Introducing the storage pool in SQL Server Big Data Clusters
Applies to: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
This article describes the role of the SQL Server storage pool in a SQL Server big data cluster. The following sections describe the architecture and functionality of a storage pool.
Important
The Microsoft SQL Server 2019 Big Data Clusters add-on will be retired. Support for SQL Server 2019 Big Data Clusters will end on February 28, 2025. All existing users of SQL Server 2019 with Software Assurance will be fully supported on the platform and the software will continue to be maintained through SQL Server cumulative updates until that time. For more information, see the announcement blog post and Big data options on the Microsoft SQL Server platform.
Storage pool architecture
The storage pool is the local HDFS (Hadoop) cluster in a SQL Server big data cluster. It provides persistent storage for unstructured and semi-structured data. Data files, such as Parquet or delimited text, can be stored in the storage pool. To persist storage each pod in the pool has a persistent volume attached to it. The storage pool files are accessible via PolyBase through SQL Server or directly using an Apache Knox Gateway.
A classical HDFS setup consists of a set of commodity-hardware computers with storage attached. The data is spread in blocks across the nodes for fault tolerance and leveraging of parallel processing. One of the nodes in the cluster functions as the name node and contains the metadata information about the files located in the data nodes.
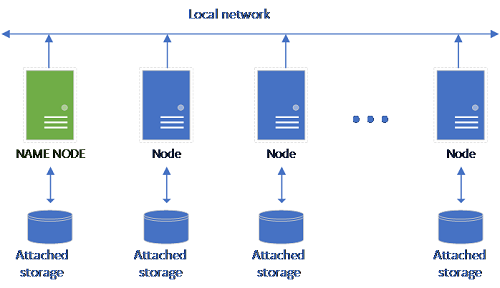
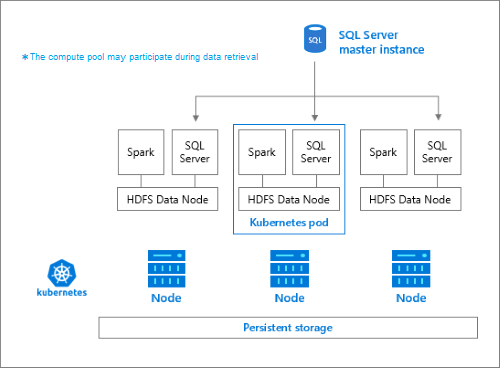
The storage pool consists of storage nodes that are members of a HDFS cluster. It runs one or more Kubernetes pods with each pod hosting the following containers:
- A Hadoop container linked to a persistent volume (storage). All containers of this type together form the Hadoop cluster. Within the Hadoop container is a YARN node manager process that can create on-demand Apache Spark worker processes. The Spark head node hosts the hive metastore, spark history, and YARN job history containers.
- A SQL Server instance to read data from HDFS using OpenRowSet technology.
collectdfor collecting of metrics data.fluentbitfor collecting of log data.
Responsibilities
Storage nodes are responsible for:
- Data ingestion through Apache Spark.
- Data storage in HDFS (Parquet and delimited text format). HDFS also provides data persistency, as HDFS data is spread across all the storage nodes in the SQL BDC.
- Data access through HDFS and SQL Server endpoints.
Accessing data
The main methods for accessing the data in the storage pool are:
- Spark jobs.
- Utilization of SQL Server external tables to allow querying of the data using PolyBase compute nodes and the SQL Server instances running in the HDFS nodes.
You can also interact with HDFS using:
- Azure Data Studio.
- Azure Data CLI (
azdata). - kubectl to issue commands to the Hadoop container.
- HDFS http gateway.
Next steps
To learn more about the SQL Server Big Data Clusters, see the following resources: