Copier et transformer des données depuis et vers un point de terminaison REST à l’aide d’Azure Data Factory
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit comment utiliser l’activité Copy dans Azure Data Factory pour copier des données depuis et vers un point de terminaison REST. Il s’appuie sur l’article Activité de copie dans Azure Data Factory, qui constitue une présentation de l’activité de copie.
Les différences entre ce connecteur REST, un connecteur HTTP et le connecteur Table web sont les suivantes :
- Le connecteur REST prend spécifiquement en charge la copie de données à partir d’API RESTful.
- Le connecteur HTTP est générique pour récupérer des données à partir de n’importe quel point de terminaison HTTP, par exemple pour télécharger un fichier. Avant que ce connecteur REST soit disponible, vous utilisiez peut-être un connecteur HTTP pour copier les données d’API RESTful, ce qui est pris en charge, mais moins fonctionnel que le connecteur REST.
- Le connecteur Table web extrait le contenu de tables d’une page web HTML.
Fonctionnalités prises en charge
Ce connecteur REST est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/récepteur) | ① ② |
| Mappage de flux de données (source/récepteur) | ① |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour obtenir la liste des magasins de données pris en charge en tant que sources et récepteurs, voir Magasins de données pris en charge.
Plus précisément, ce connecteur REST générique prend en charge ce qui suit :
- La copie de données à partir d’un point de terminaison REST à l’aide des méthodes GET ou POST et la copie de données vers un point de terminaison REST à l’aide des méthodes POST, PUT ou PATCH.
- La copie de données avec l’une des méthodes d’authentification suivantes : Anonyme, De base, Principal de service, Informations d’identification du client OAuth2, Identité managée affectée par le système et Identité managée affectée par l’utilisateur.
- La Pagination dans les API REST.
- Pour REST en tant que source, la copie de la réponse JSON REST en l’état ou son analyse à l’aide d’une mise en correspondance du schéma. Seule la charge utile de réponse dans JSON est prise en charge.
Conseil
Pour tester une requête pour l’extraction de données avant de configurer le connecteur REST dans Data Factory, obtenez des informations à partir de la spécification d’API sur les exigences d’en-tête et de corps. Vous pouvez utiliser des outils tels que Visual Studio, Invoke-RestMethod de PowerShell ou un navigateur web pour la validation.
Prérequis
Si votre magasin de données se trouve dans un réseau local, un réseau virtuel Azure ou un cloud privé virtuel Amazon, vous devez configurer un runtime d’intégration auto-hébergé pour vous y connecter.
Si votre magasin de données est un service de données cloud managé, vous pouvez utiliser Azure Integration Runtime. Si l’accès est limité aux adresses IP qui sont approuvées dans les règles de pare-feu, vous pouvez ajouter les adresses IP Azure Integration Runtime dans la liste d’autorisation.
Vous pouvez également utiliser la fonctionnalité de runtime d’intégration de réseau virtuel managé dans Azure Data Factory pour accéder au réseau local sans installer et configurer un runtime d’intégration auto-hébergé.
Pour plus d’informations sur les mécanismes de sécurité réseau et les options pris en charge par Data Factory, consultez Stratégies d’accès aux données.
Bien démarrer
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié REST à l’aide de l’interface utilisateur
Utilisez les étapes suivantes pour créer un service lié REST dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis sélectionnez Nouveau :
Recherchez REST et sélectionnez le connecteur REST.
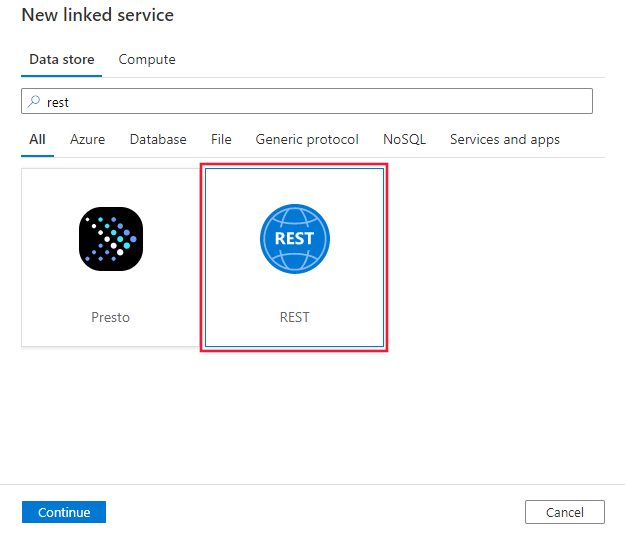
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
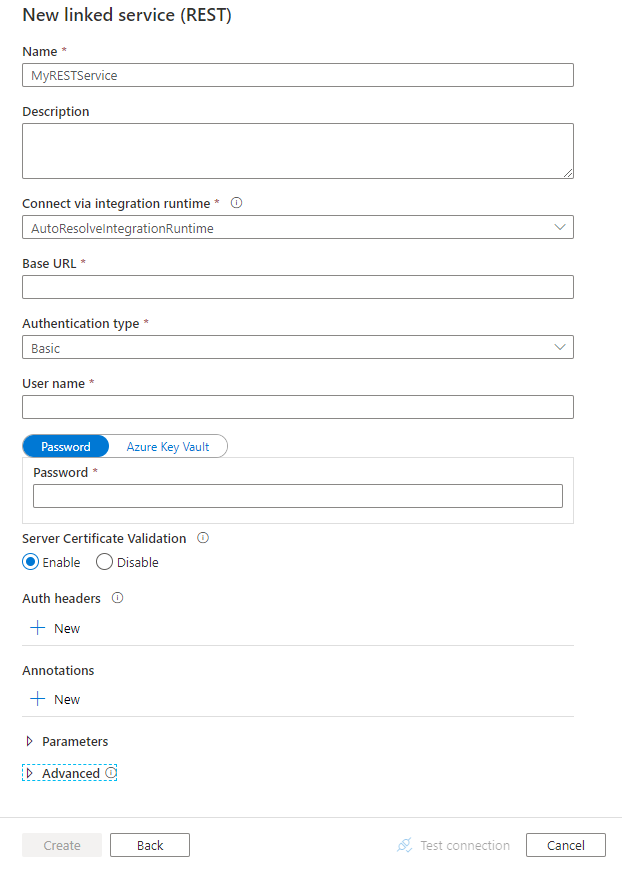
Détails de configuration des connecteurs
Les sections suivantes fournissent des informations sur les propriétés utilisées pour définir les entités Data Factory propres au connecteur REST.
Propriétés du service lié
Les propriétés prises en charge pour le service lié REST sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur RestService. | Oui |
| url | URL de base du service REST. | Oui |
| enableServerCertificateValidation | Indique s'il convient de valider ou non le certificat TLS/SSL côté serveur lors de la connexion au point de terminaison. | Non (la valeur par défaut est true) |
| authenticationType | Type d’authentification utilisé pour se connecter au service REST. Les valeurs autorisées sont Anonymous, Basic, AadServicePrincipal, OAuth2ClientCredential et ManagedServiceIdentity. Vous pouvez également configurer des en-têtes d’authentification dans la propriété authHeaders. Pour d’autres propriétés et exemples, voir les sections correspondantes ci-dessous. |
Oui |
| authHeaders | En-têtes de requête HTTP supplémentaires pour l’authentification. Par exemple, pour utiliser l’authentification par clé API, vous pouvez sélectionner le type d’authentification « anonyme » et spécifier la clé API dans l’en-tête. |
Non |
| connectVia | Runtime d’intégration à utiliser pour la connexion au magasin de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, cette propriété utilise Azure Integration Runtime par défaut. | Non |
Pour les différents types d’authentification, consultez les sections correspondantes pour plus d’informations.
- Authentification de base
- Authentification du principal de service
- Authentification des informations d’identification client OAuth2
- Authentification d’identité managée affectée par le système
- Authentification d’identité managée affectée par l’utilisateur
- Authentification anonyme
Utiliser une authentification de base
Définissez la propriété authenticationType sur De base. Outre les propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| userName | Nom d’utilisateur à utiliser pour accéder au point de terminaison REST. | Oui |
| mot de passe | Mot de passe de l’utilisateur (valeur userName). Vous pouvez marquer ce champ en tant que type SecureString pour le stocker de manière sécurisée dans Data Factory. Vous pouvez également référencer un secret stocké dans Azure Key Vault. | Oui |
Exemple
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"authenticationType": "Basic",
"url" : "<REST endpoint>",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Utiliser l’authentification du principal de service
Définissez la propriété authenticationType sur AadServicePrincipal. Outre les propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| servicePrincipalId | Indiquez l’identifiant client de l’application Microsoft Entra. | Oui |
| servicePrincipalCredentialType | Spécifiez le type d’informations d’identification à utiliser pour l’authentification de principal du service. Les valeurs autorisées sont ServicePrincipalKey et ServicePrincipalCert. |
Non |
| Pour ServicePrincipalKey | ||
| servicePrincipalKey | Indiquez la clé de l’application Microsoft Entra. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité dans Data Factory, ou référencez un secret stocké dans Azure Key Vault. | Non |
| Pour ServicePrincipalCert | ||
| servicePrincipalEmbeddedCert | Spécifiez le certificat codé en base64 de votre application inscrite dans Microsoft Entra ID, et vérifiez que le type de contenu du certificat est PKCS #12. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. Accédez à cette section pour savoir comment enregistrer le certificat dans Azure Key Vault. | Non |
| servicePrincipalEmbeddedCertPassword | Spécifiez le mot de passe de votre certificat si votre certificat est sécurisé par un mot de passe. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. | Non |
| tenant | Spécifiez les informations de locataire (nom de domaine ou ID de locataire) dans lesquels se trouve votre application. Récupérez-le en pointant la souris dans le coin supérieur droit du Portail Azure. | Oui |
| aadResourceId | Spécifiez la ressource Microsoft Entra pour laquelle vous demandez une autorisation, par exemple https://management.core.windows.net. |
Oui |
| azureCloudType | Pour l’authentification du principal de service, spécifiez le type d’environnement cloud Azure auquel votre application Microsoft Entra est inscrite. Les valeurs autorisées sont AzurePublic, AzureChina, AzureUsGovernment et AzureGermany. Par défaut, l’environnement cloud de la fabrique de données est utilisé. |
Non |
Exemple 1 : utilisation de l’authentification de la clé du principal de service
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple 2 : utilisation de l’authentification par certificat du principal du service
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalEmbeddedCert": {
"type": "SecureString",
"value": "<the base64 encoded certificate of your application registered in Microsoft Entra ID>"
},
"servicePrincipalEmbeddedCertPassword": {
"type": "SecureString",
"value": "<password of your certificate>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Enregistrer le certificat de principal de service dans Azure Key Vault
Vous avez deux options pour enregistrer le certificat de principal de service dans Azure Key Vault :
Option 1 :
Convertissez le certificat de principal de service en chaîne base64. Apprenez-en plus dans cet article.
Enregistrez la chaîne base64 en tant que secret dans Azure Key Vault.
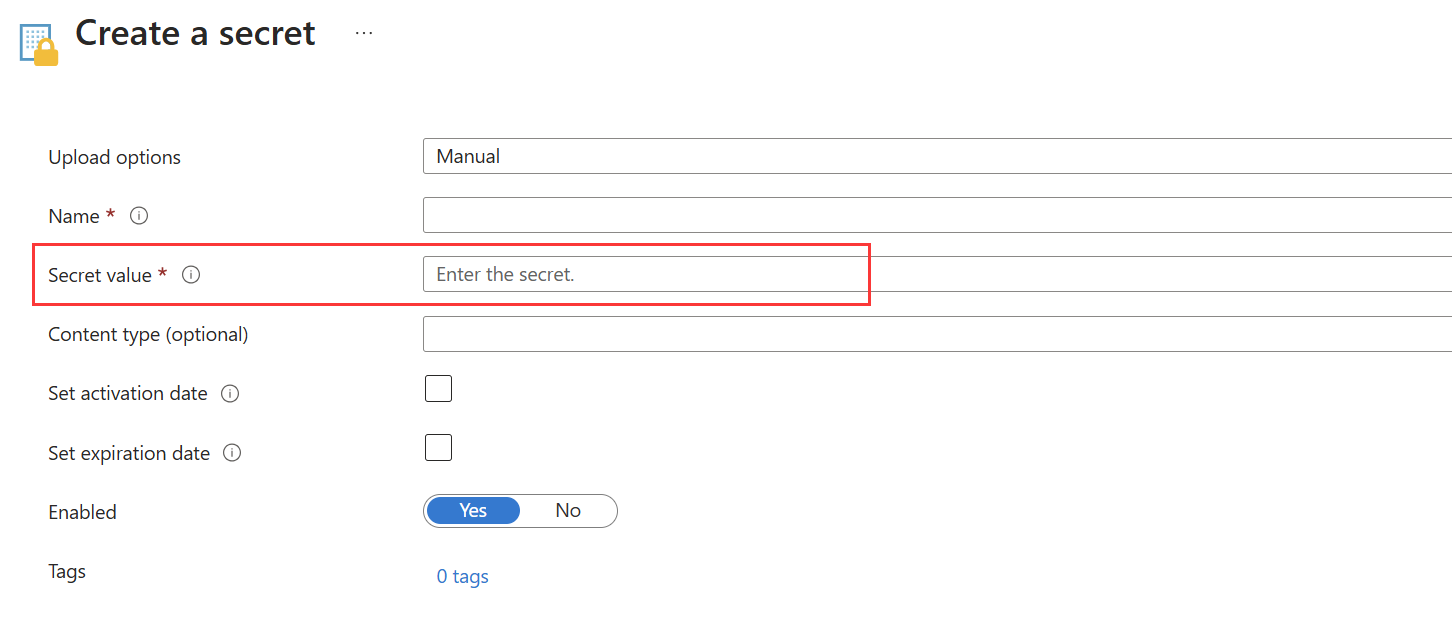
Option 2 :
Si vous ne pouvez pas télécharger le certificat à partir d’Azure Key Vault, vous pouvez utiliser ce modèle pour enregistrer le certificat de principal de service converti en tant que secret dans Azure Key Vault.

Utiliser l’authentification des informations d’identification client OAuth2
Définissez la propriété authenticationType sur OAuth2ClientCredential. Outre les propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| tokenEndpoint | Point de terminaison de jeton du serveur d’autorisation pour acquérir le jeton d’accès. | Oui |
| clientId | ID client associé à votre application. | Oui |
| clientSecret | Secret client associé à votre application. Vous pouvez marquer ce champ en tant que type SecureString pour le stocker de manière sécurisée dans Data Factory. Vous pouvez également référencer un secret stocké dans Azure Key Vault. | Oui |
| scope | Étendue de l’accès requis. Décrit le type d’accès demandé. | Non |
| resource | Service ou ressource cible auquel l’accès sera demandé. | Non |
Exemple
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"enableServerCertificateValidation": true,
"authenticationType": "OAuth2ClientCredential",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value": "<client secret>"
},
"tokenEndpoint": "<token endpoint>",
"scope": "<scope>",
"resource": "<resource>"
}
}
}
Utiliser l’authentification d’identité managée affectée par le système
Définissez la propriété authenticationType sur ManagedServiceIdentity. Outre les propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| aadResourceId | Spécifiez la ressource Microsoft Entra pour laquelle vous demandez une autorisation, par exemple https://management.core.windows.net. |
Oui |
Exemple
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<AAD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Utiliser l’authentification d’identité managée affectée par l’utilisateur
Définissez la propriété authenticationType sur ManagedServiceIdentity. Outre les propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| aadResourceId | Spécifiez la ressource Microsoft Entra pour laquelle vous demandez une autorisation, par exemple https://management.core.windows.net. |
Oui |
| credentials | Spécifiez l’identité managée affectée par l’utilisateur en tant qu’objet d’informations d’identification. | Oui |
Exemple
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Utilisation d’en-têtes d’authentification
En outre, vous pouvez configurer des en-têtes de demande pour l’authentification en plus des types d’authentification intégrés.
Exemple : Utilisation de l’authentification par clé API
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint>",
"authenticationType": "Anonymous",
"authHeaders": {
"x-api-key": {
"type": "SecureString",
"value": "<API key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Cette section contient la liste des propriétés prises en charge par le jeu de données REST.
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez Jeux de données et services liés.
Pour copier des données à partir de REST, les propriétés suivantes sont prises en charge :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur RestResource. | Oui |
| relativeUrl | URL relative de la ressource qui contient les données. Quand cette propriété n’est pas spécifiée, seule l’URL indiquée dans la définition du service lié est utilisée. Le connecteur HTTP copie les données à partir de l’URL combinée : [URL specified in linked service]/[relative URL specified in dataset]. |
Non |
Si vous avez défini requestMethod, additionalHeaders, requestBody et paginationRules dans le jeu de données, il reste pris en charge tel quel, mais nous vous suggérons d’utiliser le nouveau modèle dans l’activité à l’avenir.
Exemple :
{
"name": "RESTDataset",
"properties": {
"type": "RestResource",
"typeProperties": {
"relativeUrl": "<relative url>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<REST linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriétés de l’activité de copie
Cette section fournit la liste des propriétés prises en charge par la source et le récepteur REST.
Pour obtenir la liste complète des sections et des propriétés permettant de définir des activités, consultez Pipelines.
REST en tant que source
Les propriétés prises en charge dans la section source de l’activité de copie sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur RestSource. | Oui |
| requestMethod | Méthode HTTP. Les valeurs autorisées sont GET (par défaut) et POST. | Non |
| additionalHeaders | En-têtes de requête HTTP supplémentaires. | Non |
| requestBody | Corps de la requête HTTP. | Non |
| paginationRules | Règles de pagination pour composer des requêtes de page suivantes. Pour plus de détails, voir la section Prise en charge la pagination. | Non |
| httpRequestTimeout | Délai d’expiration (valeur TimeSpan) pour l’obtention d’une réponse par la requête HTTP. Cette valeur correspond au délai d’expiration pour l’obtention d’une réponse, et non au délai d’expiration pour la lecture des données de la réponse. La valeur par défaut est 00:01:40. | Non |
| requestInterval | Durée d’attente avant d’envoyer la requête de page suivante. La valeur par défaut est 00:00:01 | Non |
Notes
Le connecteur REST ignore tout en-tête « accepter » spécifié dans additionalHeaders. Comme le connecteur REST ne prend en charge que la réponse dans JSON, il génère automatiquement un en-tête de Accept: application/json.
Le tableau d’objets dans le corps de la réponse n’est pas pris en charge dans la pagination.
Exemple 1 : Utilisation de la méthode Get avec la pagination
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"additionalHeaders": {
"x-user-defined": "helloworld"
},
"paginationRules": {
"AbsoluteUrl": "$.paging.next"
},
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exemple 2 : Utilisation de la méthode Post
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"requestMethod": "Post",
"requestBody": "<body for POST REST request>",
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
REST en tant que récepteur
Les propriétés prises en charge dans la section sink (récepteur) de l’activité de copie sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du récepteur de l’activité Copy doit être définie sur RestSink. | Oui |
| requestMethod | Méthode HTTP. Les valeurs autorisées sont POST (valeur par défaut), PUT et PATCH. | Non |
| additionalHeaders | En-têtes de requête HTTP supplémentaires. | Non |
| httpRequestTimeout | Délai d’expiration (valeur TimeSpan) pour l’obtention d’une réponse par la requête HTTP. Cette valeur correspond au délai d’expiration pour l’obtention d’une réponse, et non au délai d’expiration pour l’écriture des données. La valeur par défaut est 00:01:40. | Non |
| requestInterval | Intervalle de temps en millisecondes entre les différentes demandes. La valeur de l’intervalle de demande doit être un nombre compris entre [10, 60000]. | Non |
| httpCompressionType | Type de compression HTTP à utiliser lors de l’envoi de données avec un niveau de compression optimal. Les valeurs autorisées sont none et gzip. | Non |
| writeBatchSize | Nombre d’enregistrements à écrire dans le récepteur REST par lot. La valeur par défaut est 10 000. | Non |
Le connecteur REST en tant que récepteur fonctionne avec les API REST qui acceptent JSON. Les données sont envoyées au format JSON avec le modèle suivant. Si nécessaire, vous pouvez utiliser le mappage de schéma de l’activité de copie pour remodeler les données sources de façon à les rendre conformes à la charge utile attendue par l’API REST.
[
{ <data object> },
{ <data object> },
...
]
Exemple :
"activities":[
{
"name": "CopyToREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<REST output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "RestSink",
"requestMethod": "POST",
"httpRequestTimeout": "00:01:40",
"requestInterval": 10,
"writeBatchSize": 10000,
"httpCompressionType": "none",
},
}
}
]
Propriétés du mappage de flux de données
REST est pris en charge dans les flux de données pour les jeux de données d’intégration et les jeux de données inline.
Transformation de la source
| Propriété | Description | Obligatoire |
|---|---|---|
| requestMethod | Méthode HTTP. Les valeurs autorisées sont GET et POST. | Oui |
| relativeUrl | URL relative de la ressource qui contient les données. Quand cette propriété n’est pas spécifiée, seule l’URL indiquée dans la définition du service lié est utilisée. Le connecteur HTTP copie les données à partir de l’URL combinée : [URL specified in linked service]/[relative URL specified in dataset]. |
Non |
| additionalHeaders | En-têtes de requête HTTP supplémentaires. | Non |
| httpRequestTimeout | Délai d’expiration (valeur TimeSpan) pour l’obtention d’une réponse par la requête HTTP. Cette valeur correspond au délai d’expiration pour l’obtention d’une réponse, et non au délai d’expiration pour l’écriture des données. La valeur par défaut est 00:01:40. | Non |
| requestInterval | Intervalle de temps en millisecondes entre les différentes demandes. La valeur de l’intervalle de demande doit être un nombre compris entre [10, 60000]. | Non |
| QueryParameters.request_query_parameter OU QueryParameters[’request_query_parameter’] | « request_query_parameter » est défini par l’utilisateur et fait référence à un nom de paramètre de requête dans l’URL de la requête HTTP suivante. | Non |
Transformation du récepteur
| Propriété | Description | Obligatoire |
|---|---|---|
| additionalHeaders | En-têtes de requête HTTP supplémentaires. | Non |
| httpRequestTimeout | Délai d’expiration (valeur TimeSpan) pour l’obtention d’une réponse par la requête HTTP. Cette valeur correspond au délai d’expiration pour l’obtention d’une réponse, et non au délai d’expiration pour l’écriture des données. La valeur par défaut est 00:01:40. | Non |
| requestInterval | Intervalle de temps en millisecondes entre les différentes demandes. La valeur de l’intervalle de demande doit être un nombre compris entre [10, 60000]. | Non |
| httpCompressionType | Type de compression HTTP à utiliser lors de l’envoi de données avec un niveau de compression optimal. Les valeurs autorisées sont none et gzip. | Non |
| writeBatchSize | Nombre d’enregistrements à écrire dans le récepteur REST par lot. La valeur par défaut est 10 000. | Non |
Vous pouvez définir les méthodes delete, insert, update et upsert, ainsi que les données de ligne relatives à envoyer au récepteur REST pour les opérations CRUD.
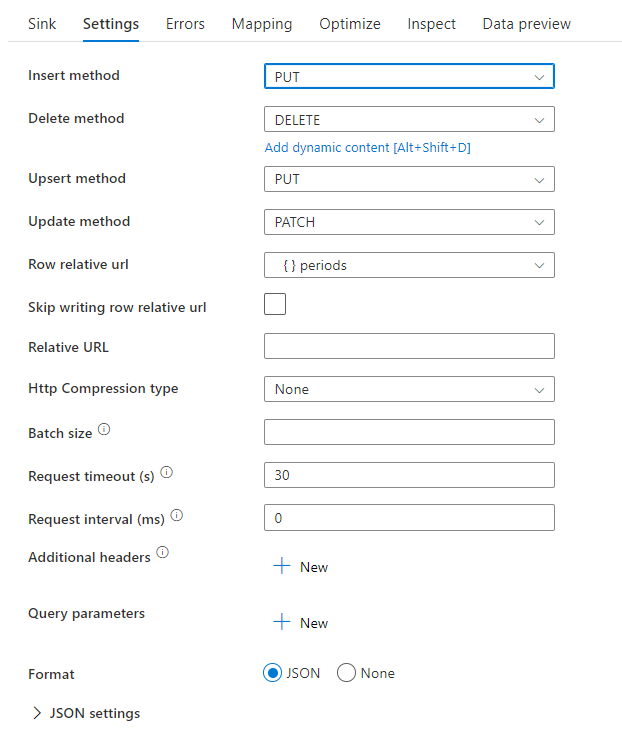
Exemple de script de flux de données
Notez l’utilisation d’une transformation alter row avant le récepteur pour indiquer à ADF le type d’action à effectuer avec votre récepteur REST. Par ex. insert, update, upsert, delete.
AlterRow1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
rowRelativeUrl: 'periods',
insertHttpMethod: 'PUT',
deleteHttpMethod: 'DELETE',
upsertHttpMethod: 'PUT',
updateHttpMethod: 'PATCH',
timeout: 30,
requestFormat: ['type' -> 'json'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Prise en charge la pagination
Normalement, quand vous copiez des données à partir de l’API REST, celles-ci limite la taille de charge utile de réponse d’une même demande à un nombre raisonnable. Pour retourner une grande quantité de données, elle fractionne le résultat en plusieurs pages et exige des appelants qu’ils envoient des demandes consécutives pour obtenir la page suivante du résultat. En règle générale, la requête d’une page est dynamique et composée par les informations retournées à partir de la réponse de la page précédente.
Ce connecteur REST générique prend en charge les modèles de pagination suivants :
- URL absolue ou relative de la requête suivante = valeur de propriété dans le corps de la réponse en cours
- URL absolue ou relative de la requête suivante = valeur d’en-tête dans les en-têtes de la réponse en cours
- Paramètre de requête de la demande suivante = valeur de propriété dans le corps de la réponse en cours
- Paramètre de requête de la demande suivante = valeur d’en-tête dans les en-têtes de la réponse en cours
- En-tête de la requête suivante = valeur de propriété dans le corps de la réponse en cours
- En-tête de la requête suivante = valeur d’en-tête dans les en-têtes de la réponse en cours
Les règles de pagination sont définies en tant que dictionnaire dans un jeu de données qui contient une ou plusieurs paires clé-valeur respectant la casse. La configuration sera utilisée pour générer la requête à partir de la deuxième page. Le connecteur arrête les itérations quand il obtient le code d’état HTTP 204 (Aucun contenu) ou quand une expression JSONPath dans « paginationRules » retourne la valeur null.
Clés prises en charge dans les règles de pagination :
| Clé | Description |
|---|---|
| AbsoluteUrl | Indique l’URL pour l’émission de la requête suivante. Il peut s’agit d’une URL absolue ou relative. |
| QueryParameters.request_query_parameter OU QueryParameters[’request_query_parameter’] | « request_query_parameter » est défini par l’utilisateur et fait référence à un nom de paramètre de requête dans l’URL de la requête HTTP suivante. |
| Headers.request_header OR Headers[’request_header’] | « request_header » est défini par l’utilisateur et fait référence à un nom d’en-tête dans la requête HTTP suivante. |
| EndCondition:end_condition | « end_condition » est défini par l’utilisateur, et indique la condition qui mettra fin à la boucle de pagination dans la requête HTTP suivante. |
| MaxRequestNumber | Indique le numéro de requête de pagination maximal. Laisser vide pour indiquer aucune limite. |
| SupportRFC5988 | Par défaut, cette propriété est définie sur la valeur true si aucune règle de pagination n’est définie. Vous pouvez désactiver cette règle en définissant la propriété supportRFC5988 sur la valeur false ou supprimer cette propriété du script. |
Valeurs prises en charge dans les règles de pagination :
| Valeur | Description |
|---|---|
| Headers.response_header OR Headers[’response_header’] | « response_header » est défini par l’utilisateur et fait référence à un nom d’en-tête dans la réponse HTTP actuelle, dont la valeur sera utilisée pour émettre la prochaine requête. |
| Expression JSONPath commençant par « $ » (représentant la racine du corps de la réponse) | Le corps de la réponse ne doit contenir qu’un seul objet JSON et le tableau d’objets en tant que corps de la réponse n’est pas pris en charge. L’expression JSONPath doit retourner une seule valeur primitive qui sera utilisée pour émettre la requête suivante. |
Notes
Les règles de pagination dans le flux de données de mappage diffèrent de celles de l’activité Copy pour les points suivants :
- La plage n’est pas prise en charge dans le flux de données de mappage.
['']n’est pas pris en charge dans le flux de données de mappage. À la place, utilisez{}pour placer un caractère spécial dans une séquence d’échappement. Par exemple,body.{@odata.nextLink}, dont le nœud JSON@odata.nextLinkcontient un caractère spécial..- La condition de fin est prise en charge dans le flux de données de mappage, mais la syntaxe de condition est différente dans l’activité Copy.
bodyest utilisé pour indiquer le corps de la réponse au lieu de$.headerest utilisé pour indiquer l’en-tête de réponse au lieu deheaders. Voici deux exemples illustrant cette différence :- Exemple 1 :
Activité Copy : "EndCondition:$.data": "Empty"
Flux de données de mappage : "EndCondition:body.data": "Empty" - Exemple 2 :
Activité Copy : "EndCondition:headers.complete": "Exist"
Flux de données de mappage : "EndCondition:header.complete": "Exist"
- Exemple 1 :
Exemples de règles de pagination
Cette section fournit une liste d’exemples de paramètres de règles de pagination.
Exemple 1 : variables dans QueryParameters
Cet exemple fournit les étapes de configuration pour envoyer plusieurs demandes dont les variables sont dans QueryParameters.
Plusieurs demandes :
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
......
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=10000
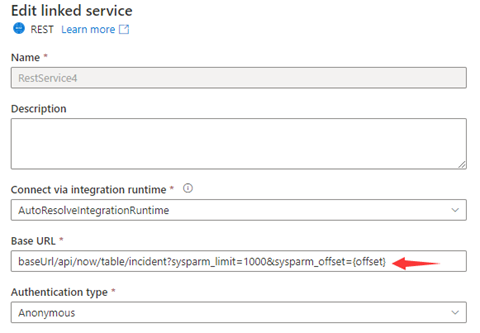
Étape 1 : entrez sysparm_offset={offset} dans l’URL de base ou l’URL relative, comme indiqué dans les captures d’écran suivantes :
ou
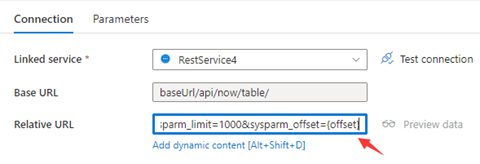
Étape 2 : définissez les Règles de pagination sur l’option 1 ou l’option 2 :
Option1 : "QueryParameters.{offset}" : "RANGE:0:10000:1000"
Option2 : "AbsoluteUrl.{offset}" : "RANGE:0:10000:1000"
Exemple 2 : variables dans AbsoluteUrl
Cet exemple fournit les étapes de configuration pour envoyer plusieurs demandes dont les variables se trouvent dans AbsoluteUrl.
Plusieurs demandes :
BaseUrl/api/now/table/t1
BaseUrl/api/now/table/t2
......
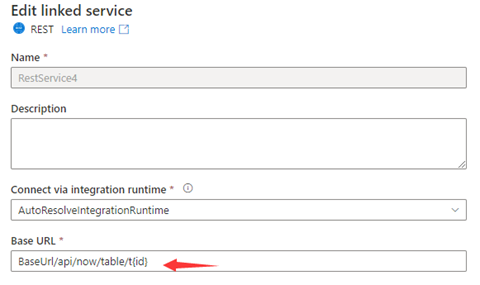
BaseUrl/api/now/table/t100
Étape 1 : entrez {id} soit dans l’URL de base dans la page de configuration du service lié ou dans l’URL relative dans le volet de connexion du jeu de données.
ou
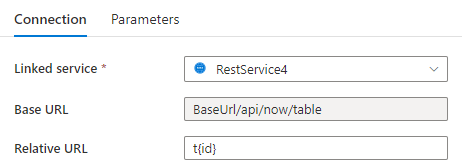
Étape 2 : définissez les Règles de pagination sur "AbsoluteUrl.{id}" :"RANGE:1:100:1".
Exemple 3 : variables dans les en-têtes
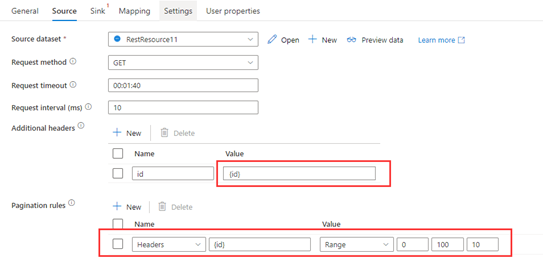
Cet exemple fournit les étapes de configuration pour envoyer plusieurs demandes dont les variables sont dans les en-têtes.
Plusieurs demandes :
RequestUrl : https://example/table
Demande 1 : Header(id->0)
Demande 2 : Header(id->10)
......
Demande 100 : Header(id->100)
Étape 1 : entrez {id} dans les En-têtes supplémentaires.
Étape 2 : Définissez les Règles de pagination sur "Headers.{id}" : "RANGE:0:100:10".
Exemple 4 : les variables se trouvent dans les en-têtes AbsoluteUrl/QueryParameters/Headers, la variable de fin n’est pas prédéfinie et la condition de fin est basée sur la réponse
Cet exemple fournit les étapes de configuration pour envoyer plusieurs demandes dont les variables sont dans AbsoluteUrl/QueryParameters/Headers, mais dont la variable de fin n’est pas définie. Pour différentes réponses, différents paramètres de règle de condition de fin sont affichés dans l’exemple 4.1-4.6.
Plusieurs demandes :
Request 1: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
Request 2: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
Request 3: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=2000,
......
Voici deux réponses rencontrées dans cet exemple :
Réponse 1 :
{
Data: [
{key1: val1, key2: val2
},
{key1: val3, key2: val4
}
]
}
Réponse 2 :
{
Data: [
{key1: val5, key2: val6
},
{key1: val7, key2: val8
}
]
}
Étape 1 : définissez la plage de Règles de pagination comme Example 1 et laissez la fin de la plage vide en tant que "AbsoluteUrl.{offset}": "RANGE:0::1000".
Étape 2 : définissez des règles de condition de fin différentes en fonction des dernières réponses. Consultez les exemples ci-dessous :
Exemple 4.1 : la pagination se termine quand la valeur du nœud spécifique dans la réponse est vide
L’API REST retourne la dernière réponse dans la structure suivante :
{ Data: [] }Définissez la règle de condition de fin sur "EndCondition:$.data": "Empty" pour terminer la pagination quand la valeur du nœud spécifique dans la réponse est vide.

Exemple 4.2 : la pagination se termine quand la valeur du nœud spécifique dans la réponse n’existe pas
L’API REST retourne la dernière réponse dans la structure suivante :
{}Définissez la règle de condition de fin sur "EndCondition:$.data": "NonExist" pour terminer la pagination quand la valeur du nœud spécifique dans la réponse n’existe pas.

Exemple 4.3 : la pagination se termine quand la valeur du nœud spécifique dans la réponse existe
L’API REST retourne la dernière réponse dans la structure suivante :
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Définissez la règle de condition de fin sur "EndCondition:$.Complete": "Exist" pour terminer la pagination quand la valeur du nœud spécifique dans la réponse existe.

Exemple 4.4 : la pagination se termine quand la valeur du nœud spécifique dans la réponse est une valeur constante définie par l’utilisateur
L’API REST retourne la réponse dans la structure suivante :
{ Data: [ {key1: val1, key2: val2 }, {key1: val3, key2: val4 } ], Complete: false }......
Et la dernière réponse est retournée dans la structure suivante :
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Définissez la règle de condition de fin sur "EndCondition:$.Complete": "Const:true" pour terminer la pagination quand la valeur du nœud spécifique dans la réponse est une valeur constante définie par l’utilisateur.

Exemple 4.5 : la pagination se termine quand la valeur de la clé d’en-tête dans la réponse est égale à une valeur constante définie par l’utilisateur
Les clés d’en-tête dans les réponses de l’API REST sont affichées dans la structure ci-dessous :
En-tête de réponse 1 :
header(Complete->0)
......
Dernier en-tête de réponse :header(Complete->1)Définissez la règle de condition de fin sur "EndCondition:headers.Complete": "Const:1" pour terminer la pagination quand la valeur de la clé d’en-tête dans la réponse est égale à la valeur constante définie par l’utilisateur.

Exemple 4.6 : la pagination se termine quand la clé existe dans l’en-tête de réponse
Les clés d’en-tête dans les réponses de l’API REST sont affichées dans la structure ci-dessous :
En-tête de réponse 1 :
header()
......
Dernier en-tête de réponse :header(CompleteTime->20220920)Définissez la règle de la condition de fin sur "EndCondition:headers.CompleteTime": "Exist" pour terminer la pagination quand la clé existe dans l’en-tête de réponse.

Exemple 5 : définir la condition de fin pour éviter les demandes sans fin quand la règle de plage n’est pas définie
Cet exemple fournit les étapes de configuration pour envoyer plusieurs demandes quand la règle de plage n’est pas utilisée. La condition de fin peut être définie. Reportez-vous à l’exemple 4.1-4.6 pour éviter les demandes sans fin. L’API REST retourne une réponse dans la structure suivante. Dans ce cas, l’URL de la page suivante est représentée dans paging.next.
{
"data": [
{
"created_time": "2017-12-12T14:12:20+0000",
"name": "album1",
"id": "1809938745705498_1809939942372045"
},
{
"created_time": "2017-12-12T14:14:03+0000",
"name": "album2",
"id": "1809938745705498_1809941802371859"
},
{
"created_time": "2017-12-12T14:14:11+0000",
"name": "album3",
"id": "1809938745705498_1809941879038518"
}
],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
...
La dernière réponse est :
{
"data": [],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "Same with Last Request URL"
}
}
Étape 1 : définissez les Règles de pagination sur "AbsoluteUrl": "$.paging.next".
Étape 2 : si next dans la dernière réponse est toujours identique à la dernière URL de demande et non vide, des demandes sans fin sont envoyées. La condition de fin peut être utilisée pour éviter les demandes sans fin. Par conséquent, définissez la règle de la condition de fin. Référez-vous à l’exemple 4.1-4.6.
Exemple 6 : définir le nombre de demande maximum pour éviter les demandes sans fin
Définissez MaxRequestNumber pour éviter les demandes sans fin, comme illustré dans la capture d’écran suivante :

Exemple 7 : la règle de pagination RFC 5988 est prise en charge par défaut
Le serveur principal obtient automatiquement l’URL suivante en fonction des liens de style RFC 5988 dans l’en-tête.

Conseil
Si vous ne souhaitez pas activer cette règle de pagination par défaut, vous pouvez définir supportRFC5988 sur false ou simplement la supprimer dans le script.
Exemple 8a : l'URL de la requête suivante se trouve dans le corps de la réponse lors de l'utilisation de la pagination dans les flux de données de mappage
Cet exemple indique comment définir la règle de pagination et la règle de la condition de fin dans les flux de données de mappage quand l’URL de la demande suivante provient du corps de la réponse.
Le schéma de réponse est illustré ci-dessous :
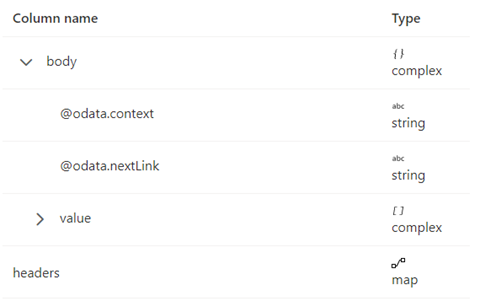
Les règles de pagination doivent être définies comme dans la capture d’écran suivante :

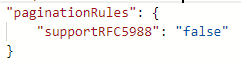
Par défaut, la pagination s’arrête quand body.{@odata.nextLink}** a la valeur Null ou est vide.
Toutefois, si la valeur de @odata.nextLink dans le corps de la dernière réponse est égale à la dernière URL de la demande, cela entraîne une boucle sans fin. Pour éviter cette condition, définissez des règles de condition de fin.
Si la Valeur dans la dernière réponse est Vide, la règle de la condition de fin peut être définie comme suit :

Si la valeur de la clé complète dans l’en-tête de réponse est égale à true et indique la fin de la pagination, la règle de la condition de fin peut être définie comme suit :
Exemple 8b : l'URL de la requête suivante se trouve dans le corps de la réponse lors de l'utilisation de la pagination dans l'activité de copie
Cet exemple montre comment définir la règle de pagination dans une activité de copie lorsque l’URL de la prochaine requête est contenue dans le corps de la réponse.
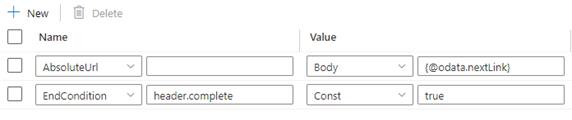
Le schéma de réponse est illustré ci-dessous :
Les règles de pagination doivent être définies comme indiqué dans la capture d'écran suivante :

Exemple 9 : le format de réponse est XML et l’URL de la demande suivante provient du corps de la réponse en cas d’utilisation de la pagination dans le flux de données de mappage
Cet exemple indique comment définir la règle de pagination dans les flux de données de mappage quand le format de réponse est XML et l’URL de la demande suivante provient du corps de la réponse. Comme indiqué dans la capture d’écran suivante, la première URL est https://<user>.dfs.core.windows.NET/bugfix/test/movie_1.xml
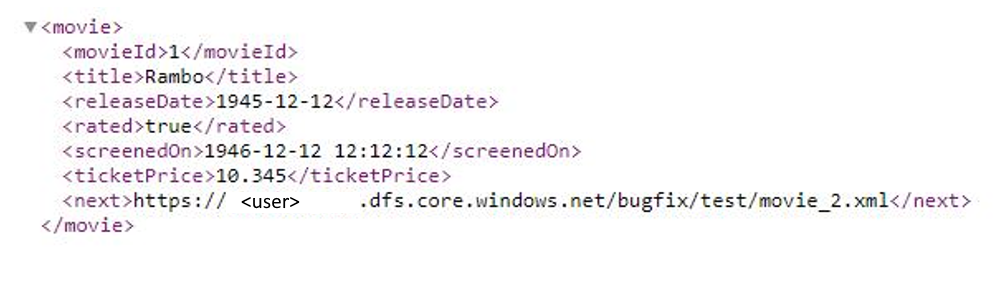
Le schéma de réponse est illustré ci-dessous :
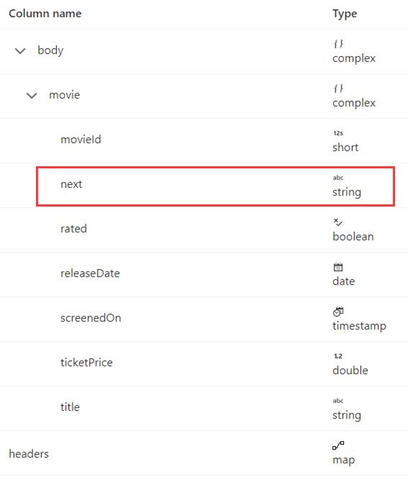
La syntaxe de la règle de pagination est identique à l’exemple 8 et doit être définie comme dans l’exemple ci-dessous :

Exporter la réponse JSON en l’état
Vous pouvez utiliser ce connecteur REST pour exporter une réponse JSON d’API REST en l’état à différentes banques basées sur un fichier. Pour obtenir une telle copie indépendante du schéma, ignorez la section « structure » (également appelée schéma) dans le mappage de schéma et de jeu de données dans l’activité de copie.
Mappage de schéma
Pour copier des données d’un point de terminaison REST vers un récepteur tabulaire, consultez Mappage de schéma.
Contenu connexe
Pour obtenir la liste des magasins de données pris en charge en tant que sources et récepteurs par l’activité de copie dans Azure Data Factory, consultez Magasins de données et formats pris en charge.