Work with Microsoft Fabric lakehouses
Now that you understand the core capabilities of a Microsoft Fabric lakehouse, let's explore how to work with one.
Create and explore a lakehouse
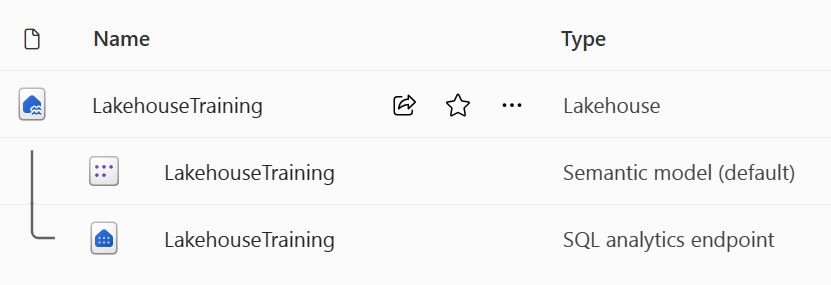
When you create a new lakehouse, you have three different data items automatically created in your workspace.
- The lakehouse contains shortcuts, folders, files, and tables.
- The Semantic model (default) provides an easy data source for Power BI report developers.
- The SQL analytics endpoint allows read-only access to query data with SQL.
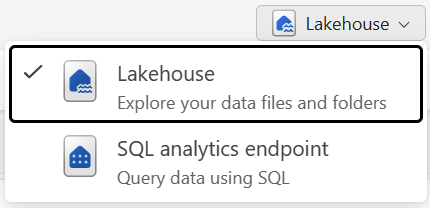
You can work with the data in the lakehouse in two modes:
- lakehouse enables you to add and interact with tables, files, and folders in the lakehouse.
- SQL analytics endpoint enables you to use SQL to query the tables in the lakehouse and manage its relational semantic model.
Ingest data into a lakehouse
Ingesting data into your lakehouse is the first step in your ETL process. Use any of the following methods to bring data into your lakehouse.
- Upload: Upload local files.
- Dataflows Gen2: Import and transform data using Power Query.
- Notebooks: Use Apache Spark to ingest, transform, and load data.
- Data Factory pipelines: Use the Copy data activity.
This data can then be loaded directly into files or tables. Consider your data loading pattern when ingesting data to determine if you should load all raw data as files before processing or use staging tables.
Spark job definitions can also be used to submit batch/streaming jobs to Spark clusters. By uploading the binary files from the compilation output of different languages (for example, .jar from Java), you can apply different transformation logic to the data hosted on a lakehouse. Besides the binary file, you can further customize the behavior of the job by uploading more libraries and command line arguments.
Note
For more information, see the Create an Apache Spark job definition documentation.
Access data using shortcuts
Another way to access and use data in Fabric is to use shortcuts. Shortcuts enable you to integrate data into your lakehouse while keeping it stored in external storage.
Shortcuts are useful when you need to source data that's in a different storage account or even a different cloud provider. Within your lakehouse you can create shortcuts that point to different storage accounts and other Fabric items like data warehouses, KQL databases, and other lakehouses.
Source data permissions and credentials are all managed by OneLake. When accessing data through a shortcut to another OneLake location, the identity of the calling user will be utilized to authorize access to the data in the target path of the shortcut. The user must have permissions in the target location to read the data.
Shortcuts can be created in both lakehouses and KQL databases, and appear as a folder in the lake. This allows Spark, SQL, Real-Time intelligence and Analysis Services to all utilize shortcuts when querying data.
Note
For more information on how to use shortcuts, see OneLake shortcuts documentation in the Microsoft Fabric documentation.