CREATE EXTERNAL TABLE (Transact-SQL)
Creates an external table.
This article provides the syntax, arguments, remarks, permissions, and examples for whichever SQL product you choose.
For more information about the syntax conventions, see Transact-SQL syntax conventions.
Select a product
In the following row, select the product name you're interested in, and only that product's information is displayed.
* SQL Server *
Overview: SQL Server
This command creates an external table for PolyBase to access data stored in a Hadoop cluster or Azure Blob Storage PolyBase external table that references data stored in a Hadoop cluster or Azure Blob Storage.
Applies to: SQL Server 2016 (or higher)
Use an external table with an external data source for PolyBase queries. External data sources are used to establish connectivity and support these primary use cases:
- Data virtualization and data load using PolyBase
- Bulk load operations using SQL Server or SQL Database using
BULK INSERTorOPENROWSET
See also CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
Syntax
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Arguments
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
The one to three-part name of the table to create. For an external table, SQL stores only the table metadata along with basic statistics about the file or folder that is referenced in Hadoop or Azure Blob Storage. No actual data is moved or stored in SQL Server.
Important
For best performance, if the external data source driver supports a three-part name, it is strongly recommended to provide the three-part name.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE supports the ability to configure column name, data type, nullability, and collation. You can't use the DEFAULT CONSTRAINT on external tables.
The column definitions, including the data types and number of columns, must match the data in the external files. If there's a mismatch, the file rows will be rejected when querying the actual data.
LOCATION = 'folder_or_filepath'
Specifies the folder or the file path and file name for the actual data in Hadoop or Azure Blob Storage. Additionally, S3-compatible object storage is supported starting in SQL Server 2022 (16.x)). The location starts from the root folder. The root folder is the data location specified in the external data source.
In SQL Server, the CREATE EXTERNAL TABLE statement creates the path and folder if it doesn't already exist. You can then use INSERT INTO to export data from a local SQL Server table to the external data source. For more information, see PolyBase Queries.
If you specify LOCATION to be a folder, a PolyBase query that selects from the external table will retrieve files from the folder and all of its subfolders. Just like Hadoop, PolyBase doesn't return hidden folders. It also doesn't return files for which the file name begins with an underline (_) or a period (.).
In the following image example, if LOCATION='/webdata/', a PolyBase query will return rows from mydata.txt and mydata2.txt. It won't return mydata3.txt because it's a file in a hidden subfolder. And it won't return _hidden.txt because it's a hidden file.
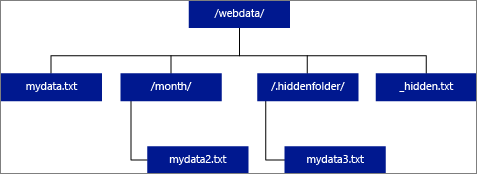
To change the default and only read from the root folder, set the attribute <polybase.recursive.traversal> to 'false' in the core-site.xml configuration file. This file is located under <SqlBinRoot>\PolyBase\Hadoop\Conf under the bin root of SQL Server. For example, C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn.
DATA_SOURCE = external_data_source_name
Specifies the name of the external data source that contains the location of the external data. This location is a Hadoop File System (HDFS), an Azure Blob Storage container, or Azure Data Lake Store. To create an external data source, use CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Specifies the name of the external file format object that stores the file type and compression method for the external data. To create an external file format, use CREATE EXTERNAL FILE FORMAT.
External file formats can be reused by multiple similar external files.
Reject Options
This option can be used only with external data sources where TYPE = HADOOP.
You can specify reject parameters that determine how PolyBase will handle dirty records it retrieves from the external data source. A data record is considered 'dirty' if it actual data types or the number of columns don't match the column definitions of the external table.
When you don't specify or change reject values, PolyBase uses default values. This information about the reject parameters is stored as additional metadata when you create an external table with CREATE EXTERNAL TABLE statement. When a future SELECT statement or SELECT INTO SELECT statement selects data from the external table, PolyBase will use the reject options to determine the number or percentage of rows that can be rejected before the actual query fails. The query will return (partial) results until the reject threshold is exceeded. It then fails with the appropriate error message.
REJECT_TYPE = value | percentage
Clarifies whether the REJECT_VALUE option is specified as a literal value or a percentage.
value
REJECT_VALUE is a literal value, not a percentage. The query will fail when the number of rejected rows exceeds reject_value.
For example, if REJECT_VALUE = 5 and REJECT_TYPE = value, the SELECT query will fail after five rows have been rejected.
percentage
REJECT_VALUE is a percentage, not a literal value. A query will fail when the percentage of failed rows exceeds reject_value. The percentage of failed rows is calculated at intervals.
REJECT_VALUE = reject_value
Specifies the value or the percentage of rows that can be rejected before the query fails.
For REJECT_TYPE = value, reject_value must be an integer between 0 and 2,147,483,647.
For REJECT_TYPE = percentage, reject_value must be a float between 0 and 100.
REJECT_SAMPLE_VALUE = reject_sample_value
This attribute is required when you specify REJECT_TYPE = percentage. It determines the number of rows to attempt to retrieve before the PolyBase recalculates the percentage of rejected rows.
The reject_sample_value parameter must be an integer between 0 and 2,147,483,647.
For example, if REJECT_SAMPLE_VALUE = 1000, PolyBase will calculate the percentage of failed rows after it has attempted to import 1000 rows from the external data file. If the percentage of failed rows is less than reject_value, PolyBase will attempt to retrieve another 1000 rows. It continues to recalculate the percentage of failed rows after it attempts to import each additional 1000 rows.
Note
Since PolyBase computes the percentage of failed rows at intervals, the actual percentage of failed rows can exceed reject_value.
Example:
This example shows how the three REJECT options interact with each other. For example, if REJECT_TYPE = percentage, REJECT_VALUE = 30, and REJECT_SAMPLE_VALUE = 100, the following scenario could occur:
- PolyBase attempts to retrieve the first 100 rows; 25 fail and 75 succeed.
- Percent of failed rows is calculated as 25%, which is less than the reject value of 30%. As a result, PolyBase will continue retrieving data from the external data source.
- PolyBase attempts to load the next 100 rows; this time 25 rows succeed and 75 rows fail.
- Percent of failed rows is recalculated as 50%. The percentage of failed rows has exceeded the 30% reject value.
- The PolyBase query fails with 50% rejected rows after attempting to return the first 200 rows. Notice that matching rows have been returned before the PolyBase query detects the reject threshold has been exceeded.
REJECTED_ROW_LOCATION = Directory Location
Applies to: SQL Server 2019 CU6 and later versions, Azure Synapse Analytics.
Specifies the directory within the External Data Source that the rejected rows and the corresponding error file should be written.
If the specified path doesn't exist, PolyBase will create one on your behalf. A child directory is created with the name "_rejectedrows". The "_" character ensures that the directory is escaped for other data processing unless explicitly named in the location parameter. Within this directory, there's a folder created based on the time of load submission in the format YearMonthDay -HourMinuteSecond (Ex. 20230330-173205). In this folder, two types of files are written, the _reason file and the data file. This option can be used only with external data sources where TYPE = HADOOP and for external tables using DELIMITEDTEXT FORMAT_TYPE. For more information, see CREATE EXTERNAL DATA SOURCE and CREATE EXTERNAL FILE FORMAT.
The reason files and the data files both have the queryID associated with the CTAS statement. Because the data and the reason are in separate files, corresponding files have a matching suffix.
Permissions
Requires these user permissions:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT (only applies to Hadoop and Azure Storage external data sources)
- CONTROL DATABASE (only applies to Hadoop and Azure Storage external data sources)
Note, the remote login specified in the DATABASE SCOPED CREDENTIAL used in the CREATE EXTERNAL TABLE command must have read permission for the path/table/collection on the external data source specified in the LOCATION parameter. If you're planning to use this EXTERNAL TABLE to export data to a Hadoop or Azure Storage external data source, then the login specified must have write permission on the path specified in LOCATION. Note that Hadoop is not currently supported in SQL Server 2022 (16.x).
For Azure Blob Storage, when configuring the access keys and shared access signature (SAS) in the Azure portal, the Azure Blob Storage or ADLS Gen2 storage accounts, configure the Allowed permissions to grant at least Read and Write permissions. List permission might also be required when searching across folders. You must also select both Container and Object as the allowed resource types.
Important
The ALTER ANY EXTERNAL DATA SOURCE permission grants any principal the ability to create and modify any external data source object, and therefore, it also grants the ability to access all database scoped credentials on the database. This permission must be considered as highly privileged, and therefore must be granted only to trusted principals in the system.
Error handling
While executing the CREATE EXTERNAL TABLE statement, PolyBase attempts to connect to the external data source. If the attempt to connect fails, the statement will fail and the external table won't be created. It can take a minute or more for the command to fail since PolyBase retries the connection before eventually failing the query.
Remarks
In ad hoc query scenarios, such as SELECT FROM EXTERNAL TABLE, PolyBase stores the rows that are retrieved from the external data source in a temporary table. After the query completes, PolyBase removes and deletes the temporary table. No permanent data is stored in SQL tables.
In contrast, in the import scenario, such as SELECT INTO FROM EXTERNAL TABLE, PolyBase stores the rows that are retrieved from the external data source as permanent data in the SQL table. The new table is created during query execution when PolyBase retrieves the external data.
PolyBase can push some of the query computation to Hadoop to improve query performance. This action is called predicate pushdown. To enable it, specify the Hadoop resource manager location option in CREATE EXTERNAL DATA SOURCE.
You can create many external tables that reference the same or different external data sources.
Limitations and restrictions
Since the data for an external table is not under the direct management control of SQL Server, it can be changed or removed at any time by an external process. As a result, query results against an external table aren't guaranteed to be deterministic. The same query can return different results each time it runs against an external table. Similarly, a query might fail if the external data is moved or removed.
You can create multiple external tables that each reference different external data sources. If you simultaneously run queries against different Hadoop data sources, then each Hadoop source must use the same 'hadoop connectivity' server configuration setting. For example, you can't simultaneously run a query against a Cloudera Hadoop cluster and a Hortonworks Hadoop cluster since these use different configuration settings. For the configuration settings and supported combinations, see PolyBase Connectivity Configuration.
When the external table is using DELIMITEDTEXT, CSV, PARQUET, or DELTA as data types, external tables only support statistics for one column per CREATE STATISTICS command.
Only these Data Definition Language (DDL) statements are allowed on external tables:
- CREATE TABLE and DROP TABLE
- CREATE STATISTICS and DROP STATISTICS
- CREATE VIEW and DROP VIEW
Constructs and operations not supported:
- The DEFAULT constraint on external table columns
- Data Manipulation Language (DML) operations of delete, insert, and update
Query limitations
PolyBase can consume a maximum of 33k files per folder when running 32 concurrent PolyBase queries. This maximum number includes both files and subfolders in each HDFS folder. If the degree of concurrency is less than 32, a user can run PolyBase queries against folders in HDFS that contain more than 33k files. We recommend that you keep external file paths short and use no more than 30k files per HDFS folder. When too many files are referenced, a Java Virtual Machine (JVM) out-of-memory exception might occur.
Table width limitations
PolyBase in SQL Server 2016 has a row width limit of 32 KB based on the maximum size of a single valid row by table definition. If the sum of the column schema is greater than 32 KB, PolyBase can't query the data.
Data type limitations
The following data types cannot be used in PolyBase external tables:
geographygeometryhierarchyidimagetextnTextxml- Any user-defined type
Data source specific limitations
Oracle
Oracle synonyms are not supported for usage with PolyBase.
External tables to MongoDB collections that contain arrays
To create external tables to MongoDB collections that contain arrays, you should use the Data Virtualization extension for Azure Data Studio to produce a CREATE EXTERNAL TABLE statement based on the schema detected by the PolyBase ODBC Driver for MongoDB. The flattening actions are performed automatically by the driver. Alternatively, you can use sp_data_source_objects (Transact-SQL) to detect the collection schema (columns) and manually create the external table. The sp_data_source_table_columns stored procedure also automatically performs the flattening via the PolyBase ODBC Driver for MongoDB driver. The Data Virtualization extension for Azure Data Studio and sp_data_source_table_columns use the same internal stored procedures to query the external schema.
Locking
Shared lock on the SCHEMARESOLUTION object.
Security
The data files for an external table are stored in Hadoop or Azure Blob Storage. These data files are created and managed by your own processes. It is your responsibility to manage the security of the external data.
Examples
A. Create an external table with data in text-delimited format
This example shows all the steps required to create an external table that has data formatted in text-delimited files. It defines an external data source mydatasource and an external file format myfileformat. These database-level objects are then referenced in the CREATE EXTERNAL TABLE statement. For more information, see CREATE EXTERNAL DATA SOURCE and CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. Create an external table with data in RCFile format
This example shows all the steps required to create an external table that has data formatted as RCFiles. It defines an external data source mydatasource_rc and an external file format myfileformat_rc. These database-level objects are then referenced in the CREATE EXTERNAL TABLE statement. For more information, see CREATE EXTERNAL DATA SOURCE and CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. Create an external table with data in ORC format
This example shows all the steps required to create an external table that has data formatted as ORC files. It defines an external data source mydatasource_orc and an external file format myfileformat_orc. These database-level objects are then referenced in the CREATE EXTERNAL TABLE statement. For more information, see CREATE EXTERNAL DATA SOURCE and CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D. Query Hadoop data
ClickStream is an external table that connects to the employee.tbl delimited text file on a Hadoop cluster. The following query looks just like a query against a standard table. However, this query retrieves data from Hadoop and then computes the results.
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. Join Hadoop data with SQL data
This query looks just like a standard JOIN on two SQL tables. The difference is that PolyBase retrieves the clickstream data from Hadoop and then joins it to the UrlDescription table. One table is an external table and the other is a standard SQL table.
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. Import data from Hadoop into a SQL table
This example creates a new SQL table ms_user that permanently stores the result of a join between the standard SQL table user and the external table ClickStream.
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. Create an external table for SQL Server
Before you create a database scoped credential, the user database must have a master key to protect the credential. For more information, see CREATE MASTER KEY and CREATE DATABASE SCOPED CREDENTIAL.
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
Create a new external data source named SQLServerInstance, and external table named sqlserver.customer:
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
I. Create an external table for Oracle
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. Create an external table for Teradata
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. Create an external table for MongoDB
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. Query S3-compatible object storage via external table
Applies to: SQL Server 2022 (16.x) and later
The following example demonstrates using T-SQL to query a parquet file stored in S3-compatible object storage via querying external table. The sample uses a relative path within the external data source.
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
Next steps
Learn more about related concepts in the following articles:
* Azure SQL Database *
Overview: Azure SQL Database
In Azure SQL Database, creates an external table for elastic queries (in preview).
See also CREATE EXTERNAL DATA SOURCE.
Syntax
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
Arguments
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
The one to three-part name of the table to create. For an external table, SQL stores only the table metadata along with basic statistics about the file or folder that is referenced in Azure SQL Database. No actual data is moved or stored in Azure SQL Database.
Important
For best performance, if the external data source driver supports a three-part name, it is strongly recommended to provide the three-part name.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE supports the ability to configure column name, data type, nullability, and collation. You can't use the DEFAULT CONSTRAINT on external tables.
Note
Text, nText and XML are not supported data types for columns in external tables for Azure SQL Database.
The column definitions, including the data types and number of columns, must match the data in the external files. If there's a mismatch, the file rows will be rejected when querying the actual data.
Sharded external table options
Specifies the external data source (a non-SQL Server data source) and a distribution method for the Elastic query.
DATA_SOURCE
The DATA_SOURCE clause defines the external data source (a shard map) that is used for the external table. For an example, see Create external tables.
Important
Azure SQL Database supports creating external tables to EXTERNAL DATA SOURCE types RDMS and SHARD_MAP_MANAGER. Azure SQL Database does not support creating external tables to Azure Blob Storage.
SCHEMA_NAME and OBJECT_NAME
The SCHEMA_NAME and OBJECT_NAME clauses map the external table definition to a table in a different schema. If omitted, the schema of the remote object is assumed to be "dbo" and its name is assumed to be identical to the external table name being defined. This is useful if the name of your remote table is already taken in the database where you want to create the external table. For example, you want to define an external table to get an aggregate view of catalog views or DMVs on your scaled out data tier. Since catalog views and DMVs already exist locally, you cannot use their names for the external table definition. Instead, use a different name and use the catalog view's or the DMV's name in the SCHEMA_NAME and/or OBJECT_NAME clauses. For an example, see Create external tables.
DISTRIBUTION
Optional. This argument is only required for databases of type SHARD_MAP_MANAGER. This argument controls whether a table is treated as a sharded table or a replicated table. With SHARDED (column name) tables, the data from different tables don't overlap. REPLICATED specifies that tables have the same data on every shard. ROUND_ROBIN indicates that an application-specific method is used to distribute the data.
The DISTRIBUTION clause specifies the data distribution used for this table. The query processor utilizes the information provided in the DISTRIBUTION clause to build the most efficient query plans.
- SHARDED means data is horizontally partitioned across the databases. The partitioning key for the data distribution is the
sharding_column_nameparameter. - REPLICATED means that identical copies of the table are present on each database. It is your responsibility to ensure that the replicas are identical across the databases.
- ROUND_ROBIN means that the table is horizontally partitioned using an application-dependent distribution method.
Permissions
Users with access to the external table automatically gain access to the underlying remote tables under the credential given in the external data source definition. Avoid undesired elevation of privileges through the credential of the external data source. Use GRANT or REVOKE for an external table just as though it were a regular table. Once you have defined your external data source and your external tables, you can now use full T-SQL over your external tables.
Error handling
While executing the CREATE EXTERNAL TABLE statement, if the attempt to connect fails, the statement will fail and the external table won't be created. It can take a minute or more for the command to fail since SQL Database retries the connection before eventually failing the query.
Remarks
In ad hoc query scenarios, such as SELECT FROM EXTERNAL TABLE, SQL Database stores the rows that are retrieved from the external data source in a temporary table. After the query completes, SQL Database removes and deletes the temporary table. No permanent data is stored in SQL tables.
In contrast, in the import scenario, such as SELECT INTO FROM EXTERNAL TABLE, SQL Database stores the rows that are retrieved from the external data source as permanent data in the SQL table. The new table is created during query execution when SQL Database retrieves the external data.
You can create many external tables that reference the same or different external data sources.
You can create multiple external tables that each reference different external data sources.
Limitations
Isolation semantics: Access to data via an external table doesn't adhere to the isolation semantics within SQL Server. This means that querying an external table doesn't impose any locking or snapshot isolation. Therefore data return can change if the data in the external data source is changing. The same query can return different results each time it runs against an external table. Similarly, a query might fail if the external data is moved or removed.
Constructs and operations not supported:
- The DEFAULT constraint on external table columns.
- Data Manipulation Language (DML) operations of delete, insert, and update.
- Dynamic Data Masking on external table columns.
- Cursors are not supported for external tables in Azure SQL Database.
Only literal predicates: Only literal predicates defined in a query can be pushed down to the external data source. This is unlike linked servers and accessing where predicates determined during query execution can be used, that is, when used in conjunction with a nested loop in a query plan. This will often lead to the whole external table being copied locally and then joined.
In the following example, if
External.Ordersis an external table andCustomeris a local table, the query copies the entire external table locally because the predicate needed isn't known at compile time.SELECT Orders.OrderId, Orders.OrderTotal FROM External.Orders WHERE CustomerId IN ( SELECT TOP 1 CustomerId FROM Customer WHERE CustomerName = 'MyCompany' );No parallelism: Use of external tables prevents use of parallelism in the query plan.
Executed as remote query: External tables are implemented as remote query, so the estimated number of rows returned is generally 1000. There are other rules based on the type of predicate used to filter the external table. They are rules-based estimates rather than estimates based on the actual data in the external table. The optimizer doesn't access the remote data source to obtain a more accurate estimate.
Not supported for private endpoint: External table queries are not supported when connection to remote table is a private endpoint.
Data type limitations
The following data types cannot be used in PolyBase external tables:
geographygeometryhierarchyidimagetextnTextxml- Any user-defined type
Locking
Shared lock on the SCHEMARESOLUTION object.
Examples
A. Create external table for Azure SQL Database
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. Create an external table for a sharded data source
This example remaps a remote DMV to an external table using the SCHEMA_NAME and OBJECT_NAME clauses.
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
Next steps
Learn more about external tables in Azure SQL Database in the following articles:
* Azure Synapse
Analytics *
Overview: Azure Synapse Analytics
Use an external table to:
- Dedicated SQL pools can query, import, and store data from Hadoop, Azure Blob Storage, and Azure Data Lake Storage Gen1 and Gen2.
- Serverless SQL pools can query, import, and store data from Azure Blob Storage, Azure Data Lake Storage Gen1 and Gen2. Serverless does not support
TYPE=Hadoop.
See also CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
For more guidance and examples on using external tables with Azure Synapse, see Use external tables with Synapse SQL.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
Arguments
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
The one to three-part name of the table to create. For an external table, only the table metadata along with basic statistics about the file or folder that is referenced in Azure Data Lake, Hadoop, or Azure Blob Storage. No actual data is moved or stored when external tables are created.
Important
For best performance, if the external data source driver supports a three-part name, it is strongly recommended to provide the three-part name.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE supports the ability to configure column name, data type, nullability, and collation. You can't use the DEFAULT CONSTRAINT on external tables.
Note
Deprecated data types text, ntext and XML are not supported data types for columns in external tables for Synapse Analytics.
- When reading delimited files, the column definitions, including the data types and number of columns, must match the data in the external files. If there's a mismatch, the file rows will be rejected when querying the actual data.
- When reading from Parquet files, you can specify only the columns you want to read and skip the rest.
LOCATION = 'folder_or_filepath'
Specifies the folder or the file path and file name for the actual data in Azure Data Lake, Hadoop, or Azure Blob Storage. The location starts from the root folder. The root folder is the data location specified in the external data source. The CREATE EXTERNAL TABLE AS SELECT statement creates the path and folder if it doesn't exist. CREATE EXTERNAL TABLE doesn't create the path and folder.
If you specify LOCATION to be a folder, a PolyBase query that selects from the external table will retrieve files from the folder and all of its subfolders. Just like Hadoop, PolyBase doesn't return hidden folders. It also doesn't return files for which the file name begins with an underline (_) or a period (.).
In the following image example, if LOCATION='/webdata/', a PolyBase query will return rows from mydata.txt and mydata2.txt. It won't return mydata3.txt because it's in a subfolder of a hidden folder. And it won't return _hidden.txt because it's a hidden file.
Unlike Hadoop external tables, native external tables don't return subfolders unless you specify /** at the end of path. In this example, if LOCATION='/webdata/', a serverless SQL pool query, will return rows from mydata.txt. It won't return mydata2.txt and mydata3.txt because they're located in a subfolder. Hadoop tables will return all files within any sub-folder.
Both Hadoop and native external tables will skip the files with the names that begin with an underline (_) or a period (.).
DATA_SOURCE = external_data_source_name
Specifies the name of the external data source that contains the location of the external data. This location is in Azure Data Lake. To create an external data source, use CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Specifies the name of the external file format object that stores the file type and compression method for the external data. To create an external file format, use CREATE EXTERNAL FILE FORMAT.
TABLE_OPTIONS
Specifies the set of options that describe how to read the underlying files. Currently, the only option that is available is {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]} that instructs the external table to ignore the updates that are made on the underlying files, even if this might cause some inconsistent read operations. Use this option only in special cases where you have frequently appended files. This option is available in serverless SQL pool for CSV format.
REJECT options
Reject options are in preview for serverless SQL pools in Azure Synapse Analytics.
This option can be used only with external data sources where TYPE = HADOOP.
You can specify reject parameters that determine how PolyBase will handle dirty records it retrieves from the external data source. A data record is considered 'dirty' if it actual data types or the number of columns don't match the column definitions of the external table.
When you don't specify or change reject values, PolyBase uses default values. This information about the reject parameters is stored as additional metadata when you create an external table with CREATE EXTERNAL TABLE statement. When a future SELECT statement or SELECT INTO SELECT statement selects data from the external table, PolyBase will use the reject options to determine the number or percentage of rows that can be rejected before the actual query fails. The query will return (partial) results until the reject threshold is exceeded. It then fails with the appropriate error message.
The PARSER_VERSION format option is only supported in serverless SQL pools.
REJECT_TYPE = value | percentage
Clarifies whether the REJECT_VALUE option is specified as a literal value or a percentage.
value
REJECT_VALUE is a literal value, not a percentage. The PolyBase query will fail when the number of rejected rows exceeds reject_value.
For example, if REJECT_VALUE = 5 and REJECT_TYPE = value, the PolyBase SELECT query will fail after five rows have been rejected.
percentage
REJECT_VALUE is a percentage, not a literal value. A PolyBase query will fail when the percentage of failed rows exceeds reject_value. The percentage of failed rows is calculated at intervals.
REJECT_VALUE = reject_value
Specifies the value or the percentage of rows that can be rejected before the query fails.
- For REJECT_TYPE = value, reject_value must be an integer between 0 and 2,147,483,647.
- For REJECT_TYPE = percentage, reject_value must be a float between 0 and 100. Percentage is only valid for dedicated SQL pools where
TYPE=HADOOP.
The query will fail when the number of rejected rows exceeds reject_value. For example, if REJECT_VALUE = 5 and REJECT_TYPE = value, the SELECT query will fail after five rows have been rejected.
REJECT_SAMPLE_VALUE = reject_sample_value
This attribute is required when you specify REJECT_TYPE = percentage. It determines the number of rows to attempt to retrieve before the PolyBase recalculates the percentage of rejected rows.
The reject_sample_value parameter must be an integer between 0 and 2,147,483,647.
For example, if REJECT_SAMPLE_VALUE = 1000, PolyBase will calculate the percentage of failed rows after it has attempted to import 1000 rows from the external data file. If the percentage of failed rows is less than reject_value, PolyBase will attempt to retrieve another 1000 rows. It continues to recalculate the percentage of failed rows after it attempts to import each additional 1000 rows.
Note
Since PolyBase computes the percentage of failed rows at intervals, the actual percentage of failed rows can exceed reject_value.
Example:
This example shows how the three REJECT options interact with each other. For example, if REJECT_TYPE = percentage, REJECT_VALUE = 30, and REJECT_SAMPLE_VALUE = 100, the following scenario could occur:
- PolyBase attempts to retrieve the first 100 rows; 25 fail and 75 succeed.
- Percent of failed rows is calculated as 25%, which is less than the reject value of 30%. As a result, PolyBase will continue retrieving data from the external data source.
- PolyBase attempts to load the next 100 rows; this time 25 rows succeed and 75 rows fail.
- Percent of failed rows is recalculated as 50%. The percentage of failed rows has exceeded the 30% reject value.
- The PolyBase query fails with 50% rejected rows after attempting to return the first 200 rows. Notice that matching rows have been returned before the PolyBase query detects the reject threshold has been exceeded.
REJECTED_ROW_LOCATION = Directory Location
Specifies the directory within the External Data Source that the rejected rows and the corresponding error file should be written.
If the specified path doesn't exist, it will be created. A child directory is created with the name _rejectedrows. The _ character ensures that the directory is escaped for other data processing unless explicitly named in the location parameter.
- In serverless SQL pools, the path is
YearMonthDay_HourMinuteSecond_StatementID. You can use statement id to correlate folder with query that generated it. - In dedicated SQL pools, the path created is based on the time of load submission in the format
YearMonthDay -HourMinuteSecond, for example20180330-173205.
In this folder, two types of files are written, the _reason file and the data file.
For more information, see CREATE EXTERNAL DATA SOURCE.
The reason files and the data files both have the queryID associated with the CTAS statement. Because the data and the reason are in separate files, corresponding files have a matching suffix.
In serverless SQL pools, the error.json file contains a JSON array with encountered errors related to rejected rows. Each element representing error contains following attributes:
| Attribute | Description |
|---|---|
| Error | Reason why row is rejected. |
| Row | Rejected row ordinal number in file. |
| Column | Rejected column ordinal number. |
| Value | Rejected column value. If the value is larger than 100 characters, only the first 100 characters will be displayed. |
| File | Path to file that row belongs to. |
Permissions
Requires these user permissions:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Note
CONTROL DATABASE permissions are required to create only the MASTER KEY, DATABASE SCOPED CREDENTIAL, and EXTERNAL DATA SOURCE
Note, the login that creates the external data source must have permission to read and write to the external data source, located in Hadoop or Azure Blob Storage.
Important
The ALTER ANY EXTERNAL DATA SOURCE permission grants any principal the ability to create and modify any external data source object, and therefore, it also grants the ability to access all database scoped credentials on the database. This permission must be considered as highly privileged, and therefore must be granted only to trusted principals in the system.
Error handling
While executing the CREATE EXTERNAL TABLE statement, PolyBase attempts to connect to the external data source. If the attempt to connect fails, the statement will fail and the external table won't be created. It can take a minute or more for the command to fail since PolyBase retries the connection before eventually failing the query.
Remarks
In ad hoc query scenarios, such as SELECT FROM EXTERNAL TABLE, PolyBase stores the rows that are retrieved from the external data source in a temporary table. After the query completes, PolyBase removes and deletes the temporary table. No permanent data is stored in SQL tables.
In contrast, in the import scenario, such as SELECT INTO FROM EXTERNAL TABLE, PolyBase stores the rows that are retrieved from the external data source as permanent data in the SQL table. The new table is created during query execution when PolyBase retrieves the external data.
PolyBase can push some of the query computation to Hadoop to improve query performance. This action is called predicate pushdown. To enable it, specify the Hadoop resource manager location option in CREATE EXTERNAL DATA SOURCE.
You can create many external tables that reference the same or different external data sources.
Pay attention to source data using the UTF-8 collation. For any source data using the UTF-8 collation, you must manually provide a non-UTF-8 collation each UTF-8 column in the CREATE EXTERNAL TABLE statement. This is because UTF-8 support does not extend to external tables. When you attempt to create an external table with a UTF-8 collation, you will receive an Unsupported collation error message. If the external table's database collation is a UTF-8 collation, external table creation will fail unless you provide an explicit non-UTF-8 column collation, for example, [UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL,.
Serverless and dedicated SQL pools in Azure Synapse Analytics use different code bases for data virtualization. Serverless SQL pools support a native data virtualization technology. Dedicated SQL pools support both native and PolyBase data virtualization. PolyBase data virtualization is used when the EXTERNAL DATA SOURCE is created with TYPE=HADOOP.
Limitations and restrictions
Since the data for an external table is not under the direct management control of Azure Synapse, it can be changed or removed at any time by an external process. As a result, query results against an external table aren't guaranteed to be deterministic. The same query can return different results each time it runs against an external table. Similarly, a query might fail if the external data is moved or removed.
You can create multiple external tables that each reference different external data sources.
Only these Data Definition Language (DDL) statements are allowed on external tables:
- CREATE TABLE and DROP TABLE
- CREATE STATISTICS and DROP STATISTICS
- CREATE VIEW and DROP VIEW
Constructs and operations not supported:
- The DEFAULT constraint on external table columns
- Data Manipulation Language (DML) operations of delete, insert, and update
- Dynamic Data Masking on external table columns
Query limitations
It is recommended to not exceed no more than 30k files per folder. When too many files are referenced, a Java Virtual Machine (JVM) out-of-memory exception might occur or performance may degrade.
Table width limitations
PolyBase in Azure Data Warehouse has a row width limit of 1 MB based on the maximum size of a single valid row by table definition. If the sum of the column schema is greater than 1 MB, PolyBase can't query the data.
Data type limitations
The following data types cannot be used in PolyBase external tables:
geographygeometryhierarchyidimagetextnTextxml- Any user-defined type
Locking
Shared lock on the SCHEMARESOLUTION object.
Examples
A. Import Data from ADLS Gen 2 into Azure Synapse Analytics
For examples for Gen ADLS Gen 1, see Create external data source.
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. Import Data from Parquet into Azure Synapse Analytics
The following example creates an external table. It then returns the first row:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
Next steps
Learn more about external tables and related concepts in the following articles:
* Analytics
Platform System (PDW) *
Overview: Analytics Platform System
Use an external table to:
- Query Hadoop or Azure Blob Storage data with Transact-SQL statements.
- Import and store data from Hadoop or Azure Blob Storage into Analytics Platform System.
See also CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
Arguments
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
The one to three-part name of the table to create. For an external table, Analytics Platform System stores only the table metadata along with basic statistics about the file or folder that is referenced in Hadoop or Azure Blob Storage. No actual data is moved or stored in Analytics Platform System.
Important
For best performance, if the external data source driver supports a three-part name, it is strongly recommended to provide the three-part name.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE supports the ability to configure column name, data type, nullability, and collation. You can't use the DEFAULT CONSTRAINT on external tables.
The column definitions, including the data types and number of columns, must match the data in the external files. If there's a mismatch, the file rows will be rejected when querying the actual data.
LOCATION = 'folder_or_filepath'
Specifies the folder or the file path and file name for the actual data in Hadoop or Azure Blob Storage. The location starts from the root folder. The root folder is the data location specified in the external data source.
In Analytics Platform System, the CREATE EXTERNAL TABLE AS SELECT statement creates the path and folder if it doesn't exist. CREATE EXTERNAL TABLE doesn't create the path and folder.
If you specify LOCATION to be a folder, a PolyBase query that selects from the external table will retrieve files from the folder and all of its subfolders. Just like Hadoop, PolyBase doesn't return hidden folders. It also doesn't return files for which the file name begins with an underline (_) or a period (.).
In the following image example, if LOCATION='/webdata/', a PolyBase query will return rows from mydata.txt and mydata2.txt. It won't return mydata3.txt because it's in a subfolder of a hidden folder. And it won't return _hidden.txt because it's a hidden file.
To change the default and only read from the root folder, set the attribute <polybase.recursive.traversal> to 'false' in the core-site.xml configuration file. This file is located under <SqlBinRoot>\PolyBase\Hadoop\Conf\ under the bin root of SQL Server. For example, C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\.
DATA_SOURCE = external_data_source_name
Specifies the name of the external data source that contains the location of the external data. This location is either a Hadoop or Azure Blob Storage. To create an external data source, use CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Specifies the name of the external file format object that stores the file type and compression method for the external data. To create an external file format, use CREATE EXTERNAL FILE FORMAT.
Reject Options
This option can be used only with external data sources where TYPE = HADOOP.
You can specify reject parameters that determine how PolyBase will handle dirty records it retrieves from the external data source. A data record is considered 'dirty' if it actual data types or the number of columns don't match the column definitions of the external table.
When you don't specify or change reject values, PolyBase uses default values. This information about the reject parameters is stored as additional metadata when you create an external table with CREATE EXTERNAL TABLE statement. When a future SELECT statement or SELECT INTO SELECT statement selects data from the external table, PolyBase will use the reject options to determine the number or percentage of rows that can be rejected before the actual query fails. The query will return (partial) results until the reject threshold is exceeded. It then fails with the appropriate error message.
REJECT_TYPE = value | percentage
Clarifies whether the REJECT_VALUE option is specified as a literal value or a percentage.
value
REJECT_VALUE is a literal value, not a percentage. The PolyBase query will fail when the number of rejected rows exceeds reject_value.
For example, if REJECT_VALUE = 5 and REJECT_TYPE = value, the PolyBase SELECT query will fail after five rows have been rejected.
percentage
REJECT_VALUE is a percentage, not a literal value. A PolyBase query will fail when the percentage of failed rows exceeds reject_value. The percentage of failed rows is calculated at intervals.
REJECT_VALUE = reject_value
Specifies the value or the percentage of rows that can be rejected before the query fails.
For REJECT_TYPE = value, reject_value must be an integer between 0 and 2,147,483,647.
For REJECT_TYPE = percentage, reject_value must be a float between 0 and 100.
REJECT_SAMPLE_VALUE = reject_sample_value
This attribute is required when you specify REJECT_TYPE = percentage. It determines the number of rows to attempt to retrieve before the PolyBase recalculates the percentage of rejected rows.
The reject_sample_value parameter must be an integer between 0 and 2,147,483,647.
For example, if REJECT_SAMPLE_VALUE = 1000, PolyBase will calculate the percentage of failed rows after it has attempted to import 1000 rows from the external data file. If the percentage of failed rows is less than reject_value, PolyBase will attempt to retrieve another 1000 rows. It continues to recalculate the percentage of failed rows after it attempts to import each additional 1000 rows.
Note
Since PolyBase computes the percentage of failed rows at intervals, the actual percentage of failed rows can exceed reject_value.
Example:
This example shows how the three REJECT options interact with each other. For example, if REJECT_TYPE = percentage, REJECT_VALUE = 30, and REJECT_SAMPLE_VALUE = 100, the following scenario could occur:
- PolyBase attempts to retrieve the first 100 rows; 25 fail and 75 succeed.
- Percent of failed rows is calculated as 25%, which is less than the reject value of 30%. As a result, PolyBase will continue retrieving data from the external data source.
- PolyBase attempts to load the next 100 rows; this time 25 rows succeed and 75 rows fail.
- Percent of failed rows is recalculated as 50%. The percentage of failed rows has exceeded the 30% reject value.
- The PolyBase query fails with 50% rejected rows after attempting to return the first 200 rows. Notice that matching rows have been returned before the PolyBase query detects the reject threshold has been exceeded.
Permissions
Requires these user permissions:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
- CONTROL DATABASE
Note, the login that creates the external data source must have permission to read and write to the external data source, located in Hadoop or Azure Blob Storage.
Important
The ALTER ANY EXTERNAL DATA SOURCE permission grants any principal the ability to create and modify any external data source object, and therefore, it also grants the ability to access all database scoped credentials on the database. This permission must be considered as highly privileged, and therefore must be granted only to trusted principals in the system.
Error handling
While executing the CREATE EXTERNAL TABLE statement, PolyBase attempts to connect to the external data source. If the attempt to connect fails, the statement will fail and the external table won't be created. It can take a minute or more for the command to fail since PolyBase retries the connection before eventually failing the query.
Remarks
In ad hoc query scenarios, such as SELECT FROM EXTERNAL TABLE, PolyBase stores the rows that are retrieved from the external data source in a temporary table. After the query completes, PolyBase removes and deletes the temporary table. No permanent data is stored in SQL tables.
In contrast, in the import scenario, such as SELECT INTO FROM EXTERNAL TABLE, PolyBase stores the rows that are retrieved from the external data source as permanent data in the SQL table. The new table is created during query execution when PolyBase retrieves the external data.
PolyBase can push some of the query computation to Hadoop to improve query performance. This action is called predicate pushdown. To enable it, specify the Hadoop resource manager location option in CREATE EXTERNAL DATA SOURCE.
You can create many external tables that reference the same or different external data sources.
Limitations and restrictions
Since the data for an external table is not under the direct management control of the appliance, it can be changed or removed at any time by an external process. As a result, query results against an external table aren't guaranteed to be deterministic. The same query can return different results each time it runs against an external table. Similarly, a query might fail if the external data is moved or removed.
You can create multiple external tables that each reference different external data sources. If you simultaneously run queries against different Hadoop data sources, then each Hadoop source must use the same 'hadoop connectivity' server configuration setting. For example, you can't simultaneously run a query against a Cloudera Hadoop cluster and a Hortonworks Hadoop cluster since these use different configuration settings. For the configuration settings and supported combinations, see PolyBase Connectivity Configuration.
Only these Data Definition Language (DDL) statements are allowed on external tables:
- CREATE TABLE and DROP TABLE
- CREATE STATISTICS and DROP STATISTICS
- CREATE VIEW and DROP VIEW
Constructs and operations not supported:
- The DEFAULT constraint on external table columns
- Data Manipulation Language (DML) operations of delete, insert, and update
- Dynamic Data Masking on external table columns
Query limitations
PolyBase can consume a maximum of 33k files per folder when running 32 concurrent PolyBase queries. This maximum number includes both files and subfolders in each HDFS folder. If the degree of concurrency is less than 32, a user can run PolyBase queries against folders in HDFS that contain more than 33k files. We recommend that you keep external file paths short and use no more than 30k files per HDFS folder. When too many files are referenced, a Java Virtual Machine (JVM) out-of-memory exception might occur.
Table width limitations
PolyBase in SQL Server 2016 has a row width limit of 32 KB based on the maximum size of a single valid row by table definition. If the sum of the column schema is greater than 32 KB, PolyBase can't query the data.
In Azure Synapse Analytics, this limitation has been raised to 1 MB.
Data type limitations
The following data types cannot be used in PolyBase external tables:
geographygeometryhierarchyidimagetextnTextxml- Any user-defined type
Locking
Shared lock on the SCHEMARESOLUTION object.
Security
The data files for an external table are stored in Hadoop or Azure Blob Storage. These data files are created and managed by your own processes. It is your responsibility to manage the security of the external data.
Examples
A. Join HDFS data with Analytics Platform System data
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. Import row data from HDFS into a distributed Analytics Platform System Table
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. Import row data from HDFS into a replicated Analytics Platform System Table
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
Next steps
Learn more about external tables in Analytics Platform System in the following articles:
* Azure SQL Managed Instance *
Overview: Azure SQL Managed Instance
Creates an external data table in Azure SQL Managed Instance. For complete information, see Data virtualization with Azure SQL Managed Instance.
Data virtualization in Azure SQL Managed Instance provides access to external data in a variety of file formats in Azure Data Lake Storage Gen2 or Azure Blob Storage, and to query them with T-SQL statements, even combine data with locally stored relational data using joins.
See also CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Arguments
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
The one to three-part name of the table to create. For an external table, only the table metadata along with basic statistics about the file or folder that is referenced in Azure Data Lake or Azure Blob Storage. No actual data is moved or stored when external tables are created.
Important
For best performance, if the external data source driver supports a three-part name, it is strongly recommended to provide the three-part name.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE supports the ability to configure column name, data type, nullability, and collation. You can't use the DEFAULT CONSTRAINT on external tables.
The column definitions, including the data types and number of columns, must match the data in the external files. If there's a mismatch, the file rows will be rejected when querying the actual data.
LOCATION = 'folder_or_filepath'
Specifies the folder or the file path and file name for the actual data in Azure Data Lake or Azure Blob Storage. The location starts from the root folder. The root folder is the data location specified in the external data source. CREATE EXTERNAL TABLE doesn't create the path and folder.
If you specify LOCATION to be a folder, the query from Azure SQL Managed Instance that selects from the external table will retrieve files from the folder but not all of its subfolders.
Azure SQL Managed Instance cannot find files in subfolders or hidden folders. It also doesn't return files for which the file name begins with an underline (_) or a period (.).
In the following image example, if LOCATION='/webdata/', a query will return rows from mydata.txt. It won't return mydata2.txt because it is in a subfolder, it won't return mydata3.txt because it's in a hidden folder, and it won't return _hidden.txt because it's a hidden file.
DATA_SOURCE = external_data_source_name
Specifies the name of the external data source that contains the location of the external data. This location is in Azure Data Lake. To create an external data source, use CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Specifies the name of the external file format object that stores the file type and compression method for the external data. To create an external file format, use CREATE EXTERNAL FILE FORMAT.
Permissions
Requires these user permissions:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Note
CONTROL DATABASE permissions are required to create only the MASTER KEY, DATABASE SCOPED CREDENTIAL, and EXTERNAL DATA SOURCE
Note, the login that creates the external data source must have permission to read and write to the external data source, located in Hadoop or Azure Blob Storage.
Important
The ALTER ANY EXTERNAL DATA SOURCE permission grants any principal the ability to create and modify any external data source object, and therefore, it also grants the ability to access all database scoped credentials on the database. This permission must be considered as highly privileged, and therefore must be granted only to trusted principals in the system.
Remarks
In ad hoc query scenarios, such as SELECT FROM EXTERNAL TABLE, the rows that are retrieved from the external data source are stored in a temporary table. After the query completes, the rows are removed and the temporary table is deleted. No permanent data is stored in SQL tables.
In contrast, in the import scenario, such as SELECT INTO FROM EXTERNAL TABLE, the rows that are retrieved from the external data source are stored as permanent data in the SQL table. The new table is created during query execution when the external data is retrieved.
Currently, data virtualization with Azure SQL Managed Instance is read-only.
You can create many external tables that reference the same or different external data sources.
Limitations and restrictions
Since the data for an external table is not under the direct management control of Azure SQL Managed Instance, it can be changed or removed at any time by an external process. As a result, query results against an external table aren't guaranteed to be deterministic. The same query can return different results each time it runs against an external table. Similarly, a query might fail if the external data is moved or removed.
You can create multiple external tables that each reference different external data sources.
Only these Data Definition Language (DDL) statements are allowed on external tables:
- CREATE TABLE and DROP TABLE
- CREATE STATISTICS and DROP STATISTICS
- CREATE VIEW and DROP VIEW
Constructs and operations not supported:
- The DEFAULT constraint on external table columns
- Data Manipulation Language (DML) operations of delete, insert, and update
Table width limitations
The row width limit of 1 MB is based on the maximum size of a single valid row by table definition. If the sum of the column schema is greater than 1 MB, data virtualization queries will fail.
Data type limitations
The following data types cannot be used in external tables in Azure SQL Managed Instance:
geographygeometryhierarchyidimagetextnTextxml- Any user-defined type
Locking
Shared lock on the SCHEMARESOLUTION object.
Examples
A. Query external data from Azure SQL Managed Instance with an external table
For more examples, see Create external data source or see Data virtualization with Azure SQL Managed Instance.
Create the database master key, if it doesn't exist.
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GOCreate the database scoped credential using a SAS token. You can also use a managed identity.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GOCreate the external data source using the credential.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GOCreate an EXTERNAL FILE FORMAT and an EXTERNAL TABLE, to query the data as if it were a local table.
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
Next steps
Learn more about external tables and related concepts in the following articles: