Suuren tiheyden viivaotanta Power BI:ssä
Power BI:n näytteenottoalgoritmi parantaa visualisointeja, joissa käytetään suuren tiheyden viivaotantaa. Saatat esimerkiksi luoda viivakaavion vähittäismyymälöittesi myyntituloksista, ja jokaisella myymälällä on yli 10 000 myyntikuittia joka vuosi. Tällaisten myyntitietojen viivakaavio ottaa näytteen jokaisen myymälän tiedoista ja luo useita sarjoja kuvaavan viivakaavion, joka edustaa pohjana olevia tietoja. Muista valita tiedoista merkityksellinen esitys, jotta voit havainnollistaa, miten myynti vaihtelee ajan kuluessa. Tämä käytäntö on yleinen suuren tiheyden tietojen visualisoinnissa. Suuren tiheyden tietojen näytteenoton tiedot on kuvattu tässä artikkelissa.
Muistiinpano
Tässä artikkelissa kuvattu suuren tiheyden näytteenoton algoritmi on käytettävissä sekä Power BI Desktopissa että Power BI -palvelu.
Suuren tiheyden viivaotannan toimintaperiaate
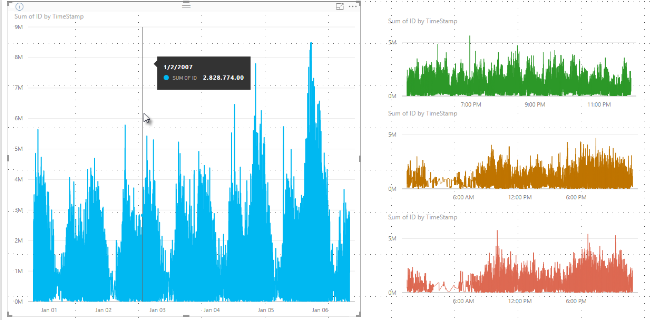
Aiemmin Power BI valitsi näytteen arvopisteitä koko pohjana olevasta tietojoukosta deterministisesti. Jos esimerkiksi visualisoinnissa on suuren tiheyden tietoja yhden kalenterivuoden ajalta, visualisoinnissa saattaa näkyä 350 arvopisteiden otos. Sillä varmistetaan, että koko tietojoukko esitetään visualisoinnissa. Asian havainnollistamiseksi voidaan ajatella esimerkiksi osakkeen hintaa yhden vuoden ajalta. Sitä kuvataan viivakaaviovisualisoinnilla, jossa valitaan 365 arvopistettä. Tämä on yksi arvopiste jokaiselle päivälle.
Tässä tilanteessa osakkeen hinnalla on monia arvoja jokaisena päivänä. Luonnollisesti osakkeella on alin ja ylin arvo, mutta ne voivat ilmetä mihin tahansa aikaan sellaisina aikoina, kun osakkeilla käydään kauppaa. Suuren tiheyden viivaotannan yhteydessä, jos pohjana oleva tietomalli otetaan joka päivä klo 10.30 ja klo 12.00, saat edustavan tilannevedoksen pohjatiedoista, kuten hinnan klo 10.30 ja klo 12.00. Tilannevedos ei kuitenkaan välttämättä sieppaa kyseisen päivän edustavan arvopisteen osakkeen ylintä ja ainta arvoa. Tässä ja monissa muissa tilanteissa näyte kuvaa pohjatietoja edustavasti mutta ei aina pysty sieppaamaan tärkeitä seikkoja, kuten tässä tapauksessa osakkeen ylintä ja alinta hintaa päivittäin.
Suuren tiheyden tiedoista otetaan näytteitä siksi, että näin voidaan kohtuullisen nopeasti luoda visualisointeja, joiden vuorovaikutteisuus säilyy. Jos visualisoinnissa on liikaa arvopisteitä, sen käyttö hidastuu ja trendit voivat poiketa näkyvyydestä. Näytteenottoalgoritmeja luodaan siksi, että tiedoista saataisiin tuotettua parhaita mahdollisia visualisointeja. Power BI Desktopissa algoritmi tarjoaa parhaan vasteajan ja esityksen yhdistelmän ja selkeän säilyttäen tärkeät arvopisteet jokaisesta sektorista.
Uuden viivaotanta-algoritmin toimintaperiaate
Suuren tiheyden viivaotannan algoritmi on käytettävissä jatkuvan x-akselin sisältävien viivakaavioiden ja aluekaavioiden visualisointiin.
Suuren tiheyden visualisointia varten Power BI viipaloi älykkäästi suuren tiheyden tiedot lohkoihin ja poimii sitten tärkeät arvopisteet edustamaan kutakin lohkoa. Suuren tiheyden tietojen viipalointiprosessi on viritetty sen varmistamiseksi, että tuloksena syntyvää kaaviota ei voi visuaalisesti erottaa kaaviosta, joka syntyisi kaikista pohjana olevista arvopisteistä, mutta se on nopeampi ja vuorovaikutteisempi.
Suuren tiheyden viivavisualisointien vähimmäis- ja enimmäisarvot
Kaikkia visualisointeja koskevat seuraavat rajoitukset:
Useimmissa visualisoinneissa näytettävien arvopisteiden enimmäismäärä on 3 500 riippumatta pohjatietojen arvopisteiden tai sarjojen määrästä. Katso poikkeukset seuraavasta luettelosta. Jos sinulla on esimerkiksi kymmenen sarjaa, joista kussakin on 350 arvopistettä, visualisoinnin arvopisteiden enimmäismäärä on saavutettu. Jos sarjoja on yksi, siinä voi olla jopa 3 500 arvopistettä, jos algoritmi pitää sitä pohjana olevien tietojen parhaana näytteenotona.
Visualisoinneissa voi olla enintään 60 sarjaa . Jos sarjoja on yli 60, jaa tiedot ja luo useita visualisointeja, joista kussakin on korkeintaan 60 sarjaa. On hyvä käyttää osittajaa näyttämään vain segmentit tiedoista, mutta vain tietyille sarjoille. Jos esimerkiksi näytät selitteessä kaikki aliluokat, voit osittajan avulla suodattaa tiedot yleisen luokan mukaan samalla raporttisivulla.
Tietorajoitusten enimmäismäärä on korkeampi seuraaville visualisointityypeille, jotka ovat poikkeuksia 3 500 arvopisteen rajaan:
- 150 000 arvopistettä enimmäismäärä R-visualisoinnille.
- 30 000 arvopistettä Azure Map -visualisointeihin.
- 10 000 arvopistettä joillekin pistekaaviomäärityksille (pistekaavioiden oletusarvo on 3 500).
- 3 500 kaikille muille visualisoinnille suuren tiheyden näytteenoton avulla. Jotkin muut visualisoinnit saattavat visualisoida enemmän tietoja, mutta ne eivät käytä näytteenottoa.
Nämä parametrit varmistavat, että Power BI Desktopin visualisoinnit hahmontavat nopeasti ja että niiden vuorovaikutteiset ominaisuudet eivät aiheuta liiallisia laskennallisia kuormituksia visualisointia hahmontavalle tietokoneelle.
Suuren tiheyden viivavisualisointien edustavien arvopisteiden arvioiminen
Kun pohjatietojen arvopisteiden määrä ylittää visualisoinnissa edettävien arvopisteiden enimmäismäärän, aloitetaan prosessi nimeltä lokerointi . Lokeroiminen lokeroi pohjana olevat tiedot lokeroiksi kutsuttuihin ryhmiin ja sitten iteratiivisesti tarkentaa näitä lokeroita.
Algoritmi luo mahdollisimman monta lokeroa, jotta visualisointiin saadaan suurin askelväli. Algoritmi etsii jokaisen lokeron sisältä pienimmän ja suurimman tietoarvon sen varmistamiseksi, että tärkeät ja merkittävät arvot, kuten poikkeavat arvot, siepataan ja näytetään visualisoinnissa. Tietojen lokeroimisen ja arvioinnin tulosten pohjalta Power BI määrittää visualisoinnin x-akselin vähimmäistarkkuuden, jotta visualisointiin saadaan mahdollisimman paljon askelvärejä.
Kuten aiemmin mainittiin, pienin askelväli kullekin sarjalle on 350 pistettä ja suurin 3 500 pistettä useimmille visualisoinnille. Poikkeukset luetellaan edellisissä kappaleissa.
Kutakin lokeroa edustaa kaksi arvopistettä, joista tulee lokeroa edustavia arvopisteitä visualisoinnissa. Arvopisteet ovat lokeron ylin ja ainerha arvo. Valitsemalla ylä- ja alaarvon lokerointiprosessi varmistaa, että visualisointiin tallennetaan ja hahmonnetaan kaikki tärkeät suuret arvot tai merkittävät pienet arvot.
Tämä kuulostaa siltä kuin satunnaisten poikkeavien havaintojen tallennuksen ja visualisoinnin näyttämisen varmistamiseksi olisi paljon analyysia, olet oikeassa. Juuri siitä syystä algoritmi ja lokerointiprosessi on valmis.
Työkaluvihjeet ja suuren tiheyden viivaotanta
On tärkeää huomioida, että tämä lokerointiprosessi, jossa lokeron enimmäis- ja vähimmäisarvot siepataan ja esitetään lokerossa, saattaa vaikuttaa työkaluvihjeiden näyttämään tietoihin, kun hiiri viedään arvopisteiden ylle. Käytetään mallina artikkelin osakkeiden hintoja.
Oletetaan, että olet luomassa visualisointia osakkeen hinnasta ja vertaat kahta eri osaketta, joista kummassakin käytetään suuren tiheyden näytteenottoa. Sarjojen pohjatiedoissa on useita arvopisteitä. Saatat esimerkiksi siepata osakkeen hinnan päivän jokaisena sekuntina. Suuren tiheyden näytteenottoalgoritmi lokeroi kunkin sarjan erillään toisistaan.
Oletetaan sitten, että ensimmäisen osakkeen hinta nousee kello 12.02 ja laskee nopeasti 10 sekuntia myöhemmin. Tämä on tärkeä arvopiste. Kun osake lokeroitaa, klo 12.02:n huippuarvo on lokeron edustava arvopiste.
Toisen osakkeen ylin tai alainen arvo ei kuitenkaan ollut kyseisen ajan sisältävässä lokerossa ylin tai alainen. Lokeron, joka sisältää klo 12.02:n, ylin ja aakkonen ilmeni ehkä kolme minuuttia myöhemmin. Kun tässä tilanteessa viivakaavio luodaan ja viet hiiren osoittimen klo 12.02:n ylle, näet työkaluvihjeessä ensimmäisen osakkeen arvon. Tämä johtuu siitä, että se hyppäsi klo 12.02 ja arvo valittiin kyseisen lokeron ylimmäksi arvopisteeksi. Et kuitenkaan näe mitään arvoa työkaluvihjeessä klo 12.02 toisen osakkeen osalta. Tämä johtuu siitä, että toisella osakkeella ei ollut ylintä tai aalhaista arvoa lokerossa, joka sisältää klo 12.02:n. Toisen osakkeen osakkeelle ei siis ole näytettävää arvoa klo 12.02 eikä näin ollen näytettävää tietoa työkaluvihjeessäkään.
Tämä tilanne toistuu työkaluvihjeissä usein. Tietyn lokeron suuret ja alhaiset arvot eivät todennäköisesti täysin täsmää tasaisesti skaalatun x-akselin arvopisteiden kanssa, eikä työkaluvihje näytä arvoa.
Suuren tiheyden viivaotannan ottaminen käyttöön
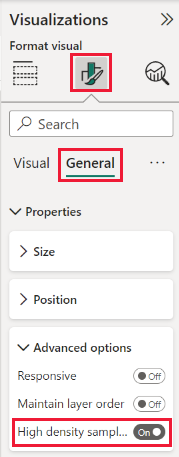
Algoritmi on oletusarvoisesti käytössä. Voit muuttaa tätä asetusta siirtymällä Yleiset-kortin Muotoilu-ruutuun, jonka alaosassa näet Suuren tiheyden näytteenotto -liukusäätimen. Valitse liukusäädin, jonka valitsin on käytössä tai ei käytössä.
Huomioitavat asiat ja rajoitukset
Suuren tiheyden viivaotannan algoritmi on merkittävä parannus Power BI:hin, mutta suuren tiheyden arvojen ja tietojen käsittelyssä on muutamia huomioon otettavia seikkoja.
Parannettu askelväli ja lokerointiprosessi saattavat aiheuttaa sen, että työkaluvihjeet näyttävät arvon vain, jos kohdistimen tiedot on tasattu edustavasti. Lisätietoja on tämän artikkelin Työkaluvihjeet ja suuren tiheyden viivaotanta -osiossa.
Kun tietolähteen koko on liian suuri, algoritmi poistaa sarjat (selitteen elementit) tietojen tuomisen enimmäisrajoitusten noudattamiseksi.
- Tässä tilanteessa algoritmi määrittää selitesarjat aakkosjärjestykseen aloittaen selitteen osien luettelon aakkosjärjestyksessä, kunnes tietojen tuomisen enimmäisraja täyttyy. Sen jälkeen lisäsarjoja ei tuoda.
Kun pohjana olevassa tietojoukossa on yli 60 sarjaa, sarjojen enimmäismäärä, algoritmi määrää sarjat aakkosjärjestykseen ja poistaa sarjat, jotka ovat aakkosjärjestyksessä 60. sarjan jälkeen.
Jos tietojen arvot eivät ole tyypiltään numeerisia tai päivämääriä/kellonaikaisia, Power BI ei käytä algoritmia ja palaa käyttämään aiempaa muun kuin suuren tiheyden näytteenoton algoritmia.
Algoritmi ei tue Näytä kohteet, joilla ei ole tietoja -asetusta.
Algoritmia ei tueta, kun käytössä on reaaliaikainen yhteys SQL Server Analysis Services -versiossa 2016 tai aiemmassa versiossa isännöityyn malliin. Sitä tuetaan Power BI:ssä tai Azure Analysis Servicesissä isännöidyissä malleissa.