Choisir la meilleure option de flux de travail CI/CD Fabric pour vous
L’objectif de cet article est de présenter aux développeurs de Fabric différentes options pour créer des processus d’intégration continue et livraison continue (CI/CD) dans Fabric basés sur des scénarios client courants. Cet article est axé plus particulièrement sur la partie déploiement continu (CD) du processus CI/CD. Pour une discussion sur la partie intégration continue (CI), consultez Gérer des branches Git.
Bien que cet article présente plusieurs options distinctes, de nombreuses organisations adoptent une approche hybride.
Prérequis
Pour accéder à la fonctionnalité de pipelines de déploiement, vous devez remplir les conditions suivantes :
Vous avez un abonnement Microsoft Fabric
Vous êtes administrateur d'un espace de travail Fabric
Processus de développement
Le processus de développement est le même dans tous les scénarios de déploiement et il est indépendant de la façon de publier de nouvelles mises à jour en production. Quand des développeurs travaillent avec le contrôle de code source, ils doivent le faire dans un environnement isolé. Dans Fabric, cet environnement peut être un IDE sur votre machine locale (par exemple Power BI Desktop ou VS Code) ou un autre espace de travail dans Fabric. Vous trouverez des informations sur les différentes considérations relatives au processus de développement dans Gérer des branches Git.
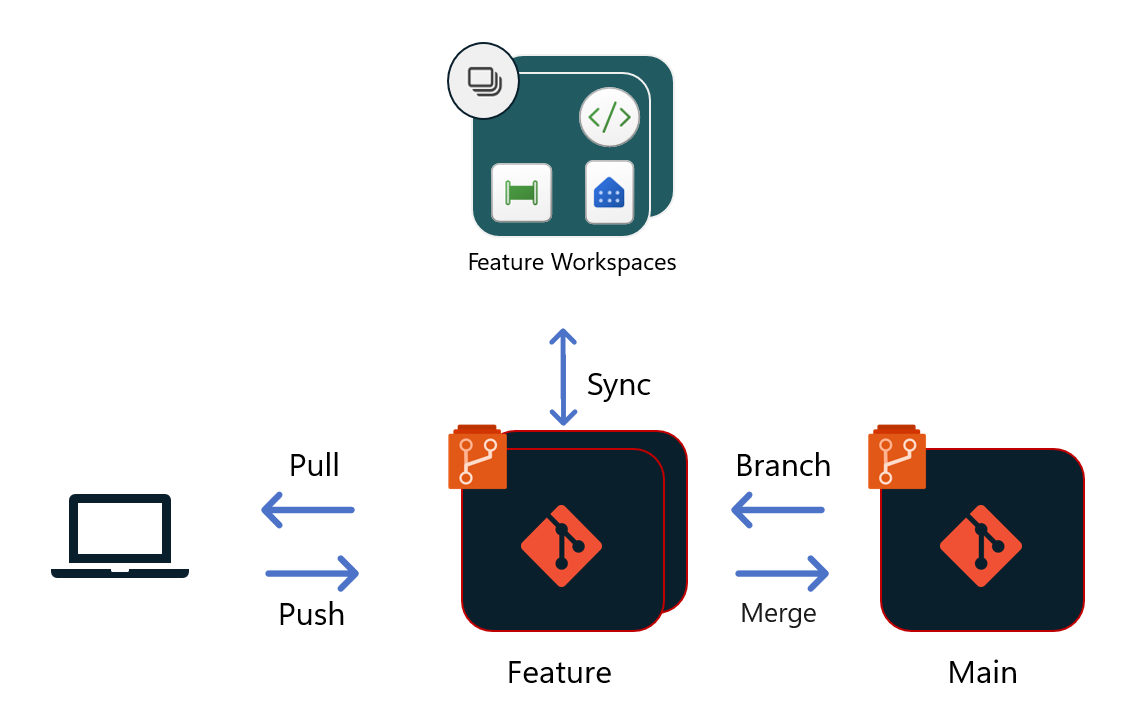
Processus de mise en production
Le processus de mise en production commence une fois que de nouvelles mises à jour sont terminées et que la demande de tirage (pull request) est fusionnée dans une branche partagée de l’équipe (comme Main, Dev, etc.). À partir de là, il existe différentes options pour créer un processus de mise en production dans Fabric.
Option 1 – Déploiements basés sur Git
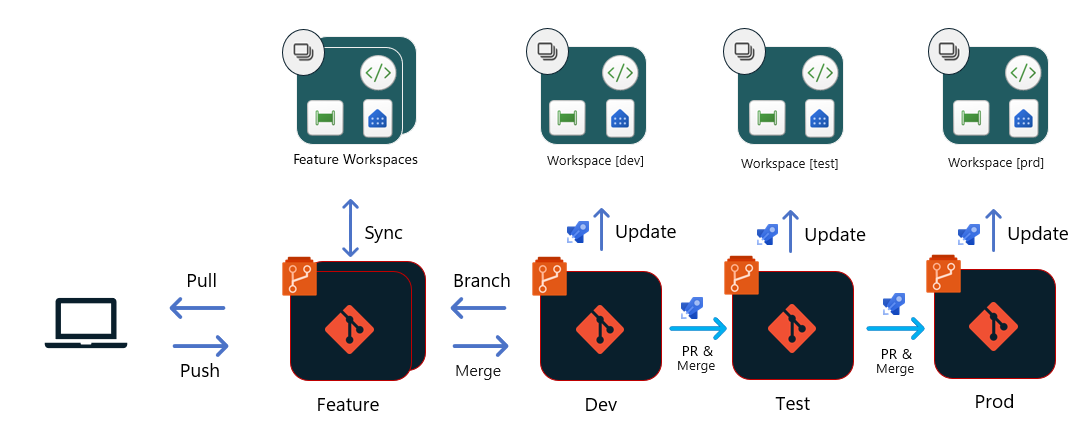
Avec cette option, tous les déploiements proviennent du référentiel Git. Chaque phase du pipeline de mise en production a une branche principale dédiée (dans le diagramme, ces phases sont Développement, Test et Production), qui alimente l’espace de travail approprié dans Fabric.
Une fois qu’une demande de tirage (pull request) effectuée auprès de la branche Dev est approuvée et fusionnée :
- Un pipeline de mise en production est déclenché pour mettre à jour le contenu de l’espace de travail Développement. Ce processus peut également inclure un pipeline de Build pour exécuter des tests unitaires, mais le chargement réel de fichiers est effectué directement depuis le référentiel dans l’espace de travail, en utilisant des API Git Fabric. Il peut être nécessaire d’appeler d’autres API Fabric pour les opérations post-déploiement qui définissent des configurations spécifiques pour cet espace de travail ou pour ingérer des données.
- Une demande de tirage (pull request) est ensuite créée dans la branche Test. Dans la plupart des cas, la demande de tirage (pull request) est créée en utilisant une branche de mise en production qui peut sélectionner le contenu à déplacer dans la phase suivante. La demande de tirage (pull request) doit inclure les mêmes processus de révision et d’approbation que les autres processus de votre équipe ou de votre organisation.
- Un autre pipeline de build et de mise en production est déclenché pour mettre à jour l’espace de travail Test en utilisant un processus similaire à celui décrit dans la première étape.
- Une demande de tirage (pull request) est créée pour la branche Prod en utilisant un processus similaire à celui décrit à l’étape 2.
- Un autre pipeline de build et de mise en production est déclenché pour mettre à jour l’espace de travail Production en utilisant un processus similaire à celui décrit dans la première étape.
Quand devez-vous envisager d’utiliser l’option 1 ?
- Quand vous voulez utiliser votre référentiel Git comme source unique de vérité et comme origine de tous les déploiements.
- Quand votre équipe suit Gitflow comme stratégie de gestion des branches, y compris plusieurs branches principales.
- Le chargement effectué depuis le référentiel va directement dans l’espace de travail, car nous n’avons pas besoin d’environnements de build pour modifier les fichiers avant les déploiements. Vous pouvez changer cela en appelant des API ou en exécutant des éléments dans l’espace de travail après le déploiement.
Option 2 – Déploiements basés sur Git avec des environnements de build
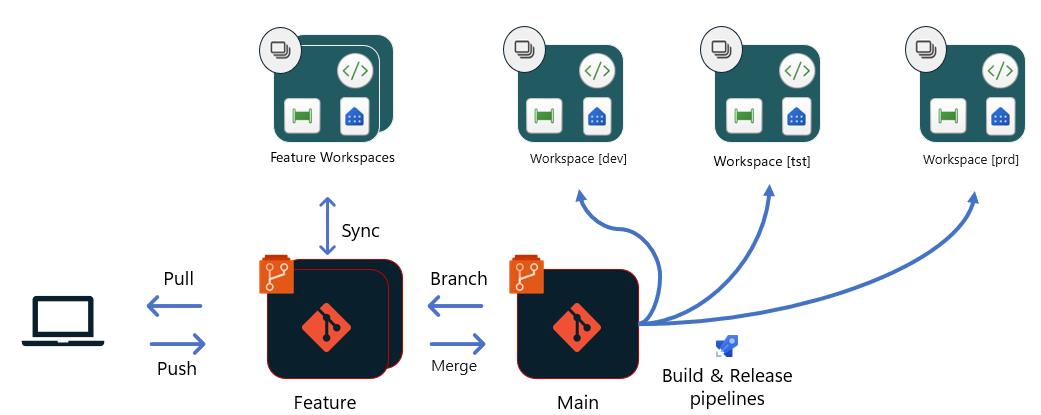
Avec cette option, tous les déploiements proviennent de la même branche du référentiel Git (Main). Chaque phase du pipeline de mise en production a un pipeline de build et de mise en production dédié. Ces pipelines peuvent utiliser un environnement de build pour exécuter des tests unitaires et des scripts qui modifient certaines des définitions dans les éléments avant leur chargement dans l’espace de travail. Par exemple, vous pouvez changer la connexion de source de données, les connexions entre des éléments de l’espace de travail ou les valeurs de paramètres afin d’ajuster la configuration pour la phase appropriée.
Une fois qu’une demande de tirage (pull request) effectuée auprès de la branche dev est approuvée et fusionnée :
- Un pipeline de build est déclenché pour créer un nouvel environnement de build et exécuter des tests unitaires pour la phase de développement. Ensuite, un pipeline de mise en production est déclenché pour charger le contenu dans un environnement de build, exécuter des scripts pour changer des éléments de la configuration, ajuster la configuration à la phase de développement et utiliser des API Mise à jour de définition d’élément de Fabric pour charger les fichiers dans l’espace de travail.
- Une fois ce processus terminé, y compris l’ingestion des données et l’approbation des responsables de la mise en production, les pipelines de build et de mise en production suivants pour la phase de test peuvent être créés. Ces phases sont créées dans un processus similaire à celui décrit dans la première étape. Pour la phase de test, d’autres tests automatisés ou manuels peuvent être nécessaires après le déploiement pour vérifier que les modifications sont prêtes à être publiées dans la phase de Production.
- Quand tous les tests automatisés et manuels sont terminés, le responsable de la mise en production peut approuver et lancer les pipelines de build et de mise en production de la phase de Production. Comme la phase de Production a généralement des configurations différentes de celles des phases test/développement, il est important de tester également les modifications après le déploiement. En outre, le déploiement doit déclencher les éventuelles ingestions de données supplémentaires en fonction de la modification, afin de minimiser l’indisponibilité potentielle pour les consommateurs.
Quand devez-vous envisager d’utiliser l’option 2 ?
- Quand vous voulez utiliser votre Git comme source unique de vérité et comme origine de tous les déploiements.
- Quand votre équipe suit un workflow de type « trunk » comme stratégie de gestion des branches.
- Vous avez besoin d’un environnement de build (avec un script personnalisé) pour modifier des attributs spécifiques à l’espace de travail, comme connectionId et lakehouseId, avant le déploiement.
- Vous avez besoin d’un pipeline de mise en production (script personnalisé) pour récupérer le contenu d’éléments auprès de git et appeler l’API Élément Fabric pour créer, mettre à jour ou supprimer des éléments Fabric modifiés.
Option 3 – Déployer en utilisant des pipelines de déploiement Fabric
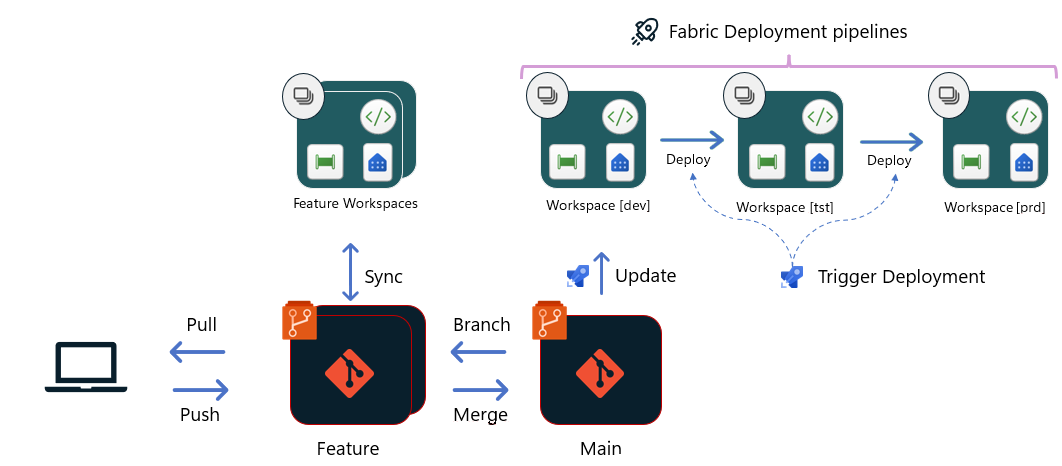
Avec cette option, Git est connecté seulement jusqu’à la phase de développement. À partir de la phase de développement, les déploiements se font directement entre les espaces de travail de Développement/Test/Production, en utilisant des pipelines de déploiement Fabric. Bien que l’outil lui-même soit interne à Fabric, les développeurs peuvent utiliser les API Pipelines de déploiement pour orchestrer le déploiement dans le cadre de leur pipeline de mise en production Azure ou d’un workflow GitHub. Ces API permettent à l’équipe de créer un processus de build et de mise en production similaire à celui des autres options, en utilisant des tests automatisés (qui peuvent être effectués dans l’espace de travail lui-même ou avant la phase de développement), des approbations, etc.
Une fois que la demande de tirage (pull request) effectuée auprès de la branche main est approuvée et fusionnée :
- Un pipeline de build est déclenché et charge les modifications dans la phase de développement en utilisant des API Git Fabric. Si nécessaire, le pipeline peut déclencher d’autres API pour démarrer des opérations/tests post-déploiement dans la phase de développement.
- Une fois le déploiement de développement terminé, un pipeline de mise en production démarre pour déployer les modifications de la phase de développement dans la phase de test. Les tests automatisés et manuels doivent avoir lieu après le déploiement, pour que les modifications soient bien testées avant d’atteindre la production.
- Une fois les tests terminés et après que le responsable de la mise en production a approuvé le déploiement dans la phase de Production, la publication en Production démarre et termine le déploiement.
Quand devez-vous envisager d’utiliser l’option 3 ?
- Quand vous utilisez le contrôle de code source seulement à des fins de développement et que vous préférez déployer les modifications directement entre les phases du pipeline de mise en production.
- Quand des règles de déploiement, la liaison automatique et d’autres API disponibles sont suffisantes pour gérer les configurations entre les phases du pipeline de mise en production.
- Quand vous voulez utiliser d’autres fonctionnalités des pipelines de déploiement Fabric, comme la visualisation des modifications dans Fabric, l’historique des déploiements, etc.
- Prenez également en compte le fait que les déploiements dans les pipelines de déploiement Fabric ont une structure linéaire, et qu’ils nécessitent d’autres autorisations pour créer et gérer le pipeline.
Option 4 – CI/CD pour les éditeurs de logiciels indépendants (ISV) dans Fabric (gestion de plusieurs clients/solutions)
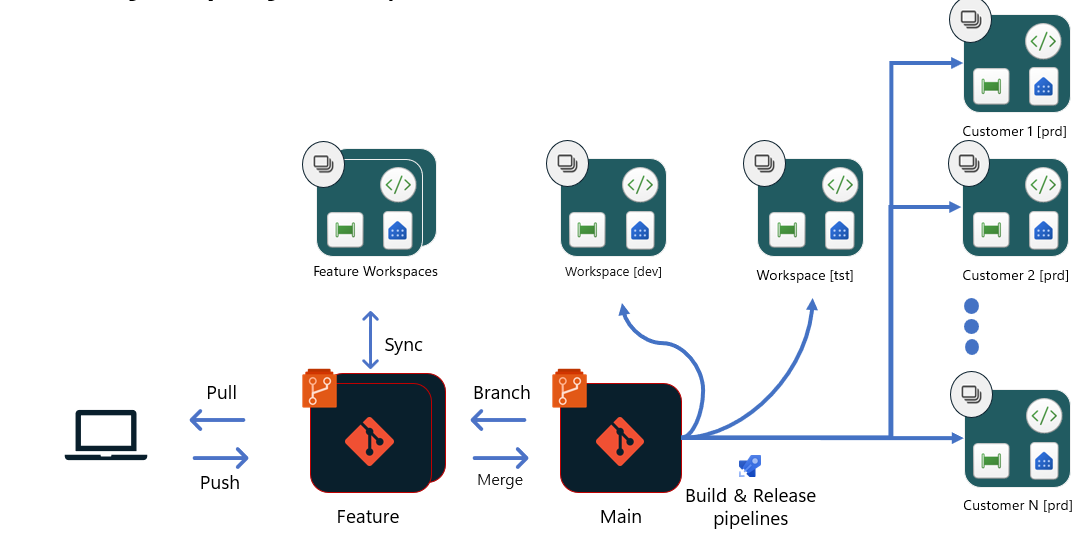
Cette option est différente des autres. Elle est la plus appropriée pour les éditeurs de logiciels indépendants qui créent des applications SaaS pour leurs clients en s’appuyant sur Fabric. Les éditeurs de logiciels indépendants ont généralement un espace de travail distinct pour chaque client, et peuvent avoir jusqu’à plusieurs centaines ou milliers d’espaces de travail. Quand la structure de l’analyse fournie à chaque client est similaire et prête à l’emploi, nous vous recommandons d’avoir un processus de développement et de test centralisé qui s’adapte à chaque client seulement dans la phase de Production.
Cette option est basée sur l’option 2. Une fois que la demande de tirage (pull request) effectuée auprès de la branche main est approuvée et fusionnée :
- Un pipeline de build est déclenché pour créer un nouvel environnement de build et exécuter des tests unitaires pour la phase de développement. Une fois les tests terminés, un pipeline de mise en production est déclenché. Ce pipeline peut charger le contenu dans un environnement de build, exécuter des scripts pour changer des éléments de la configuration, ajuster la configuration à la phase de développement et utiliser des API Mise à jour de définition d’élément de Fabric pour charger les fichiers dans l’espace de travail.
- Une fois ce processus terminé, y compris l’ingestion des données et l’approbation des responsables de la mise en production, les pipelines de build et de mise en production suivants pour la phase de test peuvent démarrer. Ce processus est similaire à celui décrit dans la première étape. Pour la phase de test, d’autres tests automatisés ou manuels peuvent être nécessaires après le déploiement pour vérifier que les modifications sont prêtes à être publiées dans la phase de Production avec un haut niveau de qualité.
- Une fois que tous les tests réussissent et que le processus d’approbation est terminé, le déploiement auprès des clients de la phase de Production peut démarrer. Chaque client a sa propre version avec ses propres paramètres, de sorte que sa configuration et sa connexion de données spécifiques peuvent être placées dans l’espace de travail du client concerné. Le changement de configuration peut se produire via des scripts dans un environnement de build ou en utilisant des API après le déploiement. Toutes les mises en production peuvent se produire en parallèle, car elles ne sont pas liées ni dépendantes les unes des autres.
Quand devez-vous envisager d’utiliser l’option 4 ?
- Vous êtes un éditeur de logiciels indépendant qui crée des applications basées sur Fabric.
- Vous utilisez des espaces de travail différents pour chaque client afin de gérer l’architecture mutualisée de votre application.
- Pour plus de séparation ou pour des tests spécifiques aux différents clients, vous pouvez utiliser l’architecture mutualisée dans les phases de développement ou de test antérieures. Dans ce cas, considérez qu’avec l’architecture mutualisée, le nombre d’espaces de travail requis augmente considérablement.
Résumé
Cet article récapitule les principales options de CI/CD pour une équipe qui veut créer un processus CI/CD automatisé dans Fabric. Si nous décrivions quatre options, les contraintes et l’architecture réelles des solutions peuvent se prêter à des options hybrides ou complètement différentes. Vous pouvez utiliser cet article pour vous guider dans les différentes options et comment les créer, mais vous n’êtes pas obligé de choisir une seule des options.
Certains scénarios ou éléments spécifiques peuvent avoir des limitations en place qui peuvent vous empêcher d’adopter un de ces scénarios.
Il en va de même pour les outils. Nous mentionnons ici différents outils, mais vous pouvez en choisir d’autres qui peuvent fournir le même niveau de fonctionnalités. Prenez en compte le fait que Fabric bénéficie d’une meilleure intégration à certains outils : choisir d’autres outils va donc entraîner davantage de limitations nécessitant différentes solutions de contournement.