Customizing ranking models to improve relevance in SharePoint
APPLIES TO:  2013 2016 2019
2013 2016 2019  SharePoint Online in Microsoft 365
SharePoint Online in Microsoft 365
Improve search relevance by customizing ranking models to calculate rank scores (relevance rank) accurately using rank features in SharePoint.
You can sort search results in SharePoint in four ways, one of which is by rank score. When you sort search results by rank score, SharePoint places the most relevant results on top in the search result set.
A search result is relevant if it receives a high rank score, which is a specific numeric score calculated by the search engine using a ranking model. A ranking model is a list of one or more rank stages that contain a set of rank features. The ranking model defines how the search engine calculates the relevance rank using various factors, which are represented in the ranking model as rank features. Factors used to calculate the relevance rank include, but are not limited to, the following:
- The appearance of query terms in the full-text index, which includes information such as a document's title and body.
- The metadata associated with a particular item, such as a document's file type or URL length.
- The anchor text associated with URL links that point to a particular item.
- The information about user clicks for each item.
- The proximity of query terms in a document's body or title.
Start your ranking model customization based on a SharePoint ranking model template
To make your customization easier, start by using one of the default ranking models in SharePoint as a template. Then, modify that ranking model to suit your data set.
SharePoint provides 14 ranking models by default. See What is a ranking model? (on TechNet) for detailed information about these ranking models and their purpose.
Important
If you install the SharePoint cumulative update of August 2013, we recommend using the Search Ranking Model with Two Linear Stages as the base model for your custom ranking model. The Search Ranking Model with Two Linear Stages is a copy of the Default Search Model with a linear second stage instead of a neural network second stage.
You use the following Windows PowerShell cmdlets to customize ranking models:
- Get-SPEnterpriseSearchRankingModel
- New-SPEnterpriseSearchRankingModel
- Remove-SPEnterpriseSearchRankingModel
- Set-SPEnterpriseSearchRankingModel
To list all available ranking models
- Open the SharePoint Management Shell as an Administrator.
- Run the following sequence of Windows PowerShell cmdlets.
$ssa = Get-SPEnterpriseSearchServiceApplication -Identity "Search Service Application"
$owner = Get-SPenterpriseSearchOwner -Level ssa
Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner
To retrieve a default ranking model to use as a template
- Open the SharePoint Management Shell as an Administrator.
- Run the following sequence of Windows PowerShell cmdlets; filename.xml is the name of a file in which you want to save the ranking model.
$ssa = Get-SPEnterpriseSearchServiceApplication
$owner = Get-SPenterpriseSearchOwner -Level ssa
$defaultRankingModel = Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner | Where-Object { $_.IsDefault -eq $True }
$defaultRankingModel.RankingModelXML > filename.xml
If you install the SharePoint cumulative update of August 2013, you can use the following procedure to retrieve the search ranking model with two linear stages to use as a template for your custom ranking model.
To retrieve the search ranking model with two linear stages to use as a template
- Open the SharePoint Management Shell as an Administrator.
- Run the following sequence of Windows PowerShell cmdlets; filename.xml is the name of a file in which you want to save the ranking model.
$ssa = Get-SPEnterpriseSearchServiceApplication
$owner = Get-SPenterpriseSearchOwner -Level ssa
$twoLinearStagesRankingModel = Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner -Identity 5E9EE87D-4A68-420A-9D58-8913BEEAA6F2
$twoLinearStagesRankingModel.RankingModelXML > filename.xml
To deploy a custom ranking model
From the list of available ranking models, copy the GUID of the ranking model that you want to use as a template. (See To list all available ranking models for the sequence of Windows PowerShell cmdlets to use.)
Run the following sequence of Windows PowerShell cmdlets using the GUID copied in step 1 for <GUID>.
$ssa = Get-SPEnterpriseSearchServiceApplication $owner = Get-SPenterpriseSearchOwner -Level ssa $rm = Get-SPEnterpriseSearchRankingModel -Identity <GUID> -SearchApplication $ssa -Owner $owner $rm.RankingModelXML > myrm.xmlEdit the
myrm.xmlfile in an XML editor. You must use new GUID values for the id attributes in RankModel2Stage element and all RankingModel2NN elements. To get a new GUID value you can for example use the following Windows PowerShell command:[guid]::NewGuid()Create a new ranking model with the New-SPEnterpriseSearchRankingModel cmdlet by running the following commands.
$myRankingModel = Get-Content .\\myrm.xml $myRankingModel = [String]$myRankingModel $ssa = Get-SPEnterpriseSearchServiceApplication $owner = Get-SPenterpriseSearchOwner -Level ssa $newrm = New-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner -RankingModelXML $myRankingModel
Rank detail
Important
We provide the rank detail and the accompanying ExplainRank page as a convenience and only to assist you in tuning and debugging your own custom ranking models. The contents of the rank detail and the accompanying ExplainRank page are not supported, and are subject to change without notice in future software patches and updates.
The rank detail is an XML document that provides detailed information about rank score calculation for a single item that matches a given user query. The rank detail is stored in a special managed property, called rankdetail.
Each rank feature in a ranking model has a separate XML node in the rank detail that describes details of the rank score calculation. The rank detail is provided only for queries that have search results that don't exceed 100 items.
Conceptually, the overall format of the rank detail looks like the following example.
<rank_log version='15.0.0000.1000' id='[internal guid of ranking model used for calculation]' >
<query tree='[representation of user query used for ranking]'/>
<stage type='linear'>
[Details of rank calculation of the first ranking stage. One XML node for each rank feature.]
<stage_model>
[Definition of the first stage of the ranking model]
</stage_model>
</stage>
<stage type='neural_net' >
[Details of rank calculation of the second ranking stage. One XML node for each rank feature.]
<stage_model>
[Definition of the second stage of the ranking model]
</stage_model>
</stage>
</rank_log>
To retrieve the rank detail, you need to be the administrator of the Search service application (SSA).
To retrieve the rank detail
- Open the SharePoint Management Shell as an Administrator.
- Run the following sequence of Windows PowerShell cmdlets, and substitute <query_text> and <url> with actual values.
$app = Get-SPEnterpriseSearchServiceApplication
$searchAppProxy = Get-spenterprisesearchserviceapplicationproxy | Where-Object { ($_.ServiceEndpointUri.PathAndQuery -like $app.Uri.PathAndQuery)}
$request = New-Object Microsoft.Office.Server.Search.Query.KeywordQuery($searchAppProxy)
$request.ResultTypes = [Microsoft.Office.Server.Search.Query.ResultType]::RelevantResults
$request.QueryText = "<query_text> AND path:""<url>"""
$request.SelectProperties.Add("rankdetail")
$searchexecutor = new-Object Microsoft.Office.Server.Search.Query.SearchExecutor
$resultTables = $searchexecutor.ExecuteQuery($request)
$resultTables[([Microsoft.Office.Server.Search.Query.ResultType]::RelevantResults)].Table
Understanding the rank score calculation via the ExplainRank page
SharePoint provides the ExplainRank page that is located in the layouts folder ( <searchCenter>/_layouts/15/). This page contains detailed information on the rank score for each rank feature based on a given search query, a document ID, and an optional ranking model ID. The information is obtained and parsed from the rank detail.
You can access the ExplainRank page with the following URL: http://<searchCenter>/_layouts/15/ExplainRank.aspx?q={x}&d={y}&rm={z}
Where:
- x is the search query.
- y is the document ID.
- z is the optional ranking model ID. If no ranking model ID is provided, the default ranking model is used.
Just like with the rank detail, to view the ExplainRank page, you need to be the administrator of the Search service application (SSA).
Tune your ranking model with rank features
Rank features work like tuning dials for a ranking model. The following sections describe the rank features that are available in the default SharePoint ranking model and how they contribute to relevance rank calculation.
BM25
The BM25 rank feature ranks items based on the appearance of query terms in the full-text index. The input to BM25 can be any of the managed properties in the full-text index.
Note
The BM25 rank feature used in this context is the fielded version, BM25F.
The BM25 rank feature calculates the relevance rank score using the following formula.
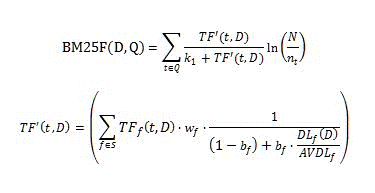
Where:
- D is a document, represented as a list of textual fields such as the title or body.
- Q is the user query, represented as a list of query terms, t.
- S defines the list of fields that contribute to relevance ranking; this list is defined by the ranking model.
- _w_f is a numeric value that defines the relative weight of the field f ??? S; this value is defined by the ranking model.
- _b_f is a numeric value that defines the document length normalization for each field f ??? S.
- _TF_f (t,D) is the number of occurrences of query term t in the field f of document D.
- _DL_f (D) is the total number of words in field f of document D.
- N is the total amount of documents in the index.
- _n_t is an amount of documents that have term t in at least one of their properties.
- _AVDL_f is the average _DL_f (D) across all indexed documents.
- _k_1 is a scalar parameter; this value is defined by the ranking model.
You must map the managed properties used for the BM25 rank feature to the default full-text index in the Choose advanced searchable settings UI.
Within a user query, query terms that are part of the following operators are excluded from relevance rank calculations: NOT(???) in FQL, NOT(???) in KQL, and FILTER(???) in FQL.
In addition, query terms that are under scope, for example, title:apple AND body:orange, are excluded from relevance rank calculations.
Example BM25 rank feature definition
<BM25Main name="ContentRank" k1="1">
<Layer1Weights>
<Weight>0.26236235707678</Weight>
</Layer1Weights>
<Properties>
<Property name="body" w="0.019391078235467" b="0.44402228898786156" propertyName="body" />
<Property name="Title" w="0.36096989709360422" b="0.38179554361297785" propertyName="Title" />
<Property name="Author" w="0.15808522836934547" b="0.13896219383271818" propertyName="Author" />
<Property name="Filename" w="0.15115036355698144" b="0.96245017871125826" propertyName="Filename" />
<Property name="QLogClickedText" w="0.3092664171701901" b="0.056446823262849853" propertyName="QLogClickedText" />
<Property name="AnchorText" w="0.021768362296187508" b="0.74173561196103566" propertyName="AnchorText" />
<Property name="SocialTag" w="0.10217215754116529" b="0.55968554315932328" propertyName="SocialTag" />
</Properties>
</BM25Main>
Example rank detail for BM25 rank feature
<bm25 name='ContentRank'>
<schema pid_mapping='[1:content::7:%default] [2:content::1:%default] [3:content::5:%default] [56:content::2:%default] [100:content::3:link] [10:content::6:link] [264:content::14:link] ' pids_not_mapped=''/>
<query_term term='WORDS(content:integration, content:integrations, content:integrations)'>
<index name='content' N='10035' n='8'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group id='%default'
ext_doc_id='55' int_doc_id='16' precalc='0' tf_prime='0.500486' weight='1'
tf='0 1 1 0 0 0 0 11 0 0 0 0 0 0 0 0 '
dl='0 4 9 0 0 2 0 1291 0 0 0 0 0 0 0 0 '/>
<group id='link'/>
</index>
<rank score='2.37967' score_acc='2.37967' term_weight='7.13439'/>
</query_term>
<query_term term='WORDS(content:effort, content:efforts, content:efforts)'>
<index name='content' N='10035' n='9'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group id='%default'/>
<group id='link'/>
</index>
<rank score='0' score_acc='2.37967' term_weight='7.01661'/>
</query_term>
<query_term term='PHRASE(content:fastserver, content:plugin)'>
<index name='content' N='10035' n='3'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group id='%default'
ext_doc_id='55' int_doc_id='16' precalc='0' tf_prime='0.0399696' weight='1'
tf='0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 '
dl='0 4 9 0 0 2 0 1291 0 0 0 0 0 0 0 0 '/>
<group id='link'/>
</index>
<rank score='0.311896' score_acc='2.69157' term_weight='8.11522'/>
</query_term>
<final score='2.69157' transformed='2.69157' normalized='2.69157' hidden_nodes_adds='0.706166 '/>
</bm25>
Weight groups
In a custom ranking model, you can have two or more managed properties that are mapped to the same weight group in the search schema. In such cases, content of these managed properties is combined in the full-text index and can't be ranked separately in BM25 calculation. This effect is the same as setting equal values for the _w_f and _b_f parameters within each group of managed properties, mapped to the same weight group in the search schema. To prevent this, map managed properties to one of the 16 different weight groups available in the search schema.
Weight groups are also known as context. See Influencing the ranking of search results by using the search schema (on TechNet) for more information about the relationship between a managed property and its context.
Static
The static rank feature ranks items based on numeric managed properties that are stored in the search index. The numeric managed properties used for relevance rank calculation in static rank features must be of type Integer and set to Refinable or Sortable in the search schema. You can't use multivalued managed properties in combination with the static rank feature.
Before the static rank feature can be aggregated with other rank features, each static rank feature is preprocessed via a single transformation. Table 1 lists all supported transform functions.
Table 1. Supported transform functions for the static and proximity rank features
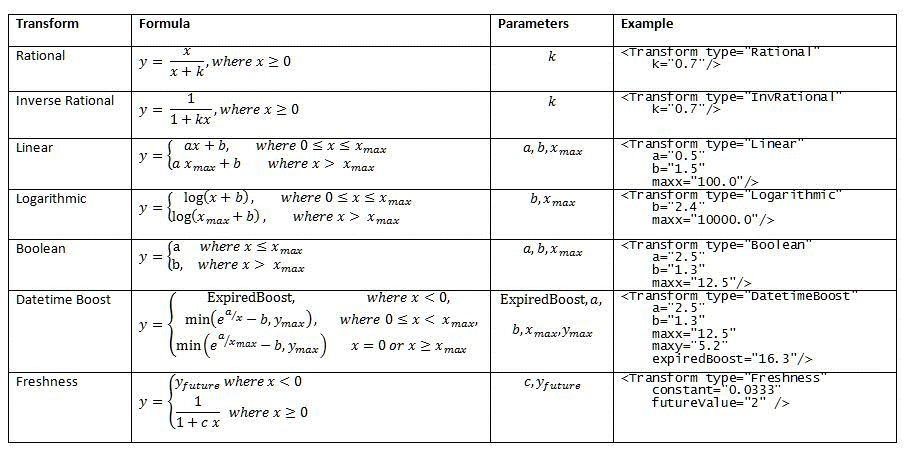
Example static rank feature definition
<Static name="clickdistance" default="5" propertyName="clickdistance">
<Transform type="InvRational" k="0.27618729159042193" />
<Layer1Weights>
<Weight>0.616326852981262</Weight>
</Layer1Weights>
</Static>
Example rank detail for a static rank feature
<static_feature name='clickdistance' property_name='clickdistance'
used_default='1' raw_value='5' raw_value_transformed='5'
transformed='0.420003' normalized='0.420003'
hidden_nodes_adds='0.258859 '/>
Bucketed static
The bucketed static rank feature ranks documents based on their file type and language. The definition of a bucketed static rank feature within a ranking model depends on whether the rank feature is part of a linear model or a neural network. The following examples apply only to linear models. For neural networks, the number of <Add> attributes for each bucket must match the number of hidden nodes in the neural network.
The managed properties used for relevance rank calculation in bucketed static rank features must be of type Integer and set to Refinable or Sortable in the search schema. You can't use multivalued managed properties in combination with the bucketed static rank feature.
Example bucketed static rank feature definition for file type
Every document has an associated file type that the content processing component detects and stores in the search index as a zero-based integer value. When you use the bucketed static rank feature to rank documents based on their file types, each document type is associated with a specific relevance rank score. For example, in the following definition, the bucket 2 corresponds to a .ppt document; the node <Add>0.680984743282165</Add> defines additional rank points that are added to the relevance rank scores for all .ppt documents.
<BucketedStatic name="InternalFileType" default="0" propertyName="InternalFileType">
<Bucket name="Html" value="0">
<HiddenNodesAdds>
<Add>0.464062832328107</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Doc" value="1">
<HiddenNodesAdds>
<Add>0.551558196047853</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Ppt" value="2">
<HiddenNodesAdds>
<Add>0.680984743282165</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Xls" value="3">
<HiddenNodesAdds>
<Add>-0.143152682829863</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Xml" value="4">
<HiddenNodesAdds>
<Add>-1.29219869408375</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Txt" value="5">
<HiddenNodesAdds>
<Add>-0.456669562992298</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="ListItems" value="6">
<HiddenNodesAdds>
<Add>0.170944938307345</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Message" value="7">
<HiddenNodesAdds>
<Add>-0.0666769377412764</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Image" value="8">
<HiddenNodesAdds>
<Add>0.106988843357609</Add>
</HiddenNodesAdds>
</Bucket>
</BucketedStatic>
Example bucketed static rank feature definition for document language
The content processing component detects the language for each document automatically before it's added to the search index. When you use the bucketed static rank feature to rank documents based on their language, you can define how to calculate the rank score based on whether the document's language that was automatically detected matches the query's language.
At query time, information about the user's language is written to the search engine as a query property.
Proximity
The proximity rank feature ranks items depending on the distance between query terms inside the full-text index. The rank score is boosted if two query terms appear in the same managed properties within the full-text index. Proximity calculations are expensive in terms of disk activity and CPU consumption; as a result, proximity boost is carried out only during the second stage of the default SharePoint rank model (if available).
You can evaluate the proximity rank feature by using several different options, controlled by attributes described in Table 2.
Table 2. Attributes that control evaluation of proximity rank features
| Attributes | Description |
|---|---|
isExact=0 |
In this mode, the proximity algorithm attempts to find the minimal span (distance) of the subset of query terms in a document. The proximity algorithm considers fragments that contain query terms in the same orders as they appear in the user query. If no fragment exists for all of the query terms, then the proximity algorithm considers fragments that contain all but one of the query terms. This process is iterated with the number of query terms reduced each time, until the length of the fragment exceeds maxMinSpan. maxMinSpan is an attribute within the proximity rank feature that specifies a threshold defining the maximum length of a fragment. An ideal fragment is one that contains all query terms but is less than maxMinSpan. |
isExact=1 |
In this mode, the proximity algorithm attempts to find a consecutive snippet of document that contains all of the query terms (or query phrase). |
isDiscounted |
This attribute is applicable to both isExact=1 and isExact=0. When isDiscounted is enabled, the proximity value is multiplied by this fraction: (number of occurrences of the best fragment or exact hits) divided by (number of occurrences of the rarest query term in this context). |
proximity="complete" |
In this mode, the proximity rank feature only boosts documents where the whole user query text occurs within a specific managed property. |
proximity="perfect" |
This mode is similar to complete mode, but is applied to short fields, such as title. The proximity rank feature only boosts documents where the whole user query text matches an exact title within a specific managed property. If the title contains additional terms outside of the user query, the item isn't considered by the proximity algorithm. |
default |
This attribute applies only to single-term queries. For items that contain the query term, the default value is used as the rank score output by the proximity rank feature. The perfect proximity is an exception to this rule. For perfect proximity, the default value is never used. Instead, single-term queries are processed in the same way as other queries. |
Example proximity rank feature definition
The following example is an excerpt from the default SharePoint rank model. In this model, the proximity feature is only part of the second stage calculation, which involves a neural network. Therefore, the example contains multiple weight elements, <LayerWeights>, which correspond to the number of neurons in the hidden layer of the neural network.
<MinSpan name="Title_MinSpanExactDiscounted" default="0.43654446989518952" maxMinSpan="1" isExact="1" isDiscounted="1" propertyName="Title">
<Normalize SDev="0.20833333333333334" Mean="0.375" />
<Transform type="Linear" a="1" b="0" maxx="10000" />
<Layer1Weights>
<Weight>0.0399835450090479</Weight>
<Weight>-0.00693681478614802</Weight>
<Weight>0.0286196612755843</Weight>
<Weight>0.11775902923563</Weight>
<Weight>0.0885860088190342</Weight>
<Weight>0.102859503886488</Weight>
</Layer1Weights>
</MinSpan>
You must map the managed properties used in proximity rank features to the default full-text index in search schema.
Example rank detail for proximity rank feature
<proximity_feature name='Title_MinSpanExactDiscounted' pid='2'
proximity_type='exact_discounted'
used_default='0' raw_value='0' transformed='0'
normalized='-1.8'
hidden_nodes_adds='-0.0719704 0.0124863 -0.0515154 -0.211966 -0.159455 -0.185147 ' />
Dynamic
The dynamic rank feature ranks an item depending on whether the query property matches a given managed property. If there is a match, the item's rank score is multiplied with a specific value to distinguish that particular item. The weight attribute is used to control how much this feature affects the overall rank score.
Note
The dynamic rank feature is not customizable; it's for internal use only. However, if you install the SharePoint cumulative update of August 2013, the AnchortextComplete rank feature is a customizable dynamic rank feature that is part of the default ranking model.
Example dynamic rank feature definition
<Dynamic name="AnchortextComplete" pid="501" default="0" property="AnchortextCompleteQueryProperty">
<Transform type="Rational" k="0.91495552365614574" />
<Layer1Weights>
<Weight>0.715419978898093</Weight>
</Layer1Weights>
</Dynamic>
Freshness
The default SharePoint ranking model doesn't boost the rank of search results based on their freshness. You can achieve this by adding a new static rank feature that combines information from the LastModifiedTime managed property with the DateTimeUtcNow query property, using the freshness transform function. The freshness transform function is the only transform that you can use for this freshness rank feature, because it converts the age of the item from an internal representation into days.
The freshness transform is based on the following formula:
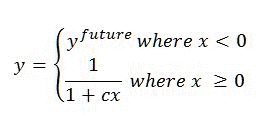
Where:
- c and _y_future are defined in the ranking model.
- x is the age of an item in days.
- The value of _y_future defines the freshness boost for items that have LastModifiedTime greater than the current date and time.
Example freshness rank feature definition
<Static name='freshboost' propertyName='LastModifiedTime' default='-1' convertPropertyToDatetime='1' rawValueTransform='compare' property='DateTimeUtcNow'>
<Transform type="Freshness" constant="0.0333" futureValue="2" />
<Layer1Weights>
<Weight>1.0</Weight>
</Layer1Weights>
</Static>
Example rank detail for freshness rank feature using an old document (approximately 580 days old)
<static_feature name='freshboost' property_name='LastModifiedTime' raw_value_transform='compare' used_default='0' property_value_found='1' property_value='9807115930137649186' raw_value='9.80661e+018' raw_value_transformed='-5.03135e+014' transformed='0.0490396' normalized='0.0490396' hidden_nodes_adds='0.0490396 '/>
Example rank detail for freshness rank feature using a new document (<1 day old)
<static_feature name='freshboost' property_name='LastModifiedTime' raw_value_transform='compare' used_default='0' property_value_found='1' property_value='9807115934928966979' raw_value='9.80712e+018' raw_value_transformed='-2.55529e+011' transformed='0.990248' normalized='0.990248'hidden_nodes_adds='0.990248 '/>
Aggregation of rank features
A ranking model consists of various rank features that are considered together to calculate a rank score.
Two-stage ranking models
A ranking model can have two rank stages. In the first stage, the ranking model applies relatively inexpensive rank features to get a gross ranking of the results. In the second stage, the ranking model applies additional and more expensive rank features to the items with the highest rank scores.
The SharePoint default ranking model is an example of two-stage ranking model. In this model, the second stage works with the top 1000 items with the highest rank score that result from the first stage.
When the ranking process in the first stage is complete, the search engine re-sorts all of the items, including the items that were excluded from the second stage. This usually results in items from the second stage having a lower rank score when compared to items in the first stage.
However, to ensure that the search engine re-sorts the items accurately, items from the second stage must have a higher rank score than items from the first stage. To solve this dilemma, the rank scores of the second stage are boosted. The search engine performs this calculation automatically, based on a combination of rank features.
Note
If you install the SharePoint cumulative update of August 2013, the default ranking model uses a linear first stage and a neural network second stage. The Search Ranking Model with Two Linear Stages is a copy of the Default Search Model with two linear stages. We recommend using this model as the base model for your custom ranking model because it is easier to tune a linear model than a model containing a neural network.
Linear model
The liner model defines a linear combination of rank scores from rank features.
The rank score provided by linear models is computed using the following formula:
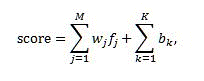
Where:
- score is the output rank score produced by the linear model.
- M is the number of rank features excluding bucketed static rank features.
- K is the number of bucketed static rank features.
- _f_j is the value of _j_th feature after transformation.
- _w_j is the contribution weight of _j_th feature to the linear combination.
Neural network
The neural network defines a nonlinear combination of rank scores from rank features. Currently, SharePoint supports neural networks that are limited to one hidden layer with up to eight neurons.
The ranking score produced by a neural network is computed using the following formula:
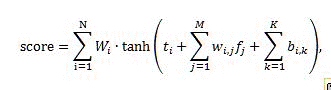
Where:
- score is the output rank score produced by the neural network.
- N is the number of neurons in the hidden layer of the neural network.
- M is the number of rank features, excluding bucketed static rank features.
- K is the number of bucketed static rank features.
- _W_i is the contribution weight of _i_th hidden neuron.
- _t_i is the threshold of _i_th hidden neuron.
- _W_i,j is the contribution weight of _j_th feature to _i_th hidden neuron.
- _b_i,k is the addition from the _k_th bucketed static feature to _i_th hidden neuron.
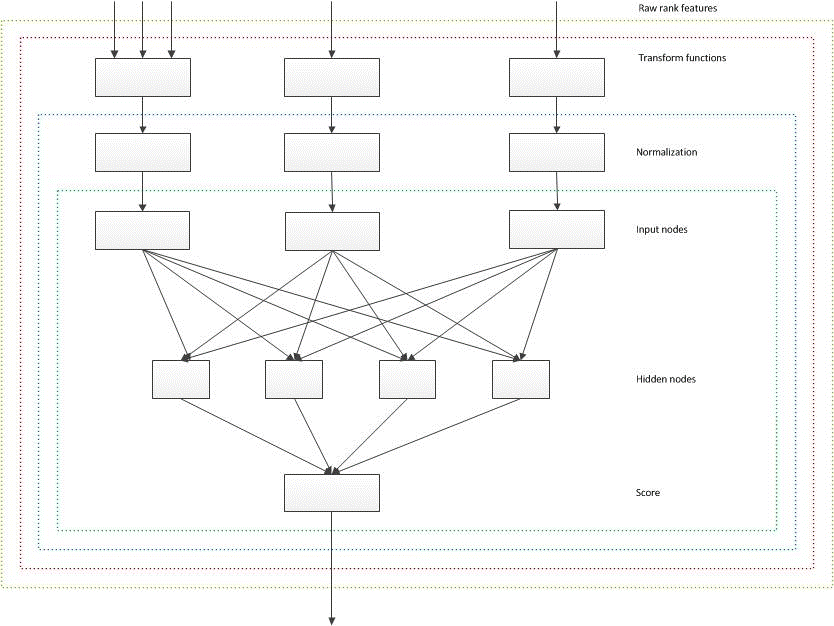
The overall schema of rank score computation with a two-layer neural network is represented in the following diagram. This diagram doesn't consider the bucketed static rank feature that contributes to neural networks by adding custom values directly into hidden nodes, without any transformation or normalization.
Figure 1. Overall schema of rank score computation with a two-layer neural network
Precalculation in BM25 and static rank features
In a ranking model, BM25 and static rank features can benefit from precalculations to improve query latency for query terms that frequently occur in items. This query latency improvement is achieved with the cost of additional indexing, both in terms of disk space used by the search index and CPU consumption.
You should use precalculation only in the first stage of a ranking model. Consequently, if precalculation is enabled, the rank detail of the first stage will not be complete.
To enable precalculation, set the precalcEnabled attribute to 1 in the rank stage definition. You can only use precalculation once in a ranking model.
Query properties
Query properties is a ranking mechanism that populates additional information useful for rank score calculation. For example, query properties can be the time and date when the query was run, which can be used by the freshness rank feature. Table 3 lists the query properties available for ranking. You can't configure query properties.
Table 3. Query properties for ranking
| Query property | Description |
|---|---|
| AnchortextCompleteQueryProperty |
Boosts complete anchor text. |
| DateTimeUtcNow |
Current date and time. This query property can be used by the freshness rank feature. |
| DetectedLanguageRanking |
ID of the query language. This query property is used by the DetectedLanguageRanking rank feature. |
| PersonalizationData |
Ranks personalized data. |
| RecommendedforQueryProperty |
Ranks recommendations. |
Example 1: Basic ranking model with one linear stage containing a single static rank feature
This ranking model assumes that the customer has created a managed property named CustomRating. The static rank feature requires CustomRating to be of Integer data type and to be configured as Sortable or Refinable in the search schema. For each document in the result set, the rank score produced by this ranking model is equal to the value of CustomRating for that document. The effect of this model is similar to sorting all search results, descending, with the CustomRating managed property.
<?xml version="1.0"?>
<RankingModel2Stage name="RankModel1"
description="Rank model -- example 1"
id="D3FAF680-D213-4916-A95A-0409031643F8"
xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN id="619F2ECD-24F7-41CD-824C-234FC2EFDDCA" precalcEnabled="0" >
<HiddenNodes count="1">
<Thresholds>
<Threshold>0</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<Static name="CustomRating" propertyName="CustomRating" default="0.0">
<Transform type="Linear" a="1" b="0" maxx="1000"/>
<Layer1Weights>
<Weight>1.0</Weight>
</Layer1Weights>
</Static>
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
Example 2: More complex ranking model with one linear stage and four rank features
This ranking model with one linear stage contains these four rank features:
BM25This rank feature is based on managed properties Title and body; thewattribute for title is set so that hits of query terms in Title are two times (2x) more important than hits of query terms in body.UrlDepthThis rank feature is based on the UrlDepth managed property, which is available by default in SharePoint installations. UrlDepth contains the number of backslashes (\) in the URL of a document. The inverse rational (InvRational) transform ensures that documents with shorter URLs receive higher rank scores.TitleProximityThis rank feature boosts documents if some of the query terms occur close to each other in the title of these documents.InternalFileTypeThis rank feature boosts documents of type HTML, DOC, XLS, or PPT. The names of the buckets in the definition of the rank model are provided for readability only.Note
The
InternalFileTypemanaged property, available by default, uses the value zero (0) to encode HTML documents, value1for DOC, value2for XLS and so on. See the definition of the Default SharePoint rank model for a list of all file types used for the FileType managed property.
<?xml version="1.0"?>
<RankingModel2Stage name=" RankModel2"
description="Rank model -- example 2"
id="DE48A3A1-67CE-44A2-9712-E8A5128787CF"
xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN id="A0A030D1-805D-437E-A001-CC151ED7473A" precalcEnabled="0">
<HiddenNodes count="1">
<Thresholds>
<Threshold>0</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<BM25Main name="BM25" k1="1">
<Layer1Weights>
<Weight>1</Weight>
</Layer1Weights>
<Properties>
<Property name="Title" propertyName="Title" w="2" b="0.5" />
<Property name="body" propertyName="body" w="1" b="0.5" />
</Properties>
</BM25Main>
<Static name="UrlDepth" propertyName="UrlDepth" default="1">
<Transform type="InvRational" k="1.5"/>
<Layer1Weights>
<Weight>0.5</Weight>
</Layer1Weights>
</Static>
<MinSpan name="TitleProximity" propertyName="Title" default="0" maxMinSpan="1" isExact="0" isDiscounted="0">
<Normalize SDev="1" Mean="0"/>
<Transform type="Linear" a="1" b="-0.5" maxx="2"/>
<Layer1Weights>
<Weight>1.2</Weight>
</Layer1Weights>
</MinSpan>
<BucketedStatic name="InternalFileType" propertyName="InternalFileType" default="0">
<Bucket name="http" value="0">
<HiddenNodesAdds>
<Add>1.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="doc" value="1">
<HiddenNodesAdds>
<Add>2.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="ppt" value="2">
<HiddenNodesAdds>
<Add>0.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="xls" value="3">
<HiddenNodesAdds>
<Add>-3.5</Add>
</HiddenNodesAdds>
</Bucket>
</BucketedStatic>
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>