Développer des applications avec Semantic Kernel et Azure AI Foundry
Dans cet article, vous allez découvrir comment utiliser Semantic Kernel avec des modèles déployés à partir du catalogue de modèles Azure AI dans le portail Azure AI Foundry.
Prérequis
Un abonnement Azure.
Un projet Azure AI, comme expliqué dans Créer un projet dans le portail Azure AI Foundry.
Modèle prenant en charge l’API d’inférence de modèle Azure AI déployée. Dans cet exemple, nous utilisons un déploiement
Mistral-Large, mais nous utilisons le modèle de votre choix. Pour utiliser des fonctionnalités d’incorporation dans LlamaIndex, vous avez besoin d’un modèle d’incorporation commecohere-embed-v3-multilingual.- Vous pouvez suivre les instructions fournies dans l’article Déployer des modèles en tant qu’API serverless.
Python 3.10 ou version ultérieure installée, y compris pip.
Semantic Kernel installé. Vous pouvez le faire avec :
pip install semantic-kernelDans cet exemple, nous travaillons avec l’API d’inférence de modèle Azure AI. Nous installons donc les dépendances Azure pertinentes. Vous pouvez le faire avec :
pip install semantic-kernel[azure]
Configurer l’environnement
Pour utiliser des grands modèles de langage (LLM) déployés dans le portail Azure AI Foundry, vous avez besoin du point de terminaison et des informations d’identification pour vous y connecter. Pour obtenir les informations dont vous avez besoin à partir du modèle que vous souhaitez utiliser, procédez comme suit :
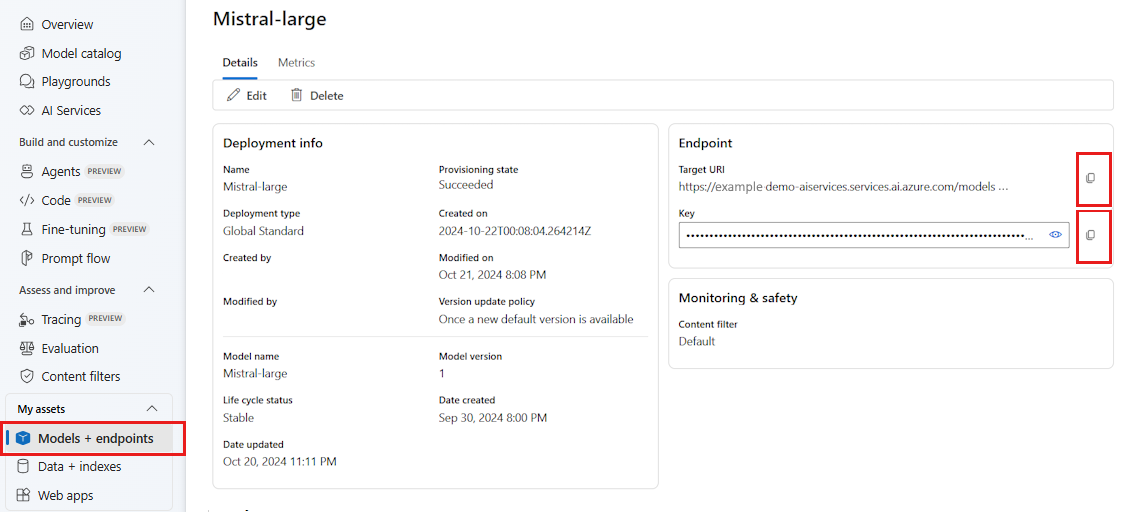
Accédez au portail Azure AI Foundry.
Ouvrez le projet dans lequel le modèle est déployé, s’il n’est pas déjà ouvert.
Accédez à Modèles + points de terminaison et sélectionnez le modèle que vous avez déployé, comme indiqué dans les prérequis.
Copiez l’URL et la clé du point de terminaison.
Conseil
Si votre modèle a été déployé avec la prise en charge de Microsoft Entra ID, vous n’avez pas besoin de clé.

Dans ce scénario, nous avons placé à la fois l’URL et la clé du point de terminaison dans les variables d’environnement suivantes :
export AZURE_AI_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_AI_INFERENCE_API_KEY="<your-key-goes-here>"
Une fois configuré, créez un client pour vous connecter au point de terminaison :
from semantic_kernel.connectors.ai.azure_ai_inference import AzureAIInferenceChatCompletion
chat_completion_service = AzureAIInferenceChatCompletion(ai_model_id="<deployment-name>")
Conseil
Le client lit automatiquement les variables d’environnement AZURE_AI_INFERENCE_ENDPOINT et AZURE_AI_INFERENCE_API_KEY pour se connecter au modèle. Toutefois, vous pouvez également passer le point de terminaison et la clé directement au client via les paramètres endpoint et api_key sur le constructeur.
Sinon, si votre point de terminaison prend en charge Microsoft Entra ID, vous pouvez utiliser le code suivant pour créer le client :
export AZURE_AI_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
from semantic_kernel.connectors.ai.azure_ai_inference import AzureAIInferenceChatCompletion
chat_completion_service = AzureAIInferenceChatCompletion(ai_model_id="<deployment-name>")
Remarque
Quand vous utilisez Microsoft Entra ID, vérifiez que le point de terminaison a été déployé avec cette méthode d’authentification, et que vous disposez des autorisations nécessaires pour l’appeler.
Modèles Azure OpenAI
Si vous utilisez un modèle Azure OpenAI, vous pouvez utiliser le code suivant pour créer le client :
from azure.ai.inference.aio import ChatCompletionsClient
from azure.identity.aio import DefaultAzureCredential
from semantic_kernel.connectors.ai.azure_ai_inference import AzureAIInferenceChatCompletion
chat_completion_service = AzureAIInferenceChatCompletion(
ai_model_id="<deployment-name>",
client=ChatCompletionsClient(
endpoint=f"{str(<your-azure-open-ai-endpoint>).strip('/')}/openai/deployments/{<deployment_name>}",
credential=DefaultAzureCredential(),
credential_scopes=["https://cognitiveservices.azure.com/.default"],
),
)
Paramètres d’inférence
Vous pouvez configurer la façon dont l’inférence est effectuée en utilisant la classe AzureAIInferenceChatPromptExecutionSettings :
from semantic_kernel.connectors.ai.azure_ai_inference import AzureAIInferenceChatPromptExecutionSettings
execution_settings = AzureAIInferenceChatPromptExecutionSettings(
max_tokens=100,
temperature=0.5,
top_p=0.9,
# extra_parameters={...}, # model-specific parameters
)
Appel du service
Commençons par appeler le service de saisie semi-automatique de conversation avec un historique des conversations simple :
Conseil
Semantic Kernel étant une bibliothèque asynchrone, vous devez utiliser la bibliothèque asyncio pour exécuter le code.
import asyncio
async def main():
...
if __name__ == "__main__":
asyncio.run(main())
from semantic_kernel.contents.chat_history import ChatHistory
chat_history = ChatHistory()
chat_history.add_user_message("Hello, how are you?")
response = await chat_completion_service.get_chat_message_content(
chat_history=chat_history,
settings=execution_settings,
)
print(response)
Vous pouvez également diffuser en continu la réponse du service :
chat_history = ChatHistory()
chat_history.add_user_message("Hello, how are you?")
response = chat_completion_service.get_streaming_chat_message_content(
chat_history=chat_history,
settings=execution_settings,
)
chunks = []
async for chunk in response:
chunks.append(chunk)
print(chunk, end="")
full_response = sum(chunks[1:], chunks[0])
Créer une conversation de longue durée
Vous pouvez créer une conversation de longue durée à l’aide d’une boucle :
while True:
response = await chat_completion_service.get_chat_message_content(
chat_history=chat_history,
settings=execution_settings,
)
print(response)
chat_history.add_message(response)
chat_history.add_user_message(user_input = input("User:> "))
Si vous diffusez la réponse en continu, vous pouvez utiliser le code suivant :
while True:
response = chat_completion_service.get_streaming_chat_message_content(
chat_history=chat_history,
settings=execution_settings,
)
chunks = []
async for chunk in response:
chunks.append(chunk)
print(chunk, end="")
full_response = sum(chunks[1:], chunks[0])
chat_history.add_message(full_response)
chat_history.add_user_message(user_input = input("User:> "))
Utiliser les modèles d’incorporations
Configurez votre environnement en procédant de la même façon que dans les étapes précédentes, mais utilisez la classe AzureAIInferenceEmbeddings :
from semantic_kernel.connectors.ai.azure_ai_inference import AzureAIInferenceTextEmbedding
embedding_generation_service = AzureAIInferenceTextEmbedding(ai_model_id="<deployment-name>")
Le code suivant montre comment obtenir des incorporations à partir du service :
embeddings = await embedding_generation_service.generate_embeddings(
texts=["My favorite color is blue.", "I love to eat pizza."],
)
for embedding in embeddings:
print(embedding)