Qu’est-ce que la continuité d’activité, la haute disponibilité et la récupération d’urgence ?
Cet article définit et décrit la continuité d’activité et de la planification de la continuité d’activité en termes de gestion des risques par le biais de la conception de la haute disponibilité et récupération d’urgence. Bien que cet article ne fournisse pas de conseils explicites sur la façon de répondre à vos propres besoins en matière de continuité d’activité, il vous aide à comprendre les concepts utilisés dans les conseils de fiabilité de Microsoft.
La continuité d’activité est l’état dans lequel une entreprise peut poursuivre ses opérations pendant des défaillances, des pannes ou des sinistres. La continuité de l’activité nécessite une planification proactive, une préparation et l’implémentation de systèmes et de processus résilients.
La planification de la continuité des activités nécessite d’identifier, de comprendre, de classer et de gérer les risques. En fonction des risques et de leurs probabilités, concevez à la fois une haute disponibilité (HA) et une récupération d’urgence (DR).
La haute disponibilité consiste à concevoir une solution résiliente aux problèmes quotidiens et à répondre aux besoins métier en matière de disponibilité.
La récupération d’urgence consiste à planifier la façon de gérer les risques inhabituels et les pannes catastrophiques qui peuvent en résulter.
Continuité des activités
En général, les solutions cloud sont liées directement aux opérations commerciales. Chaque fois qu’une solution cloud n’est pas disponible ou rencontre un problème grave, l’impact sur les opérations de l’entreprise peut être grave. Un impact grave peut briser la continuité de l’activité.
Les répercussions graves sur la continuité de l’activité peuvent inclure :
- Perte de revenus de l’entreprise.
- Incapacité à fournir un service important aux utilisateurs.
- Violation d’un engagement pris envers un client ou à une autre partie.
Il est important de comprendre et de communiquer les attentes de l’entreprise, ainsi que les conséquences des défaillances, aux parties prenantes importantes, notamment celles qui conçoivent, implémentent et exploitent la charge de travail. Ces parties prenantes réagissent ensuite en partageant les coûts impliqués dans la réalisation de cette vision. Il existe généralement un processus de négociation et de révisions de cette vision en fonction du budget et d’autres contraintes.
Planification de la continuité commerciale
Pour contrôler ou éviter complètement un impact négatif sur la continuité d’activité, il est important de créer de manière proactive un plan de continuité d’activité. Un plan de continuité d’activité est basé sur l’évaluation des risques et le développement de méthodes de contrôle de ces risques par le biais de différentes approches. Les risques et approches spécifiques à atténuer varient selon chaque organisation et chaque charge de travail.
Un plan de continuité d’activité ne prend pas seulement en compte les fonctionnalités de résilience de la plateforme cloud elle-même, mais également les fonctionnalités de l’application. Un plan robuste de continuité d’activité intègre également tous les aspects du support dans l’entreprise, notamment les personnes, les processus manuels ou automatisés liés à l’entreprise et d’autres technologies.
La planification de la continuité d’activité doit inclure les étapes séquentielles suivantes :
Identification des risques Identifiez les risques liés à la disponibilité ou aux fonctionnalités d’une charge de travail. Les risques possibles peuvent être des problèmes réseau, des défaillances matérielles, une erreur humaine, une panne de région, etc. Comprendre l’impact de chaque risque.
Classification des risques. Classez chaque risque soit comme un risque courant, qui doit être pris en compte dans les plans de haute disponibilité, soit comme un risque inhabituel, qui doit faire partie de la planification de la récupération d’urgence.
Atténuation des risques. Concevez des stratégies d’atténuation pour la haute disponibilité ou la récupération d’urgence afin de réduire ou atténuer les risques, par exemple en utilisant la redondance, la réplication, le basculement et les sauvegardes. En outre, envisagez des atténuations et des contrôles non techniques basés sur les processus.
La planification de la continuité d’activité est un processus, et non un événement unique. Tout plan de continuité d’activité créé doit être examiné et mis à jour régulièrement pour garantir qu’il reste pertinent et efficace, et qu’il prend en charge les besoins actuels de l’entreprise.
Identification des risques
La phase initiale de la planification de la continuité d’activité consiste à identifier les risques liés à la disponibilité ou aux fonctionnalités d’une charge de travail. Chaque risque doit être analysé pour comprendre sa probabilité et sa gravité. La gravité doit inclure tout temps d’arrêt ou perte de données potentiel, ainsi que la question de savoir si des aspects du reste de la conception de la solution pourraient compenser les effets négatifs.
Le tableau suivant est une liste non exhaustive des risques, classés par probabilité décroissante :
| Exemple de risque | Description | Régularité (probabilité) |
|---|---|---|
| Problème réseau temporaire | Défaillance temporaire dans un composant de la pile de mise en réseau, récupérable après une courte durée (généralement quelques secondes ou moins). | Regular |
| Redémarrage de la machine virtuelle | Redémarrage d’une machine virtuelle que vous utilisez ou qu’un service dépendant utilise. Les redémarrages peuvent se produire, car la machine virtuelle plante ou doit appliquer un correctif. | Regular |
| Défaillance matérielle | Échec d’un composant au sein d’un centre de données, tel qu’un nœud matériel, un rack ou un cluster. | Occasionnel |
| Panne du centre de données | Panne qui affecte la majeure partie ou la totalité d’un centre de données, comme une panne d’alimentation, un problème de connectivité réseau ou des problèmes de chauffage et de refroidissement. | Inhabituel |
| Panne dans une région | Panne qui affecte toute une zone métropolitaine ou une zone plus large, telle qu’une catastrophe naturelle majeure. | Très inhabituel |
La planification de la continuité d’activité ne concerne pas seulement la plateforme cloud et l’infrastructure. Il est important de prendre en compte le risque d’erreurs humaines. De plus, certains risques qui peuvent traditionnellement être considérés comme des risques de sécurité, de performances ou opérationnels doivent également être considérés comme des risques de fiabilité, car ils affectent la disponibilité de la solution.
Voici quelques exemples :
| Exemple de risque | Description |
|---|---|
| Perte ou altération des données | Les données ont été supprimées, remplacées ou endommagées par un accident ou par une violation de la sécurité comme une attaque par rançongiciel. |
| Bogue logiciel | Un déploiement de code nouveau ou mis à jour introduit un bogue qui a un impact sur la disponibilité ou l’intégrité, laissant la charge de travail dans un état de dysfonctionnement. |
| Déploiements ayant échoué | Un déploiement d’un nouveau composant ou d’une nouvelle version a échoué, laissant la solution dans un état incohérent. |
| Attaques par déni de service | Le système a été attaqué dans une tentative d’empêcher l’utilisation légitime de la solution. |
| Administrateurs non autorisés | Un utilisateur disposant de privilèges administratifs a intentionnellement effectué une action préjudiciable contre le système. |
| Afflux inattendu de trafic vers une application | Un pic de trafic a dépassé les ressources du système. |
L’analyse du mode échec (FMA) est le processus d’identification des méthodes potentielles d’échec d’une charge de travail ou de ses composants et de la façon dont la solution se comporte dans ces situations. Pour plus d’informations, consultez Suggestions pour effectuer une analyse du mode d’échec.
Classification des risques
Les plans de continuité d’activité doivent aborder les risques courants et inhabituels.
Les risques courants sont planifiés et prévus. Par exemple, dans un environnement cloud, il est courant qu’il y ait des défaillances temporaires notamment des pannes de réseau brèves, des redémarrages d’équipement en raison de correctifs, de délais d’expiration lorsqu’un service est occupé, etc. Étant donné que ces événements se produisent régulièrement, les charges de travail doivent être résilientes.
Une stratégie de haute disponibilité doit prendre en compte et contrôler chaque risque de ce type.
Lesrisques inhabituels sont généralement le résultat d’un événement imprévisible, tel qu’une catastrophe naturelle ou une attaque réseau majeure, qui peut entraîner une panne catastrophique.
Les processus de récupération d’urgence traitent de ces risques rares.
La haute disponibilité et la récupération d’urgence sont liées. Il est donc important de planifier des stratégies pour les deux ensemble.
Il est important de comprendre que la classification des risques dépend de l’architecture de la charge de travail et des exigences de l’entreprise, et certains risques peuvent être classés comme haute disponibilité pour une charge de travail et comme récupération d’urgence pour une autre charge de travail. Par exemple, une panne complète d’une région Azure serait généralement considérée comme un risque de récupération d’urgence pour les charges de travail de cette région. Toutefois, pour les charges de travail qui utilisent plusieurs régions Azure dans une configuration active-active avec une réplication complète, une redondance et un basculement automatique de région, une panne de région est classée comme un risque de haute disponibilité.
Atténuation des risques
L’atténuation des risques consiste à élaborer des stratégies de haute disponibilité ou de récupération d’urgence pour réduire ou atténuer les risques liés à la continuité de l’activité. L’atténuation des risques peut être humaine ou basée sur la technologie.
Atténuation des risques basée sur la technologie
L’atténuation des risques basée sur la technologie utilise des contrôles de risque basés sur la façon dont la charge de travail est implémentée et configurée, par exemple :
- Redondance
- Réplication des données
- Basculement
- Sauvegardes
Les contrôles de risque basés sur la technologie doivent être pris en compte dans le contexte du plan de continuité d’activité.
Par exemple :
Exigences en matière de temps d’arrêt faible. Certains plans de continuité d’activité ne peuvent tolérer aucun risque de temps d’arrêt en raison d’exigences strictes de haute disponibilité. Il existe certains contrôles basés sur la technologie qui peuvent nécessiter du temps pour qu’un humain soit averti, puis pour répondre. Les contrôles de risque basés sur la technologie qui incluent des processus manuels lents sont susceptibles d’être inadaptables à l’inclusion dans leur stratégie d’atténuation des risques.
Tolérance à une défaillance partielle. Certains plans de continuité d’activité peuvent tolérer un flux de travail qui s’exécute dans un état détérioré. Lorsqu’une solution fonctionne dans un état détérioré, certains composants peuvent être désactivés ou non fonctionnels, mais les opérations métier principales peuvent continuer à être effectuées. Pour plus d’informations, consultez Suggestions en matière de self-healing et d’auto-préservation.
Atténuation des risques par une personne
L’atténuation des risques par une personne utilise des contrôles de risque basés sur des processus métier, tels que :
- Déclenchement d’un playbook de réponse.
- Revenir à des opérations manuelles.
- Formation et changements culturels.
Important
Les individus qui conçoivent, implémentent, mettent en œuvre et évoluent la charge de travail doivent être compétents, encouragés à parler s’ils ont des préoccupations et à ressentir un sentiment de responsabilité pour le système.
Étant donné que les contrôles de risque par une personne sont souvent plus lents que les contrôles basés sur la technologie et plus susceptibles d’entraîner des erreurs humaines, un bon plan de continuité d’activité doit inclure un processus de contrôle de changement formel pour tout ce qui modifierait l’état du système en cours d’exécution. Par exemple, envisagez d’implémenter les processus suivants :
- Testez rigoureusement vos charges de travail conformément à leur criticité. Pour éviter les problèmes liés aux modifications, veillez à tester les modifications apportées à la charge de travail.
- Introduisez des portes de qualité stratégiques dans le cadre des pratiques de déploiement sécurisées de votre charge de travail. Pour plus d’informations, consultez Suggestions pour des pratiques de déploiement sécurisées.
- Formaliser des procédures pour l’accès à la production ad hoc et la manipulation des données. Ces activités, aussi mineures soient-elles, peuvent présenter un risque élevé de provoquer des incidents de fiabilité. Les procédures peuvent inclure le jumelage avec un autre ingénieur, l’utilisation de listes de contrôle et l’obtention d’évaluation par les pairs avant d’exécuter des scripts ou d’appliquer des modifications.
Haute disponibilité
La haute disponibilité est l’état dans lequel une charge de travail spécifique peut maintenir son niveau de disponibilité nécessaire au quotidien, même en cas de défauts transitoires et de défaillances intermittentes. Étant donné que ces événements se produisent régulièrement, il est important que chaque charge de travail soit conçue et configurée pour une haute disponibilité conformément aux exigences de l’application spécifique et des attentes des clients. La haute disponibilité de chaque charge de travail contribue à votre plan de continuité d’activité.
Étant donné que la haute disponibilité peut varier avec chaque charge de travail, il est important de comprendre les exigences et les attentes des clients lors de la détermination de la haute disponibilité. Par exemple, une application utilisée par votre organisation pour commander des fournitures de bureau peut nécessiter un niveau de durée de bon fonctionnement relativement faible, tandis qu’une application financière critique peut nécessiter une durée de bon fonctionnement beaucoup plus élevée. Même dans une charge de travail, différents flux peuvent avoir des exigences différentes. Par exemple, dans une application eCommerce, les flux qui prennent en charge la navigation et le passage de commandes peuvent être plus importants que les flux d’exécution des commandes et de traitement du back-office. Pour en savoir plus sur les flux, consultez Suggestions afin d’identifier et d’évaluer les flux.
En règle générale, la durée de bon fonctionnement est mesurée en fonction du nombre de « neuf » dans le pourcentage de la durée. Le pourcentage de durée de bon fonctionnement correspond à la quantité de temps d’arrêt que vous autorisez pendant une période donnée. Voici quelques exemples :
- Une exigence de durée de bon fonctionnement de 99,9 % (trois neuf) permet environ 43 minutes de temps d’arrêt en un mois.
- Une exigence de durée de bon fonctionnement de 99,95 % (trois neuf et demi) permet environ 21 minutes de temps d’arrêt en un mois.
Plus la durée de bon fonctionnement est élevée, moins vous avez de tolérance pour les pannes, et plus avez de travail à faire pour atteindre ce niveau de disponibilité. La durée de bon fonctionnement n’est pas mesuré par la durée de bon fonctionnement d’un composant unique comme un nœud, mais par la disponibilité globale de la charge de travail entière.
Important
Ne sur-concevez pas votre solution pour atteindre des niveaux de fiabilité plus élevés que ceux justifiés. Utilisez les exigences métier pour guider vos décisions.
Éléments de conception haute disponibilité
Pour atteindre les exigences de haute disponibilité, une charge de travail peut inclure un certain nombre d’éléments de conception. Certains des éléments communs sont répertoriés et décrits ci-dessous dans cette section.
Remarque
Certaines charges de travail sont stratégiques, ce qui signifie que tout temps d’arrêt peut avoir des conséquences graves sur la vie humaine et la sécurité, ou des pertes financières importantes. Si vous concevez une charge de travail stratégique, il existe des éléments spécifiques à prendre en compte lorsque vous concevez votre solution et gérez votre continuité d’activité. Pour plus d’informations, consultez Framework Azure Well-Architected : charges de travail stratégiques.
Services et niveaux Azure qui prennent en charge la haute disponibilité
De nombreux services Azure sont conçus pour être hautement disponibles et peuvent être utilisés pour créer des charges de travail hautement disponibles. Voici quelques exemples :
- Azure Virtual Machine Scale Sets fournit une haute disponibilité pour les machines virtuelles en créant et en gérant automatiquement des instances de machine virtuelle et en distribuant ces instances de machine virtuelle pour réduire l’impact des défaillances de l’infrastructure.
- Azure App Service offre une haute disponibilité grâce à diverses approches, notamment le déplacement automatique des workers d’un nœud non sain vers un nœud sain et en fournissant des fonctionnalités de self-healing à partir de nombreux types d’erreurs courants.
Utilisez chaque guide de fiabilité du service pour comprendre les fonctionnalités du service, décider des niveaux à utiliser et déterminer les fonctionnalités à inclure dans votre stratégie de haute disponibilité.
Passez en revue les contrats de niveau de service (SLA) pour chaque service afin de comprendre les niveaux de disponibilité attendus et les conditions que vous devez respecter. Vous devrez peut-être sélectionner ou éviter des niveaux spécifiques de services pour atteindre certains niveaux de disponibilité. Certains services de Microsoft sont proposés avec la compréhension qu’aucun contrat SLA n’est fourni, comme les niveaux de développement ou de base, ou que la ressource peut être récupérée à partir de votre système en cours d’exécution, comme les offres basées sur des emplacements. En outre, certains niveaux ont ajouté des fonctionnalités de fiabilité, telles que la prise en charge de zones de disponibilité.
Tolérance de panne
La tolérance de panne est la capacité d’un système à continuer à fonctionner, dans une certaine capacité définie, en cas de défaillance. Par exemple, une application web peut être conçue pour continuer à fonctionner même si un serveur web unique échoue. La tolérance de panne peut être obtenue par le biais de la redondance, du basculement, du partitionnement, de la dégradation progressive et d’autres techniques.
La tolérance de panne nécessite également que vos applications gèrent les défauts transitoires. Lorsque vous générez votre propre code, vous devrez peut-être activer vous-même la gestion de défauts transitoires. Certains services Azure fournissent une gestion de défauts transitoires intégrée pour certaines situations. Par exemple, par défaut, Azure Logic Apps retente automatiquement les demandes ayant échoué auprès d’autres services. Pour plus d’informations, consultez Suggestions pour la gestion des défauts transitoires.
Redondance
La redondance est la pratique de dupliquer des instances ou des données pour augmenter la fiabilité de la charge de travail.
La redondance peut être obtenue en distribuant des réplicas ou des instances redondantes de l’une des manières suivantes :
- À l’intérieur d’un centre de données (redondance locale)
- Entre les zones de disponibilité au sein d’une région (redondance de zone)
- Entre les régions (géo-redondance).
Voici quelques exemples de la façon dont certains services Azure fournissent des options de redondance :
- Azure App Service vous permet d’exécuter plusieurs instances de votre application pour vous assurer que l’application reste disponible même si une instance échoue. Si vous activez la redondance de zone, ces instances sont réparties entre plusieurs zones de disponibilité dans la région Azure que vous utilisez.
- Stockage Azure offre une haute disponibilité en répliquant automatiquement les données au moins trois fois. Vous pouvez distribuer ces réplicas entre les zones de disponibilité en activant le stockage redondant interzone (ZRS) et dans de nombreuses régions, vous pouvez également répliquer vos données de stockage entre les régions à l’aide du stockage géoredondant (GRS).
- Azure SQL Database dispose de plusieurs réplicas pour garantir que les données restent disponibles même si un réplica échoue.
Pour en savoir plus sur la redondance, consultez Suggestions relatives à la conception de redondance et Suggestions relatives à l’utilisation de zones de disponibilité et de régions.
Extensibilité et élasticité
La scalabilité et l’élasticité sont les capacités d’un système à gérer une charge accrue en ajoutant et en supprimant des ressources (scalabilité) et à le faire rapidement à mesure que vos besoins changent (élasticité). La scalabilité et l’élasticité peuvent aider un système à maintenir la disponibilité pendant les charges de pointe.
De nombreux services Azure prennent en charge la scalabilité. Voici quelques exemples :
- Azure Virtual Machine Scale Sets, Gestion des API Azure et plusieurs autres services prennent en charge la mise à l’échelle automatique Azure Monitor. Avec la mise à l’échelle automatique d’Azure Monitor, vous pouvez spécifier des stratégies telles que « lorsque mon unité centrale dépasse 80 %, ajoutez une autre instance ».
- Azure Functions peut approvisionner dynamiquement des instances pour répondre à vos demandes.
- Azure Cosmos DB prend en charge le débit de mise à l’échelle automatique, où le service peut gérer automatiquement les ressources affectées à vos bases de données en fonction des stratégies que vous spécifiez.
La scalabilité est un facteur clé à prendre en compte lors d’un dysfonctionnement partiel ou complet. Si un réplica ou une instance de calcul n’est pas disponible, les composants restants peuvent avoir besoin d’être plus chargés pour gérer la charge précédemment gérée par le nœud défectueux. Envisagez le surapprovisionnement si votre système ne peut pas être mis à l’échelle suffisamment rapidement pour gérer les changements de charge attendus.
Pour plus d’informations sur la conception d’un système évolutif et élastique, consultez Suggestions relatives à la conception d’une stratégie de mise à l’échelle fiable.
Techniques de déploiement sans temps d’arrêt
Les déploiements et autres changements système présentent un risque important de temps d’arrêt. Étant donné que le risque de temps d’arrêt est un défi pour les exigences de haute disponibilité, il est important d’utiliser des pratiques de déploiement sans temps d’arrêt pour apporter des mises à jour et des modifications de configuration sans temps d’arrêt nécessaire.
Les techniques de déploiement sans temps d’arrêt peuvent inclure :
- Mise à jour d’un sous-ensemble de vos ressources à la fois.
- Contrôle de la quantité de trafic qui atteint le nouveau déploiement.
- Surveillance de tout impact sur vos utilisateurs ou votre système.
- Correction rapide du problème, par exemple en revenant à un déploiement connu précédent.
Pour en savoir plus sur les techniques de déploiement sans temps d’arrêt, consultez Pratiques de déploiement sécurisées.
Azure lui-même utilise des approches de déploiement sans temps d’arrêt pour nos propres services. Lorsque vous créez vos propres applications, vous pouvez adopter des déploiements sans temps d’arrêt via diverses approches, telles que :
- Azure Container Apps fournit plusieurs révisions de votre application, qui peuvent être utilisées pour réaliser des déploiements sans temps d’arrêt.
- Azure Kubernetes Service (AKS) prend en charge diverses techniques de déploiement sans temps d’arrêt.
Bien que les déploiements sans temps d’arrêt soient souvent associés aux déploiements d’applications, ils doivent également être utilisés pour les modifications de configuration. Voici quelques façons d’appliquer les modifications de configuration en toute sécurité :
- Stockage Azure vous permet de modifier vos clés d’accès de compte de stockage en plusieurs étapes, ce qui évite les temps d’arrêt pendant les opérations de rotation des clés.
- Azure App Configuration fournit des indicateurs de fonctionnalités, des instantanés et d’autres fonctionnalités pour vous aider à contrôler l’application des modifications de configuration.
Si vous décidez de ne pas implémenter de déploiements sans temps d’arrêt, veillez à définir des fenêtres de maintenance afin que vous puissiez apporter des modifications système à un moment où vos utilisateurs s’y attendent.
Tests automatisés
Il est important de tester la capacité de votre solution à résister aux pannes et aux défaillances que vous considérez comme étant dans l’étendue de la haute disponibilité. La plupart de ces défaillances peuvent être simulées dans des environnements de test. Le test de la capacité de votre solution à tolérer ou à récupérer automatiquement à partir d’un large éventail de types de défaut est appelé ingénierie de chaos. L’ingénierie du chaos est critique pour les organisations matures avec des normes strictes pour la haute disponibilité. Azure Chaos Studio est un outil d’ingénierie de chaos qui peut simuler certains types de défauts courants.
Pour plus d’informations, consultez Suggestions relatives à la conception d’une stratégie de test de fiabilité.
Surveillance et alerte
La surveillance vous permet de connaître l’intégrité de votre système, même lorsque des atténuations automatisées ont lieu. La surveillance est essentielle pour comprendre comment votre solution se comporte et pour surveiller les premiers signaux de défaillances, comme des taux d’erreur accrus ou une consommation élevée de ressources. Avec des alertes, vous pouvez recevoir de manière proactive des modifications importantes dans votre environnement.
Azure fournit une variété de fonctionnalités de surveillance et d’alerte, notamment les suivantes :
- Azure Monitor collecte les journaux et les indicateurs de performance à partir de ressources et d’applications Azure, et peut envoyer des alertes et afficher des données dans des tableaux de bord.
- Azure Monitor Application Insights fournit une surveillance détaillée de vos applications.
- Azure Service Health et Azure Resource Health surveillent l’intégrité de la plateforme Azure et de vos ressources.
- Scheduled Events conseille quand la maintenance est planifiée pour les machines virtuelles.
Pour plus d’informations, consultez Suggestions pour concevoir une stratégie de surveillance et d’alerte fiable.
Récupération d’urgence
Un sinistre est un événement majeur distinct et rare qui a un impact plus important et plus durable qu’une application peut atténuer par le biais de l’aspect haute disponibilité de sa conception. Voici quelques exemples de sinistres :
- Des catastrophes naturelles, comme des ouragans, des tremblements de terre, des inondations ou des incendies.
- Des erreurs humaines qui entraînent un impact majeur, comme la suppression accidentelle de données de production ou un pare-feu mal configuré qui expose des données sensibles.
- Des incidents de sécurité majeures, comme des attaques par déni de service ou rançongiciel qui entraînent une altération des données, une perte de données ou des pannes de service.
La récupération d’urgence consiste à planifier la façon dont vous répondez à ces types de situations.
Remarque
Vous devez suivre les pratiques recommandées dans votre solution pour réduire la probabilité de ces événements. Cependant, même après une planification proactive minutieuse, il est prudent de planifier la manière dont vous réagiriez à ces situations si elles se présentaient.
Exigences en matière de récupération d’urgence
En raison de la rareté et de la gravité des événements d’urgence, la planification de la récupération d’urgence apporte différentes attentes pour votre réponse. De nombreuses organisations acceptent le fait que, dans un scénario de sinistre, un certain niveau de temps d’arrêt ou de perte de données est inévitable. Un plan de récupération d’urgence complet doit spécifier les exigences métier critiques suivantes pour chaque flux :
L’objectif de point de récupération (RPO) est la durée maximale de perte de données acceptable en cas de sinistre. Le RPO est mesuré en unités de temps, telles que « 30 minutes de données » ou « quatre heures de données ».
L’objectif de délai de récupération (RTO) est la durée maximale d’un temps d’arrêt acceptable en cas de sinistre, où « temps d’arrêt » est défini selon vos spécifications. Le RTO est également mesuré en unités de temps, comme « huit heures de temps d’arrêt ».
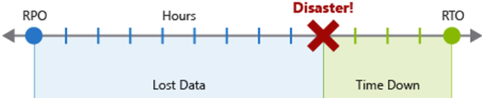
Chaque composant ou flux de la charge de travail peut avoir des valeurs RPO et RTO individuelles. Examinez les risques liés au scénario d’urgence et les stratégies de récupération potentielle lors de la détermination des exigences. Le processus de spécification d’un RPO et RTO crée des exigences de récupération d’urgence pour votre charge de travail motivées par les préoccupations spécifiques à votre entreprise (coûts, impact, perte de données, etc.).
Remarque
Bien qu’il soit tentant de viser un RTO et un RPO de zéro (aucun temps d’arrêt et aucune perte de données en cas de sinistre), dans la pratique, cela est difficile et coûteux à implémenter. Il est important pour les parties prenantes techniques et commerciales de discuter ensemble de ces exigences et de décider des exigences réalistes. Pour plus d’informations, consultez Recommandations pour définir des objectifs de fiabilité.
Plans de reprise après sinistre
Quelle que soit la cause du sinistre, il est important de créer un plan de récupération d’urgence bien défini et testable. Ce plan sera utilisé dans le cadre de la conception de l’infrastructure et de l’application pour le prendre en charge activement. Vous pouvez créer plusieurs plans de récupération d’urgence pour différents types de situations. Les plans de récupération d’urgence s’appuient souvent sur les contrôles de processus et l’intervention manuelle.
La récupération d’urgence n’est pas une fonctionnalité automatique d’Azure. Toutefois, de nombreux services fournissent des fonctionnalités et des capacités que vous pouvez utiliser pour prendre en charge vos stratégies de récupération d’urgence. Passer en revue les guides de fiabilité pour chaque service Azure afin de comprendre le fonctionnement du service et ses fonctionnalités, puis mapper ces fonctionnalités à votre plan de récupération d’urgence.
Les sections suivantes répertorient certains éléments courants d’un plan de récupération d’urgence et décrivent comment Azure peut vous aider à les atteindre.
Basculement et restauration automatique
Certains plans de récupération d’urgence impliquent l’approvisionnement d’un déploiement secondaire dans un autre emplacement. Si un sinistre affecte le déploiement principal de la solution, le trafic peut alors être basculé sur l’autre site. Le basculement nécessite une planification et une implémentation minutieuses. Azure fournit un large éventail de services pour faciliter le basculement, par exemple :
- Azure Site Recovery fournit un basculement automatisé pour les environnements locaux et les solutions hébergées par des machines virtuelles dans Azure.
- Azure Front Door et Azure Traffic Manager prennent en charge le basculement automatisé du trafic entrant entre différents déploiements de votre solution, comme dans différentes régions.
Il faut généralement un certain temps pour qu’un processus de basculement détecte que l’instance principale a échoué et bascule vers l’instance secondaire. Vérifiez que le RTO de la charge de travail est aligné sur le temps de basculement.
Il est également important de prendre en compte la restauration automatique, c’est-à-dire le processus par lequel vous restaurez les opérations dans la région primaire après sa récupération. La restauration automatique peut être complexe à planifier et à implémenter. Par exemple, les données de la région primaire peuvent avoir été écrites après le début du basculement. Vous devez prendre des décisions professionnelles prudentes sur la façon dont vous gérez ces données.
Sauvegardes
Les sauvegardes impliquent de prendre une copie de vos données et de les stocker en toute sécurité pendant une période définie. Avec les sauvegardes, vous pouvez vous remettre d’un sinistre lorsque le basculement automatique vers un autre réplica n’est pas possible, ou lorsque la corruption des données s’est produite.
Lorsque vous utilisez des sauvegardes dans le cadre d’un plan de récupération d’urgence, il est important de prendre en compte les éléments suivants :
L’emplacement de stockage. Lorsque vous utilisez des sauvegardes dans le cadre d’un plan de récupération d’urgence, elles doivent être stockées séparément dans les données principales. En règle générale, les sauvegardes sont stockées dans une autre région Azure.
La perte de données. Étant donné que les sauvegardes ne sont généralement pas effectuées fréquemment, la restauration des sauvegardes implique généralement une perte de données. Pour cette raison, la récupération de sauvegarde doit être utilisée en dernier recours et un plan de récupération d’urgence doit spécifier la séquence d’étapes et de tentatives de récupération qui doivent avoir lieu avant la restauration à partir d’une sauvegarde. Il est important de s’assurer que le RPO de charge de travail est aligné sur l’intervalle de sauvegarde.
Le délai de récupération. La restauration des sauvegardes prend souvent du temps. Il est donc essentiel de tester vos sauvegardes et processus de restauration pour vérifier leur intégrité et comprendre le temps nécessaire au processus de restauration. Assurez-vous que le RTO de la charge de travail tient compte du temps nécessaire à la restauration de votre sauvegarde.
De nombreux services de stockage et de données Azure prennent en charge les sauvegardes, telles que :
- Sauvegarde Azure fournit des sauvegardes automatisées pour les disques de machine virtuelle, les comptes de stockage, AKS et diverses autres sources.
- De nombreux services de base de données Azure, notamment Azure SQL Database et Azure Cosmos DB, disposent d’une fonctionnalité de sauvegarde automatisée pour vos bases de données.
- Azure Key Vault fournit des fonctionnalités pour sauvegarder vos secrets, certificats et clés.
Déploiements automatisés
Pour déployer et configurer rapidement les ressources nécessaires en cas de sinistre, utilisez des ressources d’infrastructure en tant que code (IaC), telles que des fichiers Bicep, des modèles ARM ou un fichier de configuration Terraform. L’utilisation d’IaC réduit le délai de récupération et le risque d’erreur, par rapport au déploiement et à la configuration manuels des ressources.
Tests et exercices
Il est essentiel de valider et de tester régulièrement vos plans de récupération d’urgence, ainsi que votre stratégie de fiabilité plus large. Incluez tous les processus humains dans vos exercices et ne vous concentrez pas uniquement sur les processus techniques.
Si vous n’avez pas testé vos processus de récupération dans une simulation d’urgence, vous êtes plus susceptible de rencontrer des problèmes majeurs lors de leur utilisation en cas de sinistre réel. En outre, en testant vos plans de récupération d’urgence et vos processus requis, vous pouvez valider la faisabilité de votre RTO.
Pour plus d’informations, consultez Suggestions relatives à la conception d’une stratégie de test de fiabilité.
Contenu connexe
- Utilisez les guides de fiabilité des services Azure pour comprendre comment chaque service Azure prend en charge la fiabilité dans sa conception et pour en savoir plus sur les fonctionnalités que vous pouvez créer dans vos plans de haute disponibilité et de récupération d’urgence.
- Utilisez Azure Well-Architected Framework : pilier de fiabilité pour en savoir plus sur la conception d’une charge de travail fiable sur Azure.
- Utilisez la perspective Well-Architected Framework sur les services Azure pour en savoir plus sur la façon de configurer chaque service Azure afin de répondre à vos besoins en matière de fiabilité et sur les autres piliers de Well-Architected Framework.
- Pour en savoir plus sur la planification de la récupération d’urgence, consultez Suggestions relatives à la conception d’une stratégie de récupération d’urgence.