Métriques de code - Complexité cyclomatique
Lorsque vous utilisez des métriques de code, l’un des éléments les moins compris semble être une complexité cyclomatique. Essentiellement, avec la complexité cyclomatique, les nombres plus élevés sont mauvais et les nombres inférieurs sont bons. Vous pouvez utiliser la complexité cyclomatique pour avoir une idée de la façon dont le code donné peut être difficile à tester, gérer ou résoudre les problèmes, ainsi qu’une indication de la probabilité que le code produise des erreurs. À un niveau élevé, nous déterminons la valeur de la complexité cyclomatique en comptant le nombre de décisions prises dans votre code source. Dans cet article, vous allez commencer par un exemple simple de complexité cyclomatique pour comprendre rapidement le concept, puis examiner quelques informations supplémentaires sur l’utilisation réelle et les limites suggérées. Enfin, il y a une section de citations qui peut être utilisée pour approfondir ce sujet.
Exemple
La complexité cyclomatique est définie comme la mesure de la « quantité de logique de décision dans une fonction de code source » NIST235. Autrement dit, plus les décisions doivent être prises dans le code, plus il est complexe.
Voyons-le en action. Créez une application console et calculez immédiatement vos métriques de code en accédant à Analyser > Calculer les métriques de code pour la solution.
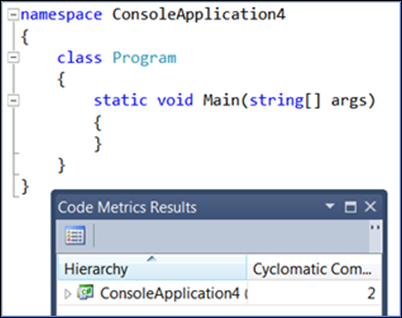
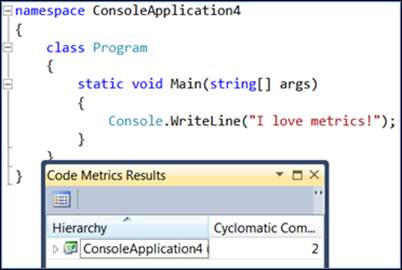
Notez que la complexité cyclomatique est à 2 (la valeur la plus basse possible). Si vous ajoutez du code non décisionnel, notez que la complexité ne change pas :
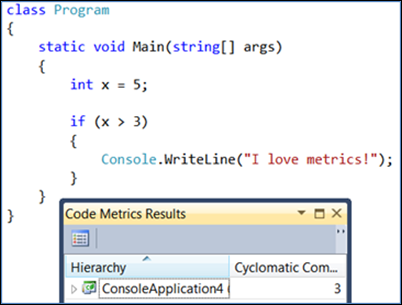
Si vous ajoutez une décision, la valeur de complexité cyclomatique augmente de un.
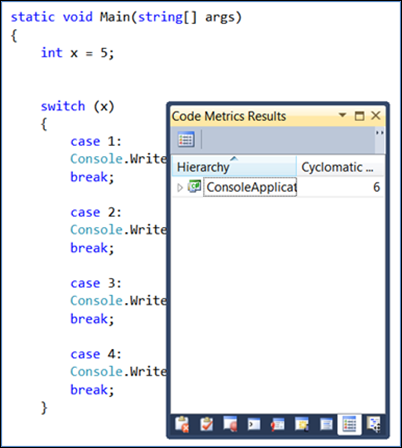
Lorsque vous remplacez l’instruction if par une instruction switch avec quatre décisions à prendre, elle passe des deux à six d’origine :
Examinons une base de code (hypothétique) plus grande.
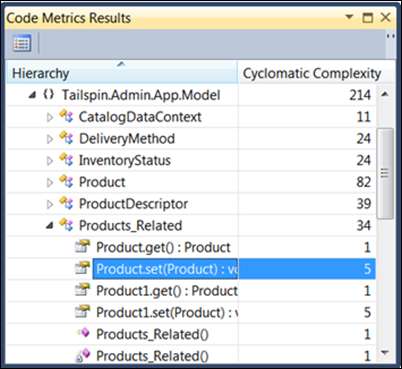
Notez que la plupart des éléments, à mesure que vous explorez dans la classe Products_Related, ont une valeur d’une, mais deux d’entre eux ont une complexité de cinq. En soi, cette différence peut ne pas être un gros problème, mais étant donné que la plupart des autres membres ont un membre dans la même classe, vous devez certainement regarder plus près ces deux éléments et voir ce qui se trouve dans eux. Vous pouvez examiner de plus près l’élément en cliquant avec le bouton droit sur l’élément et en choisissant Accéder au code source dans le menu contextuel. Observez de plus près Product.set(Product):
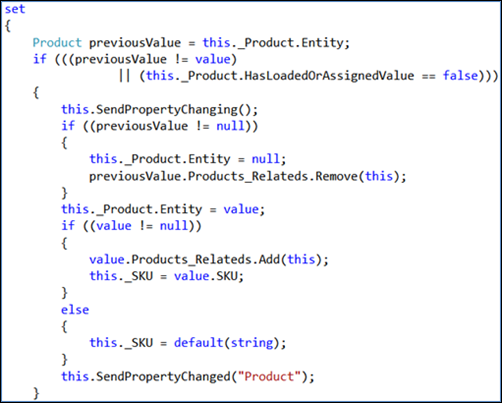
Le nombre d’instructions if explique pourquoi la complexité cyclomatique a la valeur cinq. À ce stade, vous pouvez décider que ce résultat est un niveau de complexité acceptable, ou vous pouvez refactoriser pour réduire la complexité.
Le numéro magique
Comme avec de nombreuses métriques dans ce secteur, il n’existe aucune limite de complexité cyclomatique exacte qui correspond à toutes les organisations. Toutefois, NIST235 indique qu’une limite de 10 est un bon point de départ :
« Le nombre précis à utiliser comme limite, cependant, reste quelque peu controversé. La limite initiale de 10 proposée par McCabe a une preuve de soutien significative, mais les limites aussi élevées que 15 ont été utilisées avec succès. Les limites supérieures à 10 doivent être réservées aux projets qui présentent plusieurs avantages opérationnels par rapport aux projets classiques, par exemple le personnel expérimenté, la conception formelle, un langage de programmation moderne, la programmation structurée, les procédures pas à pas de code et un plan de test complet. En d’autres termes, une organisation peut choisir une limite de complexité supérieure à 10, mais seulement si elle sait ce qu’elle fait et est prête à consacrer les efforts de test supplémentaires requis par des modules plus complexes." NIST235
Complexité cyclomatique et numéros de ligne
Regarder simplement le nombre de lignes de code est, au mieux, un prédicteur très vaste de la qualité du code. Il y a une vérité de base à l’idée que plus les lignes de code dans une fonction, plus il est probable qu’il y ait des erreurs. Toutefois, lorsque vous combinez la complexité cyclomatique avec des lignes de code, vous avez une image beaucoup plus claire du risque d’erreurs.
Comme décrit par le Software Assurance Technology Center (SATC) à la NASA :
La SATC a constaté que l’évaluation la plus efficace est une combinaison de la taille et de la complexité cyclomatique. Les modules avec une complexité élevée et une grande taille ont tendance à avoir la fiabilité la plus faible. Les modules avec une taille faible et une complexité élevée sont également un risque de fiabilité, parce qu'ils ont tendance à être du code très concis, ce qui est difficile à modifier. » SATC
Analyse du code
L’analyse du code comprend une catégorie de règles de maintenance. Pour plus d’informations, consultez règles de maintenance. Lors de l’utilisation de l’analyse du code hérité, l’ensemble de règles de recommandations de conception étendue contient une zone de facilité de maintenance :
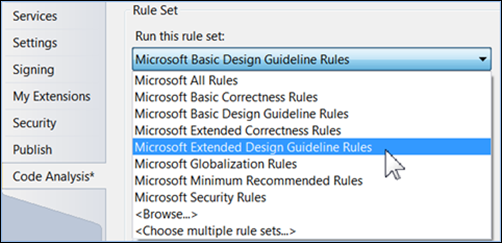
Dans la zone de maintenabilité, il existe une règle de complexité :

Cette règle émet un avertissement lorsque la complexité cyclomatique atteint 25, de sorte qu’elle peut vous aider à éviter une complexité excessive. Pour en savoir plus sur la règle, consultez CA1502
Tout assembler
La ligne de fond est qu’un nombre élevé de complexité signifie une plus grande probabilité d’erreurs avec un temps accru de maintenance et de résolution des problèmes. Regardez de plus près les fonctions qui ont une complexité élevée et déterminez si elles doivent être refactorisées pour les rendre moins complexes.
Références
MCCABE5
McCabe, T. et A. Watson (1994), Complexité logicielle (CrossTalk : The Journal of Defense Software Engineering).
NIST235
Watson, A. H., & McCabe, T. J. (1996). Tests structurés : méthodologie de test utilisant la métrique de complexité cyclomatique (publication spéciale NIST 500-235). Récupéré le 14 mai 2011 à partir du site web mcCabe Software : http://www.mccabe.com/pdf/mccabe-nist235r.pdf
SATC
Rosenberg, L., Hammer, T., Shaw, J. (1998). Métriques logicielles et fiabilité (Procédures du Symposium international IEEE sur l’ingénierie de fiabilité des logiciels). Récupéré le 14 mai 2011 à partir du site web de Penn State University : https://citeseerx.ist.psu.edu/pdf/31e3f5732a7af3aecd364b6cc2a85d9495b5c159