Cluster en mode application Apache Flink sur HDInsight sur AKS
Important
Azure HDInsight sur AKS a été mis hors service le 31 janvier 2025. En savoir plus avec cette annonce.
Vous devez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent pour éviter l’arrêt brusque de vos charges de travail.
Important
Cette fonctionnalité est actuellement en préversion. Les Conditions d’utilisation supplémentaires pour les préversions Microsoft Azure incluent des termes juridiques supplémentaires qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou qui ne sont pas encore publiées en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les informations en préversion sur Azure HDInsight sur AKS . Pour des questions ou des suggestions de fonctionnalités, envoyez une demande sur AskHDInsight avec les détails et suivez-nous pour plus de mises à jour sur Communauté Azure HDInsight.
HDInsight sur AKS propose désormais un cluster en mode Application Flink. Ce cluster vous permet de gérer le cycle de vie du mode application Flink du cluster à l’aide du portail Azure avec une interface facile à utiliser et des API Rest Azure Resource Management. Les clusters en mode application sont conçus pour prendre en charge des travaux volumineux et longs avec des ressources dédiées et gérer des tâches de traitement de données gourmandes en ressources ou étendues.
Ce mode de déploiement vous permet d’affecter des ressources dédiées pour des applications Flink spécifiques, en vous assurant qu’elles disposent d’une puissance de calcul et d’une mémoire suffisantes pour gérer efficacement les charges de travail volumineuses.

Avantages
Déploiement de cluster simplifié avec le fichier jar de travail.
API REST conviviale : HDInsight sur AKS fournit des API REST ARM conviviales pour gérer l’opération de travail en mode application telle que Update, Savepoint, Cancel, Delete.
Facile à gérer les mises à jour des travaux et la gestion de l’état : l’intégration native du portail Azure offre une expérience sans problème pour mettre à jour les travaux et les restaurer à leur dernier état enregistré (savepoint). Cette fonctionnalité garantit la continuité et l’intégrité des données tout au long du cycle de vie du travail.
Automatisez les travaux Flink à l’aide d’Azure Pipelines ou d’autres outils CI/CD : à l’aide de HDInsight sur AKS, les utilisateurs Flink ont accès à l’API REST ARM conviviale, vous pouvez intégrer en toute transparence les opérations de travail Flink à votre pipeline Azure ou à d’autres outils CI/CD.
Fonctionnalités clés
Arrêter et démarrer des travaux avec des points de sauvegarde: Les utilisateurs peuvent arrêter et démarrer facilement leurs travaux Flink AppMode à partir de leur état précédent (Savepoint). Les points d'enregistrement garantissent que la progression du travail est conservée, permettant une reprise sans interruption.
mises à jour du job: l'utilisateur peut mettre à jour le job AppMode en cours après la mise à jour du fichier JAR sur le compte de stockage. Cette mise à jour prend automatiquement le point de sauvegarde et démarre le travail AppMode avec un nouveau fichier JAR.
mises à jour sans état: l’exécution d’un nouveau redémarrage pour un travail AppMode est simplifiée par le biais de mises à jour sans état. Cette fonctionnalité permet aux utilisateurs de lancer un redémarrage propre à l’aide du fichier jar de travail mis à jour.
Savepoint Management: à tout moment donné, les utilisateurs peuvent créer des points d’enregistrement pour leurs travaux en cours d’exécution. Ces points d’enregistrement peuvent être répertoriés et utilisés pour redémarrer la tâche à partir d’un point de contrôle spécifique si nécessaire.
Annuler: Annule définitivement la tâche.
Supprimer: supprimer le cluster AppMode.
Comment créer un cluster d’applications Flink
Conditions préalables
Remplir les conditions préalables dans les sections suivantes :
Ajoutez un fichier jar de travail dans le compte de stockage.
Avant de configurer un cluster Flink App Mode, plusieurs étapes préparatoires sont requises. L’une de ces étapes implique de placer le fichier JAR du travail en mode application dans le compte de stockage du cluster.
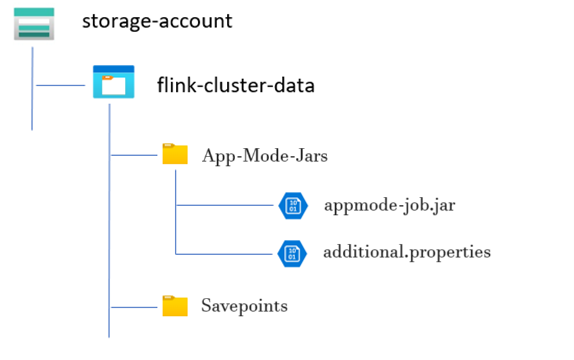
Créez un répertoire pour le fichier JAR de la tâche mode application :
Dans les conteneurs dédiés, créez un répertoire dans lequel vous chargez le fichier JAR du travail en mode Application. Ce répertoire sert d’emplacement pour stocker les fichiers JAR que vous souhaitez inclure dans le chemin de classe du cluster ou du travail Flink.
Répertoire Savepoints (facultatif) :
Si les utilisateurs ont l’intention de prendre des points d’enregistrement pendant l’exécution du travail, créez un répertoire distinct dans le compte de stockage pour stocker ces points d’enregistrement. Ce répertoire utilisé pour stocker les données de point de contrôle et les métadonnées pour les points d’enregistrement.
Exemple de structure de répertoire :

Créer un cluster Flink en mode application
Les clusters AppMode Flink peuvent être créés une fois le déploiement du pool de clusters terminé, passons en revue les étapes en cas de prise en main d’un pool de clusters existant.
Dans le portail Azure, tapez HDInsight cluster pools/HDInsight/HDInsight sur AKS et sélectionnez Azure HDInsight sur les pools de clusters HDInsight sur AKS pour accéder à la page des pools de clusters. Sur la page des pools de clusters HDInsight sur AKS, sélectionnez le pool de clusters dans lequel vous souhaitez créer un nouveau cluster Flink.

Dans la page du pool de clusters spécifique, cliquez sur + Nouveau cluster et fournissez les informations suivantes :
Propriété Description Abonnement Ce champ est renseigné automatiquement avec l’abonnement Azure enregistré pour le Pool de Clusters. Groupe de ressources Ce champ se remplit automatiquement et affiche le groupe de ressources dans le pool de clusters. Région Ce champ remplit automatiquement et affiche la région sélectionnée sur le pool de clusters. Pool de clusters Ce champ remplit automatiquement et affiche le nom du pool de clusters sur lequel le cluster est maintenant créé. Pour créer un cluster dans un autre pool, recherchez le pool de clusters dans le portail, puis cliquez sur + Nouveau cluster. HDInsight sur la version du pool AKS Ce champ remplit automatiquement et affiche la version du pool de clusters sur laquelle le cluster est maintenant créé. HDInsight sur la version AKS Sélectionnez la version mineure ou corrective de HDInsight sur AKS du nouveau cluster. Type de cluster Dans la liste déroulante, sélectionnez Flink. Nom du cluster Entrez le nom du nouveau cluster. Identité gérée attribuée par l’utilisateur Dans la liste déroulante, sélectionnez l’identité managée à utiliser avec le cluster. Si vous êtes propriétaire de l’identité du service managé (MSI) et que le rôle d’opérateur d’identité managée n’est pas sur le cluster, cliquez sur le lien situé sous la zone pour attribuer l’autorisation nécessaire à partir du MSI du pool d’agents AKS. Si le MSI dispose déjà des autorisations appropriées, aucun lien n’est affiché. Consultez les conditions préalables pour les autres attributions de rôles requises pour le MSI. Compte de stockage Dans la liste déroulante, sélectionnez le compte de stockage à associer au cluster Flink et spécifiez le nom du conteneur. L’identité managée est également autorisée à accéder au compte de stockage spécifié, à l’aide du rôle « Propriétaire des données blob de stockage » lors de la création du cluster. Réseau virtuel Réseau virtuel du cluster. Sous-réseau Sous-réseau virtuel du cluster. Activation du catalogue Hive pour Flink SQL :
Propriété Description Utiliser le catalogue Hive Activez cette option pour utiliser un metastore Hive externe. SQL Database pour Hive Dans la liste déroulante, sélectionnez la base de données SQL dans laquelle ajouter des tables hive-metastore. Nom d’utilisateur administrateur SQL Entrez le nom d’utilisateur administrateur du serveur SQL. Ce compte est utilisé par le metastore pour communiquer avec la base de données SQL. Coffre-fort de clés Dans la liste déroulante, sélectionnez le coffre de clés, qui contient un secret avec un mot de passe pour le nom d’utilisateur d’administrateur SQL Server. Vous devez configurer une stratégie d'accès avec toutes les autorisations requises, telles que les autorisations de clé, les autorisations de secrets et les autorisations de certificat pour le MSI, utilisé pour la création du cluster. L’instance MSI a besoin d’un rôle Administrateur Key Vault. Ajoutez les autorisations requises à l’aide d’IAM. Nom du secret de mot de passe SQL Entrez le nom du secret à partir du coffre de clés où le mot de passe de la base de données SQL est stocké. 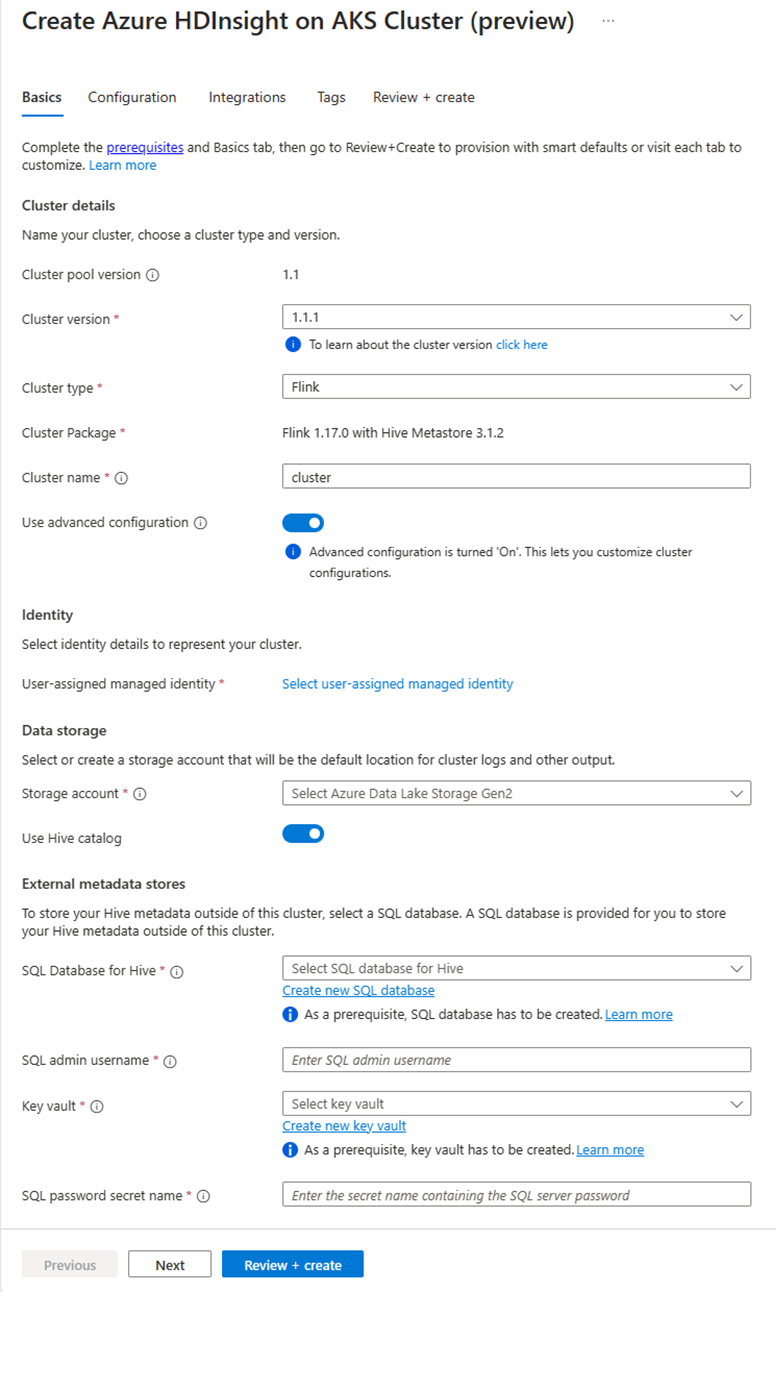
Remarque
Par défaut, nous utilisons le compte de stockage pour le catalogue Hive identique au compte de stockage et au conteneur utilisés lors de la création du cluster.
Sélectionnez Suivant : Configuration pour continuer.
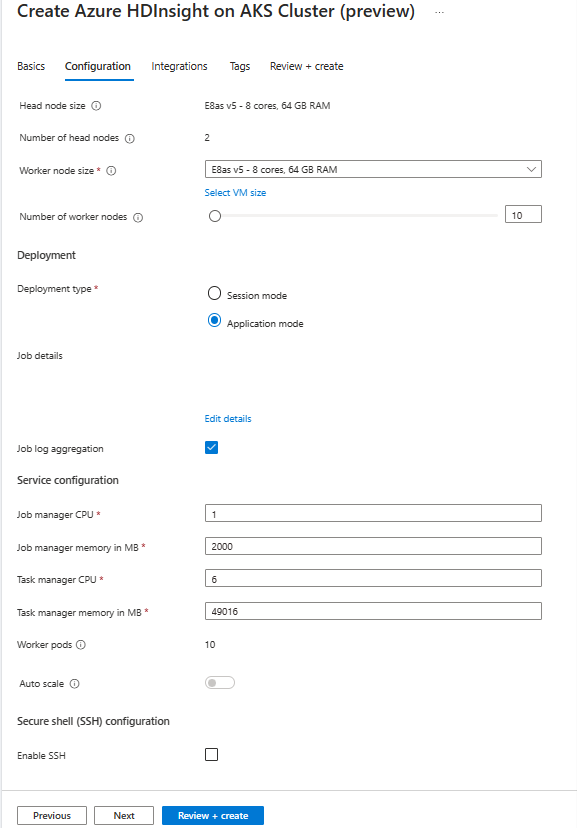
Dans la page Configuration, fournissez les informations suivantes :
Propriété Description Taille du nœud Sélectionnez la taille du nœud à utiliser pour les nœuds Flink, qu'il s'agisse des nœuds principaux ou des nœuds de travail. Nombre de nœuds Sélectionnez le nombre de nœuds pour le cluster Flink ; par défaut, les nœuds principaux sont deux. Le dimensionnement des nœuds de travail permet de déterminer les configurations du gestionnaire de tâches pour Flink. Le gestionnaire de travaux et les serveurs d’historique se trouvent sur les nœuds principaux. Dans la section Déploiement, choisissez le type de déploiement en tant que mode application fournissez les informations suivantes :
Propriété Description Chemin jar Donnez le chemin d’accès ABFS (Stockage) pour votre fichier jar de travail. Par exemple, abfs://flink@teststorage.dfs.core.windows.net/appmode/job.jarClasse Entrée (Facultatif) Classe principale pour votre cluster en mode application. Ex : com.microsoft.testjob Arguments (facultatif) Argument de la classe principale de votre travail. Nom du point de sauvegarde Nom de l’ancien point d’enregistrement, que vous souhaitez utiliser afin de lancer le travail Mode de mise à niveau Sélectionnez l’option De mise à niveau par défaut. Cette option utilisée lorsque la mise à niveau de version majeure se produit pour le cluster. Il existe trois options disponibles. UPDATE : utilisé lorsqu’un utilisateur souhaite récupérer à partir du dernier point de sauvegarde après une mise à niveau. STATELESS_UPDATE : est utilisé lorsqu’un utilisateur veut redémarrer un travail après une mise à niveau. LAST_STATE_UPDATE : Utilisé lorsqu’un utilisateur souhaite récupérer la tâche à partir du dernier point de contrôle après la mise à niveau Configuration du travail Flink Ajoutez une configuration supplémentaire requise pour le travail Flink. Sélectionnez « Agrégation du journal des travaux ». Cochez la case si vous souhaitez charger votre journal de travail dans le stockage distant. Il permet de déboguer les problèmes de travail. L’emplacement par défaut du journal des travaux est « StorageAccount/Container/DeploymentId/logs ». Vous pouvez modifier le répertoire de journal par défaut en configurant « pipeline.remote.log.dir ». L’intervalle par défaut pour la collecte de journaux est de 600 secondes. L’utilisateur peut changer en configurant « pipeline.log.aggregation.interval ».
Dans la section Configuration du service, fournissez les informations suivantes :
Propriété Description Processeur du gestionnaire de tâches Entier. Entrez la taille des processeurs du gestionnaire de tâches (en cœurs). Mémoire du gestionnaire de tâches en Mo Entrez la taille de mémoire du Gestionnaire de tâches en Mo. Min de 1 800 Mo. Processeur du gestionnaire de tâches Entier. Entrez le nombre de processeurs pour le gestionnaire de travaux (en cœurs). Mémoire du gestionnaire de travaux en Mo Entrez la taille de mémoire en Mo. Minimum de 1 800 Mo. Processeur du serveur d’historique Entier. Entrez le nombre de processeurs pour le gestionnaire de travaux (en cœurs). Mémoire du serveur d’historique en Mo Entrez la taille de mémoire en Mo. Minimum de 1 800 Mo. capture d’écran
Cliquez sur Suivant : bouton Intégration pour passer à la page suivante.
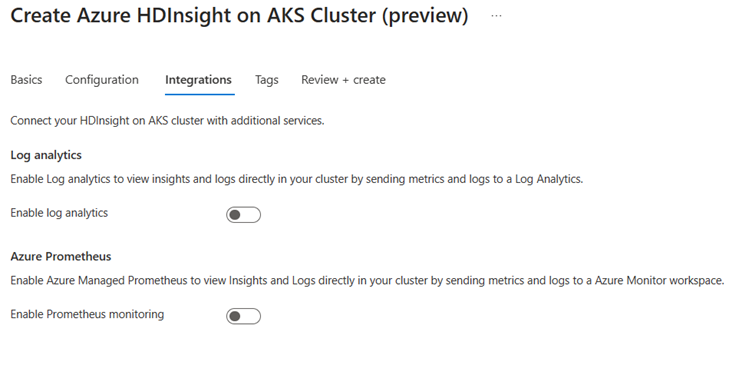
Dans la page Intégration, fournissez les informations suivantes :
Propriété Description Log Analytics Cette fonctionnalité est disponible uniquement si l'espace de travail Log Analytics associé au pool de clusters est activé. Une fois les journaux d'activité activés, ils peuvent être sélectionnés pour la collecte. Azure Prometheus Cette fonctionnalité permet d'afficher les insights et les journaux directement dans votre cluster en envoyant les métriques et les journaux à l’espace de travail Azure Monitor. capture d’écran
Cliquez sur le bouton Suivant : Balises pour passer à la page suivante.
Dans la page Balises, fournissez les informations suivantes :
Propriété Description Nom Optionnel. Entrez un nom tel que HDInsight sur AKS pour identifier facilement toutes les ressources associées à vos ressources de cluster. Valeur Vous pouvez laisser ce champ vide. Ressource Sélectionnez Toutes les ressources sélectionnées. Sélectionnez Suivant : Vérifier + créer pour continuer.
Dans la page Vérifier + créer, recherchez le message Validation réussie en haut de la page, puis cliquez sur Créer.




La page de déploiement en cours affiche la création du cluster. La création du cluster prend 5 à 10 minutes. Une fois le cluster créé, le message « Votre déploiement est terminé » s’affiche. Si vous quittez la page, vous pouvez vérifier l’état actuel de vos notifications.
Gérer le travail d’application à partir du portail
HDInsight AKS permet de gérer les travaux Flink. Vous pouvez relancer un travail ayant échoué. Redémarrez le travail à partir du portail.
Pour exécuter le travail Flink à partir du portail, accédez à :
Portail > HDInsight sur le pool de clusters AKS > Cluster Flink > Paramètres > Travaux Flink.

Arrêt : Arrêter le travail n’a pas besoin de paramètres. L’utilisateur peut arrêter le travail en sélectionnant l’action. Une fois la tâche arrêtée, l’état de la tâche sur le portail doit indiquer ARRÊTÉ.
Démarrer : démarre le travail à partir du point d’enregistrement. Pour démarrer le travail, sélectionnez le travail arrêté et démarrez-le.
Mise à jour : la mise à jour permet de redémarrer les travaux avec le code de travail mis à jour. Les utilisateurs doivent mettre à jour le fichier jar de travail le plus récent dans l’emplacement de stockage et mettre à jour le travail à partir du portail. Cette action arrête le travail avec le point d’enregistrement et recommencez avec le dernier fichier jar.
Mise à jour sans état : La mise à jour sans état est semblable à une mise à jour, mais elle implique une réinitialisation de la tâche avec le code le plus récent. Une fois la tâche mise à jour, l’état de la tâche sur le portail s’affiche comme En cours.
Savepoint : effectuez le savepoint pour le job Flink.
Annuler : mettre fin à la tâche.
Supprimer : supprimer un cluster AppMode.
Afficher les détails de l'emploi : Pour consulter les détails de l'emploi, l'utilisateur peut cliquer sur le nom du poste. Cela fournit des informations sur l'emploi et le résultat de la dernière action.


Pour toute action ayant échoué, cette vue json fournit des exceptions détaillées et des raisons de l’échec.