Détection d’anomalie multivariée
Pour obtenir des informations générales sur la détection d’anomalies multivariées dans Real-Time Intelligence, consultez La détection d'anomalie multivariée dans Microsoft Fabric - Vue d'ensemble. Dans ce tutoriel, vous utilisez des exemples de données pour entraîner un modèle de détection d’anomalie multivariée à l’aide du moteur Spark dans un notebook Python. Vous prédisez ensuite les anomalies en appliquant le modèle entraîné aux nouvelles données à l’aide du moteur Eventhouse. Les premières étapes configurent vos environnements et les étapes suivantes entraînent le modèle et prédisent les anomalies.
Prérequis
- Un espace de travail avec une capacité compatible Microsoft Fabric
- Un rôle Administrateur, Contributeur, ou Membre dans un espace de travail. Ce niveau d’autorisation est nécessaire pour créer des éléments tels qu’un environnement.
- Un eventhouse dans votre espace de travail avec une base de données.
- Téléchargez l’exemple de données à partir du référentiel GitHub
- Téléchargez le notebook à partir du référentiel GitHub
Partie 1 - Activer la disponibilité de OneLake
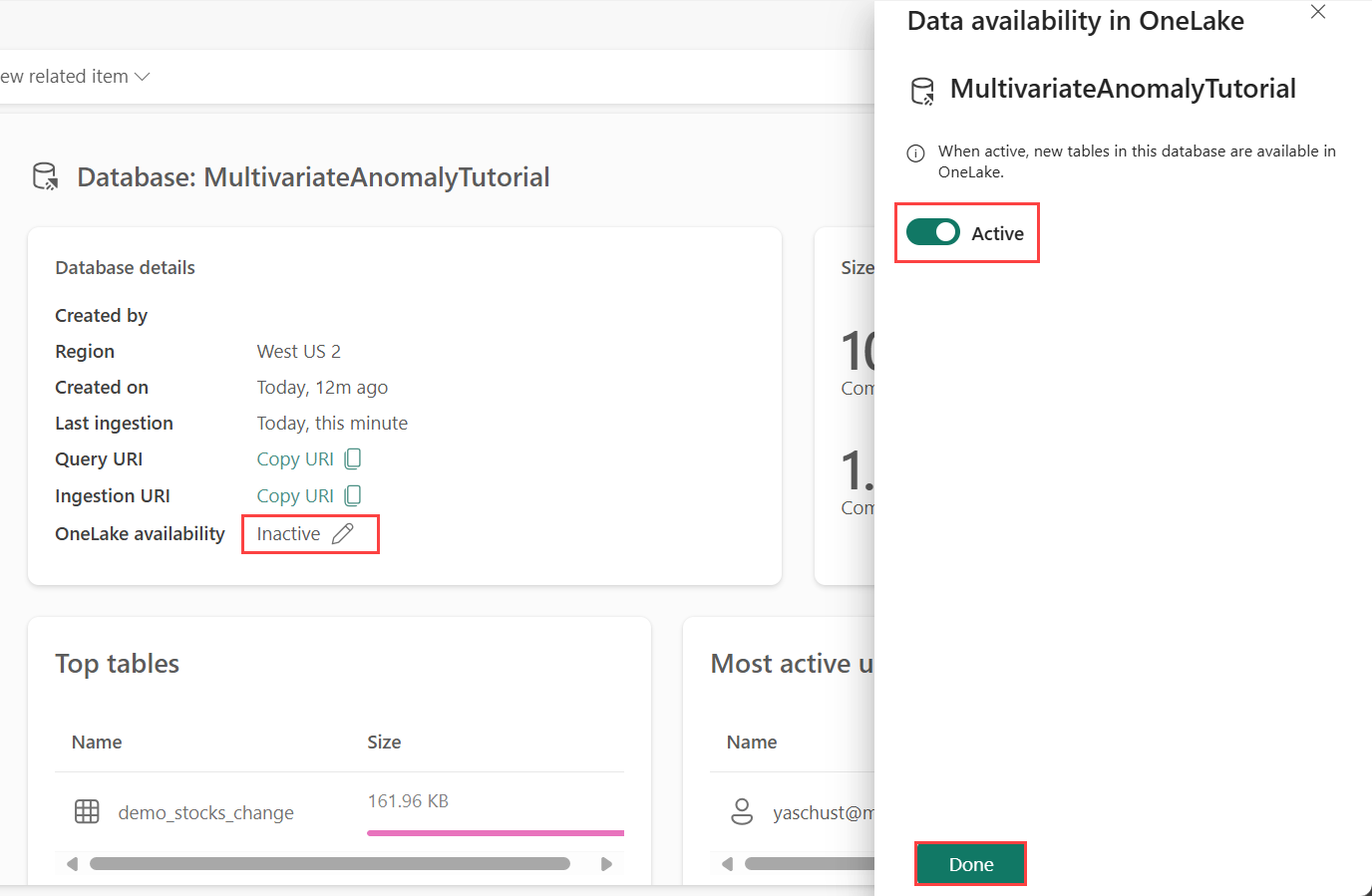
La disponibilité de OneLake doit être activée avant d’obtenir des données dans Eventhouse. Cette étape est importante, car elle permet aux données que vous ingérez de devenir disponibles dans OneLake. Dans une étape ultérieure, vous accédez à ces mêmes données à partir de votre notebook Spark pour entraîner le modèle.
Dans votre espace de travail, sélectionnez l’Eventhouse que vous avez créé dans les composants requis. Choisissez la base de données vers lequel vous souhaitez charger vos données.
Dans le volet Détails de la base de données, basculez le bouton de disponibilité OneLake pour Actif.
Partie 2 - Activer le plug-in Python KQL
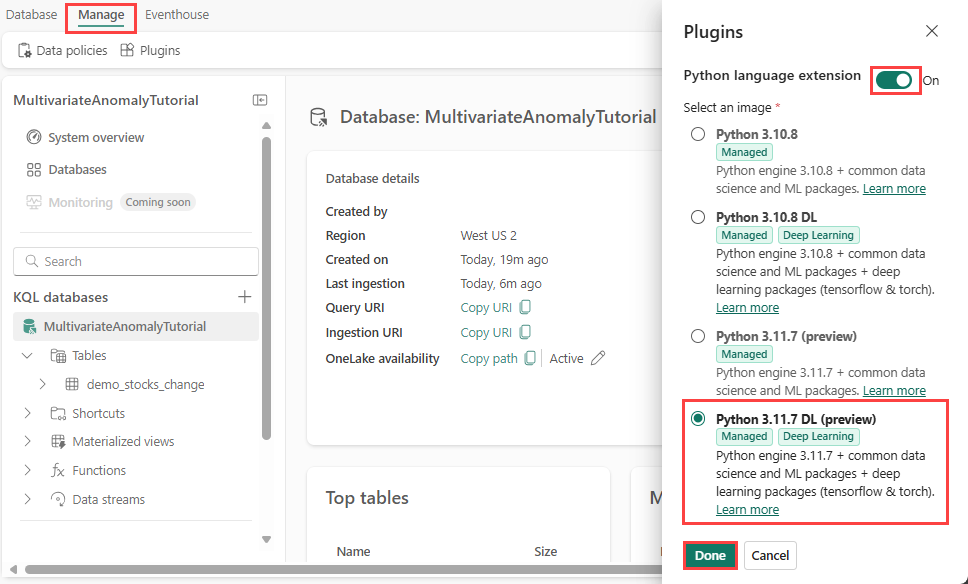
Dans cette étape, vous activez le plug-in Python dans votre Eventhouse. Cette étape est nécessaire pour exécuter le code Python des anomalies prédites dans l’ensemble de requêtes KQL. Il est important de choisir l’image appropriée qui contient le module détecteur d’anomalies de séries chronologiques.
Dans l’écran Eventhouse, sélectionnez Eventhouse>Plugins à partir du ruban.
Dans le volet Plug-ins, basculez l’extension du langage Python sur Activé.
Sélectionnez Python 3.11.7 DL (préversion).
Cliquez sur Terminé.

Partie 3 - Créer un environnement Spark
Dans cette étape, vous créez un environnement Spark pour exécuter le notebook Python qui entraîne le modèle de détection d'anomalie multivariée à l’aide du moteur Spark. Pour plus d’informations sur la création d’environnements, voir Créer et gérer des environnements.
Dans votre espace de travail, sélectionnez + Nouvel élément puis Environnement.
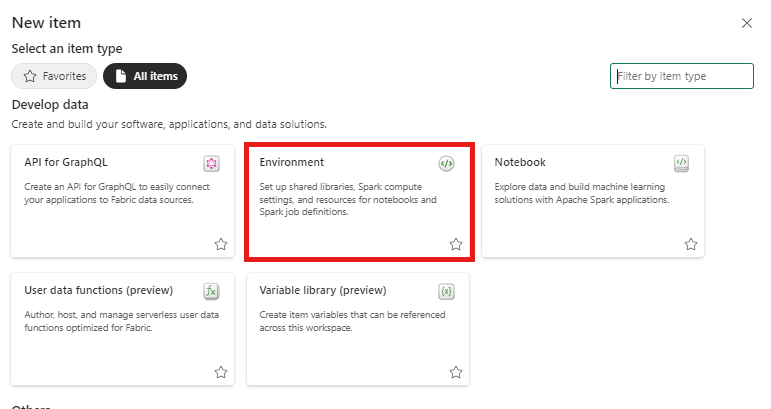
Entrez le nom MVAD_ENV de l’environnement, puis sélectionnez Créer.
Sous l’onglet Accueil de l’environnement, sélectionnez Runtime>1.2 (Spark 3.4, Delta 2.4).
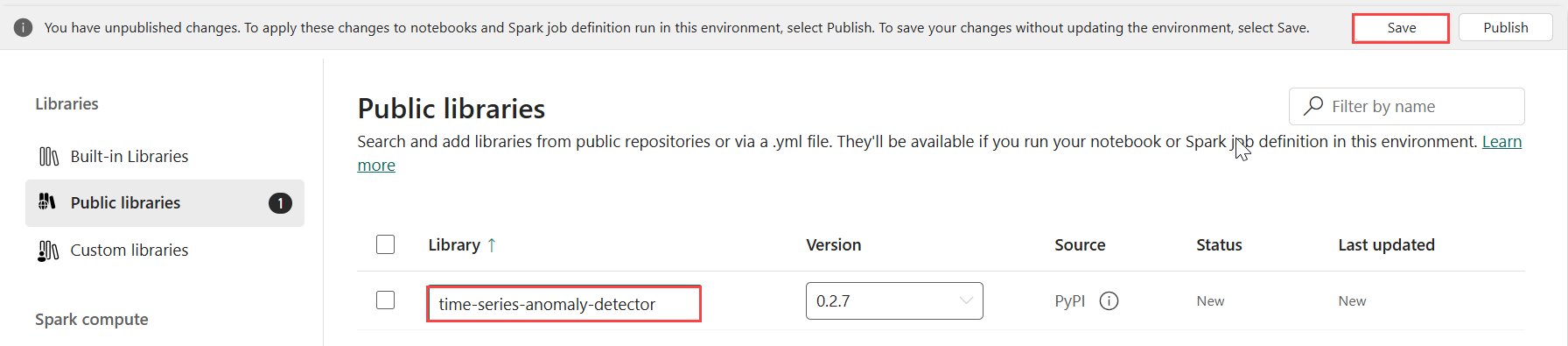
Sous Bibliothèques, sélectionnez Bibliothèques publiques.
Sélectionnez Ajouter à partir de PyPI.
Dans la zone de recherche, entrez time-series-anomaly-detector. La version remplit automatiquement la version la plus récente. Ce tutoriel a été créé à l’aide de la version 0.3.2.
Cliquez sur Enregistrer.
Sélectionnez l’onglet Accueil dans l’environnement.
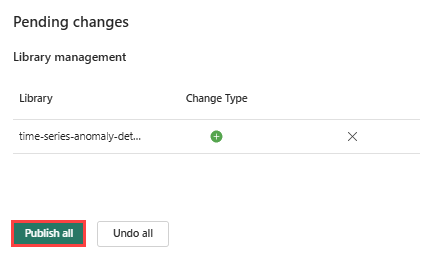
Dans le ruban en haut, cliquez sur l’icône Publier.

Sélectionnez Publier tous. Cette étape peut prendre plusieurs minutes.


Partie 4 - Obtenir des données dans eventhouse
Pointez sur la base de données KQL où vous souhaitez stocker vos données. Sélectionnez le menu Plus [...]>Obtenir les données>Fichier.
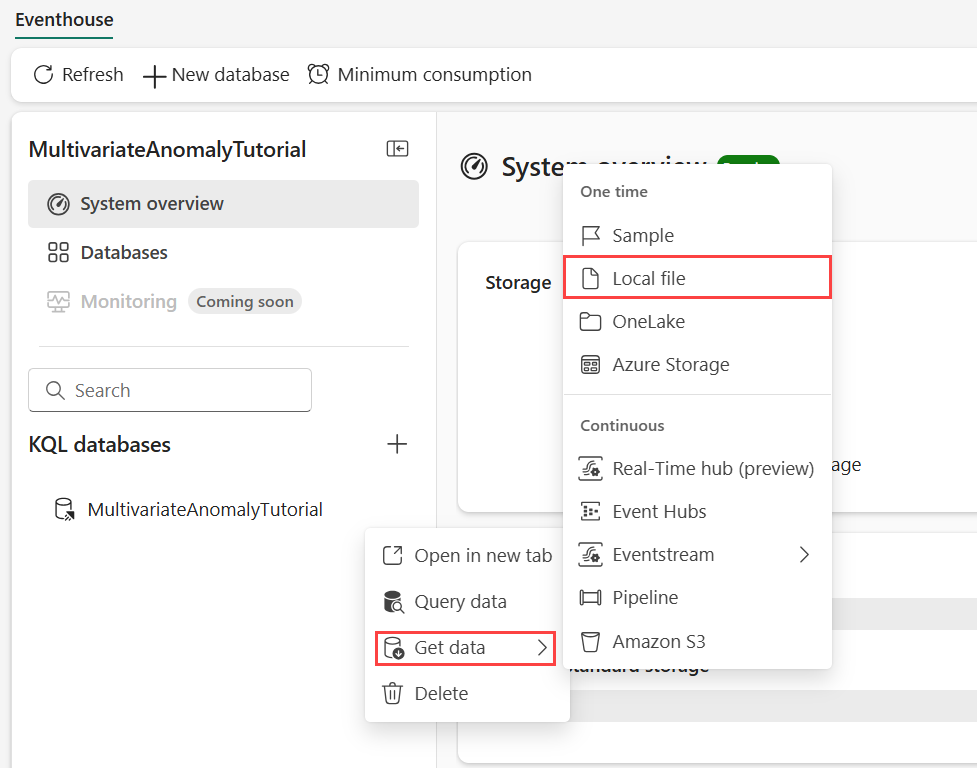
Sélectionnez + Nouvelle table et entrez demo_stocks_change comme nom de table.
Dans la boîte de dialogue Charger des données, sélectionnez Rechercher des fichiers et chargez l’exemple de fichier de données téléchargé dans les conditions préalables
Cliquez sur Suivant.
Dans la section Inspecter les données, basculez La première ligne est l’en-tête de colonne sur Activé.
Sélectionnez Terminer.
Une fois que les données sont chargées, cliquez sur Fermer.
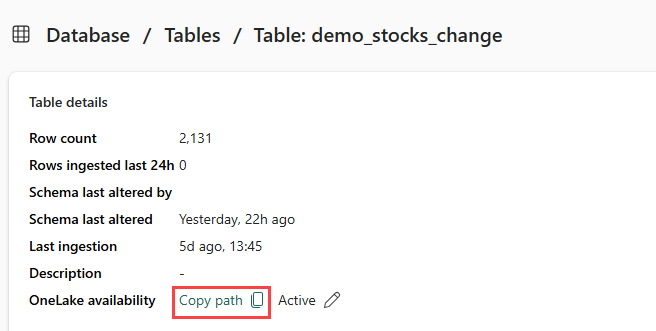
Partie 5 - Copier le chemin OneLake dans la table
Veillez à sélectionner la table demo_stocks_change. Dans le volet Détails du tableau, sélectionnez Dossier OneLake pour copier le chemin d’accès OneLake dans le Presse-papiers. Enregistrez ce texte copié dans un éditeur de texte quelque part pour être utilisé dans une étape ultérieure.
Partie 6 - Préparer le notebook
Sélectionnez votre espace de travail.
Sélectionnez Importer, Notebook, puis À partir de cet ordinateur.
Sélectionnez Télécharger, puis choisissez le notebook que vous avez téléchargé dans les conditions préalables.
Une fois le notebook chargé, vous pouvez rechercher et ouvrir votre notebook à partir de votre espace de travail.
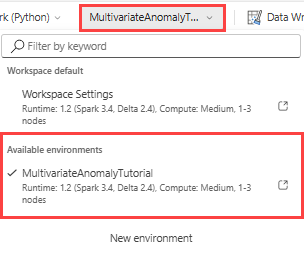
Dans le ruban supérieur, sélectionnez la liste déroulante Espace de travail par défaut, puis sélectionnez l’environnement que vous avez créé à l’étape précédente.
Partie 7 - Exécuter le notebook
Importer des packages standard.
import numpy as np import pandas as pdSpark a besoin d’un URI ABFSS pour se connecter en toute sécurité au stockage OneLake. L’étape suivante définit cette fonction pour convertir l’URI OneLake en URI ABFSS.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriRemplacez l’espace réservé OneLakeTableURI par votre URI OneLake copié à partir de Partie 5 - Copier le chemin OneLake vers la table pour charger demo_stocks_change table dans un dataframe pandas.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Exécutez les cellules suivantes pour préparer les trames de données d’entraînement et de prédiction.
Remarque
Les prédictions réelles seront exécutées sur les données par l’Eventhouse dans la Partie 9 - Predict-anomalies-in-the-kql-queryset. Dans un scénario de production, si vous diffusez des données dans la maison d’événements, les prédictions seront effectuées sur les nouvelles données de diffusion en continu. Dans le cadre du didacticiel, le jeu de données a été divisé par date en deux sections pour l’entraînement et la prédiction. Il s’agit de simuler des données historiques et de nouvelles données de streaming.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Exécutez les cellules pour entraîner le modèle et l’enregistrer dans le registre des modèles Fabric MLflow.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )Exécutez la cellule suivante pour extraire le chemin d'accès du modèle enregistré afin de l'utiliser pour la prédiction avec le sandbox Python Kusto.
mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)Copiez l’URI du modèle à partir de la dernière sortie de cellule pour l’utiliser dans une étape ultérieure.
Partie 8 - Configurer votre ensemble de requêtes KQL
Pour obtenir des informations générales, consultez Créer un ensemble de requêtes KQL.
- Dans votre espace de travail, sélectionnez +Nouvel élément>Ensemble de requêtes KQL.
- Entrez le nom MultivariateAnomalyDetectionTutorial, puis sélectionnez Créer.
- Dans la fenêtre du hub de données OneLake, sélectionnez la base de données KQL dans laquelle vous avez stocké les données.
- Sélectionnez Connecter.
Partie 9 - Prédire les anomalies dans l’ensemble de requêtes KQL
Exécutez la requête « .create-or-alter function » suivante pour définir la fonction stockée
predict_fabric_mvad_fl():.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Exécutez la requête de prédiction suivante, en remplaçant l’URI du modèle de sortie par l’URI copié à la fin de étape 7.
La requête détecte les anomalies multivariées sur les cinq actions, en fonction du modèle d’apprentissage et affiche les résultats sous forme de
anomalychart. Les points anormaux sont rendus sur le premier stock (AAPL), bien qu’ils représentent des anomalies multivariées (en d’autres termes, des anomalies des modifications conjointes des cinq actions dans la date spécifique).let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
Le graphique d'anomalie obtenu devrait ressembler à l'image suivante :

Nettoyer les ressources
Lorsque vous avez terminé le tutoriel, vous pouvez supprimer les ressources que vous avez créées pour éviter les coûts supplémentaires. Pour supprimer les ressources, suivez ces étapes :
- Accédez à la page d’accueil de votre espace de travail.
- Supprimez l’environnement que vous avez créé dans ce tutoriel.
- Supprimez le notebook que vous avez créé dans ce tutoriel.
- Supprimez l’Eventhouse ou la base de données utilisée dans ce tutoriel.
- Supprimez l’ensemble de requêtes KQL que vous avez créé dans ce tutoriel.