Tärkeiden vaikuttajien visualisointien luominen
KOSKEE: ![]() Power BI Desktopin
Power BI Desktopin ![]() Power BI -palvelu
Power BI -palvelu
Tärkeimpien vaikuttajien visualisoinnin avulla ymmärrät paremmin sinua kiinnostavaa arvoa ohjaavat tekijät. Se analysoi tietosi, luokittelee tärkeät tekijät ja näyttää ne tärkeinä vaikuttajina. Oletetaan esimerkiksi, että haluat selvittää, millaiset asiat vaikuttavat henkilöstön vaihtuvuuteen. Yksi tekijä voi olla työsopimuksen pituus ja toinen voi olla työmatka-aika.
Milloin tärkeimpiä vaikuttajia kannattaa käyttää?
Tärkeimpien vaikuttajien visualisointi on hyvä valinta, kun haluat:
- nähdä, mitkä tekijät vaikuttavat analysoitavaan arvoon.
- verrata näiden tekijöiden suhteellista tärkeyttä toisiinsa. Vaikuttaako lyhytaikaiset sopimukset esimerkiksi vaihtuvuussuhteeseen enemmän kuin pitkäaikaisiin sopimuksiin?
Tärkeimpien vaikuttajien visualisoinnin ominaisuudet
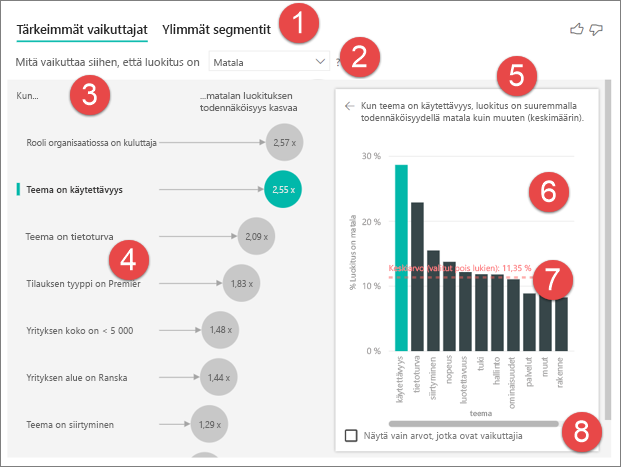
Välilehdet: Valitse välilehti ja siirry näkymästä toiseen. Tärkeimmät vaikuttajat näyttävät valittuun mittausarvoon eniten vaikuttavat tekijät. Ylimmissä segmenteissä näet valittuun mittausarvoon eniten vaikuttavat segmentit. Segmentti koostuu arvojen yhdistelmästä. Yksi segmentti voivat olla kuluttajat, jotka ovat pitkäaikaisia asiakkaita ja asuvat maan länsiosissa.
Avattava luetteloruutu: Tutkimuksen kohteena olevan mittarin arvo. Tarkastele tässä esimerkissä luokitus-arvoa. Valittu arvo on pieni.
Oikaisu: Oikaisu auttaa tulkitsemaan vasemman ruudun visualisointia.
Vasen ruutu: Vasen ruutu sisältää yhden visualisoinnin. Tässä tapauksessa vasen ruutu näyttää luettelon tärkeimmistä vaikuttajista.
Oikaisu: Oikaisu auttaa meitä tulkitsemaan oikean ruudun visualisointia.
Oikea ruutu: Oikea ruutu sisältää yhden visualisoinnin. Tässä tapauksessa pylväskaavio näyttää kaikki arvot tärkeimmälle vaikuttajalle Teema , joka valittiin vasemmasta ruudusta. Tietty vasemman ruudun käytettävyys-arvo näkyy vihreänä. Kaikki muut Teeman arvot näkyvät mustana.
Keskiarvon viiva: Keskiarvo lasketaan kaikille mahdollisille Teeman arvoille paitsi käytettävyydelle (joka on valittu vaikuttaja). Laskelma koskee siis kaikkia mustalla näkyviä arvoja. Se kertoo, millä muiden teemojen prosenttiosuudella oli alhainen luokitus. Tässä tapauksessa 11,35 prosentilla oli alhainen luokitus (näkyy pisteviivana).
Valintaruutu: Tämä suodattaa oikeanpuoleisessa ruudussa näkyvän visualisoinnin näyttämään vain arvot, jotka ovat kyseisen kentän vaikuttajia. Tässä esimerkissä visualisointi on suodatettu näyttämään käytettävyys, suojaus ja siirtyminen.
Luokittaisen arvon analysointi
- Tuotepäällikkö haluaa selvittää, mitkä tekijät saavat asiakkaat esittämään kielteisiä mielipiteitä pilvipalvelustasi. Seuraa mukana Power BI Desktopissa avaamalla asiakaspalautteen PBIX-tiedosto.
Muistiinpano
Asiakaspalautteen tietojoukko perustuu versioon [Moro et al., 2014] S. Moro, P. Cortez ja P. Rita. "Aineistopohjainen lähestymistapa pankkitelemarkkinoinnin onnistumisen ennustamiseen." Decision Support Systems, Elsevier, 62:22-31, kesäkuu 2014.
Valitse Visualisoinnit-ruudun Rakenna visualisointi -kohdasta Tärkeimmät vaikuttajat -kuvake.
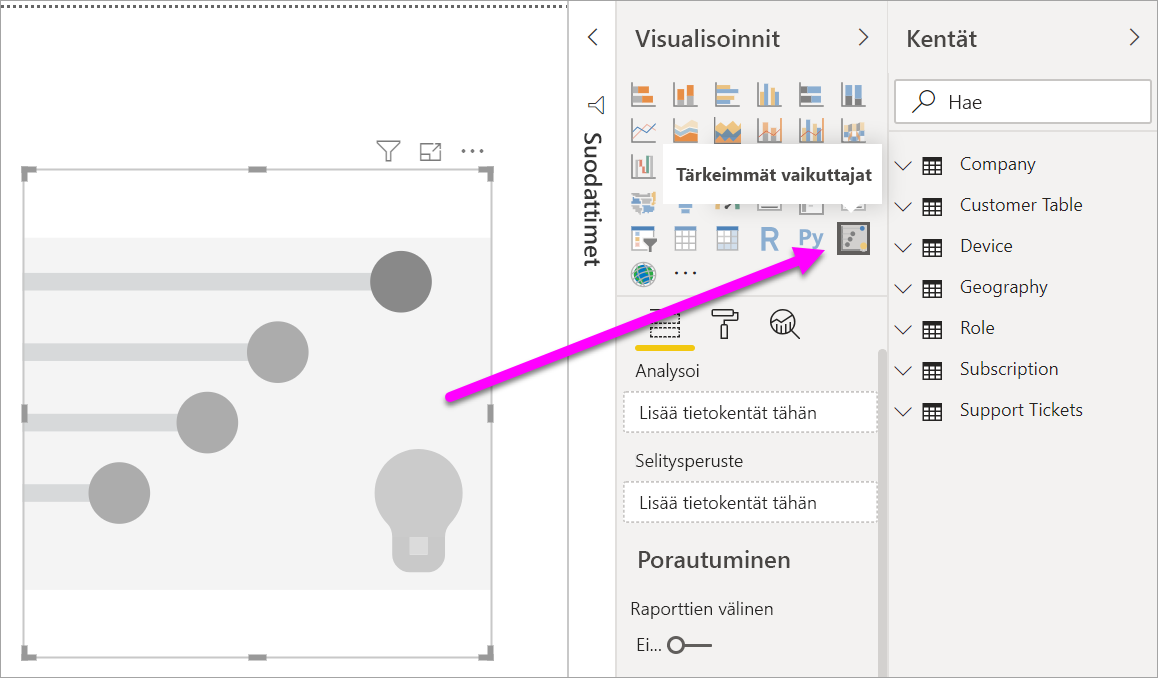
Siirrä tutkittava mittausarvo Analysoi-kenttään. Jos haluat nähdä, mikä saa palvelun asiakkaan luokituksen matalaksi, valitse Asiakastaulukon>luokitus.
Siirrä mielestäsi Luokitukseen vaikuttavia kenttiä Selitysperuste-kenttään. Voit siirtää niin monta kenttää kuin haluat. Aloita tässä tapauksessa seuraavasti:
- Country-Region
- Rooli organisaatiossa
- Tilauksen tyyppi
- Yrityksen koko
- Teema
Jätä Laajenna-kenttä tyhjäksi. Tätä kenttää käytetään vain analysoitaessa mittaria tai yhteenvetokenttää.
Jos haluat keskittyä negatiivisiin luokituksiin, valitse alhainen-vaihtoehto avattavasta Mikä vaikuttaa luokituksen olevan -ruudusta.
Analyysi suoritetaan analysoitavan kentän taulukkotasolla. Tässä tapauksessa se on Luokitus-arvo. Tämä mittausarvo määritetään asiakastasolla. Jokainen asiakas antaa joko korkean tai alhaisen pistemäärän. Kaikki selittävät tekijät on määriteltävä asiakastasolla, jotta visualisointi voi hyödyntää niitä.
Edellisessä esimerkissä kaikki selittävät tekijät ovat joko yksi yhteen- tai monta yhteen -suhteessa mittausarvoon. Tässä tapauksessa jokainen asiakas määritti luokitukselleen yksittäisen teeman. Vastaavasti asiakkaat ovat kotoisin yhdestä maasta tai alueelta, heillä on yksi jäsenyystyyppi ja heillä on yksi rooli organisaatiossaan. Selittävät tekijät ovat jo asiakkaan määritteitä, eikä muunnoksia tarvita. Visualisointi voi käyttää niitä välittömästi.
Myöhemmin tarkastelemme tässä opetusohjelmassa monimutkaisempia esimerkkejä, joissa on yksi moneen -suhteita. Näissä tapauksissa sarakkeet on ensin koostettava asiakastasolle, ennen kuin analyysi voidaan suorittaa.
Selittävinä tekijöinä käytetyt mittarit ja koosteet arvioidaan myös Analysoi-arvon taulukkotasolla. Tässä artikkelissa on myöhemmin esimerkkejä.
Tärkeimpien luokkavaikuttajien tulkitseminen
Katsotaanpa tärkeimpiä vaikuttajia alhaisten luokitusten takana.
Tärkein yksittäinen tekijä, joka vaikuttaa alhaisen luokituksen todennäköisyyteen
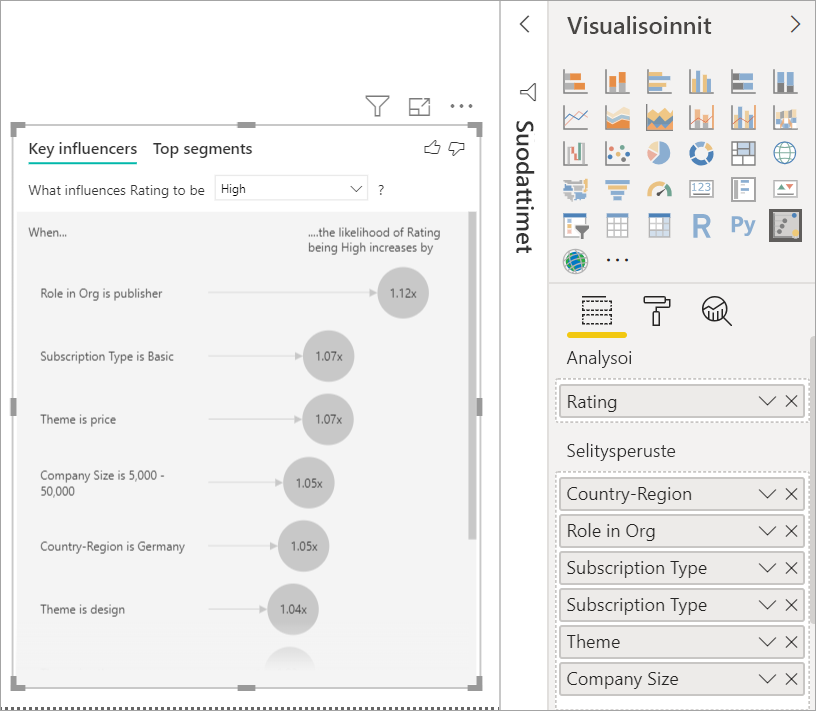
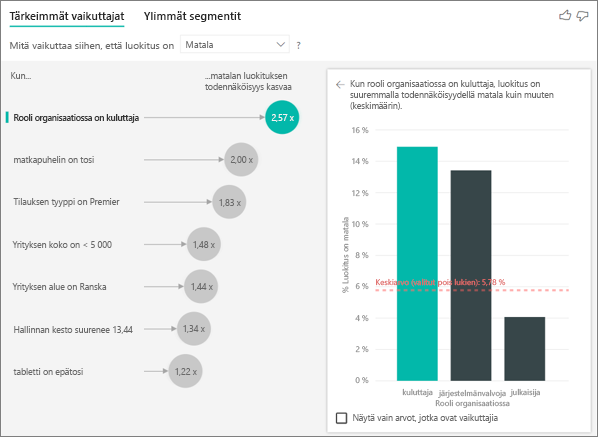
Tässä esimerkissä asiakkaalla voi olla kolme roolia: kuluttaja, järjestelmänvalvoja ja julkaisija. Kuluttajan rooli on tärkeimpiä alhaiseen luokitukseen liittyviä tekijöitä.
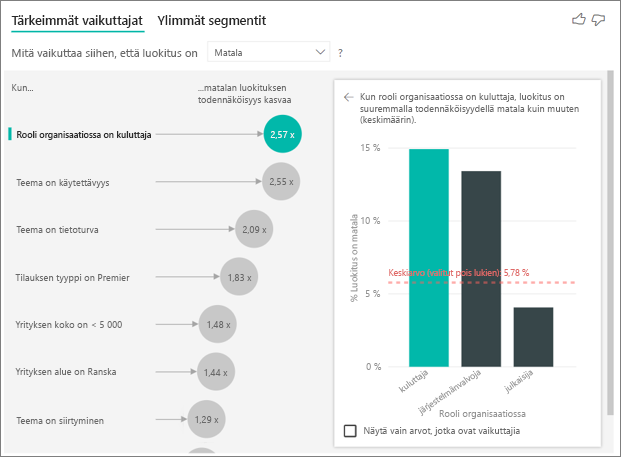
Tarkemmin sanoen, kuluttajat antavat palvelullesi kielteisen pistemäärän 2,57 kertaa todennäköisemmin. Tärkeimpien vaikuttajien kaavio luetteloi tekijän Rooli organisaatiossa = kuluttaja vasemmalla olevan luettelon kärkeen. Kun valitset Rooli organisaatiossa = kuluttaja, Power BI näyttää lisätietoja oikeanpuoleisessa ruudussa. Kunkin roolin suhteellinen vaikutus alhaisen luokituksen todennäköisyyteen näytetään.
- 14,93 % kuluttajista antaa alhaisen pistemäärän.
- Keskimäärin kaikki muut roolit antavat alhaisen pistemäärän 5,78 % ajasta.
- Kuluttajat antavat alhaisen pistemäärän 2,57 kertaa todennäköisemmin kuin kaikki muut roolit. Voit määrittää nämä pisteet jakamalla vihreän palkin punaisella pisteviivalla.
Toiseksi tärkein yksittäinen tekijä, joka vaikuttaa alhaisen luokituksen todennäköisyyteen
Tärkeimpien vaikuttajien visualisointi vertaa ja luokittelee tekijöitä monista eri muuttujista. Toinen vaikuttajamme ei liity mitenkään rooliin organisaatiossa. Valitse luettelon toinen vaikuttava tekijä, joka on Teema = käytettävyys.
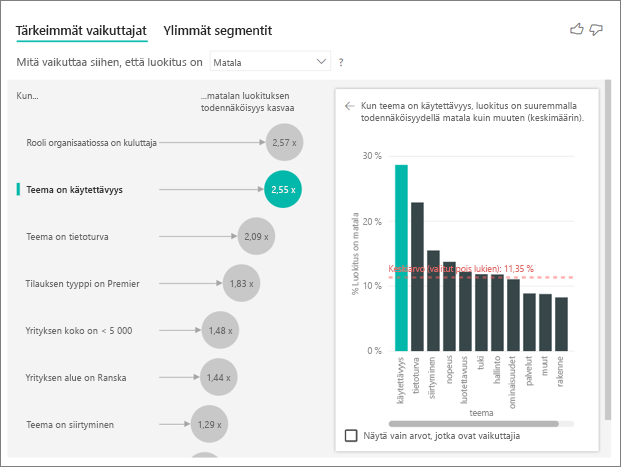
Toiseksi tärkein tekijä liittyy asiakasarvostelun teemaan. Asiakkaat, jotka kommentoivat tuotteen käytettävyyttä, antavat 2,55 kertaa todennäköisemmin alhaisen pistemäärän kuin asiakkaat, jotka kommentoivat muita teemoja, kuten luotettavuutta, rakennetta tai nopeutta.
Visualisointien välillä punainen katkoviiva osoittaa keskiarvon, joka on muuttunut 5,78 %:sta 11,35 %:iin. Keskiarvo on muuttuva, koska se perustuu kaikkien muiden arvojen keskiarvoon. Ensimmäisen vaikuttajan tapauksessa keskiarvo sulki asiakkaan roolin ulkopuolelle. Toisen vaikuttajan tapauksessa se sulki pois käytettävyyden teeman.
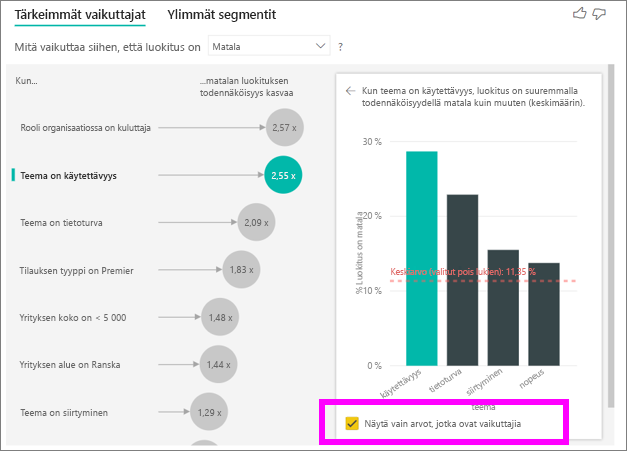
Valitse Näytä vain arvot, jotka ovat vaikuttajia -valintaruutu suodattaaksesi vain vaikuttavien arvojen perusteella. Tässä tapauksessa ne ovat rooleja, jotka lisäävät alhaisen pistemäärän alhaista pistemäärää. Power BI tunnistaa kahdestatoista teemasta neljä, jotka lisäävät alhaisia luokituksia.
Vuorovaikutus muiden visualisointien kanssa
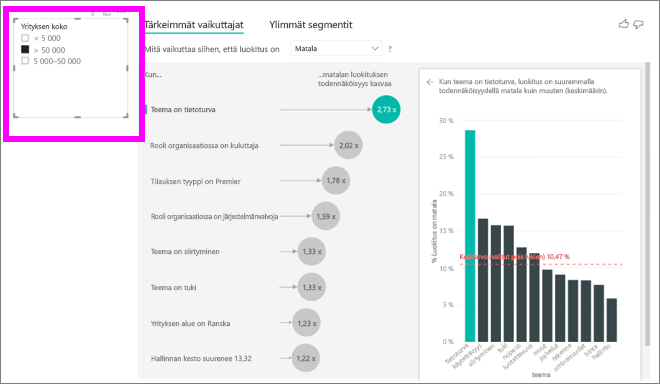
Aina, kun valitset osittajan, suodattimen tai muun pohjalla olevan visualisoinnin, tärkeimpien vaikuttajien visualisointi suorittaa analyysinsa uudelleen uudelle tieto-osalle. Voit esimerkiksi siirtää Yrityksen koko -elementin raporttiin ja käyttää sitä osittajana. Sen avulla voit nähdä, eroavako suuryritysasiakkaiden tärkeimmät vaikuttajat muusta väestöstä. Yrityksen koossa on yli 50 000 työntekijää.
Suorita analyysi uudelleen valitsemalla >50 000 , niin näet, että vaikuttajat ovat muuttuneet. Suuryritysasiakkaiden osalta alhaisten luokitusten tärkein vaikuttaja liittyy teemaltaan tietoturvaan. Sinun kannattaa tutkia asiaa tarkemmin nähdäksesi, ovatko suuret asiakkaasi tyytymättömiä tiettyihin tietoturvaominaisuuksiin.
Tärkeimpien jatkuvien vaikuttajien tulkitseminen
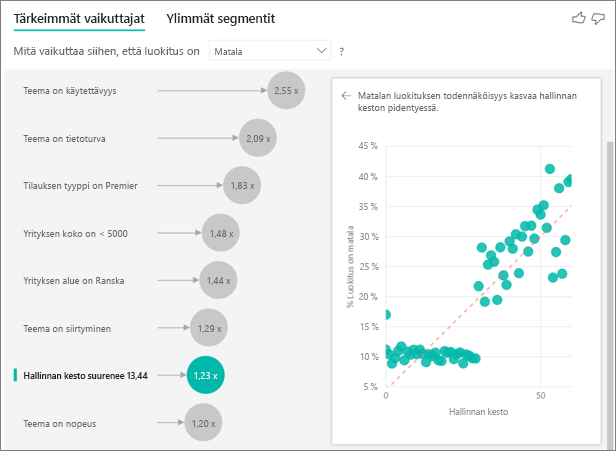
Toistaiseksi olet oppinut käyttämään visualisointia sen selvittämiseen, kuinka erilaiset luokkakentät vaikuttavat alhaisiin luokituksiin. Voit halutessasi käyttää Selitysperuste-kentässä myös jatkuvia tekijöitä, kuten ikä, pituus ja hinta. Katsotaan, mitä tapahtuu, kun Asiakkuuden pituus siirretään asiakastaulukosta Selitysperuste-kohtaan. Asiakkuuden pituus kuvaa, kuinka kauan asiakas käyttää palvelua.
Asiasuhteen pidentyessä myös alhaisemman luokituksen todennäköisyys kasvaa. Tämä trendi viittaa siihen, että pitkäaikaiset asiakkaat antavat todennäköisemmin negatiivisen pistemäärän. Tämä merkityksellinen tieto on kiinnostava, ja haluat ehkä jatkaa siitä myöhemmin.
Visualisointi näyttää, että aina kun asiakkuuden kesto kasvaa 13,44 kuukaudella, alhaisen luokituksen todennäköisyys kasvaa keskimäärin 1,23-kertaiseksi. Tässä tapauksessa 13,44 kuukautta kuvaa asiakkuuden keston keskihajontaa. Näin saamasi merkityksellinen tieto tarkastelee sitä, kuinka asiasuhteen keston nostaminen vakiomäärän (asiamäärän standardihajonnan) verran vaikuttaa alhaisen luokituksen todennäköisyyteen.
Oikeanpuoleisessa ruudussa oleva pistekaavio näyttää alhaisen luokituksen prosenttiosuuden kunkin asiamäärän kestoarvon mukaan. Se korostaa rinteen trendiviivalla.
Lokeroidut tärkeimmät jatkuvat vaikuttajat
Joissakin tapauksissa saatat huomata, että jatkuvat tekijät muuttuvat automaattisesti luokittaisiksi. Jos muuttujien välinen suhde ei ole lineaarinen, yhteyttä ei voi kuvailla yksinkertaisesti kasvavaksi tai väheneväksi (kuten edellisessä esimerkissä).
Määritämme korrelaatiotestejä suorittamalla, miten lineaarista vaikuttajaa verrataan tavoitteeseen. Jos kohde on jatkuva, suoritamme Pearsonin korrelaation, ja jos kohde on luokittainen, teemme pistebiseriaaliset korrelaatiotestit. Jos havaitsemme, että suhde ei ole riittävän lineaarinen, suoritamme valvotun lokeroinnin ja luomme enintään viisi lokeroa. Selvittääksemme mitkä lokerot ovat järkevimpiä, käytämme valvottua lokerointimenetelmää. Valvotussa lokerointimenetelmässä tarkastellaan selittävän tekijän ja analysoitavan kohteen välistä suhdetta.
Mittareiden ja koosteiden tulkitseminen tärkeiksi vaikuttajiksi
Voit käyttää mittareita ja koosteita selittävinä tekijöinä analyysisi sisällä. Miten esimerkiksi asiakkaiden palvelupyyntöjen määrä vaikuttaa saamaasi pistemäärään. Tai mikä vaikutus avoimen lipun keskimääräisellä kestolla on saamaasi pistemäärään.
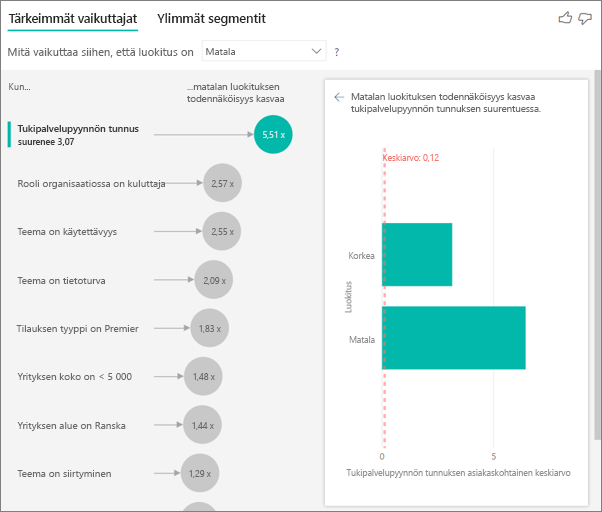
Tässä tapauksessa haluat nähdä, vaikuttaako asiakkaan tukipalvelupyyntöjen määrä hänen antamaansa pistemäärään. Tuo tukipalvelupyynnön tunnus tukipalvelupyyntöjen taulukosta. Koska asiakkaalla voi olla useita tukipalvelupyyntöjä, voit koostaa tunnuksen asiakastasolle. Koostaminen on tärkeää, koska analyysi suoritetaan asiakastasolla, joten kaikki ohjaimet on määriteltävä kyseisellä askelvälitasolla.
Katsotaan tunnuksien määrää. Kullakin asiakasrivillä on siihen liittyvien tukipalvelupyyntöjen määrä. Tässä tapauksessa luokituksen matalan määrän kasvaessa luokituksen todennäköisyys kasvaa 4,08-kertaiseksi. Näyttökuvassa näkyy asiakastasolla arvioitujen eri luokitusarvojen tukipalvelupyyntöjen keskimääräinen määrä eri luokitusarvojen mukaan.
Tulosten tulkinta: Ylimmät segmentit
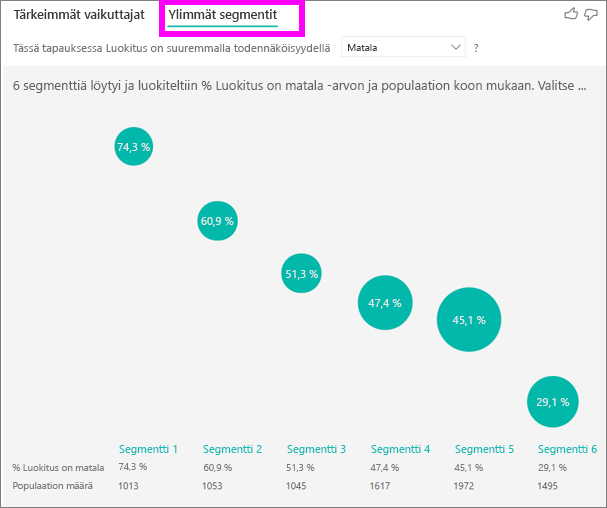
Voit arvioida kunkin tekijän erikseen Tärkeimmät vaikuttajat -välilehden avulla. Voit myös käyttää Ylimmät segmentit -välilehteä nähdäksesi, miten eri tekijät yhdessä vaikuttavat analysoitavaan arvoon.
Ylimmissä segmenteissä näytetään ensiksi yleiskatsaus kaikkiin segmentteihin, jotka Power BI on löytänyt. Seuraavassa esimerkissä löytyi kuusi segmenttiä. Segmentin alhaisten luokituksen prosenttiosuus määrittää sijoituksen. Esimerkiksi segmentillä 1 on 74,3 % alhaisista asiakasluokituksista. Mitä korkeammalla kuplakaavio on, sitä suurempi on alhaisten luokitusten osuus. Kuplan koko edustaa sitä, kuinka monta asiakasta segmentissä on.
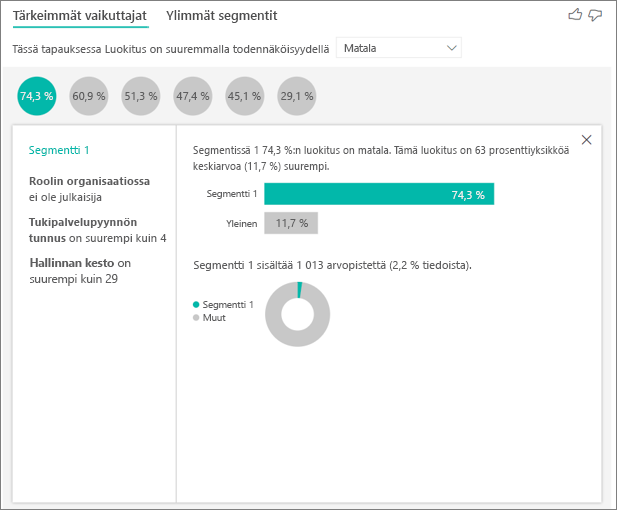
Valitsemalla kuplakaavion näet segmentin tiedot. Jos valitset esimerkiksi segmentin 1, huomaat, että se edustaa vakiintuneita asiakkaita. He ovat olleet asiakkaita yli 29 kuukautta ja heillä on enemmän kuin neljä tukipalvelupyyntöä. He eivät myöskään ole julkaisijoita, joten he ovat joko kuluttajia tai järjestelmänvalvojia.
Tässä ryhmässä 74,3 % asiakkaista antoi alhaisen luokituksen. Keskimääräinen asiakas antaa alhaisen luokituksen 11,7 % ajasta, joten tällä segmentillä on suurempi määrä alhaisia luokituksia. Se on 63 prosenttiyksikköä suurempi arvo. Segmentti 1 sisältää noin 2,2 % tiedoista, joten se edustaa populaation osoitettavissa olevaa osaa.
Määrien lisääminen
Joskus vaikuttajalla voi olla merkittävä vaikutus, mutta se edustaa vain vähän tietoja. Esimerkiksi Teema = käytettävyys on kolmanneksi suurin vaikuttaja alhaisille luokituksille. Käytettävyydestä on kuitenkin ehkä valittanut vain kourallinen asiakkaita. Määrät voivat auttaa sinua asettamaan etusijalle ne vaikuttajat, joihin haluat keskittyä.
Voit ottaa määrät käyttöön muotoiluruudun Analyysi-kortissa .
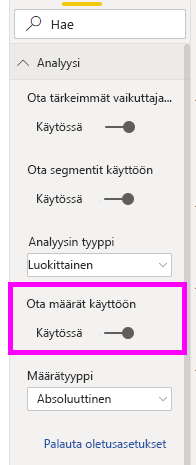
Kun määrät on otettu käyttöön, näet kehän kunkin vaikuttajan kuplan ympärillä. Se edustaa likimääräistä prosenttiosuutta tiedoista, jotka vaikuttaja sisältää. Mitä enemmän kuplaa kehä ympäröi, sitä enemmän tietoja se sisältää. Voimme huomata, että Teema on käytettävyys sisältää pienen osan tiedoista.
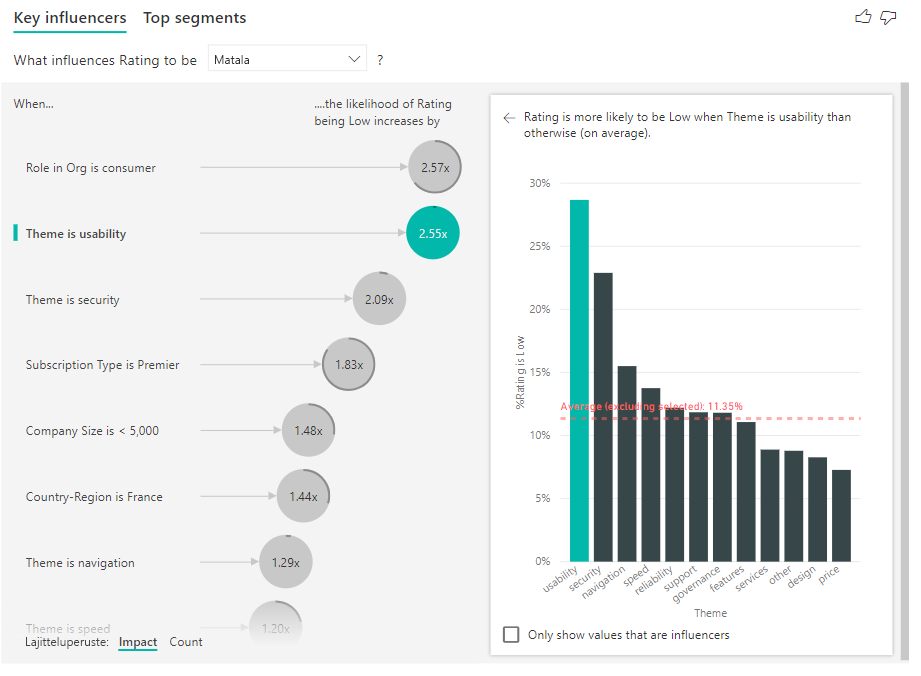
Voit myös lajitella kuplat ensin määrän mukaan vaikutuksen sijasta käyttämällä visualisoinnin vasemmassa alakulmassa olevaa Lajitteluperuste-vaihtokytkintä. Tilauksen tyyppi on Premier on tärkein vaikuttaja määrän perusteella.
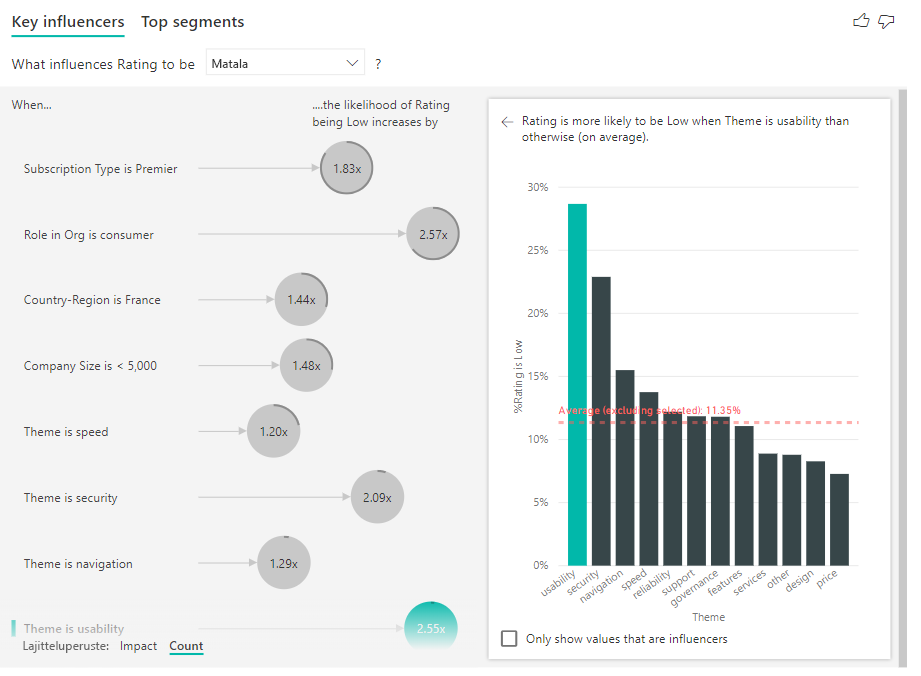
Jos kehä on kokonaan ympyrän ympärillä, vaikuttaja sisältää 100 % tiedoista. Voit muuttaa määrän tyypin suhteelliseksi suurimman vaikuttajan mukaan käyttämällä avattavaa Määrän tyyppi -valikkoa muotoiluruudun Analyysi-kortissa. Nyt suurimman tietomäärän vaikuttaja esitetään täydellä kehällä ja kaikki muut määrät suhteutetaan siihen.
Numeerisen arvon analysointi
Jos siirrät yhteenvetämättömän numeerisen kentän Analysoi-kenttään , voit valita, miten kyseistä skenaariota käsitellään. Voit muuttaa visualisoinnin toimintaa siirtymällä Muotoilu-ruutuun ja vaihtamalla Luokittainen analyysityyppi ja Jatkuva analyysityyppi -asetuksen välillä.
Luokittainen analyysityyppi on kuvattu aiemmin tässä artikkelissa. Jos esimerkiksi tarkastelet kyselyn pisteitä välillä 1–10, voit kysyä "Mitkä asiat vaikuttavat siihen, että kyselyn pisteet ovat 1?"
Jatkuva analyysityyppi muuttaa kysymyksen jatkuvaksi. Edellistä esimerkkiä hyödyntäen uusi kysymys on "Mitkä asiat vaikuttavat kyselyn pisteiden suurenemiseen/pienenemiseen?"
Tästä erottelusta on hyötyä, kun analysoimassasi kentässä on paljon yksilöllisiä arvoja. Seuraavassa esimerkissä tarkastellaan talojen hintoja. Ei ole merkityksellistä kysyä "Mitkä asiat vaikuttavat siihen, että talon hinta on 156 214?", koska se on tarkka eikä meillä todennäköisesti ole riittävästi tietoja mallin päätellämiseksi.
Sen sijaan haluamme ehkä kysyä "Mitkä asiat vaikuttavat talon hinnan nousuun", jolloin talojen hintoja voidaan pitää pikemminkin valikoimana kuin erillisinä arvoina.
Tulosten tulkinta: Tärkeimmät vaikuttajat
Muistiinpano
Tämän osion esimerkeissä käytetään julkisten toimialueiden talojen hintojen tietoja. Voit ladata mallitietojoukon , jos haluat seurata mukana.
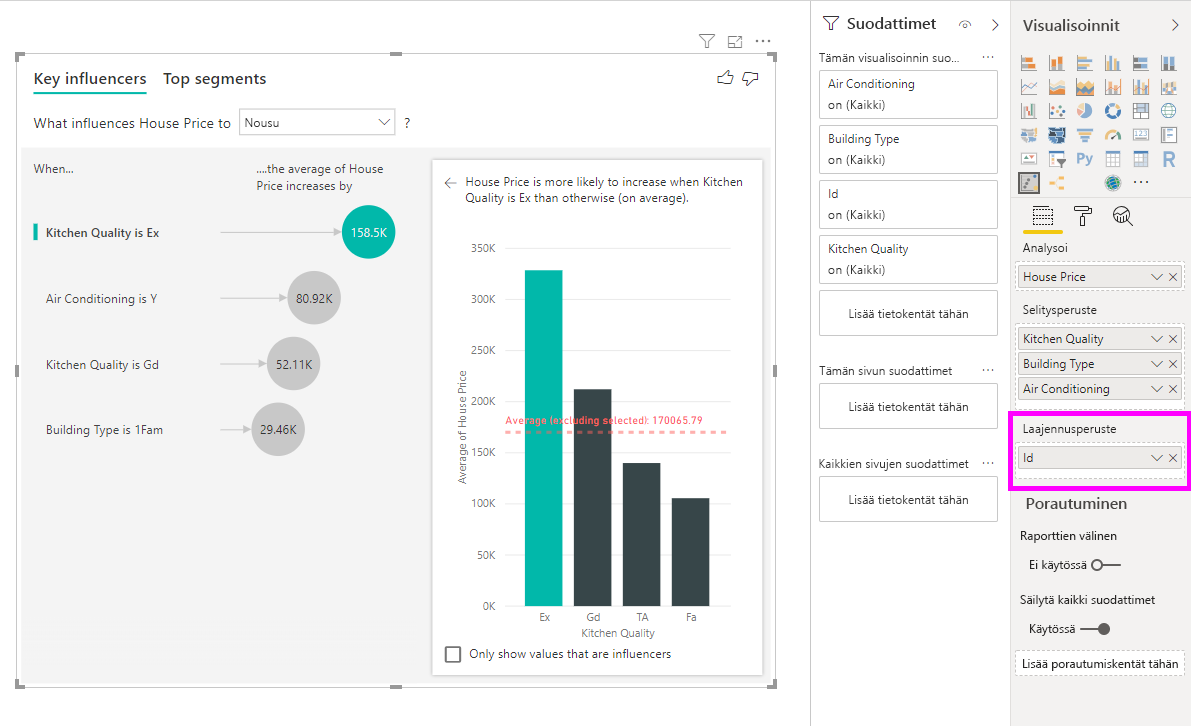
Tässä skenaariossa tarkastelemme "mitkä asiat vaikuttavat talon hinnan nousuun". Useat selittävät tekijät voivat vaikuttaa talon hintaan, kuten Year Built (vuosi, jonka talo on rakennettu), KitchenQual (keittiön laatu) ja YearRemodAdd (talon remontointivuosi).
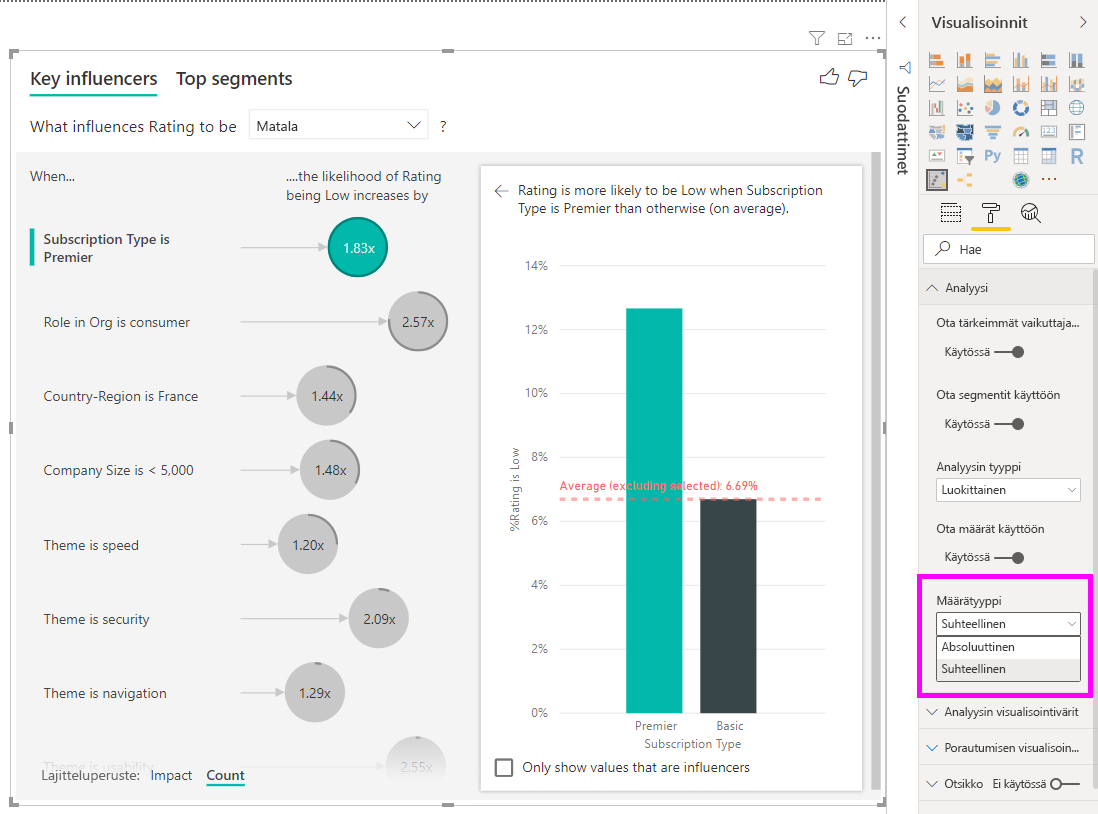
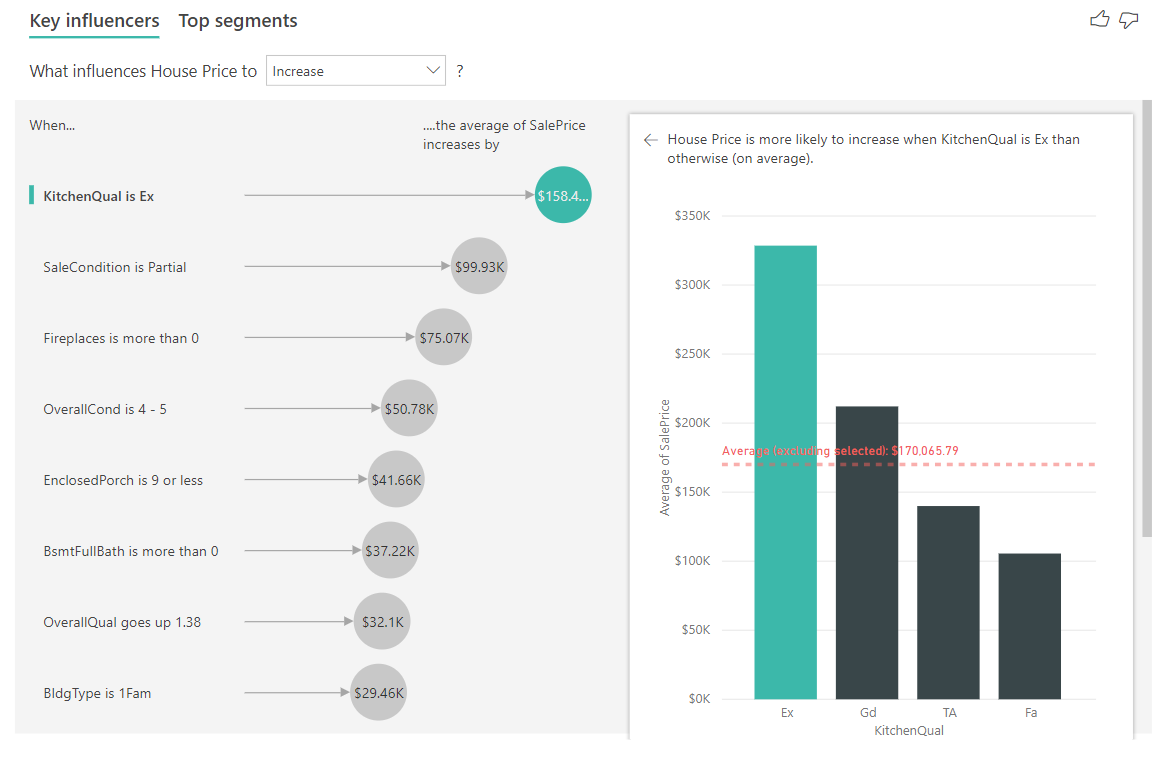
Alla olevassa esimerkissä tarkastelemme tärkeintä vaikuttajaa, jonka keittiön laatu on Erinomainen. Tulokset ovat samankaltaisia analysoitaessamme luokittaisia arvoja. Oleellisia eroja ovat:
- Oikeanpuoleinen pylväskaavio näyttää prosenttiosuuksien sijasta keskiarvot. Se siis näyttää, millainen on erinomaisella keittiöllä varustettujen talojen (vihreä palkki) keskimääräinen talon hinta verrattuna erinomaisen keittiön (pisteviiva) talon keskimääräiseen hintaan.
- Kuplassa oleva numero on yhä punaisen pisteviivan ja vihreän palkin ero, mutta se ilmaistaan lukuna (158 490 $) todennäköisyyden (1,93x) sijaan. Erinomaisella keittiöllä sijaitsevat talot ovat siis lähes 160 000 $ kalliimpia kuin talot, joiden keittiöt eivät ole erinomaisia.
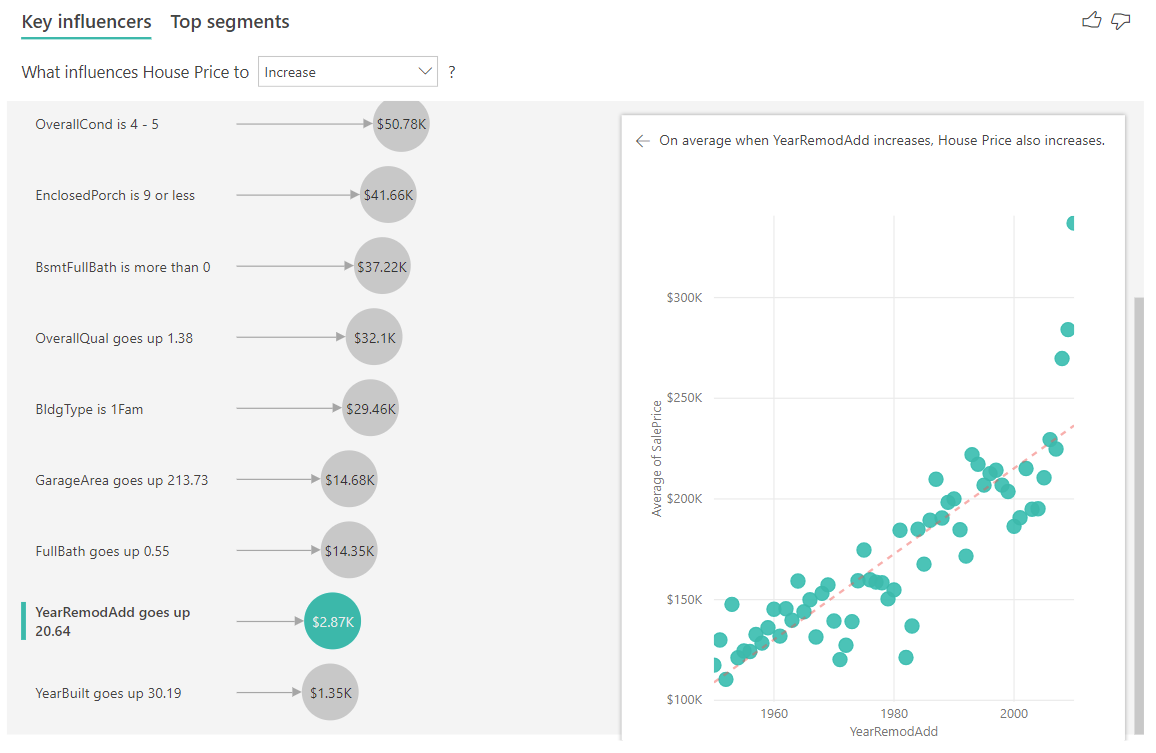
Alla olevassa esimerkissä tarkastellaan jatkuvan vaikuttavan tekijän (talon remontointivuosi) vaikutusta talon hintaan. Luokittaisten mittareiden jatkuvien vaikuttajien analysointi eroaa seuraavasti:
- Oikeanpuoleisen ruudun pistekaavio näyttää talon keskimääräisen hinnan kutakin remontointivuoden erillistä arvoa kohden.
- Kuplassa oleva arvo kertoo, paljonko talon keskimääräinen hinta kasvaa (tässä tapauksessa 2 870 $), kun remontointivuosi nousee keskihajonnan mukaan (tässä tapauksessa 20 vuotta)
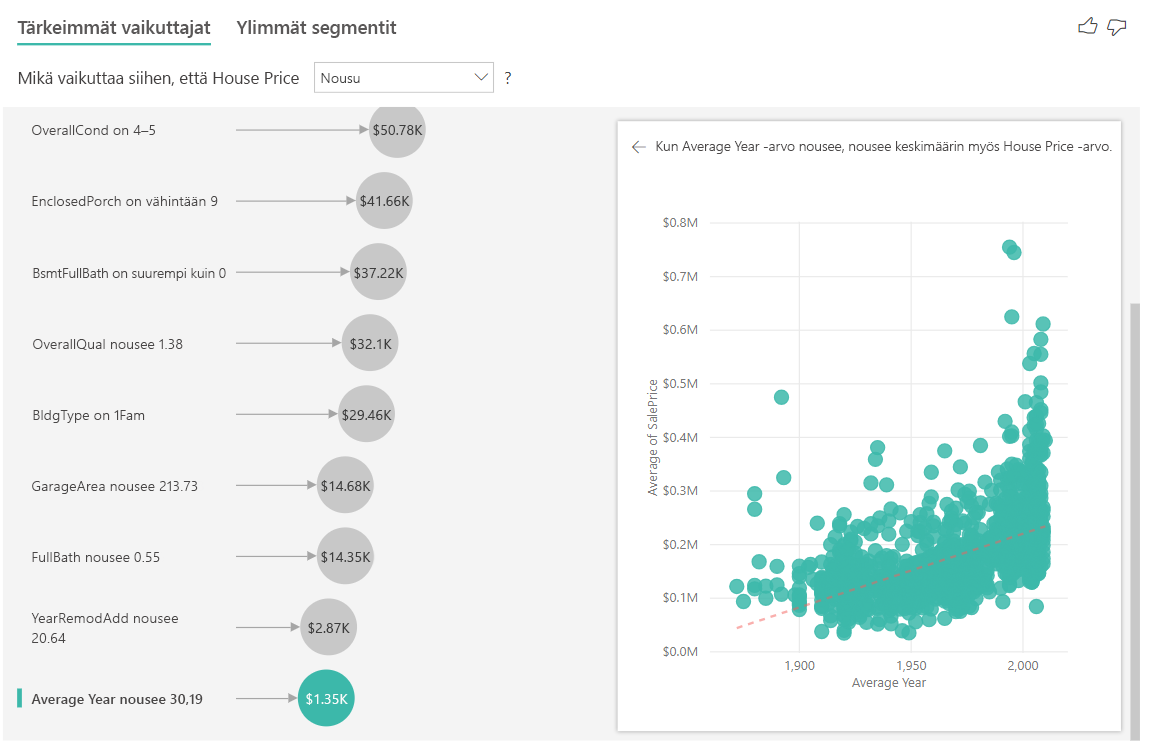
Mittareiden tapauksessa tarkastellaan talon keskimääräistä rakentamisen vuotta. Analyysi on seuraava:
- Oikeanpuoleisessa ruudussa pistekaavio näyttää talon keskimääräisen hinnan taulukon kullekin erilliselle arvolle
- Kuplassa oleva arvo kertoo, paljonko talon keskimääräinen hinta kasvaa (tässä tapauksessa 1 350 $), kun keskimääräinen vuosi nousee keskihajonnan mukaan (tässä tapauksessa 30 vuotta)
Tulosten tulkinta: Ylimmät segmentit
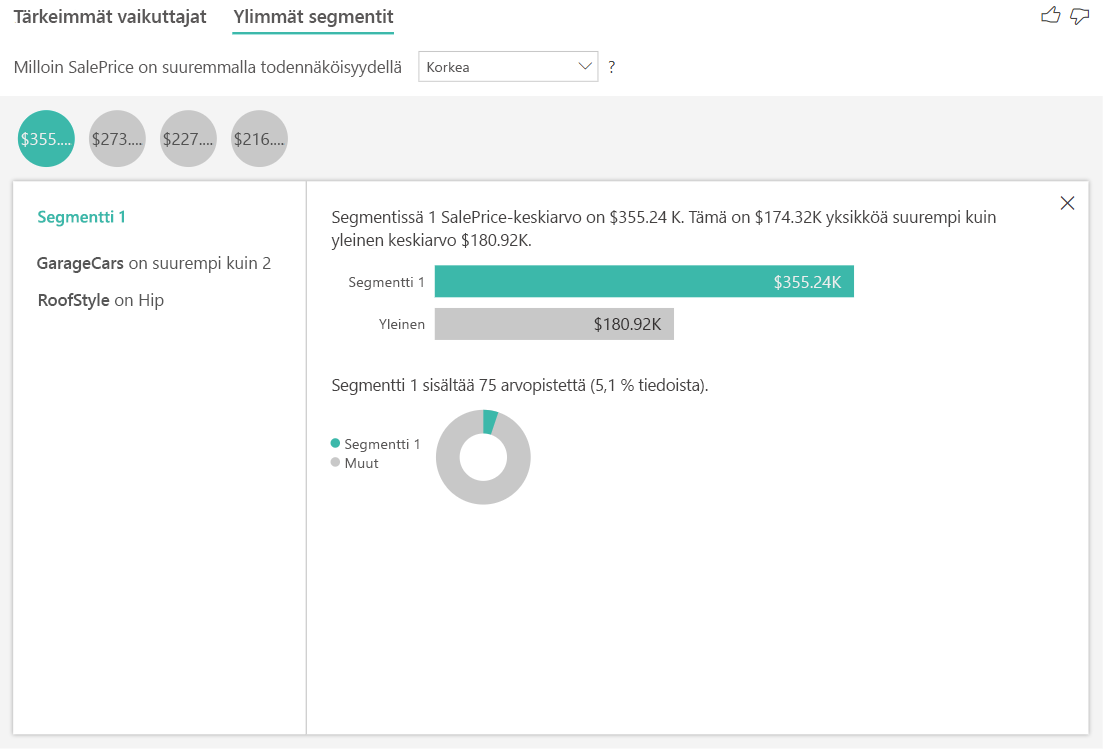
Numeeristen kohteiden ylimmät segmentit näyttävät ryhmät, joissa talojen hinnat ovat keskimäärin suuremmat kuin yleisessä tietojoukossa. Alla olevassa esimerkissä segmentti 1 koostuu taloista, joiden GarageCars-arvo (autotallin mahtuvien autojen määrä) on suurempi kuin 2 ja RoofStyle-arvo on Trendikäs. Talot, joilla on nämä ominaisuudet, niiden keskimääräinen hinta on 355 000 $, kun talojen keskimääräinen hinta tiedoissa on 180 000 $.
Analysoi arvo, joka on mittari tai yhteenvetosarake
Jos kyseessä on mittari tai yhteenvetosarake, analyysin oletusarvona on jatkuva analyysityyppi, joka kuvattiin aiemmin tässä artikkelissa. Arvoa ei voi muuttaa. Suurin ero mittari/yhteenvetosarakkeen ja yhteenvetämättömän numeerisen sarakkeen analysoinnissa on taso, jolla analyysi suoritetaan.
Yhteenvetämättömissä sarakkeissa analyysi suoritetaan aina taulukon tasolla. Talon hinnan esimerkissä analysoimme talon hinnan mittausarvoa nähdäksemme, mikä vaikuttaa talon hintaan nostavasti/laskevasti. Analyysi suoritetaan automaattisesti taulukkotasolla. Taulukossa on yksilöivä tunnus kullekin talolle, joten analyysi suoritetaan talon tasolla.
Mittayksiköissä ja yhteenvetosarakkeissa ei ole heti selvää, millä tasolla ne analysoidaan. Jos talon hinta tiivistettiin keskiarvoksi, meidän on pohdittava, millä tasolla haluamme laskea tämän keskimääräisen talon hinnan. Onko se keskimääräinen talon hinta naapuruston tasolla? Vai kenties alueellisella tasolla?
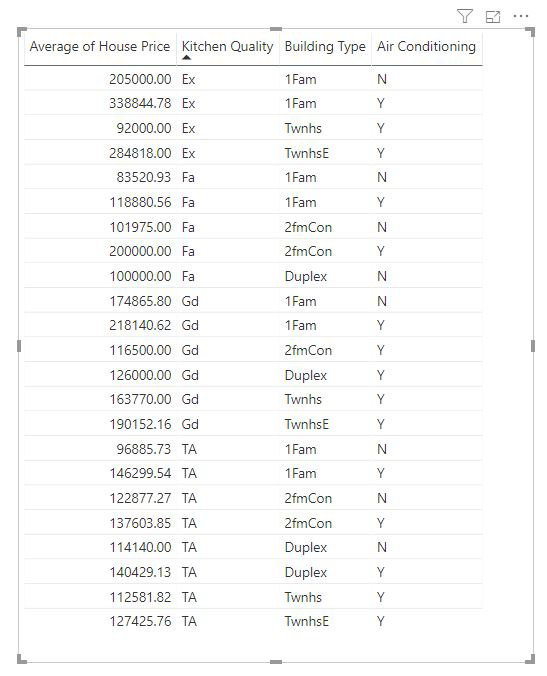
Mittarit ja yhteenvetosarakkeet analysoidaan automaattisesti käytettyjen Selitysperuste-kenttien tasolla. Oletetaan, että haluamme tarkastella kolmea kenttää selitysperusteena: keittiön laatu, rakennuksen tyyppi ja ilmastointi. Keskimääräinen talon hinta laskettaisiin kullekin näiden kolmen kentän yksilölliselle yhdistelmälle. Usein on hyödyllistä vaihtaa taulukkonäkymään sen tarkastelemiseksi, miltä arvioidut tiedot näyttävät.
Tämä analyysi on hyvin tiivistetty, joten regressiomallin voi olla vaikea löytää tiedoista mitään mallia, josta se voisi oppia. Meidän pitäisi suorittaa analyysi yksityiskohtaisemmalla tasolla parempien tulosten saamiseksi. Jos haluamme analysoida talon hintaa talon tasolla, meidän on eksplisiittisesti lisättävä analyysiin Tunnus-kenttä. Emme kuitenkaan halua, että talon tunnusta pidetään vaikuttajana. Ei ole hyödyllistä oppia, että talon tunnuksen kasvaessa talon hinta nousee. Laajenna-kentän asetus on kätevä tässä. Laajenna-asetuksen avulla voit lisätä käytettäviksi haluamasi kentät analyysin tason määrittämiseksi etsimättä uusia vaikuttajia.
Tutustu siihen, miltä visualisointi näyttää, kun lisäämme tunnuksen Laajenna-asekseen. Kun olet määrittänyt tason, jolla haluat mitata mittaria, vaikuttajien tulkitseminen on täsmälleen samanlaista kuin yhteenvetämättömissä numeerisissa sarakkeissa.
Jos haluat tietoja siitä, miten Power BI käyttää ML.NET taustalla tietojen päättelemiseksi ja merkityksellisten tietojen esille saamiseksi luonnollisella tavalla, katso Power BI tunnistaa tärkeimmät vaikuttajat ML.NET avulla.
Huomioon otettavat seikat ja vianmääritys
Mitä rajoituksia visualisointiin liittyy?
Tärkeimpien vaikuttajien visualisoinnissa on joitakin rajoituksia:
- Suoraa kyselyä ei tueta
- reaaliaikaista Azure Analysis Services- ja SQL Server Analysis Services -yhteyttä ei tueta
- Julkaisemista verkkoon ei tueta
- .NET Framework 4.6 tai uudempi vaaditaan
- SharePoint Onlinen upottamista ei tueta
Näkyviin tulee virhesanoma, joka mukaan vaikuttajia tai segmenttejä ei löytynyt. Miksi?
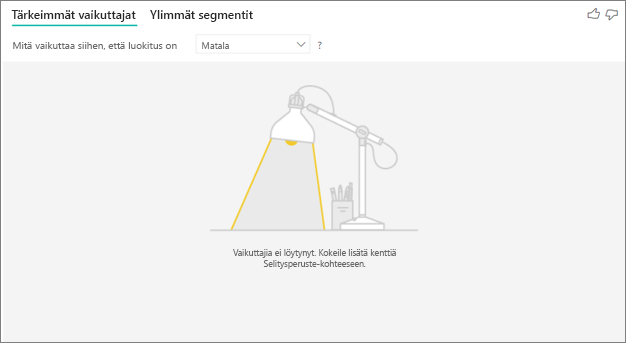
Tämä virhe ilmenee, kun sisällytit kenttiä Selitysperuste-kenttään, mutta vaikuttajia ei löytynyt.
- Sisällytit analysoimani arvon sekä Analysoi- että Selitysperuste-kohdassa. Poista se Selitysperuste-kohdasta.
- Selityskentissäsi on liian monta luokkaa, joissa on liian vähän havaintoja. Tässä tilanteessa visualisoinnin on vaikea määrittää, mitkä tekijät ovat vaikuttajia. Yleistys on vaikeaa muutaman havainnon perusteella. Jos analysoit numeerista kenttää, sinun kannattaa vaihtaa Luokittainen analyysi Jatkuvaan analyysiinAnalyysi-kortin Muotoilu-ruudussa.
- Selittävillä tekijöilläsi on riittävästi havaintoja yleistysten esittämiseen, mutta visualisointi ei löytänyt merkityksellisiä korrelaatioita raportoitaviksi.
Näen sellaisen virheen, että analysoimallani arvolla ei ole riittävästi tietoja analyysin suorittamiseksi. Miksi?
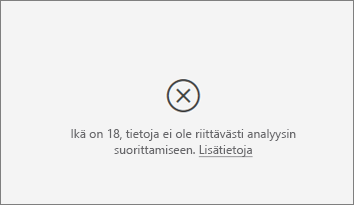
Visualisointi toimii tarkastelemalla kuvioita yhden ryhmän tiedoissa verrattuna muihin ryhmiin. Se etsii esimerkiksi alhaisia arvosanoja antaneet asiakkaat korkeita arvosanoja antaneiden asiakkaiden joukosta. Jos mallisi tiedoissa on vain vähän havaintoja, kuvioita on vaikea löytää. Jos visualisoinnilla ei ole riittävästi tietoja merkityksellisten vaikuttajien löytämiseksi, analyysin suorittamiseen tarvitaan enemmän tietoja.
Suosittelemme, että valitussa tilassa on vähintään 100 havaintoa. Tässä tapauksessa tilan muodostavat vaihtuvat asiakkaat. Vertailussa käytettävissä tiloissa on oltava vähintään 10 havaintoa. Tässä tapauksessa vertailutilan muodostavat asiakkaat, jotka eivät erkaannu.
Jos analysoit numeerista kenttää, sinun kannattaa vaihtaa Luokittainen analyysi Jatkuvaan analyysiinAnalyysi-kortin Muotoilu-ruudussa.
Näkyviin tulee virhesanoma, jonka mukaan Analysoi-kohteessa ei ole yhteenvetoa, mutta analyysi suoritetaan sen päätaulukon rivitasolla. Tämän tason muuttamista Laajenna-kenttien kautta ei sallita. Miksi?
Kun analysoidaan numeerista tai luokittaista saraketta, analyysi suoritetaan aina taulukon tasolla. Jos esimerkiksi analysoit talojen hintoja ja taulukkosi sisältää tunnussarakkeen, analyysi suoritetaan automaattisesti talon tunnuksen tasolla.
Kun analysoit mittaria tai yhteenvetosaraketta, sinun on eksplisiittisesti ilmoitettava, millä tasolla haluat suorittaa analyysin. Laajenna-asetuksen avulla voit muuttaa mittayksiköiden ja yhteenvetosarakkeiden analyysin tasoa lisäämättä uusia vaikuttajia. Jos Talon hinta on määritetty mittariksi, voit lisätä talon tunnus -sarakkeen Laajenna-arvoon, jos haluat muuttaa analyysin tasoa.
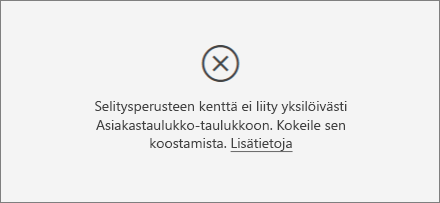
Näen sellaisen virheen, että Selitysperuste-kohdan kenttä ei ole ainutlaatuisessa suhteessa taulukkoon, joka sisältää analysoimani arvon. Miksi?
Analyysi suoritetaan analysoitavan kentän taulukkotasolla. Jos esimerkiksi analysoit palvelusi saamaa asiakaspalautetta, sinulla on ehkä taulukko, josta ilmenee, onko asiakas antanut sinulle korkean vai alhaisen luokituksen. Tässä tapauksessa analyysisi suoritetaan asiakastaulukkotasolla.
Jos sinulla on asiaan liittyvä taulukko määritettynä rakeisempina kuin mittausarvosi sisältävä taulukko, näet tämän virheen. Esimerkki:
- Analysoit, mikä saa asiakkaat antamaan alhaisia luokituksia palvelullesi.
- Haluat nähdä, vaikuttaako heidän antamiin arvosteluihin laite, jolla asiakas käyttää palveluasi.
- Asiakas voi käyttää palvelua monin eri tavoin.
- Seuraavassa esimerkissä asiakas 10000000 käyttää palvelua sekä selaimella että taulutietokoneella.
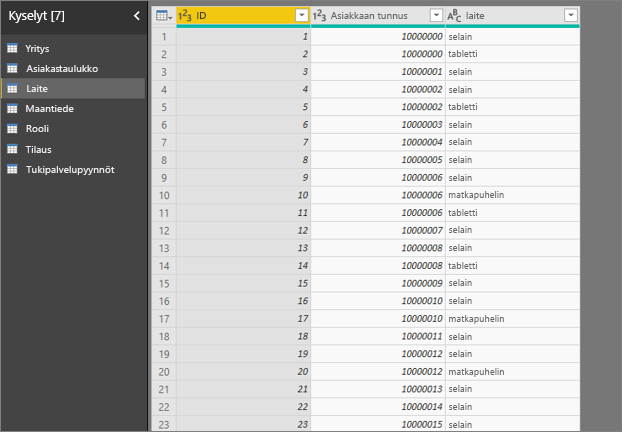
Jos yrität käyttää laitesaraketta selittävänä tekijänä, saat seuraavan virheilmoituksen:
Tämä virhesanoma tulee näkyviin, koska laitetta ei ole määritetty asiakastasolla. Yksi asiakas voi käyttää palvelua useilla laitteilla. Jotta visualisointi voi etsiä kuvioita, laitteesta on tehtävä asiakkaan ominaisuus. Voit käyttää useita ratkaisuja, jotka riippuvat siitä, miten ymmärrät yrityksen toiminnan:
- Voit muuttaa laskettavan laitteiden yhteenvetoa. Käytä laskentaa esimerkiksi, jos laitteiden määrä saattaa vaikuttaa asiakkaan antamaan pistemäärään.
- Voit pivotoida laitesarakkeen nähdäksesi, vaikuttaako palvelun käyttäminen tietyllä laitteella asiakkaan luokitukseen.
Tässä esimerkissä tiedot pivotoitiin uusien sarakkeiden luomiseksi selaimelle, mobiililaitteelle ja taulutietokoneelle (varmista, että poistat suhteesi ja luot ne uudelleen mallinnusnäkymässä tietojen pivotoinnin jälkeen). Voit nyt käyttää näitä laitteita Selitysperuste-kohdassa. Kaikki laitteet osoittavat vaikuttajiksi, ja selaimella on suurin vaikutus asiakkaan antamaan pistemäärään.
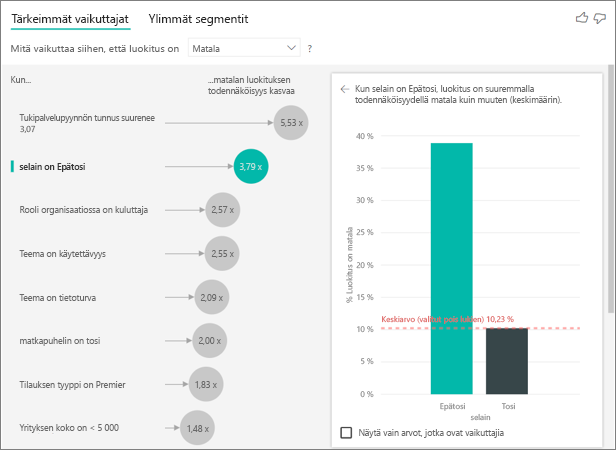
Tarkemmin sanoen, asiakkaat, jotka eivät käytä palvelua selaimen kautta, antavat 3,79 kertaa todennäköisemmin alhaiset pisteet kuin muut asiakkaat. Alempana luettelossa mobiililaitteilla arvo on päinvastainen. Asiakkaat, jotka käyttävät mobiilisovellusta, antavat todennäköisemmin alhaiset pisteet kuin muut asiakkaat.
Näen varoituksen, että mittareita ei sisälly analyysiini. Miksi?
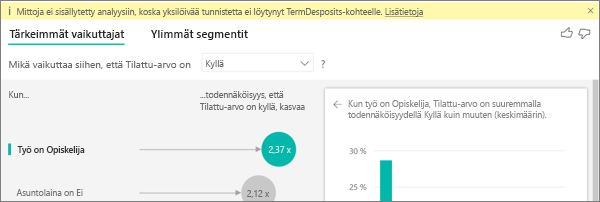
Analyysi suoritetaan analysoitavan kentän taulukkotasolla. Jos analysoit asiakkaiden vaihtuvuutta, sinulla saattaa olla taulukko, joka kertoo, onko asiakas vaihtunut vai ei. Tässä tapauksessa analyysisi suoritetaan asiakastaulukkotasolla.
Mittarit ja koosteet analysoidaan oletusarvoisesti taulukkotasolla. Jos käytössä olisi keskimääräisten kuukausittaisten kulujen mittari, se analysoitaisiin asiakastaulukkotasolla.
Jos asiakastaulukolla ei ole yksilöivää tunnusta, et voi arvioida mittaria, ja analyysi jättää sen huomiotta. Jos haluat välttää tämän tilanteen, varmista, että arvon sisältävällä taulukolla on yksilöivä tunnus. Tässä tapauksessa kyse on asiakastaulukosta ja yksilöivä tunnus on asiakastunnus. Voit myös lisätä indeksisarakkeen helposti Power Queryn avulla.
Saan varoituksen, että analysoimallani arvolla on yli 10 yksilöllistä arvoa ja että tämä voi vaikuttaa analyysini laatuun. Miksi?
AI-visualisointi voi analysoida luokittaisia kenttiä ja numeerisia kenttiä. Luokittaisissa kentissä vaihtuvuus on esimerkiksi Kyllä tai Ei ja asiakastyytyväisyys on suuri, keskitasoinen tai pieni. Analysoitavien luokkien määrän suurentaminen tarkoittaa, että luokkaa kohti on vähemmän havaintoja. Tässä tilanteessa visualisoinnin on vaikea löytää tiedoista kuvioita.
Kun analysoit numeerisia kenttiä, voit valita, käsitelläänkö numeerisia kenttiä, kuten tekstiä, jolloin suoritat saman analyysin kuin luokittaisille tiedoille (Luokittainen analyysi). Jos sinulla on paljon erillisiä arvoja, suosittelemme, että vaihdat analyysin jatkuvaan analyysiin , koska se tarkoittaa, että kuvioita voidaan päätellä numeroiden suurenemisesta tai pienenemisestä sen sijaan, että niitä käsiteltäisi yksittäisinä arvoina. Voit vaihtaa Luokittaisen analyysin Jatkuvaan analyysiinAnalyysi-kortin Muotoilu-ruudussa.
Vahvempien vaikuttajien löytämiseksi suosittelemme ryhmittelemään samanlaiset arvot yksittäiseksi yksiköksi. Jos yksi mittausarvoistasi on hinta, saat luultavasti parempia tuloksia ryhmittämällä samansuuntaiset hinnat Kallis-, Keskihintainen- ja Halpa-luokkiin sen sijaan, että käyttäisit yksittäisiä hintapisteitä.
Tiedoissani on tekijöitä, jotka näyttävät tärkeimpien vaikuttajien olevan tärkeitä, mutta eivät ole. Miten näin voi käydä?
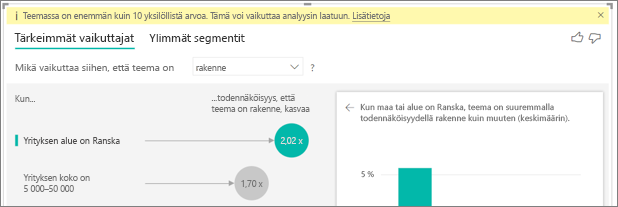
Seuraavassa esimerkissä kuluttaja-asiakkaat ovat alhaisten luokitusten taustalla ja 14,93 % luokituksista on alhaisia. Myös järjestelmänvalvojan rooliin liittyy korkea alhaisten luokitusten prosenttiosuus (13,42 %), mutta roolia ei pidetä vaikuttajana.
Tämä johtuu siitä, että visualisointi huomioi myös arvopisteiden määrän vaikuttajia etsiessään. Seuraavassa esimerkissä kuluttajia on yli 29 000 kuluttajaa ja 10 kertaa vähemmän järjestelmänvalvojia (noin 2 900). Heistä vain 390 on antanut alhaisen luokituksen. Visualisoinnilla ei ole riittävästi tietoja määrittämään, onko se löytänyt järjestelmänvalvojien arvioihin koskevan kuvion vai onko kyseessä vain sattuma.
Mitkä ovat tärkeimpien vaikuttajien arvopisterajat? Suoritamme analyysin 10 000 arvopisteiden otokselle. Yhden puolen kuplat näyttävät kaikki löytyneet vaikuttajat. Toisen puolen pylväskaavioissa ja pistekaavioissa käytetään kyseisten tärkeiden visualisointien otosstrategioita.
Miten tärkeimmät vaikuttajat lasketaan luokittaista analyysia varten?
Taustalla AI-visualisointi suorittaa ML.NET avulla logistista regressiota tärkeimpien vaikuttajien laskemiseksi. Logistinen regressio on tilastollinen malli, joka vertaa eri ryhmiä toisiinsa.
Jos haluat nähdä, mistä alhaiset luokitukset ovat johtuneet, logistinen regressio tarkastelee sitä, miten alhaisen pistemäärän antaneet asiakkaat eroavat korkean pistemäärän antaneista. Jos sinulla on useita luokkia, kuten korkea, neutraali ja alhainen, tarkastelet, miten alhaisen luokituksen antaneet asiakkaat eroavat asiakkaista, jotka eivät antaneet alhaista luokitusta. Miten tässä tapauksessa alhaisen pistemäärän antaneet asiakkaat eroavat asiakkaista, jotka antoivat korkean tai neutraalin luokituksen?
Logistinen regressio etsii tiedoista kuvioita ja etsii, miten alhaisen luokituksen antaneet asiakkaat mahdollisesti eroavat korkean luokituksen antaneista. Se saattaa esimerkiksi havaita, että asiakkaat, joilla on enemmän tukipalvelupyyntöjä, antavat prosentuaalisesti suuremman määrän alhaisia luokituksia kuin ne, joilla tukipalvelupyyntöjä on vähän tai ei lainkaan.
Logistinen regressio huomioi myös arvopisteiden määrän. Jos esimerkiksi asiakkaat, jotka ovat järjestelmänvalvojan roolissa, antavat suhteessa enemmän kielteisiä pistemääriä, mutta järjestelmänvalvojia on vain muutama, tätä ei pidetä vaikutusvaltaisena. Tämä määritys tehdään, koska arvopisteitä ei ole riittävästi kuvion määrittämiseksi. Tilastoanalyysitestiä eli Waldin testiä käytetään sen määrittämiseen, voidaanko tekijää pitää vaikuttajana. Visualisointi määrittää kynnysarvon p-arvolla 0,05.
Miten tärkeimmät vaikuttajat lasketaan numeerista analyysia varten?
Taustalla AI-visualisointi suorittaa ML.NET avulla lineaarista regressiota tärkeimpien vaikuttajien laskemiseksi. Lineaarinen regressio on tilastollinen malli, joka tarkastelee analysoitavan kentän muutoksia selittävien tekijöiden perusteella.
Jos esimerkiksi analysoit talojen hintoja, lineaarinen regressio näyttää, että erinomaiset keittiön hA:t vaikuttavat talon hintaan. Onko erinomaisella keittiöillä varustettujen talojen hinta yleisesti alhaisempi tai korkeampi kuin sellaisten talojen, joissa ei ole erinomaista keittiötä?
Lineaarinen regressio huomioi myös arvopisteiden määrän. Jos esimerkiksi tenniskenttä nostaa talon hintaa, mutta meillä on vain vähän taloja, joissa on tenniskenttä, tätä tekijää ei pidetä vaikutusvaltaisena. Tämä määritys tehdään, koska arvopisteitä ei ole riittävästi kuvion määrittämiseksi. Tilastoanalyysitestiä eli Waldin testiä käytetään sen määrittämiseen, voidaanko tekijää pitää vaikuttajana. Visualisointi määrittää kynnysarvon p-arvolla 0,05.
Miten segmentit lasketaan?
Taustalla AI-visualisointi suorittaa ML.NET avulla päätöspuuta kiinnostavien aliryhmien löytämiseksi. Päätöspuun tarkoituksena on saada näkyviin aliryhmä arvopisteitä, jolla kiinnostava mittausarvo on suhteellisen korkealla. Kyse voi olla asiakkaista, joilla on alhaiset luokitukset, tai taloista, joiden hinnat ovat korkeat.
Päätöspuu ottaa kunkin selittävän tekijän käsittelyyn ja pyrkii päättelemään, millä tekijällä saadaan paras jako. Jos esimerkiksi suodatat tiedot niin, että ne sisältävät vain suuryritysasiakkaat, erottaako tämä joukosta asiakkaat, jotka antoivat korkean tai alhaisen luokituksen? Tai ehkä on parempi suodattaa tiedot niin, että ne sisältävät vain tietoturva-asioita kommentoineet asiakkaat?
Kun päätöspuu tekee jaon, se vie tietojen aliryhmän ja määrittää kyseisten tietojen seuraavaksi parhaan jaon. Tässä tapauksessa aliryhmä koostuu asiakkaista, jotka kommentoivat tietoturva-asioita. Kunkin jaon jälkeen päätöspuussa käsitellään myös sitä, onko kyseisellä ryhmällä riittävästi arvopisteitä, jotta se olisi kyllin edustava kuvion päättelemiseksi. Jos näin ei ole, kyseessä on tietojen poikkeama, ei todellinen segmentti. Toista tilastoanalyysitestiä sovelletaan jaetun ehdon tilastollisen merkittävyyden tarkistamiseksi p-arvon ollessa 0,05.
Kun päätöspuun suorittaminen on päättynyt, se ottaa kaikki jaot, kuten tietoturvakommentit ja suuryritykset, ja luo Power BI -suodattimia. Tämä suodatinyhdistelmä pakataan segmentiksi visualisoinnissa.
Miksi eräät tekijät muuttuvat vaikuttajiksi tai lakkaavat olemasta vaikuttajia, kun siirrän lisää kenttiä Selitysperuste-kenttään ?
Visualisointi arvioi kaikki selittävät tekijät yhdessä. Tekijä voi olla vaikuttaja yksinään, mutta muiden tekijöiden ohella ei välttämättä. Oletetaan, että haluat analysoida sitä, mikä nostaa talon hintaa. Selittävinä tekijöinä ovat makuuhuoneiden ja talon koko:
- Yksinään makuuhuoneiden lisääminen voi olla talon hintaa nostava tekijä.
- Jos talon koko sisällytetään analyysiin, se tarkoittaa, että näet, mitä makuuhuoneille tapahtuu talon koon pysyessä vakiona.
- Jos rakennuksen vakiokoko on 1500 neliömetriä, on epätodennäköistä, että makuuhuoneiden määrän jatkuva kasvu nostaisi talon hintaa dramaattisesti.
- Makuuhuoneet eivät ehkä ole yhtä tärkeitä kuin ennen talon koon huomioimista.
Raportin jakaminen työtoverin kanssa Power BI:ssä edellyttää, että teillä kummallakin on oma Power BI Pro -käyttöoikeus tai että raportti on tallennettu Premium-kapasiteettiin. Katso raporttien jakaminen.