OCR:n suorittaminen monikielisillä asiakirjoilla
Tekstin tunnistuksen (OCR) avulla voit etsiä ja poimia tekstiä kuvista tai näytöstä.
Vaikka useimmissa skenaarioissa tekstiä on käsiteltävä tietyllä kielellä, joissakin tapauksissa lähteet ovat monikielisiä.
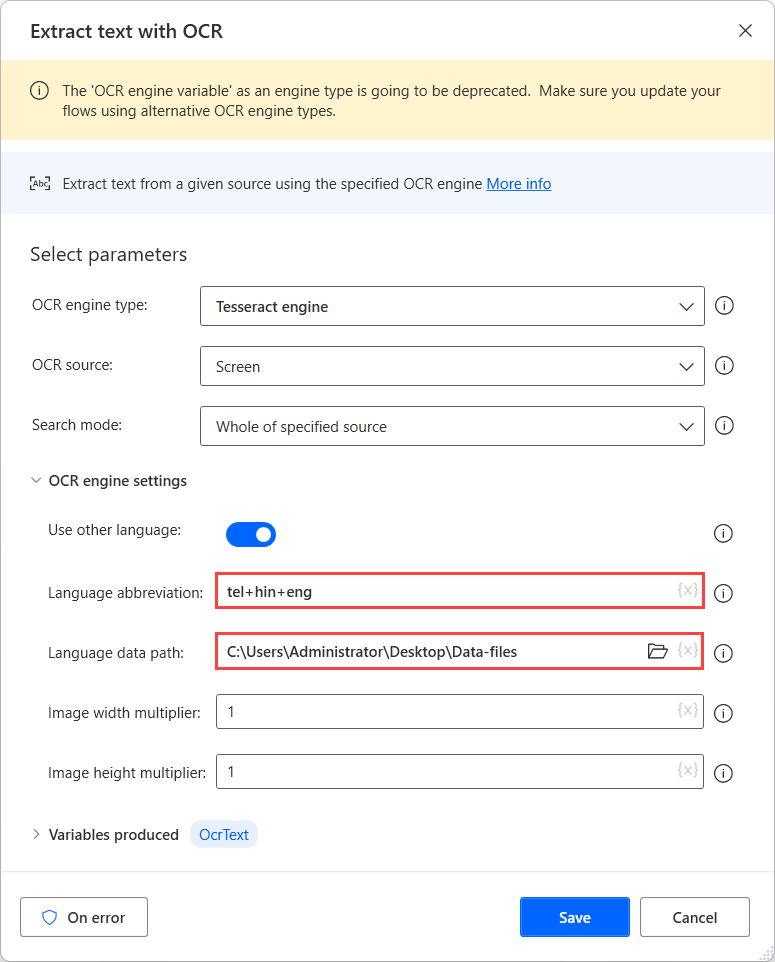
Jos haluat suorittaa OCR:n näille lähteille, käytä Tesseract-ydintä vastaavaan OCR-toimintoon ja ota käyttöön Käytä muita kieliä -asetus ydinasetuksissa.
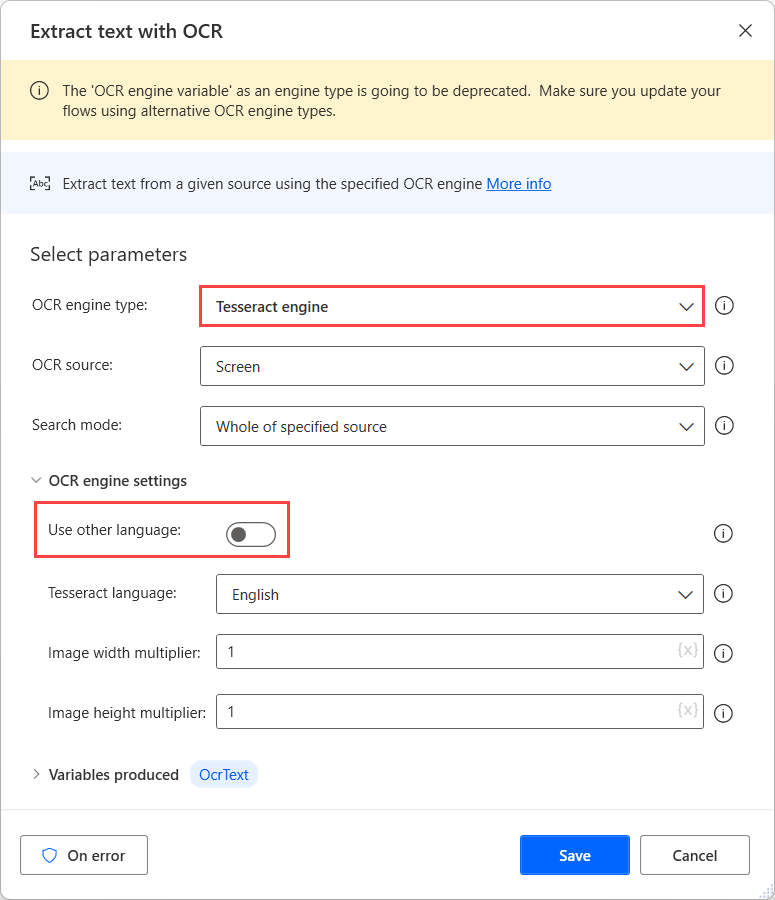
Kun Käytä muita kieliä -asetus on käytössä, toiminto näyttää kaksi lisäasetusta: Kielen lyhenne- ja Kielen tietopolku -kentät.
Kielen lyhenne -kenttä osoittaa ytimelle, mitä kieltä OCR:n aikana etsitään. Kielen tietopolku -kenttä sisältää kielen datatiedostot (.traineddata), joita käytetään OCR-moduulin harjoittamiseen.
Kun olet ladannut tarvittavien kielten datatiedostot, siirrä ne yleiseen kansioon, jotta ne ovat käytettävissä samalla polulla.
Valitse sitten luotu tiedosto Kielen tietopolku -kentässä ja täytä vastaavat kielikoodit Kielen lyhenne -kenttään. Käytä lisäksi kielikoodien erottamiseksi plus-merkkiä (+).
Huomautus
Löydät kaikki käytettävissä olevat kielikoodit kielidatatiedostojen lähteestä. Seuraavassa esimerkissä käytetyt koodit kuvaavat telugua, hindiä ja englantia.