Démarrage rapide : Commencer à utiliser la génération audio Azure OpenAI
Le modèle gpt-4o-audio-preview introduit la modalité audio dans l’API /chat/completions existante. Le modèle audio étend le potentiel des applications IA dans les interactions textuelles et vocales et les analyses audio. Les modalités prises en charge dans le modèle gpt-4o-audio-preview sont les suivantes : texte, audio et texte + audio.
Voici un tableau des modalités prises en charge avec des exemples de cas d’usage :
| Entrée de modalité | Sortie de la modalité | Exemple de cas d’usage |
|---|---|---|
| Détails | Texte + audio | Synthèse vocale, génération de livres audio |
| Audio | Texte + audio | Transcription audio, génération de livres audio |
| Audio | Détails | Transcription audio |
| Texte + audio | Texte + audio | Génération de livres audio |
| Texte + audio | Détails | Transcription audio |
En utilisant des fonctionnalités de génération audio, vous pouvez obtenir des applications IA plus dynamiques et interactives. Les modèles qui prennent en charge les entrées et sorties audio vous permettent de générer des réponses audio parlées aux invites et d’utiliser des entrées audio pour inviter le modèle.
Modèles pris en charge
Actuellement, seule la gpt-4o-audio-preview version : 2024-12-17 prend en charge la génération audio.
Le modèle gpt-4o-audio-preview est disponible pour les déploiements globaux dans les régions USA Est 2 et Suède Centre.
Actuellement, les voix suivantes sont prises en charge pour l’audio out : Alliage, Echo et Shimmer.
La taille maximale d'un fichier audio est de 20 Mo.
Remarque
L’API en temps réel utilise le même modèle audio GPT-4o sous-jacent que l’API de saisie semi-automatique, mais est optimisée pour les interactions audio à faible latence et en temps réel.
Prise en charge des API
La prise en charge des compléments audio a été ajoutée pour la première fois dans la version API 2025-01-01-preview.
Déployer un modèle de génération audio
Pour déployer le modèle gpt-4o-audio-preview dans le portail Azure AI Foundry :
- Accédez à la page Azure OpenAI Service dans le portail Azure AI Foundry. Vérifiez que vous êtes connecté avec l’abonnement Azure qui a votre ressource Azure OpenAI Service et le modèle
gpt-4o-audio-previewdéployé. - Sélectionnez le terrain de jeu Conversation sous Terrains de jeu dans le volet gauche.
- Sélectionnez + Créer un déploiement>À partir de modèles de base pour ouvrir la fenêtre de déploiement.
- Recherchez et sélectionnez le modèle
gpt-4o-audio-preview, puis sélectionnez Déployer sur une ressource sélectionnée. - Dans l’Assistant de déploiement, sélectionnez la version du modèle
2024-12-17. - Suivez l’Assistant pour terminer le déploiement du modèle.
Maintenant que vous disposez d’un déploiement du modèle gpt-4o-audio-preview, vous pouvez interagir avec lui en temps réel dans le terrain de jeu Conversation le portail Azure AI Foundry ou l’API Temps réel.
Utiliser la génération audio GPT-4o
Pour converser avec votre gpt-4o-audio-preview modèle déployé dans le terrain de jeu Conversation du portail Azure AI Foundry, procédez comme suit :
Accédez à la page Azure OpenAI Service dans le portail Azure AI Foundry. Vérifiez que vous êtes connecté avec l’abonnement Azure qui a votre ressource Azure OpenAI Service et le modèle
gpt-4o-audio-previewdéployé.Sélectionnez le terrain de jeux Conversation instantanée dans la rubrique Ressources de terrains de jeux dans le volet de gauche.
Sélectionnez votre modèle
gpt-4o-audio-previewdéployé dans la liste déroulante Déploiement.Commencez à converser avec le modèle et écoutez les réponses audio.
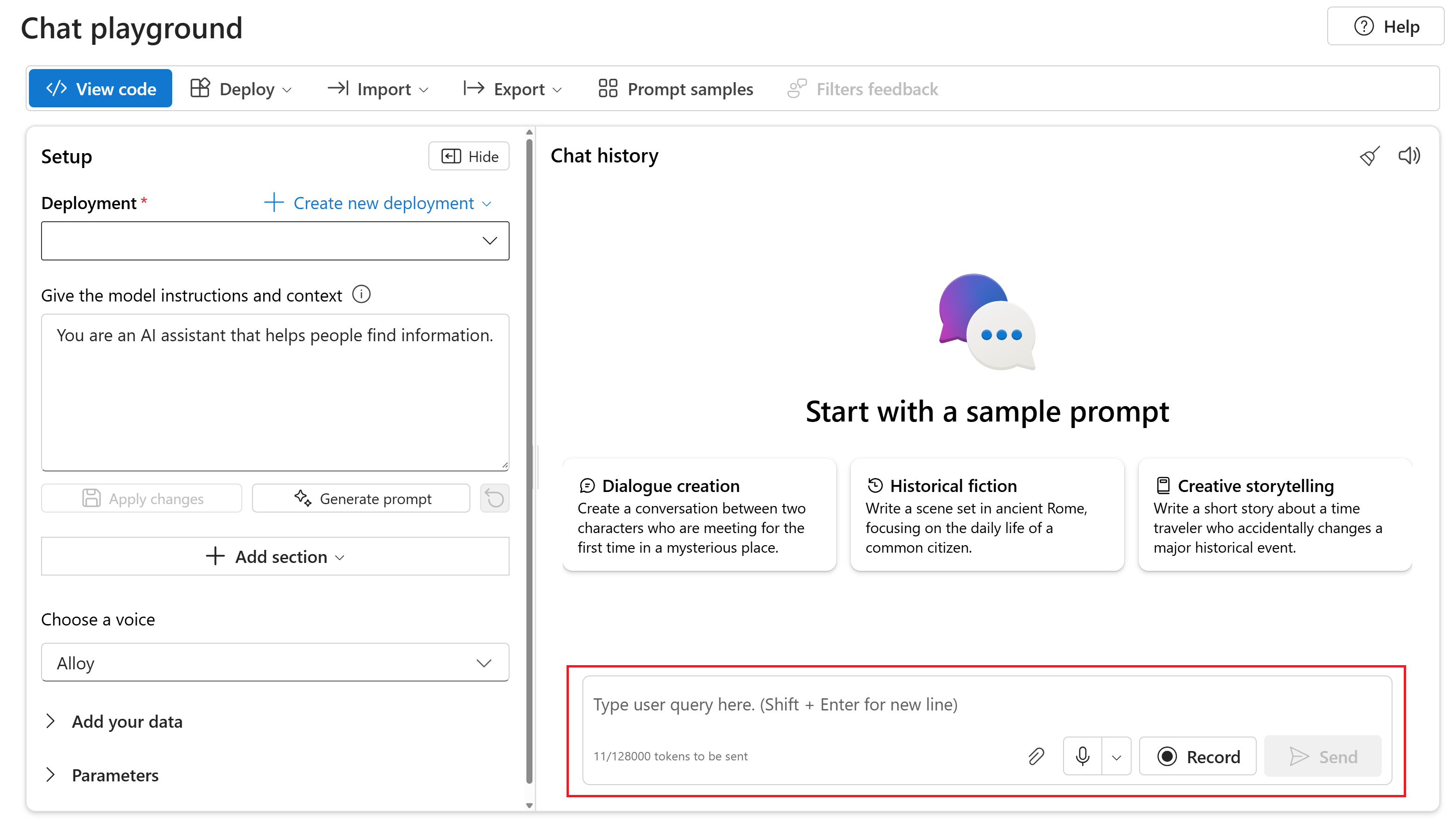
Vous pouvez :
- Enregistrez des invites audio.
- Joignez des fichiers audio à la conversation.
- Entrez des invites de texte.

Documentation de référence | Code source de la bibliothèque | Package (npm) | Exemples
Le modèle gpt-4o-audio-preview introduit la modalité audio dans l’API /chat/completions existante. Le modèle audio étend le potentiel des applications IA dans les interactions textuelles et vocales et les analyses audio. Les modalités prises en charge dans le modèle gpt-4o-audio-preview sont les suivantes : texte, audio et texte + audio.
Voici un tableau des modalités prises en charge avec des exemples de cas d’usage :
| Entrée de modalité | Sortie de la modalité | Exemple de cas d’usage |
|---|---|---|
| Détails | Texte + audio | Synthèse vocale, génération de livres audio |
| Audio | Texte + audio | Transcription audio, génération de livres audio |
| Audio | Détails | Transcription audio |
| Texte + audio | Texte + audio | Génération de livres audio |
| Texte + audio | Détails | Transcription audio |
En utilisant des fonctionnalités de génération audio, vous pouvez obtenir des applications IA plus dynamiques et interactives. Les modèles qui prennent en charge les entrées et sorties audio vous permettent de générer des réponses audio parlées aux invites et d’utiliser des entrées audio pour inviter le modèle.
Modèles pris en charge
Actuellement, seule la gpt-4o-audio-preview version : 2024-12-17 prend en charge la génération audio.
Le modèle gpt-4o-audio-preview est disponible pour les déploiements globaux dans les régions USA Est 2 et Suède Centre.
Actuellement, les voix suivantes sont prises en charge pour l’audio out : Alliage, Echo et Shimmer.
La taille maximale d'un fichier audio est de 20 Mo.
Remarque
L’API en temps réel utilise le même modèle audio GPT-4o sous-jacent que l’API de saisie semi-automatique, mais est optimisée pour les interactions audio à faible latence et en temps réel.
Prise en charge des API
La prise en charge des compléments audio a été ajoutée pour la première fois dans la version API 2025-01-01-preview.
Prérequis
- Un abonnement Azure - En créer un gratuitement
- Prise en charge de Node.js LTS ou ESM.
- Une ressource Azure OpenAI créée dans les régions USA Est 2 ou Suède Centre. Consultez Disponibilité dans les régions.
- Ensuite, vous devez déployer un modèle
gpt-4o-audio-previewavec votre ressource Azure OpenAI. Pour plus d’informations, consultez l’article Créer une ressource et déployer un modèle à l’aide d’Azure OpenAI.
Prérequis pour Microsoft Entra ID
Pour l’authentification sans clé recommandée avec Microsoft Entra ID, vous devez effectuer les tâches suivantes :
- Installez l’interface Azure CLI utilisée pour l’authentification sans clé avec Microsoft Entra ID.
- Attribuez le rôle
Cognitive Services Userà votre compte d’utilisateur. Vous pouvez attribuer des rôles dans le Portail Azure sous Contrôle d’accès (IAM)>Ajouter une attribution de rôle.
Configurer
Créez un dossier
audio-completions-quickstartpour contenir l’application et ouvrez Visual Studio Code dans ce dossier avec la commande suivante :mkdir audio-completions-quickstart && code audio-completions-quickstartCréez le
package.jsonavec la commande suivante :npm init -yMettez à jour le
package.jsonvers ECMAScript avec la commande suivante :npm pkg set type=moduleInstallez la bibliothèque de client OpenAI pour JavaScript avec :
npm install openaiPour l’authentification sans clé recommandée avec Microsoft Entra ID, installez le package
@azure/identityavec :npm install @azure/identity
Récupérer des informations sur les ressources
Vous devez récupérer les informations suivantes pour authentifier votre application auprès de votre ressource Azure OpenAI :
| Nom de la variable | Valeur |
|---|---|
AZURE_OPENAI_ENDPOINT |
Cette valeur se trouve dans la section Clés et point de terminaison quand vous examinez votre ressource à partir du portail Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Cette valeur correspond au nom personnalisé que vous avez choisi pour votre déploiement lorsque vous avez déployé un modèle. Cette valeur peut être trouvée dans le Portail Azure sous Gestion des ressources>Déploiements de modèles. |
OPENAI_API_VERSION |
En savoir plus sur les versions d’API. |
En savoir plus sur l’authentification sans clé et la définition de variables d’environnement.
Attention
Pour utiliser l’authentification sans clé recommandée avec le kit de développement logiciel (SDK), vérifiez que la variable d’environnement AZURE_OPENAI_API_KEY n’est pas définie.
Générer de l’audio à partir d’une entrée de texte
Remplacez le fichier
to-audio.jsavec le code suivant :require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Connectez-vous à Azure à l’aide de la commande suivante :
az loginExécutez le fichier JavaScript.
node to-audio.js
Attendez quelques instants pour obtenir une réponse.
Sortie de la génération audio à partir d’une entrée de texte
Le script génère un fichier audio nommé dog.wav dans le même répertoire que le script. Le fichier audio contient la réponse parlée à l’invite : « Est-ce qu’un récupérateur doré est un bon chien de famille ? »
Générer du contenu audio et du texte à partir d’une entrée audio
Remplacez le fichier
from-audio.jsavec le code suivant :require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Connectez-vous à Azure à l’aide de la commande suivante :
az loginExécutez le fichier JavaScript.
node from-audio.js
Attendez quelques instants pour obtenir une réponse.
Sortie pour la génération audio et de texte à partir d’une entrée audio
Le script génère une transcription du résumé de l’entrée audio parlée. Cela génère également un fichier audio nommé analysis.wav dans le même répertoire que le script. Le fichier audio contient la réponse parlée à l’invite.
Générer de l’audio et utiliser des saisies semi-automatiques de conversation
Remplacez le fichier
multi-turn.jsavec le code suivant :require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: { id: response.choices[0].message.audio.id } }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Connectez-vous à Azure à l’aide de la commande suivante :
az loginExécutez le fichier JavaScript.
node multi-turn.js
Attendez quelques instants pour obtenir une réponse.
Sortie pour les achèvements de conversation à plusieurs tour
Le script génère une transcription du résumé de l’entrée audio parlée. Ensuite, il effectue une saisie semi-automatique de conversation multitours pour résumer brièvement l’entrée audio parlée.
Code source de la bibliothèque | Package | Exemples
Le modèle gpt-4o-audio-preview introduit la modalité audio dans l’API /chat/completions existante. Le modèle audio étend le potentiel des applications IA dans les interactions textuelles et vocales et les analyses audio. Les modalités prises en charge dans le modèle gpt-4o-audio-preview sont les suivantes : texte, audio et texte + audio.
Voici un tableau des modalités prises en charge avec des exemples de cas d’usage :
| Entrée de modalité | Sortie de la modalité | Exemple de cas d’usage |
|---|---|---|
| Détails | Texte + audio | Synthèse vocale, génération de livres audio |
| Audio | Texte + audio | Transcription audio, génération de livres audio |
| Audio | Détails | Transcription audio |
| Texte + audio | Texte + audio | Génération de livres audio |
| Texte + audio | Détails | Transcription audio |
En utilisant des fonctionnalités de génération audio, vous pouvez obtenir des applications IA plus dynamiques et interactives. Les modèles qui prennent en charge les entrées et sorties audio vous permettent de générer des réponses audio parlées aux invites et d’utiliser des entrées audio pour inviter le modèle.
Modèles pris en charge
Actuellement, seule la gpt-4o-audio-preview version : 2024-12-17 prend en charge la génération audio.
Le modèle gpt-4o-audio-preview est disponible pour les déploiements globaux dans les régions USA Est 2 et Suède Centre.
Actuellement, les voix suivantes sont prises en charge pour l’audio out : Alliage, Echo et Shimmer.
La taille maximale d'un fichier audio est de 20 Mo.
Remarque
L’API en temps réel utilise le même modèle audio GPT-4o sous-jacent que l’API de saisie semi-automatique, mais est optimisée pour les interactions audio à faible latence et en temps réel.
Prise en charge des API
La prise en charge des compléments audio a été ajoutée pour la première fois dans la version API 2025-01-01-preview.
Utilisez ce guide pour commencer à générer des audios avec le SDK Azure OpenAI pour Python.
Prérequis
- Un abonnement Azure. Créez-en un gratuitement.
- Python 3.8 ou version ultérieure. Nous vous recommandons d’utiliser Python 3.10 ou version ultérieure, mais l’utilisation d’au moins Python 3.8 est requise. Si vous n’avez pas installé une version appropriée de Python, vous pouvez suivre les instructions du didacticiel Python VS Code pour le moyen le plus simple d’installer Python sur votre système d’exploitation.
- Une ressource Azure OpenAI créée dans les régions USA Est 2 ou Suède Centre. Consultez Disponibilité dans les régions.
- Ensuite, vous devez déployer un modèle
gpt-4o-audio-previewavec votre ressource Azure OpenAI. Pour plus d’informations, consultez l’article Créer une ressource et déployer un modèle à l’aide d’Azure OpenAI.
Prérequis pour Microsoft Entra ID
Pour l’authentification sans clé recommandée avec Microsoft Entra ID, vous devez effectuer les tâches suivantes :
- Installez l’interface Azure CLI utilisée pour l’authentification sans clé avec Microsoft Entra ID.
- Attribuez le rôle
Cognitive Services Userà votre compte d’utilisateur. Vous pouvez attribuer des rôles dans le Portail Azure sous Contrôle d’accès (IAM)>Ajouter une attribution de rôle.
Configurer
Créez un dossier
audio-completions-quickstartpour contenir l’application et ouvrez Visual Studio Code dans ce dossier avec la commande suivante :mkdir audio-completions-quickstart && code audio-completions-quickstartCréez un environnement virtuel. Si Python 3.10, ou une version ultérieure est déjà installé, vous pouvez créer un environnement virtuel à l’aide des commandes suivantes :
L'activation de l'environnement Python signifie que lorsque vous exécutez
pythonoupipdepuis la ligne de commande, vous utilisez alors l'interpréteur Python contenu dans le dossier.venvde votre application. Vous pouvez utiliser la commandedeactivatepour quitter l’environnement virtuel Python et la réactiver ultérieurement si nécessaire.Conseil
Nous vous recommandons de créer et d’activer un nouvel environnement Python pour installer les packages dont vous avez besoin pour ce tutoriel. N’installez pas de packages dans votre installation globale de Python. Vous devez toujours utiliser un environnement virtuel ou conda lors de l’installation de packages Python. Sinon, votre installation globale de Python peut être interrompue.
Installez la bibliothèque de client OpenAI pour Python avec :
pip install openaiPour l’authentification sans clé recommandée avec Microsoft Entra ID, installez le package
azure-identityavec :pip install azure-identity
Récupérer des informations sur les ressources
Vous devez récupérer les informations suivantes pour authentifier votre application auprès de votre ressource Azure OpenAI :
| Nom de la variable | Valeur |
|---|---|
AZURE_OPENAI_ENDPOINT |
Cette valeur se trouve dans la section Clés et point de terminaison quand vous examinez votre ressource à partir du portail Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Cette valeur correspond au nom personnalisé que vous avez choisi pour votre déploiement lorsque vous avez déployé un modèle. Cette valeur peut être trouvée dans le Portail Azure sous Gestion des ressources>Déploiements de modèles. |
OPENAI_API_VERSION |
En savoir plus sur les versions d’API. |
En savoir plus sur l’authentification sans clé et la définition de variables d’environnement.
Générer de l’audio à partir d’une entrée de texte
Remplacez le fichier
to-audio.pyavec le code suivant :import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Make the audio chat completions request completion=client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": "Is a golden retriever a good family dog?" } ] ) print(completion.choices[0]) # Write the output audio data to a file wav_bytes=base64.b64decode(completion.choices[0].message.audio.data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Exécutez le fichier Python.
python to-audio.py
Attendez quelques instants pour obtenir une réponse.
Sortie de la génération audio à partir d’une entrée de texte
Le script génère un fichier audio nommé dog.wav dans le même répertoire que le script. Le fichier audio contient la réponse parlée à l’invite : « Est-ce qu’un récupérateur doré est un bon chien de famille ? »
Générer du contenu audio et du texte à partir d’une entrée audio
Remplacez le fichier
from-audio.pyavec le code suivant :import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Make the audio chat completions request completion = client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] ) print(completion.choices[0].message.audio.transcript) # Write the output audio data to a file wav_bytes = base64.b64decode(completion.choices[0].message.audio.data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Exécutez le fichier Python.
python from-audio.py
Attendez quelques instants pour obtenir une réponse.
Sortie pour la génération audio et de texte à partir d’une entrée audio
Le script génère une transcription du résumé de l’entrée audio parlée. Cela génère également un fichier audio nommé analysis.wav dans le même répertoire que le script. Le fichier audio contient la réponse parlée à l’invite.
Générer de l’audio et utiliser des saisies semi-automatiques de conversation
Remplacez le fichier
multi-turn.pyavec le code suivant :import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] # Get the first turn's response completion = client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=messages ) print("Get the first turn's response:") print(completion.choices[0].message.audio.transcript) print("Add a history message referencing the first turn's audio by ID:") print(completion.choices[0].message.audio.id) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.choices[0].message.audio.id } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) # Send the follow-up request with the accumulated messages completion = client.chat.completions.create( model="gpt-4o-audio-preview", messages=messages ) print("Very briefly, summarize the favorability.") print(completion.choices[0].message.content)Exécutez le fichier Python.
python multi-turn.py
Attendez quelques instants pour obtenir une réponse.
Sortie pour les achèvements de conversation à plusieurs tour
Le script génère une transcription du résumé de l’entrée audio parlée. Ensuite, il effectue une saisie semi-automatique de conversation multitours pour résumer brièvement l’entrée audio parlée.
Le modèle gpt-4o-audio-preview introduit la modalité audio dans l’API /chat/completions existante. Le modèle audio étend le potentiel des applications IA dans les interactions textuelles et vocales et les analyses audio. Les modalités prises en charge dans le modèle gpt-4o-audio-preview sont les suivantes : texte, audio et texte + audio.
Voici un tableau des modalités prises en charge avec des exemples de cas d’usage :
| Entrée de modalité | Sortie de la modalité | Exemple de cas d’usage |
|---|---|---|
| Détails | Texte + audio | Synthèse vocale, génération de livres audio |
| Audio | Texte + audio | Transcription audio, génération de livres audio |
| Audio | Détails | Transcription audio |
| Texte + audio | Texte + audio | Génération de livres audio |
| Texte + audio | Détails | Transcription audio |
En utilisant des fonctionnalités de génération audio, vous pouvez obtenir des applications IA plus dynamiques et interactives. Les modèles qui prennent en charge les entrées et sorties audio vous permettent de générer des réponses audio parlées aux invites et d’utiliser des entrées audio pour inviter le modèle.
Modèles pris en charge
Actuellement, seule la gpt-4o-audio-preview version : 2024-12-17 prend en charge la génération audio.
Le modèle gpt-4o-audio-preview est disponible pour les déploiements globaux dans les régions USA Est 2 et Suède Centre.
Actuellement, les voix suivantes sont prises en charge pour l’audio out : Alliage, Echo et Shimmer.
La taille maximale d'un fichier audio est de 20 Mo.
Remarque
L’API en temps réel utilise le même modèle audio GPT-4o sous-jacent que l’API de saisie semi-automatique, mais est optimisée pour les interactions audio à faible latence et en temps réel.
Prise en charge des API
La prise en charge des compléments audio a été ajoutée pour la première fois dans la version API 2025-01-01-preview.
Prérequis
- Un abonnement Azure. Créez-en un gratuitement.
- Python 3.8 ou version ultérieure. Nous vous recommandons d’utiliser Python 3.10 ou version ultérieure, mais l’utilisation d’au moins Python 3.8 est requise. Si vous n’avez pas installé une version appropriée de Python, vous pouvez suivre les instructions du didacticiel Python VS Code pour le moyen le plus simple d’installer Python sur votre système d’exploitation.
- Une ressource Azure OpenAI créée dans les régions USA Est 2 ou Suède Centre. Consultez Disponibilité dans les régions.
- Ensuite, vous devez déployer un modèle
gpt-4o-audio-previewavec votre ressource Azure OpenAI. Pour plus d’informations, consultez l’article Créer une ressource et déployer un modèle à l’aide d’Azure OpenAI.
Prérequis pour Microsoft Entra ID
Pour l’authentification sans clé recommandée avec Microsoft Entra ID, vous devez effectuer les tâches suivantes :
- Installez l’interface Azure CLI utilisée pour l’authentification sans clé avec Microsoft Entra ID.
- Attribuez le rôle
Cognitive Services Userà votre compte d’utilisateur. Vous pouvez attribuer des rôles dans le Portail Azure sous Contrôle d’accès (IAM)>Ajouter une attribution de rôle.
Configurer
Créez un dossier
audio-completions-quickstartpour contenir l’application et ouvrez Visual Studio Code dans ce dossier avec la commande suivante :mkdir audio-completions-quickstart && code audio-completions-quickstartCréez un environnement virtuel. Si Python 3.10, ou une version ultérieure est déjà installé, vous pouvez créer un environnement virtuel à l’aide des commandes suivantes :
L'activation de l'environnement Python signifie que lorsque vous exécutez
pythonoupipdepuis la ligne de commande, vous utilisez alors l'interpréteur Python contenu dans le dossier.venvde votre application. Vous pouvez utiliser la commandedeactivatepour quitter l’environnement virtuel Python et la réactiver ultérieurement si nécessaire.Conseil
Nous vous recommandons de créer et d’activer un nouvel environnement Python pour installer les packages dont vous avez besoin pour ce tutoriel. N’installez pas de packages dans votre installation globale de Python. Vous devez toujours utiliser un environnement virtuel ou conda lors de l’installation de packages Python. Sinon, votre installation globale de Python peut être interrompue.
Installez la bibliothèque de client OpenAI pour Python avec :
pip install openaiPour l’authentification sans clé recommandée avec Microsoft Entra ID, installez le package
azure-identityavec :pip install azure-identity
Récupérer des informations sur les ressources
Vous devez récupérer les informations suivantes pour authentifier votre application auprès de votre ressource Azure OpenAI :
| Nom de la variable | Valeur |
|---|---|
AZURE_OPENAI_ENDPOINT |
Cette valeur se trouve dans la section Clés et point de terminaison quand vous examinez votre ressource à partir du portail Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Cette valeur correspond au nom personnalisé que vous avez choisi pour votre déploiement lorsque vous avez déployé un modèle. Cette valeur peut être trouvée dans le Portail Azure sous Gestion des ressources>Déploiements de modèles. |
OPENAI_API_VERSION |
En savoir plus sur les versions d’API. |
En savoir plus sur l’authentification sans clé et la définition de variables d’environnement.
Générer de l’audio à partir d’une entrée de texte
Remplacez le fichier
to-audio.pyavec le code suivant :import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Is a golden retriever a good family dog?" } ] } ] } # Make the audio chat completions request completion = requests.post(url, headers=headers, json=body) audio_data = completion.json()['choices'][0]['message']['audio']['data'] # Write the output audio data to a file wav_bytes = base64.b64decode(audio_data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Exécutez le fichier Python.
python to-audio.py
Attendez quelques instants pour obtenir une réponse.
Sortie de la génération audio à partir d’une entrée de texte
Le script génère un fichier audio nommé dog.wav dans le même répertoire que le script. Le fichier audio contient la réponse parlée à l’invite : « Est-ce qu’un récupérateur doré est un bon chien de famille ? »
Générer du contenu audio et du texte à partir d’une entrée audio
Remplacez le fichier
from-audio.pyavec le code suivant :import requests import base64 import os from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] } completion = requests.post(url, headers=headers, json=body) print(completion.json()['choices'][0]['message']['audio']['transcript']) # Write the output audio data to a file audio_data = completion.json()['choices'][0]['message']['audio']['data'] wav_bytes = base64.b64decode(audio_data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Exécutez le fichier Python.
python from-audio.py
Attendez quelques instants pour obtenir une réponse.
Sortie pour la génération audio et de texte à partir d’une entrée audio
Le script génère une transcription du résumé de l’entrée audio parlée. Cela génère également un fichier audio nommé analysis.wav dans le même répertoire que le script. Le fichier audio contient la réponse parlée à l’invite.
Générer de l’audio et utiliser des saisies semi-automatiques de conversation
Remplacez le fichier
multi-turn.pyavec le code suivant :import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": messages } # Get the first turn's response, including generated audio completion = requests.post(url, headers=headers, json=body) print("Get the first turn's response:") print(completion.json()['choices'][0]['message']['audio']['transcript']) print("Add a history message referencing the first turn's audio by ID:") print(completion.json()['choices'][0]['message']['audio']['id']) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.json()['choices'][0]['message']['audio']['id'] } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) body = { "model": "gpt-4o-audio-preview", "messages": messages } # Send the follow-up request with the accumulated messages completion = requests.post(url, headers=headers, json=body) print("Very briefly, summarize the favorability.") print(completion.json()['choices'][0]['message']['content'])Exécutez le fichier Python.
python multi-turn.py
Attendez quelques instants pour obtenir une réponse.
Sortie pour les achèvements de conversation à plusieurs tour
Le script génère une transcription du résumé de l’entrée audio parlée. Ensuite, il effectue une saisie semi-automatique de conversation multitours pour résumer brièvement l’entrée audio parlée.
Documentation de référence | Code source de la bibliothèque | Package (npm) | Exemples
Le modèle gpt-4o-audio-preview introduit la modalité audio dans l’API /chat/completions existante. Le modèle audio étend le potentiel des applications IA dans les interactions textuelles et vocales et les analyses audio. Les modalités prises en charge dans le modèle gpt-4o-audio-preview sont les suivantes : texte, audio et texte + audio.
Voici un tableau des modalités prises en charge avec des exemples de cas d’usage :
| Entrée de modalité | Sortie de la modalité | Exemple de cas d’usage |
|---|---|---|
| Détails | Texte + audio | Synthèse vocale, génération de livres audio |
| Audio | Texte + audio | Transcription audio, génération de livres audio |
| Audio | Détails | Transcription audio |
| Texte + audio | Texte + audio | Génération de livres audio |
| Texte + audio | Détails | Transcription audio |
En utilisant des fonctionnalités de génération audio, vous pouvez obtenir des applications IA plus dynamiques et interactives. Les modèles qui prennent en charge les entrées et sorties audio vous permettent de générer des réponses audio parlées aux invites et d’utiliser des entrées audio pour inviter le modèle.
Modèles pris en charge
Actuellement, seule la gpt-4o-audio-preview version : 2024-12-17 prend en charge la génération audio.
Le modèle gpt-4o-audio-preview est disponible pour les déploiements globaux dans les régions USA Est 2 et Suède Centre.
Actuellement, les voix suivantes sont prises en charge pour l’audio out : Alliage, Echo et Shimmer.
La taille maximale d'un fichier audio est de 20 Mo.
Remarque
L’API en temps réel utilise le même modèle audio GPT-4o sous-jacent que l’API de saisie semi-automatique, mais est optimisée pour les interactions audio à faible latence et en temps réel.
Prise en charge des API
La prise en charge des compléments audio a été ajoutée pour la première fois dans la version API 2025-01-01-preview.
Prérequis
- Un abonnement Azure - En créer un gratuitement
- Prise en charge de Node.js LTS ou ESM.
- TypeScript installé globalement.
- Une ressource Azure OpenAI créée dans les régions USA Est 2 ou Suède Centre. Consultez Disponibilité dans les régions.
- Ensuite, vous devez déployer un modèle
gpt-4o-audio-previewavec votre ressource Azure OpenAI. Pour plus d’informations, consultez l’article Créer une ressource et déployer un modèle à l’aide d’Azure OpenAI.
Prérequis pour Microsoft Entra ID
Pour l’authentification sans clé recommandée avec Microsoft Entra ID, vous devez effectuer les tâches suivantes :
- Installez l’interface Azure CLI utilisée pour l’authentification sans clé avec Microsoft Entra ID.
- Attribuez le rôle
Cognitive Services Userà votre compte d’utilisateur. Vous pouvez attribuer des rôles dans le Portail Azure sous Contrôle d’accès (IAM)>Ajouter une attribution de rôle.
Configurer
Créez un dossier
audio-completions-quickstartpour contenir l’application et ouvrez Visual Studio Code dans ce dossier avec la commande suivante :mkdir audio-completions-quickstart && code audio-completions-quickstartCréez le
package.jsonavec la commande suivante :npm init -yMettez à jour le
package.jsonvers ECMAScript avec la commande suivante :npm pkg set type=moduleInstallez la bibliothèque de client OpenAI pour JavaScript avec :
npm install openaiPour l’authentification sans clé recommandée avec Microsoft Entra ID, installez le package
@azure/identityavec :npm install @azure/identity
Récupérer des informations sur les ressources
Vous devez récupérer les informations suivantes pour authentifier votre application auprès de votre ressource Azure OpenAI :
| Nom de la variable | Valeur |
|---|---|
AZURE_OPENAI_ENDPOINT |
Cette valeur se trouve dans la section Clés et point de terminaison quand vous examinez votre ressource à partir du portail Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Cette valeur correspond au nom personnalisé que vous avez choisi pour votre déploiement lorsque vous avez déployé un modèle. Cette valeur peut être trouvée dans le Portail Azure sous Gestion des ressources>Déploiements de modèles. |
OPENAI_API_VERSION |
En savoir plus sur les versions d’API. |
En savoir plus sur l’authentification sans clé et la définition de variables d’environnement.
Attention
Pour utiliser l’authentification sans clé recommandée avec le kit de développement logiciel (SDK), vérifiez que la variable d’environnement AZURE_OPENAI_API_KEY n’est pas définie.
Générer de l’audio à partir d’une entrée de texte
Remplacez le fichier
to-audio.tsavec le code suivant :import { writeFileSync } from "node:fs"; import { AzureOpenAI } from "openai/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Créez le fichier
tsconfig.jsonpour transpiler le code TypeScript et copiez le code suivant pour ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpiler de TypeScript à JavaScript.
tscConnectez-vous à Azure à l’aide de la commande suivante :
az loginExécutez le code avec la commande suivante :
node to-audio.js
Attendez quelques instants pour obtenir une réponse.
Sortie de la génération audio à partir d’une entrée de texte
Le script génère un fichier audio nommé dog.wav dans le même répertoire que le script. Le fichier audio contient la réponse parlée à l’invite : « Est-ce qu’un récupérateur doré est un bon chien de famille ? »
Générer du contenu audio et du texte à partir d’une entrée audio
Remplacez le fichier
from-audio.tsavec le code suivant :import { AzureOpenAI } from "openai"; import { writeFileSync } from "node:fs"; import { promises as fs } from 'fs'; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync("analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" }); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Créez le fichier
tsconfig.jsonpour transpiler le code TypeScript et copiez le code suivant pour ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpiler de TypeScript à JavaScript.
tscConnectez-vous à Azure à l’aide de la commande suivante :
az loginExécutez le code avec la commande suivante :
node from-audio.js
Attendez quelques instants pour obtenir une réponse.
Sortie pour la génération audio et de texte à partir d’une entrée audio
Le script génère une transcription du résumé de l’entrée audio parlée. Cela génère également un fichier audio nommé analysis.wav dans le même répertoire que le script. Le fichier audio contient la réponse parlée à l’invite.
Générer de l’audio et utiliser des saisies semi-automatiques de conversation
Remplacez le fichier
multi-turn.tsavec le code suivant :import { AzureOpenAI } from "openai/index.mjs"; import { promises as fs } from 'fs'; import { ChatCompletionMessageParam } from "openai/resources/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages: ChatCompletionMessageParam[] = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: response.choices[0].message.audio ? { id: response.choices[0].message.audio.id } : undefined }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Créez le fichier
tsconfig.jsonpour transpiler le code TypeScript et copiez le code suivant pour ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpiler de TypeScript à JavaScript.
tscConnectez-vous à Azure à l’aide de la commande suivante :
az loginExécutez le code avec la commande suivante :
node multi-turn.js
Attendez quelques instants pour obtenir une réponse.
Sortie pour les achèvements de conversation à plusieurs tour
Le script génère une transcription du résumé de l’entrée audio parlée. Ensuite, il effectue une saisie semi-automatique de conversation multitours pour résumer brièvement l’entrée audio parlée.
Nettoyer les ressources
Si vous souhaitez nettoyer et supprimer une ressource Azure OpenAI, vous pouvez la supprimer. Vous devez d’abord supprimer tous les modèles déployés avant de supprimer la ressource.
Contenu connexe
- En savoir plus sur les types de déploiement Azure OpenAI
- En savoir plus sur les quotas et limites Azure OpenAI