Optimisation des transformations
Utilisez les stratégies suivantes pour optimiser les performances des transformations dans le flux de données de mappage dans les pipelines Azure Data Factory et Azure Synapse Analytics.
Optimisation des transformations Joins, Exists et Lookups
Diffusion
Dans les transformations Joins, Exists et Lookups, si un ou les deux flux de données sont suffisamment petits pour tenir dans la mémoire de nœud worker, vous pouvez optimiser les performances en activant la Diffusion. Un diffusion a lieu quand vous envoyez de petites trames de données à tous les nœuds du cluster. Cela permet au moteur Spark d’effectuer une jointure sans remanier les données dans le grand flux. Par défaut, le moteur Spark détermine automatiquement s’il faut ou non diffuser un côté d’une jointure. Si vous êtes familiarisé avec vos données entrantes et savez qu’un flux est plus petit que l’autre, vous pouvez sélectionner une diffusion Fixe. Une diffusion fixe force Spark à diffuser le flux sélectionné.
Si la taille des données diffusées est trop importante pour le nœud Spark, il se peut que vous rencontriez une erreur de mémoire insuffisante. Pour éviter les erreurs de mémoire insuffisante, utilisez des clusters à mémoire optimisée. Si vous rencontrez des délais d’expiration de diffusion au cours d’exécutions de flux de données, vous pouvez désactiver l’optimisation de la diffusion. Toutefois, cela se traduit par des flux de données plus lents.
Lorsque vous utilisez des sources de données dont la requête peut prendre plus de temps, comme les requêtes de base de données volumineuses, il est recommandé de désactiver la diffusion pour les jointures. La source avec des temps de requête longs peut entraîner des délais d’attente Spark lorsque le cluster tente de diffuser des nœuds de calcul. La désactivation de la diffusion est également conseillée lorsque vous avez un flux dans votre flux de données qui regroupe des valeurs à utiliser ultérieurement dans une transformation de recherche. Ce modèle peut troubler l’optimiseur Spark et provoquer des délais d’attente.
Jointures croisées
Si vous utilisez des valeurs littérales dans vos conditions de jointure ou si vous avez plusieurs correspondances des deux côtés d’une jointure, Spark exécute la jointure comme une jointure croisée. Une jointure croisée est un produit cartésien complet qui filtre les valeurs jointes. Cela est plus lent que les autres types de jointures. Vérifiez que vous disposez de références de colonnes des deux côtés de vos conditions de jointure pour éviter l’impact sur les performances.
Tri avant les jointures
Contrairement à la jointure de fusion dans les outils tels que SSIS, la transformation de jointure n’est pas une opération de jointure de fusion obligatoire. Les clés de jointure ne nécessitent pas de tri avant la transformation. L’utilisation de transformations de Tri dans les flux de données de mappage n’est pas recommandée.
Performances de la transformation de fenêtre
La transformation de fenêtre dans les flux de données de mappage partitionne vos données par valeur dans les colonnes que vous sélectionnez pour la clause over() dans les paramètres de transformation. Il existe de nombreuses fonctions d’analyse et d’agrégation très populaires qui sont exposées dans la transformation Windows. Toutefois, si votre cas d’usage consiste à générer une fenêtre sur l’ensemble de votre jeu de données pour le classement rank() ou le numéro de ligne rowNumber(), il est recommandé d’utiliser à la place la transformation de classement (Rank) et la transformation de clé de substitution (Surrogate Key). Ces transformations sont plus efficaces que les opérations sur des jeux de données complets utilisant ces fonctions.
Repartitionnement de données asymétriques
Certaines transformations, telles que des jointures et des agrégats, remanient vos partitions de données et peuvent entraîner une asymétrie des données. Une telle asymétrie a pour effet que les données ne sont pas réparties uniformément entre les partitions. Une asymétrie importante des données peut entraîner un ralentissement des transformations en aval et des écritures dans le récepteur. Vous pouvez vérifier l’asymétrie de vos données à tout moment pendant l’exécution d’un flux de données en cliquant sur la transformation dans l’affichage de la surveillance.
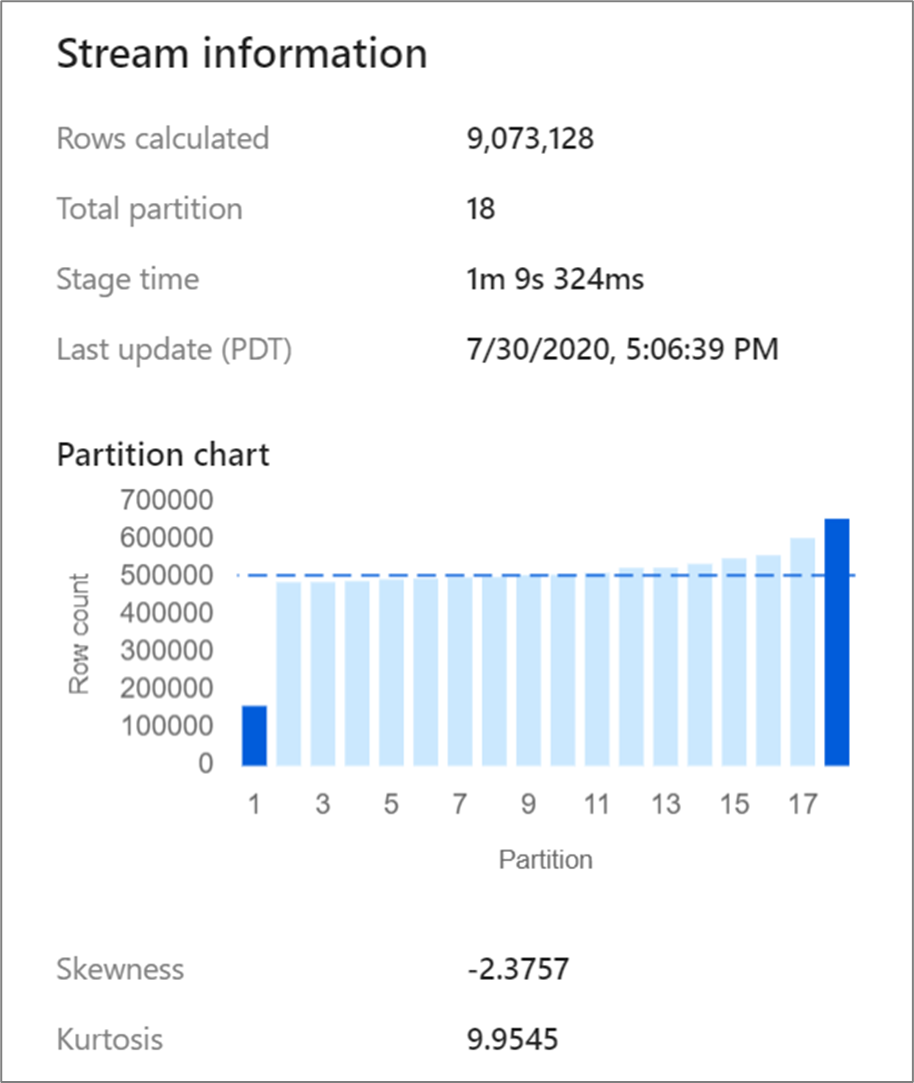
L’affichage de la surveillance montre comment les données sont réparties sur chaque partition, ainsi que deux métriques, l’asymétrie et le kurtosis. L’asymétrie est une mesure de l’asymétrie des données. Elle peut avoir une valeur positive, nulle, négative ou indéfinie. Une asymétrie négative signifie que la queue gauche est plus longue que la droite. Le kurtosis mesure sur l’importance de la queue. Des valeurs de kurtosis élevées ne sont pas souhaitables. Les plages idéales d’asymétrie sont comprises entre -3 et +3, et les plages de kurtosis sont inférieures à 10. Un moyen simple d’interpréter ces nombres consiste à examiner le graphique de partition pour voir si la barre 1 est plus grande que le reste.
Si vos données ne sont pas partitionnées uniformément après une transformation, vous pouvez utiliser l’onglet Optimiser pour repartitionner. Le remaniement des données prend du temps et peut ne pas améliorer les performances de votre flux de données.
Conseil
Si vous repartitionnez vos données, mais avez des transformations en aval qui remanient vos données, utilisez un partitionnement de hachage sur une colonne utilisée comme clé de jointure.
Notes
Les transformations à l’intérieur de votre flux de données (à l’exception de la transformation de récepteur) ne modifient pas le partitionnement de fichiers et de dossiers des données au repos. Partitionnement dans chaque répartition des données de transformation à l’intérieur des trames de données du cluster Spark serverless temporaire que ADF gère pour chacune de vos exécutions de flux de données.
Contenu connexe
- Vue d’ensemble des performances de flux de données
- Optimisation des sources
- Optimisation des récepteurs
- Utilisation des flux de données dans des pipelines
Consultez d’autres articles sur les flux de données consacrés aux performances :