Copie rapide dans Dataflows Gen2
Cet article décrit la fonctionnalité de copie rapide dans Dataflows Gen2 pour Data Factory dans Microsoft Fabric. Les flux de données aident à ingérer et à transformer les données. Avec l’introduction du scale-out du flux de données avec le calcul SQL DW, vous pouvez transformer vos données à grande échelle. Toutefois, vos données doivent d’abord être ingérées. Avec l’introduction de la copie rapide, vous pouvez ingérer des téraoctets de données avec l'expérience simple des flux de données, mais avec le back end évolutif de l’activité Copy du pipeline.
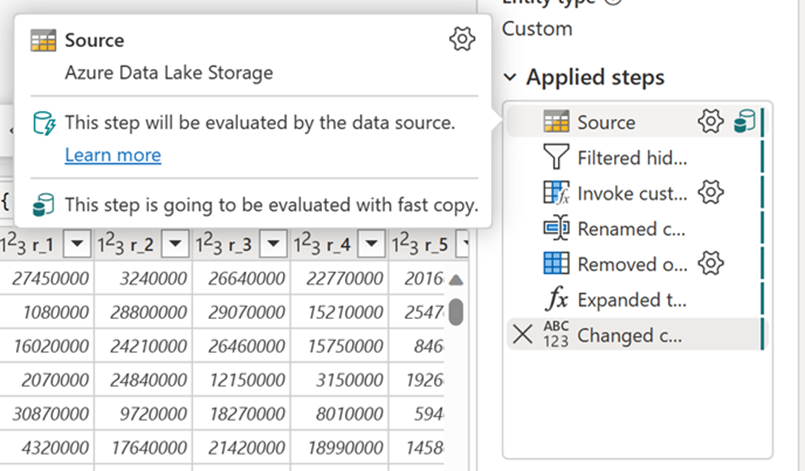
Après avoir activé cette fonctionnalité, les flux de données basculent automatiquement le back end lorsque la taille des données dépasse un seuil particulier, sans avoir à modifier quoi que ce soit lors de la création des flux de données. Après l’actualisation d’un flux de données, vous pouvez vérifier dans l’historique d’actualisation pour voir si une copie rapide a été utilisée pendant l’exécution en examinant le type Moteur qui s’y affiche.
Avec l’option Exiger une copie rapide activée, l’actualisation du flux de données est annulée si la copie rapide n’est pas utilisée. Cela vous permet d’éviter d’attendre un délai d’expiration d’actualisation pour continuer. Ce comportement peut également être utile dans une session de débogage pour tester le comportement du flux de données avec vos données tout en réduisant le temps d’attente. À l’aide des indicateurs de copie rapide dans le volet étapes de requête, vous pouvez facilement vérifier si votre requête peut s’exécuter avec une copie rapide.
Prérequis
- Vous devez disposer d’une capacité Fabric.
- Pour les données de fichier, les fichiers sont au format .csv ou parquet d’au moins 100 Mo et stockés dans un Azure Data Lake Storage (ADLS) Gen2 ou un compte de stockage blob.
- Pour les bases de données, y compris Azure SQL DB et PostgreSQL, 5 millions de lignes ou plus de données dans la source de données.
Remarque
Vous pouvez contourner le seuil pour forcer la copie rapide en sélectionnant le paramètre « Exiger une copie rapide ».
Prise en charge du connecteur
La copie rapide est actuellement prise en charge pour les connecteurs Dataflow Gen2 suivants :
- ADLS Gen2
- Stockage Blob
- Azure SQL DB
- Lakehouse
- PostgreSQL
- SQL Server localement
- Entrepôt
- Oracle
- Snowflake
L’activité de copie prend uniquement en charge quelques transformations lors de la connexion à une source de fichier :
- Combiner des fichiers
- Sélectionner des colonnes
- Changer les types de données
- Renommer une colonne
- Supprimer une colonne
Vous pouvez toujours appliquer d’autres transformations en fractionnant les étapes d’ingestion et de transformation en requêtes distinctes. La première requête récupère les données et la deuxième requête fait référence à ses résultats afin que le calcul DW puisse être utilisé. Pour les sources SQL, toute transformation qui fait partie de la requête native est prise en charge.
Lorsque vous chargez directement la requête vers une destination de sortie, seules les destinations Lakehouse sont prises en charge actuellement. Si vous souhaitez utiliser une autre destination de sortie, vous pouvez d’abord indexer la requête et la référencer ultérieurement.
Comment utiliser la copie rapide
Accédez au point de terminaison Fabric approprié.
Accédez à un espace de travail Premium et créez un flux de données Gen2.
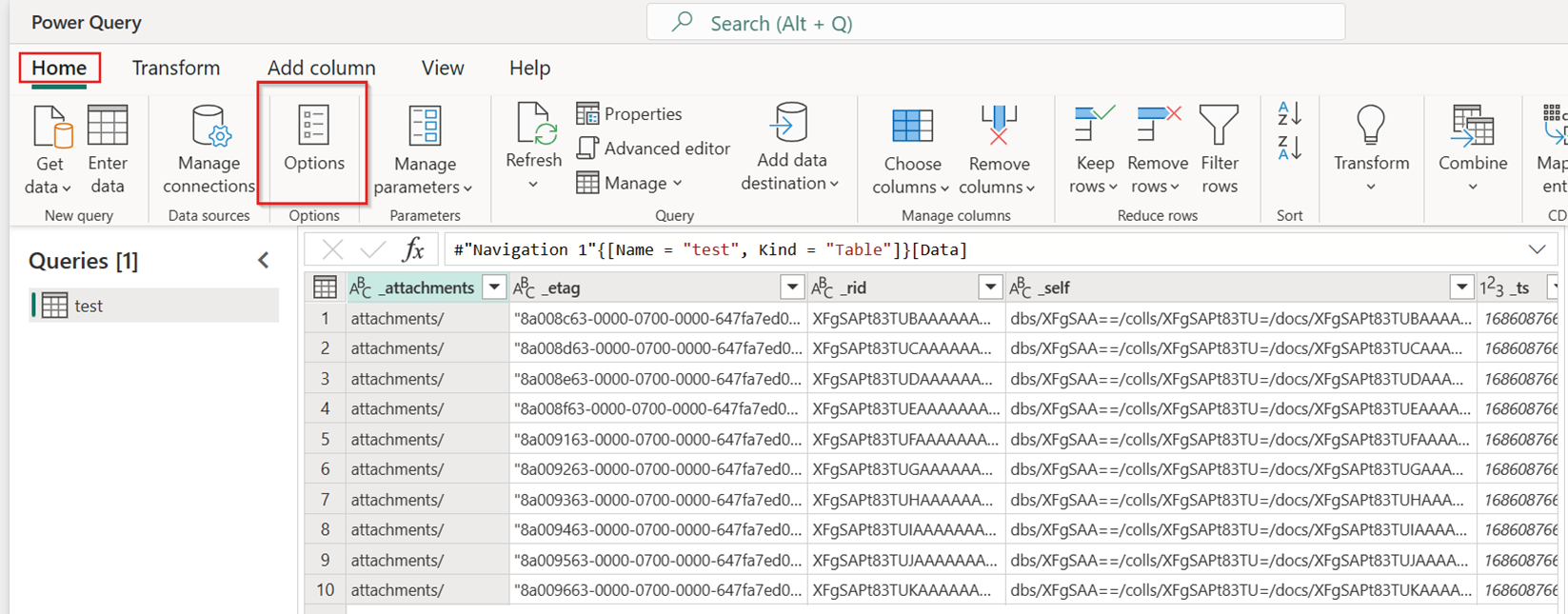
Sous l’onglet Accueil du nouveau flux de données, sélectionnez Options :
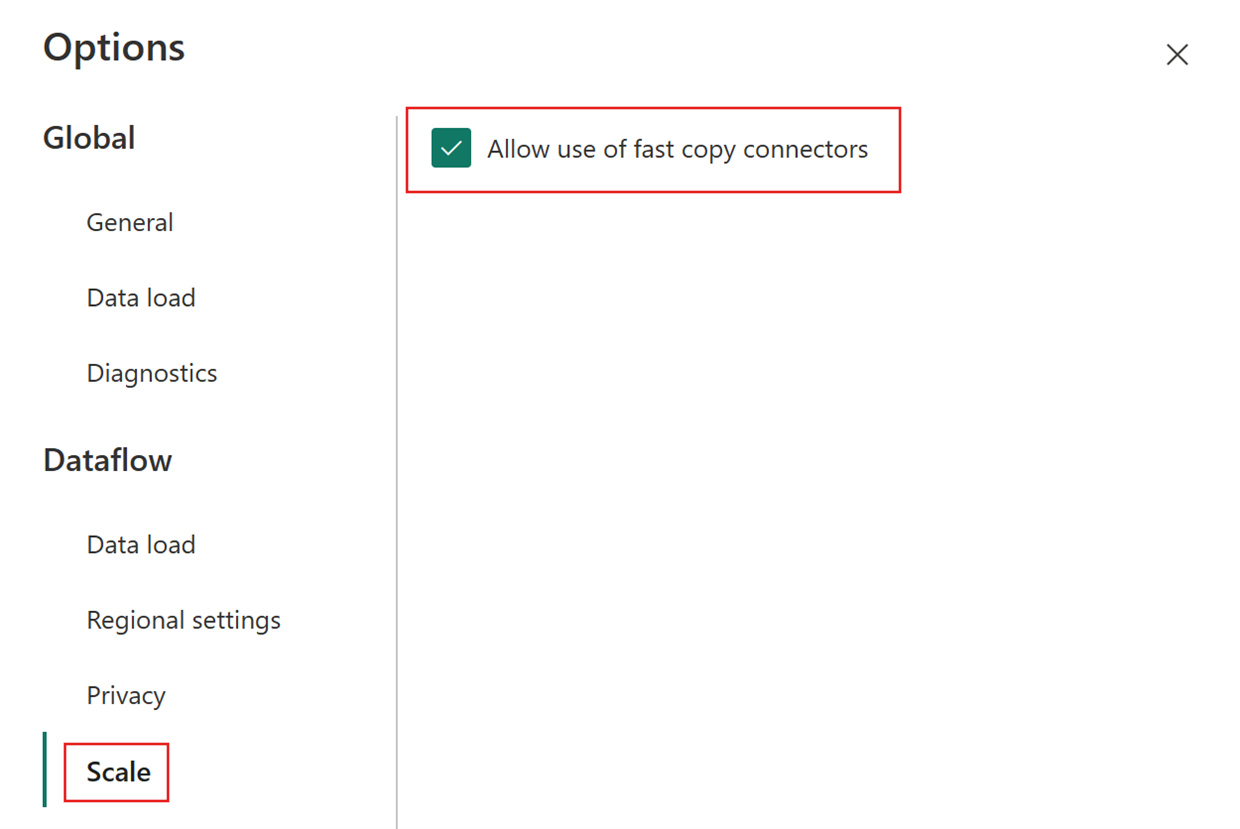
Choisissez ensuite l’onglet Mise à l’échelle dans la boîte de dialogue Options et sélectionnez la case à cocher Autoriser l’utilisation des connecteurs de copie rapide pour activer la copie rapide. Fermez ensuite la boîte de dialogue Options.
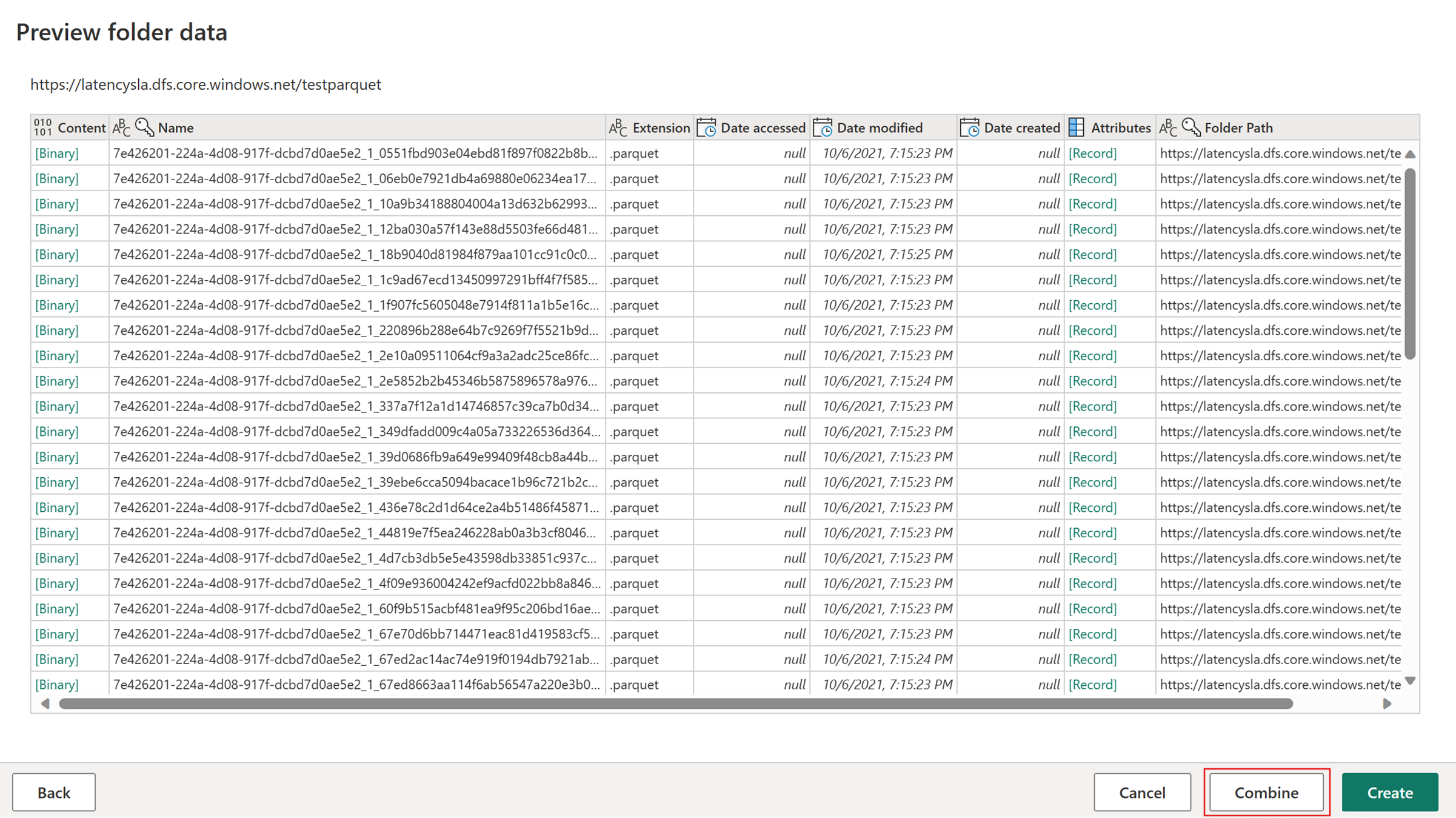
Sélectionnez Obtenir des données, puis choisissez la source ADLS Gen2, puis renseignez les détails de votre conteneur.
Utilisez la fonctionnalité Combiner un fichier.
Pour garantir une copie rapide, appliquez uniquement les transformations répertoriées dans la section Prise en charge du connecteur de cet article. Si vous avez besoin d’appliquer plus de transformations, indexer d’abord les données et référencez la requête ultérieurement. Effectuez d’autres transformations sur la requête référencée.
(Facultatif) Vous pouvez définir l’option Exiger une copie rapide pour la requête en cliquant dessus avec le bouton droit pour sélectionner et activer cette option.
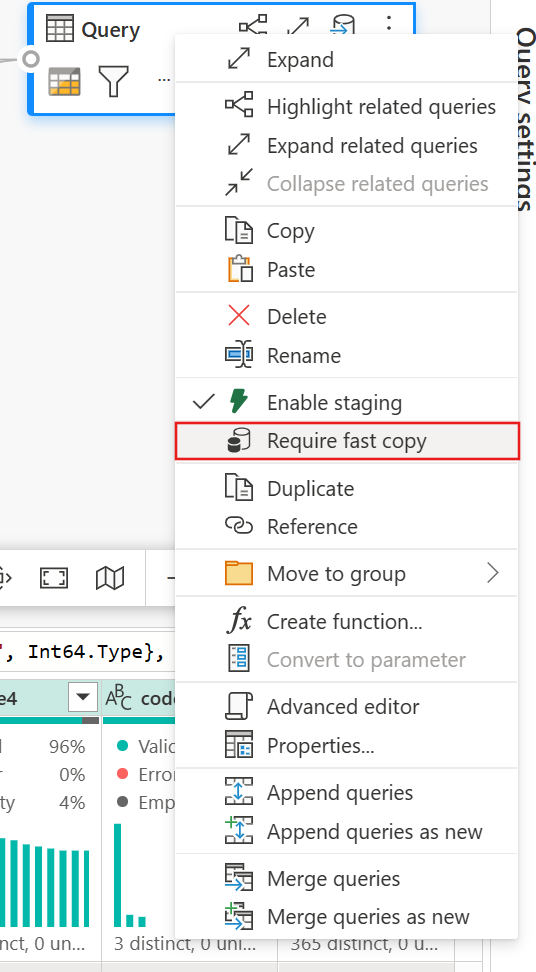
(Facultatif) Actuellement, vous ne pouvez configurer qu’un Lakehouse comme destination de sortie. Pour toute autre destination, indexez la requête et référencez-la ultérieurement dans une autre requête où vous pouvez générer une sortie vers n’importe quelle source.
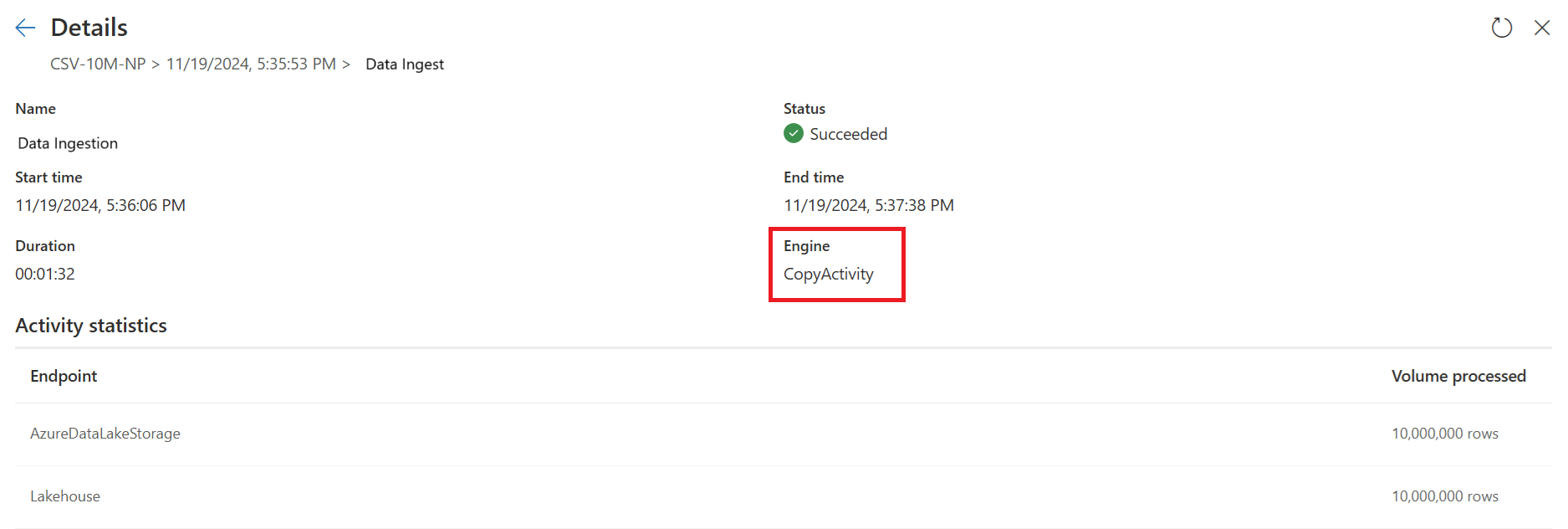
Vérifiez les indicateurs de copie rapide pour voir si votre requête peut s’exécuter avec une copie rapide. Si c’est le cas, le type Moteur affiche CopyActivity.

Publiez le flux de données.
Vérifiez une fois l’actualisation terminée pour confirmer que la copie rapide a été utilisée.

Comment diviser votre requête pour bénéficier de la copie rapide
Pour des performances optimales lors du traitement de grands volumes de données avec Dataflow Gen2, utilisez la fonctionnalité De copie rapide pour ingérer d’abord des données en préproduction, puis la transformer à grande échelle avec le calcul SQL DW. Cette approche améliore considérablement les performances de bout en bout.
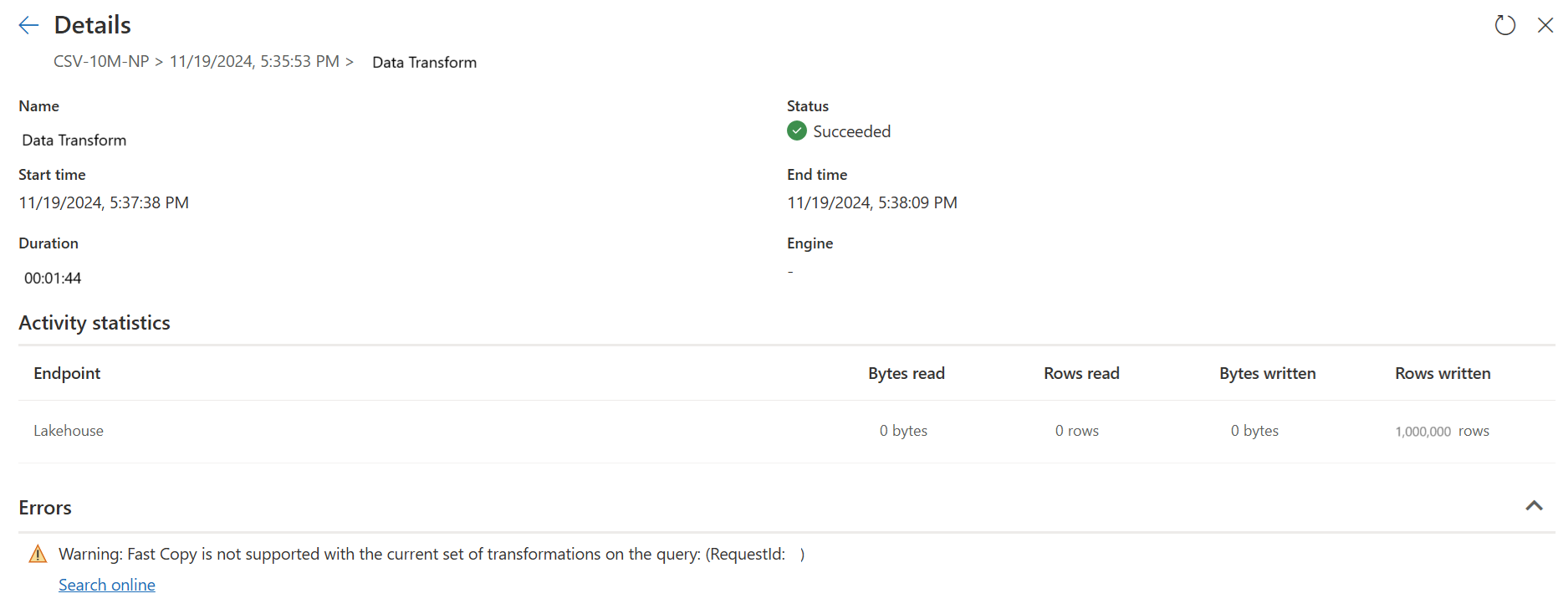
Pour implémenter cela, les indicateurs Fast Copy peuvent vous guider pour fractionner la requête en deux parties : l’ingestion de données vers la transformation intermédiaire et à grande échelle avec le calcul SQL DW. Vous êtes invité à transférer le plus d'évaluation possible d'une requête vers Fast Copy, qui peut être utilisé pour intégrer vos données. Lorsque les indicateurs de Copie rapide indiquent que les étapes restantes ne peuvent pas être exécutées par Copie rapide, vous pouvez fractionner le reste de la requête avec le mode de mise en scène activé.
Indicateurs de diagnostic d’étape
| Indicateur | Icône | Description |
|---|---|---|
| Cette étape va être évaluée avec une copie rapide | 
|
L’indicateur de copie rapide vous indique que la requête jusqu’à cette étape est compatible avec la copie rapide. |
| Cette étape n’est pas prise en charge par copie rapide | 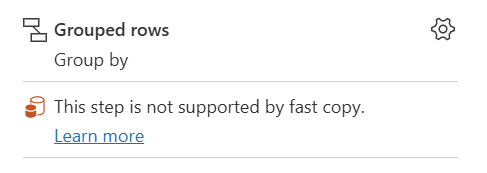
|
L’indicateur De copie rapide indique que cette étape ne prend pas en charge la copie rapide. |
| Une ou plusieurs étapes de votre requête ne sont pas prises en charge par la requête rapide | 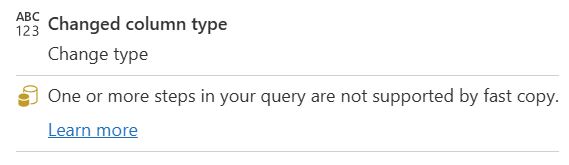
|
L’indicateur De copie rapide indique que certaines étapes de cette requête prennent en charge la copie rapide, tandis que d’autres ne le font pas. Pour optimiser, fractionnez la requête : étapes jaunes (potentiellement prises en charge par la copie rapide) et étapes rouges (non prises en charge). |
Conseils pas à pas
Une fois votre logique de transformation de données terminée dans Dataflow Gen2, l’indicateur Copie rapide évalue chaque étape pour déterminer le nombre d’étapes pouvant tirer parti de La copie rapide pour obtenir de meilleures performances.
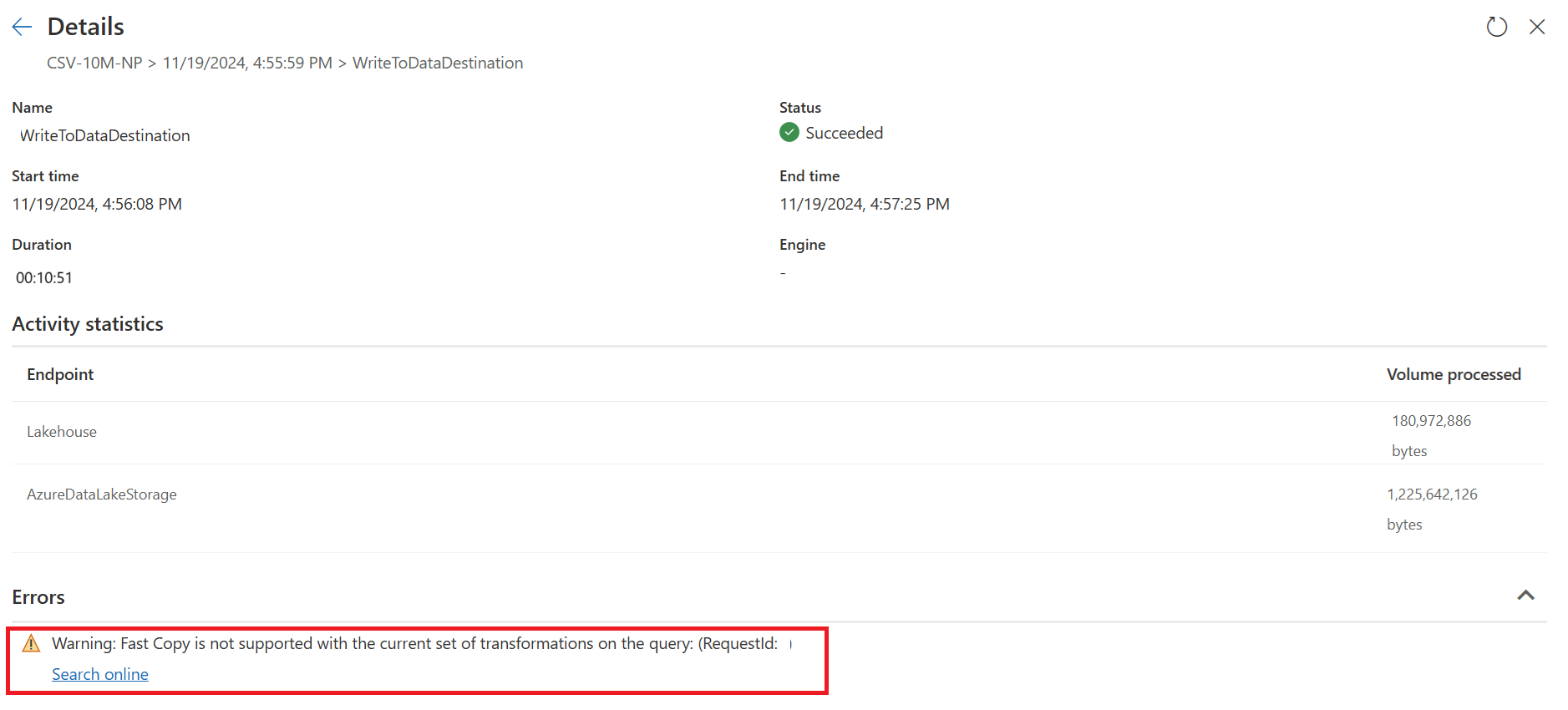
Dans l’exemple ci-dessous, la dernière étape s'affiche en rouge, indiquant que l’étape avec Grouper par n’est pas prise en charge par Copie Rapide. Toutefois, toutes les étapes précédentes montrant le jaune peuvent potentiellement être soutenues par Fast Copy.
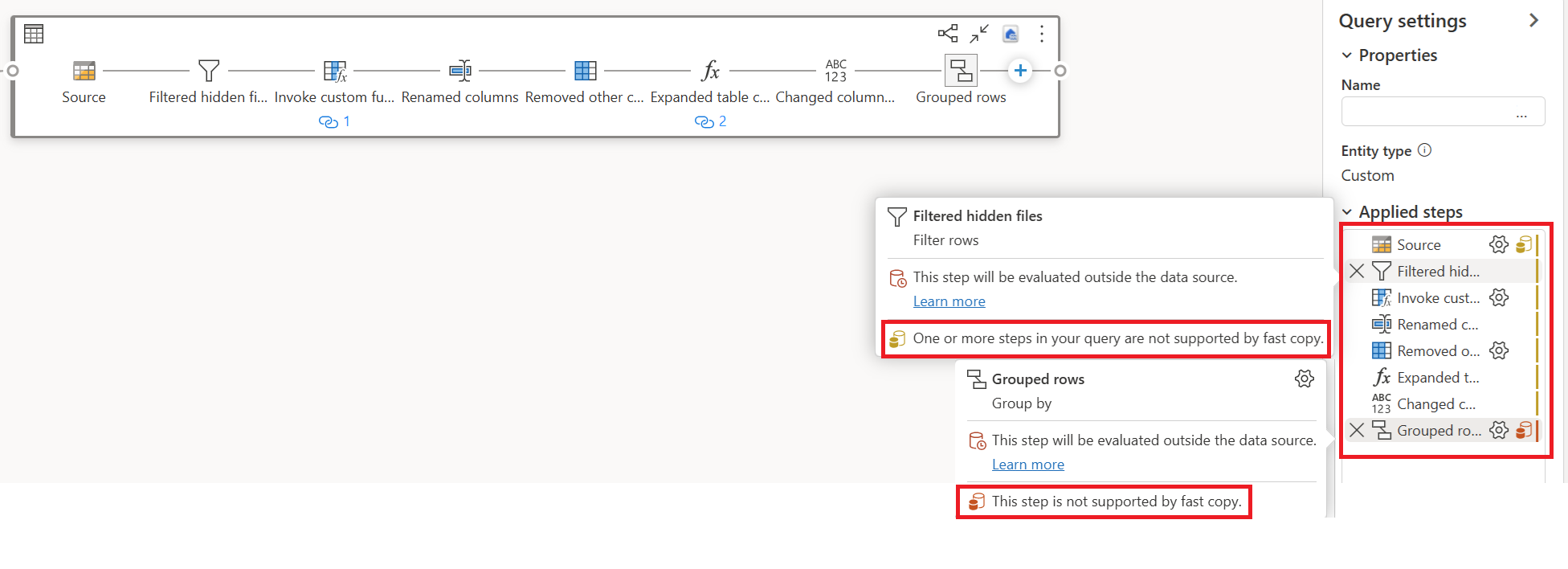
À ce stade, si vous publiez et exécutez directement votre Dataflow Gen2, il n’utilise pas le moteur de copie rapide pour charger vos données comme image ci-dessous :
Pour utiliser le moteur de copie rapide et améliorer les performances de votre Dataflow Gen2, vous pouvez fractionner votre requête en deux parties : l’ingestion de données en transformation intermédiaire et à grande échelle avec le calcul SQL DW, comme suit :
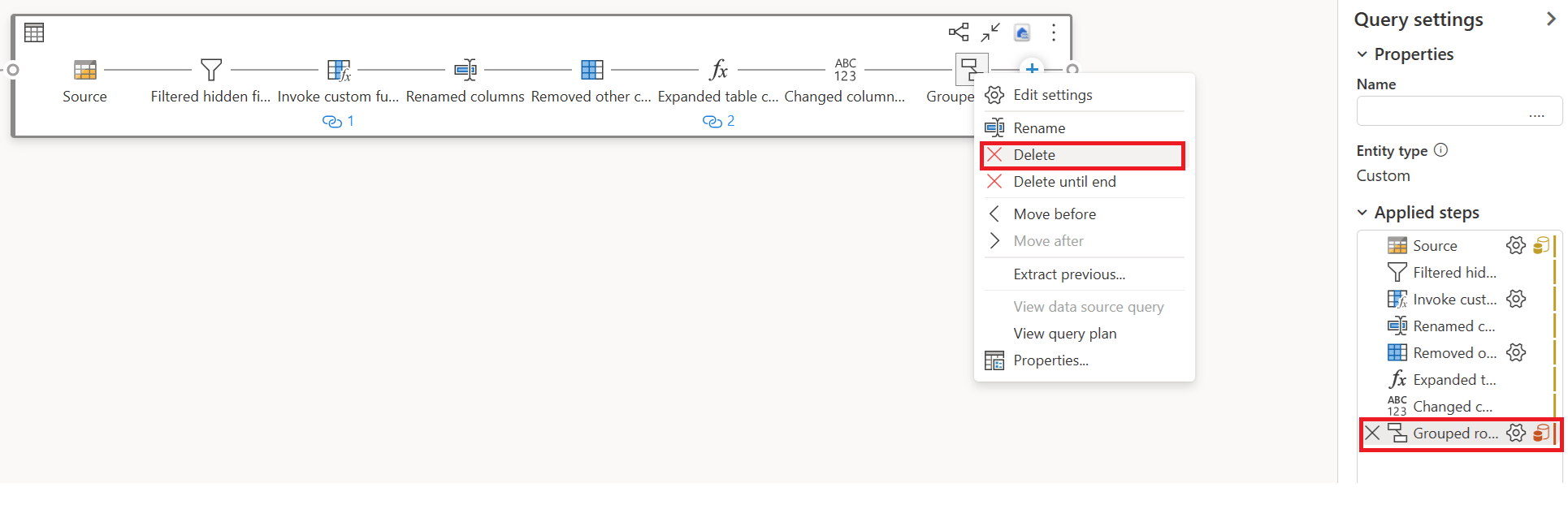
Supprimez les transformations (en rouge) qui ne sont pas prises en charge par la copie rapide, ainsi que la destination (si elle est définie).
L’indicateur De copie rapide affiche désormais vert pour les étapes restantes, ce qui signifie que votre première requête peut tirer parti de La copie rapide pour de meilleures performances.
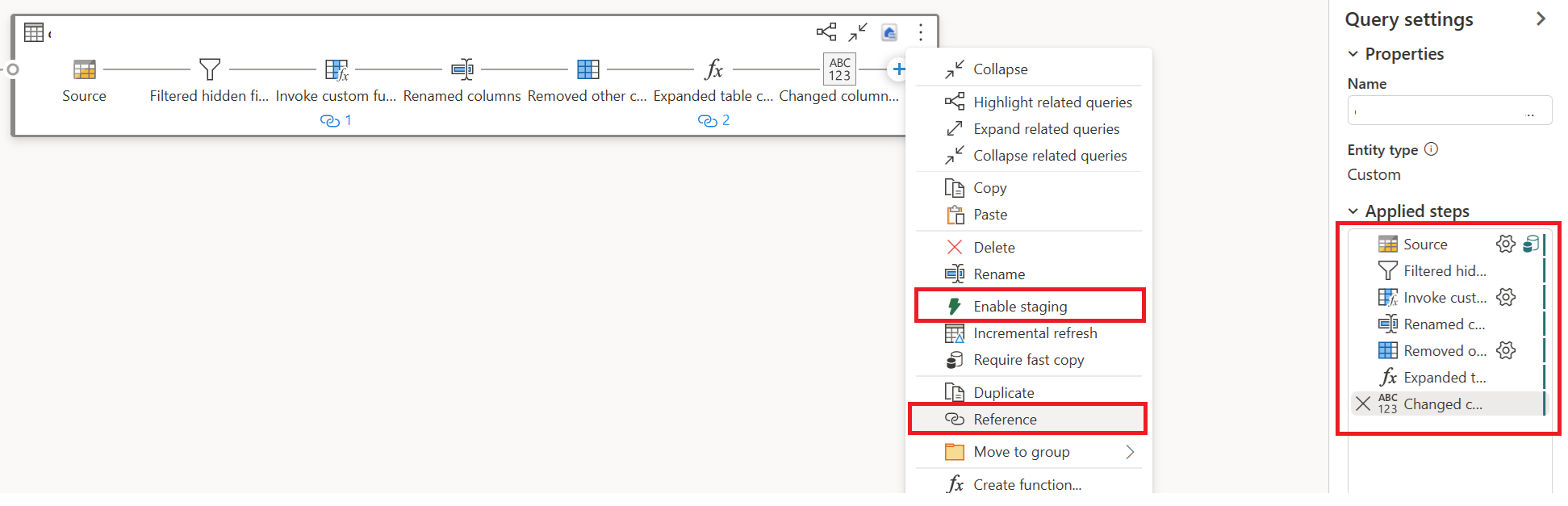
Sélectionnez Action pour votre première requête, puis choisissez Activation du transit et de la référence.
Dans une nouvelle requête référencée, lisez la transformation « Group By » et la destination (le cas échéant).
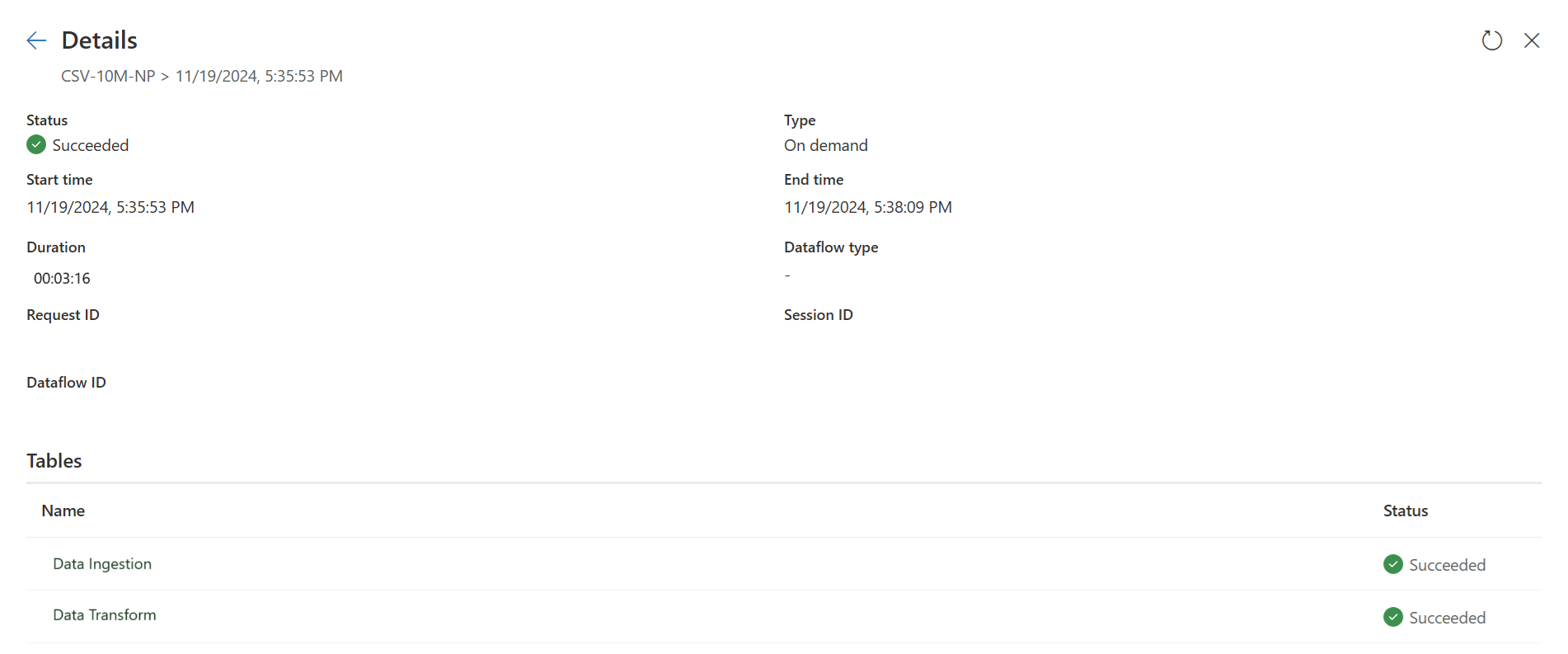
Publiez et actualisez votre Dataflow Gen2. Vous verrez maintenant deux requêtes dans votre Dataflow Gen2 et la durée globale est largement réduite.
La première requête ingère des données dans la zone de préparation à l’aide de Fast Copy.
La deuxième requête effectue des transformations à grande échelle à l’aide du calcul SQL DW.
La première requête :
La deuxième requête :
Limitations connues
- Une passerelle de données locale version 3000.214.2 ou ultérieure est nécessaire pour prendre en charge la copie rapide.
- La passerelle de réseau virtuel n’est pas prise en charge.
- L’écriture de données dans une table existante dans Lakehouse n’est pas prise en charge.
- Le schéma corrigé n’est pas pris en charge.