Tutoriel : Partie 3 - Évaluer une application de conversation personnalisée avec le Kit de développement logiciel (SDK) Azure AI Foundry
Dans ce tutoriel, vous utilisez le Kit de développement logiciel (SDK) Azure AI (et d’autres bibliothèques) pour évaluer l’application de conversation que vous avez créée Partie 2 de la série de didacticiels. Dans cette troisième partie, vous allez apprendre à :
- Créer un jeu de données d’évaluation
- Évaluer l’application de conversation avec les programmes d’évaluation Azure AI
- Itérer et améliorer votre application
Ce tutoriel est la troisième partie de tutoriels qui en compte trois.
Prérequis
- Suivre la deuxième partie de cette série de tutoriels pour générer l’application de conversation.
- Vérifiez que vous avez terminé les étapes permettant d’ajouter la journalisation des données de télémétrie de la partie 2.
Évaluer la qualité des réponses des applications de conversation
Maintenant que vous savez que votre application de conversation répond bien à vos requêtes, y compris avec l’historique des conversations, il est temps d’évaluer ses performances avec quelques métriques différentes et davantage de données.
Vous utilisez un évaluateur avec un jeu de données d’évaluation et la fonction cible get_chat_response(), puis évaluez les résultats de l’évaluation.
Une fois que vous avez exécuté une évaluation, vous pouvez apporter des améliorations à votre logique, comme améliorer votre prompt système et observer comment les réponses de l’application de conversation changent et s’améliorent.
Créer un jeu de données d’évaluation
Utilisez le jeu de données d’évaluation suivant, qui contient des exemples de questions et des réponses attendues (vérité).
Créez un fichier appelé chat_eval_data.jsonl dans votre dossier de ressources.
Collez ce jeu de données dans le fichier :
{"query": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"query": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"query": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"query": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"query": "What brand is TrailMaster tent? ", "truth": "OutdoorLiving"} {"query": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"query": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"query": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"query": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"query": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"query": "How long are the TrailBlaze pants under warranty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"query": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"query": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
Évaluer avec les évaluateurs Azure AI
Définissez maintenant un script d’évaluation qui :
- Génère un wrapper de fonction cible autour de notre logique d’application de conversation.
- Charge l’exemple de jeu de données
.jsonl. - Exécute l’évaluation, autrement dit qui prend la fonction cible et fusionne le jeu de données d’évaluation avec les réponses de l’application de conversation.
- Générer un ensemble de mesures assistées par GPT (pertinence, ancrage et cohérence) pour évaluer la qualité des réponses de l’application de conversation.
- Affiche les résultats localement, et consigne les résultats dans le projet cloud.
Le script vous permet de passer en revue les résultats localement, en plaçant les résultats sur la ligne de commande et dans un fichier json.
Le script consigne également les résultats de l’évaluation dans le projet cloud afin que vous puissiez comparer les exécutions d’évaluation dans l’interface utilisateur.
Créez un fichier appelé evaluate.py dans votre dossier principal.
Ajoutez le code suivant pour importer les bibliothèques requises, créer un client de projet et configurer certains paramètres :
import os import pandas as pd from azure.ai.projects import AIProjectClient from azure.ai.projects.models import ConnectionType from azure.ai.evaluation import evaluate, GroundednessEvaluator from azure.identity import DefaultAzureCredential from chat_with_products import chat_with_products # load environment variables from the .env file at the root of this repo from dotenv import load_dotenv load_dotenv() # create a project client using environment variables loaded from the .env file project = AIProjectClient.from_connection_string( conn_str=os.environ["AIPROJECT_CONNECTION_STRING"], credential=DefaultAzureCredential() ) connection = project.connections.get_default(connection_type=ConnectionType.AZURE_OPEN_AI, include_credentials=True) evaluator_model = { "azure_endpoint": connection.endpoint_url, "azure_deployment": os.environ["EVALUATION_MODEL"], "api_version": "2024-06-01", "api_key": connection.key, } groundedness = GroundednessEvaluator(evaluator_model)Ajoutez du code pour créer une fonction wrapper qui implémente l’interface d’évaluation pour l’évaluation des requêtes et des réponses :
def evaluate_chat_with_products(query): response = chat_with_products(messages=[{"role": "user", "content": query}]) return {"response": response["message"].content, "context": response["context"]["grounding_data"]}Enfin, ajoutez du code pour exécuter l’évaluation, visualisez les résultats localement, et utilisez le lien fourni vers les résultats de l’évaluation dans le portail Azure AI Foundry :
# Evaluate must be called inside of __main__, not on import if __name__ == "__main__": from config import ASSET_PATH # workaround for multiprocessing issue on linux from pprint import pprint from pathlib import Path import multiprocessing import contextlib with contextlib.suppress(RuntimeError): multiprocessing.set_start_method("spawn", force=True) # run evaluation with a dataset and target function, log to the project result = evaluate( data=Path(ASSET_PATH) / "chat_eval_data.jsonl", target=evaluate_chat_with_products, evaluation_name="evaluate_chat_with_products", evaluators={ "groundedness": groundedness, }, evaluator_config={ "default": { "query": {"${data.query}"}, "response": {"${target.response}"}, "context": {"${target.context}"}, } }, azure_ai_project=project.scope, output_path="./myevalresults.json", ) tabular_result = pd.DataFrame(result.get("rows")) pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
Configurer le modèle d’évaluation
Étant donné que le script d’évaluation appelle le modèle plusieurs fois, vous pouvez augmenter le nombre de jetons par minute pour le modèle d’évaluation.
Dans la partie 1 de cette série de tutoriels, vous avez créé un fichier .env qui spécifie le nom du modèle d’évaluation, gpt-4o-mini. Essayez d’augmenter la limite de jetons par minute pour ce modèle, si vous disposez d’un quota disponible. Si vous n’avez pas suffisamment de quota pour augmenter la valeur, ne vous inquiétez pas. Le script est conçu pour gérer les erreurs de limite.
- Dans votre projet dans le portail Azure AI Foundry, sélectionnez Modèles + points de terminaison.
- Sélectionnez gpt-4o-mini.
- Sélectionnez Modifier.
- Si vous avez un quota pour augmenter la limite de débit des jetons par minute, essayez de l’augmenter à 30.
- Sélectionnez Enregistrer et fermer.
Exécuter le script d’évaluation
À partir de votre console, connectez-vous à votre compte Azure avec Azure CLI :
az loginInstallez le package requis :
pip install azure-ai-evaluation[remote]Exécutez maintenant le script d’évaluation :
python evaluate.py
Interpréter la sortie d’évaluation
Dans la sortie de la console, vous voyez une réponse pour chaque question, suivie d’un tableau avec des métriques résumées. (Votre sortie peut comporter des colonnes différentes.)
Si vous n’avez pas pu augmenter la limite de jetons par minute pour votre modèle, des erreurs de délai d’attente peuvent s’afficher, qui sont attendues. Le script d’évaluation est conçu pour gérer ces erreurs et continuer à s’exécuter.
Remarque
Vous pouvez également voir de nombreuses WARNING:opentelemetry.attributes: : elles peuvent être ignorées en toute sécurité et n’affectent pas les résultats de l’évaluation.
====================================================
'-----Summarized Metrics-----'
{'groundedness.gpt_groundedness': 1.6666666666666667,
'groundedness.groundedness': 1.6666666666666667}
'-----Tabular Result-----'
outputs.response ... line_number
0 Could you specify which tent you are referring... ... 0
1 Could you please specify which camping table y... ... 1
2 Sorry, I only can answer queries related to ou... ... 2
3 Could you please clarify which aspects of care... ... 3
4 Sorry, I only can answer queries related to ou... ... 4
5 The TrailMaster X4 Tent comes with an included... ... 5
6 (Failed) ... 6
7 The TrailBlaze Hiking Pants are crafted from h... ... 7
8 Sorry, I only can answer queries related to ou... ... 8
9 Sorry, I only can answer queries related to ou... ... 9
10 Sorry, I only can answer queries related to ou... ... 10
11 The PowerBurner Camping Stove is designed with... ... 11
12 Sorry, I only can answer queries related to ou... ... 12
[13 rows x 8 columns]
('View evaluation results in Azure AI Foundry portal: '
'https://xxxxxxxxxxxxxxxxxxxxxxx')
Afficher les résultats d’une évaluation sur le portail Azure AI Foundry
Une fois l’exécution de l’évaluation terminée, suivez le lien pour afficher les résultats de l’évaluation dans la page Évaluation dans le portail Azure AI Foundry.
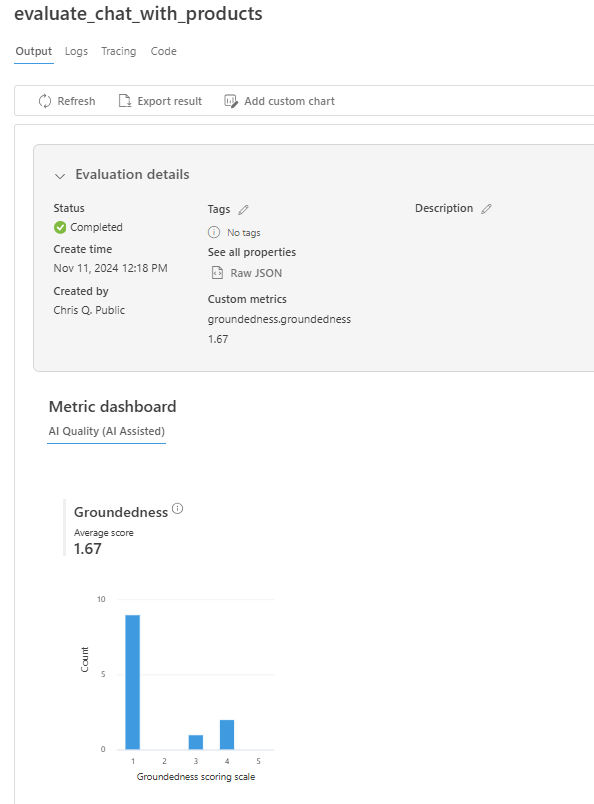
Vous pouvez également examiner chacune des lignes et afficher les scores de métriques par ligne, et afficher le contexte complet/les documents récupérés. Ces métriques peuvent être utiles pour interpréter et déboguer les résultats de l’évaluation.
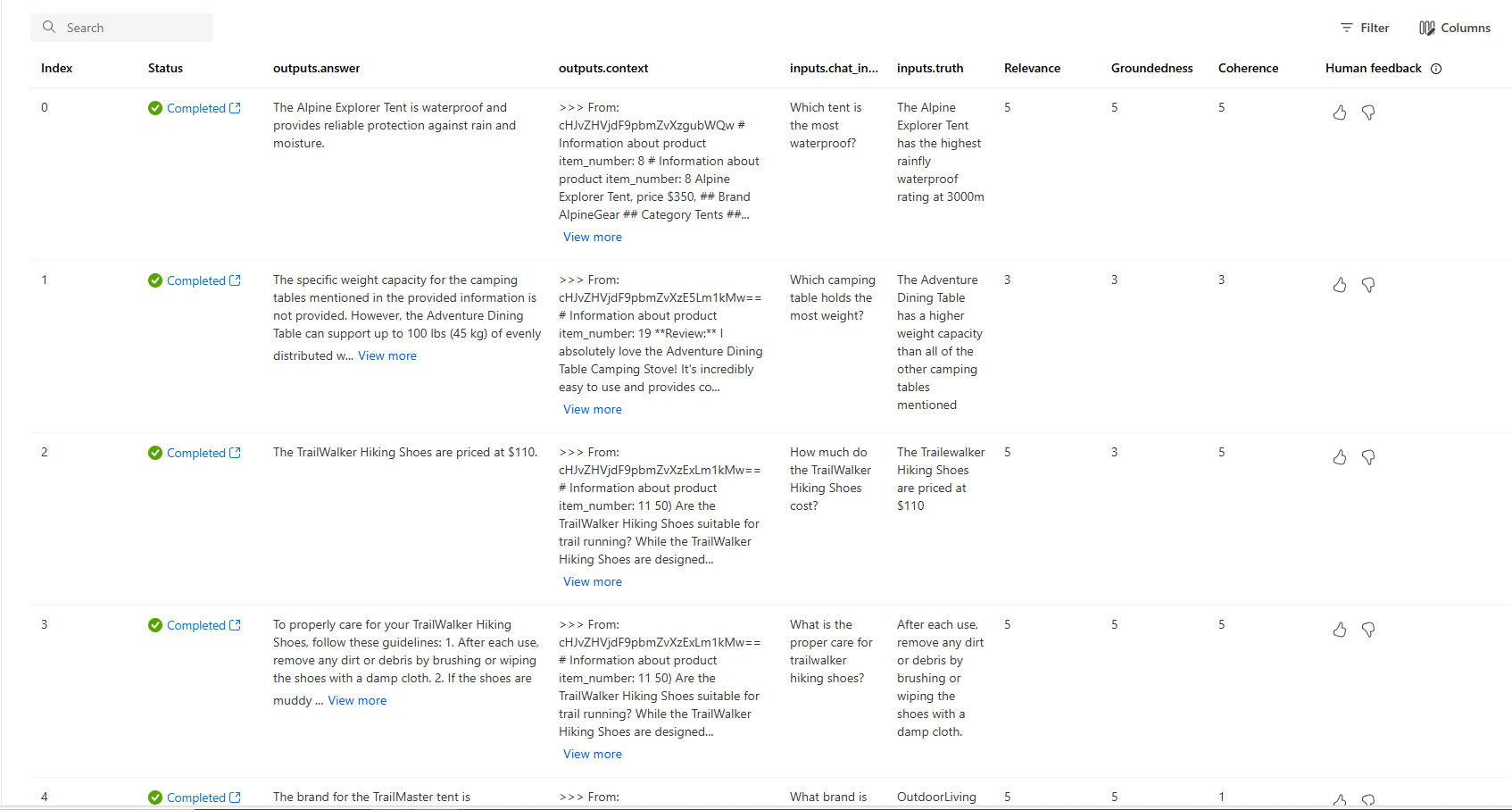
Pour plus d’informations sur les résultats de l’évaluation dans le portail Azure AI Foundry, consultez Comment afficher les résultats d’une évaluation dans le portail Azure AI Foundry.
Itérer et améliorer
Remarquez que les réponses ne sont pas bien fondées. Dans de nombreux cas, le modèle répond par une question au lieu de fournir une réponse. Il s’agit du résultat des instructions du modèle de requête.
- Dans votre fichier assets/grounded_chat.prompty, recherchez la phrase « Si la question concerne des vêtements et équipements de camping/d’extérieur, mais qu’elle est vague, poser des questions pour obtenir des précisions au lieu de faire référence à des documents. »
- Remplacez la phrase par « Si la question concerne des vêtements et équipements de camping/d’extérieur, mais qu’elle est vague, essayez de répondre en fonction des documents de référence, puis poser des questions pour obtenir des précisions. »
- Enregistrez le fichier et exécutez à nouveau le script d’évaluation.
Tentez d’apporter d’autres modifications au modèle de requête, ou essayez d’autres modèles pour voir comment les modifications affectent les résultats de l’évaluation.
Nettoyer les ressources
Pour éviter la facturation de coûts Azure inutiles, vous devez supprimer les ressources créées dans ce tutoriel si elles ne sont plus nécessaires. Pour gérer les ressources, vous pouvez utiliser le Portail Microsoft Azure.