Résolution des problèmes d’échec de répartition lorsque vous déployez des Azure Cloud Services (classique) dans Azure
Important
Cloud Services (classique) est désormais déconseillé pour tous les clients depuis le 1er septembre 2024. Depuis octobre 2024, tous les déploiements en cours d’exécution ont été arrêtés par Microsoft et les données ont été définitivement perdues. Les nouveaux déploiements doivent utiliser le nouveau modèle de déploiement basé sur Azure Resource Manager Azure Cloud Services (support étendu) .
Résumé
Lorsque vous déployez des instances sur un service cloud ou ajoutez de nouvelles instances de rôle Web ou de rôle de travail, Microsoft Azure alloue des ressources de calcul. Vous pouvez parfois recevoir des erreurs lorsque vous effectuez ces opérations avant même d’avoir atteint les limites de votre abonnement Azure. Cet article explique les causes de certains échecs d’allocation courants et propose des solutions possibles. Les informations peuvent également être utiles dans le cadre de la planification du déploiement de vos services.
Si le problème que vous rencontrez avec Azure n’est pas traité dans cet article, parcourez les forums Azure sur Microsoft Q&A et Stack Overflow. Vous pouvez publier votre problème sur ces forums ou @AzureSupport sur Twitter. Vous pouvez également envoyer une demande de support Azure. Pour envoyer une demande de support sur la page Prise en charge Azure, sélectionnez Obtenir de l’aide.
Fonctionne de l’allocation en arrière-plan
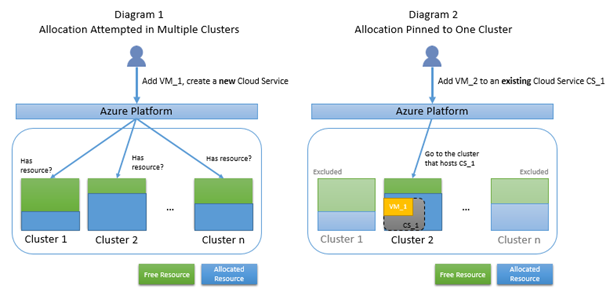
Les serveurs des centres de données Azure sont partitionnés en clusters. Une nouvelle demande d'allocation de service cloud est tentée dans plusieurs clusters. Lorsque la première instance est déployée sur un service cloud (intermédiaire ou de production), ce service cloud est épinglé sur un cluster. Les déploiements ultérieurs du service cloud s'effectueront dans le même cluster. Dans cet article, nous aborderons l’état « épinglé à un cluster ». Le diagramme suivant illustre le cas d’une allocation normale, qui est tentée dans plusieurs clusters. Le deuxième diagramme illustre le cas d’une allocation épinglée au cluster 2, car c’est là que le service cloud existant CS_1 est hébergé.
Raisons de l’échec d’une allocation
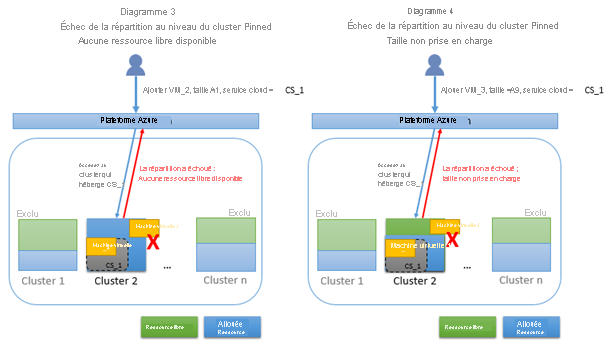
Lorsqu'une demande d'allocation est épinglée à un cluster, il y a plus de risques de ne pas trouver de ressources disponibles puisque le pool de ressources disponibles est limité à un cluster. En outre, si votre demande d’allocation est épinglée à un cluster, mais que le cluster ne prend pas en charge le type de ressource que vous avez demandé, votre requête échoue même si le cluster dispose d’une ressource gratuite. Le diagramme suivant illustre le cas d’une allocation épinglée qui se solde par un échec, car le seul cluster candidat ne comporte pas de ressources disponibles. Le diagramme 4 illustre le cas de figure où une allocation épinglée se solde par un échec parce que le seul cluster candidat ne prend pas en charge la taille de machine virtuelle demandée, bien qu'il puisse libérer des ressources.
Résolution des problèmes d'échec d'allocation pour les services cloud
Message d’erreur
Dans le portail Azure, accédez à votre service cloud puis, dans la barre latérale, sélectionnez Journaux des opérations (classique) pour afficher les journaux.
Consultez les autres solutions pour les exceptions ci-dessous :
| Type d’exception | Message d’erreur | Solution |
|---|---|---|
| FabricInternalServerError | L’opération a échoué avec le code d’erreur « InternalError » et le message d’erreur « Le serveur a rencontré une erreur interne. Réessayez la requête. | Résoudre les problèmes FabricInternalServerError |
| ServiceAllocationFailure | L’opération a échoué avec le code d’erreur « InternalError » et le message d’erreur « Le serveur a rencontré une erreur interne. Réessayez la requête. | Résoudre les problèmes ServiceAllocationFailure |
| LocationNotFoundForRoleSize | L’opération « {Operation ID} » a échoué : « Le niveau de machine virtuelle demandé n’est pas disponible actuellement dans la région ({Region ID}) pour cet abonnement. Essayez un autre niveau ou effectuez le déploiement à un autre emplacement. |
Résoudre les problèmes LocationNotFoundForRoleSize |
| ConstrainedAllocationFailed | L’opération Azure « {Operation ID} » a échoué. Code : Compute.ConstrainedAllocationFailed. Détails : L’allocation a échoué. Impossible de satisfaire aux contraintes spécifiées dans la demande. Le nouveau déploiement de service demandé est lié à un groupe d’affinités ou cible un réseau virtuel, ou un déploiement existant se trouve sous ce service hébergé. Toutes ces conditions réduisent le nouveau déploiement à certaines ressources Azure spécifiques. Veuillez réessayer ultérieurement, ou bien essayez de réduire la taille de la machine virtuelle ou le nombre d’instances de rôle. Vous pouvez aussi supprimer les contraintes ou essayer de déployer dans une autre région, si cela est possible. |
Résoudre les problèmes ConstrainedAllocationFailed |
| OverConstrainedAllocationRequest | La taille de la machine virtuelle (ou la combinaison de tailles de machines virtuelles) demandée par ce déploiement ne peut pas être fournie en raison des contraintes de la demande de déploiement. Si possible, essayez d’assouplir les contraintes telles que les liaisons de réseau virtuel, de déployer vers un service hébergé sans aucun autre déploiement et vers un autre groupe d’affinités ou sans groupe d’affinités, ou essayez de déployer vers une autre région. | Résoudre les problèmes OverconstrainedAllocationRequest |
Exemple de message d’erreur :
« L’opération Azure » {ID d’opération} a échoué. Code : Compute.ConstrainedAllocationFailed. Détails : L’allocation a échoué. Impossible de satisfaire aux contraintes spécifiées dans la demande. Le nouveau déploiement de service demandé est lié à un groupe d’affinités ou cible un réseau virtuel, ou un déploiement existant se trouve sous ce service hébergé. Toutes ces conditions réduisent le nouveau déploiement à certaines ressources Azure spécifiques. Veuillez réessayer ultérieurement, ou bien essayez de réduire la taille de la machine virtuelle ou le nombre d’instances de rôle. Vous pouvez aussi éventuellement supprimer les contraintes mentionnées précédemment ou essayer de déployer dans une autre région. »
Problèmes courants
Voici les scénarios d'allocation courants qui entraînent l'épinglage d'une demande d'allocation à un seul cluster.
- Déploiement sur un emplacement intermédiaire : si un service cloud est déployé dans l'un des deux emplacements, l'ensemble du service cloud est épinglé à un cluster spécifique. Par conséquent, s'il existe déjà un déploiement dans l'emplacement de production, un nouveau déploiement intermédiaire ne peut être affecté que dans le même cluster que l'emplacement de production. Si le cluster est presque plein, la demande peut échouer.
- Mise à l'échelle : l'ajout de nouvelles instances à un service cloud existant doit être alloué au même cluster. Les demandes de mise à l'échelle minime peuvent généralement être allouées, mais pas toujours. Si le cluster est presque plein, la demande peut échouer.
- Groupe d’afffinité - L’infrastructure de tout cluster de cette région peut allouer un nouveau déploiement à un service cloud vide, sauf si le service cloud est épinglé à un groupe d’affinité. Les déploiements tentent d’utiliser le même groupe d’affinités sur le même cluster. Si le cluster est presque plein, la demande peut échouer.
- Réseau virtuel de groupe d'affinités - Des réseaux virtuels plus anciens ont été liés à des groupes d'affinités plutôt qu'à des régions ; et des services cloud dans ces réseaux virtuels seraient épinglés au cluster du groupe d'affinités. Des déploiements vers ce type de réseau virtuel seront tentés sur le cluster épinglé. Si le cluster est presque plein, la demande peut échouer.
Solutions
Redéployer vers un service cloud : cette solution est la plus susceptible de réussir car elle permet à la plateforme de choisir parmi tous les clusters de cette région.
- Déployez la charge de travail vers un nouveau service cloud
- Mettez à jour l'enregistrement CNAME ou A pour faire pointer le trafic vers le nouveau service cloud
- Une fois le trafic de l'ancien site nul, vous pouvez supprimer l'ancien service cloud. Cette solution ne devrait pas entraîner de temps d'arrêt.
Supprimez à la fois les emplacements de production et de mise en lots : cette solution conserve votre nom DNS (Domain Name System) existant, mais provoque un temps d’arrêt pour votre application.
- Supprimez les emplacements de production et intermédiaire d'un service cloud de sorte que le service cloud soit vide, puis
- Créez un nouveau déploiement dans le service cloud. Cette solution réessaie d’obtenir l’allocation sur tous les clusters de la région. Vérifiez que le service cloud n'est pas lié à un groupe d'affinités.
Adresse IP réservée - Cette solution conserve votre adresse IP existante, mais provoque un temps d’arrêt pour votre application.
Créer une IP réservée pour votre déploiement à l’aide de PowerShell
New-AzureReservedIP -ReservedIPName {new reserved IP name} -Location {location} -ServiceName {existing service name}Suivez la solution 2 mentionnée plus haut, en veillant à spécifier la nouvelle adresse IP réservée dans le CSCFG du service.
Supprimer le groupe d'affinités pour les nouveaux déploiements : les groupes d'affinités ne sont plus recommandés. Suivez les étapes de la solution 1 ci-dessus pour déployer un nouveau service cloud. Vérifiez que le service cloud n'est pas un groupe d'affinités.
Convertir en réseau virtuel régional - consultez Comment migrer des groupes d'affinités vers un réseau virtuel régional (VNet).