Journaliser et afficher les métriques et les fichiers journaux v1
S’APPLIQUE À :  SDK Python azureml v1
SDK Python azureml v1
Consignez des informations en temps réel en utilisant à la fois le package de journalisation Python par défaut et les fonctionnalités au Kit de développement logiciel (SDK) Python Azure Machine Learning. Vous pouvez journaliser en local et envoyer des journaux à votre espace de travail dans le portail.
Les journaux peuvent vous aider à diagnostiquer les erreurs et les avertissements, ou à effectuer le suivi des métriques de performances, telles que les paramètres et les performances du modèle. Dans cet article, vous allez apprendre à activer la journalisation dans les scénarios suivants :
- Journalisation des métriques d’exécution
- Sessions de formation interactives
- Envoi de travaux de formation à l’aide de ScriptRunConfig
- Paramètres
loggingnatifs Python - Journalisation à partir de sources supplémentaires
Conseil
Cet article explique comment surveiller le processus de formation du modèle. Si vous êtes intéressé par la supervision de l’utilisation de ressources et d’événements de Azure Machine Learning, comme des quotas, des cycles de formation accomplis ou des modèles de déploiement effectués, consultez Supervision de Azure Machine Learning.
Types de données
Vous pouvez journaliser plusieurs types de données, notamment des valeurs scalaires, des listes, des tableaux, des images, des répertoires, etc. Pour plus d’informations et pour obtenir des exemples de code Python pour différents types de données, consultez la page Exécuter la référence de classe.
Journalisation des métriques d’exécution
Utilisez les méthodes suivantes dans les API de journalisation pour influencer les visualisations des métriques. Notez les limites de service pour ces métriques journalisées.
| Valeur connectée | Exemple de code | Format dans le portail |
|---|---|---|
| Journaliser un tableau de valeurs numériques | run.log_list(name='Fibonacci', value=[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]) |
graphique en courbes à variable unique |
| Journaliser une valeur numérique avec le même nom de métrique utilisé à plusieurs reprises (comme à l’intérieur d’une boucle for) | for i in tqdm(range(-10, 10)): run.log(name='Sigmoid', value=1 / (1 + np.exp(-i))) angle = i / 2.0 |
Graphique en courbes à variable unique |
| Journaliser une ligne avec 2 colonnes numériques à plusieurs reprises | run.log_row(name='Cosine Wave', angle=angle, cos=np.cos(angle)) sines['angle'].append(angle) sines['sine'].append(np.sin(angle)) |
Graphique en courbes à deux variables |
| Journaliser un table avec 2 colonnes numériques | run.log_table(name='Sine Wave', value=sines) |
Graphique en courbes à deux variables |
| Journaliser une image | run.log_image(name='food', path='./breadpudding.jpg', plot=None, description='desert') |
Utilisez cette méthode pour consigner un fichier image ou un tracé matplotlib dans l’exécution. Ces images seront visibles et comparables dans l’enregistrement d’exécution. |
Journalisation avec MLflow
Nous vous recommandons de journaliser vos modèles, métriques et artefacts avec MLflow, car il est open source et prend en charge le mode local pour la portabilité du cloud. Le tableau et les exemples de code suivants montrent comment utiliser MLflow pour journaliser des métriques et des artefacts à partir de vos exécutions de formation. En savoir plus sur les méthodes de journalisation et les modèles de conception de MLflow.
Veillez à installer les packages pip mlflow et azureml-mlflow dans votre espace de travail.
pip install mlflow
pip install azureml-mlflow
Définissez l’URI de suivi MLflow pour qu’il pointe vers le back-end Azure Machine Learning afin de vous assurer que vos métriques et vos artefacts sont journalisés dans votre espace de travail.
from azureml.core import Workspace
import mlflow
from mlflow.tracking import MlflowClient
ws = Workspace.from_config()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.create_experiment("mlflow-experiment")
mlflow.set_experiment("mlflow-experiment")
mlflow_run = mlflow.start_run()
| Valeur connectée | Exemple de code | Notes |
|---|---|---|
| Journaliser une valeur numérique (int ou float) | mlflow.log_metric('my_metric', 1) |
|
| Journaliser une valeur booléenne | mlflow.log_metric('my_metric', 0) |
0 = True, 1 = False |
| Journaliser une chaîne | mlflow.log_text('foo', 'my_string') |
Journalisé en tant qu’artefact |
| Journaliser les métriques numpy ou les objets d’image PIL | mlflow.log_image(img, 'figure.png') |
|
| Journaliser un fichier image ou un tracé matlotlib | mlflow.log_figure(fig, "figure.png") |
Afficher les métriques d’exécution via le kit SDK
Vous pouvez afficher les métriques d’un modèle entraîné à l’aide de run.get_metrics().
from azureml.core import Run
run = Run.get_context()
run.log('metric-name', metric_value)
metrics = run.get_metrics()
# metrics is of type Dict[str, List[float]] mapping metric names
# to a list of the values for that metric in the given run.
metrics.get('metric-name')
# list of metrics in the order they were recorded
Vous pouvez également accéder aux informations d’exécution à l’aide de MLflow via les propriétés d’informations et les données de l’objet d’exécution. Pour plus d’informations, consultez la documentation Objet MLflow.entities.Run.
Une fois l’exécution terminée, vous pouvez la récupérer à l’aide de MlFlowClient().
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
finished_mlflow_run = MlflowClient().get_run(mlflow_run.info.run_id)
Vous pouvez afficher les métriques, les paramètres et les balises pour l’exécution dans le champ de données de l’objet d’exécution.
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
Notes
Le dictionnaire des métriques sous mlflow.entities.Run.data.metrics ne retourne que la dernière valeur journalisée pour un nom de métrique donné. Par exemple, si vous journalisez, dans l’ordre, 1, puis 2, puis 3, puis 4 sur une métrique appelée sample_metric, seule la valeur 4 est présente dans le dictionnaire des métriques pour sample_metric.
Pour obtenir toutes les mesures journalisées pour un nom de métrique spécifique, vous pouvez utiliser MlFlowClient.get_metric_history().
Afficher les métriques d’exécution dans l’IU du studio
Vous pouvez parcourir les enregistrements d’exécution terminés, notamment les mesures journalisées, dans le studio Azure Machine Learning.
Accédez à l’onglet Expériences. Pour afficher toutes les exécutions de votre espace de travail dans Expériences, sélectionnez l’onglet Toutes les exécutions. Vous pouvez explorer les exécutions au niveau du détail pour des Expériences spécifiques en appliquant le filtre Expérience dans la barre de menus supérieure.
Pour l’affichage individuel de l’Expérience, sélectionnez l’onglet Toutes les expériences. Dans le tableau de bord d’exécution d’expérience, vous pouvez voir les journaux et les métriques suivis pour chaque exécution.
Vous pouvez également modifier la table de la liste d’exécution pour sélectionner plusieurs exécutions et afficher la valeur la plus récente, la valeur minimale ou la valeur maximale du journal pour vos exécutions. Personnalisez vos graphiques pour comparer les valeurs des mesures journalisées et les agrégats sur plusieurs exécutions. Vous pouvez tracer plusieurs métriques sur l’axe Y de votre graphique et personnaliser l’axe X pour tracer vos mesures consignées.
Afficher et télécharger des fichiers journaux pour une exécution
Les fichiers journaux sont une ressource essentielle pour déboguer les charges de travail Azure Machine Learning. Après avoir soumis un travail de formation, descendez dans la hiérarchie jusqu’à une exécution spécifique pour afficher ses journaux et ses sorties :
- Accédez à l’onglet Expériences.
- Sélectionnez le runID associé à une exécution spécifique.
- Sélectionnez Sorties + journaux en haut de la page.
- Sélectionnez Télécharger tout pour télécharger tous vos journaux dans un dossier zip.
- Vous pouvez également télécharger des fichiers journaux individuellement en choisissant le fichier journal et en sélectionnant Télécharger.
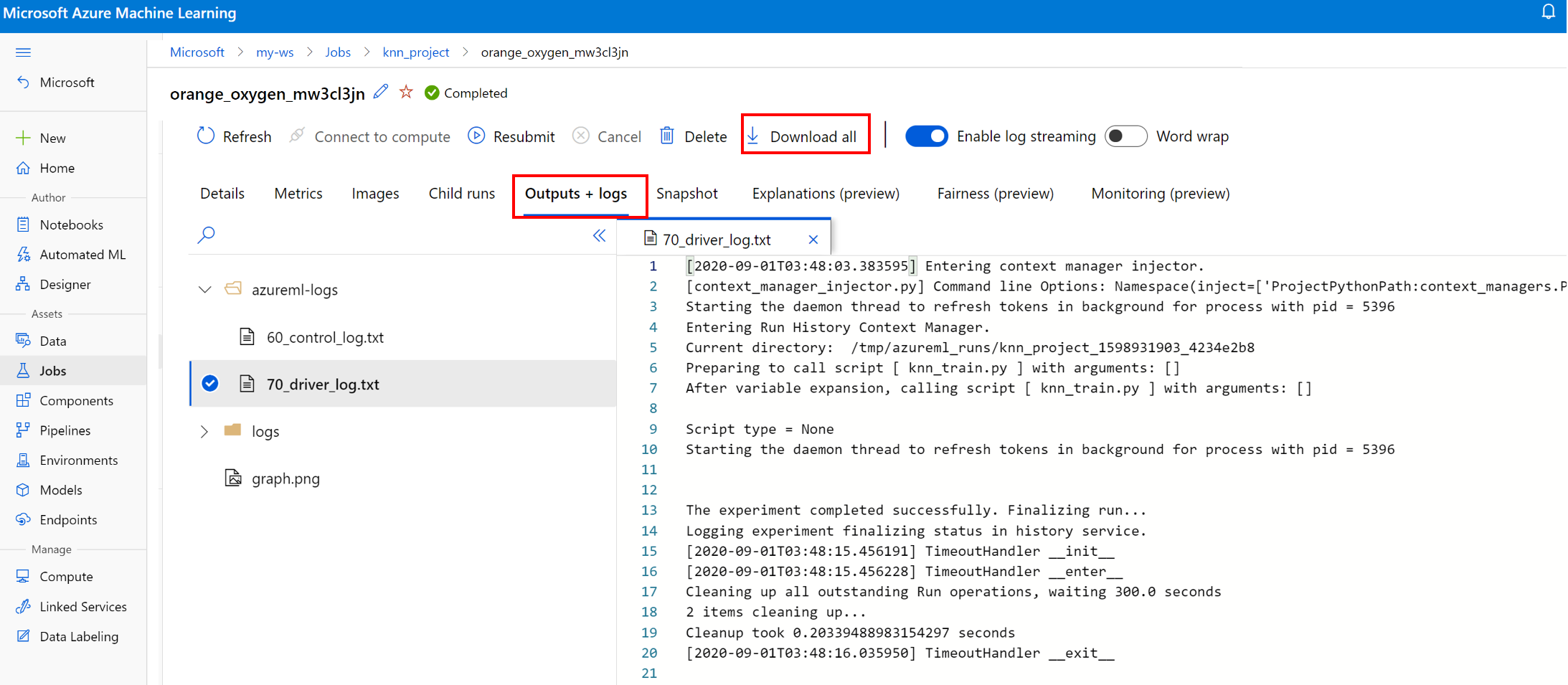
Dossier user_logs
Ce dossier contient des informations sur les journaux générés par l’utilisateur. Ce dossier est ouvert par défaut, et le journal std_log.txt est sélectionné. Les journaux de votre code (par exemple, les instructions print) apparaissent dans std_log.txt. Ce fichier contient le journal stdout et les journaux stderr de vos script de contrôle et script de formation, un par processus. Dans la majorité des cas, c’est là que vous supervisez les journaux.
Dossier system_logs
Ce dossier contient les journaux générés par Azure Machine Learning et il sera fermé par défaut. Les journaux générés par le système sont regroupés dans différents dossiers, en fonction de la phase du travail dans le runtime.
Autres dossiers
Pour les travaux qui effectuent un entraînement sur des clusters multicalculs, les journaux sont présents pour chaque adresse IP de nœud. La structure de chaque nœud est identique à celle des travaux mononœuds. Il existe un autre dossier de journaux pour les journaux stderr, stdout et d’exécution générale.
Azure Machine Learning consigne les informations provenant de diverses sources pendant la formation, telles qu’AutoML ou le conteneur Docker qui exécute le travail de formation. La plupart de ces journaux ne sont pas documentés. Si vous rencontrez des problèmes et que vous contactez le support Microsoft, il pourra peut-être utiliser ces journaux pendant la résolution des problèmes.
Session de journalisation interactive
Les sessions de journalisation interactives sont généralement utilisées dans les environnements notebook. La méthode Experiment.start_logging() démarre une session de journalisation interactive. Toutes les métriques qui sont consignées pendant la session sont ajoutées à l’enregistrement d’exécution dans l’expérience. La méthode run.complete() met fin aux sessions et marque l’exécution comme terminée.
Journaux ScriptRun
Dans cette section, vous découvrirez comment ajouter un code de journalisation au sein des exécutions créées lorsque la configuration est effectuée avec ScriptRunConfig. Vous pouvez utiliser la classe ScriptRunConfig pour encapsuler des scripts et des environnements pour des exécutions reproductibles. Vous pouvez également utiliser cette option pour afficher un widget Jupyter Notebook visuel pour la surveillance.
Cet exemple effectue un balayage de paramètre sur des valeurs alpha et capture les résultats à l’aide de la méthode run.log().
Créez un script de formation incluant la logique de journalisation,
train.py.# Copyright (c) Microsoft. All rights reserved. # Licensed under the MIT license. from sklearn.datasets import load_diabetes from sklearn.linear_model import Ridge from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split from azureml.core.run import Run import os import numpy as np import mylib # sklearn.externals.joblib is removed in 0.23 try: from sklearn.externals import joblib except ImportError: import joblib os.makedirs('./outputs', exist_ok=True) X, y = load_diabetes(return_X_y=True) run = Run.get_context() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) data = {"train": {"X": X_train, "y": y_train}, "test": {"X": X_test, "y": y_test}} # list of numbers from 0.0 to 1.0 with a 0.05 interval alphas = mylib.get_alphas() for alpha in alphas: # Use Ridge algorithm to create a regression model reg = Ridge(alpha=alpha) reg.fit(data["train"]["X"], data["train"]["y"]) preds = reg.predict(data["test"]["X"]) mse = mean_squared_error(preds, data["test"]["y"]) run.log('alpha', alpha) run.log('mse', mse) model_file_name = 'ridge_{0:.2f}.pkl'.format(alpha) # save model in the outputs folder so it automatically get uploaded with open(model_file_name, "wb") as file: joblib.dump(value=reg, filename=os.path.join('./outputs/', model_file_name)) print('alpha is {0:.2f}, and mse is {1:0.2f}'.format(alpha, mse))Envoyez le script
train.pyà exécuter dans un environnement géré par l’utilisateur. L’intégralité du dossier de script est soumise pour la formation.from azureml.core import ScriptRunConfig src = ScriptRunConfig(source_directory='./scripts', script='train.py', environment=user_managed_env)run = exp.submit(src)Le paramètre
show_outputactive la journalisation détaillée, qui vous permet d’afficher les détails du processus de formation, ainsi que des informations sur les éventuelles cibles de calcul ou ressources à distance. Utilisez le code suivant pour activer la journalisation détaillée lorsque vous soumettez l’expérience.run = exp.submit(src, show_output=True)Vous pouvez également utiliser le même paramètre dans la fonction
wait_for_completionlors de l’exécution qui en résulte.run.wait_for_completion(show_output=True)
Journalisation Python native
Certains journaux du Kit de développement logiciel (SDK) risquent de contenir une erreur qui exige de définir le niveau de journalisation sur DÉBOGAGE. Pour définir le niveau de journalisation, ajoutez le code suivant à votre script.
import logging
logging.basicConfig(level=logging.DEBUG)
Autres sources de journalisation
Azure Machine Learning peut aussi consigner des informations provenant d’autres sources pendant la formation, notamment les exécutions du Machine Learning automatisé ou des conteneurs Docker qui exécutent les travaux. Ces journaux ne sont pas documentés, mais si vous rencontrez des problèmes et contactez le support Microsoft, il pourra peut-être utiliser ces journaux pendant la résolution des problèmes.
Pour plus d’informations sur la journalisation des métriques dans le concepteur Azure Machine Learning, consultez Comment journaliser des métriques dans le concepteur
Exemples de notebooks
Les notebooks suivants illustrent les concepts de cet article :
- how-to-use-azureml/training/train-on-local
- how-to-use-azureml/track-and-monitor-experiments/logging-api
Découvrez comment exécuter des notebooks dans l’article Utiliser des notebooks Jupyter pour explorer ce service.
Étapes suivantes
Consultez ces articles pour en savoir plus sur l’utilisation d’Azure Machine Learning :
- Examinez un exemple d’inscription et de déploiement du meilleur modèle dans le tutoriel Entraîner un modèle de classification d’images avec Azure Machine Learning.