Qu’est-ce qu’Apache Spark™ dans HDInsight sur AKS ? (Préversion)
Important
Azure HDInsight sur AKS a été mis hors service le 31 janvier 2025. Pour en savoir plus, consultez cette annonce .
Vous devez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent pour éviter l’arrêt brusque de vos charges de travail.
Important
Cette fonctionnalité est actuellement en préversion. Les Conditions d’utilisation supplémentaires pour les préversions Microsoft Azure incluent des termes juridiques supplémentaires qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou qui ne sont pas encore publiées en disponibilité générale. Pour obtenir des informations sur cet aperçu spécifique, consultez les informations sur Azure HDInsight sur AKS en version préliminaire. Pour des questions ou des suggestions de fonctionnalités, envoyez une demande sur AskHDInsight avec les détails et suivez-nous pour plus de mises à jour sur Communauté Azure HDInsight.
Apache Spark™ est une infrastructure de traitement parallèle qui prend en charge le traitement en mémoire pour améliorer les performances des applications analytiques Big Data.
Apache Spark™ fournit des primitives pour le calcul des clusters en mémoire. Un travail Spark peut charger et mettre en cache des données en mémoire et les interroger à plusieurs reprises. L’informatique en mémoire est plus rapide que les applications basées sur disque, telles que Hadoop, qui partagent des données via le système de fichiers distribué Hadoop (HDFS). Apache Spark permet l’intégration avec les langages de programmation Scala et Python pour vous permettre de manipuler des jeux de données distribués comme des collections locales. Il n’est pas nécessaire de structurer tous les éléments comme des opérations map et reduce.
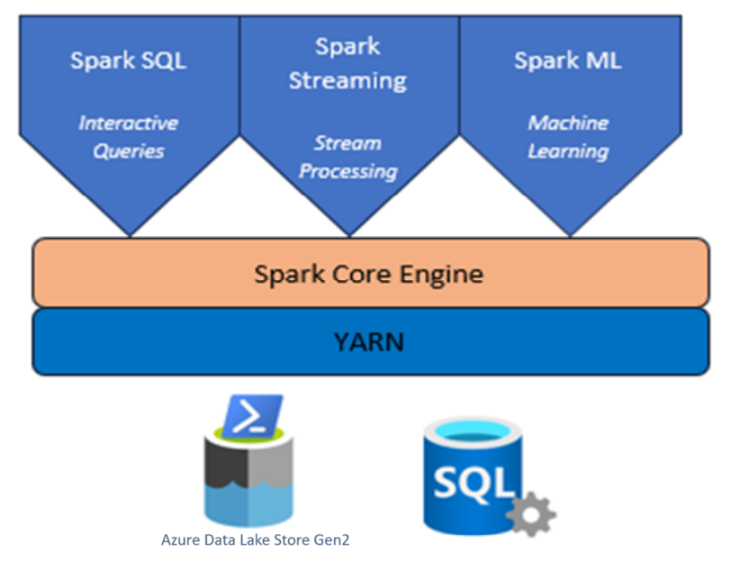
Cluster Apache Spark avec HDInsight sur AKS
Azure HDInsight est un service d’analytique open source managé, complet et à spectre complet pour les entreprises.
Apache Spark™ dans Azure HDInsight sur AKS est le service Spark managé dans Microsoft Azure. Avec Apache Spark dans Azure HDInsight sur AKS, vous pouvez stocker et traiter vos données dans Azure. Les clusters Spark dans HDInsight sont compatibles avec Azure Data Lake Storage Gen2, ce qui vous permet d’appliquer le traitement Spark sur vos magasins de données existants.
L’infrastructure Apache Spark pour HDInsight sur AKS permet d’analyser rapidement les données et le calcul des clusters à l’aide du traitement en mémoire. Jupyter Notebook vous permet d’interagir avec vos données, de combiner du code avec du texte markdown et d’effectuer des visualisations simples.
Apache Spark dans HDInsight sur AKS composé de plusieurs composants sous forme de pods.
Contrôleurs de cluster
Les contrôleurs de cluster sont responsables de l’installation et de la gestion du service respectif. Différents contrôleurs sont installés et gérés dans un cluster Spark.
Composants du service Apache Spark
service Zookeeper : un cluster Zookeeper à trois nœuds, sert de coordinateur distribué ou de stockage haute disponibilité pour d’autres services.
service Yarn : cluster Hadoop Yarn, les tâches Spark seront planifiées dans le cluster comme applications dans Yarn.
Interfaces clientes : les clusters Apache Spark dans HDInsight sur AKS fournissent différentes interfaces clientes. Les services Livy Server, Jupyter Notebook et Spark History Server fournissent des services Spark aux utilisateurs d'HDInsight sur AKS.
Référence
- Apache, Apache Spark, Spark et les noms de projets open-source associés sont des marques déposées de la Apache Software Foundation (ASF).