Il a un nom de paramètre raccourci avec le suffixeconnectionString. - La propriété
secretAccessKeyse trouve être unAzureKeyVaultSecret(par exemple, dans un service lié Amazon S3). Elle est paramétrable automatiquement en tant que secret Azure Key Vault et extraite du coffre de clés configuré. Vous pouvez également paramétrer le coffre de clés proprement dit.
Groupes de données
- La personnalisation spécifique au type est disponible pour les jeux de données, mais vous pouvez fournir une configuration sans avoir explicitement de configuration au niveau *. Dans l’exemple précédent, toutes les propriétés du jeu de données sous
typePropertiessont paramétrables.
Remarque
Si des alertes et matrices Azure sont configurées pour un pipeline, notez qu’elles ne sont actuellement pas prises en charge en tant que paramètres pour les déploiements de modèle ARM. Pour réappliquer les alertes et les matrices dans un nouvel environnement, suivez les indications de Surveillance, alertes et matrices Data Factory.
Modèle de paramétrage par défaut
Vous trouverez ci-dessous le modèle actuel. Si vous n’avez besoin d’ajouter que quelques paramètres, il peut être judicieux de modifier directement ce modèle, car vous ne perdrez pas la structure de paramétrage existante.
{
"Microsoft.DataFactory/factories": {
"properties": {
"globalParameters": {
"*": {
"value": "="
}
}
},
"location": "="
},
"Microsoft.DataFactory/factories/globalparameters": {
"properties": {
"*": {
"value": "="
}
}
},
"Microsoft.DataFactory/factories/pipelines": {
},
"Microsoft.DataFactory/factories/dataflows": {
},
"Microsoft.DataFactory/factories/integrationRuntimes":{
"properties": {
"typeProperties": {
"ssisProperties": {
"catalogInfo": {
"catalogServerEndpoint": "=",
"catalogAdminUserName": "=",
"catalogAdminPassword": {
"value": "-::secureString"
}
},
"customSetupScriptProperties": {
"sasToken": {
"value": "-::secureString"
}
}
},
"linkedInfo": {
"key": {
"value": "-::secureString"
},
"resourceId": "="
},
"computeProperties": {
"dataFlowProperties": {
"externalComputeInfo": [{
"accessToken": "-::secureString"
}
]
}
}
}
}
},
"Microsoft.DataFactory/factories/triggers": {
"properties": {
"pipelines": [{
"parameters": {
"*": "="
}
}
],
"pipeline": {
"parameters": {
"*": "="
}
},
"typeProperties": {
"scope": "="
}
}
},
"Microsoft.DataFactory/factories/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
"username": "=",
"userName": "=",
"accessKeyId": "=",
"servicePrincipalId": "=",
"userId": "=",
"host": "=",
"clientId": "=",
"clusterUserName": "=",
"clusterSshUserName": "=",
"hostSubscriptionId": "=",
"clusterResourceGroup": "=",
"subscriptionId": "=",
"resourceGroupName": "=",
"tenant": "=",
"dataLakeStoreUri": "=",
"baseUrl": "=",
"database": "=",
"serviceEndpoint": "=",
"batchUri": "=",
"poolName": "=",
"databaseName": "=",
"systemNumber": "=",
"server": "=",
"url":"=",
"functionAppUrl":"=",
"environmentUrl": "=",
"aadResourceId": "=",
"sasUri": "|:-sasUri:secureString",
"sasToken": "|",
"connectionString": "|:-connectionString:secureString",
"hostKeyFingerprint": "="
}
}
},
"Odbc": {
"properties": {
"typeProperties": {
"userName": "=",
"connectionString": {
"secretName": "="
}
}
}
}
},
"Microsoft.DataFactory/factories/datasets": {
"*": {
"properties": {
"typeProperties": {
"folderPath": "=",
"fileName": "="
}
}
}
},
"Microsoft.DataFactory/factories/managedVirtualNetworks/managedPrivateEndpoints": {
"properties": {
"*": "="
}
}
}
Exemple : paramétrage d’un ID de cluster interactif Azure Databricks existant
L’exemple suivant montre comment ajouter une valeur unique au modèle de paramétrage par défaut. Nous voulons seulement ajouter un ID de cluster Azure Databricks interactif pour un service Databricks lié au fichier de paramètres. Ce fichier est le même que le fichier précédent, à l’exception de l’ajout de existingClusterId sous le champ des propriétés de Microsoft.DataFactory/factories/linkedServices.
{
"Microsoft.DataFactory/factories": {
"properties": {
"globalParameters": {
"*": {
"value": "="
}
}
},
"location": "="
},
"Microsoft.DataFactory/factories/pipelines": {
},
"Microsoft.DataFactory/factories/dataflows": {
},
"Microsoft.DataFactory/factories/integrationRuntimes":{
"properties": {
"typeProperties": {
"ssisProperties": {
"catalogInfo": {
"catalogServerEndpoint": "=",
"catalogAdminUserName": "=",
"catalogAdminPassword": {
"value": "-::secureString"
}
},
"customSetupScriptProperties": {
"sasToken": {
"value": "-::secureString"
}
}
},
"linkedInfo": {
"key": {
"value": "-::secureString"
},
"resourceId": "="
}
}
}
},
"Microsoft.DataFactory/factories/triggers": {
"properties": {
"pipelines": [{
"parameters": {
"*": "="
}
}
],
"pipeline": {
"parameters": {
"*": "="
}
},
"typeProperties": {
"scope": "="
}
}
},
"Microsoft.DataFactory/factories/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
"username": "=",
"userName": "=",
"accessKeyId": "=",
"servicePrincipalId": "=",
"userId": "=",
"clientId": "=",
"clusterUserName": "=",
"clusterSshUserName": "=",
"hostSubscriptionId": "=",
"clusterResourceGroup": "=",
"subscriptionId": "=",
"resourceGroupName": "=",
"tenant": "=",
"dataLakeStoreUri": "=",
"baseUrl": "=",
"database": "=",
"serviceEndpoint": "=",
"batchUri": "=",
"poolName": "=",
"databaseName": "=",
"systemNumber": "=",
"server": "=",
"url":"=",
"aadResourceId": "=",
"connectionString": "|:-connectionString:secureString",
"existingClusterId": "-"
}
}
},
"Odbc": {
"properties": {
"typeProperties": {
"userName": "=",
"connectionString": {
"secretName": "="
}
}
}
}
},
"Microsoft.DataFactory/factories/datasets": {
"*": {
"properties": {
"typeProperties": {
"folderPath": "=",
"fileName": "="
}
}
}}
}
Contenu connexe
- Vue d’ensemble de l’intégration et de la livraison continues
- Automatiser l’intégration continue à l’aide des versions d’Azure Pipelines
- Promouvoir manuellement un modèle Resource Manager pour chaque environnement
- Modèles Resource Manager liés
- Utilisation d’un environnement de production de correctif logiciel
- Exemple de script de pré-déploiement et de post-déploiement