Security domain: operational security
The operational security domain ensures ISVs implement a strong set of security mitigation techniques against a myriad of threats faced from threat actors. This is designed to protect the operating environment and software development processes to build secure environments.
Awareness training
Security awareness training is important for organizations as it helps to minimize the risks stemming from human error, which is involved in more than 90% of security breaches. It helps employees understand the importance of security measures and procedures. When security awareness training is offered it reinforces the importance of a security-aware culture where users know how to recognize and respond to potential threats. An effective security awareness training program should include content that covers a wide range of topics and threats that users might face, such as social engineering, password management, privacy, and physical security.
Control No. 1
Please provide evidence that:
The organization provides established security awareness training to information system users (including managers, senior executives, and contractors):
As part of initial training for new users.
When required by information system changes.
Organization-defined frequency of awareness training.
Documents and monitors individual information system security awareness activities and retains individual training records over an organization-defined frequency.
Intent: training for new users
This subpoint focuses on establishing a mandatory security awareness training program designed for all employees and for new employees who join the organization, irrespective of their role. This includes managers, senior executives, and contractors. The security awareness program should encompass a comprehensive curriculum designed to impart foundational knowledge about the organization’s information security protocols, policies, and best practices to ensure that all members of the organization are aligned with a unified set of security standards, creating a resilient information security environment.
Guidelines: training for new users
Most organizations will utilize a combination of platform-based security awareness training and administrative documentation such as policy documentation and records to track the completion of the training for all employees across the organization. Evidence supplied must show that employees have completed the training, and this should be backed up with supporting policies/procedures outlining the security awareness requirement.
Example evidence: training for new users
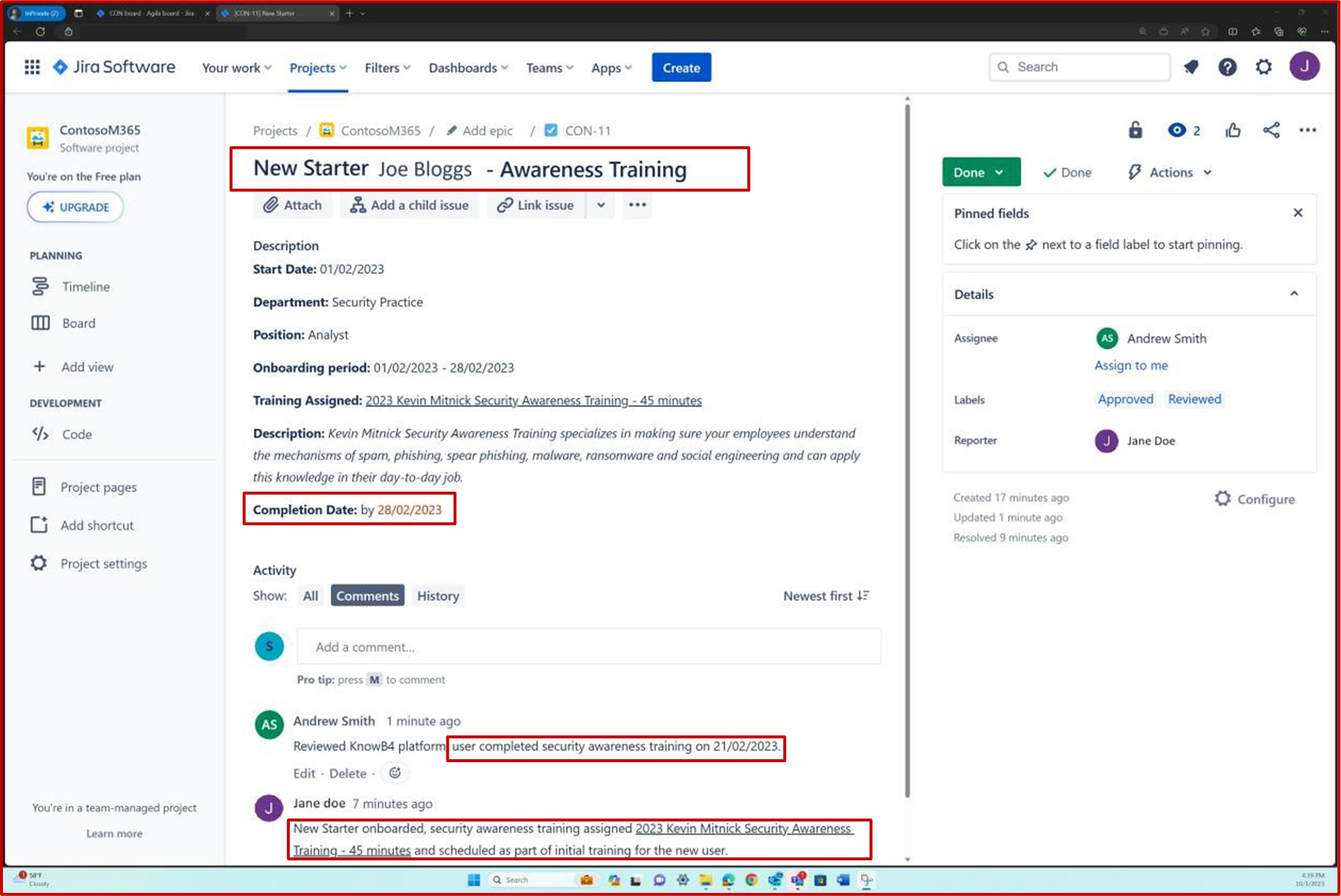
The following screenshot shows the Confluence platform being used to track the onboarding of new employees. A JIRA ticket was raised for the new employee including their assignment, role, department, etc. With the new starter process, the security awareness training has been selected and assigned to the employee which needs to be completed by the due date of 28th of February 2023.
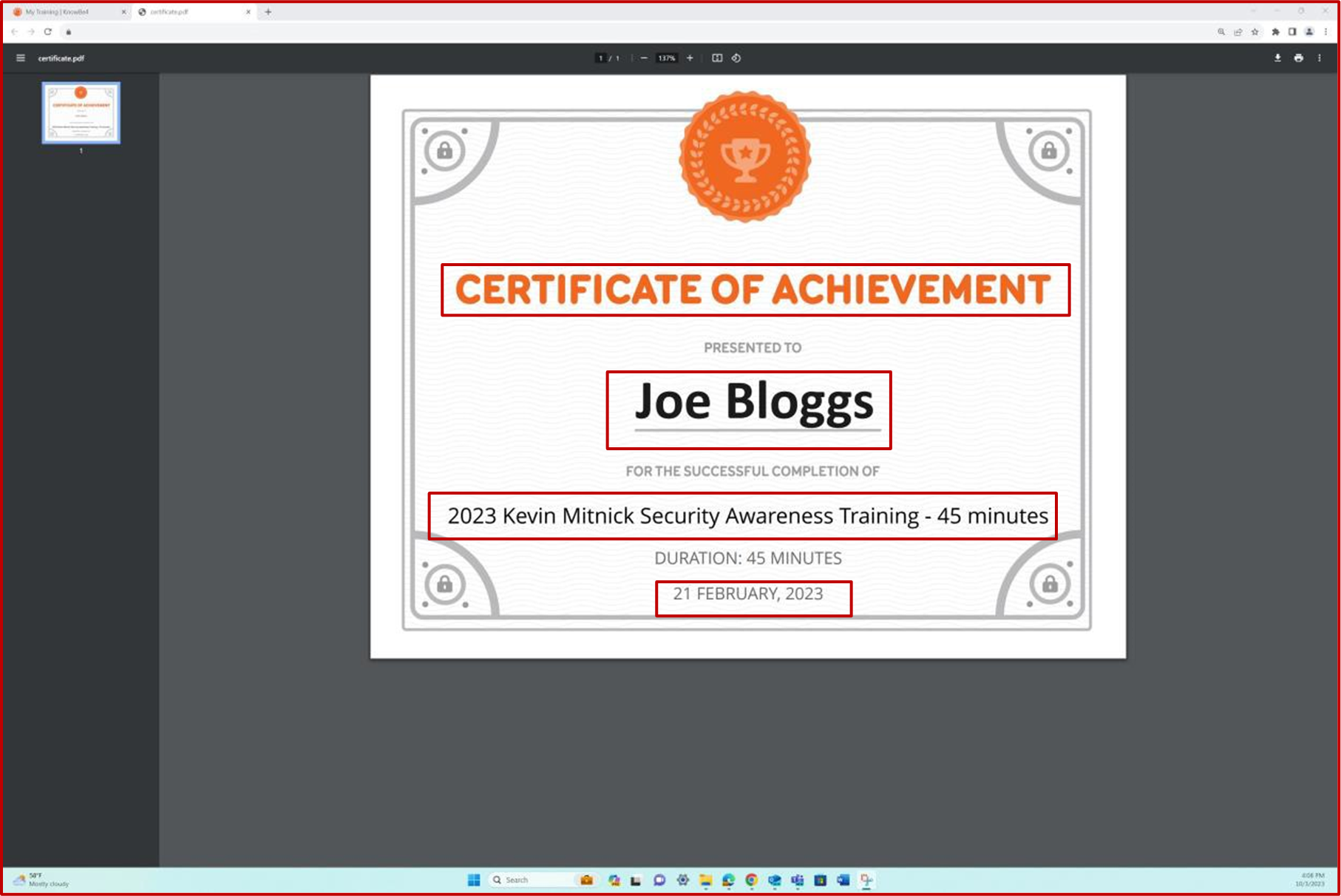
The screenshot shows the certificate of completion generated by Knowb4 upon the employee’s successful completion of the security awareness training. The completion date is 21st of February 2023 which is within the assigned period.
Intent: information system changes.
The objective of this subpoint is to ensure that adaptive security awareness training is initiated whenever there are significant changes to the organization’s information systems. The modifications could arise due to software updates, architectural changes, or new regulatory requirements. The updated training session ensures that all employees are informed about the new changes and the resulting impact on security measures, allowing them to adapt their actions and decisions accordingly. This proactive approach is vital for protecting the organization’s digital assets from vulnerabilities that could arise from system changes.
Guidelines: information system changes.
Most organizations will utilize a combination of platform-based security awareness training, and administrative documentation such as policy documentation and records to track the completion of the training for all employees. Evidence provided must demonstrate that various employees have completed the training based on different changes to the organization’s systems.
Example evidence: information system changes.
The next screenshots show the assignment of security awareness training to various employees and demonstrates that phishing simulations occur.
The platform is used to assign new training whenever a system change occurs, or a test is failed.
Intent: frequency of awareness training.
The objective of this subpoint is to define an organization-specific frequency for periodic security awareness training. This could be scheduled annually, semi-annually, or at a different interval determined by the organization. By setting a frequency the organization ensures that users are regularly updated on the evolving landscape of threats, as well as on new protective measures and policies. This approach can help to maintain a high level of security awareness among all users and to reinforce previous training components.
Guidelines: frequency of awareness training.
Most organizations will have administrative documentation and/or a technical solution to outline/implement the requirement and procedure for security awareness training as well as define the frequency of the training. Evidence supplied should demonstrate the completion of various awareness training within the defined period and that a defined period by your organization exists.
Example evidence: frequency of awareness training.
The following screenshots show snapshots of the security awareness policy documentation and that it exists and is maintained. The policy requires that all employees of the organization receive security awareness training as outlined in the scope section of the policy. The training must be assigned and completed on an annual basis by the relevant department.
According to the policy document, all employees of the organization must complete three courses (one training and two assessments) annually and within twenty days of the assignment. The courses must be sent out via email and assigned through KnowBe4.
The example provided only shows snapshots of the policy, please note that the expectation is that the full policy document will be submitted.

The second screenshot is the continuation of the policy, and it shows the section of the document which mandates the annual training requirement, and it demonstrates that the organization-defined frequency of awareness training is set to annually.

The next two screenshots demonstrate successful completion of the training assessments mentioned previously. The screenshots were taken from two different employees.
Intent: documentation and monitoring.
The objective of this subpoint is to create, maintain, and monitor meticulous records of each user’s participation in security awareness training. These records should be retained over an organization- defined period. This documentation serves as an auditable trail for compliance with regulations and internal policies. The monitoring component allows the organization to assess the effectiveness of the
training, identifying areas for improvement and understanding user engagement levels. By retaining these records over a defined period, the organization can track long-term effectiveness and compliance.
Guidelines: documentation and monitoring.
The evidence that can be provided for security awareness training will depend on how the training is implemented at the organization level. This can include whether the training is conducted through a platform or performed internally based on an in-house process. Evidence supplied must show that historical records of training completed for all users over a period exists and how this is tracked.
Example evidence: documentation and monitoring.
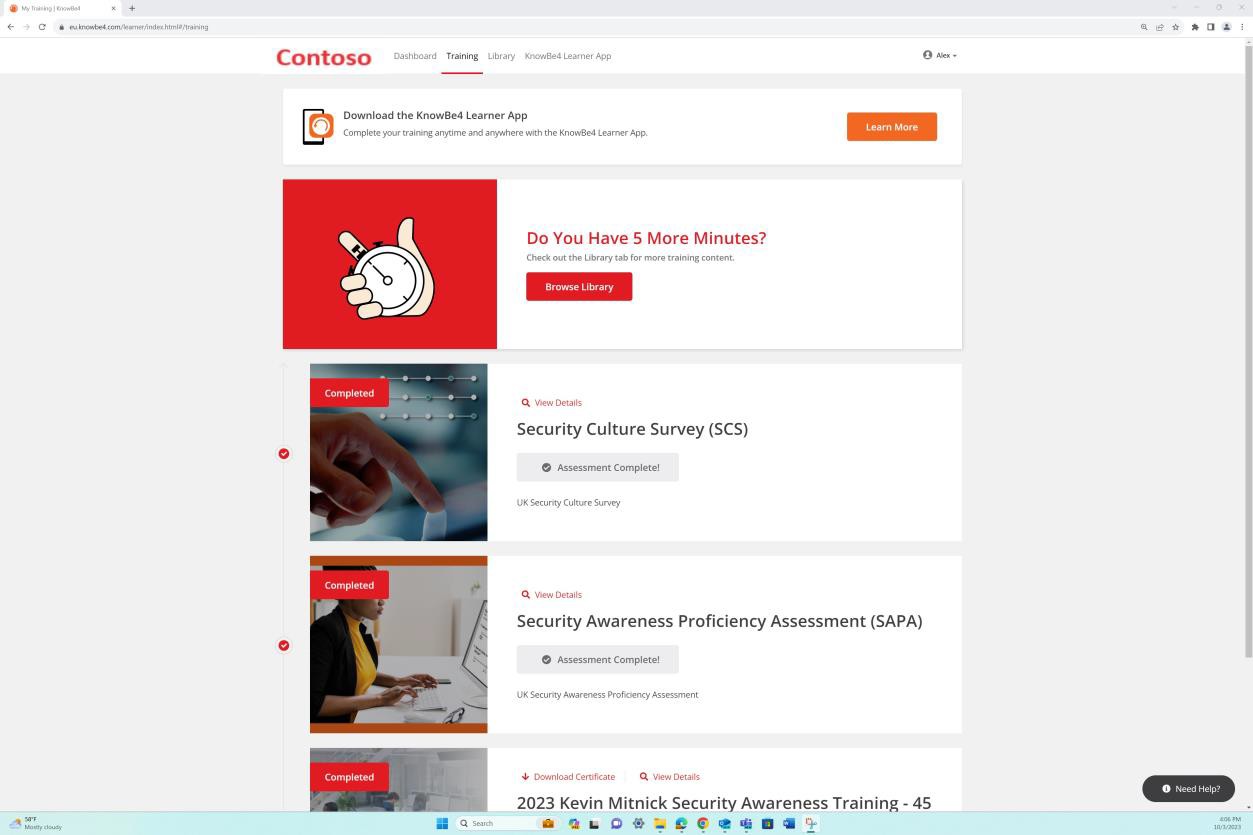
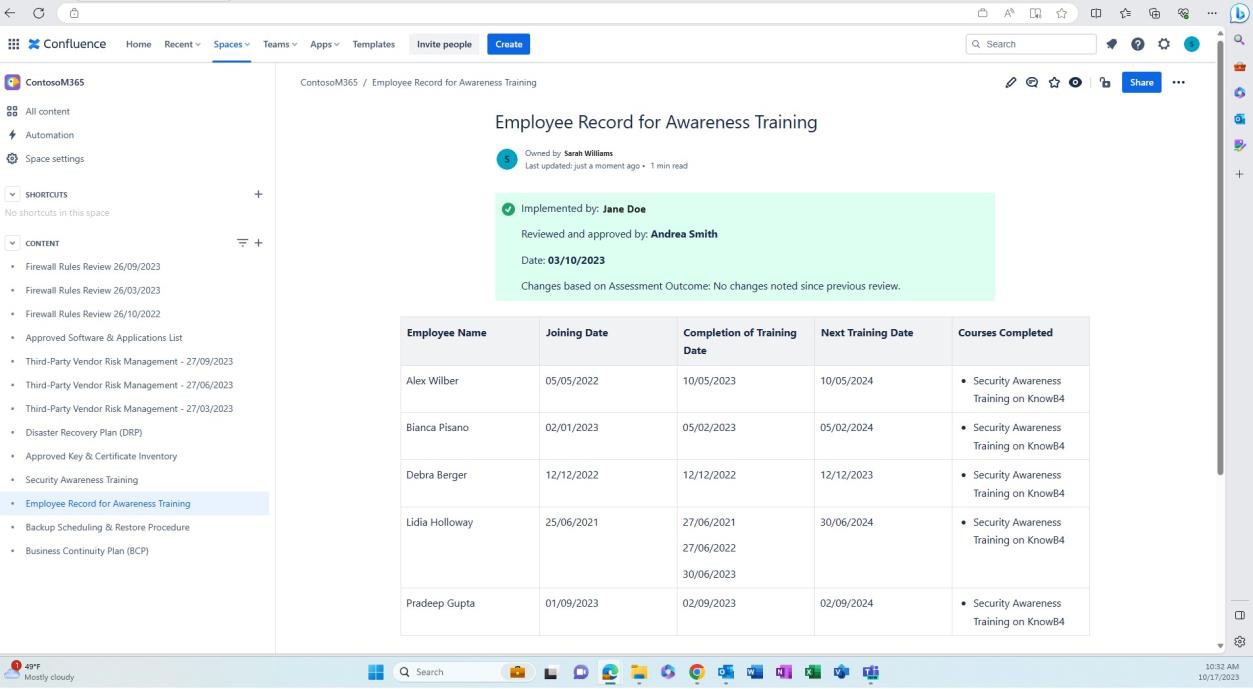
The next screenshot shows the historical training record for each user including their joining date, completion of training and when the next training is scheduled. Assessment of this document is performed periodically and at least once a year to ensure training records of security awareness for each employee is kept up to date.
Malware protection/anti-malware
Malware poses a significant risk to organizations which can vary the security impact caused to the operational environment, depending upon the malware characteristics. Threat actors have realized that malware can be successfully monetized, which has been realized through the growth of ransomware style malware attacks. Malware can also be used to provide an ingress point for a threat actor to compromise an environment to steal sensitive data, i.e., Remote Access Trojans/Rootkits. Organizations therefore need to implement suitable mechanisms to protect against these threats. Defenses that can be used are anti-virus (AV)/Endpoint Detection and Response (EDR)/Endpoint Detection and Protection Response (EDPR)/Heuristic based scanning using Artificial Intelligence (AI). If you have deployed a different technique to mitigate the risk of malware, then please let the Certification Analyst know who will be happy to explore if this meets the intent or not.
Control No. 2
Please provide evidence that your anti-malware solution is active and enabled across all the sampled system components and configured to meet the following criteria:
if anti-virus that on-access scanning is enabled and that signatures are up to date within 1-day.
for anti-virus that it automatically blocks malware or alerts and quarantines when malware is detected
OR If EDR/EDPR/NGAV:
that periodic scanning is being performed.
is generating audit logs.
is kept up-to-date continually and has self-learning capabilities.
it blocks known malware and identifies and blocks new malware variants based on macro behaviors as well as having full allowance capabilities.
Intent: on-access scanning
This subpoint is designed to verify that the anti-malware software is installed across all sampled system components and is actively performing on-access scanning. The control also mandates that the signature database of the anti-malware solution is up to date within a one-day timeframe. An up-to-date signature database is crucial for identifying and mitigating the latest malware threats, thereby ensuring that the system components are adequately protected.
Guidelines: on-access scanning**.**
To demonstrate that an active instance of AV is running in the assessed environment, provide a screenshot for every device in the sample set agreed with your analyst that supports the use of anti- malware. The screenshot should show that the anti-malware is running, and that the anti-malware software is active. If there is a centralized management console for anti-malware, evidence from the management console may be provided. Also, ensure to provide a screenshot that shows the sampled devices are connected and working.
Example evidence: on-access scanning**.**
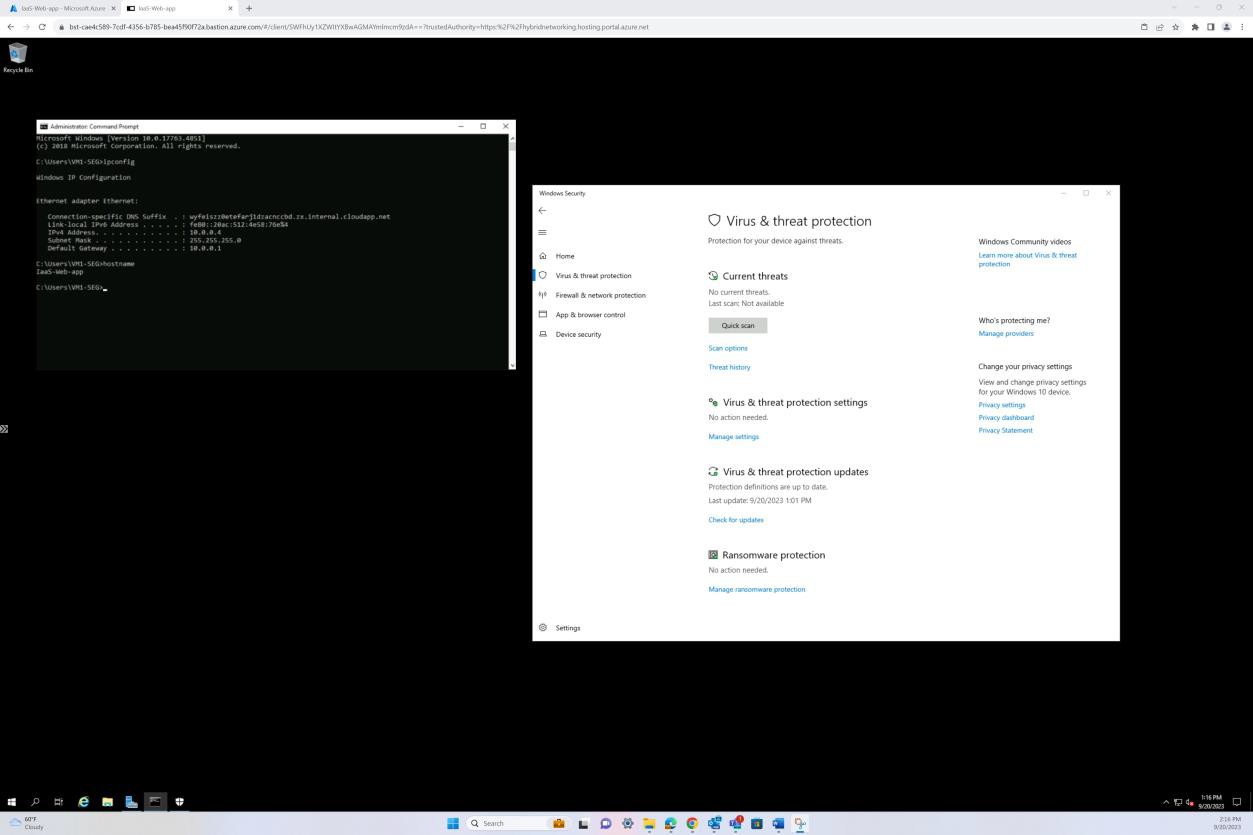
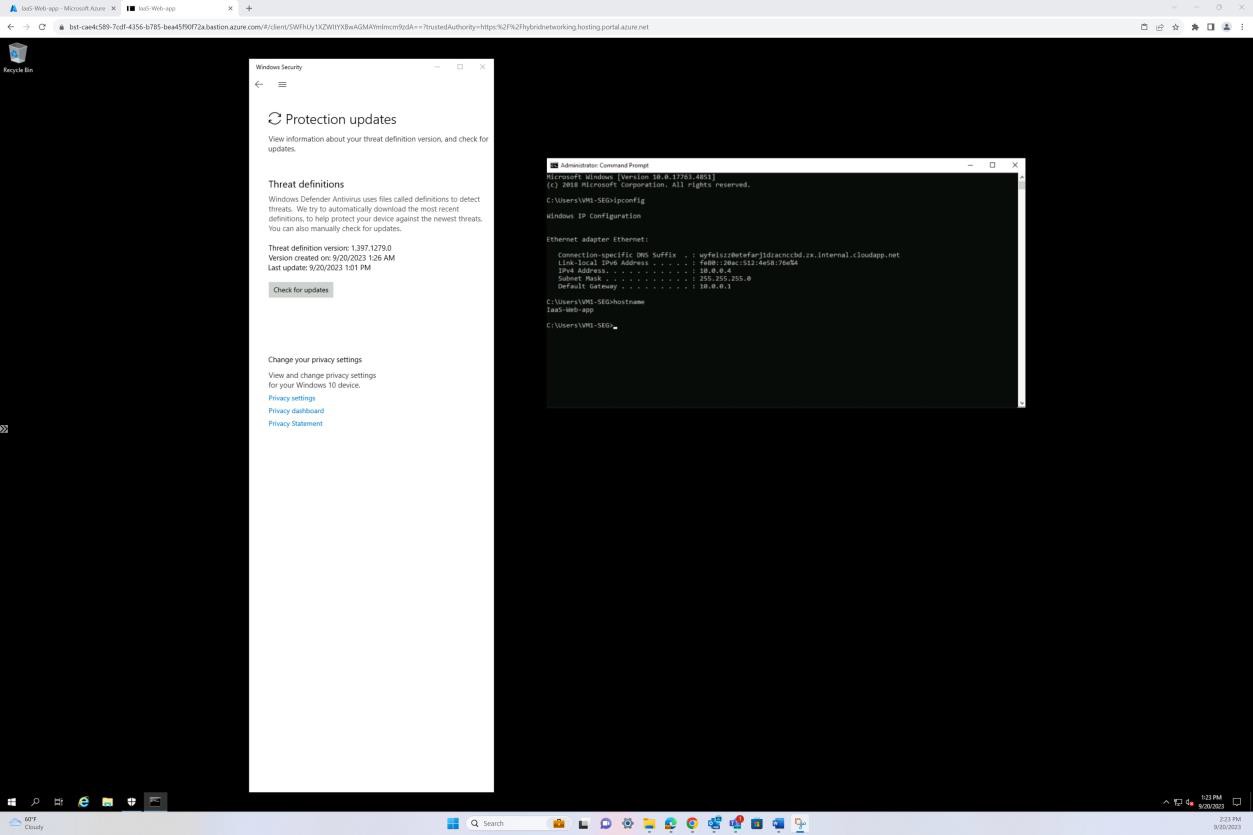
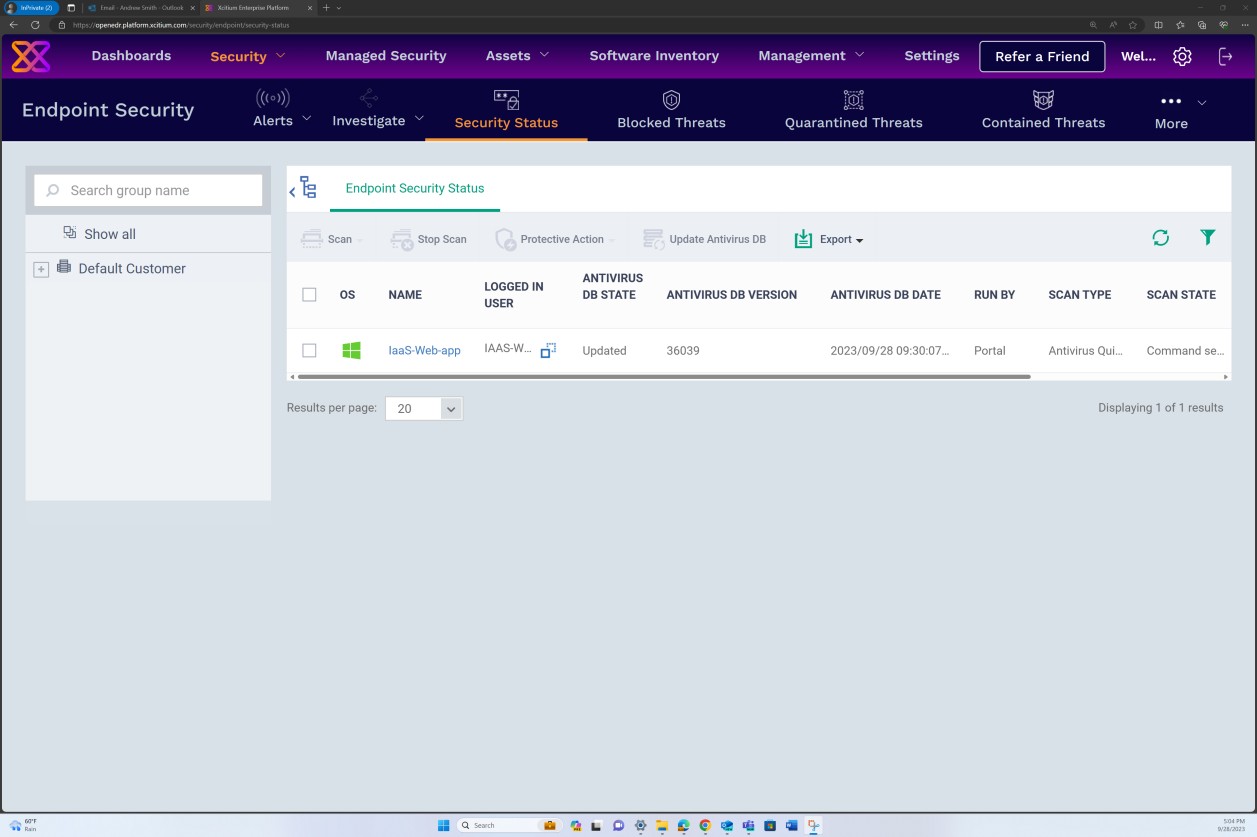
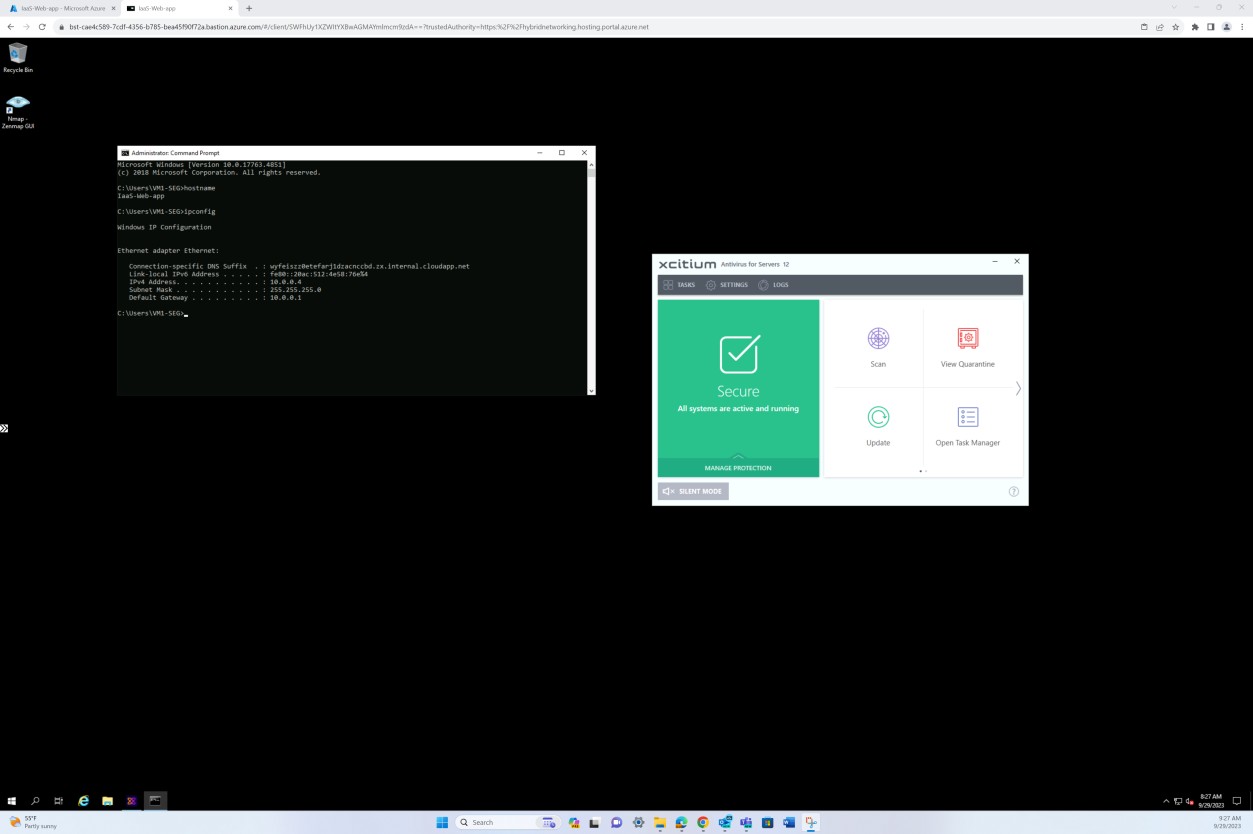
The following screenshot has been taken from a Windows Server device, showing that “Microsoft Defender” is enabled for the host name “IaaS-Web-app”.
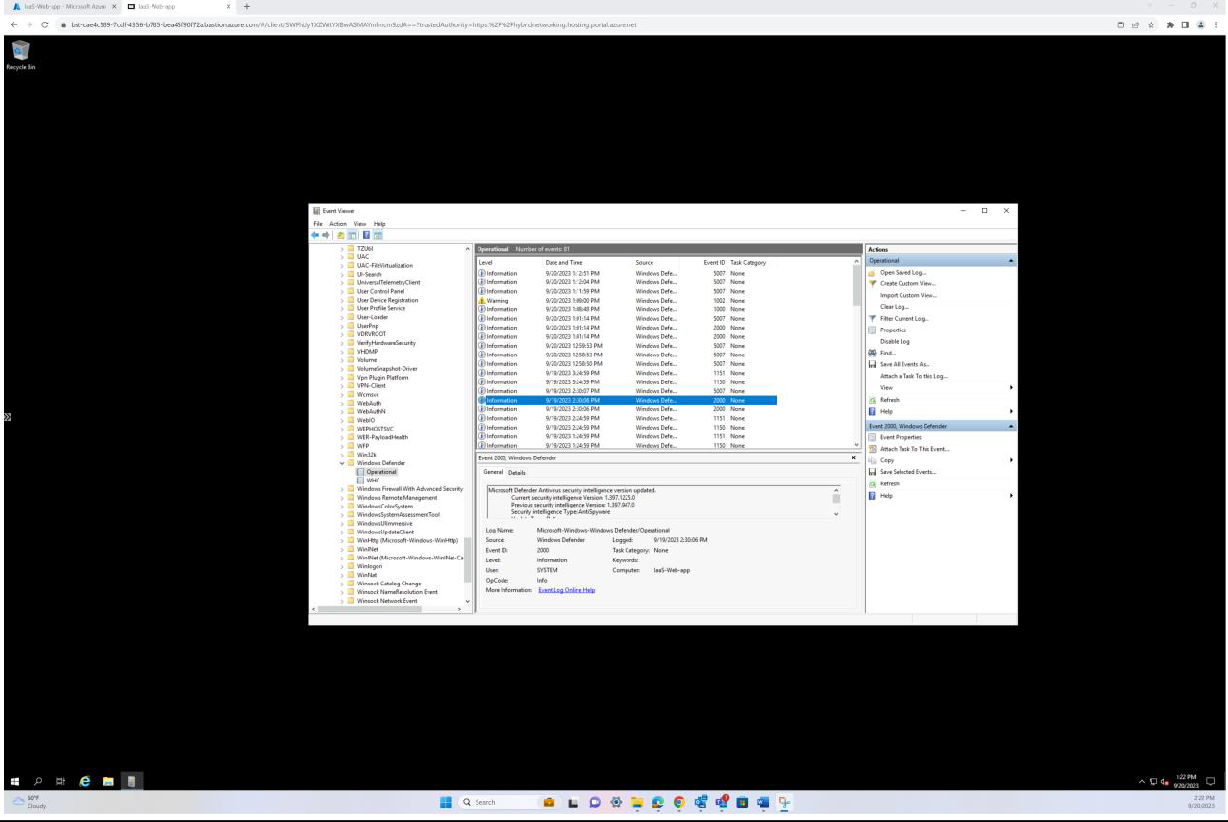
The next screenshot has been taken from a Windows Server device, showing Microsoft Defender Antimalware security intelligence version has updated the log from the Windows event viewer. This demonstrates the latest signatures for the host name “IaaS-Web-app”.
This screenshot has been taken from a Windows Server device, showing Microsoft Defender Anti-malware Protection updates. This clearly shows the threat definition versions, version created on, and last update to demonstrate that malware definitions are up to date for the host name “IaaS-Web- app”.
Intent: anti-malware blocks.
The purpose of this subpoint is to confirm that the anti-malware software is configured to automatically block malware upon detection or generate alerts and move detected malware to a secure quarantine area. This can ensure immediate action is taken when a threat is detected, reducing the window of vulnerability, and maintaining a strong security posture of the system.
Guidelines: anti-malware blocks.
Provide a screenshot for every device in the sample that supports the use of anti-malware. The screenshot should show that anti-malware is running and is configured to automatically block malware, alert or to quarantine and alert.
Example evidence: anti-malware blocks.
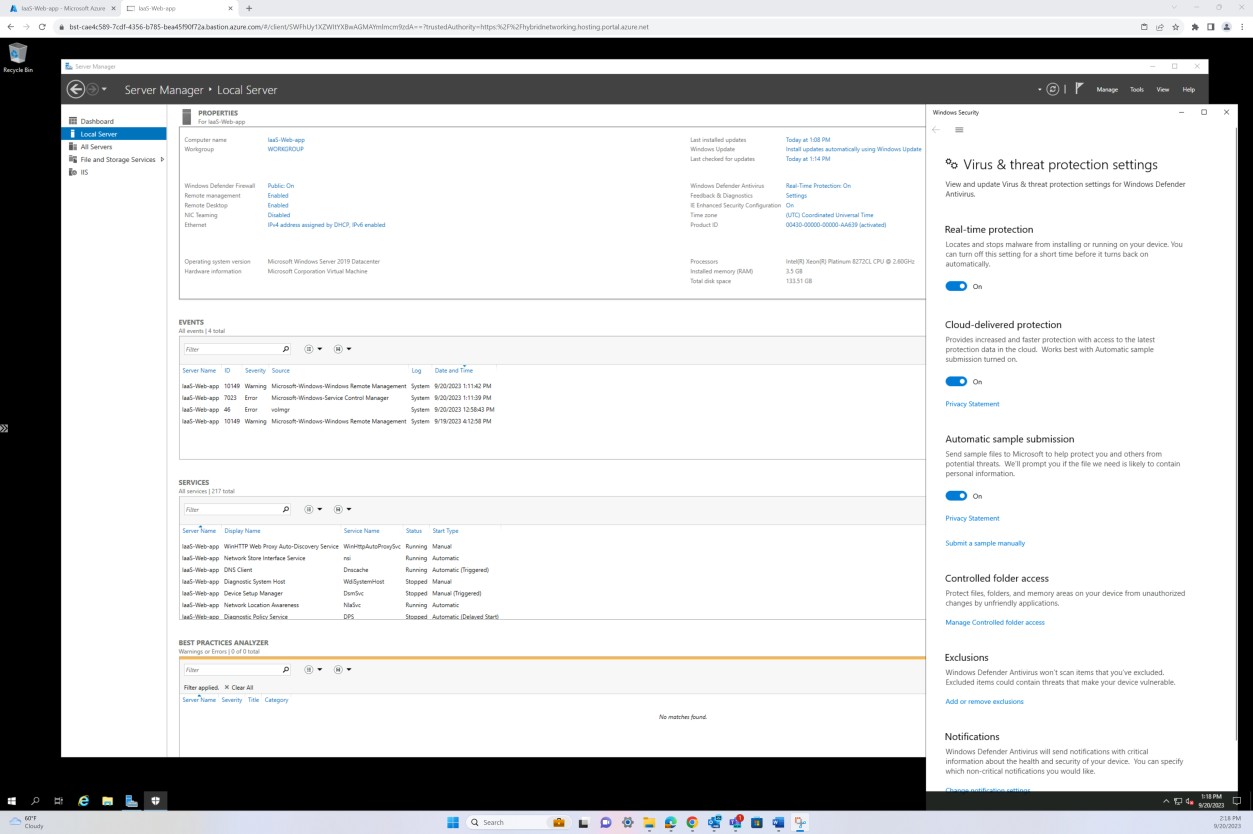
The next screenshot shows the host “IaaS-Web-app” is configured with real-time protection as ON for Microsoft Defender Antimalware. As the setting says, this locates and stops the malware from installing or running on the device.
Intent: EDR/NGAV
This subpoint aims to verify that Endpoint Detection and Response (EDR) or Next-Generation Antivirus (NGAV) are actively performing periodic scans across all sampled system components; audit logs are generated for tracking scanning activities and results; the scanning solution is continuously updated and possess self- learning capabilities to adapt to new threat landscapes.
Guidelines: EDR/NGAV
Provide a screenshot from your EDR/NGAV solution demonstrating that all the agents from the sampled systems are reporting in and showing that their status is active.
Example evidence: EDR/NGAV
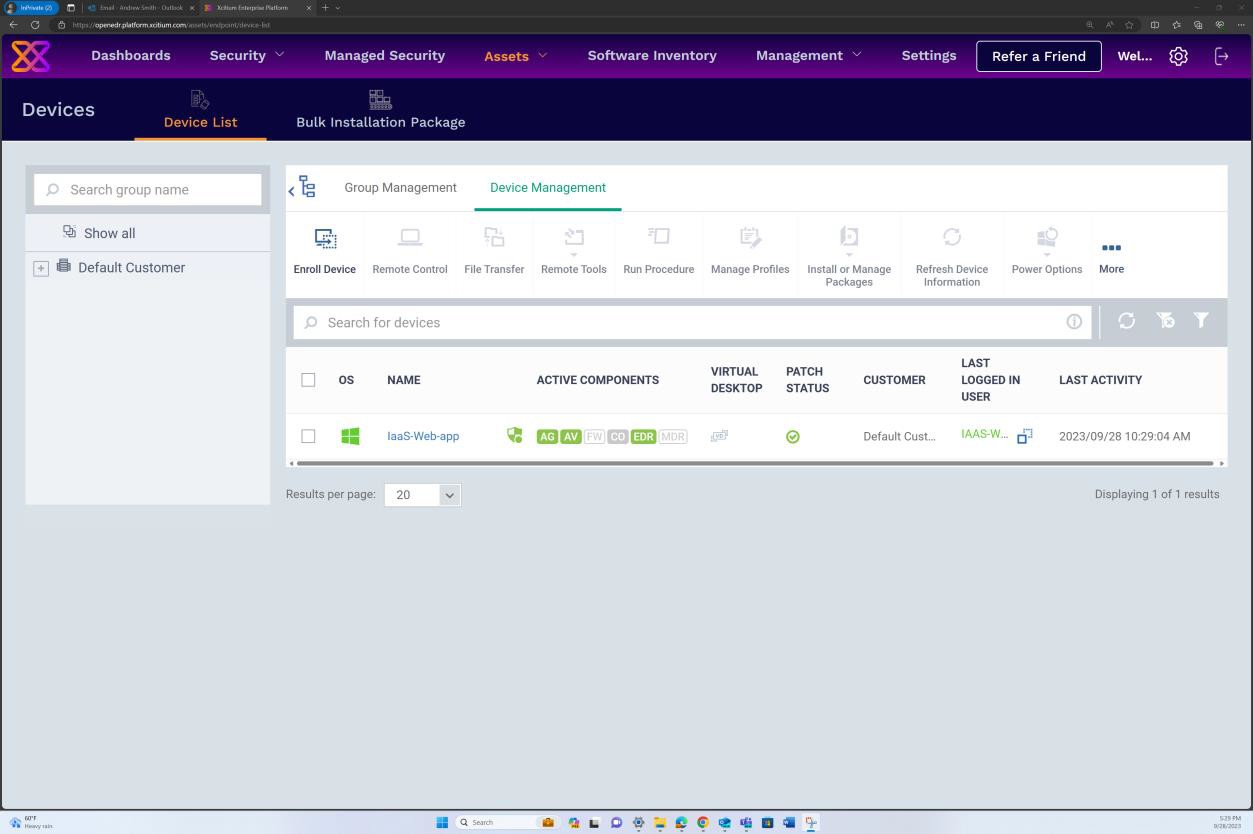
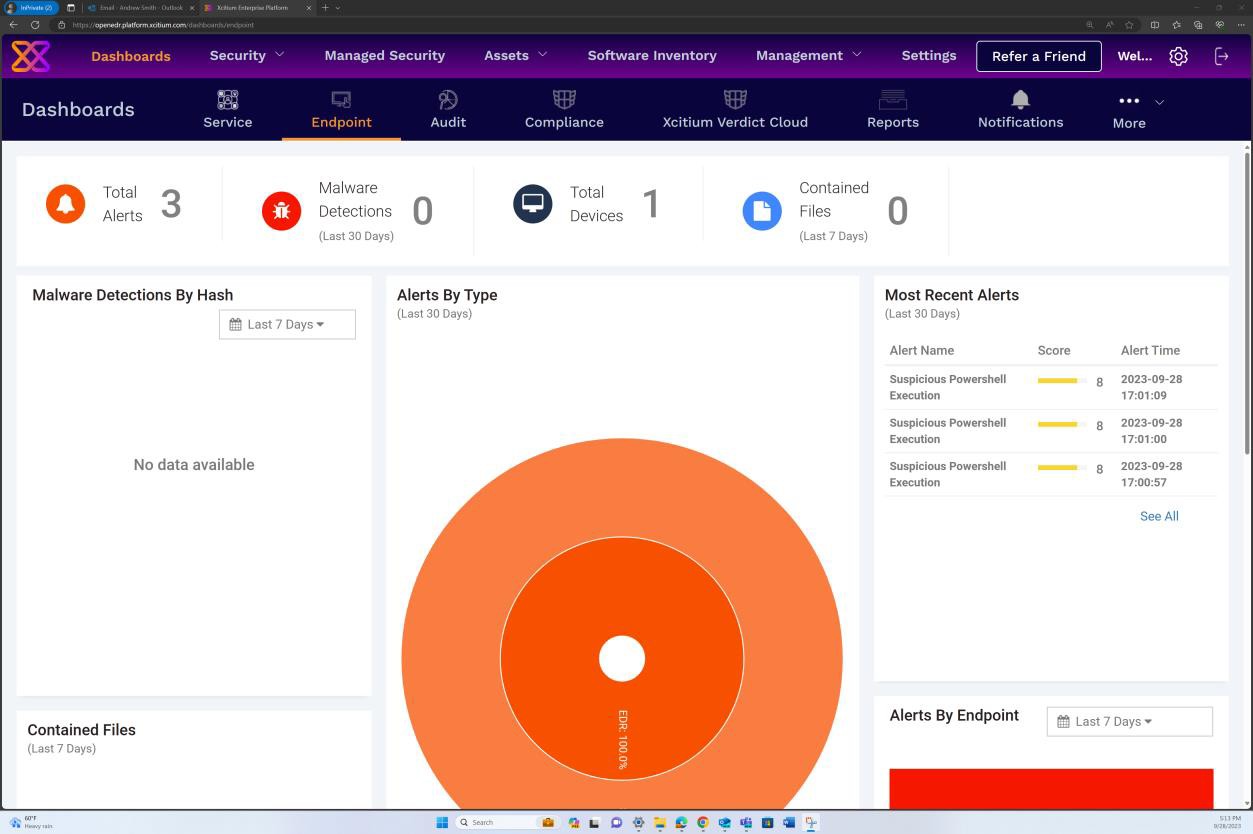
The next screenshot from the OpenEDR solution shows that an agent for the host “IaaS-Web-app” is active and reporting in.
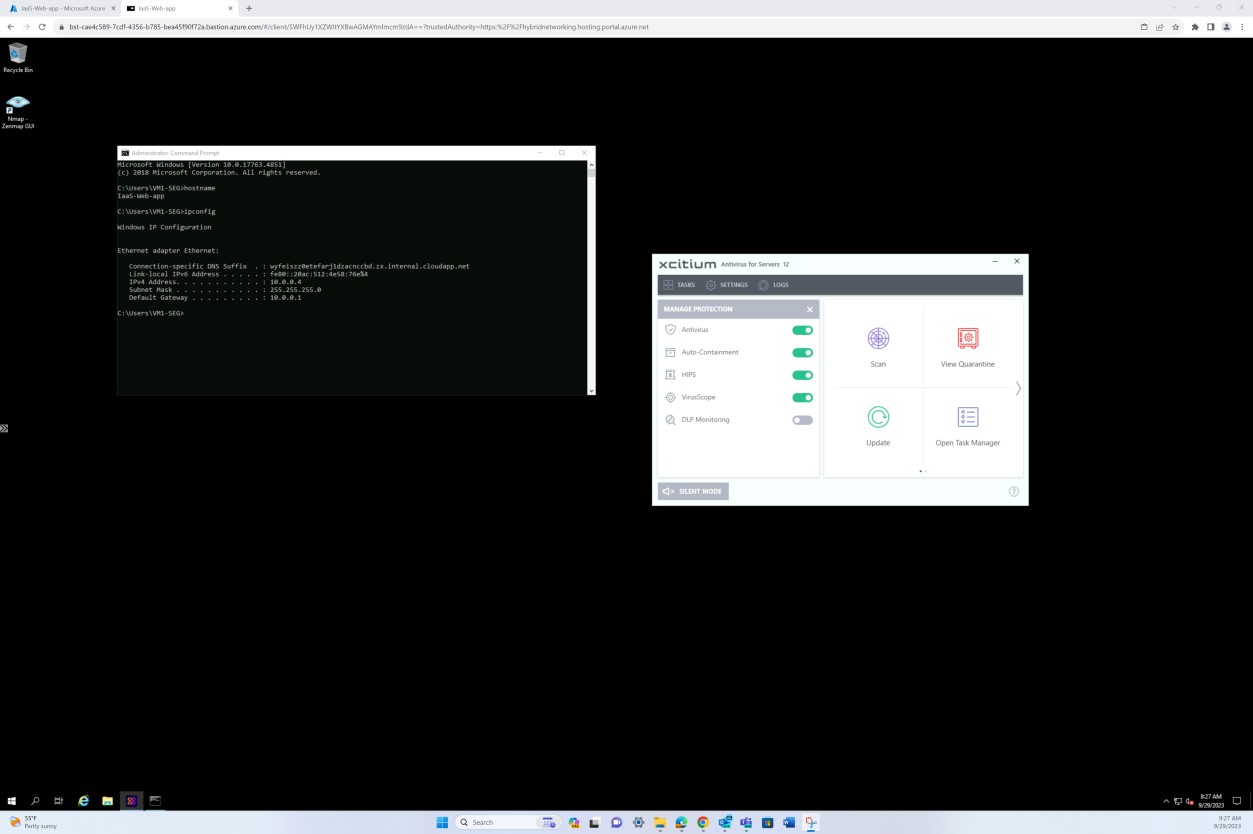
The next screenshot from OpenEDR solution shows that real-time scanning is enabled.
The next screenshot shows that alerts are generated based on behavior metrics which have been obtained in real-time from the agent installed at the system level.
The next screenshots from the OpenEDR solution demonstrate the configuration and generation of audit logs and alerts. The second image shows that the policy is enabled, and the events are configured.
The next screenshot from OpenEDR solution demonstrates that the solution is kept up-to-date continually.
Intent: EDR/NGAV
The focus of this subpoint is to ensure that EDR/NGAV have the capability to block known malware automatically and identify and block new malware variants based on macro behaviors. It also ensures that the solution has full approval capabilities, allowing the organization to permit trusted software while blocking all else, thereby adding an additional layer of security.
Guidelines: EDR/NGAV
Depending on the type of solution used, evidence can be provided showing the configuration settings of the solution and that the solution has Machine Learning/heuristics capabilities, as well as being configured to block malware upon detection. If configuration is implemented by default on the solution, then this must be validated by vendor documentation.
Example evidence: EDR/NGAV
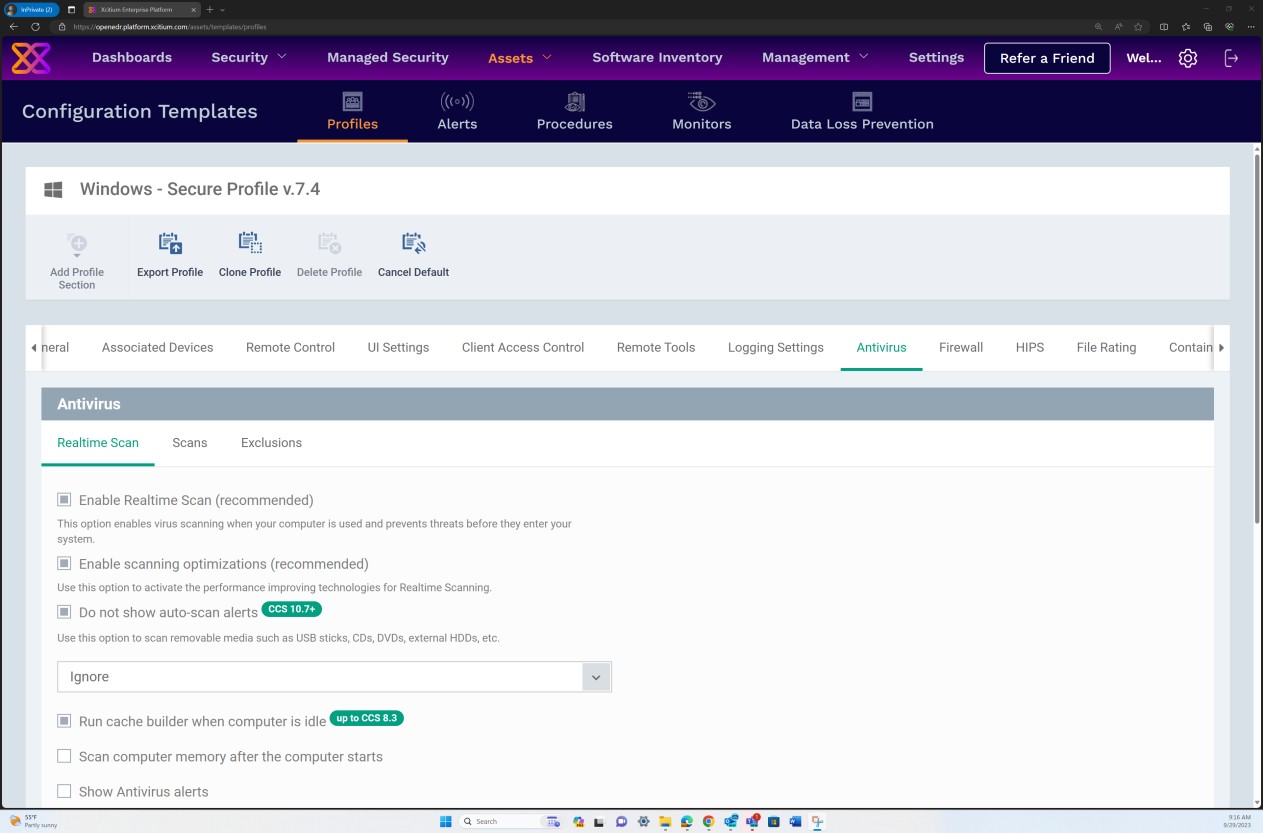
The next screenshots from the OpenEDR solution demonstrate that a Secure Profile v7.4 is configured to enforce real-time scan, block malware, and quarantine.
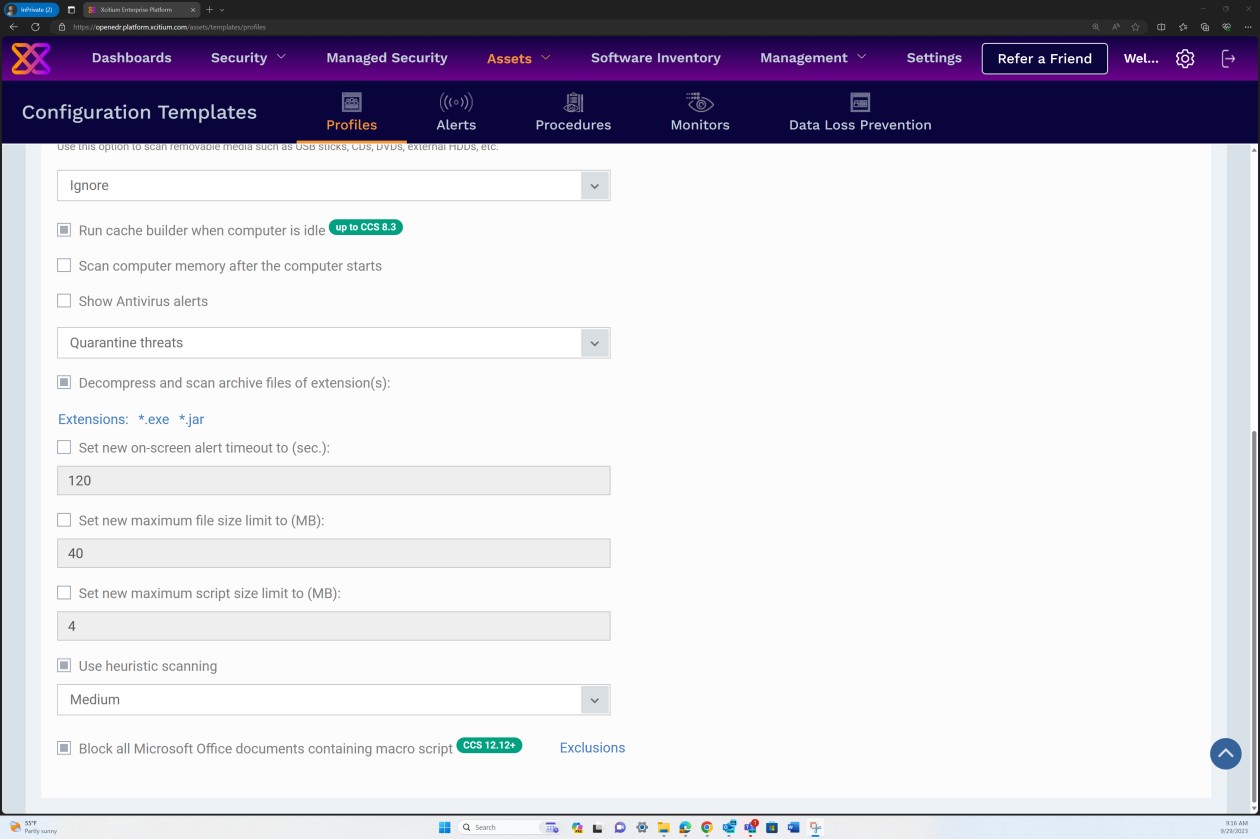
The next screenshots from the Secure Profile v7.4 configuration demonstrate that the solution implements both “Realtime” scanning based on a more traditional antimalware approach, which scans for known malware signatures, and “Heuristics” scanning set to a medium level. The solution detects and removes malware by checking the files and the code that behave in a suspicious/unexpected or malicious manner.
The scanner is configured to decompress archives and scan the files inside to detect potential malware that might be masking itself under the archive, Additionally, the scanner is configured to block micro scripts within Microsoft Office files.
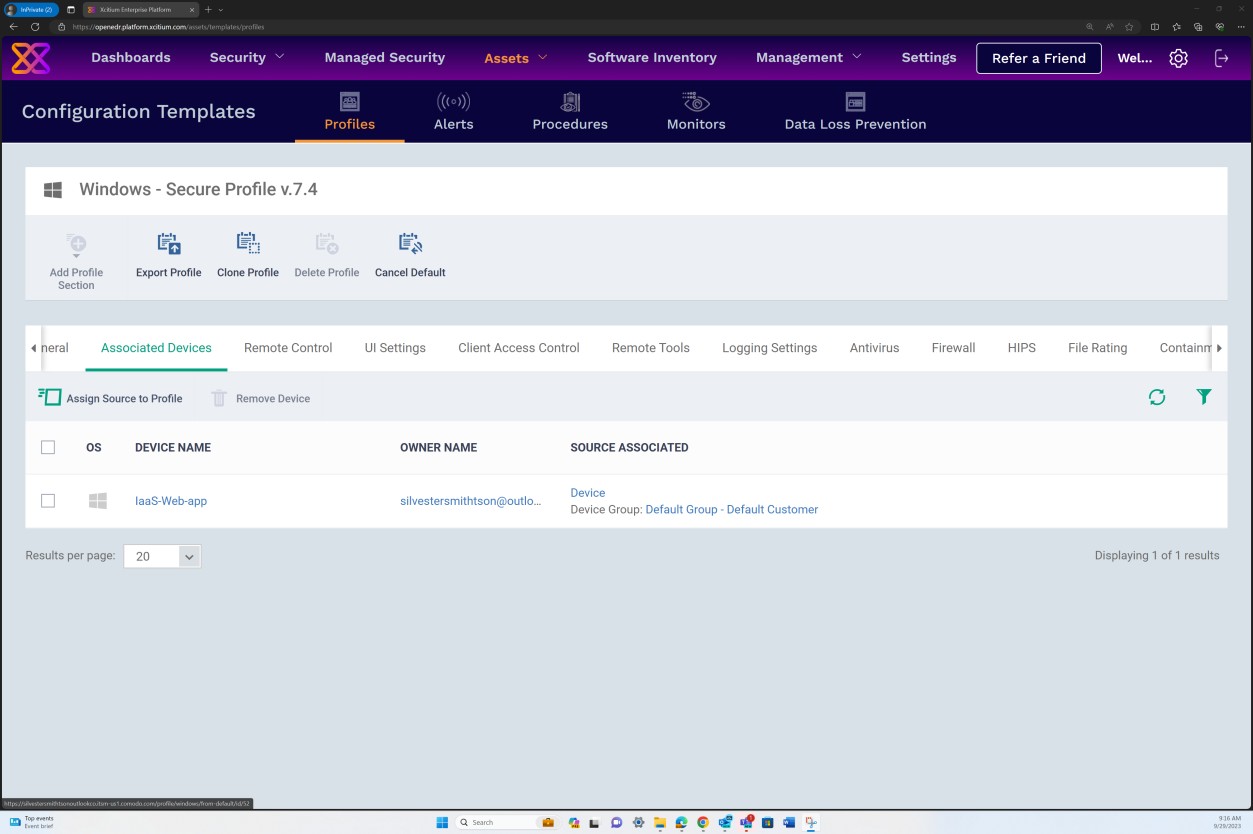
The next screenshots demonstrate that Secure Profile v.7.4 has been assigned to our Windows Server device ‘IaaS-Web-app’ host.
The next screenshot was taken from the Windows Server device ‘IaaS-Web-app’, which demonstrated that OpenEDR agent is enabled and running on the host.
Malware protection/application control
Application control is a security practice that blocks or restricts unauthorized applications from executing in ways that put data at risk. Application controls are an important part of a corporate security program and can help prevent malicious actors from exploiting application vulnerabilities and reduce the risk of a breach. By implementing application control, businesses and organizations can greatly reduce the risks and threats associated with application usage because applications are prevented from executing if they put the network or sensitive data at risk. Application controls provide operations and security teams with a reliable, standardized, and systematic approach to mitigating cyber risk. They also give organizations a fuller picture of the applications in their environment, which can help IT and security organizations effectively manage cyber risk.
Control No. 3
Please provide evidence demonstrating that:
You have an approved list of software/applications with business justification:
exists and is kept up to date, and
that each application undergoes an approval process and sign off prior to its deployment.
That application control technology is active, enabled, and configured across all the sampled system components as documented.
Intent: software list
This subpoint aims to ensure that an approved list of software and applications exist within the organization and is continually kept up to date. Ensure that each software or application on the list has a documented business justification to validate its necessity. This list serves as an authoritative reference to regulate software and application deployment, thus aiding in the elimination of unauthorized or redundant software that could pose a security risk.
Guidelines: software list
A document containing the approved list of software and applications if maintained as a digital document (Word, PDF, etc.). If the approved list of software and applications is maintained through a platform, then screenshots of the list from the platform must be provided.
Example evidence: software list
The next screenshots demonstrate that a list of approved software and applications is maintained in Confluence Cloud platform.
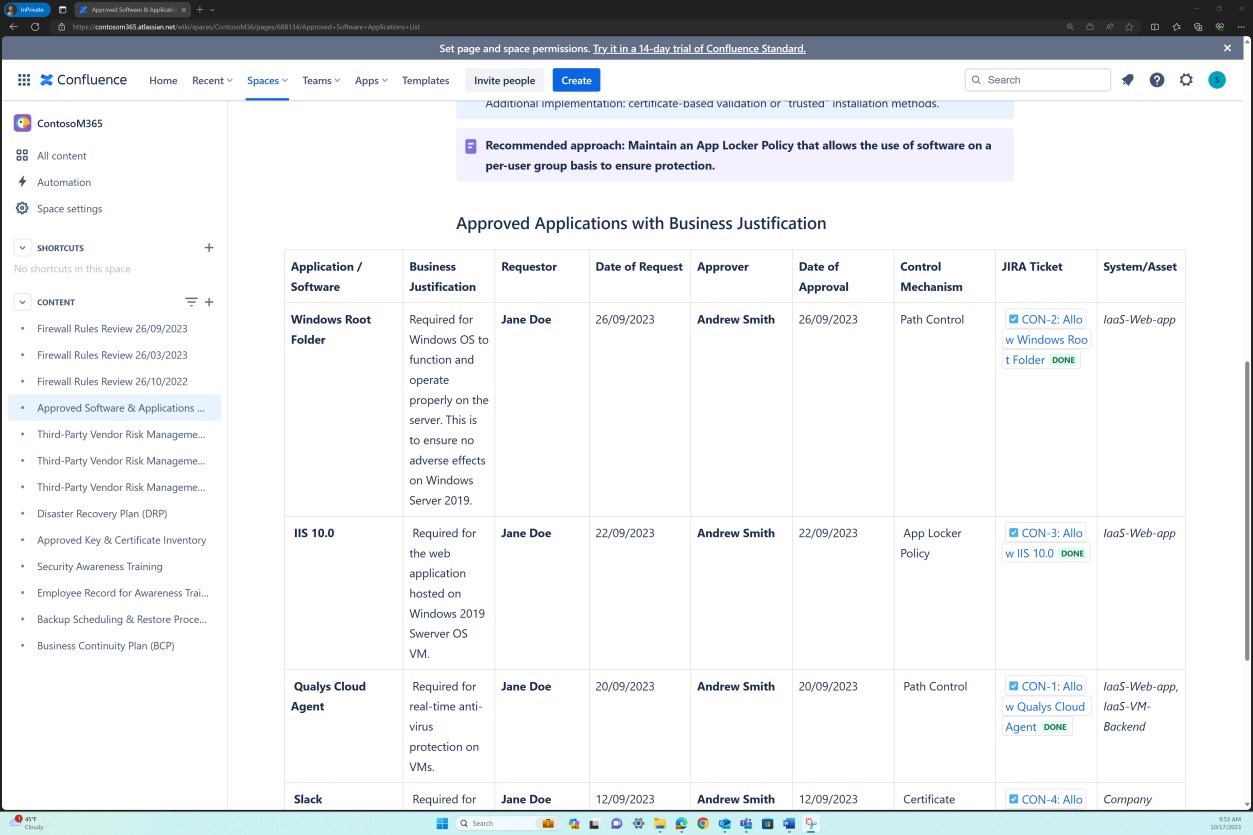
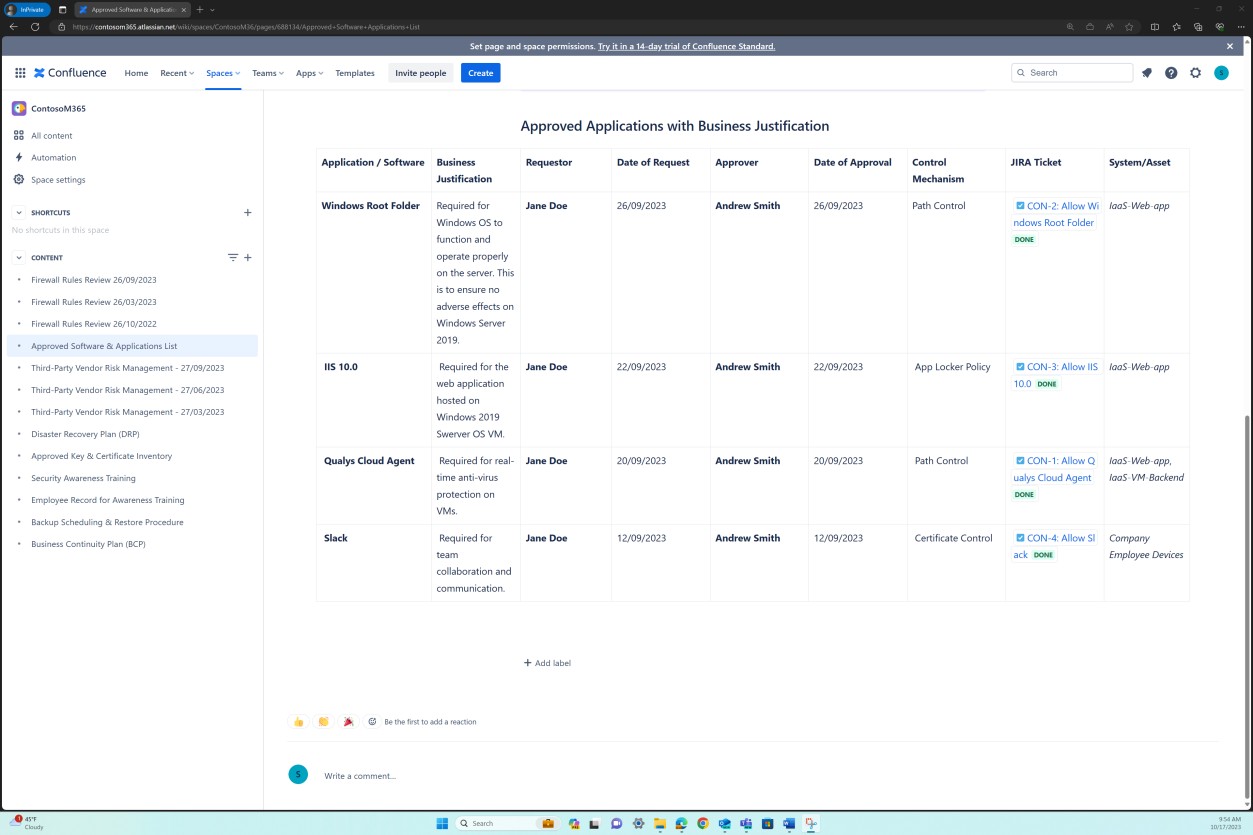
The next screenshots demonstrates that the list of approved software and applications including the requestor, date of request, approver, date of approval, control mechanism, JIRA ticket, system/asset is maintained.
Intent: software approval
The purpose of this subpoint is to confirm that each software/application undergoes a formal approval process before its deployment within the organization. The approval process should includes a technical evaluation and an executive sign-off, ensuring that both operational and strategic perspectives have been considered. By instituting this rigorous process, the organization ensures that only vetted and necessary software is deployed, thereby minimizing security vulnerabilities and ensuring alignment with the business objectives.
Guidelines
Evidence can be provided showing that the approval process is being followed. This may be provided by means of signed documents, tracking within the change control systems or using something like Azure DevOps/JIRA to track the change requests and authorization.
Example evidence
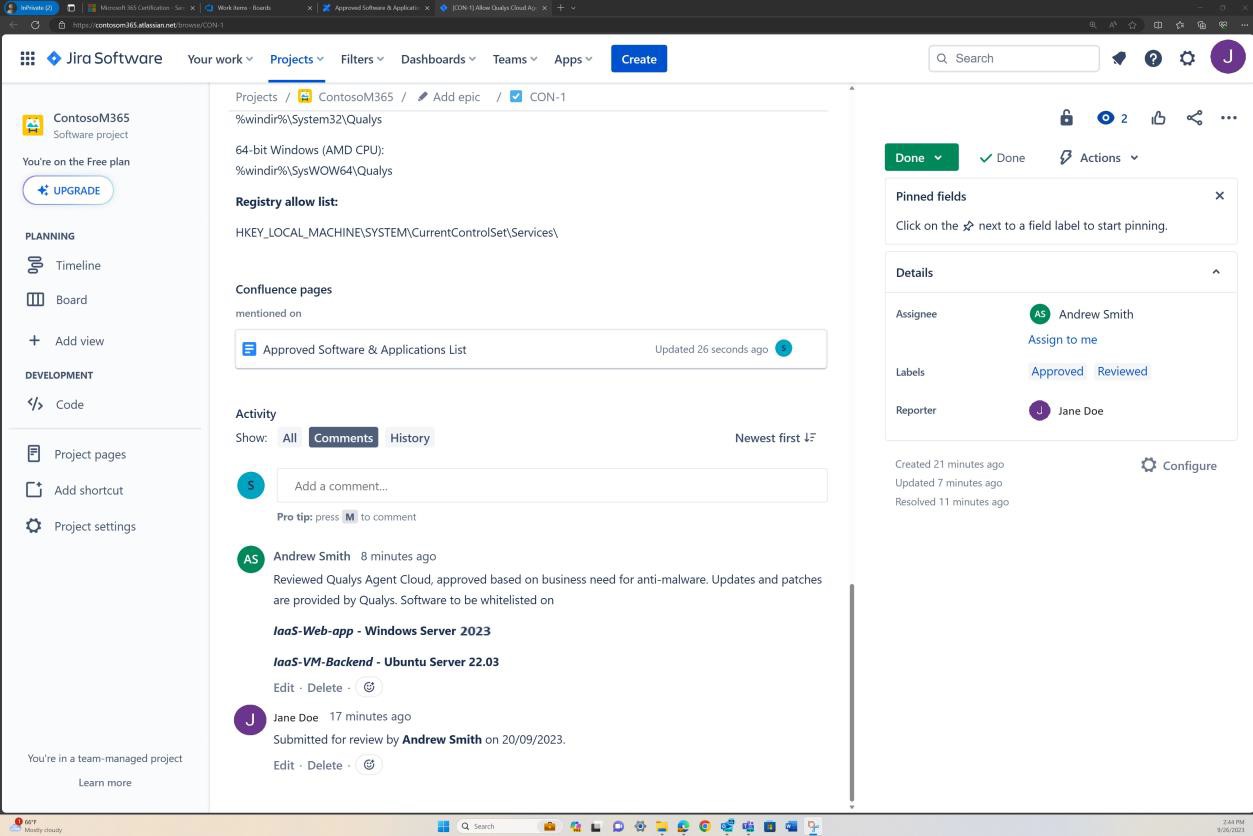
The next screenshots demonstrate a complete approval process in JIRA Software. A user ‘Jane Doe’ has raised a request for ‘Allow Qualys Cloud Agent’ to be installed on ‘IaaS-Web-app’ and ‘IaaS-VM- Backend’ servers. ‘Andrew Smith’ has reviewed the request and approved it with the comment ‘approved based on business need for anti-malware. Updates and patches provided by Qualys. Software to be approved.’
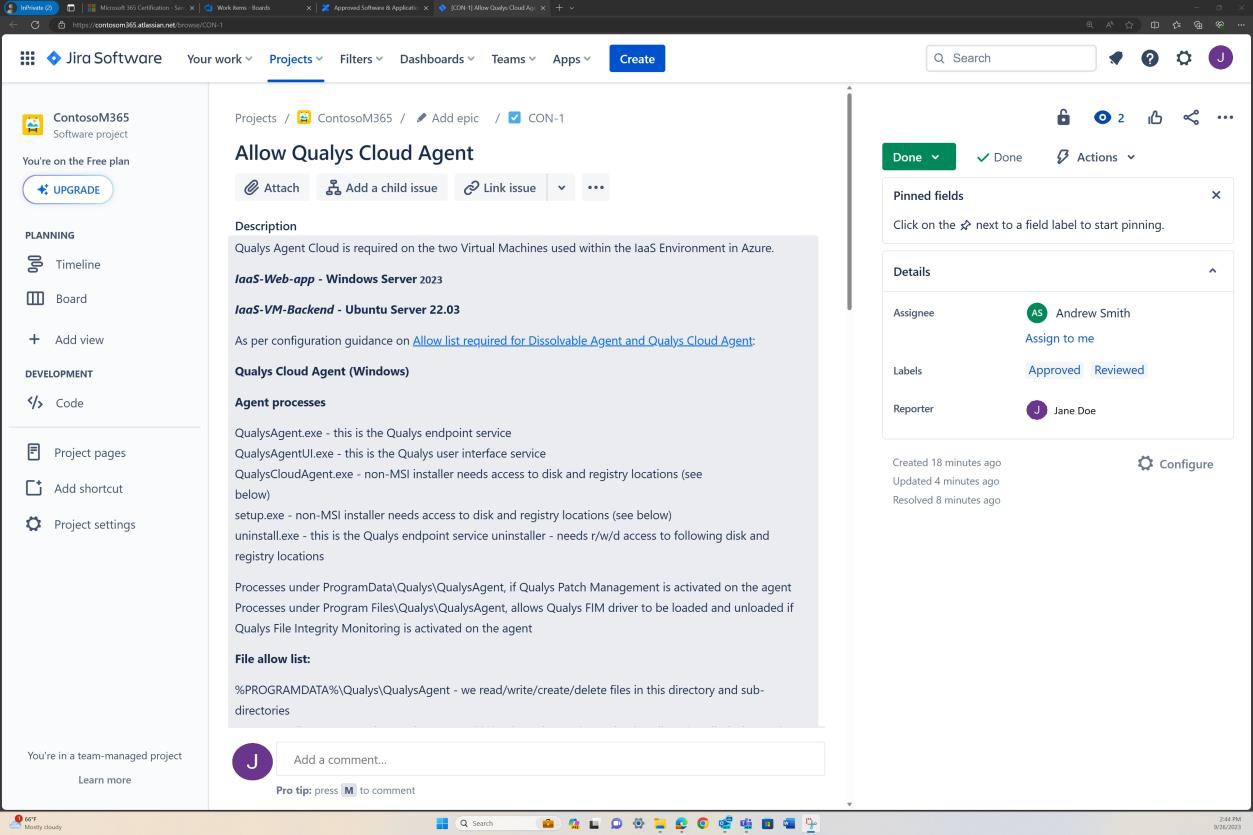
The next screenshot shows approval being granted via the ticket raised on Confluence platform before allowing the application to run on the production server.
Intent: app control technology
This subpoint focuses on verifying that application control technology is active, enabled and correctly configured across all sampled system components. Ensure that the technology operates in accordance with documented policies and procedures, which serve as guidelines for its implementation and maintenance. By having an active, enabled, and a well-configured application control technology, the organization can help prevent the execution of unauthorized or malicious software and enhance the overall security posture of the system.
Guidelines: app control technology
Provide documentation detailing how application control has been setup and evidence from the applicable technology showing how each application/process has been configured.
Example evidence: app control technology
The next screenshots demonstrate that Windows Group Policies (GPO) is configured to enforce only approved software and applications.
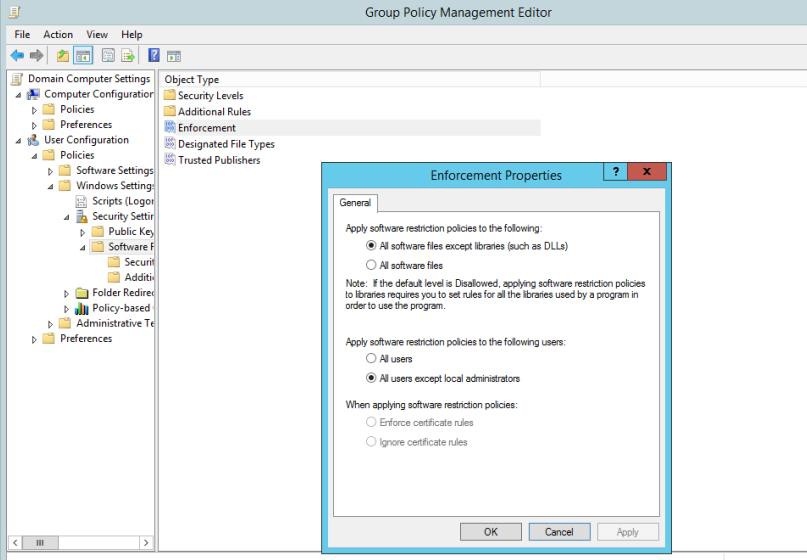
The next screenshot shows the software/applications allowed to run via path control.
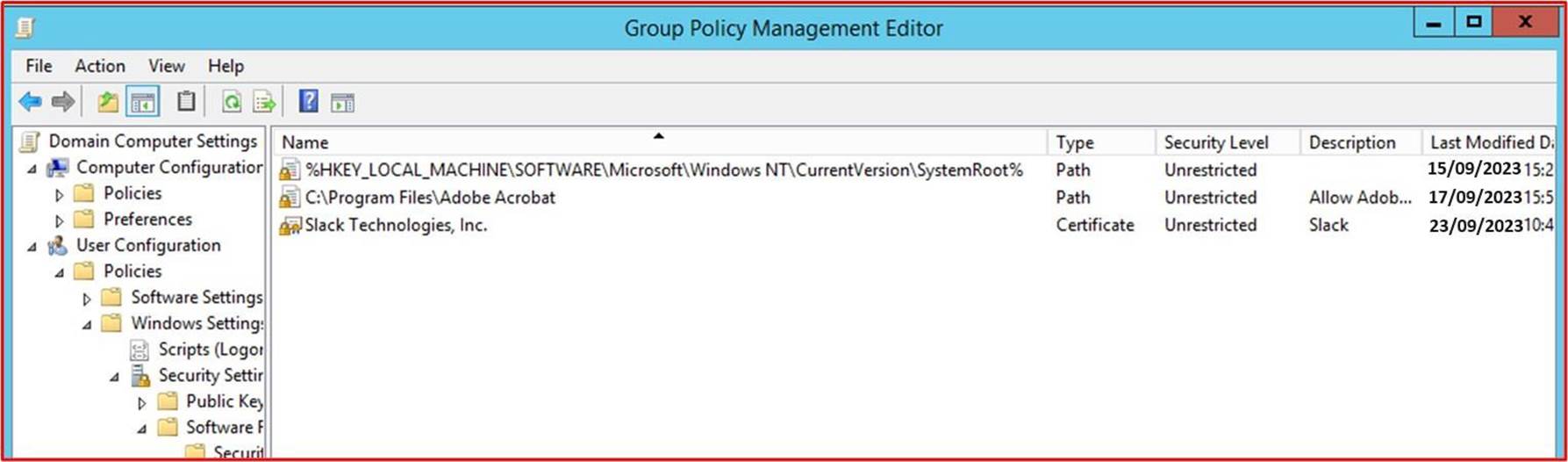
Note: In these examples full screenshots were not used, however ALL ISV submitted evidence screenshots must be full screen screenshots showing any URL, logged in user and the system time and date.
Patch management/patching and risk ranking
Patch management, often referred to as patching, is a critical component of any robust cybersecurity strategy. It involves the systematic process of identifying, testing, and applying patches or updates to software, operating systems, and applications. The primary objective of patch management is to mitigate security vulnerabilities, ensuring that systems and software remain resilient against potential threats. Additionally, patch management encompasses risk ranking a vital element in prioritizing patches. This involves evaluating vulnerabilities based on their severity and potential impact on an organization’s security posture. By assigning risk scores to vulnerabilities, organizations can allocate resources efficiently, focusing their efforts on addressing critical and high-risk vulnerabilities promptly while maintaining a proactive stance against emerging threats. An effective patch management and risk ranking strategy not only enhances security but also contributes to the overall stability and performance of IT infrastructure, helping organizations stay resilient in the ever-evolving landscape of cybersecurity threats.
To maintain a secure operating environment, applications/add-ons and supporting systems must be suitably patched. A suitable timeframe between identification (or public release) and patching needs to be managed to reduce the window of opportunity for a vulnerability to be exploited by a threat actor. The Microsoft 365 Certification does not stipulate a ‘Patching Window’; however, certification analysts will reject timeframes that are not reasonable or in line with industry best practices. This security control group is also in scope for Platform-as-a-Service (PaaS) hosting environments as the application/add-in third-party software libraries and code base must be patched based upon the risk ranking.
Control No. 4
Provide evidence that patch management policy and procedure documentation define all of the following:
A suitable minimal patching window for critical/high and medium risks vulnerabilities.
Decommissioning of unsupported operating systems and software.
How new security vulnerabilities are identified and assigned a risk score.
Intent: patch management
Patch management is required by many security compliance frameworks i.e., PCI-DSS, ISO 27001, NIST (SP) 800-53, FedRAMP and SOC 2. The importance of good patch management cannot be over stressed
as it can correct security and functionality problems in software, firmware and mitigate vulnerabilities, which helps in the reduction of opportunities for exploitation. The intent of this control is to minimize the window of opportunity a threat actor has, to exploit vulnerabilities that may exist within the in- scope environment.
Provide a patch management policy and procedure documentation which comprehensively covers the following aspects:
A suitable minimal patching window for critical/high and medium risks vulnerabilities.
The organization’s patch management policy and procedure documentation must clearly define a suitable minimal patching window for vulnerabilities categorized as critical/high and medium risks. Such a provision establishes the maximum allowable time within which patches must be applied after the identification of a vulnerability, based on its risk level. By explicitly stating these time frames, the organization standardized its approach to patch management, minimizing the risk associated with unpatched vulnerabilities.
Decommissioning of unsupported operating systems and software.
The patch management policy includes provisions for the decommissioning of unsupported operating systems and software. Operating systems and software that no longer receive security updates pose a significant risk to an organization’s security posture. Therefore, this control ensures that such systems are identified and removed or replaced in a timely manner, as defined in the policy documentation.
- A documented procedure outlining how new security vulnerabilities are identified and assigned a risk score.
Patching needs to be based upon risk, the riskier the vulnerability, the quicker it needs to be remediated. Risk ranking of identified vulnerabilities is an integral part of this process. The intent of this control is to ensure that there is a documented risk ranking process which is being followed to ensure all identified vulnerabilities are suitably ranked based upon risk. Organizations usually utilize the Common Vulnerability Scoring System (CVSS) rating provided by vendors or security researchers. It is recommended that if organizations rely on CVSS, that a re-ranking mechanism is included within the process to allow the organization to change the ranking based upon an internal risk assessment. Sometimes, the vulnerability may not be applicable due to the way the application has been deployed within the environment. For example, a Java vulnerability may be released which impacts a specific library that is not used by the organization.
Note: Even if you are running within a purely Platform as a Service ‘PaaS/Serverless’ environment, you still have a responsibility to identify vulnerabilities within your code base: i.e., third-party libraries.
Guidelines: patch management
Supply the policy document. Administrative evidence such as policy and procedure documentation detailing the organization’s defined processes which cover all elements for the given control must be provided.
Note: that logical evidence can be provided as supporting evidence which will provide further insight into your organization’s Vulnerability Management Program (VMP), but it will not meet this control on its own.
Example evidence: patch management
The next screenshot shows a snippet of a patch management/risk ranking policy as well as the different levels of risk categories. This is followed by the classification and remediation timeframes. Please Note: The expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.


Example of (Optional) Additional Technical Evidence Supporting the Policy Document
Logical evidence such as vulnerability tracking spreadsheets, vulnerability technical assessment reports, or screenshots of tickets raised through online management platforms to track the status and progress of vulnerabilities used to support the implementation of the process outlined in the policy documentation to be provided. The next screenshot demonstrated that Snyk, which is a Software Composition Analysis (SCA) tool, is used to scan the code base for vulnerabilities. This is followed by a notification via email.
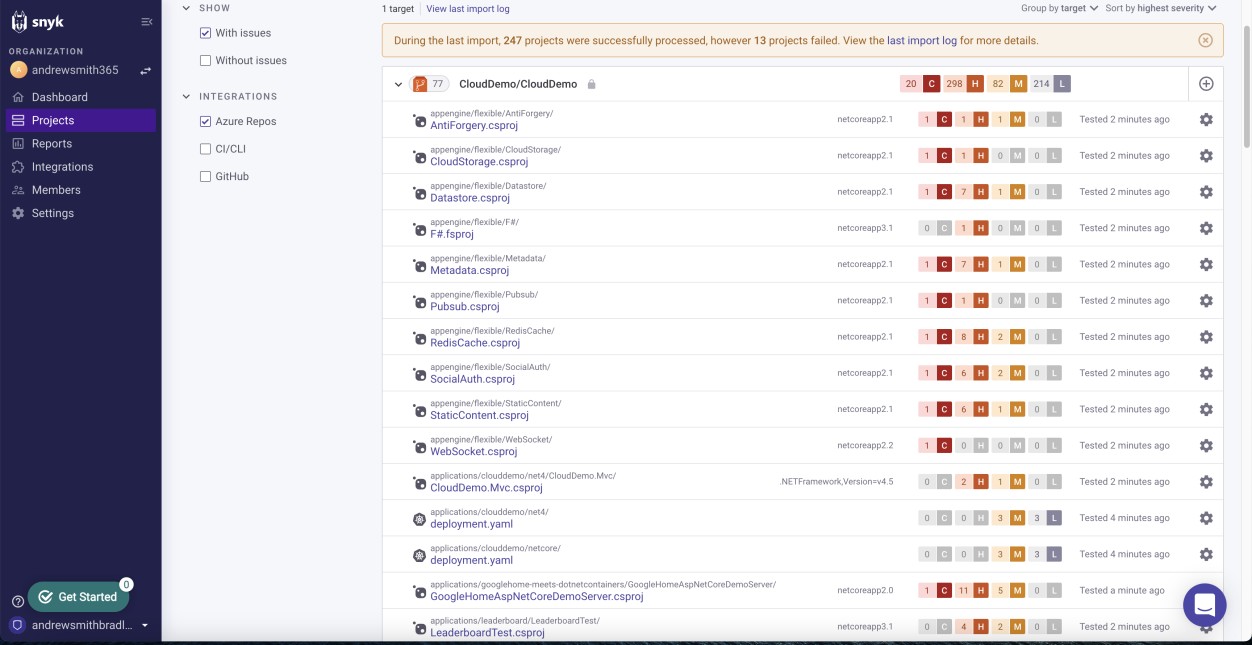
Please Note: In these example a full screenshot was not used, however ALL ISV submitted evidence screenshots must be full screenshots showing any URL, logged in user and the system time and date.
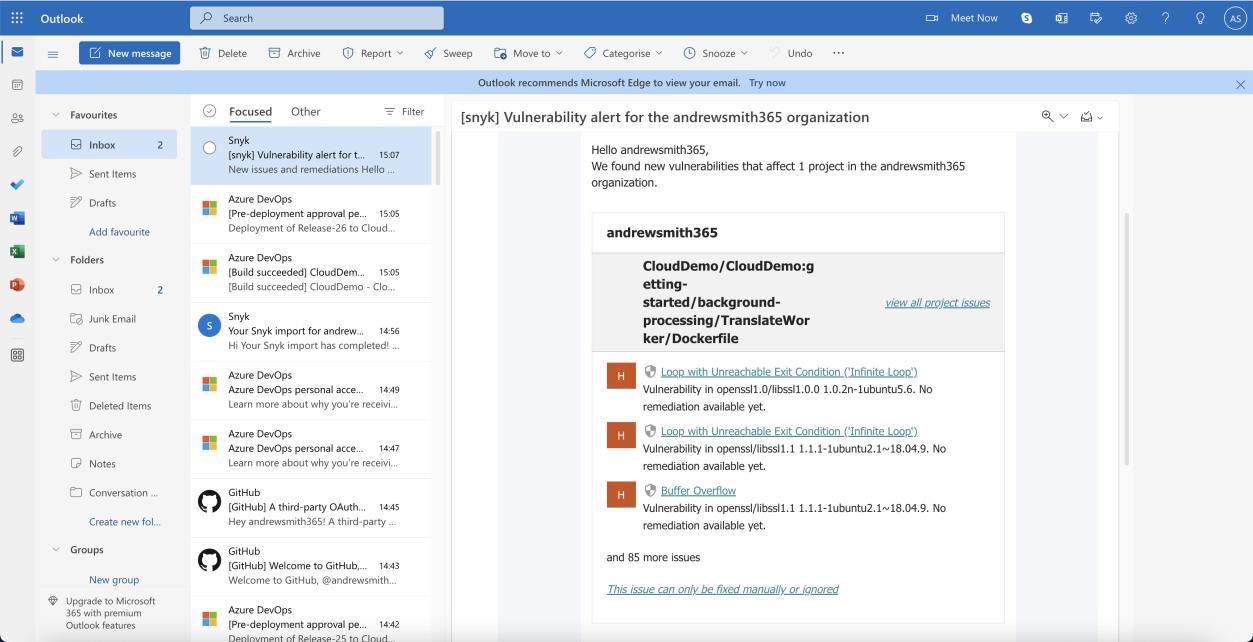
The next two screenshots show an example of the email notification received when new vulnerabilities are flagged by Snyk. We can see the email contains the project affected and the assigned user for receiving the alerts.
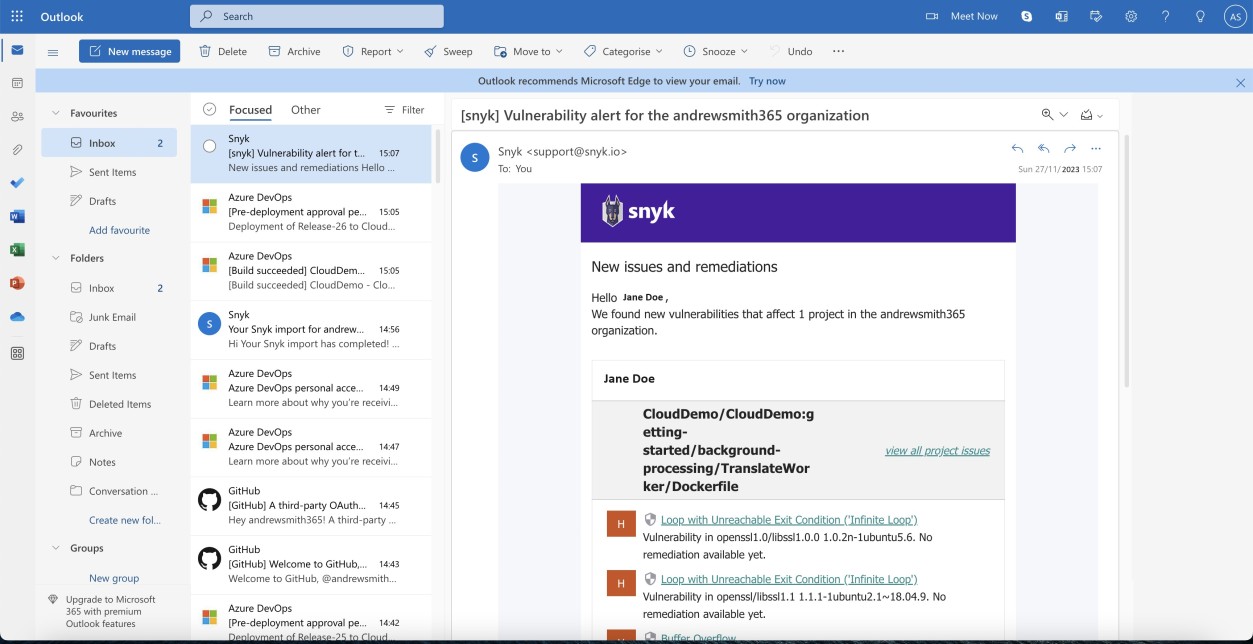
The following screenshot shows the vulnerabilities identified.
Please Note: In the previous examples full screenshots were not used, however ALL ISV submitted evidence screenshots must be full screenshots showing URL, any logged in user and system time and date.
Example evidence
The next screenshots show GitHub security tools configured and enabled to scan for vulnerabilities within the code base and alerts are sent via email.
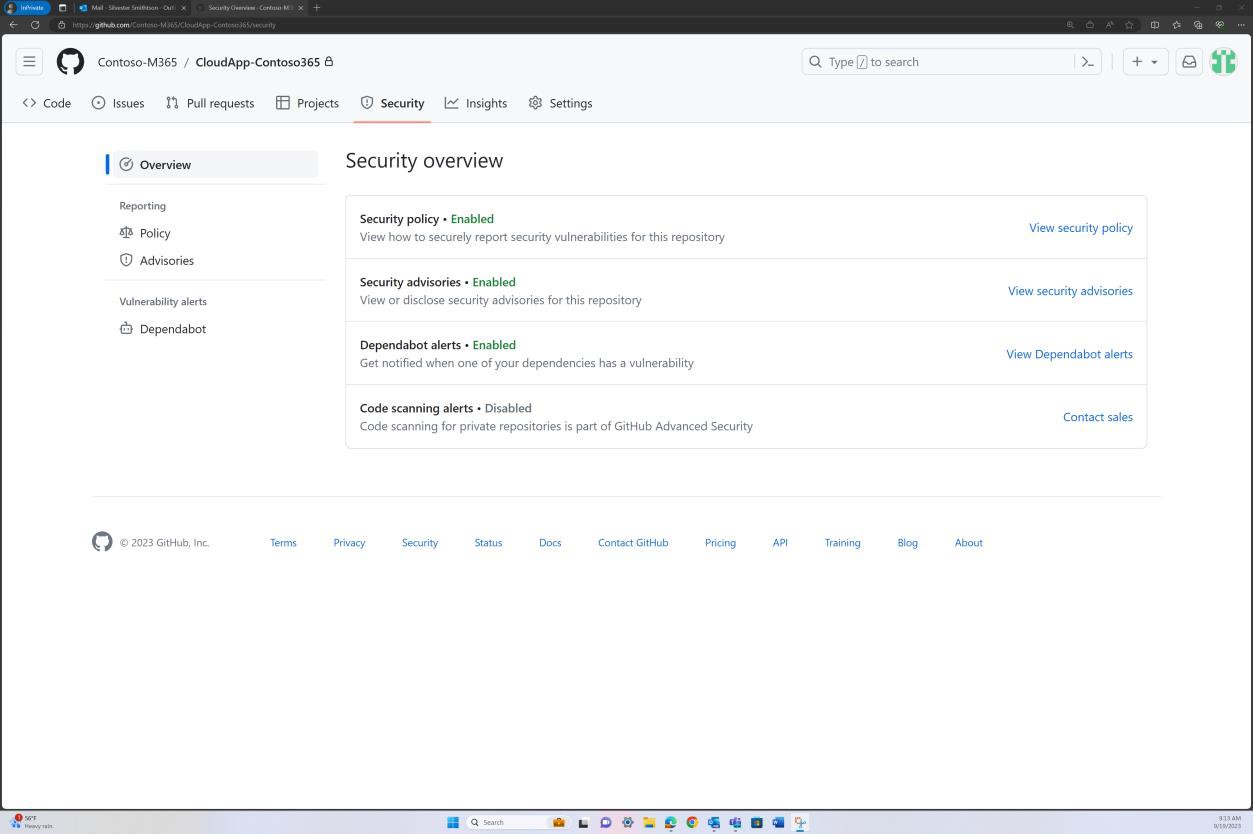
The email notification shown next is a confirmation that the flagged issues will be automatically resolved through a pull request.
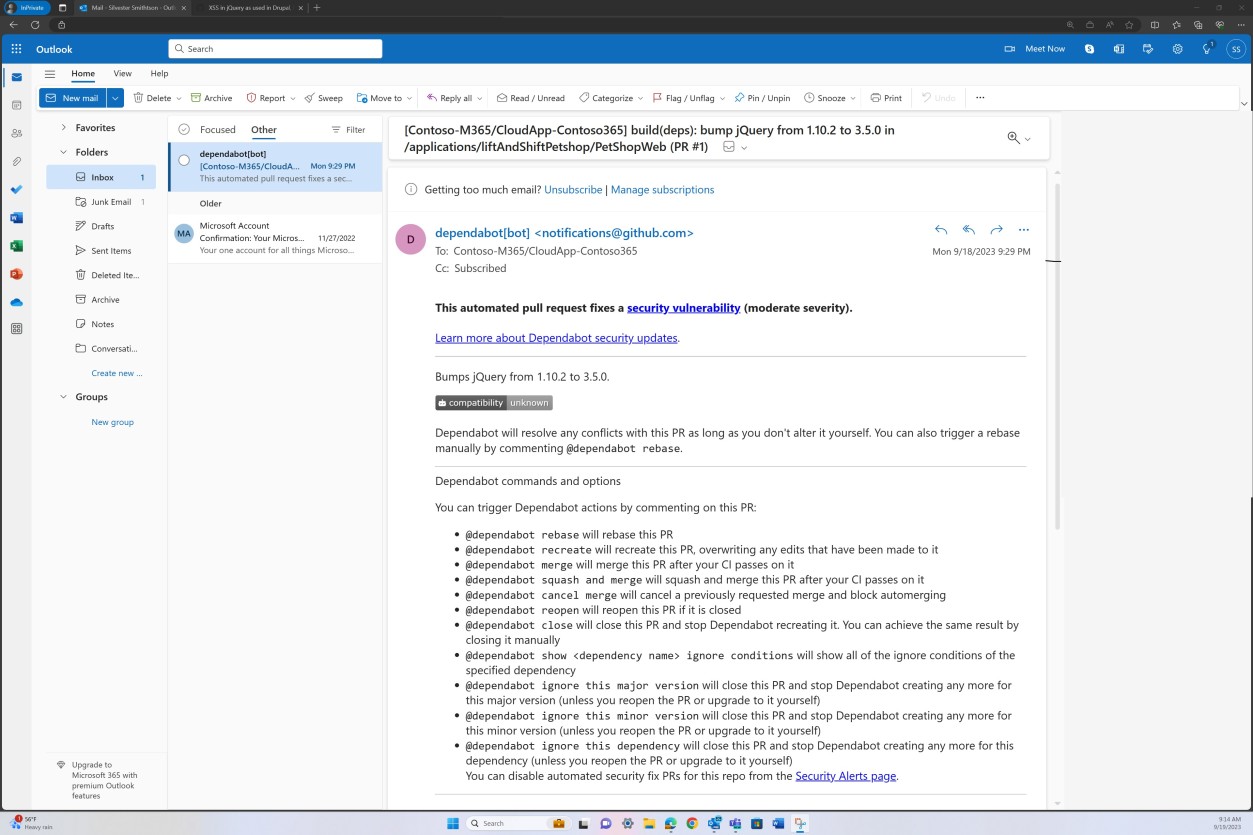
Example evidence
The next screenshot shows the internal technical assessment and ranking of vulnerabilities via a spreadsheet.
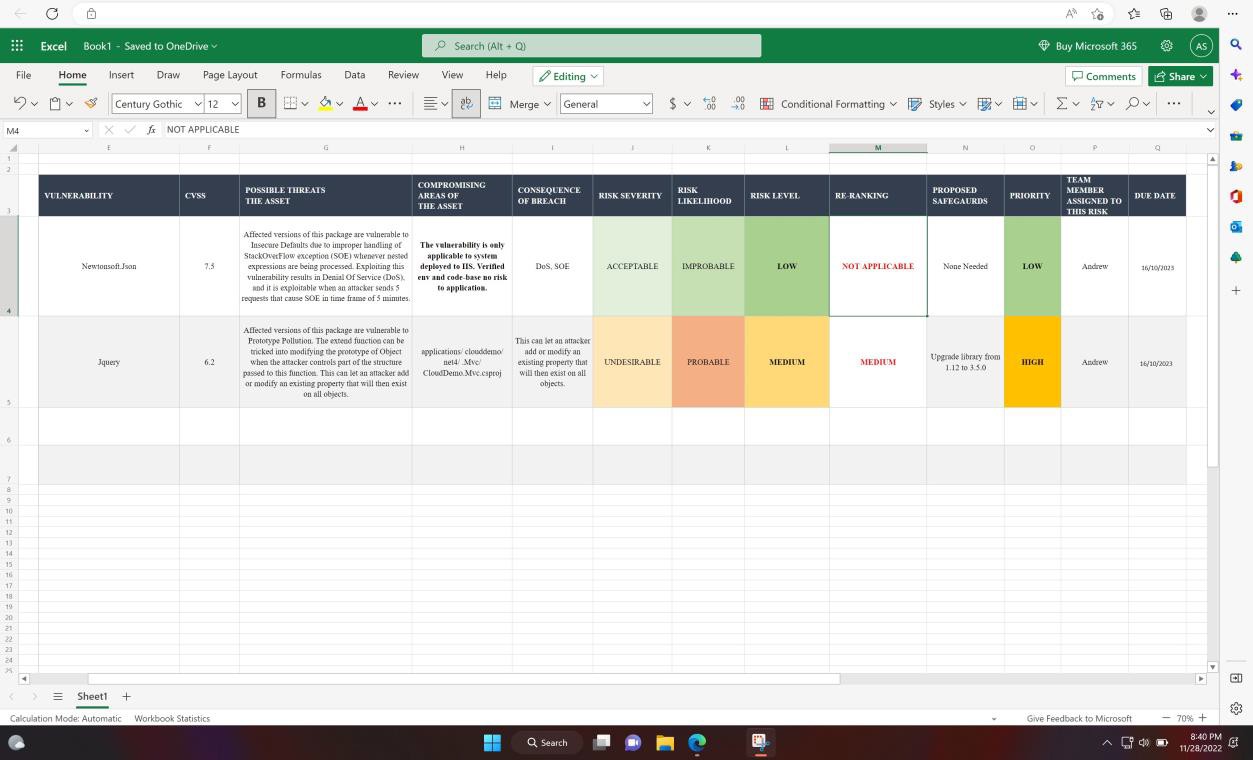
Example evidence
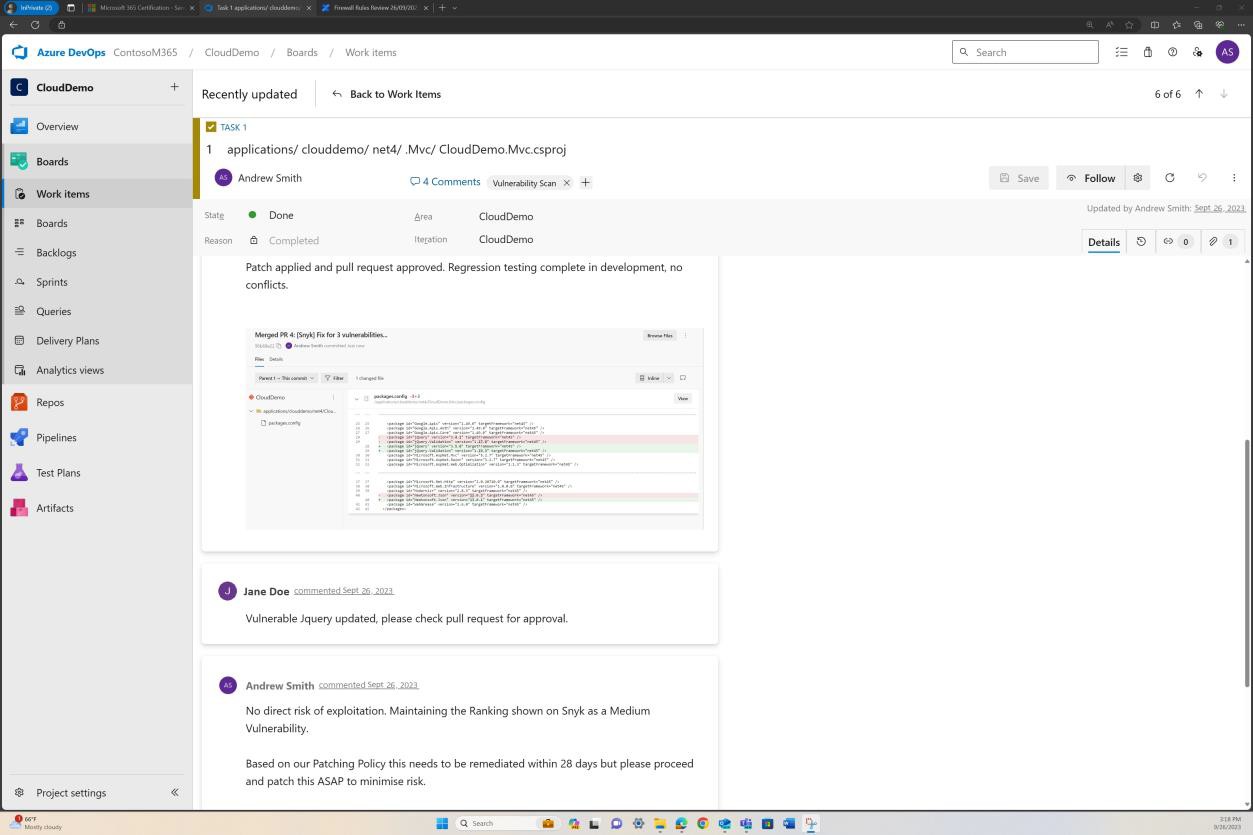
The next screenshots show tickets raised in DevOps for each vulnerability that has been discovered.
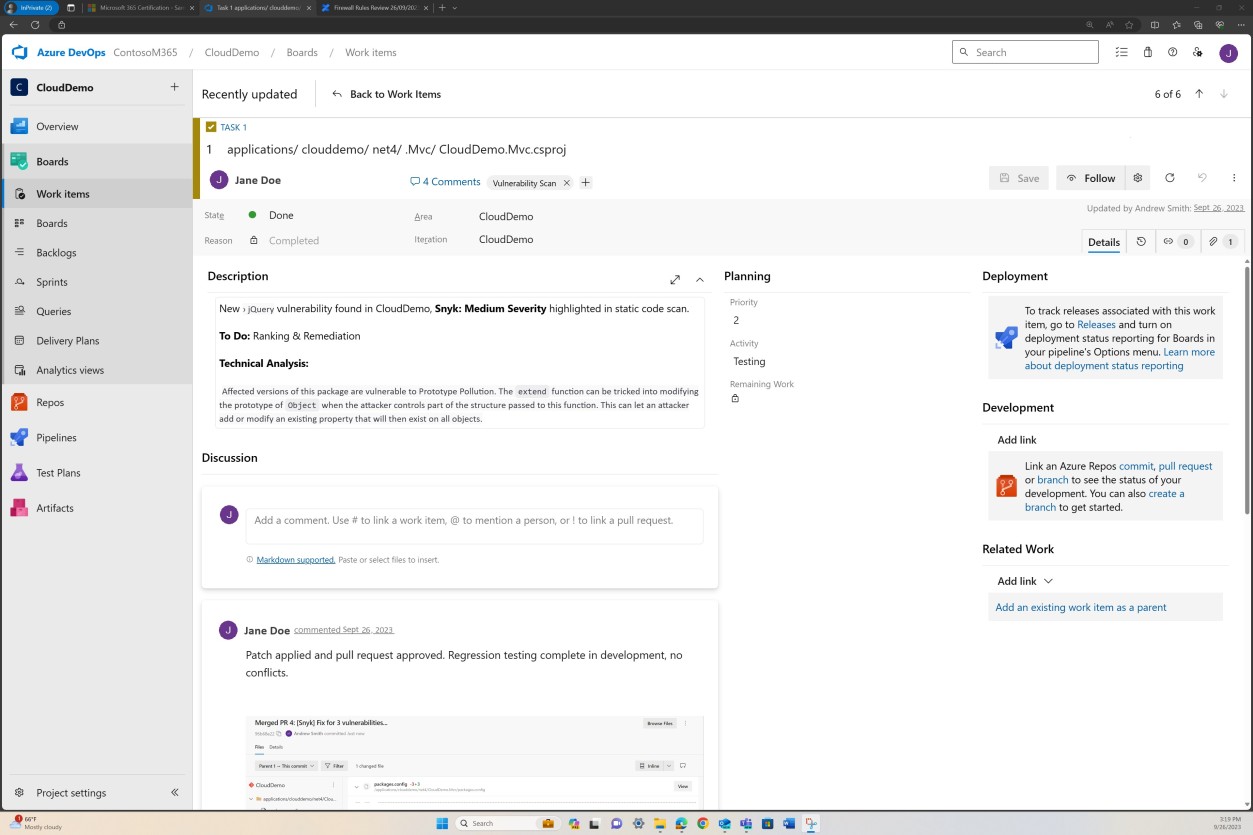
Assessment, ranking and reviewed by a separate employee occurs before implementing the changes.
Control No. 5
Provide demonstratable evidence that:
All sampled system components are being patched.
Provide demonstratable evidence that unsupported operating systems and software components are not in use.
Intent: sampled system components
This subpoint aims to ensure that verifiable evidence is provided to confirm that all sampled system components within the organization are being actively patched. The evidence may include but is not limited to, patch management logs, system audit reports, or documented procedures showing that patches have been applied. Where serverless technology or Platform as a Service (PaaS) is employed, this should extend to include the code base to confirm that the most recent and secure versions of libraries and dependencies are in use.
Guidelines: sampled system components
Provide a screenshot for every device in the sample and supporting software components showing that patches are installed in line with the documented patching process. Additionally, provide screenshots demonstrating the patching of the code base.
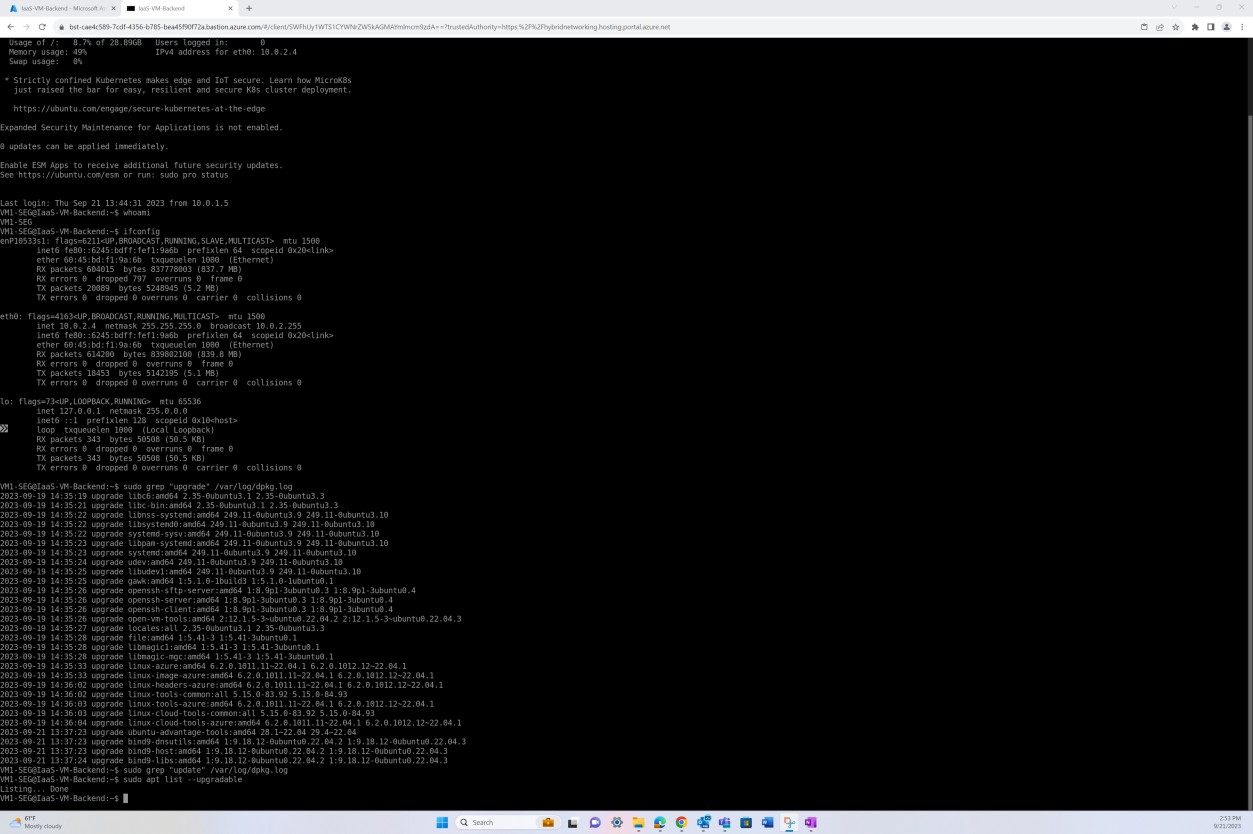
Example evidence: sampled system components
The next screenshot demonstrates the patching of a Linux operating system virtual machine ‘IaaS- VM-Backend’.
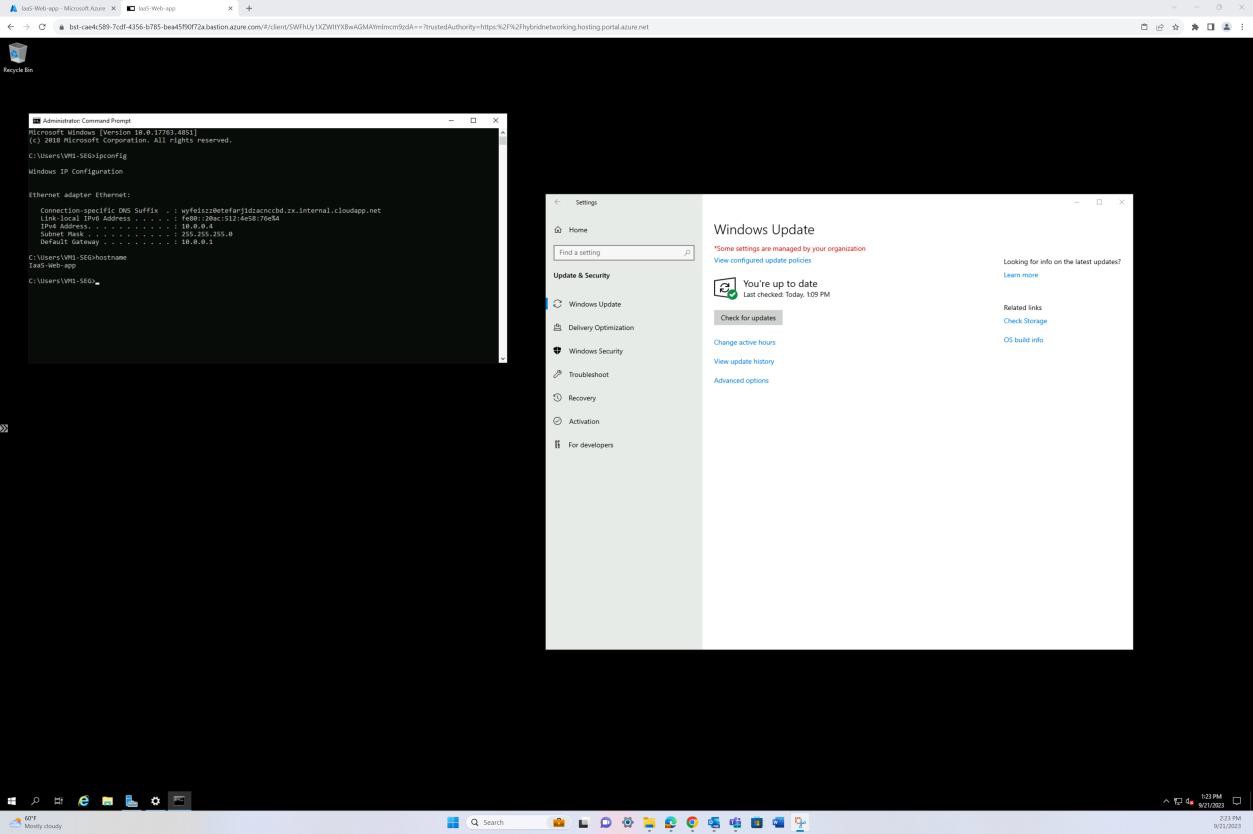
Example evidence
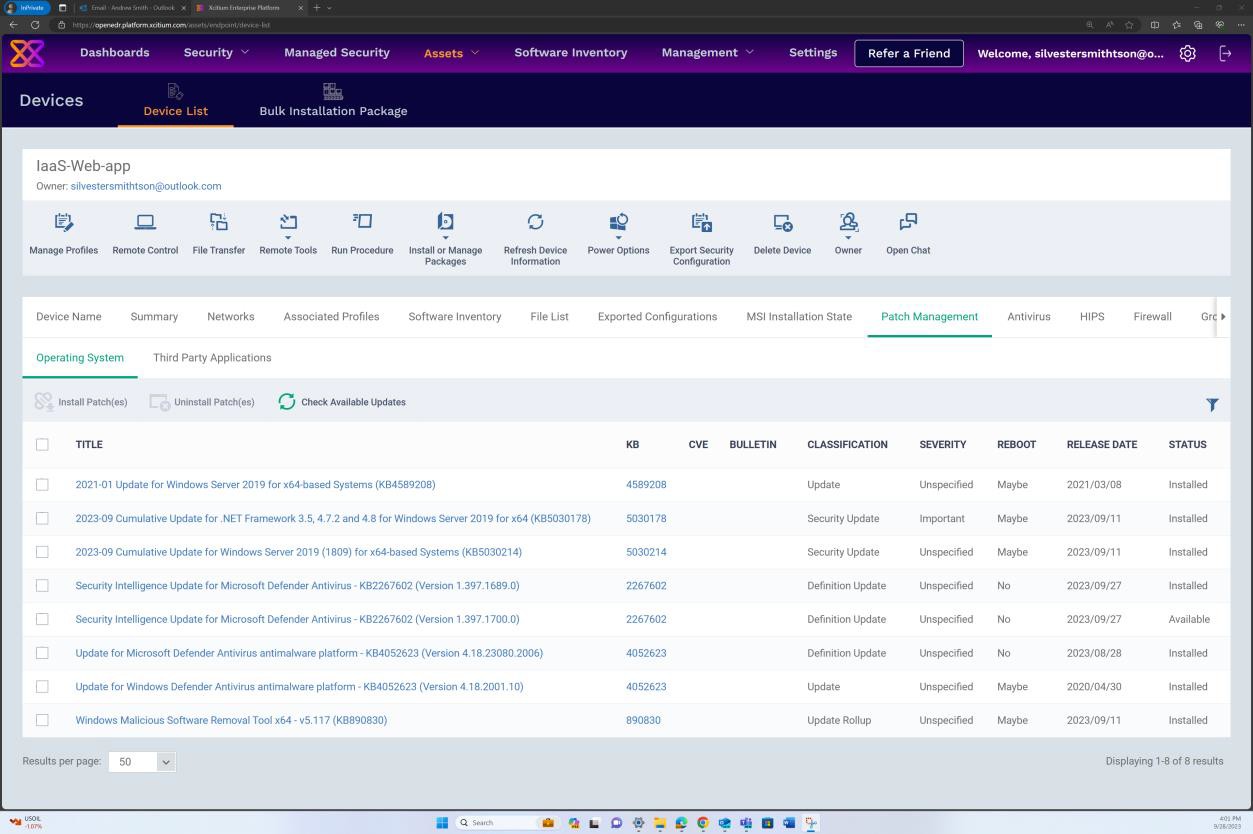
The next screenshot demonstrates the patching of a Windows operating system virtual machine ‘IaaS-Web-app’.
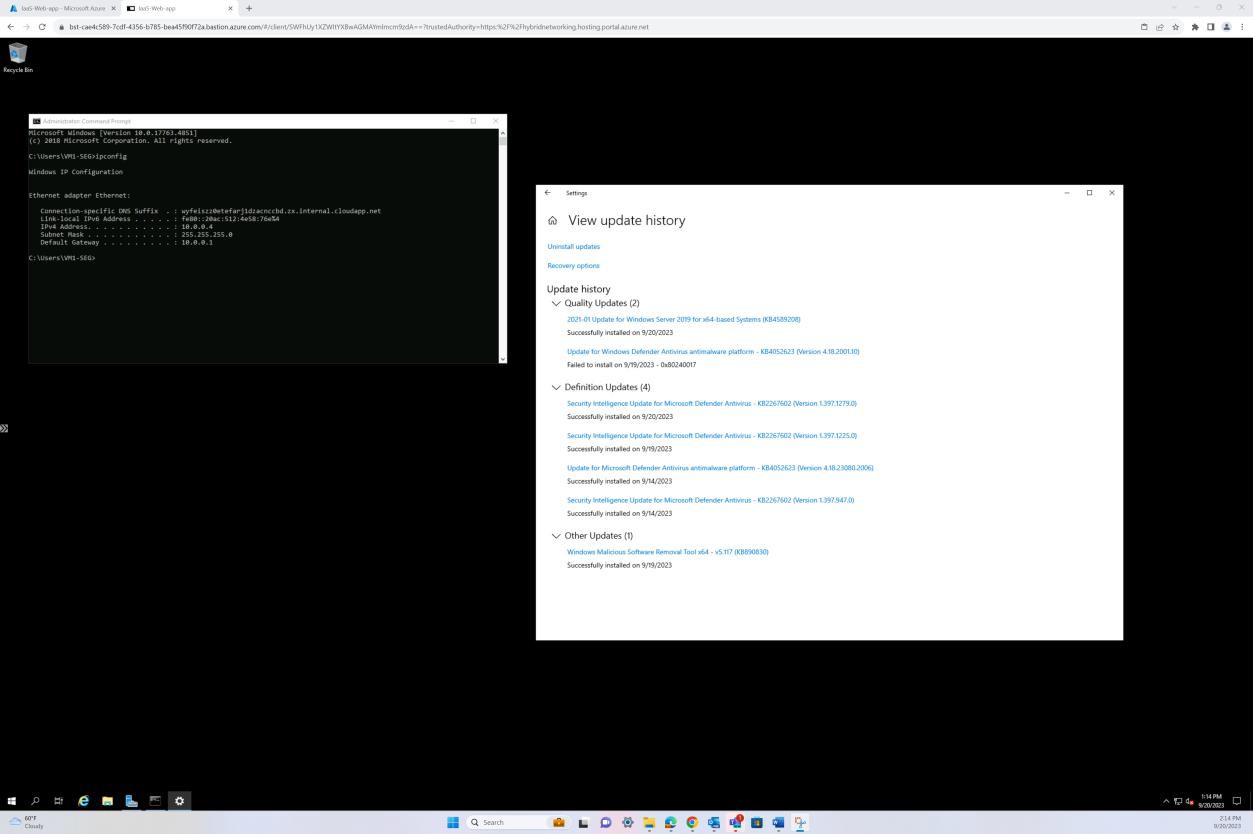
Example evidence
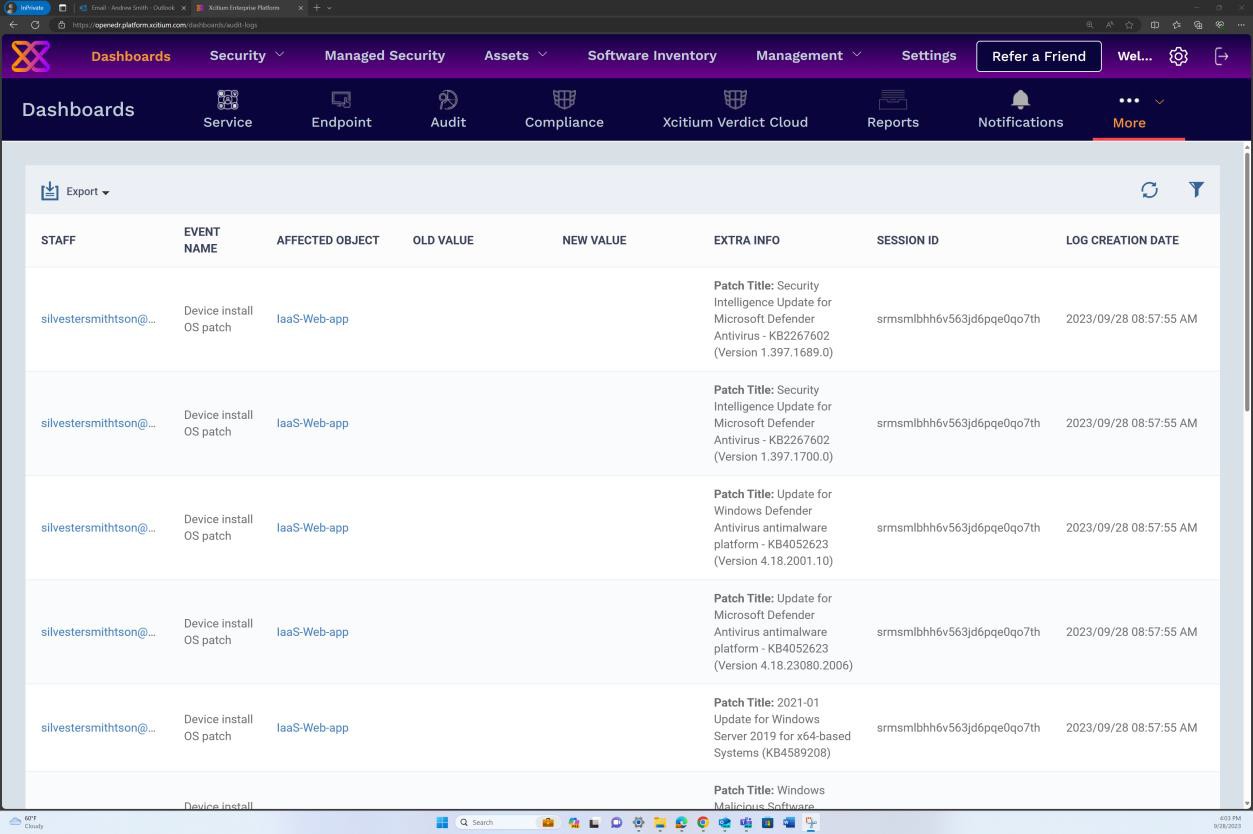
If you are maintaining the patching from any other tools such as Microsoft Intune, Defender for Cloud etc., screenshots can be provided from these tools. The next screenshots from the OpenEDR solution demonstrate that patch management is performed via the OpenEDR portal.
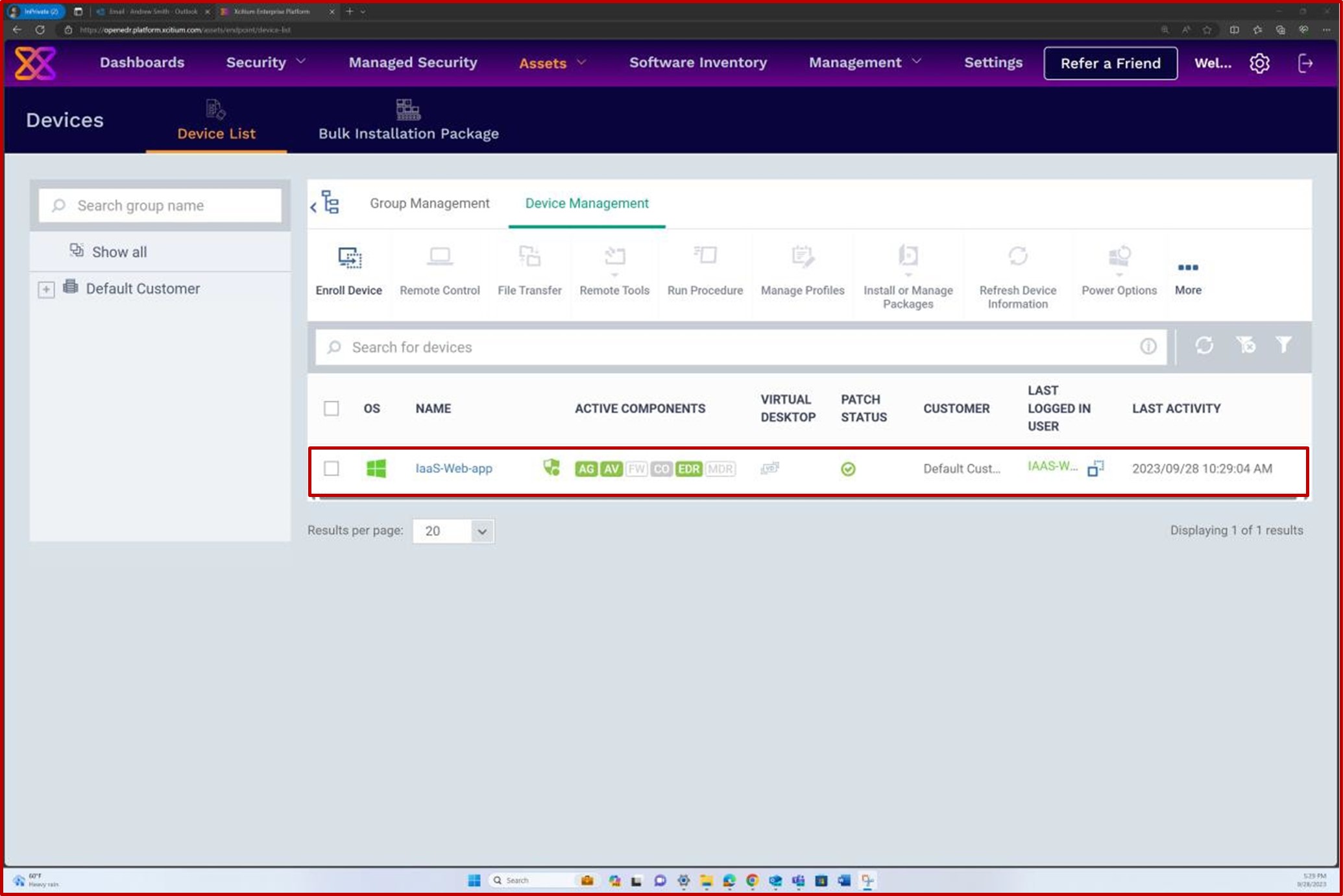
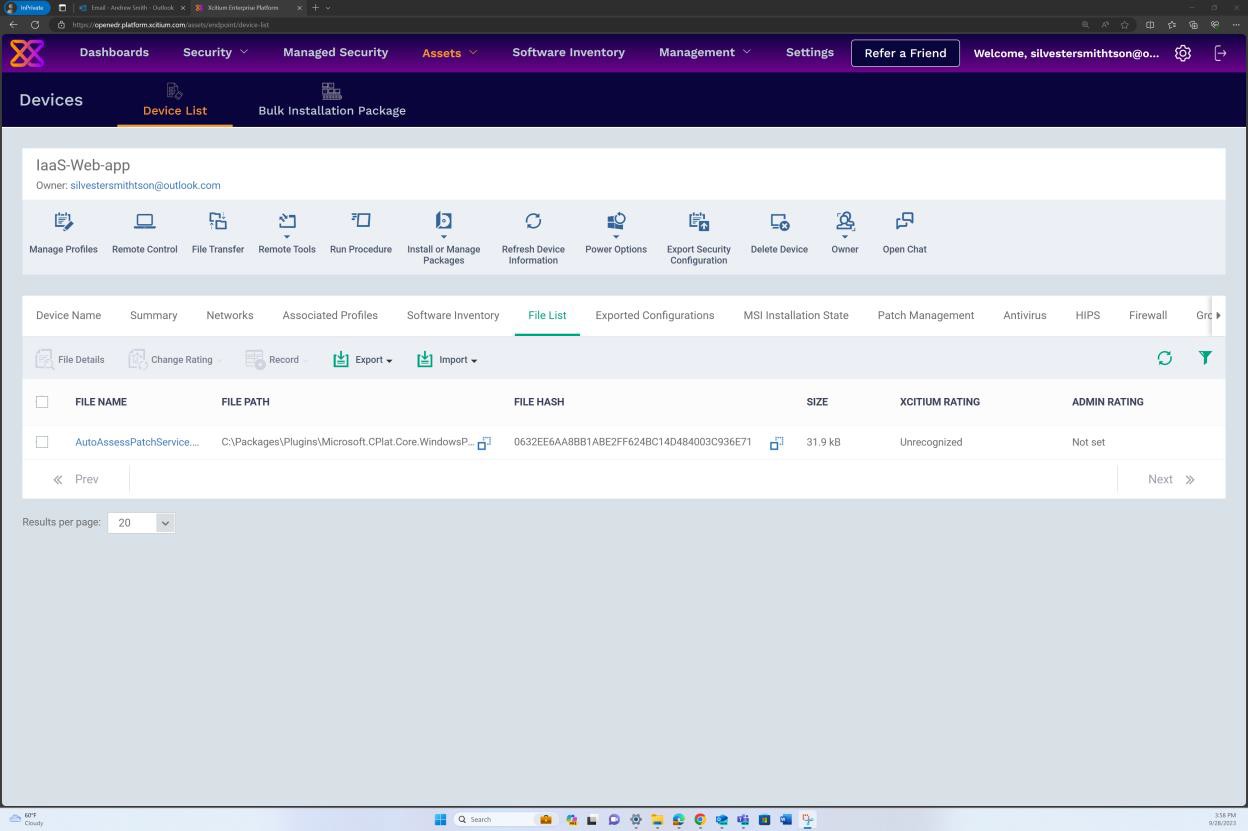
The next screenshot demonstrates that patch management of the in-scope server is done via the OpenEDR platform. The classification and the status are visible below demonstrating that patching occurs.
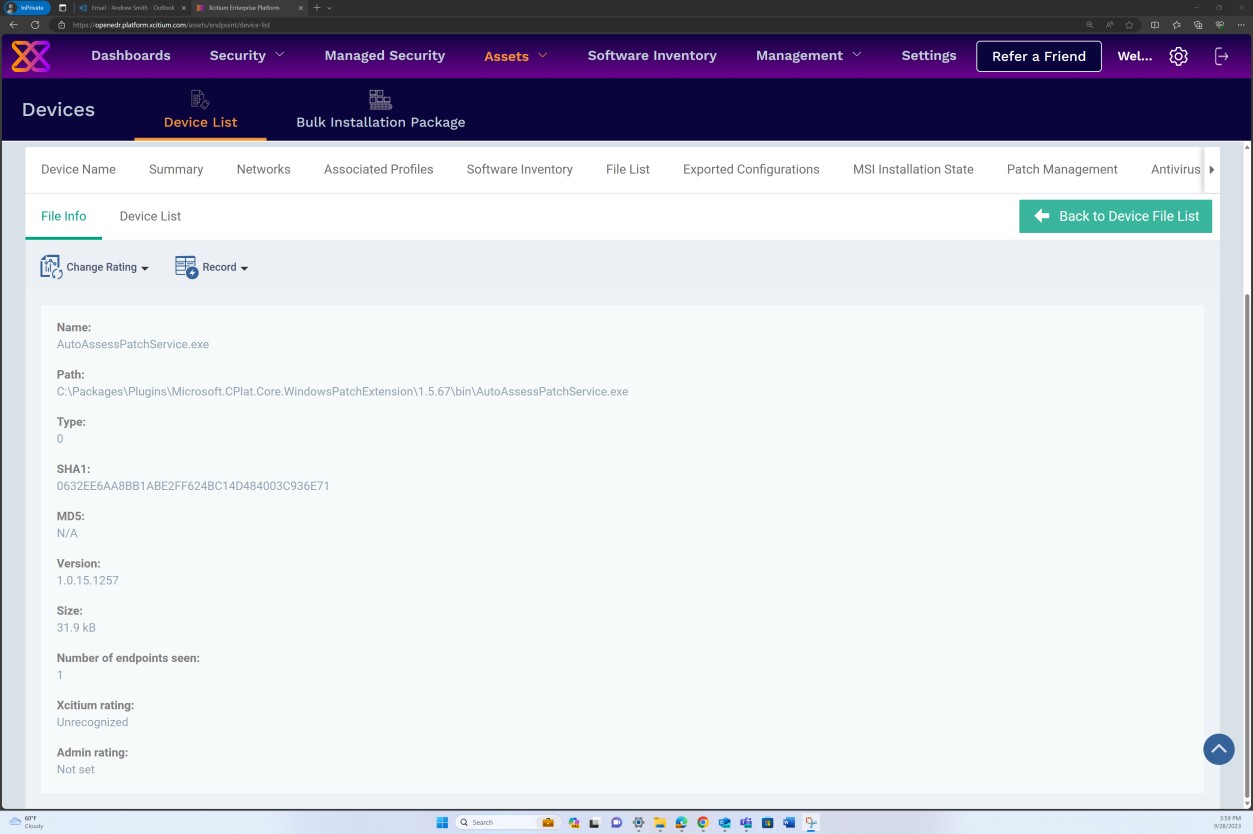
The next screenshot shows that logs are generated for the patches successfully installed on the server.
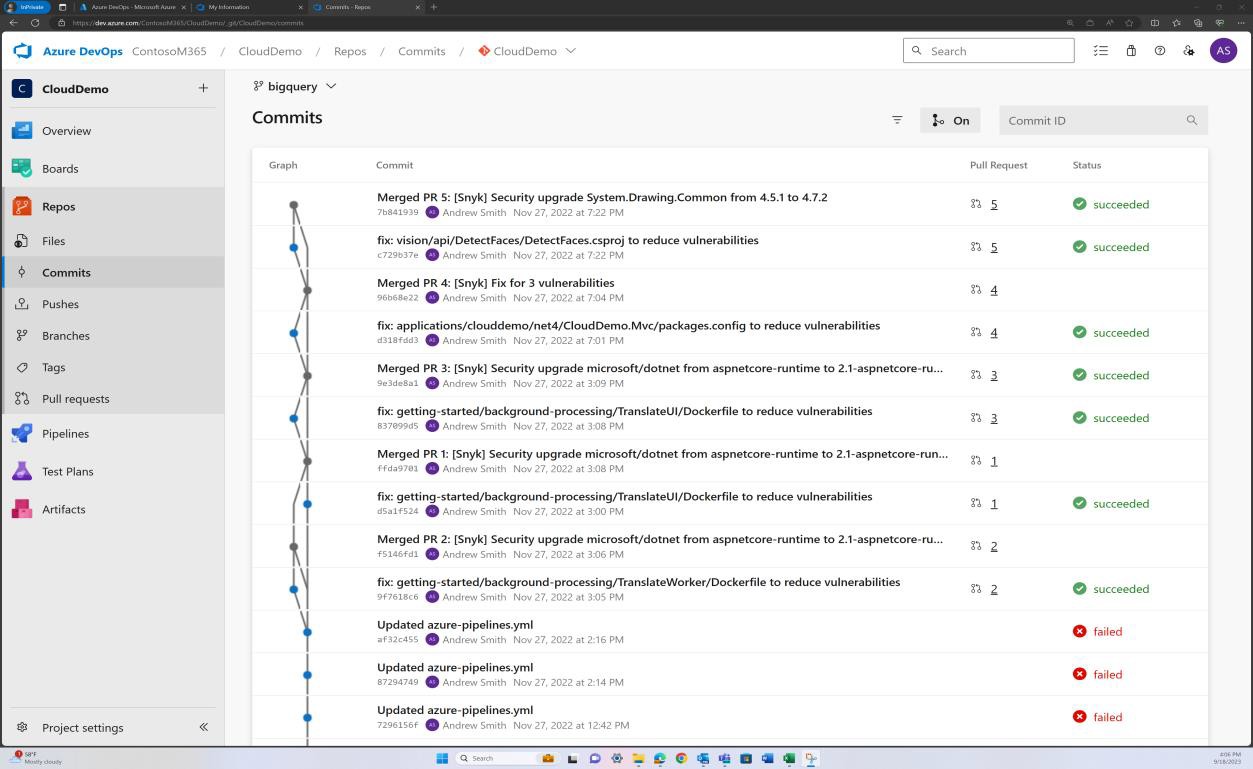
Example evidence
The next screenshot demonstrates that the code base/third party library dependencies are patched via Azure DevOps.
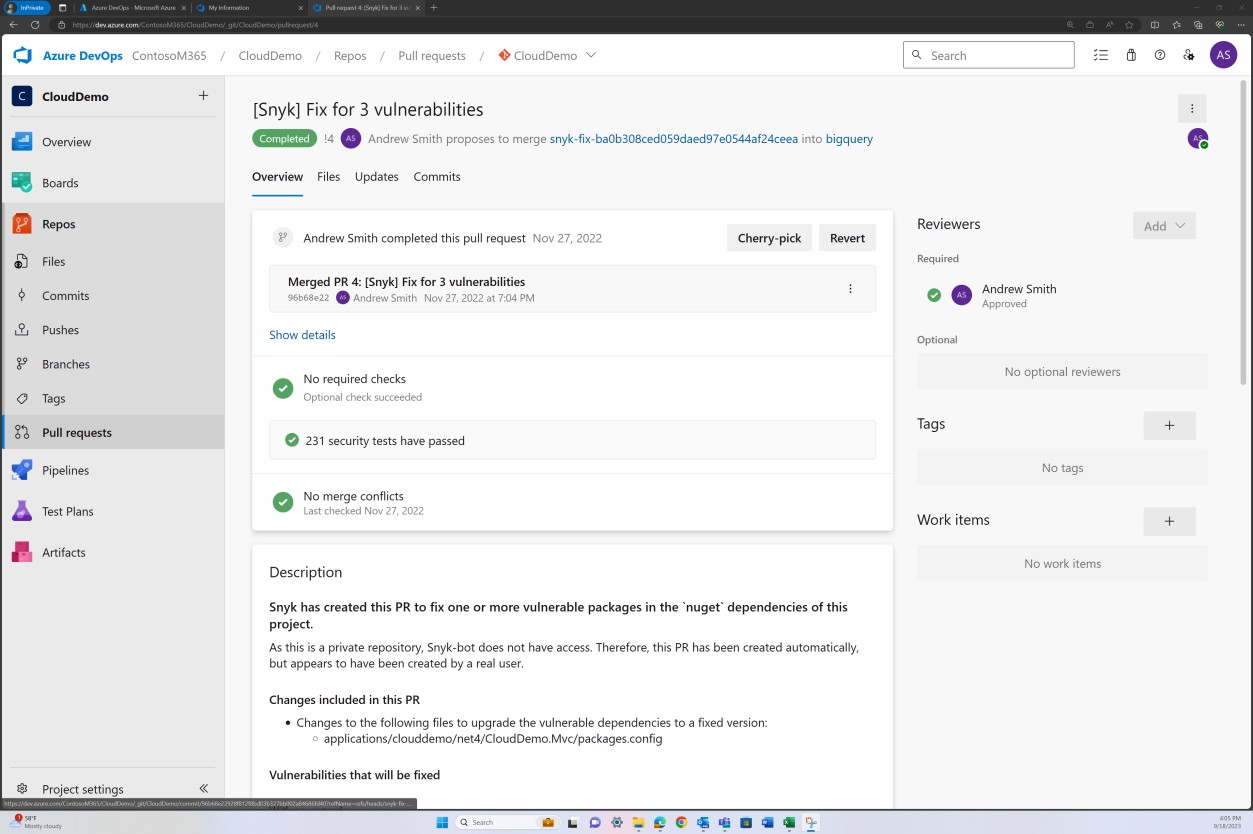
The next screenshot shows that a fix for vulnerabilities discovered by Snyk is being committed to the branch to resolve outdated libraries.
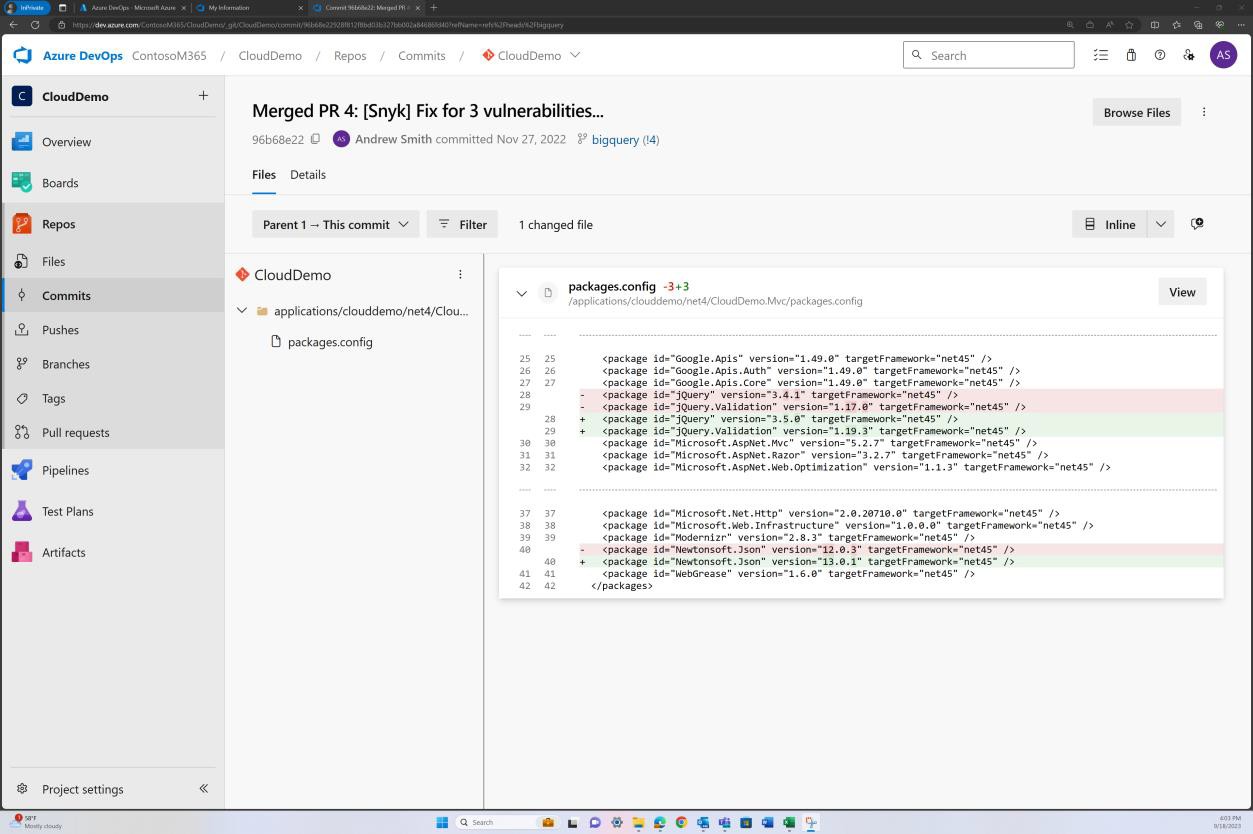
The next screenshot demonstrates that the libraries have been upgraded to supported versions.
Example evidence
The next screenshots demonstrate that code base patching is maintained via GitHub Dependabot. Closed items demonstrate that patching occurs, and vulnerabilities have been resolved.
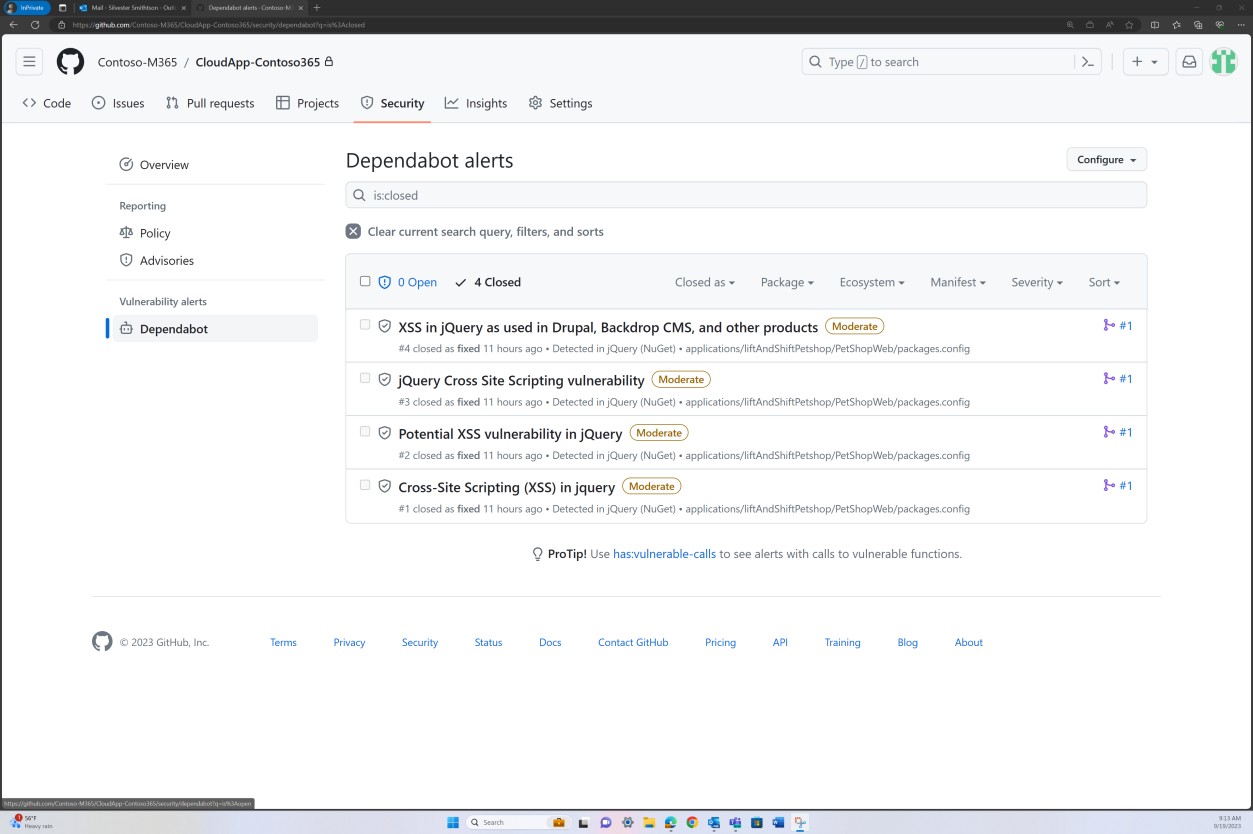
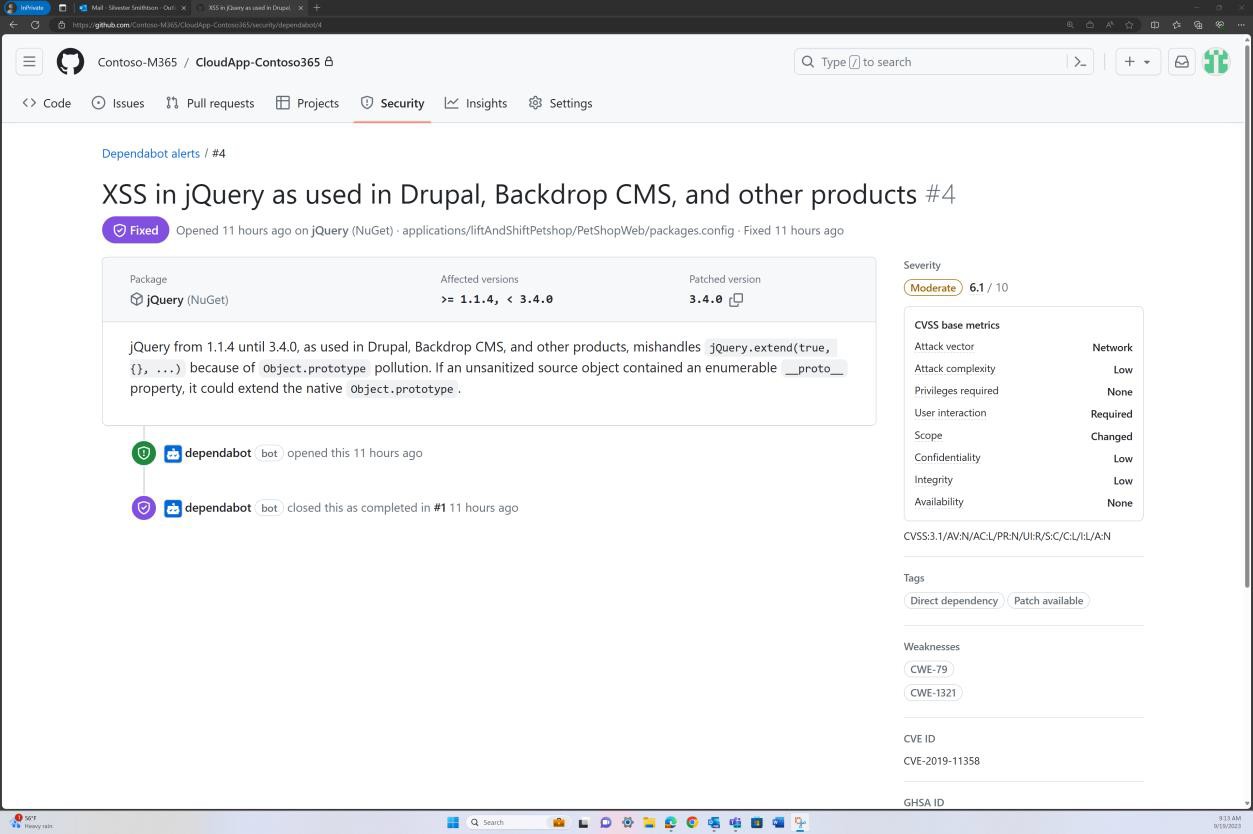
Intent: unsupported OS
Software that is not being maintained by vendors will, overtime, suffer from known vulnerabilities that are not fixed. Therefore, the use of unsupported operating systems and software components must not be used within production environments. Where Infrastructure-as-a-Service (IaaS) is deployed, the requirement for this subpoint expands to include both the infrastructure and the code base to ensure that every layer of the technology stack is compliant with the organization’s policy on the use of supported software.
Guidelines: unsupported OS
Provide a screenshot for every device in the sample set chosen by your analyst for you to collect evidence against showing the version of OS running (include the device/server’s name in the screenshot). In addition to this, provide evidence that software components running within the environment are running supported versions of the software. This may be done by providing the output of internal vulnerability scan reports (providing authenticated scanning is included) and/or the output of tools which check third-party libraries, such as Snyk, Trivy or NPM Audit. If running in PaaS only third-party library patching needs to be covered.
Example evidence: unsupported OS
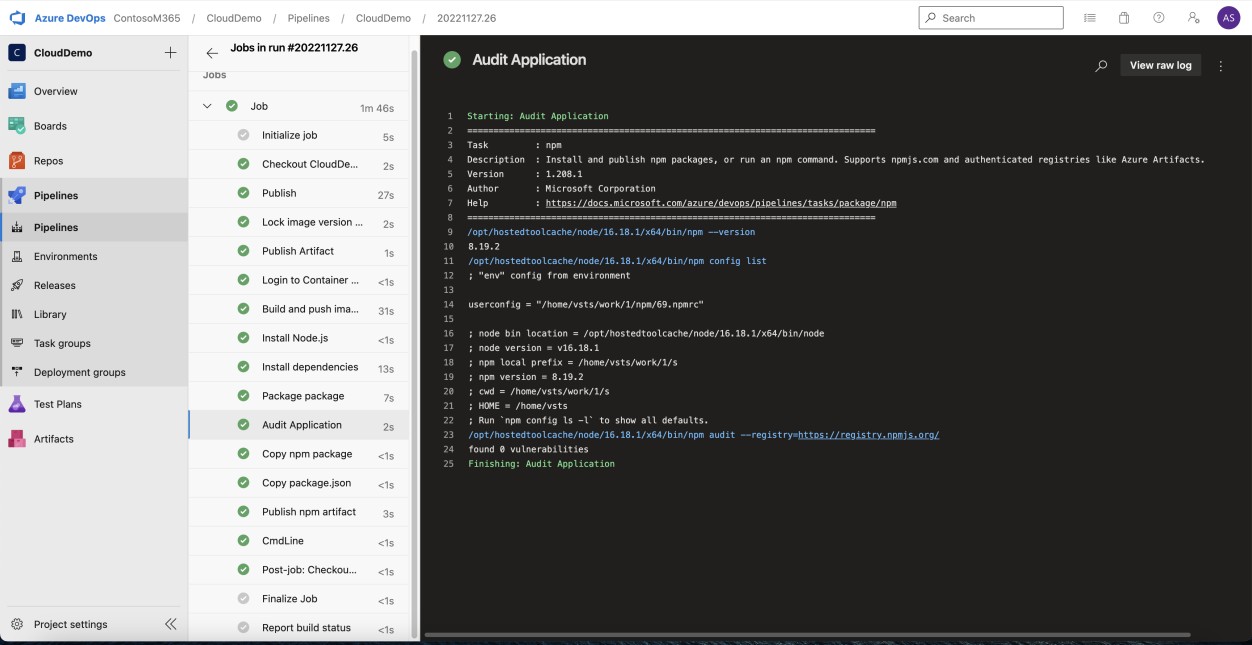
The next screenshot from Azure DevOps NPM audit demonstrates that no unsupported libraries/ dependencies are utilized within the web app.
Note: In the next example a full screenshot was not used, however ALL ISV submitted evidence screenshots must be full screenshots showing URL, any logged in user and system time and date.
Example evidence
The next screenshot from GitHub Dependabot demonstrates that no libraries/dependencies are utilized within the web app.
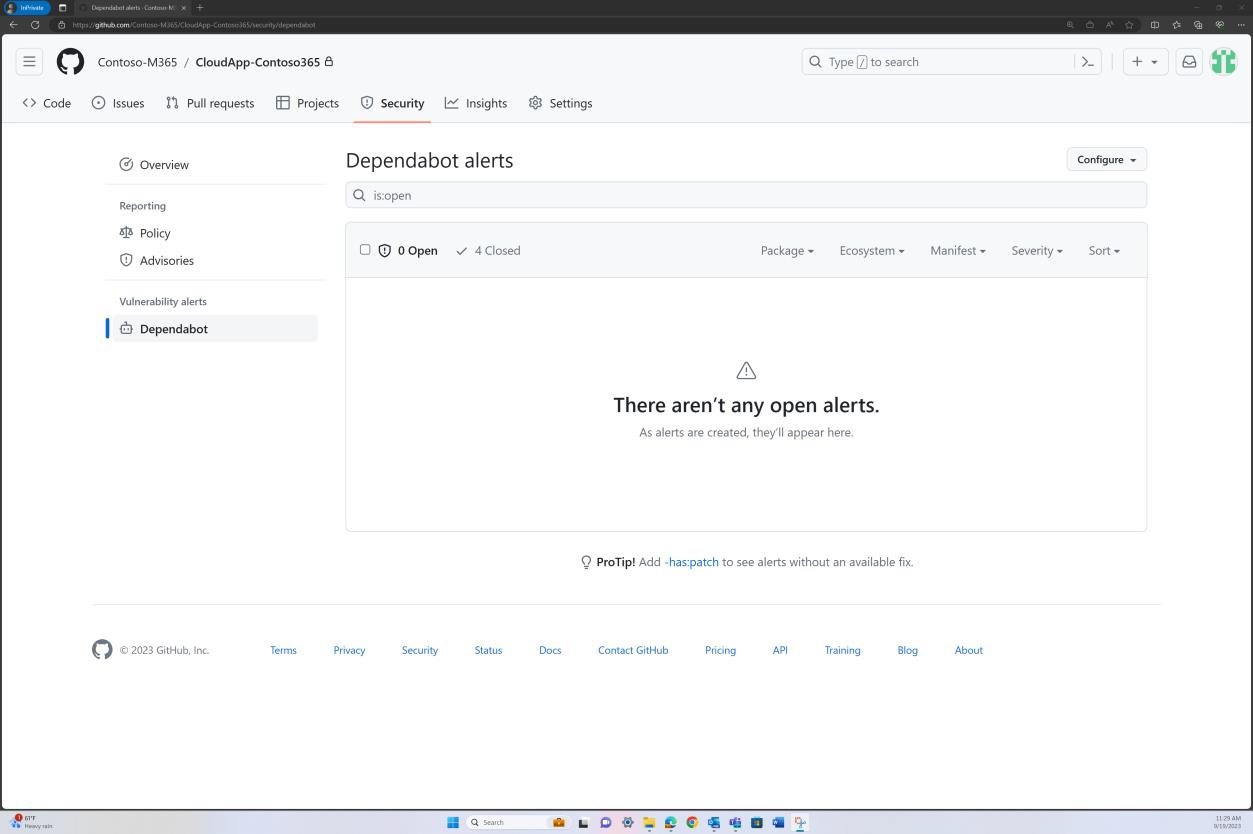
Example evidence
The next screenshot from software inventory for Windows operating system via OpenEDR demonstrates that no unsupported or outdated operating system and software versions were found.
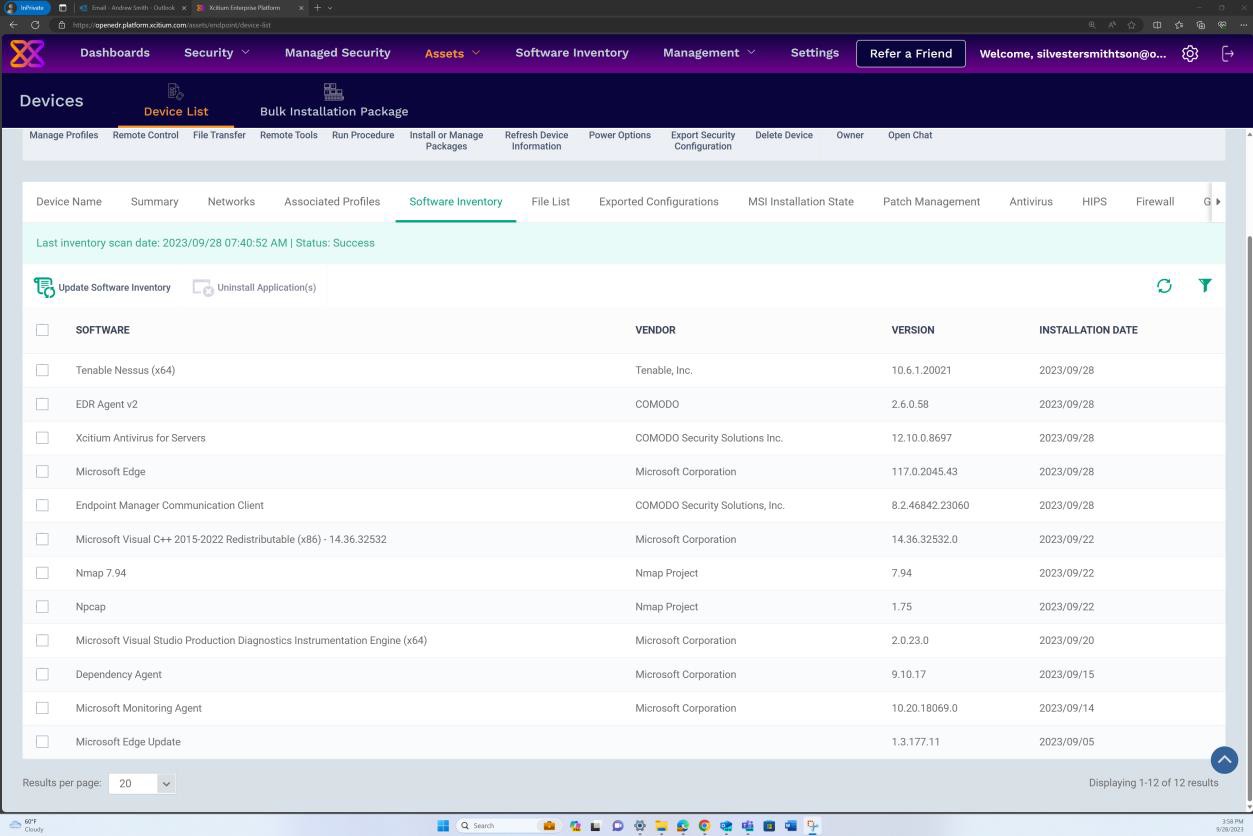
Example evidence
The next screenshot is from OpenEDR under the OS Summary showing Windows Server 2019 Datacenter (x64) and OS full version history including service pack, build version, etc… validating that no unsupported operating system was found.
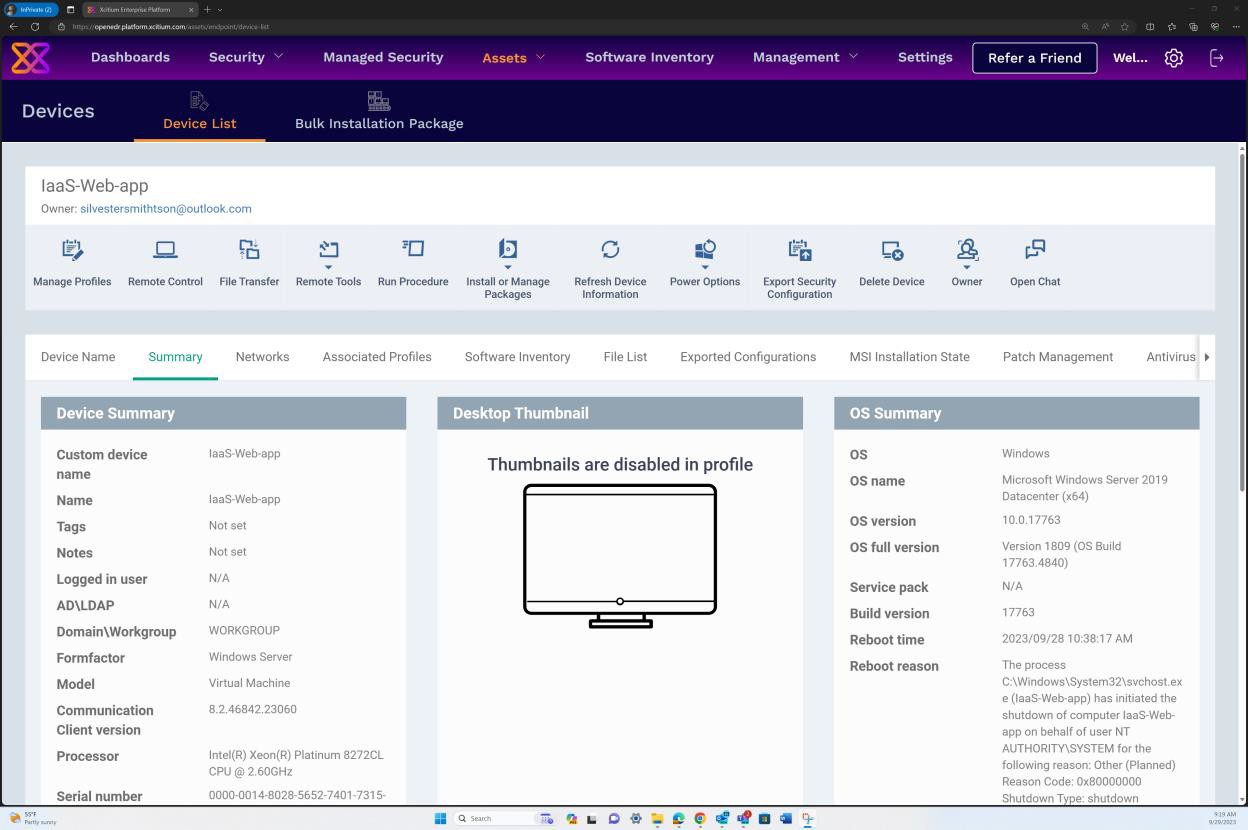
Example evidence
The next screenshot from a Linux operating system server demonstrates all the version details including Distributor ID, Description, Release and Codename validating that no unsupported Linux operating system was found.
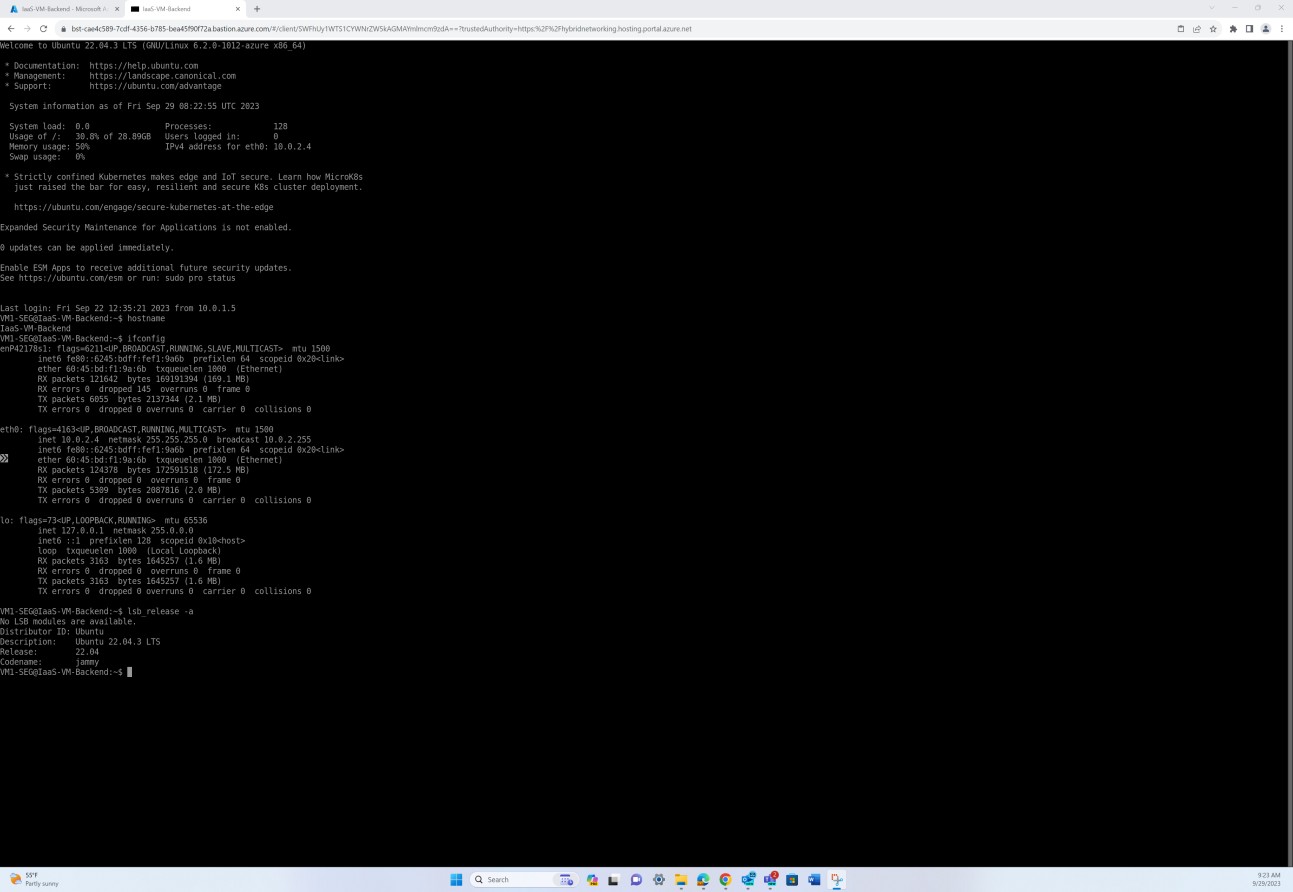
Example evidence:
The next screenshot from Nessus vulnerability scan report demonstrates that no unsupported operating system (OS) and software were found on the target machine.
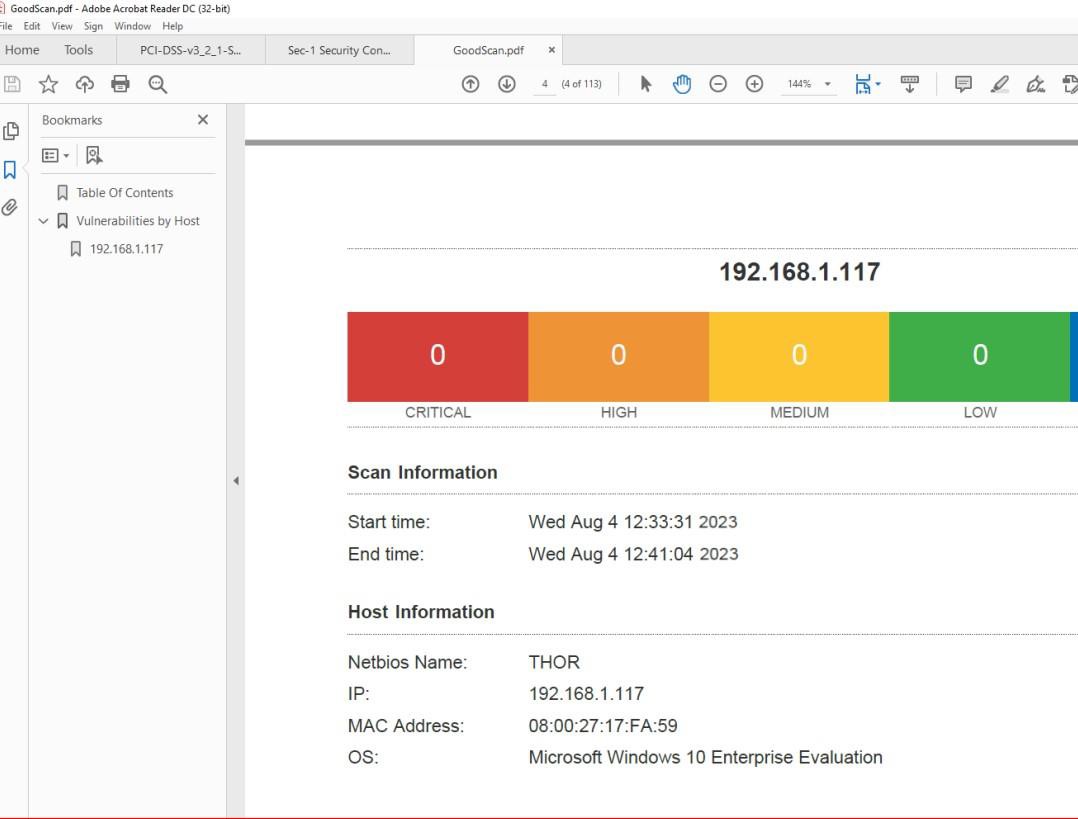
Please Note: In the previous examples a full screenshot was not used, however ALL ISV submitted evidence screenshots must be full screenshots showing URL, any logged in user and system time and date.
Vulnerability scanning
Vulnerability scanning looks for possible weaknesses in an organization’s computer system, networks, and web applications to identify holes which could potentially lead to security breaches and the exposure of sensitive data. Vulnerability scanning is often required by industry standards and government regulations, for example, the PCI DSS (Payment Card Industry Data Security Standard).
A report by Security Metric entitled “2020 Security Metrics Guide to PCI DSS Compliance” states that ‘on average it took 166 days from the time an organization was seen to have vulnerabilities for an attacker to compromise the system. Once compromised, attackers had access to sensitive data for an average of 127 days’ therefore this control is aimed at identifying potential security weakness within the in-scope environment.
By introducing regular vulnerability assessments, organizations can detect weaknesses and insecurities within their environments which may provide an entry point for a malicious actor to compromise the environment. Vulnerability scanning can help to identify missing patches or misconfigurations within the environment. By regularly conducting these scans, an organization can provide appropriate remediation to minimize the risk of a compromise due to issues that are commonly picked up by these vulnerability scanning tools.
Control No. 6
Please provide evidence demonstrating that:
Quarterly infrastructure and web application vulnerability scanning is carried out.
Scanning needs to be carried out against the entire public footprint (IPs/URLs) and internal IP ranges if the environment is IaaS, Hybrid or On-prem.
Note: This must include the full scope of the environment.
Intent: vulnerability scanning
This control aims to ensure that the organization conducts vulnerability scanning on a quarterly basis, targeting both its infrastructure and web applications. The scanning must be comprehensive, covering both public footprints such as public IPs and URLs, as well as internal IP ranges. The scope of scanning varies depending on the nature of the organization’s infrastructure:
If an organization implements hybrid, on-premises, or Infrastructure-as-a-Service (IaaS) models, the scanning must encompass both external public IPs/URLs and internal IP ranges.
If an organization implements Platform-as-a-Service (PaaS), the scanning must encompass external public IPs/URLs only.
This control also mandates that the scanning should include the full scope of the environment, thereby leaving no component unchecked. The objective is to identify and evaluate vulnerabilities in all parts of the organization’s technology stack to ensure comprehensive security.
Guidelines: vulnerability scanning
Provide the full scan report(s) for each quarter’s vulnerability scans that have been carried out over the past 12 months. The reports should clearly state the targets to validate that the full public footprint is included, and where applicable, each internal subnet. Provide ALL scan reports for EVERY quarter.
Example evidence: vulnerability scanning
The next screenshot shows a network discovery and a port scan performed via Nmap on the External infrastructure to identify any unsecured open ports.
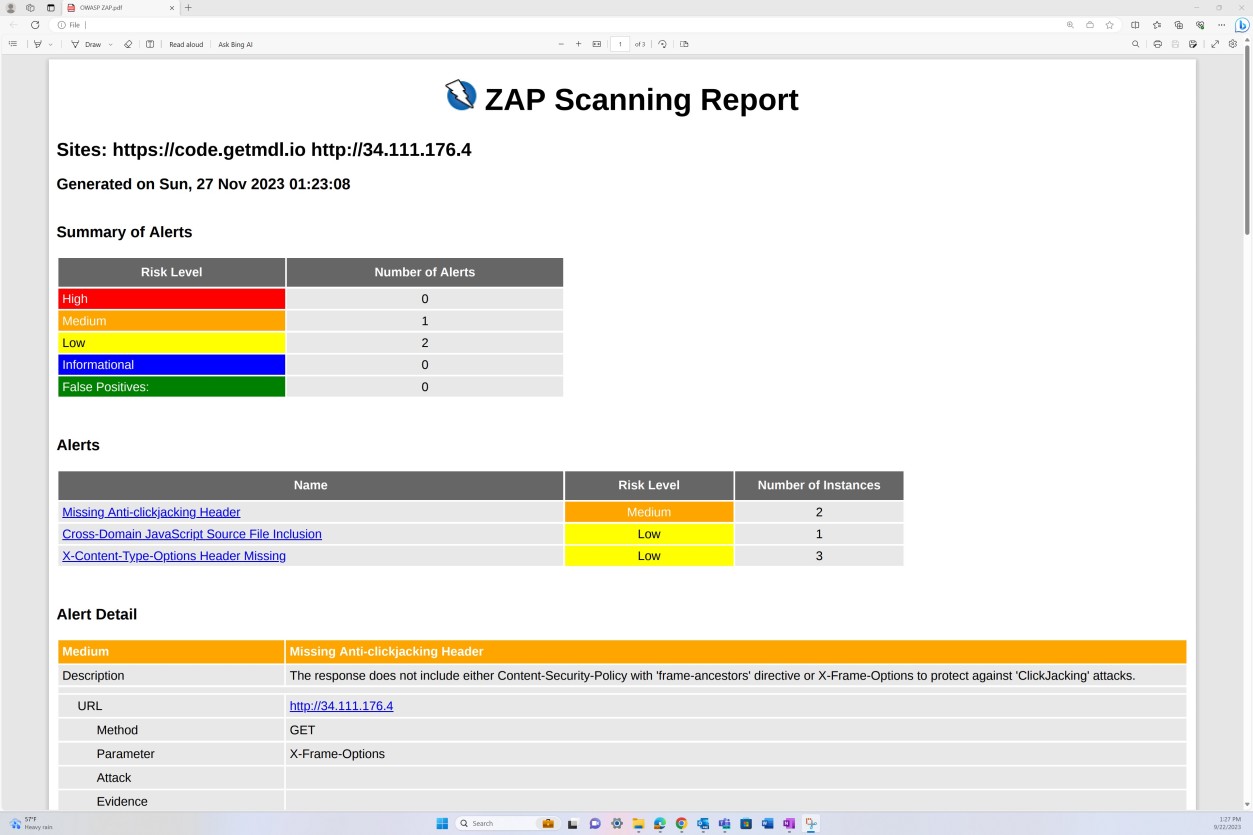
Note: Nmap on its own cannot be utilized to meet this control as the expectation is that a complete vulnerability scan must be provided. The Nmap port discovery is part of the vulnerability management process exemplified below and is complemented by OpenVAS and OWASP ZAP scans against the external infrastructure.
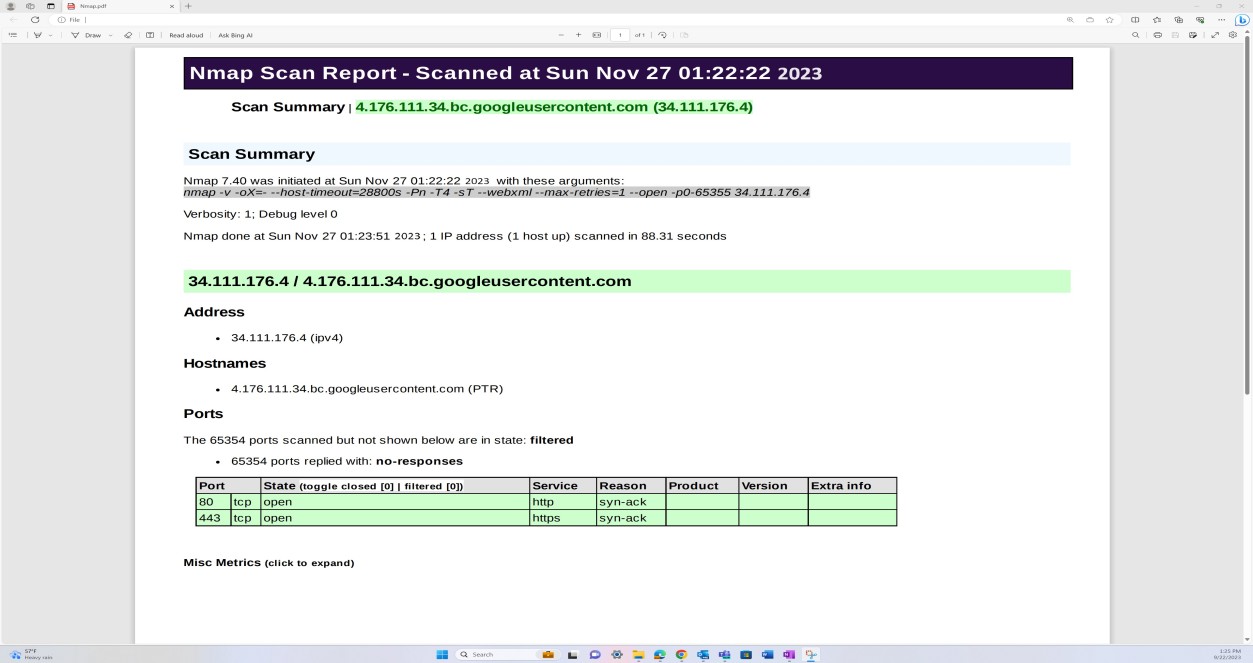
The screenshot shows vulnerability scanning via OpenVAS against the external infrastructure to identify any misconfigurations and outstanding vulnerabilities.
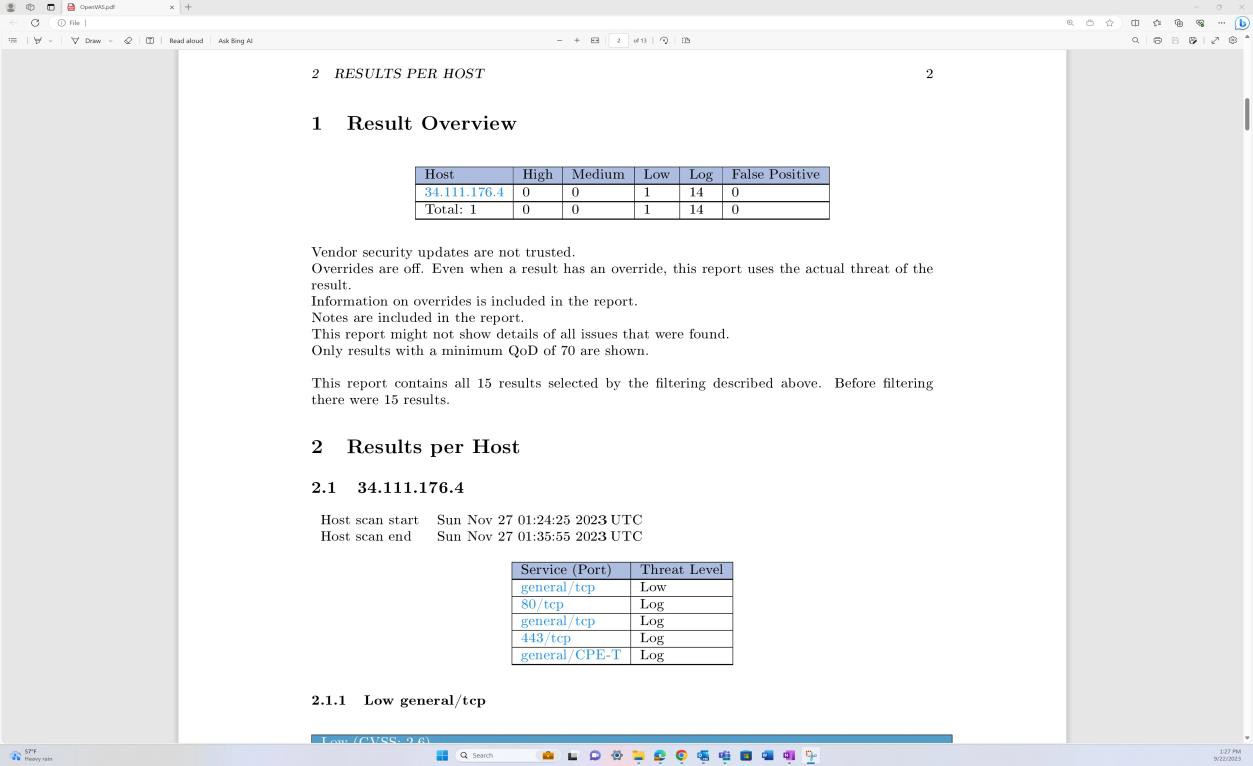
The next screenshot shows the vulnerability scan report from OWASP ZAP demonstrating dynamic application security testing.
Example evidence: vulnerability scanning
The following screenshots from tenable Nessus Essentials vulnerability scan report demonstrate that internal infrastructure scanning is performed.
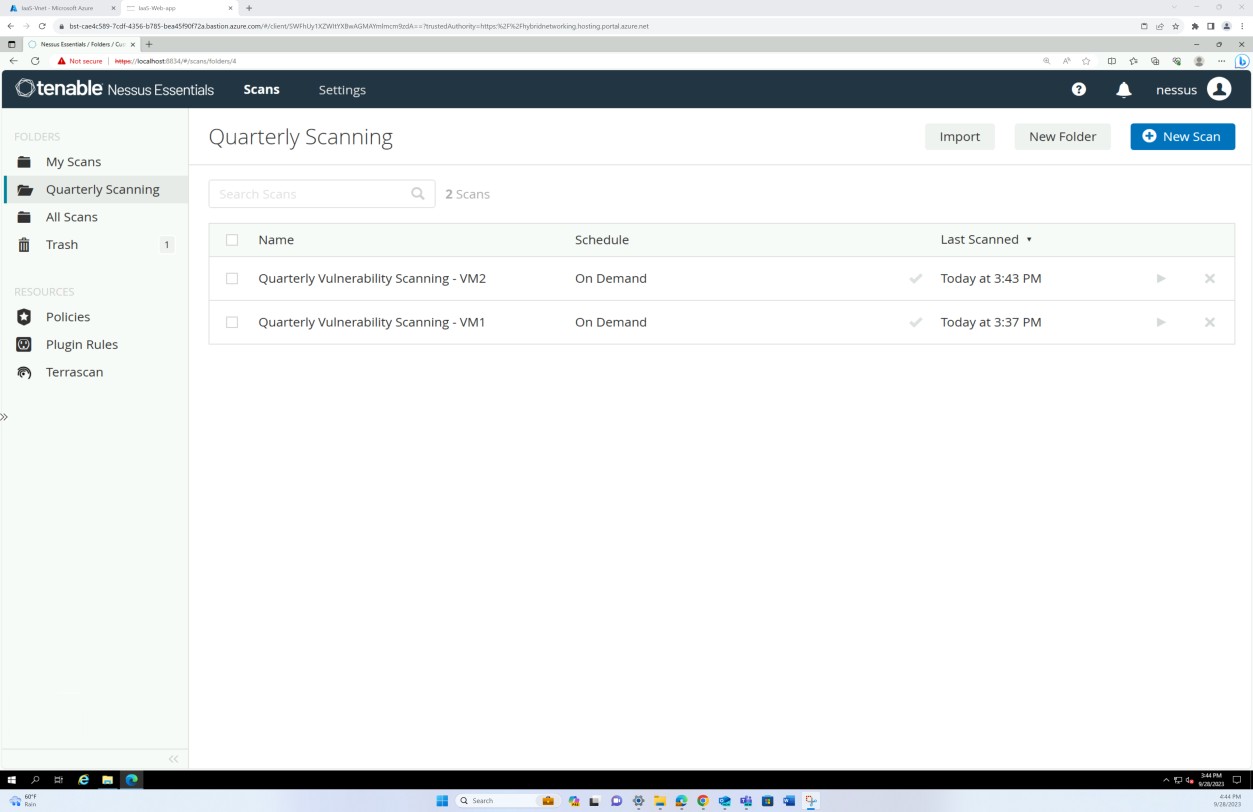
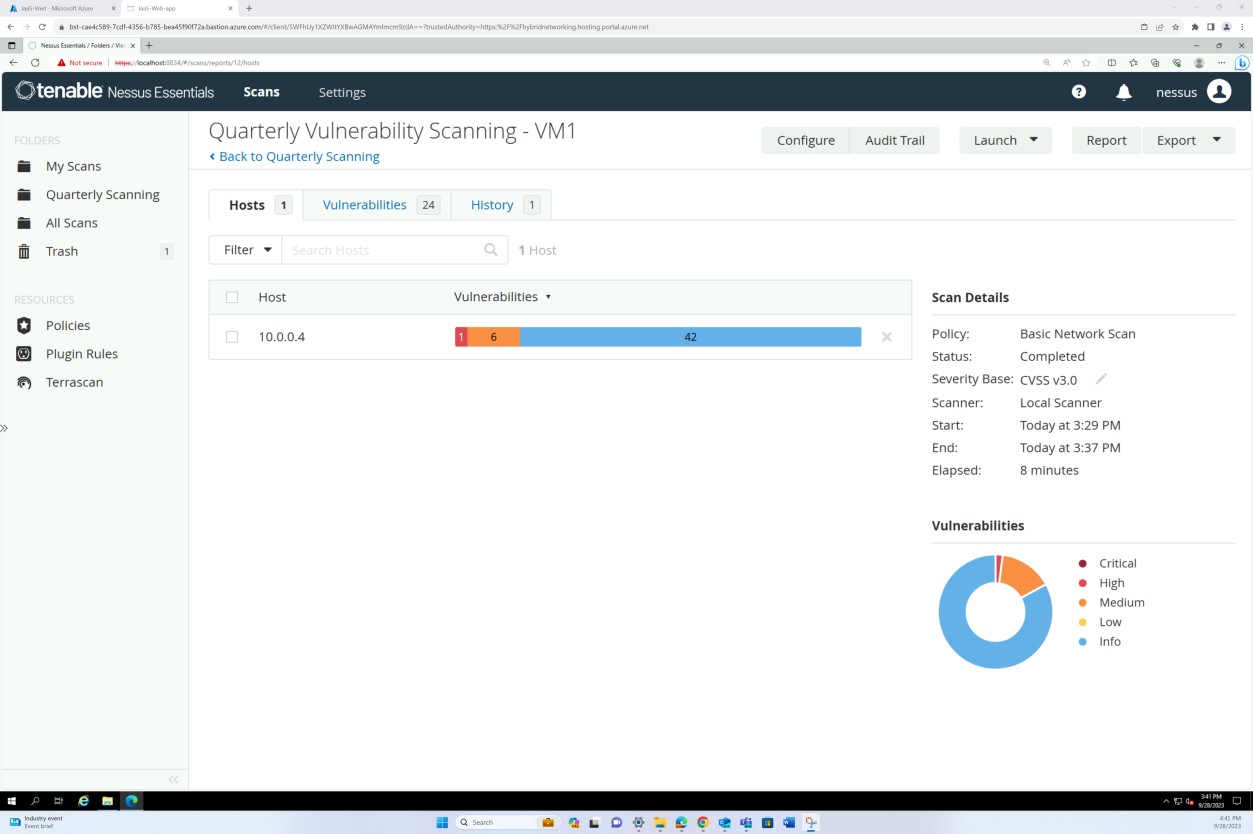
The previous screenshots demonstrate the folders setup for quarterly scans against the host VMs.
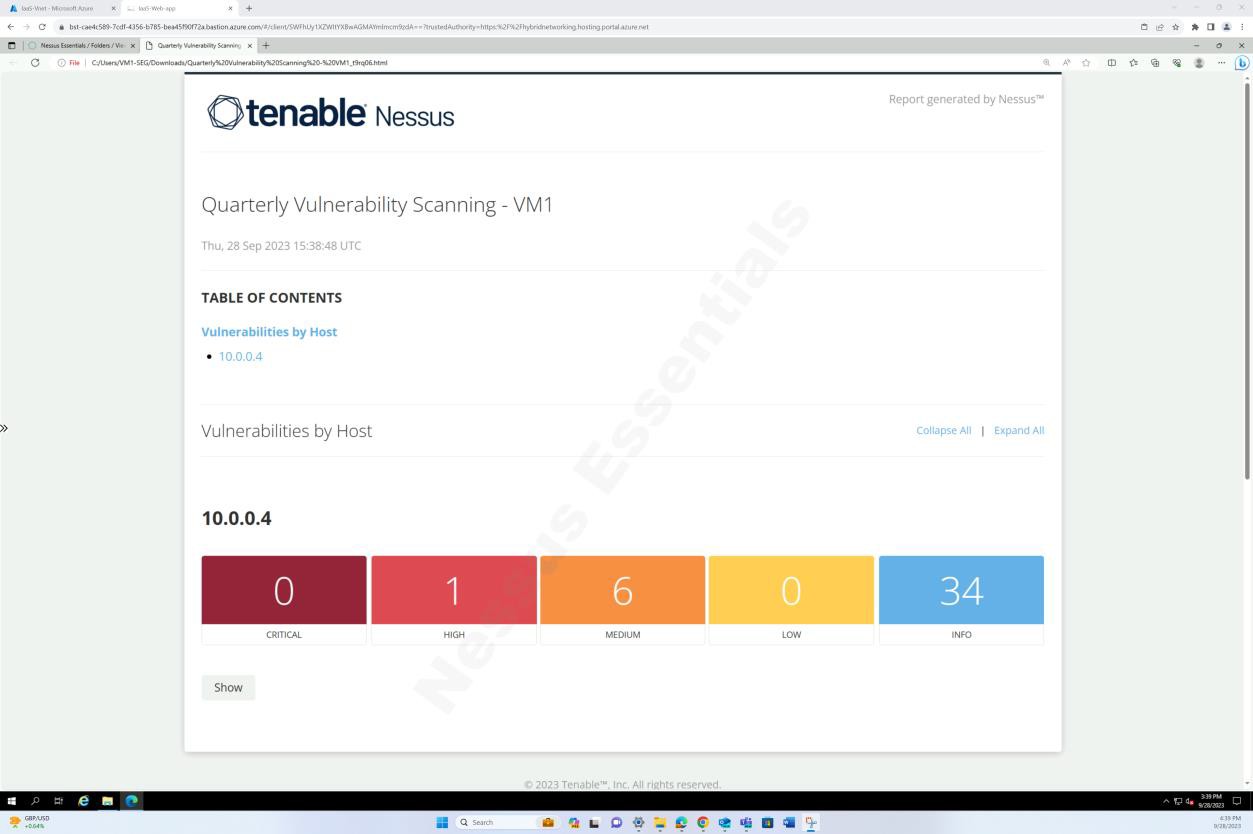
The screenshots above and below show the output of the vulnerability scan report.
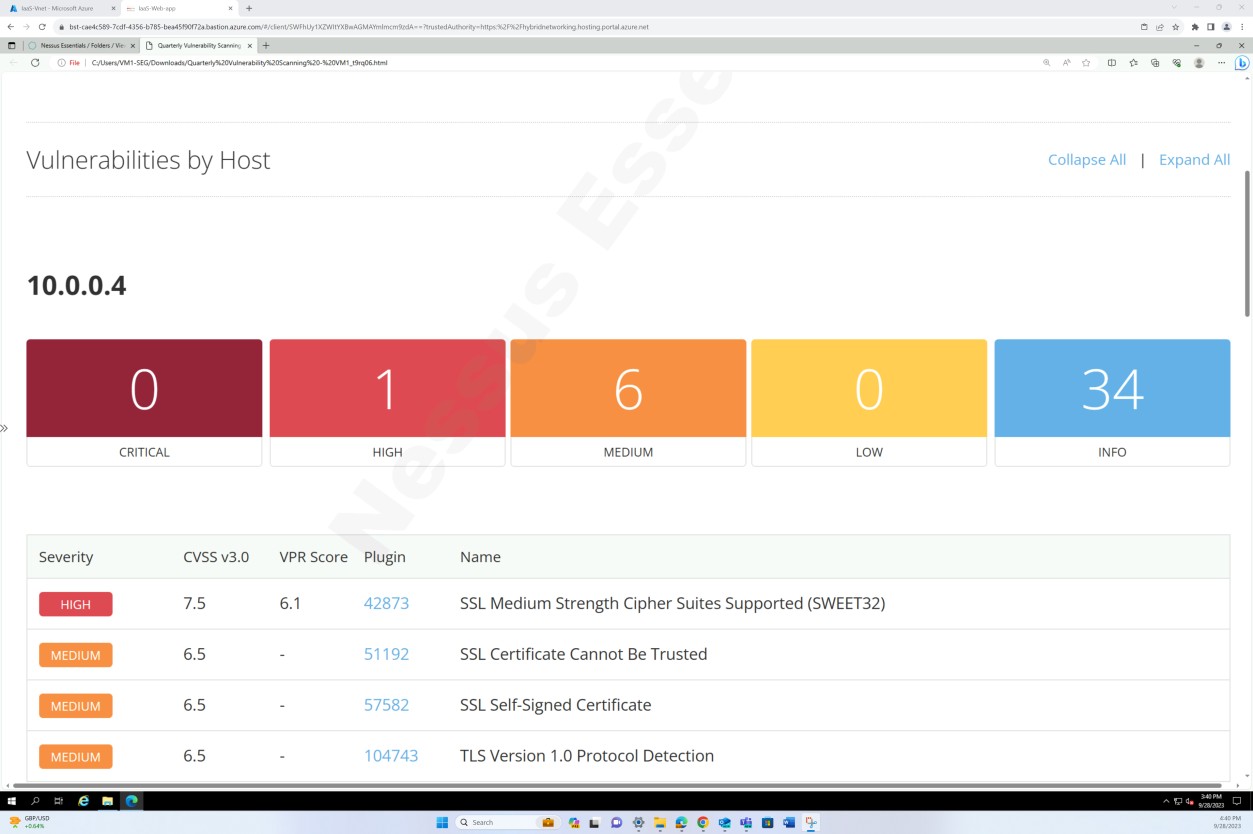
The next screenshot shows the continuation of the report covering all issues found.
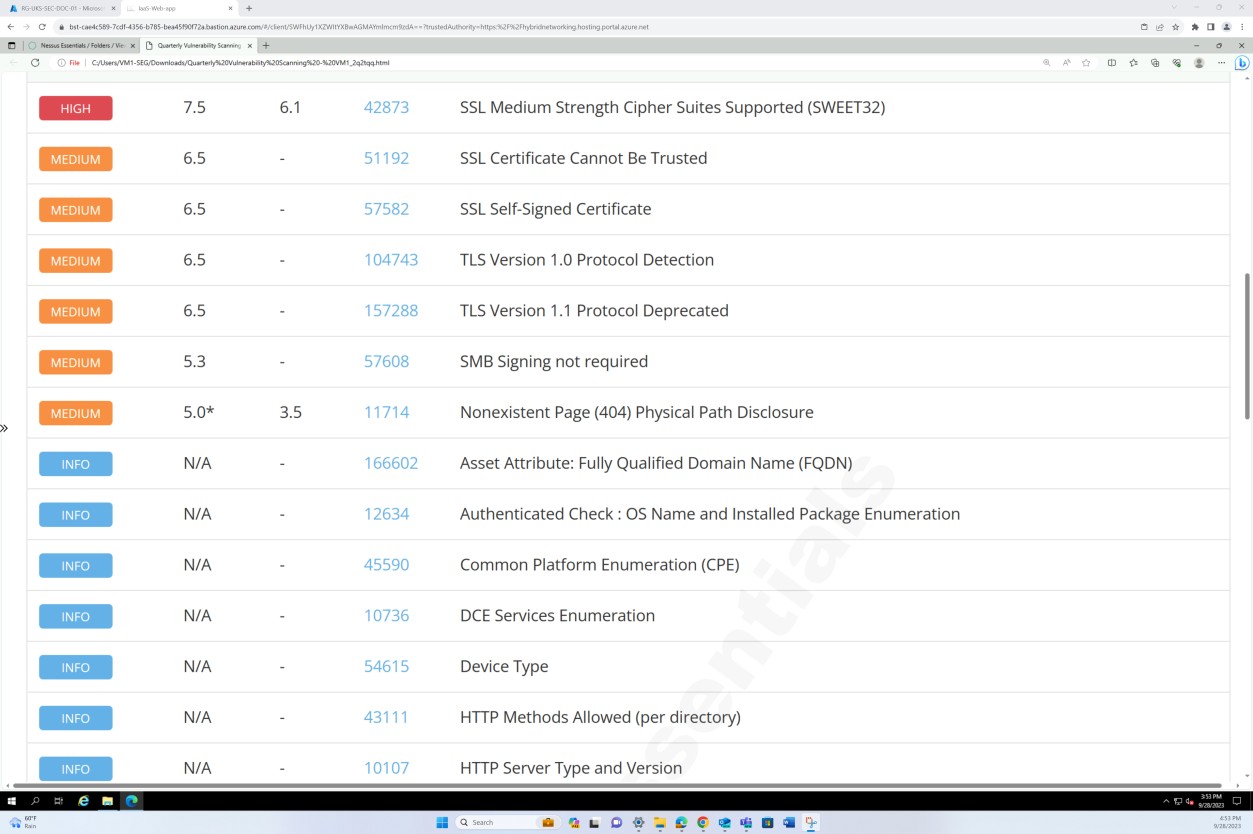
Control No. 7
Please provide rescan evidence demonstrating that:
- Remediation of all vulnerabilities identified in Control 6 are patched in line with the minimal patching window defined in your policy.
Intent: patching
Failure to identify, manage and remediate vulnerabilities and misconfigurations quickly can increase an organization’s risk of a compromise leading to potential data breaches. Correctly identifying and remediating issues is seen as important for an organization’s overall security posture and environment which is in line with best practices of various security frameworks e.g., ISO 27001 and PCI DSS.
The intent of this control is to ensure that the organization provides credible evidence of rescans, demonstrating that all vulnerabilities identified in a Control 6 have been remediated. The remediation must align with the minimal patching window defined in the organization’s patch management policy.
Guidelines: patching
Provide re-scan reports validating that any vulnerabilities identified in control 6 have been remediated in line with the patching windows defined in control 4 .
Example evidence: patching
The next screenshot shows a Nessus scan of the in-scope environment (a single machine in this example named Thor) showing vulnerabilities on the 2nd of August 2023.
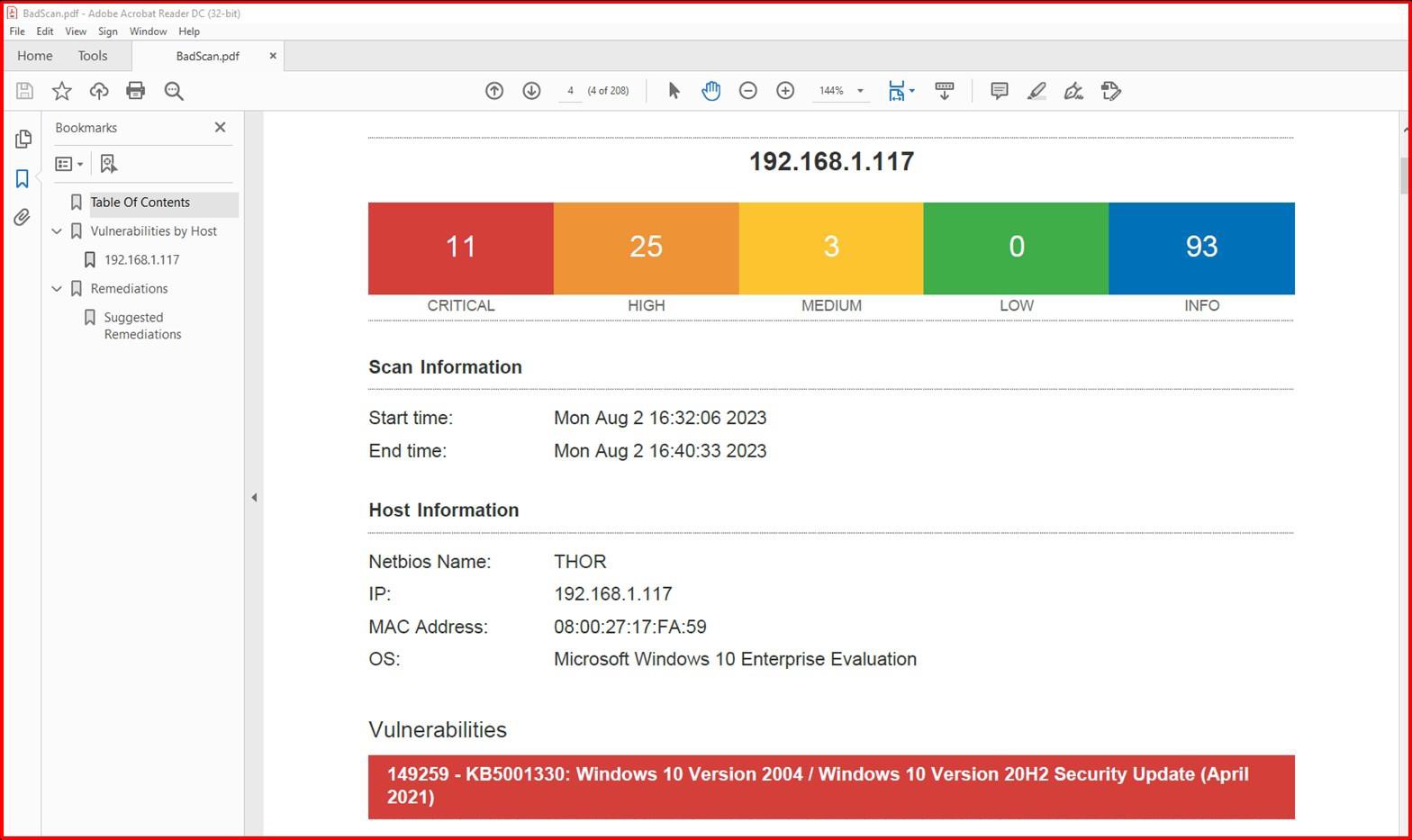
The next screenshot shows that the issues were resolved, 2 days later which is within the patching window defined within the patching policy.
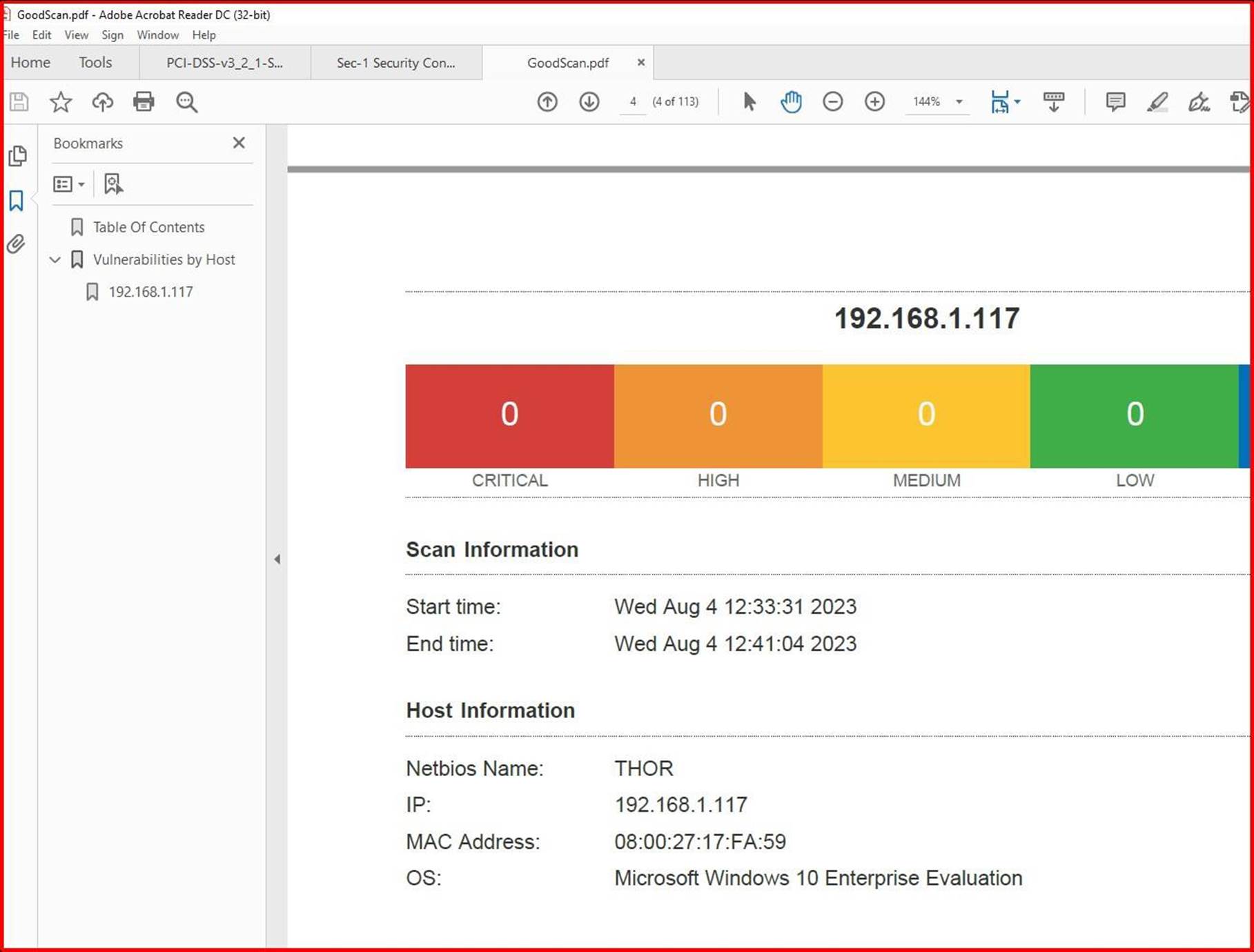
Note: In the previous examples a full screenshot was not used, however ALL ISV submitted
evidence screenshots must be full screenshots showing any URL, logged in user and the system time and date.
Network Security Controls (NSC)
Network security controls are an essential component of cyber security frameworks such as ISO 27001, CIS controls, and NIST Cybersecurity Framework. They help organizations manage risks associated with cyber threats, protect sensitive data from unauthorized access, comply with regulatory requirements, detect, and respond to cyber threats in a timely manner, and ensure business continuity. Effective network security protects organizational assets against a wide range of threats from within or outside the organization.
Control No. 8
Provide demonstrable evidence that:
- Network Security Controls (NSC) are installed on the boundary of the in-scope environment and installed between the perimeter network and internal networks.
AND if Hybrid, On-prem, IaaS also provide evidence that:
- All public access terminates at the perimeter network.
Intent: NSC
This control aims to confirm that Network Security Controls (NSC) are installed at key locations within the organization’s network topology. Specifically, NSCs must be placed on the boundary of the in-scope environment and between the perimeter network and the internal networks. The intent of this control is to confirm that these security mechanisms are correctly situated to maximize their effectiveness in protecting the organization’s digital assets.
Guidelines: NSC
Evidence should be provided to demonstrate that Network Security Controls (NSC) are installed on the boundary and configured between perimeter and internal networks. This can be achieved by providing the screenshots from the configuration settings from the Network Security Controls (NSC) and the scope that it is applied to e.g., a firewall or equivalent technology such as Azure Network Security Groups (NSGs), Azure Front Door etc.
Example evidence: NSC
The next screenshot is from the Web app ‘PaaS-web-app’; the networking blade demonstrates that all the inbound traffic is passing through Azure Front Door, whilst all traffic from the application to other Azure resources are routed and filtered via the Azure NSG through VNET integration.
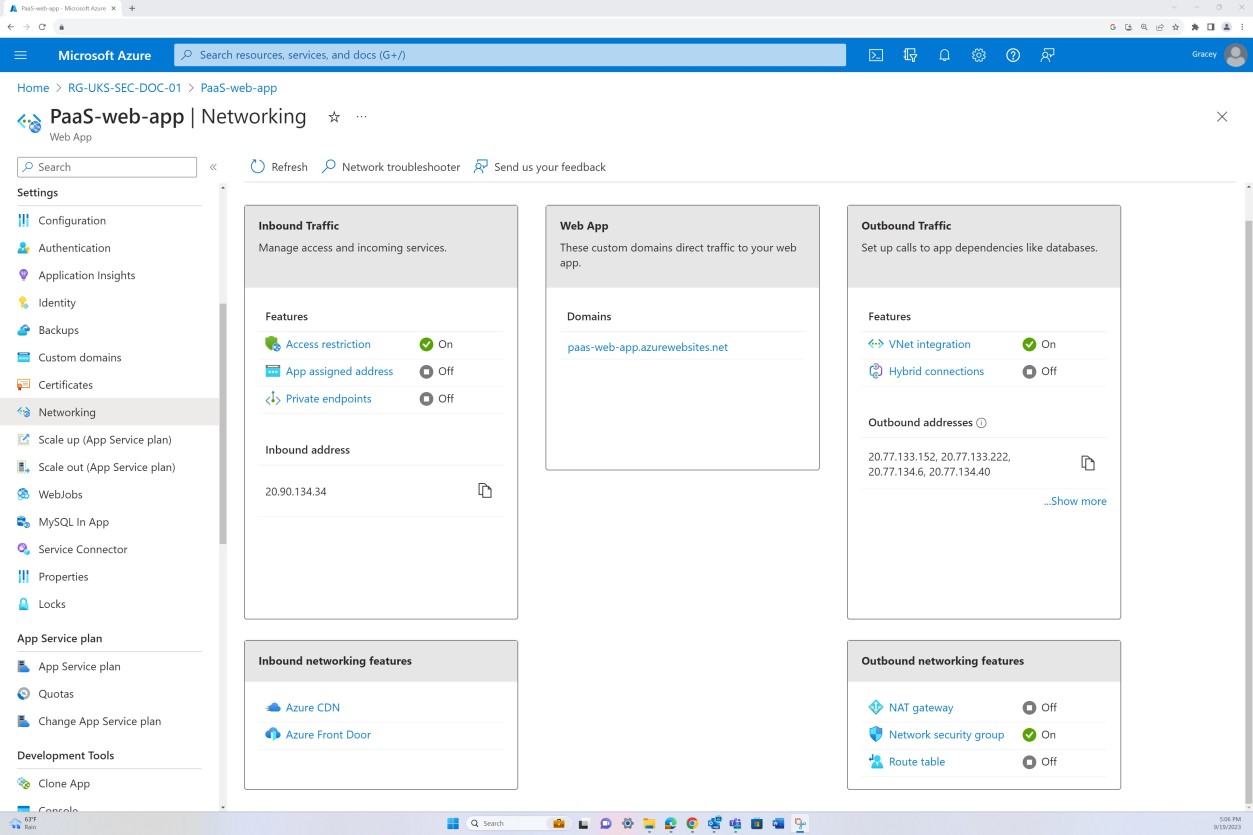
Deny rules within the “Access restrictions” prevent any inbound except from Front Door (FD), traffic is routed through FD before reaching the application.
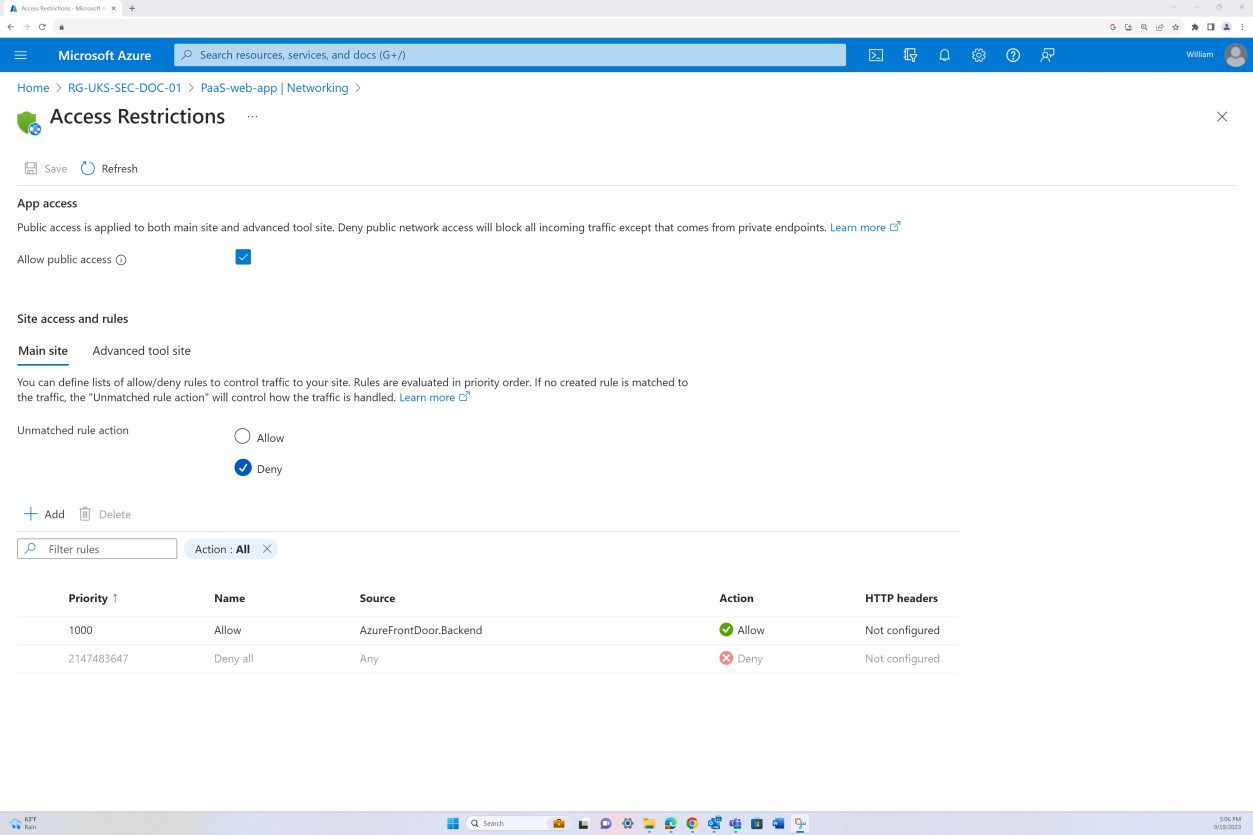
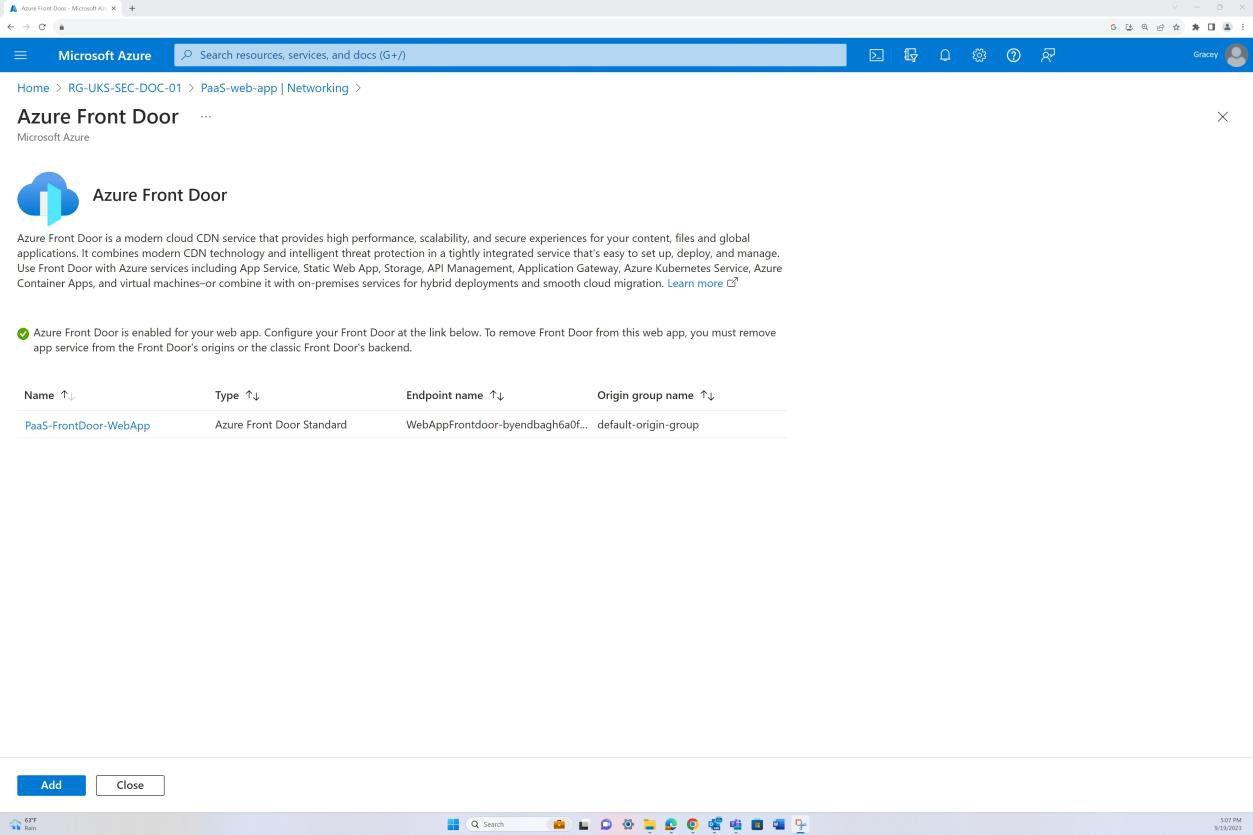
Example evidence: NSC
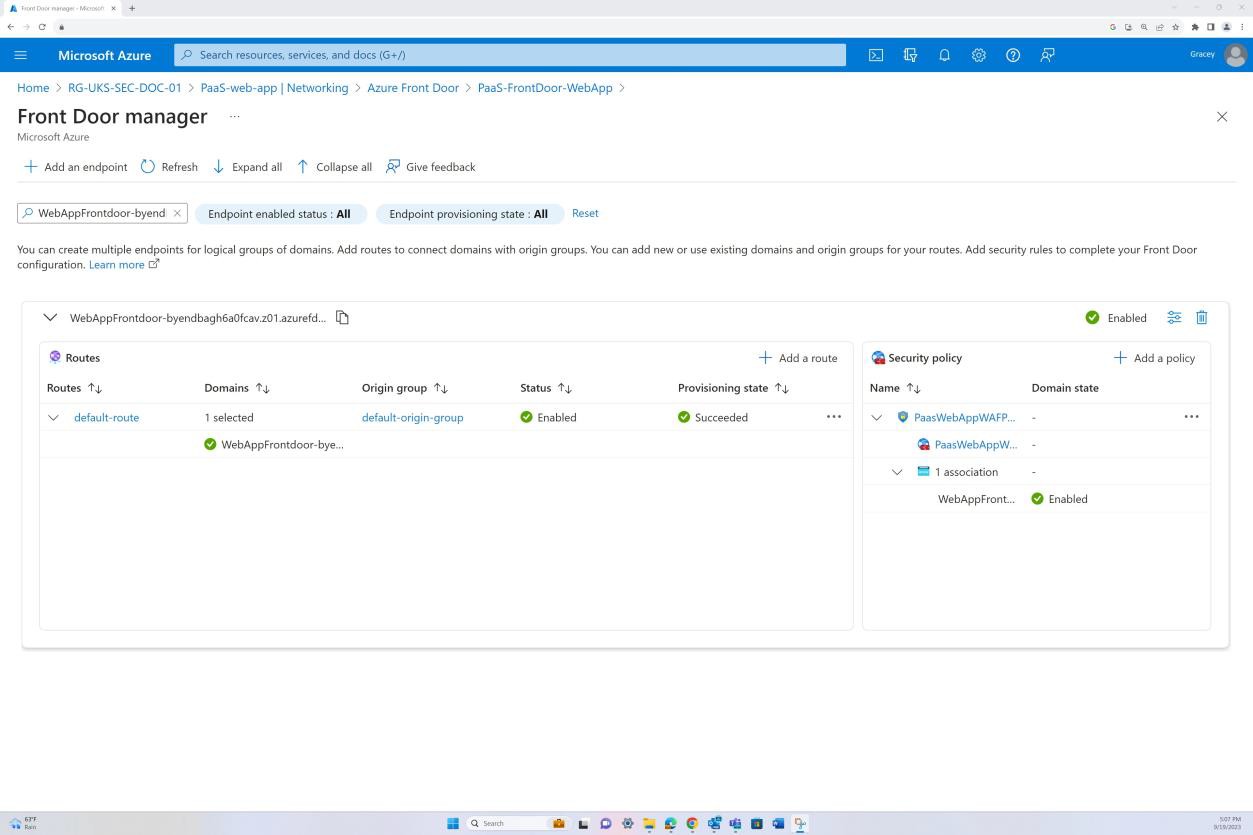
The following screenshot shows Azure Front Door’s default route, and that the traffic is routed through Front Door before reaching the application. WAF policy has also been applied.
Example evidence: NSC
The first screenshot shows an Azure Network Security Group applied at VNET level to filter inbound and outbound traffic. Second screenshot demonstrates that SQL server is not routable over the internet and is integrated via the VNET and through a private link.
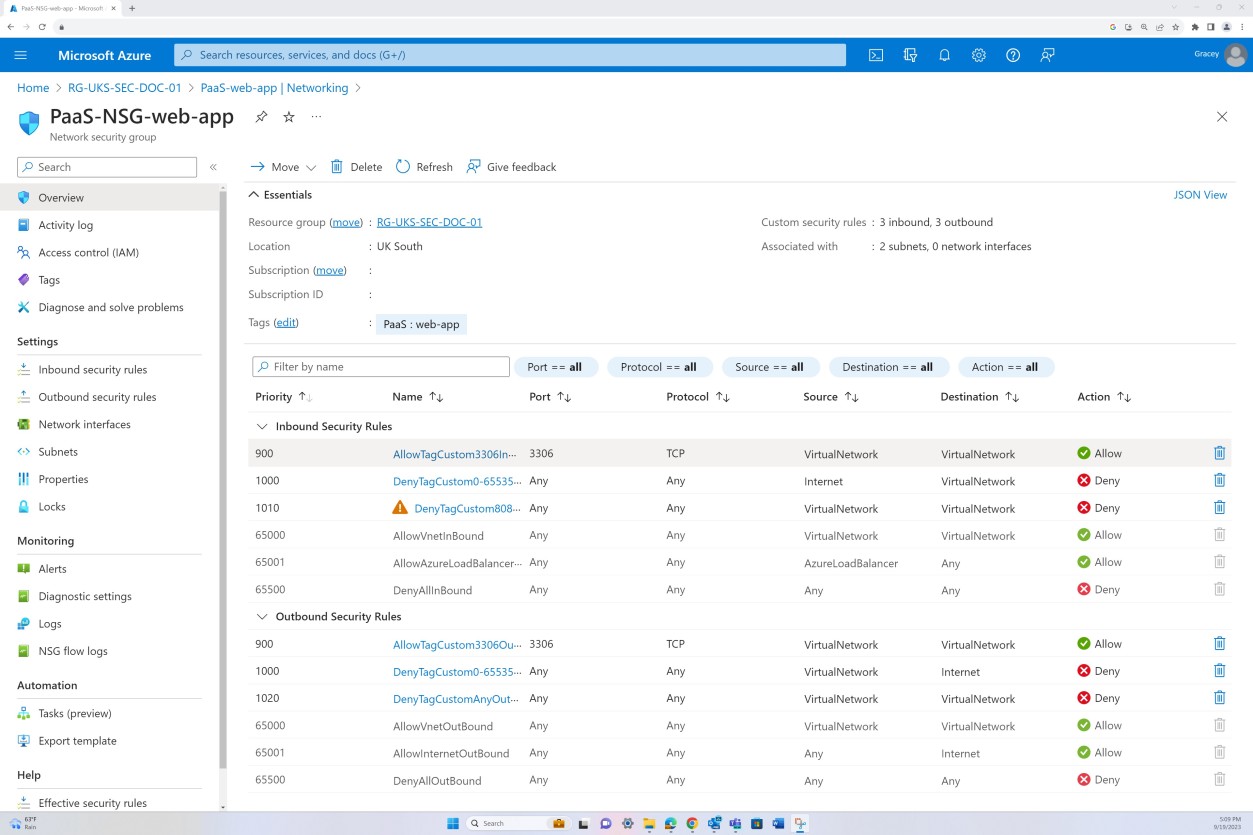
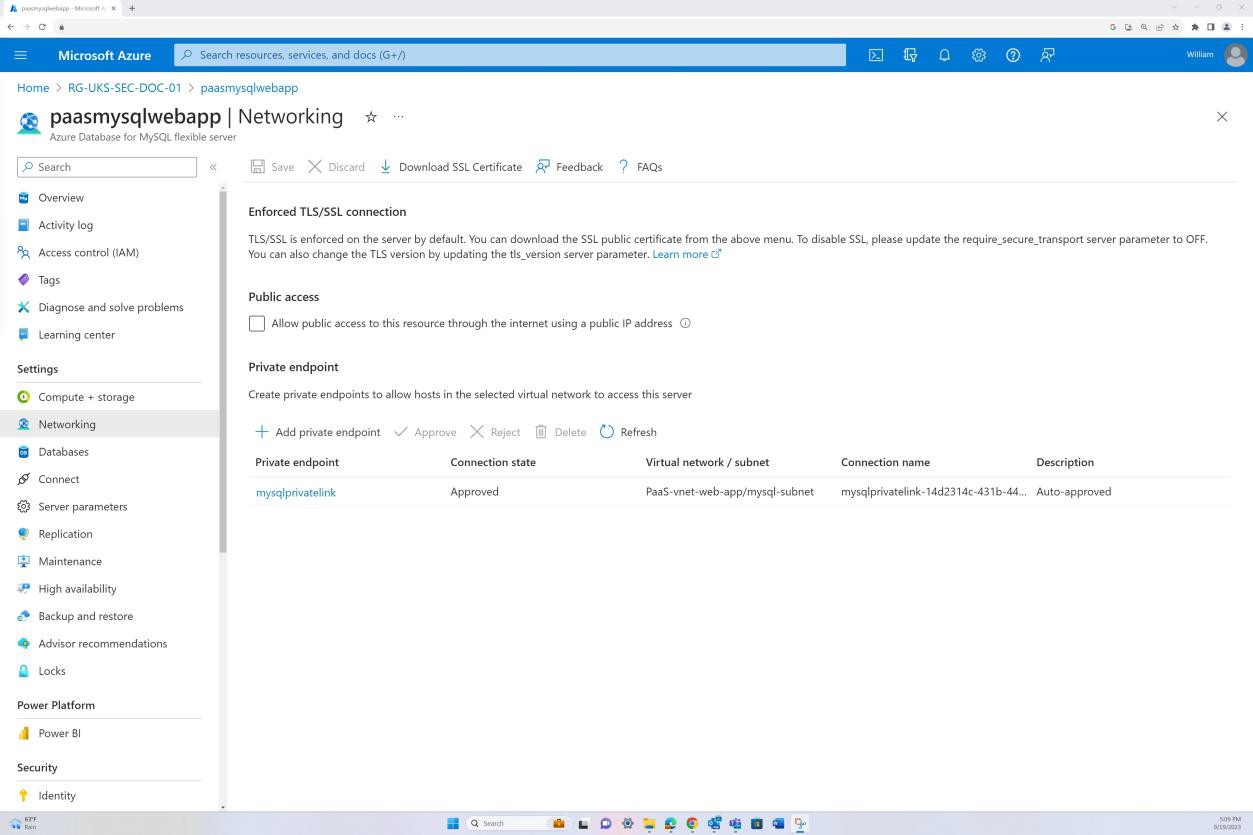
This ensures that internal traffic and communication is filtered by the NSG before reaching the SQL server.
Intent**:** hybrid, on-prem, IaaS
This subpoint is essential for organizations that operate hybrid, on-premises, or Infrastructure-as-a- Service (IaaS) models. It seeks to ensure that all public access terminates at the perimeter network, which is crucial for controlling points of entry into the internal network and reducing potential exposure to external threats. Evidence of compliance may include firewall configurations, network access control lists, or other similar documentation that can substantiate the claim that public access does not extend beyond the perimeter network.
Example evidence: hybrid, on-prem, IaaS
The screenshot demonstrates that SQL server is not routable over the internet, and it is integrated via the VNET and through a private link. This ensures only internal traffic is allowed.
Example evidence: hybrid, on-prem, IaaS
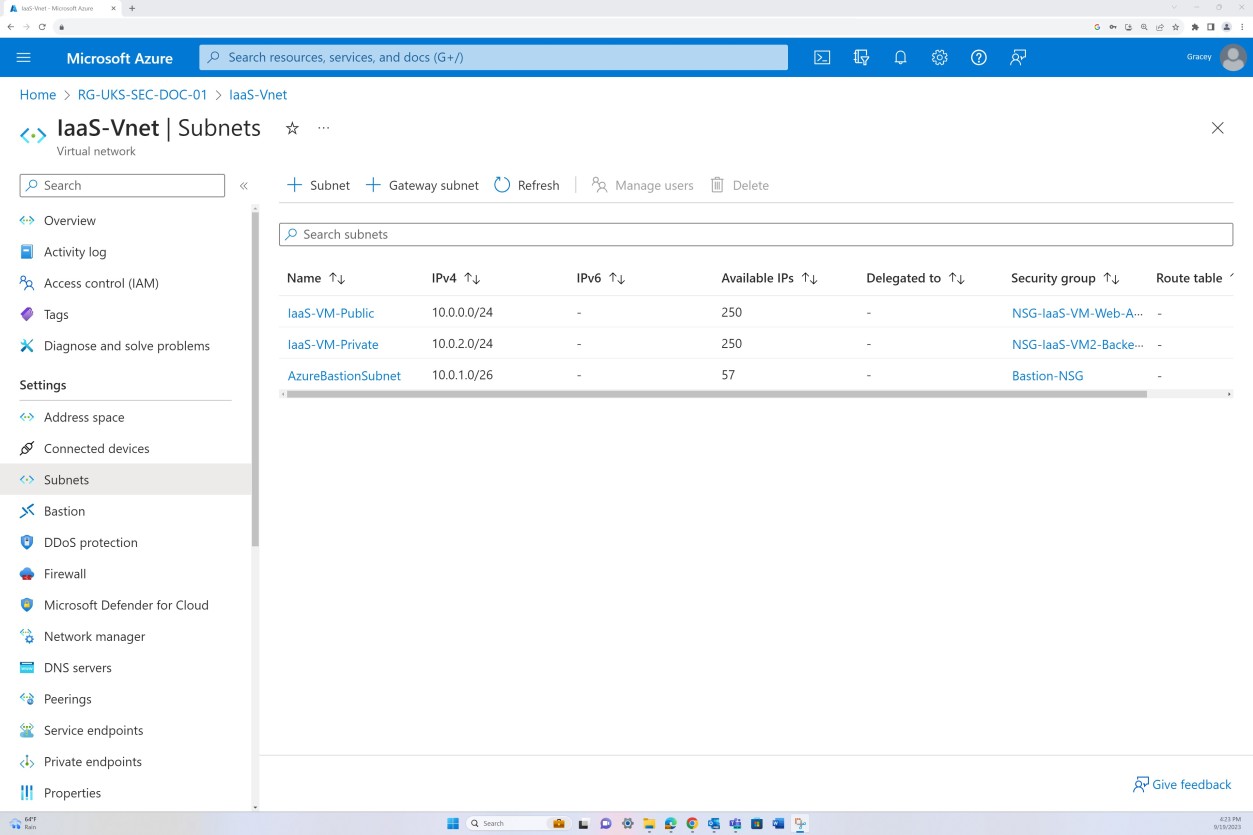
The next screenshots demonstrate that network segmentation is in place within the in-scope virtual network. The VNET as shown following is divided into three subnets, each with an NSG applied.
The public subnet acts as the perimeter network. All public traffic is routed through this subnet and filtered via the NSG with specific rules and only explicitly defined traffic is allowed. The backend consists of the private subnet with no public access. All VM access is permitted only through the Bastion Host which has its own NSG applied at subnet level.
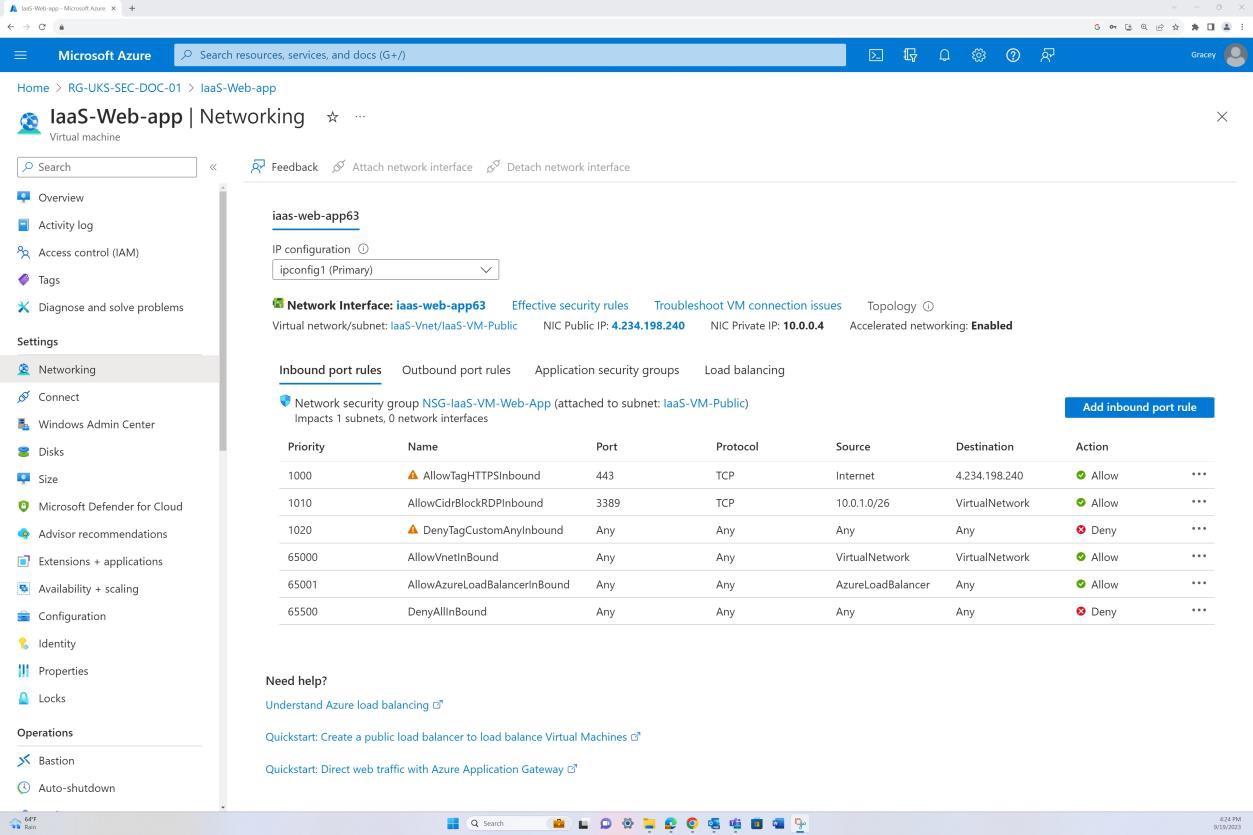
The next screenshot shows that traffic is allowed from the internet to a specific IP address only on port 443. Additionally, RDP is allowed only from the Bastion IP range to the virtual network.
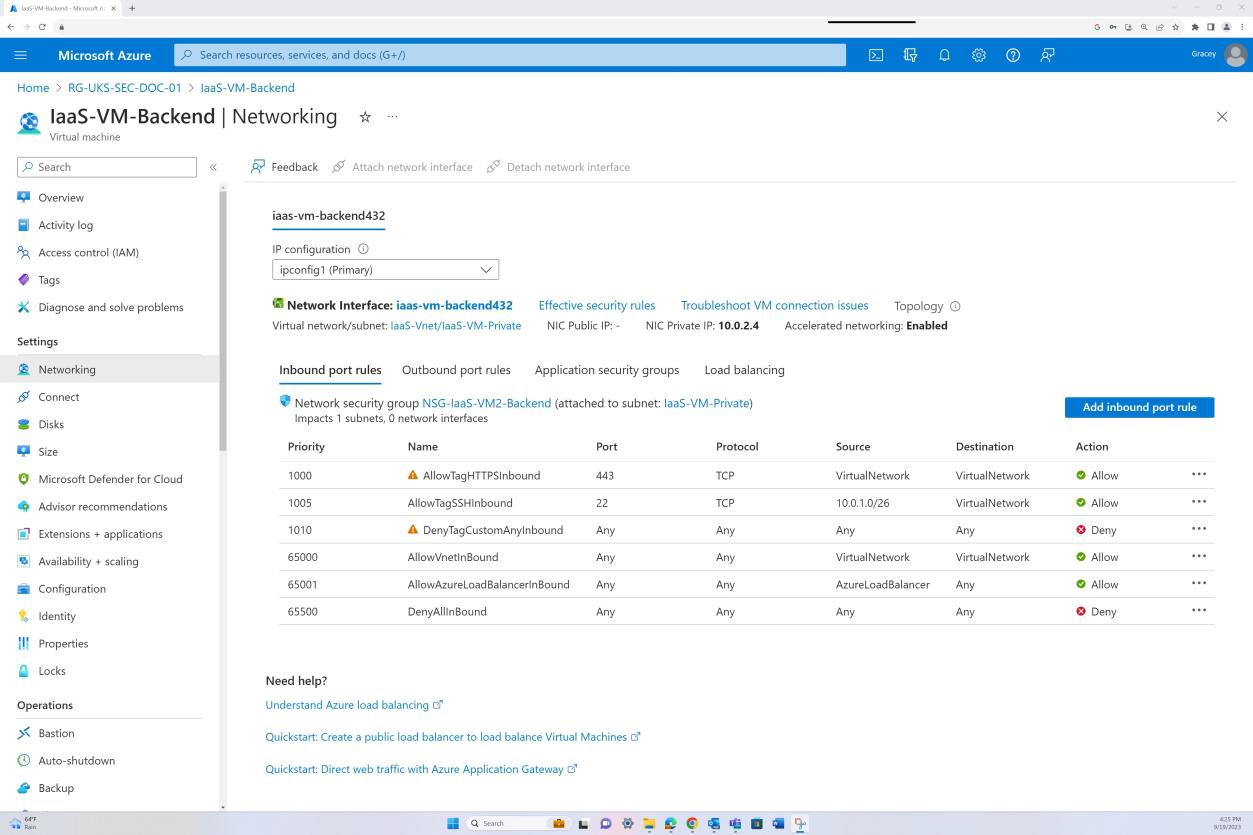
The next screenshot demonstrates that the backend is not routable over the internet (this is due to there being no public IP for the NIC) and that the traffic is only allowed to originate from the Virtual Network and Bastion.
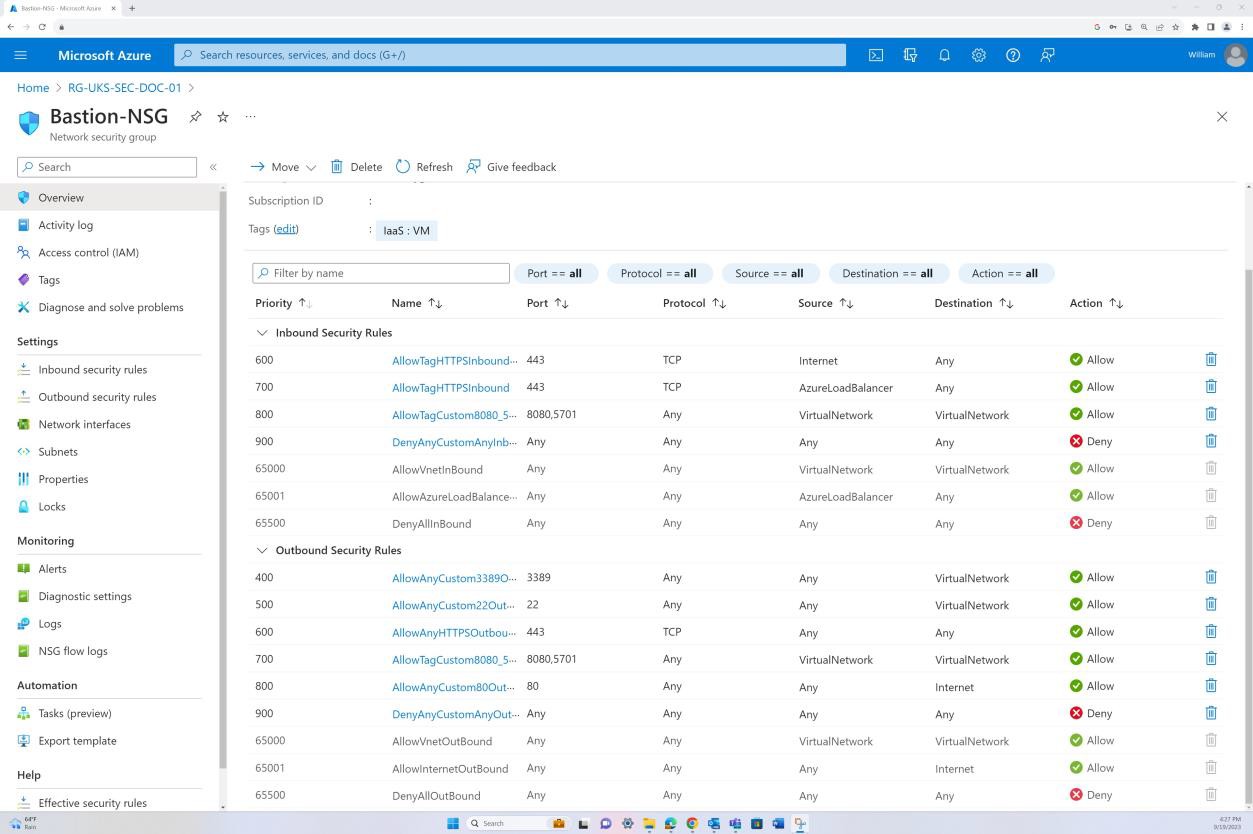
The screenshot demonstrates that Azure Bastion host is used to access the virtual machines for maintenance purposes only.
Control No. 9
All Network Security Controls (NSC) are configured to drop traffic not explicitly defined within the rule base.
Network Security Controls (NSC) rule reviews are carried out at least every 6 months.
Intent: NSC
This subpoint ensures that all Network Security Controls (NSC) in an organization are configured to drop any network traffic that is not explicitly defined within their rule base. The objective is to enforce the principle of least privilege at the network layer by allowing only authorized traffic while blocking all unspecified or potentially malicious traffic.
Guidelines: NSC
Evidence provided for this could be rule configurations which show the inbound rules and where these rules are terminated; either by routing public IP Addresses to the resources, or by providing the NAT (Network Address Translation) of the inbound traffic.
Example evidence: NSC
The screenshot shows the NSG configuration including the default rules set and a custom Deny:All rule to reset all the NSG’s default rules and ensure all traffic is prohibited. In the additional custom rules the Deny:All rule is explicitly defining the traffic that is allowed.
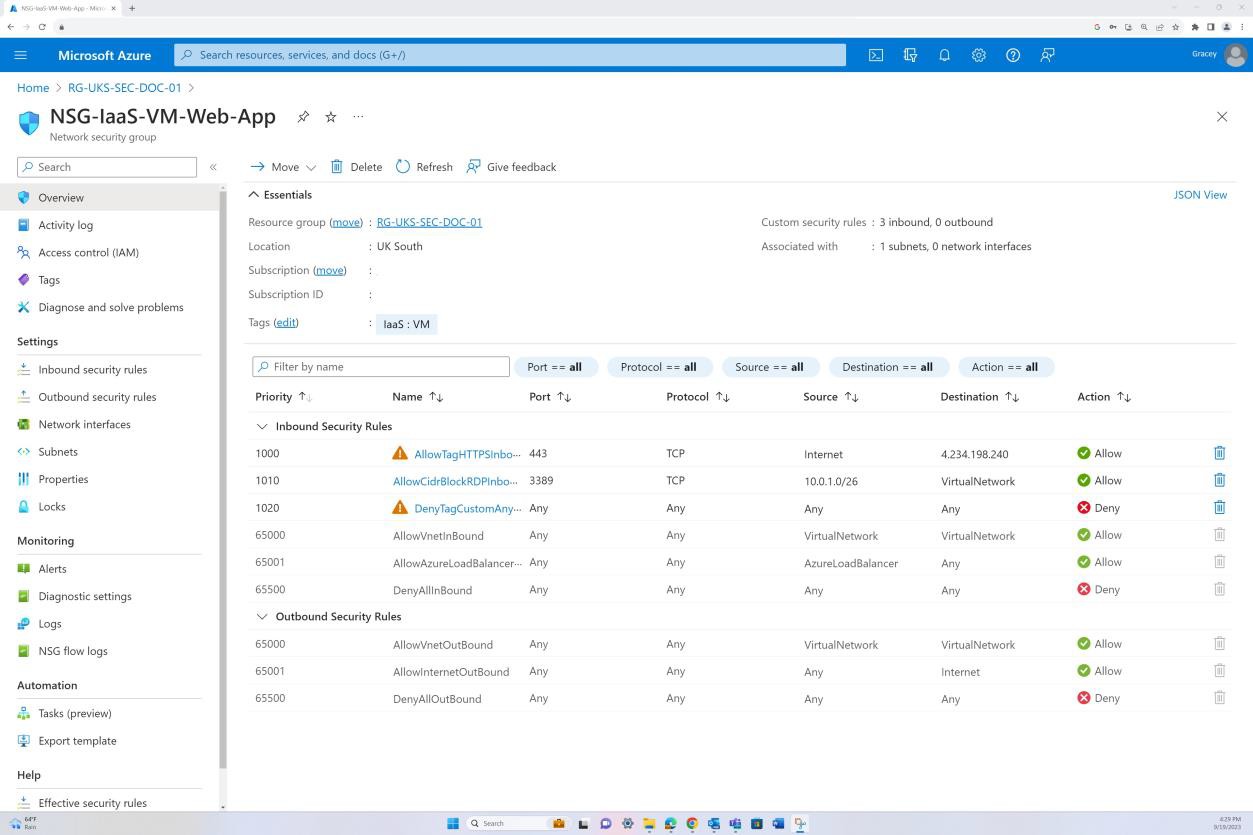
Example evidence: NSC
The following screenshots show that Azure Front Door is deployed, all traffic is routed through the Front Door. A WAF Policy in “Prevention Mode” is applied which filters inbound traffic for potential malicious payloads and blocks it.
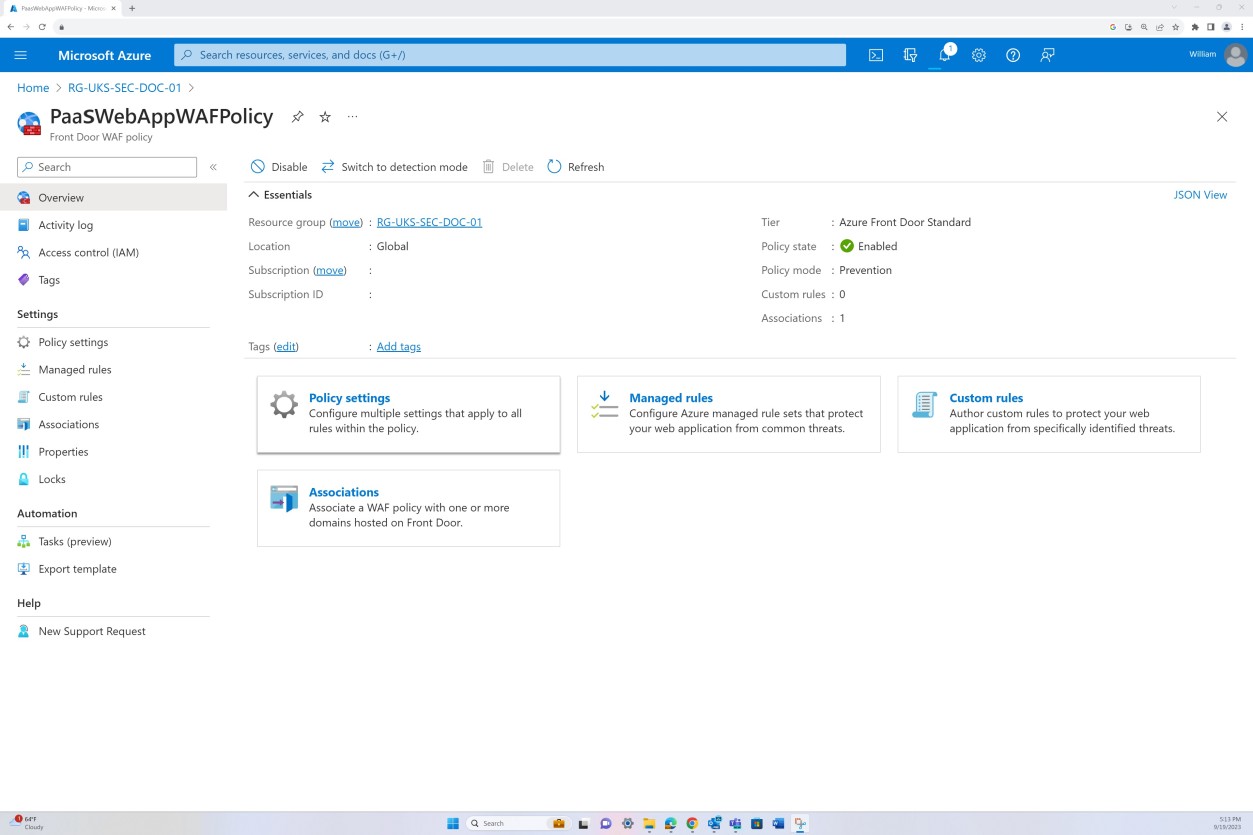
Intent: NSC
Without regular reviews, Network Security Controls (NSC) may become outdated and ineffective, leaving an organization vulnerable to cyber-attacks. This can result in data breaches, theft of sensitive information, and other cyber security incidents. Regular NSC reviews are essential for managing risks, protecting sensitive data, complying with regulatory requirements, detecting, and responding to cyber threats in a timely manner, and ensuring business continuity. This subpoint requires that Network Security Controls (NSC) undergo rule base reviews at least every six months. Regular reviews are crucial for maintaining the effectiveness and relevance of the NSC configurations, especially in dynamically changing network environments.
Guidelines: NSC
Any evidence provided needs to be able to demonstrate that rule review meetings have been occurring. This can be done by sharing meeting minutes of the NSC review and any additional change control evidence that shows any actions taken from the review. Please ensure that dates are present as the certification analyst reviewing your submission would need to see a minimum of two of these meetings review documents (i.e., every six months).
Example evidence: NSC
These screenshots demonstrate that six-monthly firewall reviews exist, and the details are maintained in the Confluence Cloud platform.
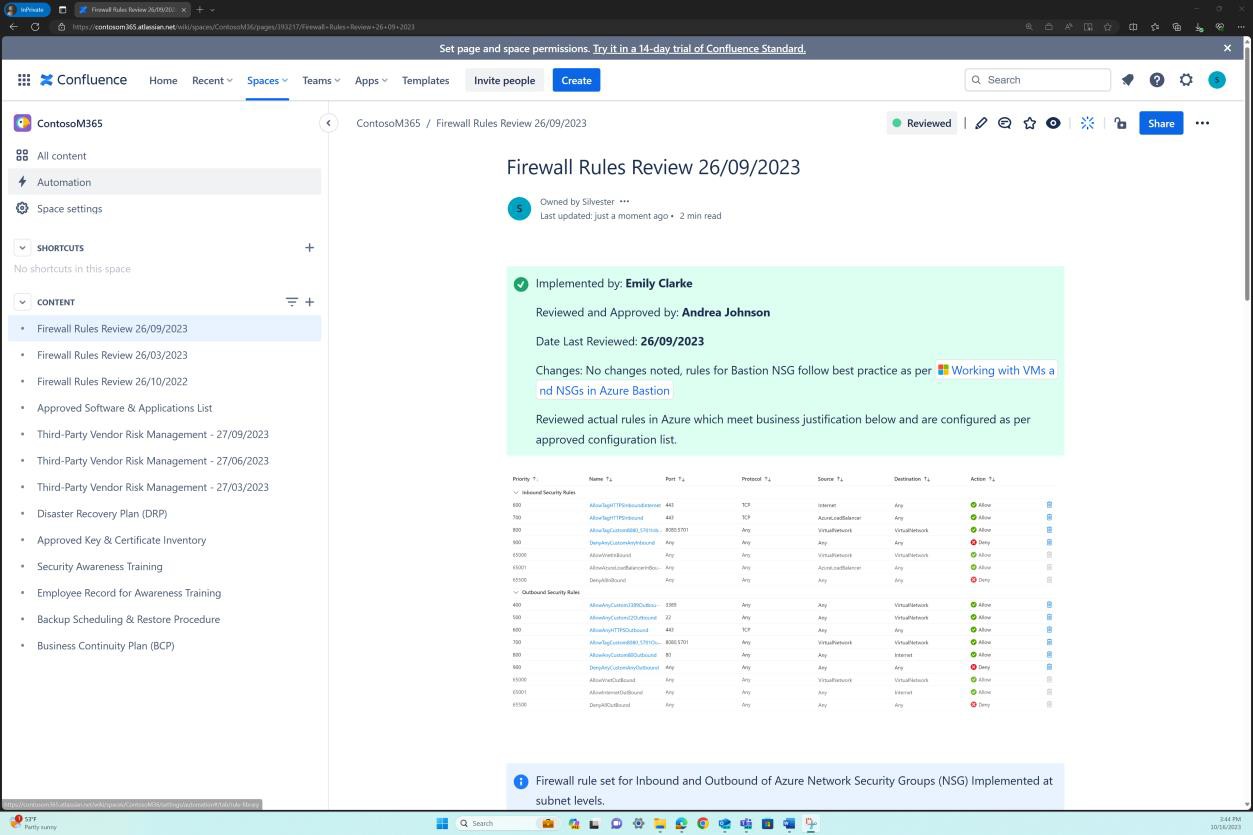
The next screenshot demonstrates that every rule review has a page created in Confluence. The rule review contains an approved ruleset list outlining the traffic allowed, the port number, protocol, etc. along with the business justification.
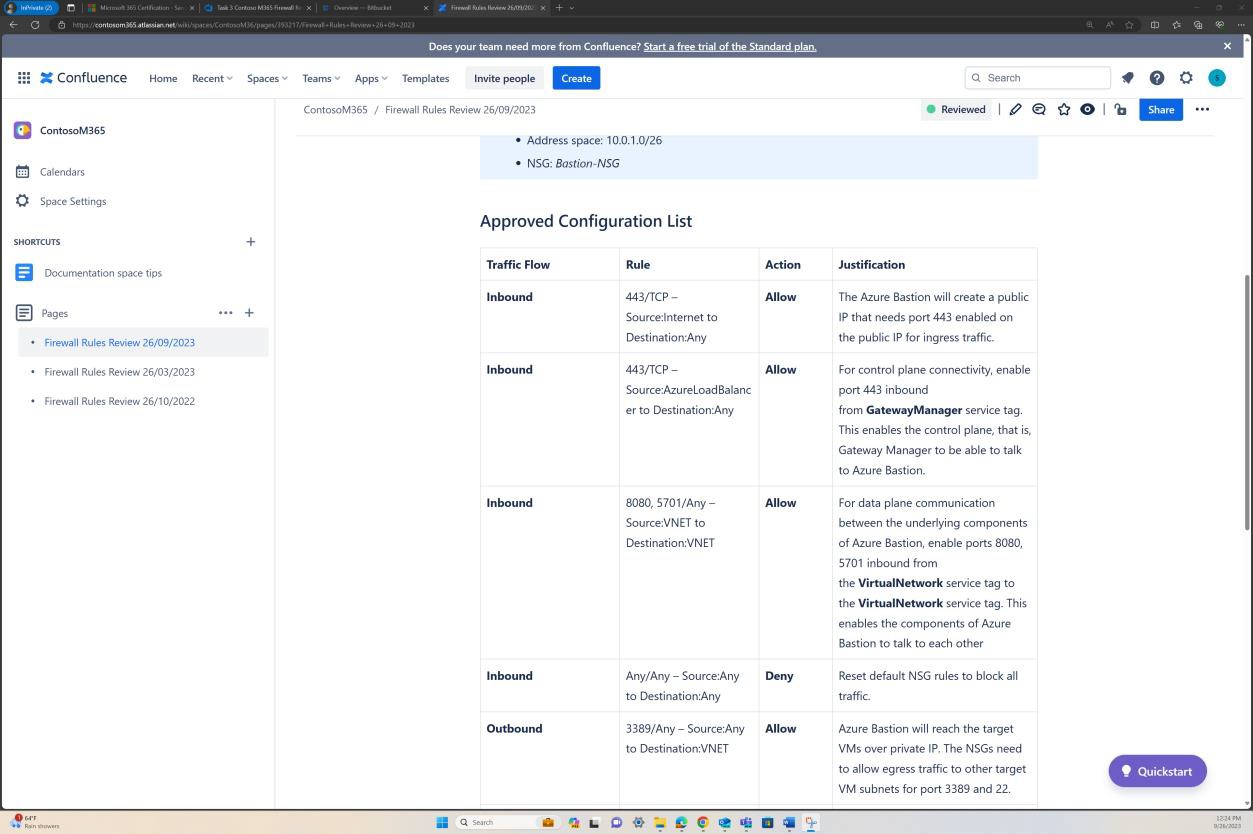
Example evidence: NSC
The next screenshot demonstrates an alternative example of six-months rules review being maintained in DevOps.
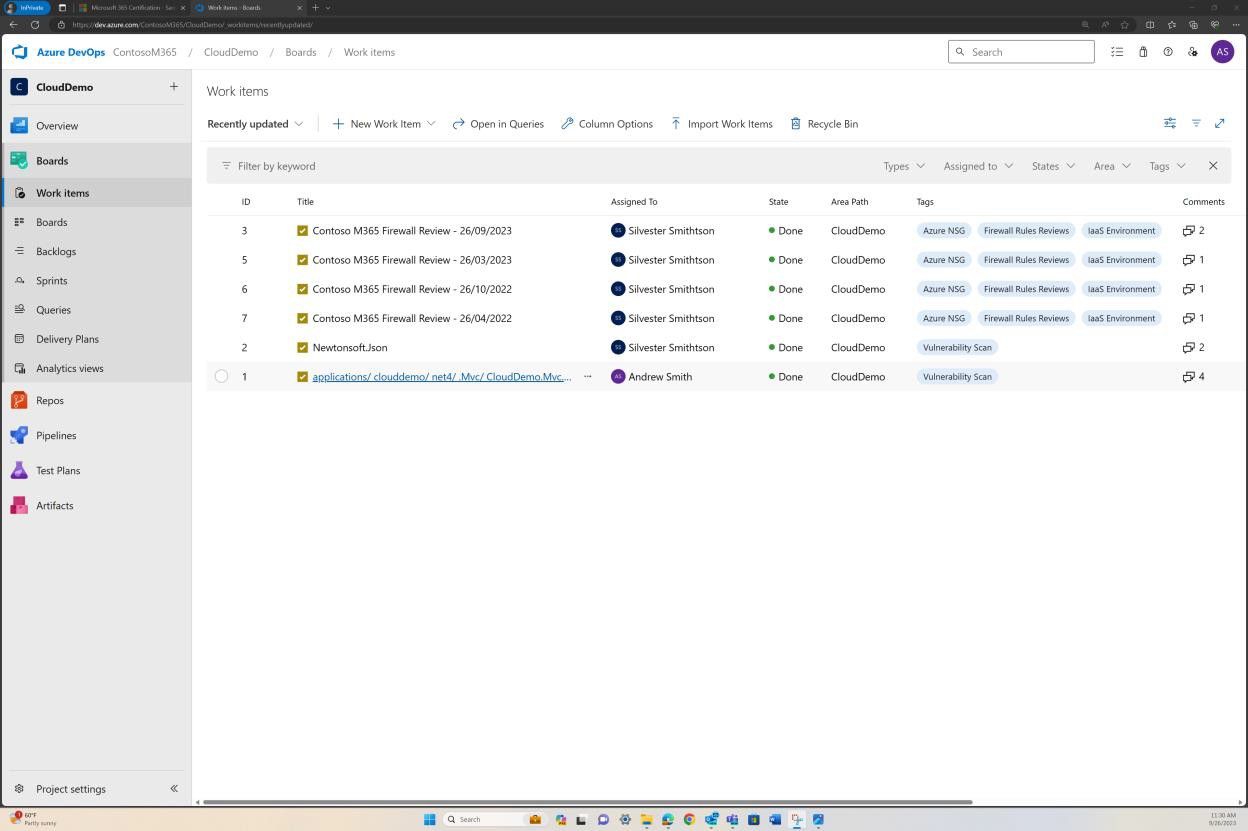
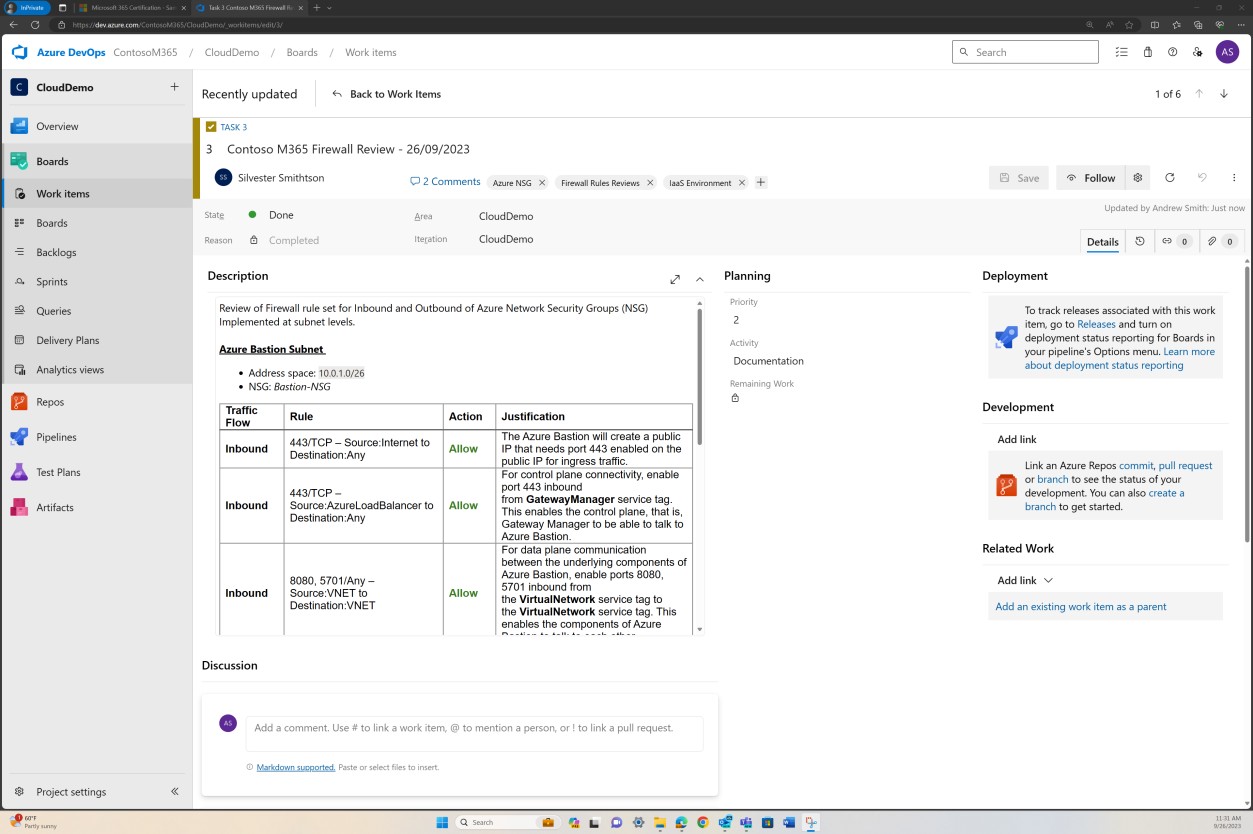
Example evidence: NSC
This screenshot demonstrates an example of a rule review being performed and recorded as a ticket in DevOps.
The previous screenshot shows the established documented rule list alongside the business justification, while the next image demonstrates a snapshot of the rules within the ticket from the actual system.
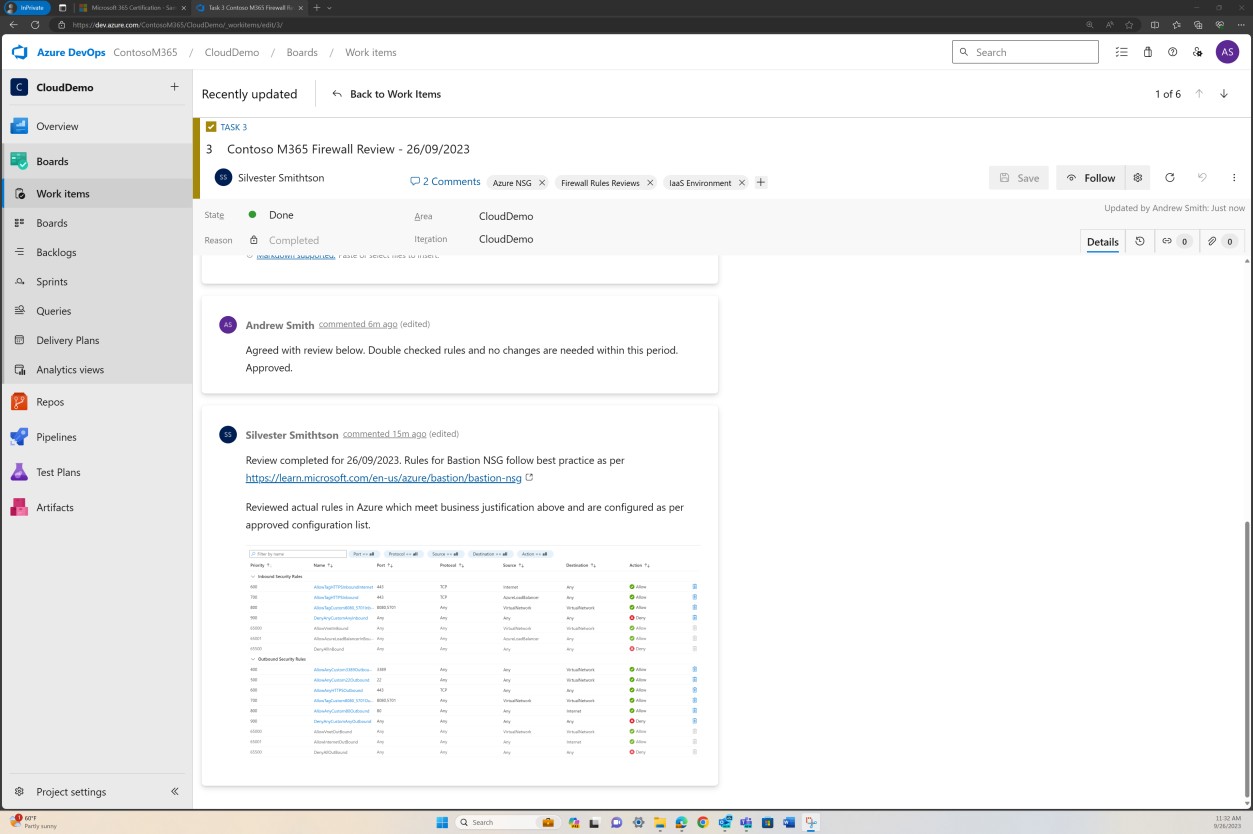
Change control
An established and understood change control process is essential in ensuring that all changes go through a structured process which is repeatable. By ensuring all changes go through a structured process, organizations can ensure changes are effectively managed, peer reviewed and adequately tested before being signed off. This not only helps to minimize the risk of system outages, but also helps to minimize the risk of potential security incidents through improper changes being introduced.
Control No. 10
Please provide evidence demonstrating that:
Any changes introduced to production environments are implemented through documented change requests which contain:
impact of the change.
details of back-out procedures.
testing to be carried out.
review and approval by authorized personnel.
Intent: change control
The intent of this control is to ensure that any requested changes have been carefully considered and documented. This includes assessing the impact of the change on the security of the system/environment, documenting any back-out procedures to aid in the recovery if something goes wrong, and detailing the testing needed to validate the change’s success.
Processes must be implemented which forbid changes to be carried out without proper authorization and sign off. The change needs to be authorized before being implemented and the change needs to be signed off once complete. This ensures that the change requests have been properly reviewed and someone in authority has signed off the change.
Guidelines: change control
Evidence can be provided by sharing screenshots of a sample of change requests demonstrating that the details of impact of the change, back-out procedures, testing are held within the change request.
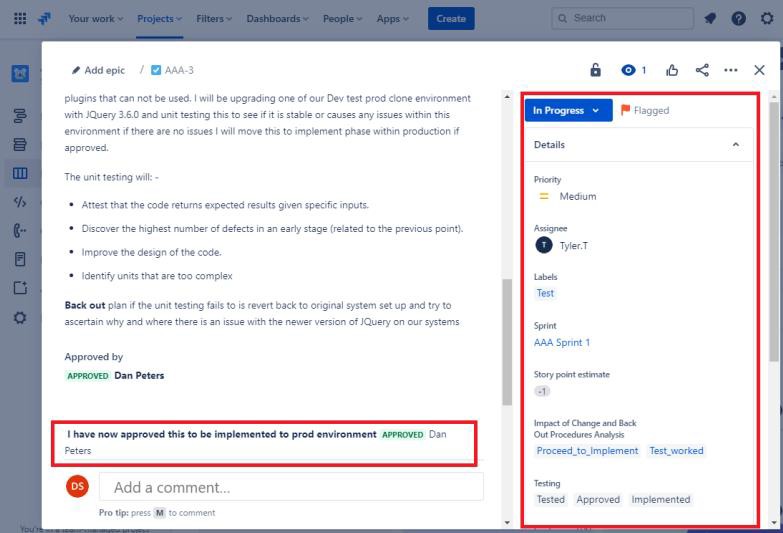
Example evidence: change control
The next screenshot shows a new Cross Site Scripting Vulnerability (XSS) being assigned and document for change request. The tickets below demonstrate the information that has been set or added to the ticket on its journey to being resolved.
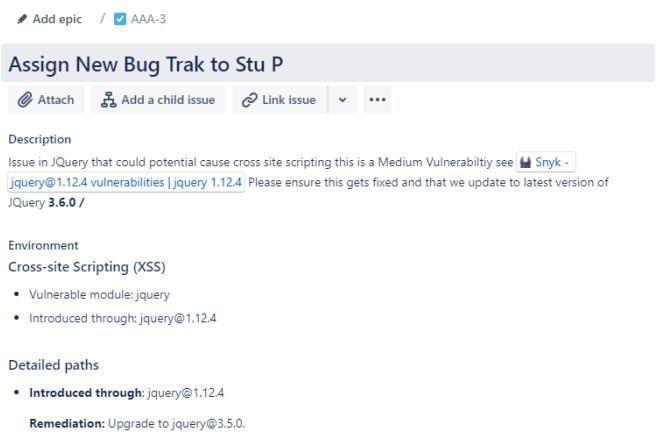
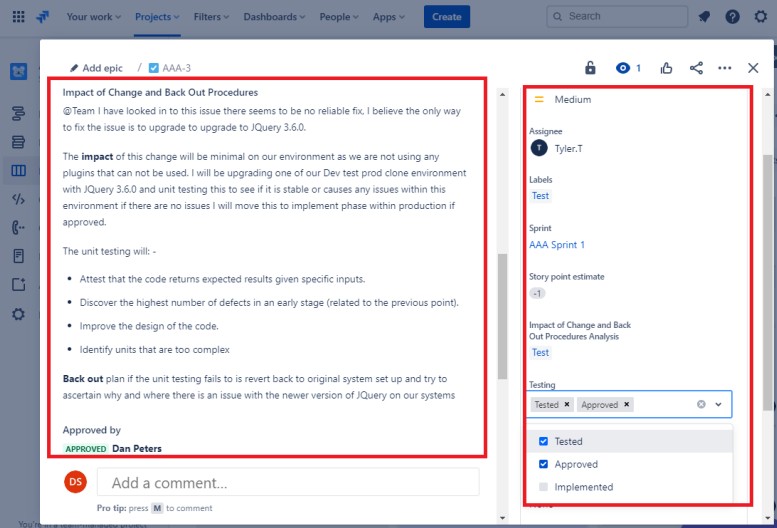
The two tickets following show the impact of the change to the system and the back out procedures which may be needed in the event of an issue. The impact of changes and back out procedures have gone through an approval process and have been approved for testing.
On the following screenshot, the testing of the changes has been approved, and on the right, you see that the changes have now been approved and tested.
Throughout the process note that the person doing the job, the person reporting on it and the person approving the work to be done are different people.
The ticket following shows that the changes have now been approved for implementation to the production environment. The right-hand box shows that the test worked and was successful and that the changes are now been implemented to the Prod Environment.
Example evidence
The next screenshots show an example Jira ticket showing that the change needs to be authorized before being implemented and approved by someone other than the developer/requester. The changes are approved by someone with authority. The right of the screenshot shows that the change has been signed by DP once complete.
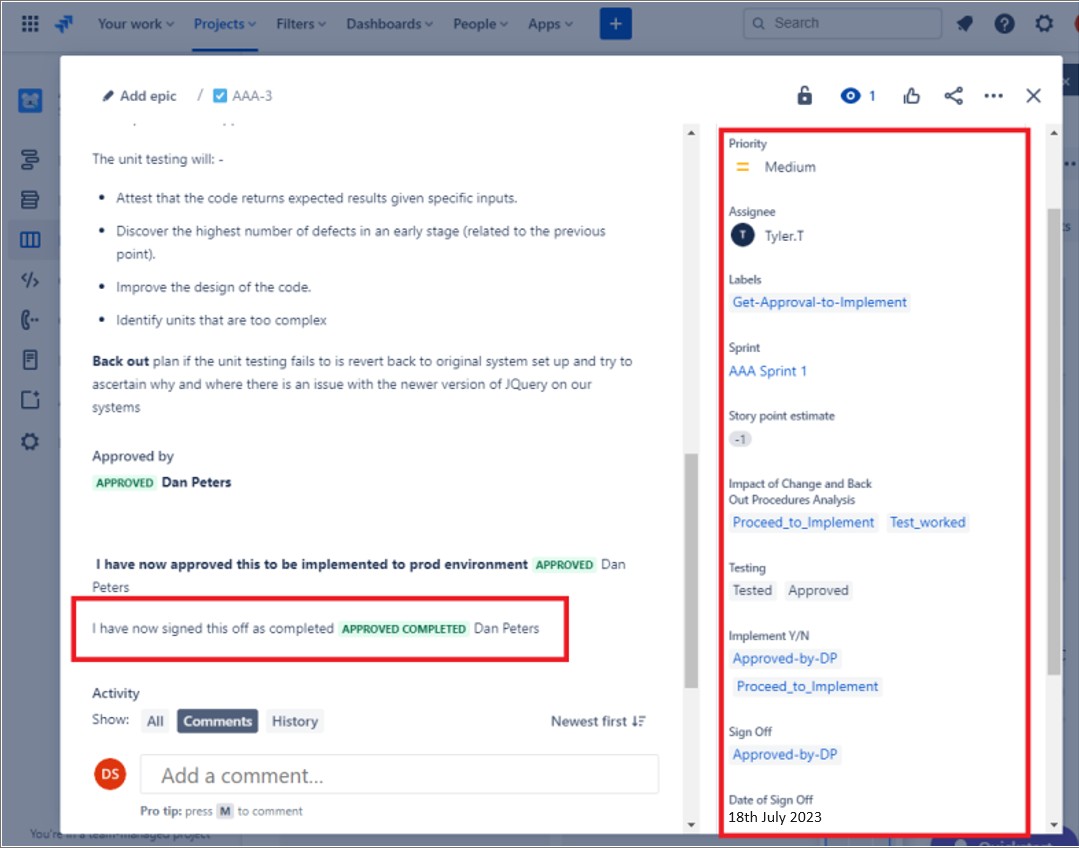
In the ticket following the change has been signed off once complete and shows the job completed and closed.
Please Note: - In these examples a full screenshot was not used, however ALL ISV submitted evidence screenshots must be full screenshots showing any URL, logged in user and the system time and date.
Control No. 11
Please provide evidence that:
Separate environments exist so that:
Development and test/staging environments enforce separation of duties from the production environment.
Separation of duties is enforced via access controls.
Sensitive production data is not in use within the development or test/staging environments.
Intent: separate environments
Most organizations’ development/test environments are not configured to the same vigor as the production environments and are therefore less secure. Additionally, testing should not be carried out within the production environment as this can introduce security issues or can be detrimental to service delivery for customers. By maintaining separate environments which enforce a separation of duties, organizations can ensure changes are being applied to the correct environments, thereby, reducing the risk of errors by implementing changes to production environments when it was intended for the development/test environment.
The access controls should be configured such that personnel responsible for development and testing do not have unnecessary access to the production environment, and vice versa. This minimizes the potential for unauthorized changes or data exposure.
Using production data in development/test environments can increase the risk of a compromise and expose the organization to data breaches or unauthorized access. The intent requires that any data used for development or testing should be sanitized, anonymized, or generated specifically for that purpose.
Guidelines: separate environments
Screenshots could be provided which demonstrate different environments being used for development/test environments and production environments. Typically, you would have different people/teams with access to each environment, or where this is not possible, the environments would utilize different authorization services to ensure users cannot mistakenly log into the wrong environment to apply changes.
Example evidence: separate environments
The next screenshots demonstrate for that environments for development/testing are separated from production, this is achieved via Resource Groups in Azure, which is a way to logical group resources into a container. Other ways to achieve the separation could be different Azure Subscriptions, Networking and Subnetting etc.
The following screenshot shows the development environment and the resources within this resource group.
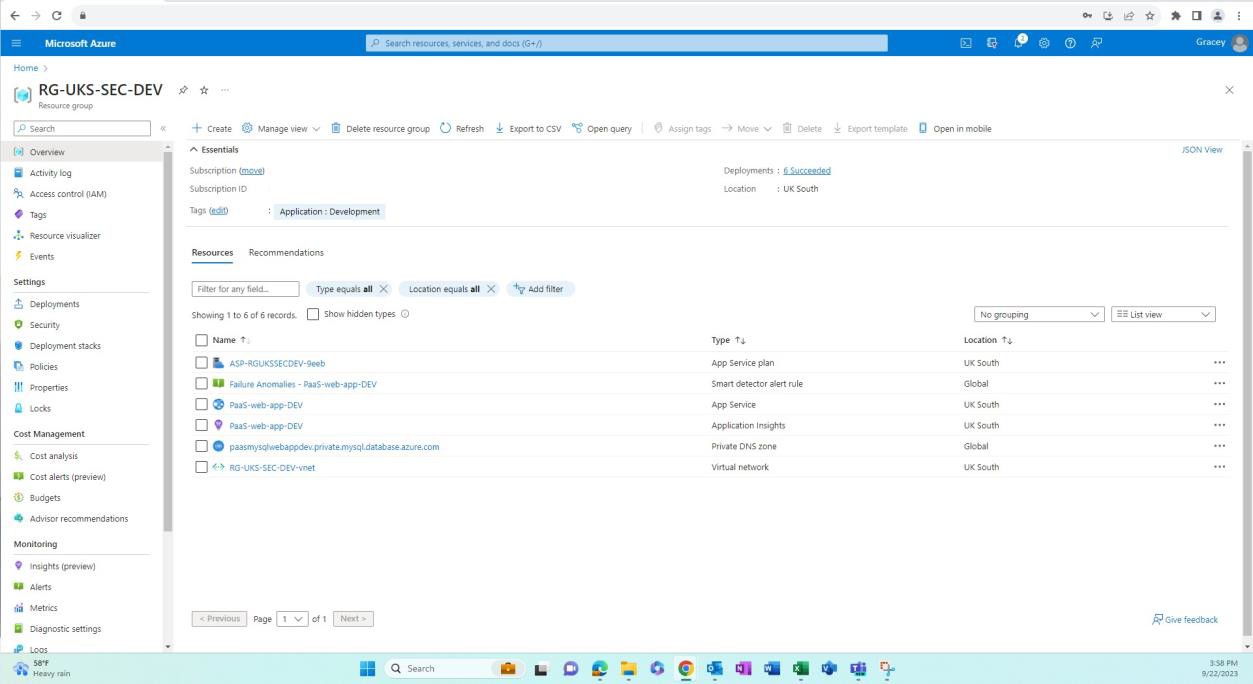
The next screenshot shows the production environment and the resources within this resource group.
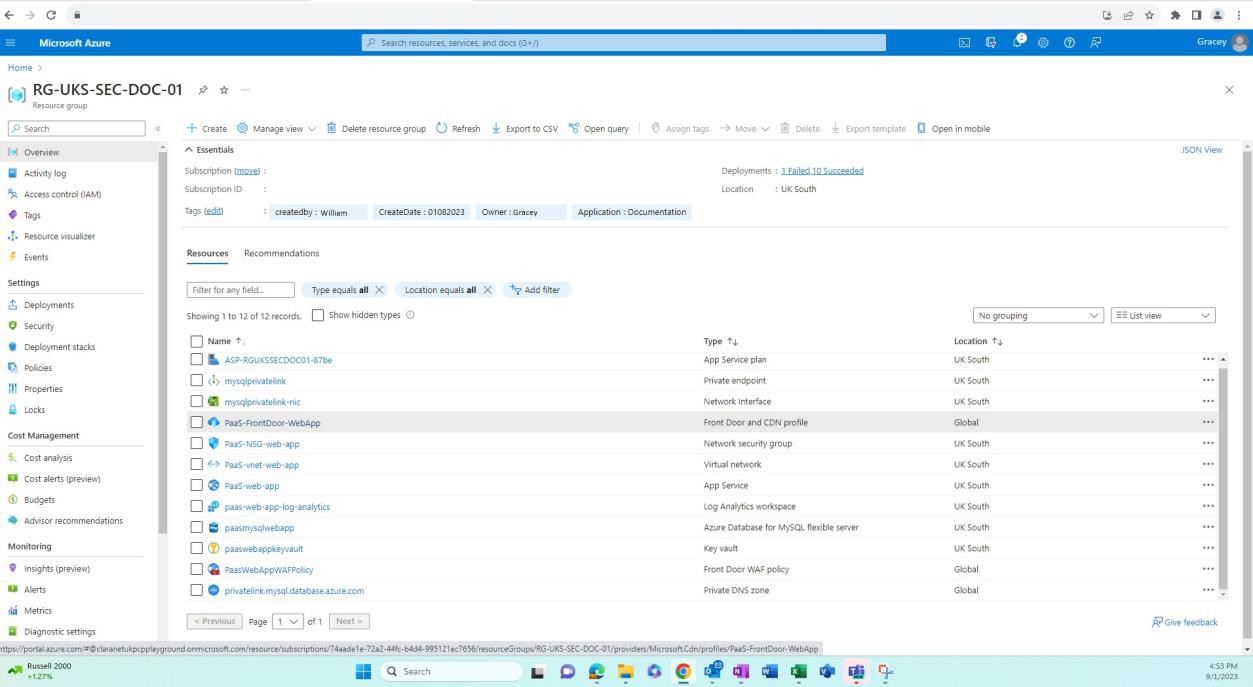
Example evidence:
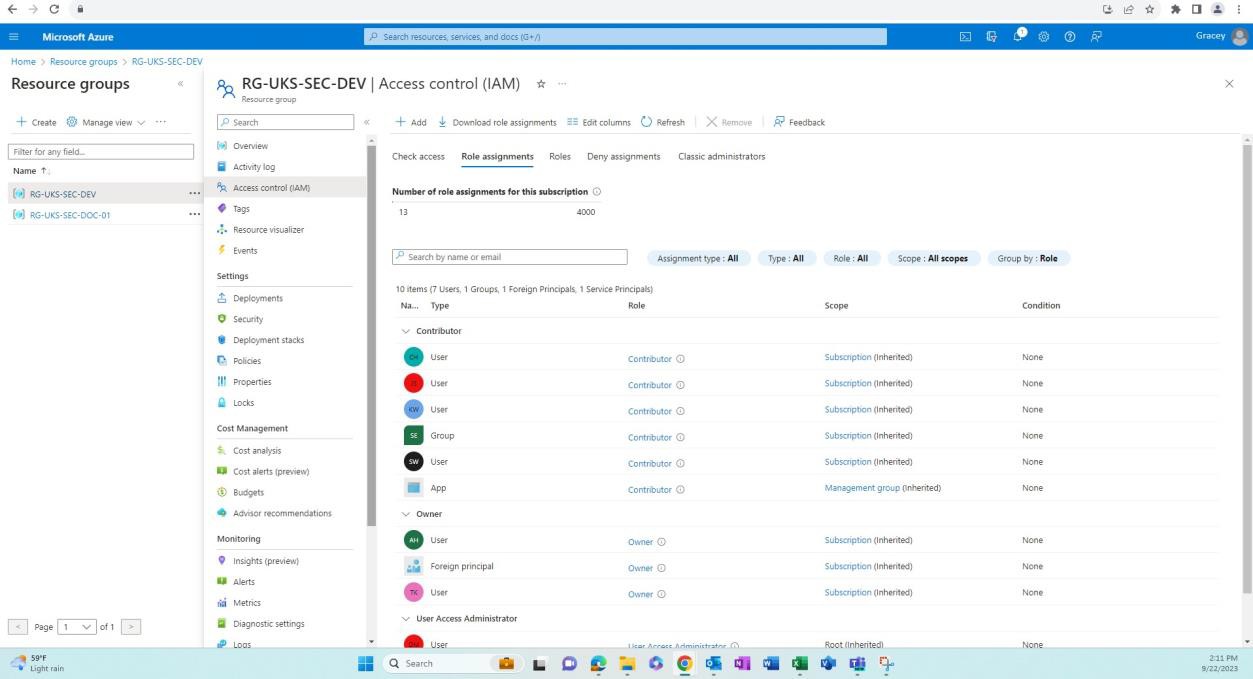
The next screenshots demonstrate that environments for development/testing are separate from the production environment. Adequate separation of environments is achieved via different users/groups with different permissions associated with each environment.
The next screenshot shows the development environment and the users with access to this resource group.
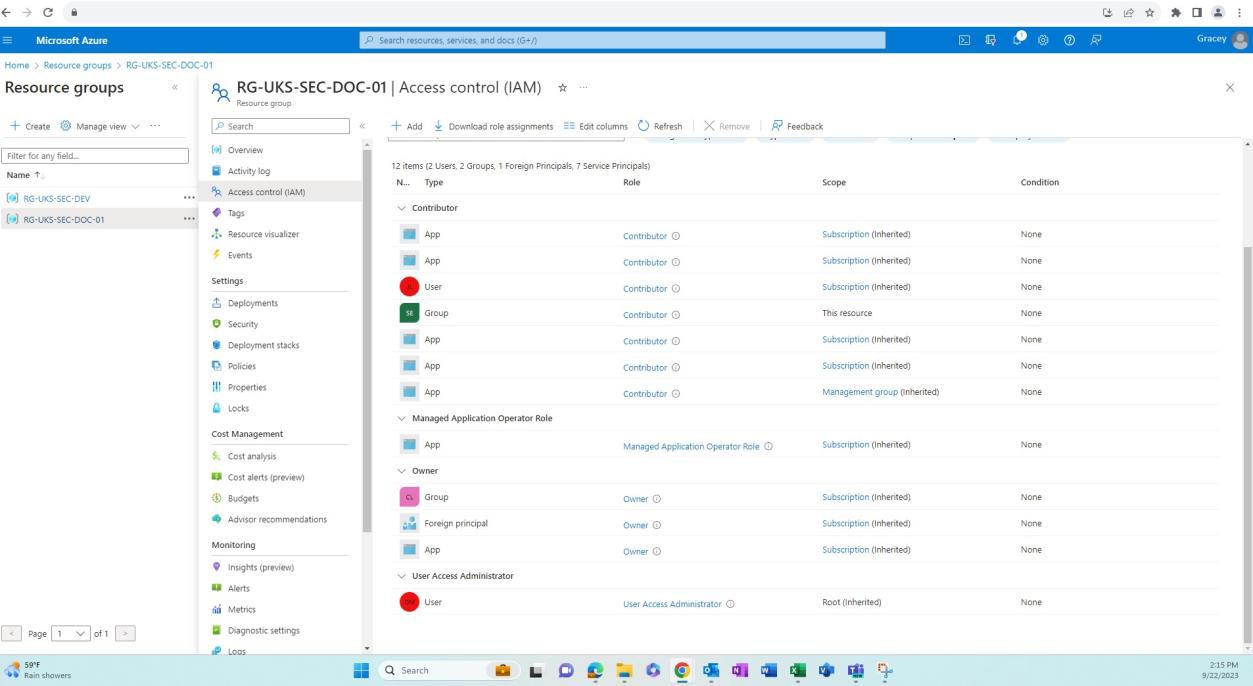
The next screenshot shows the production environment and the users (different from the development environment) that have access to this resource group.
Guidelines:
Evidence can be provided by sharing screenshots of the output of the same SQL query against a production database (redact any sensitive information) and the development/test database. The output of the same commands should produce different data sets. Where files are being stored, viewing the contents of the folders within both environments should also demonstrate different data sets.
Example evidence
The screenshot shows the top 3 records (for evidence submission, please provide top 20) from the production database.
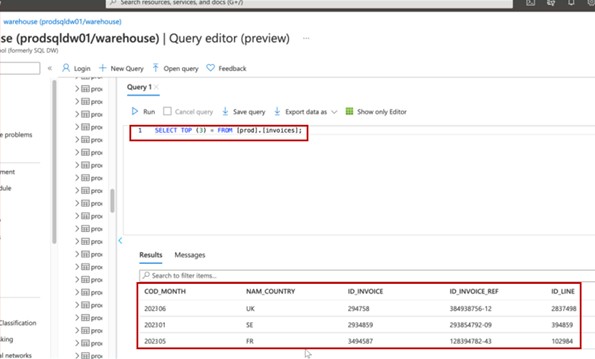
The next screenshot shows the same query from the Development Database, showing different records.
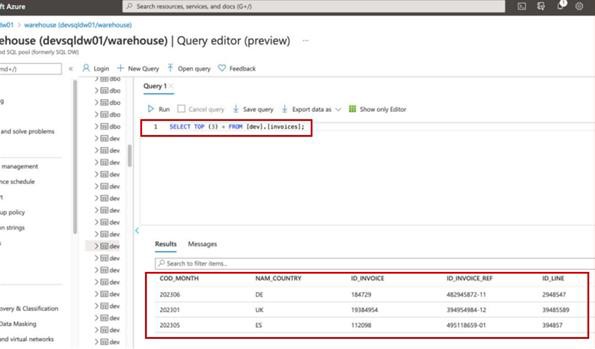
Note: In this example a full screenshot was not used, however ALL ISV submitted evidence screenshots must be full screenshots showing URL, any logged in user and system time and date.
Secure software development/deployment
Organizations involved in software development activities are often faced with competing priorities between security and TTM (Time to Market) pressures, however, implementing security related activities throughout the software development lifecycle (SDLC) can not only save money, but can also save time. When security is left as an afterthought, issues are usually only identified during the test phase of the (DSLC), which can often be more time consuming and costly to fix. The intent of this security section is to ensure secure software development practices are followed to reduce the risk of coding flaws being introduced into the software which is developed. Additionally, this section looks to include some controls to aid in secure deployment of software.
Control No. 12
Please provide evidence demonstrating documentation exists and is maintained that:
supports the development of secure software and includes industry standards and/or best practices for secure coding, such as OWASP Top 10 or SANS Top 25 CWE.
developers undergo relevant secure coding and secure software development training annually.
Intent: secure development
Organizations need to do everything in their power in ensuring software is securely developed and free from vulnerabilities. In a best effort to achieve this, a robust secure software development lifecycle (SDLC) and secure coding best practices should be established to promote secure coding techniques and secure development throughout the whole software development process. The intent is to reduce the number and severity of vulnerabilities in the software.
Coding best practices and techniques exist for all programming languages to ensure code is securely developed. There are external training courses that are designed to teach developers the different types of software vulnerabilities classes and the coding techniques that can be used to stop introducing these vulnerabilities into the software. The intention of this control is also to teach these techniques to all developers and to ensure that these techniques are not forgotten, or newer techniques are learned by carrying this out annually.
Guidelines: secure development
Supply the documented SDLC and/or support documentation which demonstrates that a secure development life cycle is in use and that guidance is provided for all developers to promote secure coding best practice. Take a look at OWASP in SDLC and the OWASP Software Assurance Maturity Model (SAMM).
Example evidence: secure development
An example of the Secure Software Development policy document is shown below. The following is an extract from Contoso's Secure Software Development Procedure, which demonstrates secure development and coding practices.

Note: In the previous examples full screenshots were not used, however ALL ISV submitted evidence screenshots must be full screenshots showing any URL, logged in user and the system time and date.
Guidelines: secure development training
Provide evidence by way of certificates if training is carried out by an external training company, or by providing screenshots of the training diaries or other artifacts which demonstrates that developers have attended training. If this training is carried out via internal resources, provide evidence of the training material as well.
Example evidence: secure development training
The next screenshot is an email requesting staff in the DevOps team to be enrolled into OWASP Top Ten Training Annual Training.

The next screenshot shows that training has been requested with business justification and approval. This is then followed by screenshots taken from the training and a completion record showing that the person has finished the annual training.
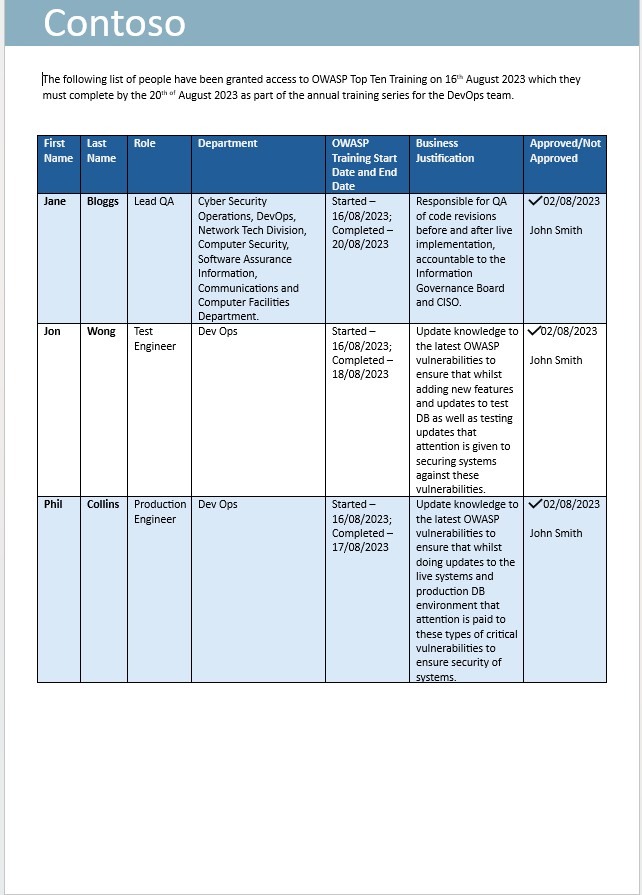
Note: In this example a full screenshot was not used, however ALL ISV submitted evidence screenshots must be full screenshots showing URL, any logged in user and system time and date.
Control No. 13
Please provide evidence that code repositories are secured so that:
all code changes undergo a review and approval process by a second reviewer prior to being merged with main branch.
appropriate access controls are in place.
all access is enforced through multi-factor authentication (MFA).
all releases made into the production environment(s) are reviewed and approved prior to their deployment.
Intent: code review
The intent with this subpoint is to perform a code review by another developer to help identify any coding mistakes which could introduce a vulnerability in the software. Authorization should be established to ensure code reviews are carried, testing is done, etc. prior to deployment. The authorization step validates that the correct processes have been followed which underpins the SDLC defined in control 12.
The objective is to ensure that all code changes undergo a rigorous review and approval process by a second reviewer before they are merged into the main branch. This dual-approval process serves as a quality control measure, aiming to catch any coding errors, security vulnerabilities, or other issues that could compromise the integrity of the application.
Guidelines: code review
Provide evidence that code undergoes a peer review and must be authorized before it can be applied to the production environment. This evidence may be via an export of change tickets, demonstrating that code reviews have been carried out and the changes authorized, or it could be through code review software such as Crucible
Example evidence: code review
The following is a ticket that shows code changes undergo a review and authorization process by someone other than the original developer. It shows that a code review has been requested by the assignee and will be assigned to someone else for the code review.
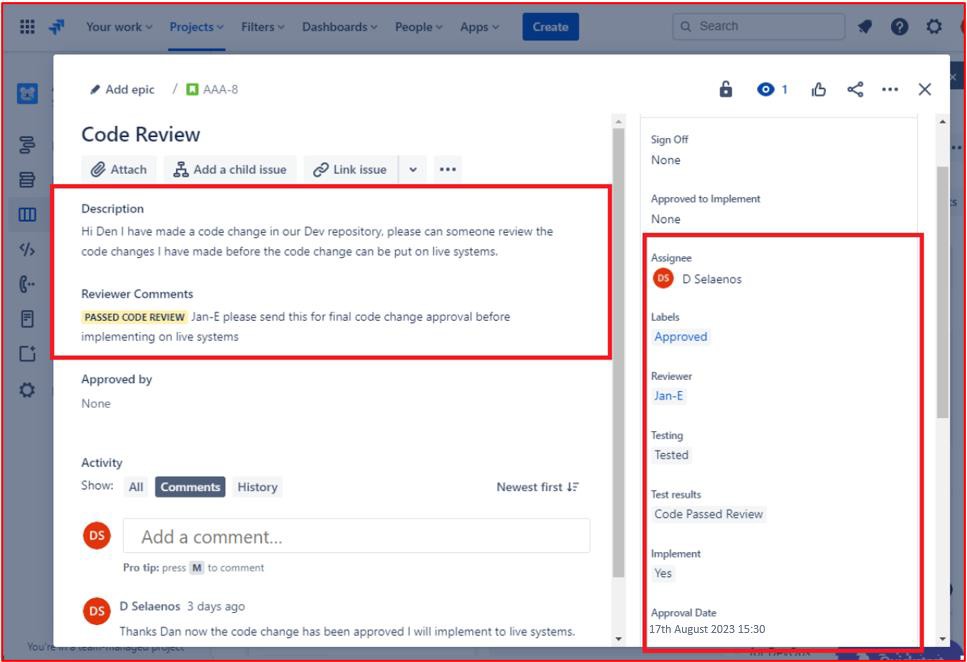
The next image shows that the code review was assigned to someone other than the original developer as shown by the highlighted section on the right-hand side of the image. On the lefthand side the code has been reviewed and given a ’PASSED CODE REVIEW’ status by the code reviewer. The ticket must now get approval by a manager before the changes can be put onto live production systems.
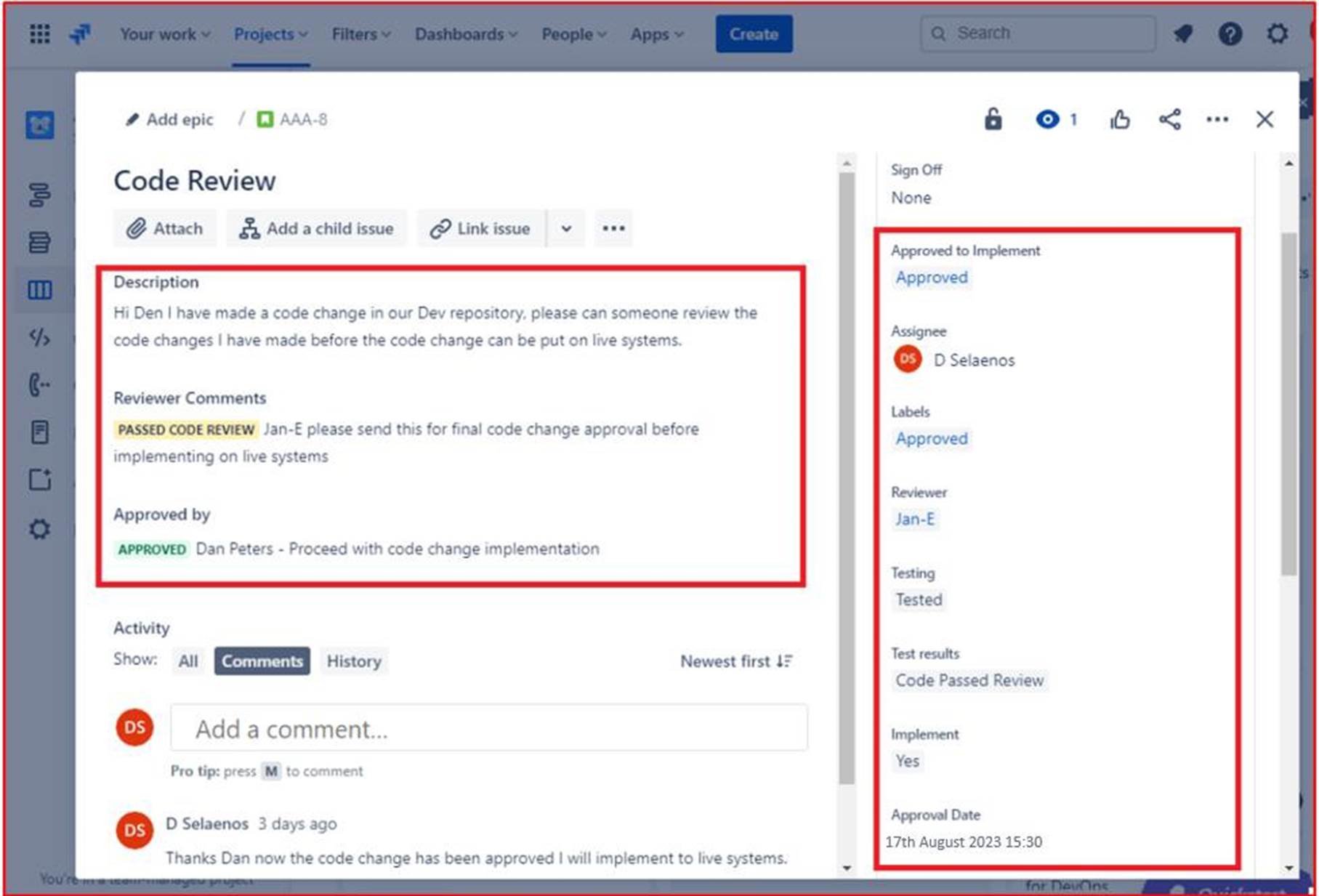
The following image shows that the reviewed code has been given approved to be implemented onto the live production systems. After the code changes have been done the final job gets sign off. Please note that throughout the process there are three people involved, the original developer of the code, the code reviewer, and a manager to give approval and sign off. To meet the criteria for this control, it would be an expectation that your tickets will follow this process.
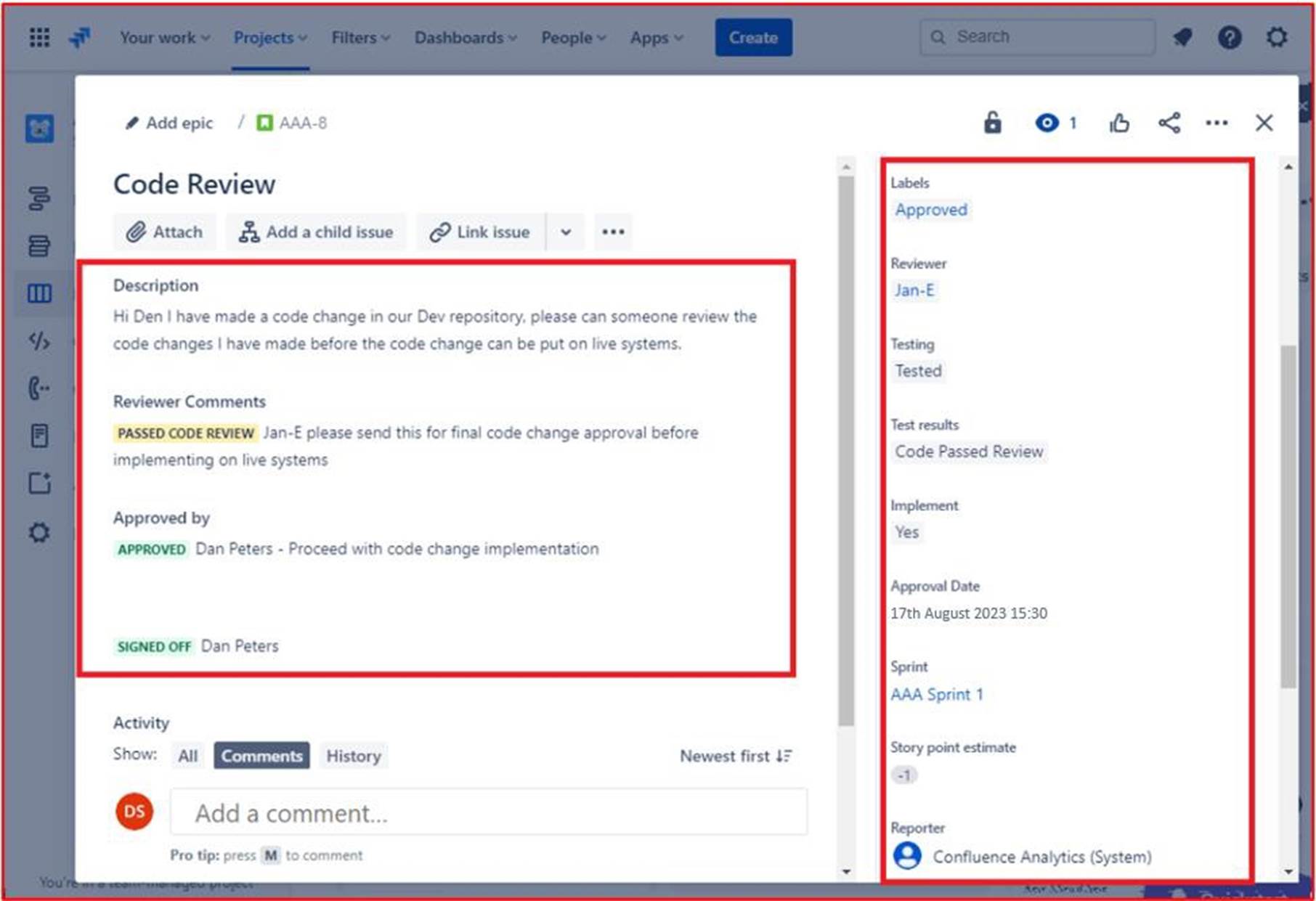
Note: In this example a full screenshot was not used, however ALL ISV submitted evidence screenshots must be full screenshots showing URL, any logged in user and system time and date.
Example evidence: code review
Besides the administrative part of the process shown above, with modern code repositories and platforms additional controls such as branch policy enforcing review can be implemented to ensure merges cannot occur until such review is completed. The example following shows this being achieved in DevOps.
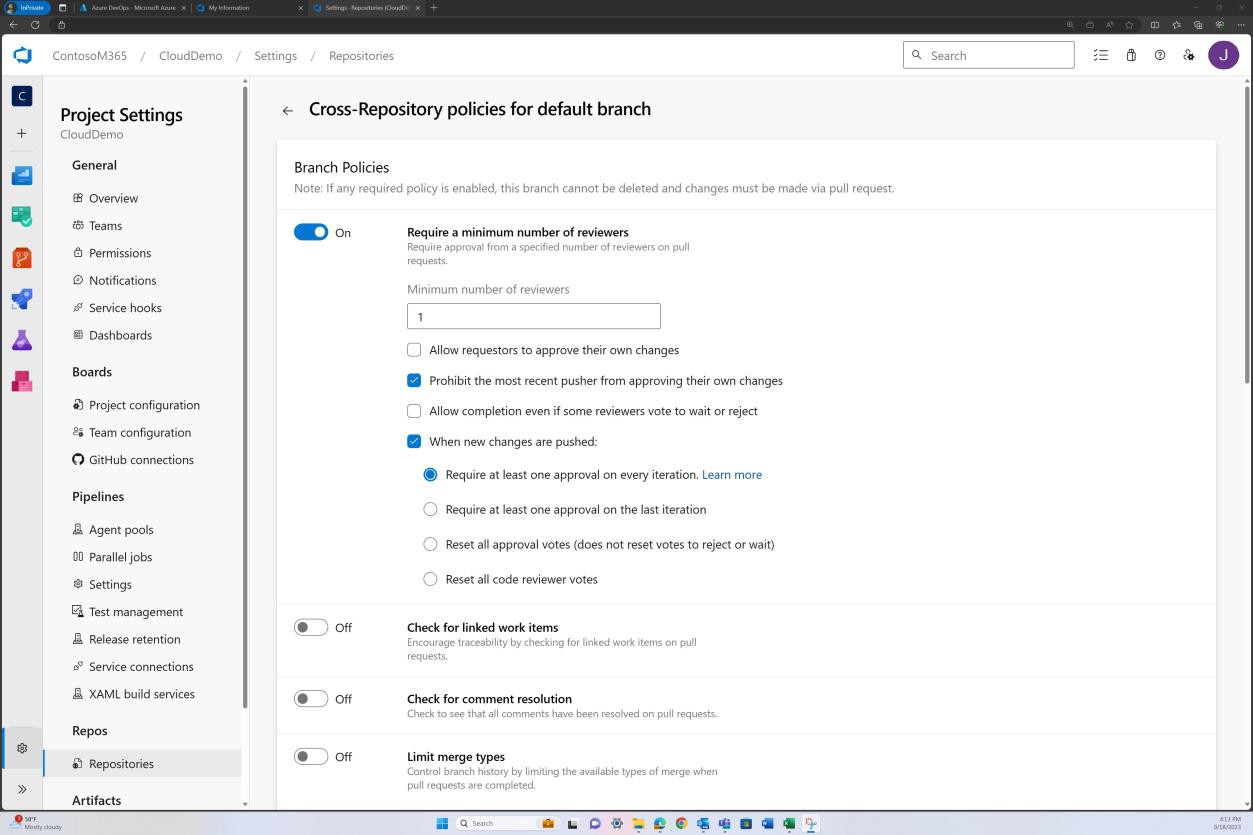
The next screenshot shows that default reviewers are assigned, and review is automatically required.
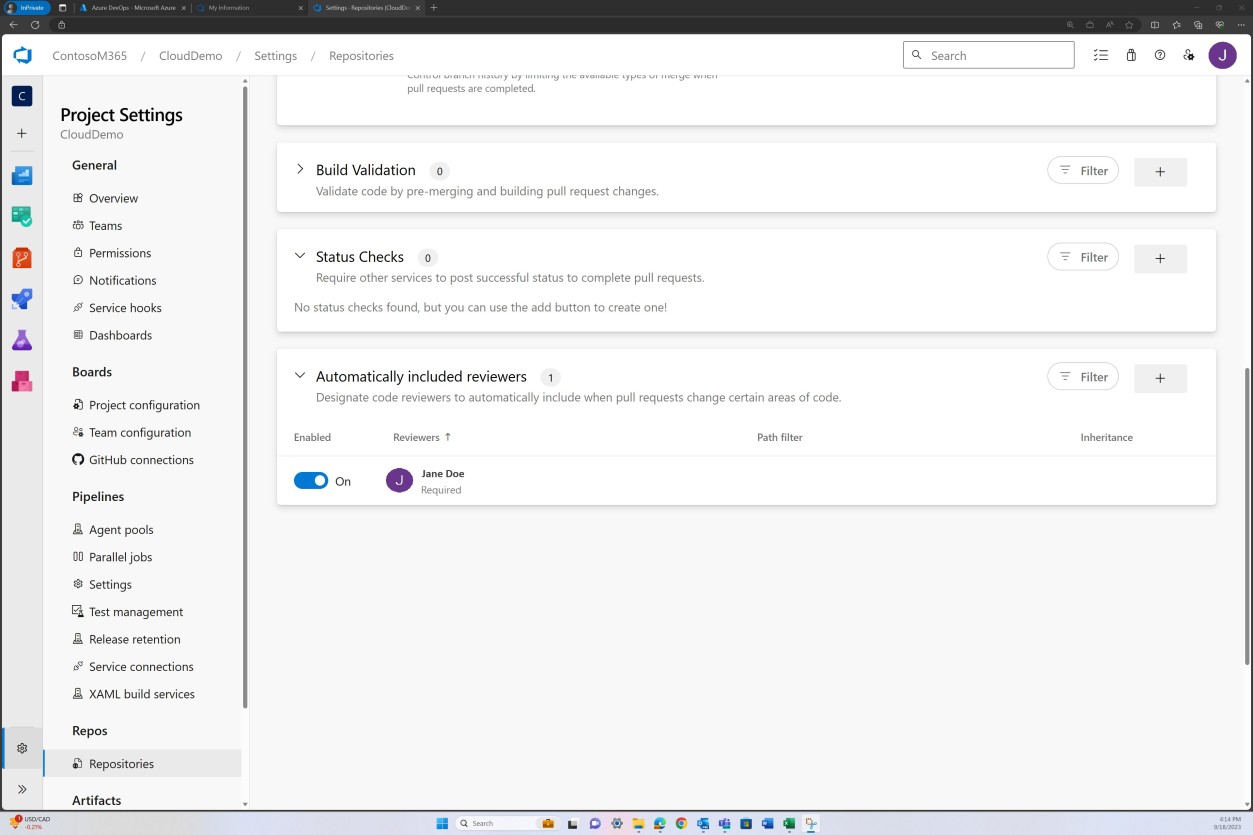
Example evidence: code review
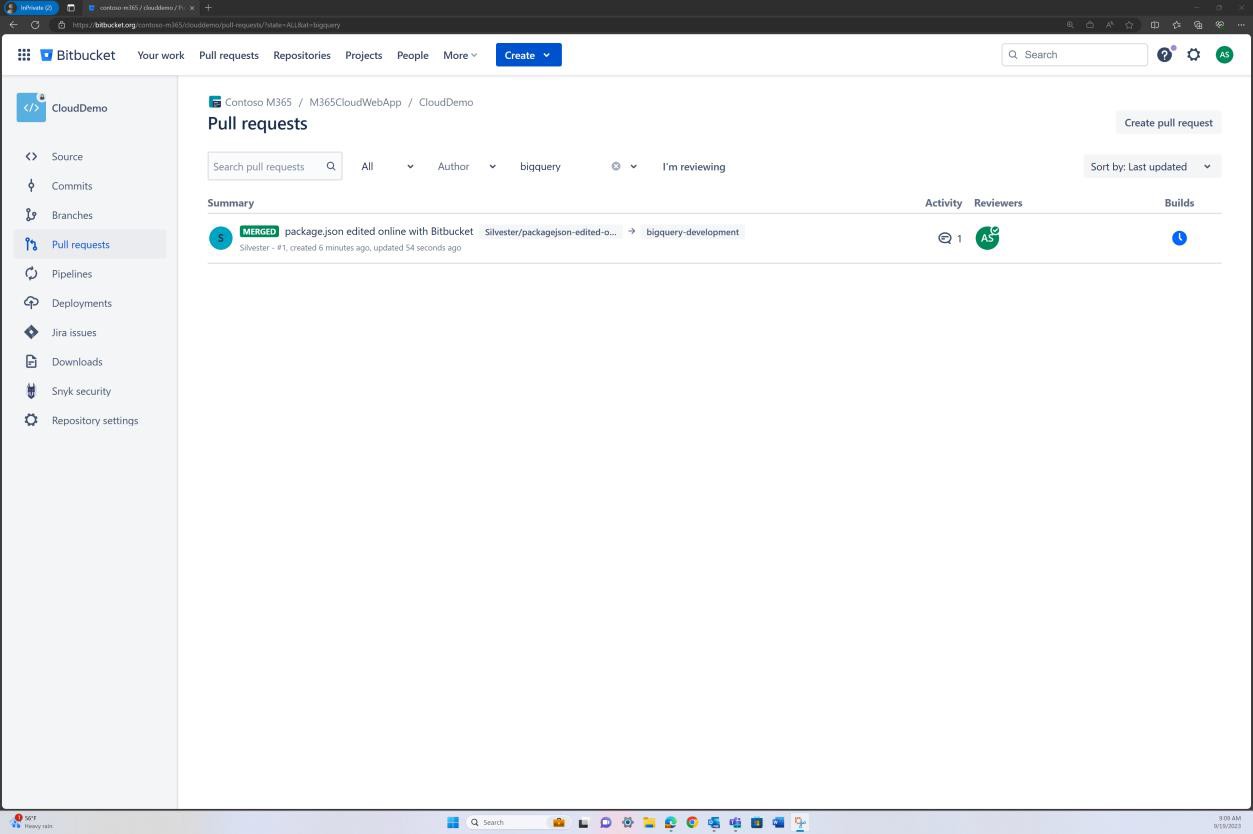
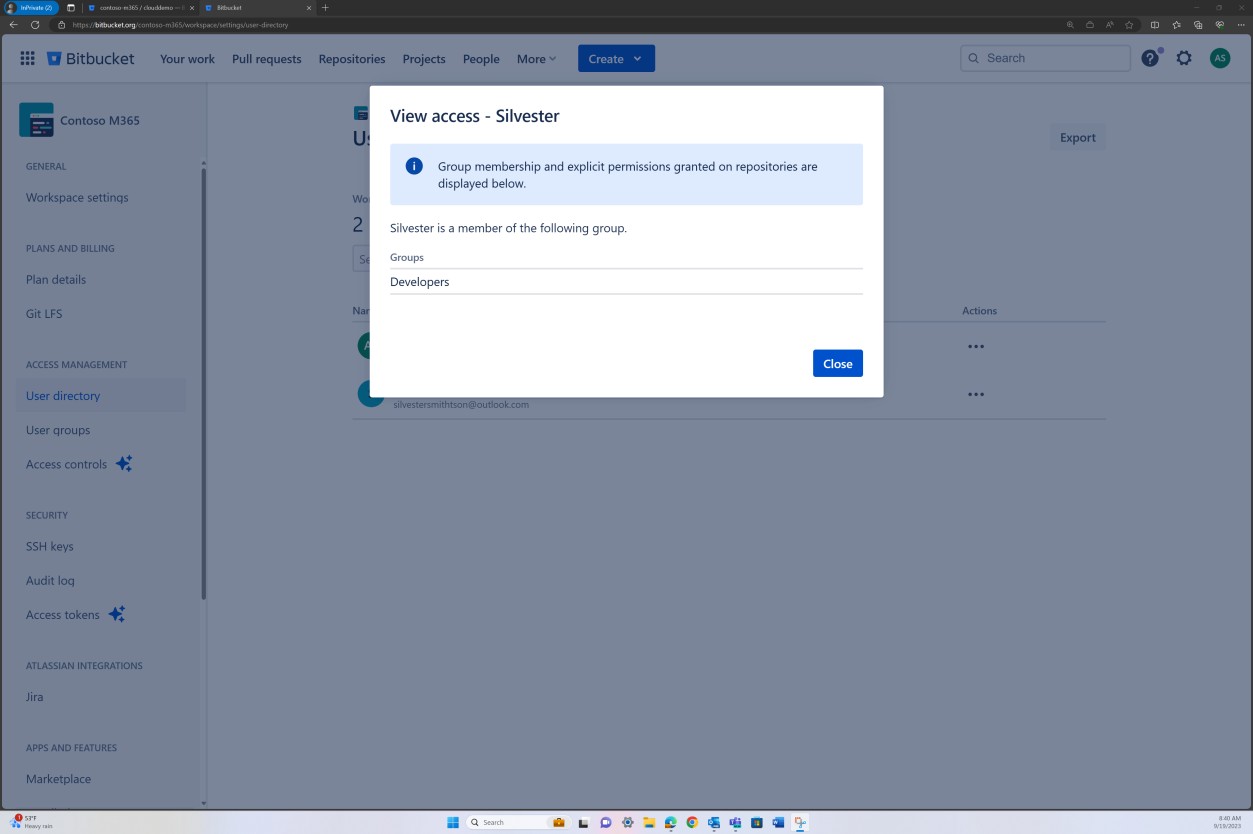
Branch policy enforcing review can also be achieved in Bitbucket.
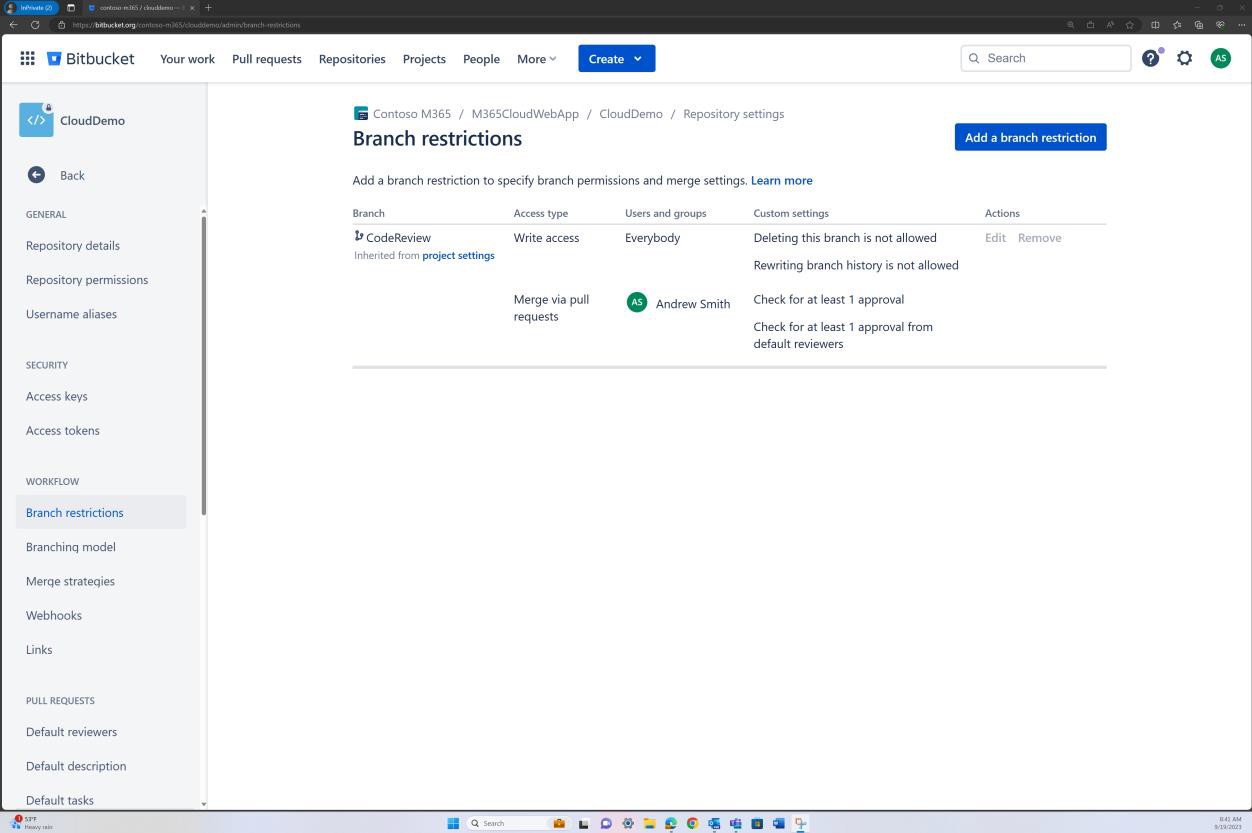
In the next screenshot that a default reviewer is set. This ensures that any merges will require a review from the assigned individual before the change is propagated to the main branch.
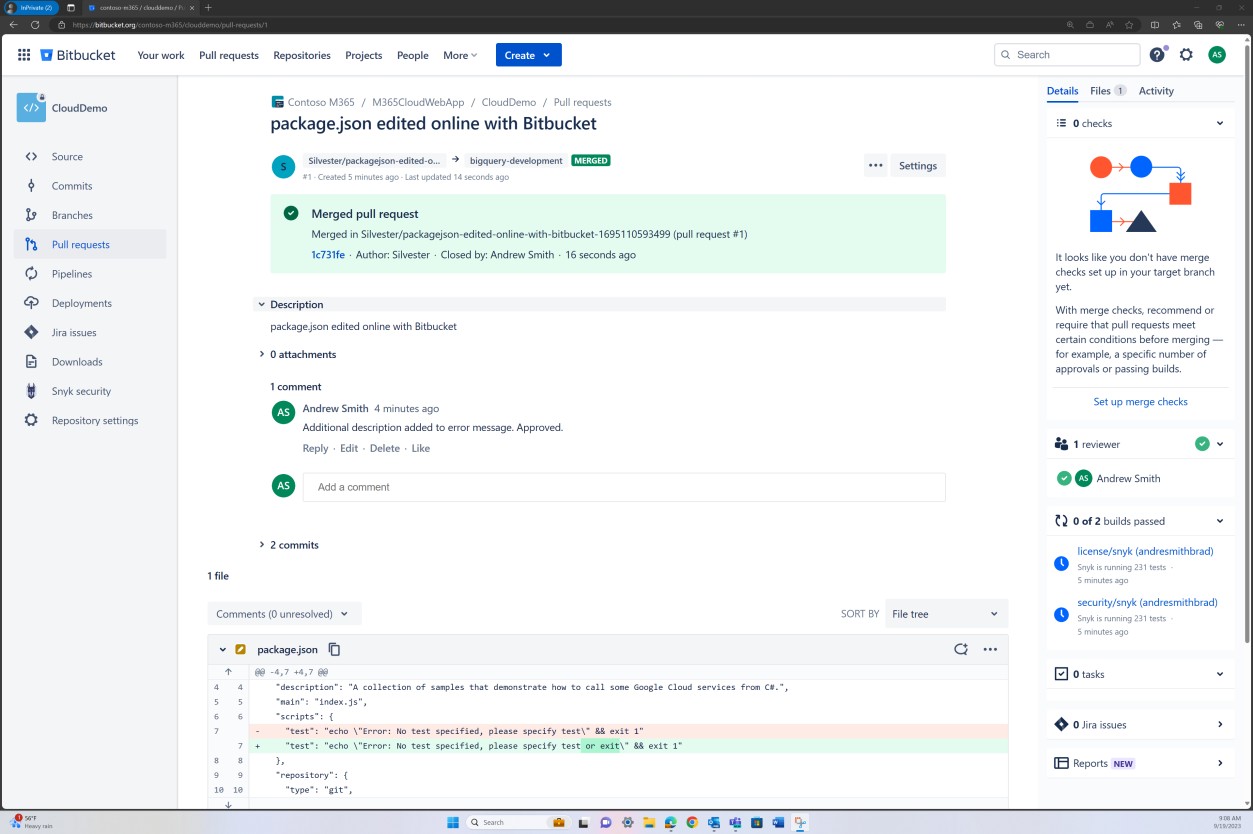
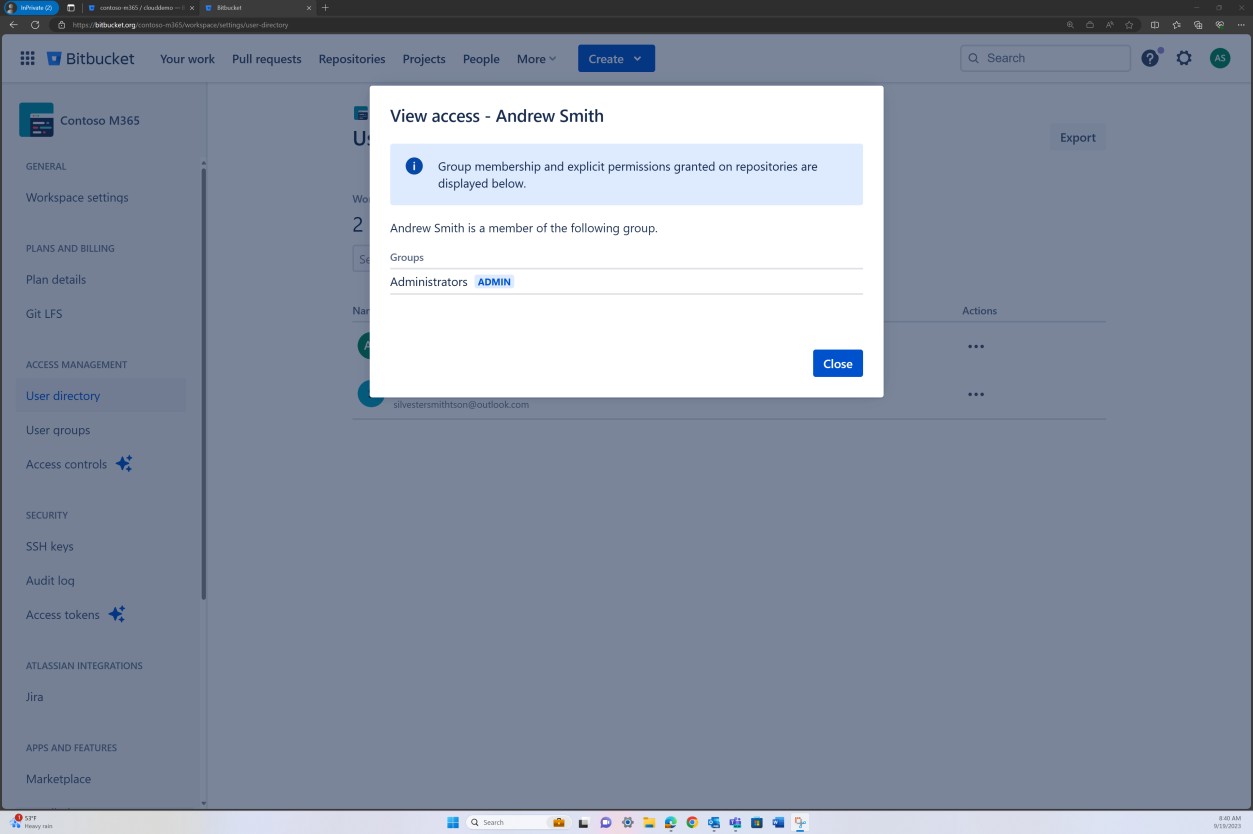
The subsequent two screenshots, demonstrate an example of the configuration settings being applied. As well as a completed pull request, which was initiated by the user Silvester and required approval from the default reviewer Andrew before being merged with the main branch.
Please note that when evidence is supplied the expectation will be for the end-to-end process to be demonstrated. Note: Screenshots should be supplied showing the configuration settings if a branch policy is in place (or some other programmatic method/control), and tickets/records of approval being granted.
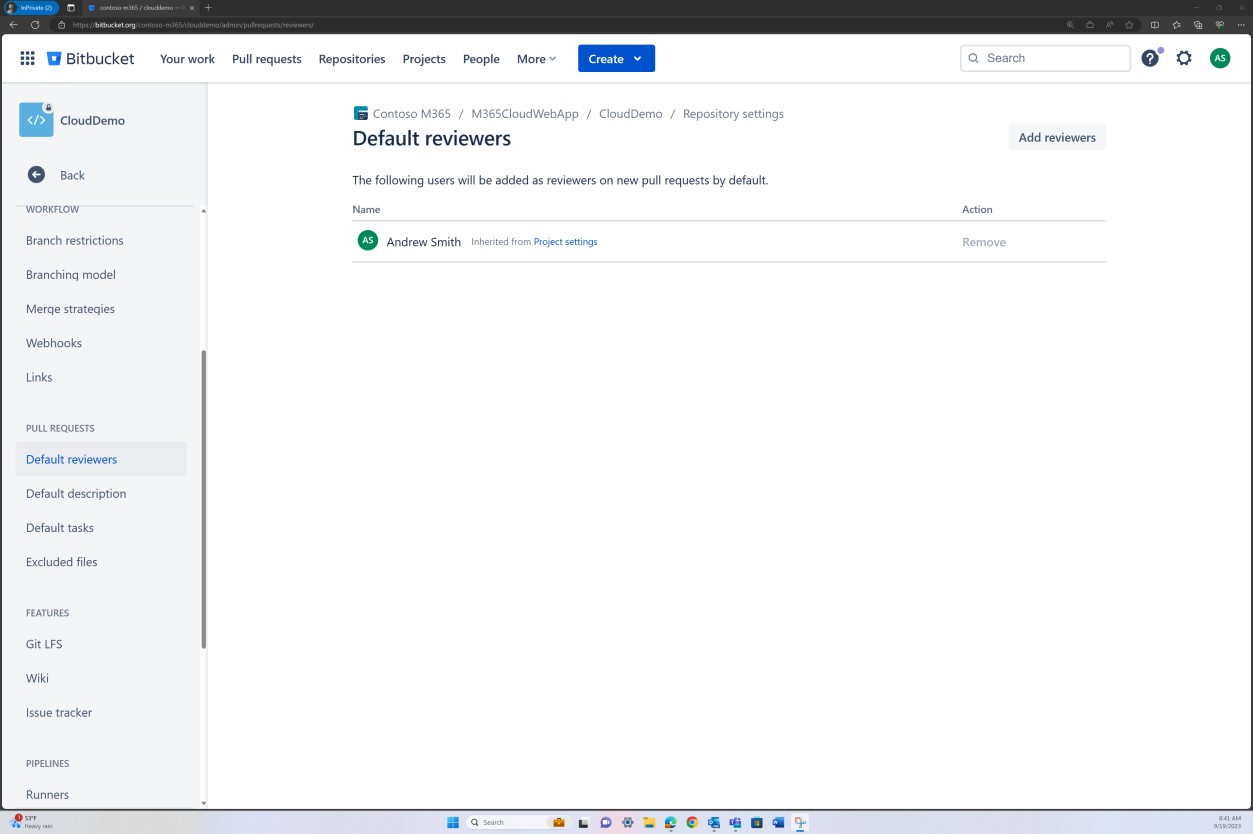
Intent: restricted access
Leading on from the previous control, access controls should be implemented to limit access to only individual users who are working on specific projects. By limiting access, you can limit the risk of unauthorized changes being carried out and thereby introducing insecure code changes. A least privileged approach should be taken to protect the code repository.
Guidelines: restricted access
Provide evidence by way of screenshots from the code repository that access is restricted to individuals needed, including different privileges.
Example evidence: restricted access
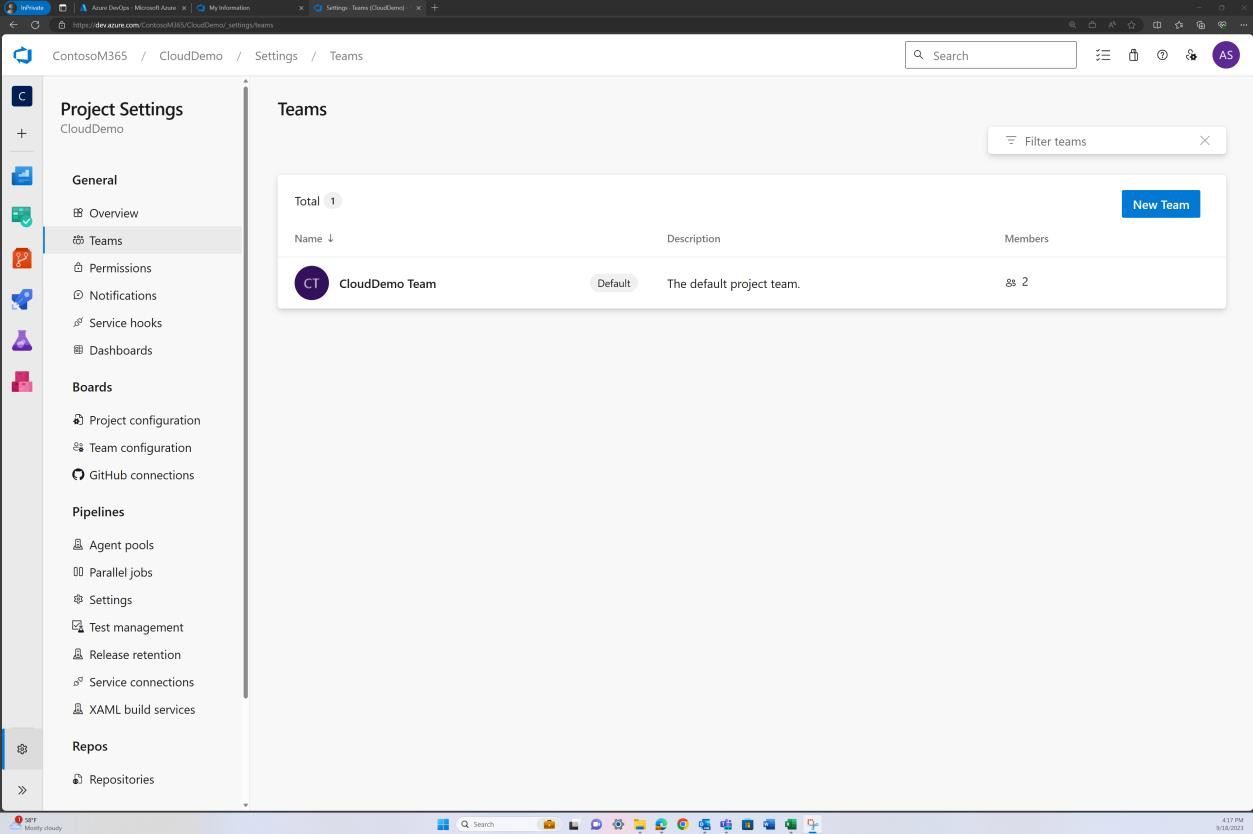
The next screenshots show the access controls that have been implemented in Azure DevOps. The “CloudDemo Team” is shown to have two members, and each member has different permissions.
Note: The next screenshots show an example of the type of evidence and format that would be expected to meet this control. This is by no means extensive and the real-world cases might differ on how access controls are implemented.
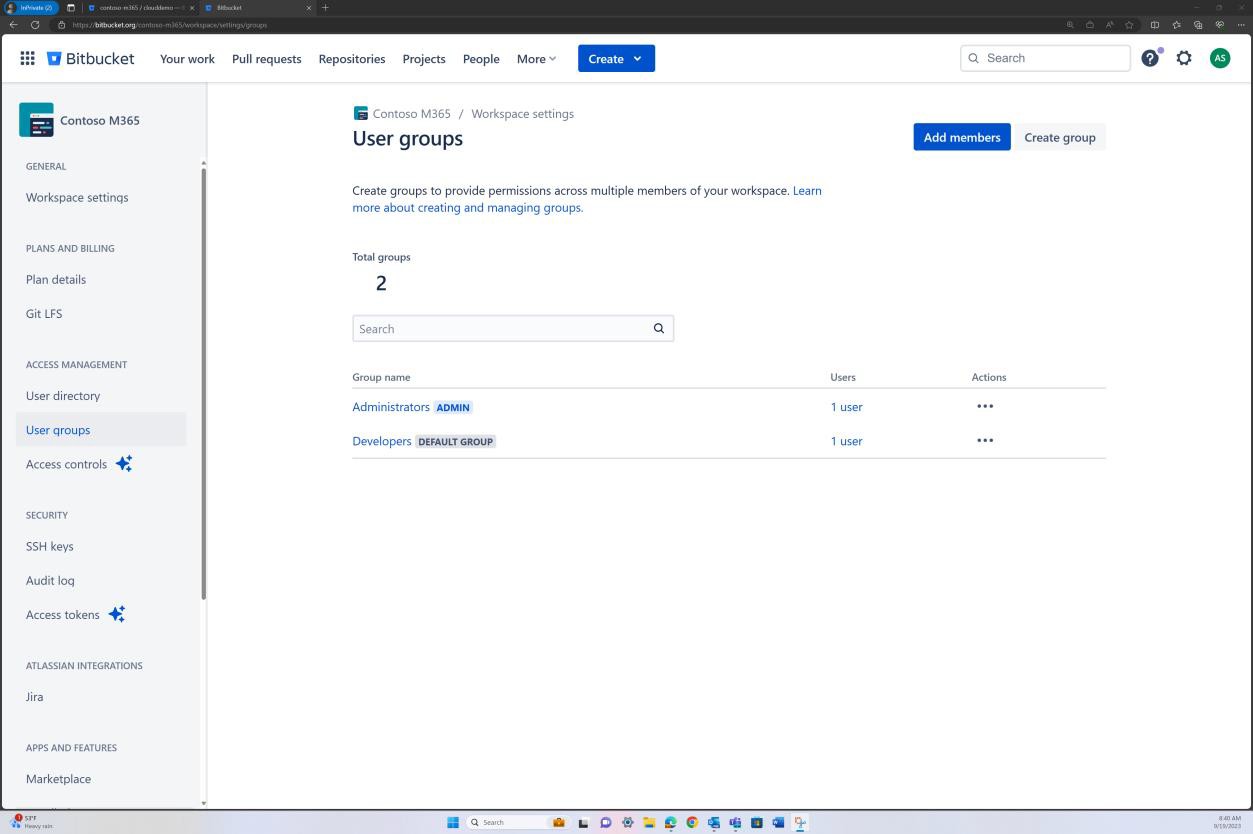
If permissions are set at group level, then evidence of each group and the users of that group must be supplied as shown in the second example for Bitbucket.
Screenshot following shows the members of the “CloudDemo Team”.
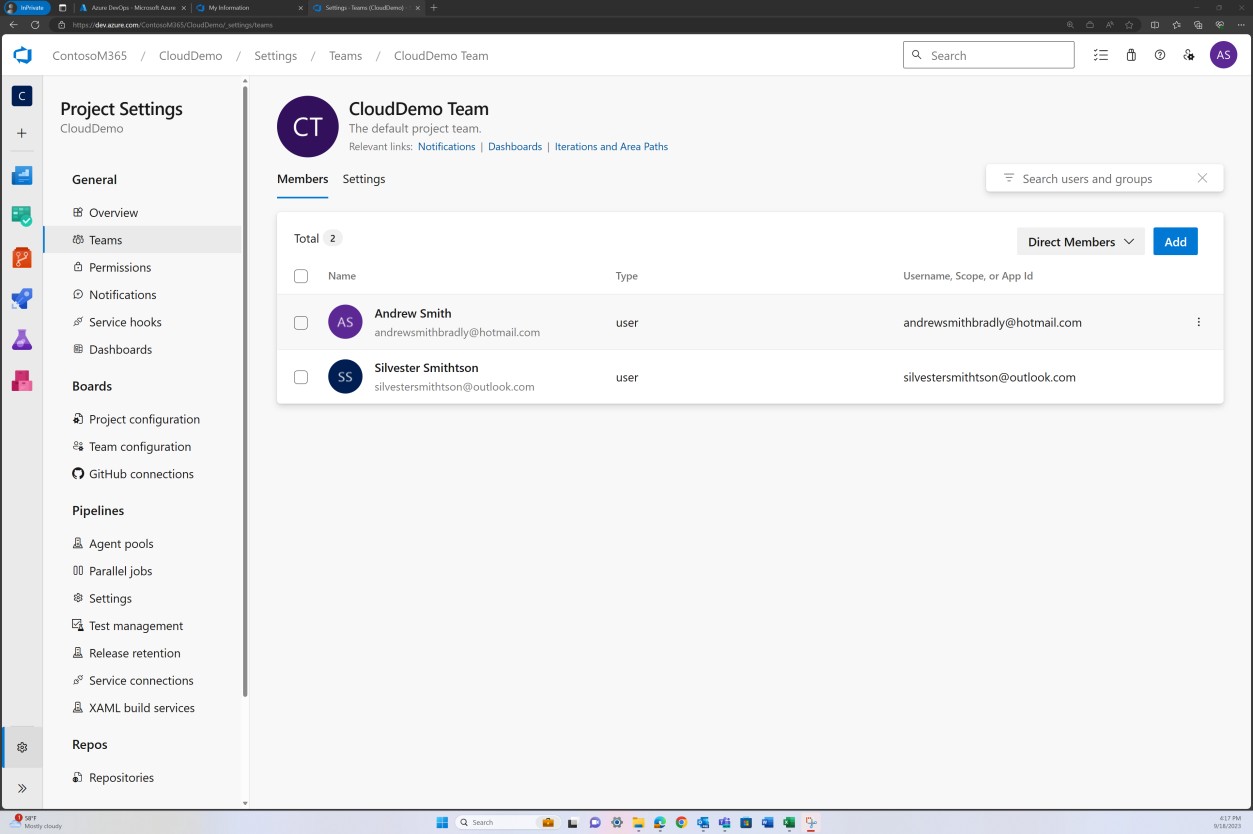
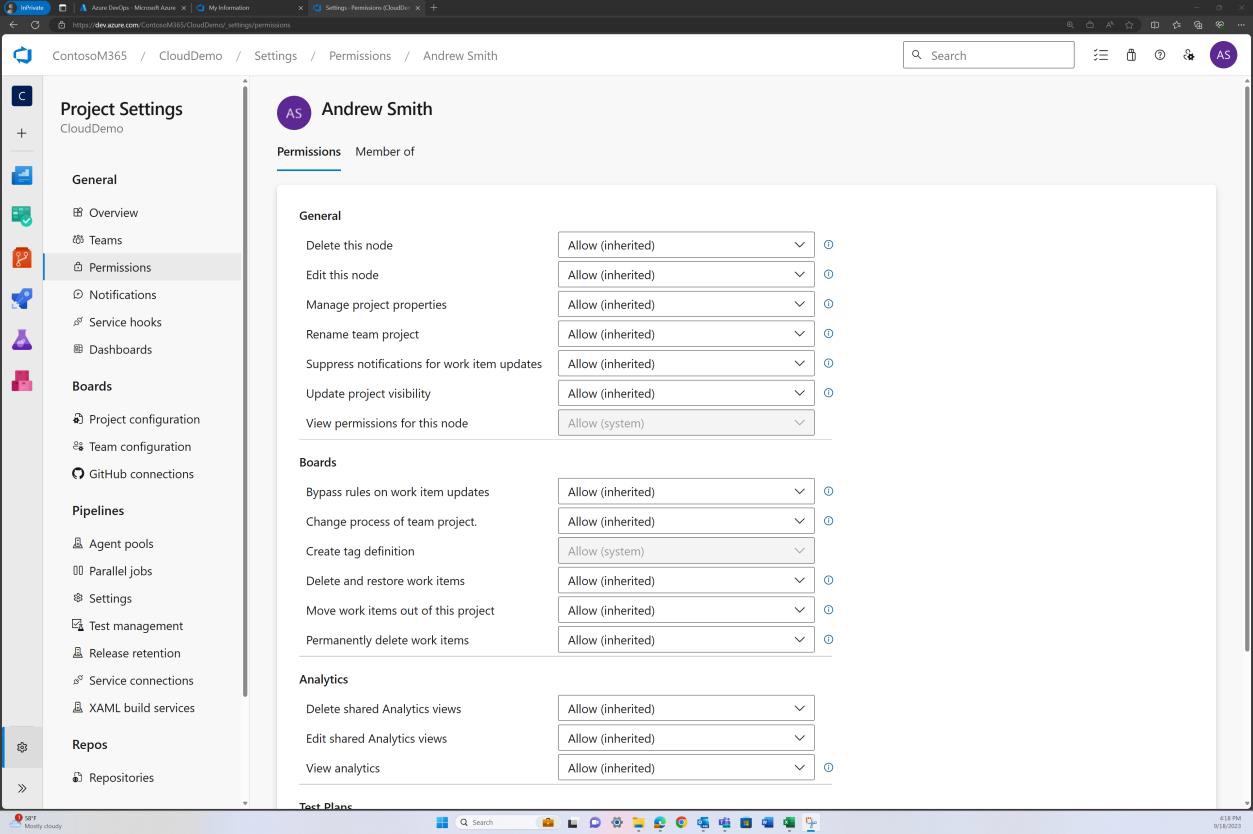
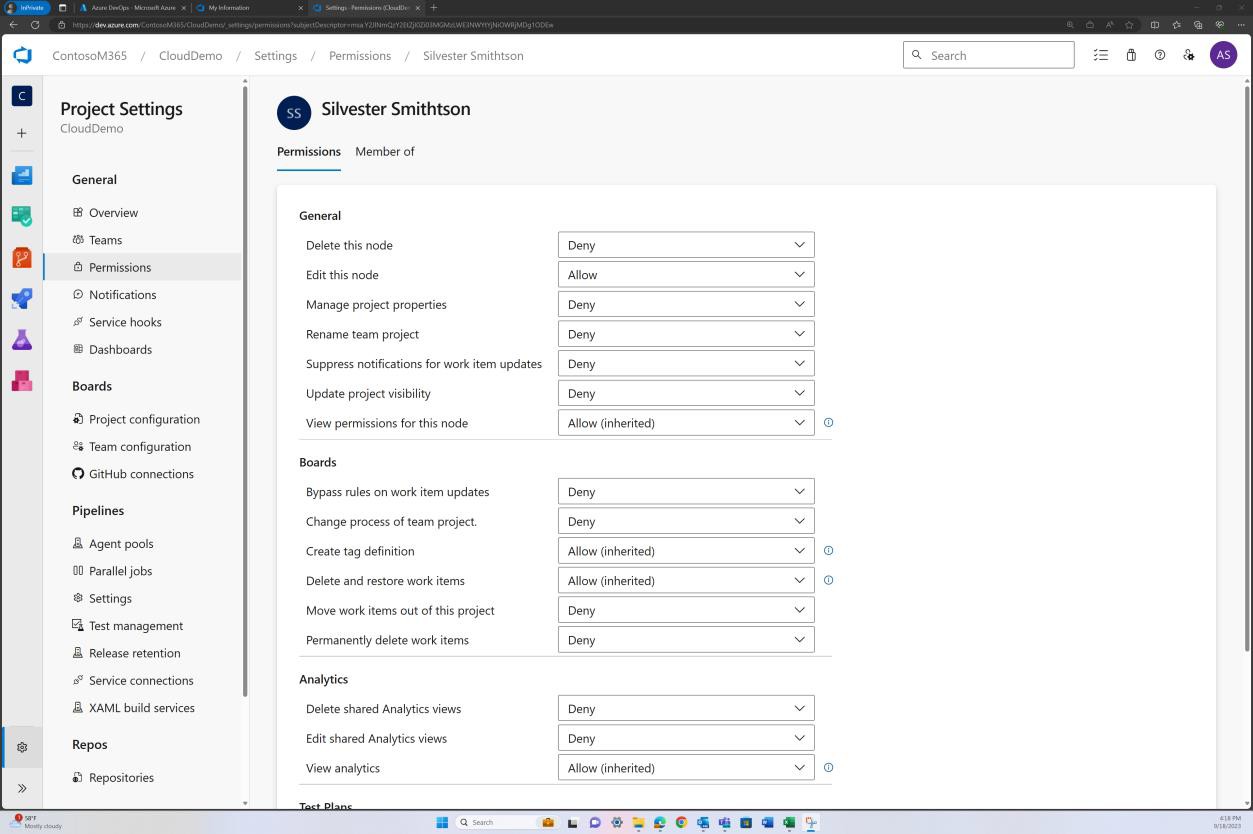
The previous image shows that Andrew Smith has significantly higher privileges as the project owner than Silvester below.
Example evidence
In the next screenshot, access controls implemented in Bitbucket is achieved via permissions set at group level. For repository access level there is an “Administrator” group with one user and a “Developer” group with another user.
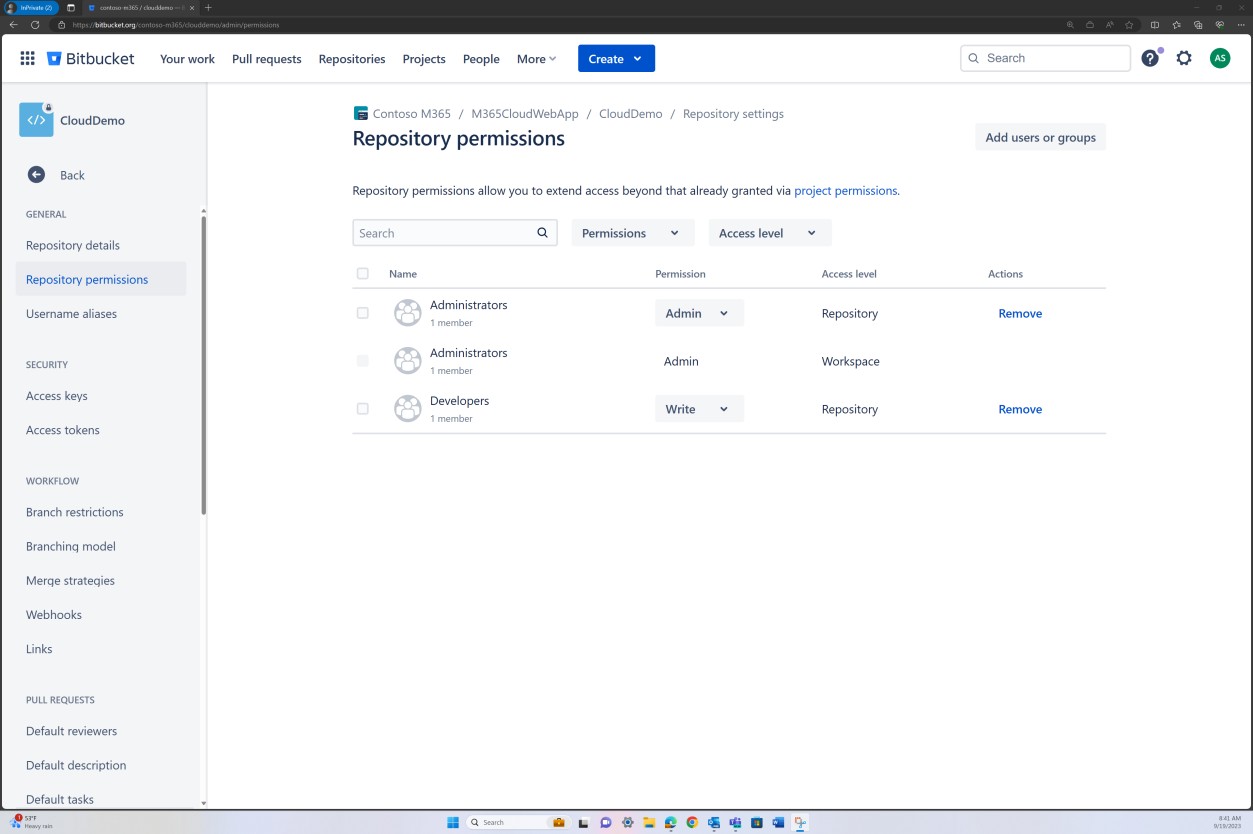
The next screenshots show that each of the users belongs to a different group and inherently has a different level of permissions. Andrew Smith is the Administrator, and Silvester is part of the Developer group, which only grants him developer privileges.
Intent: MFA
If a threat actor can access and modify a software’s code base, they could introduce vulnerabilities, backdoors, or malicious code into the code base and therefore into the application. There have been several instances of this already, with probably the most publicized being the SolarWinds attack of 2020, where the attackers injected malicious code into a file that was later included in SolarWinds' Orion software updates. More than 18,000 SolarWinds customers installed the malicious updates, with the malware spreading undetected.
The intent of this subpoint is to verify that all access to code repositories is enforced through multi- factor authentication (MFA).
Guidelines: MFA
Provide evidence by way of screenshots from the code repository that ALL users have MFA enabled.
Example evidence: MFA
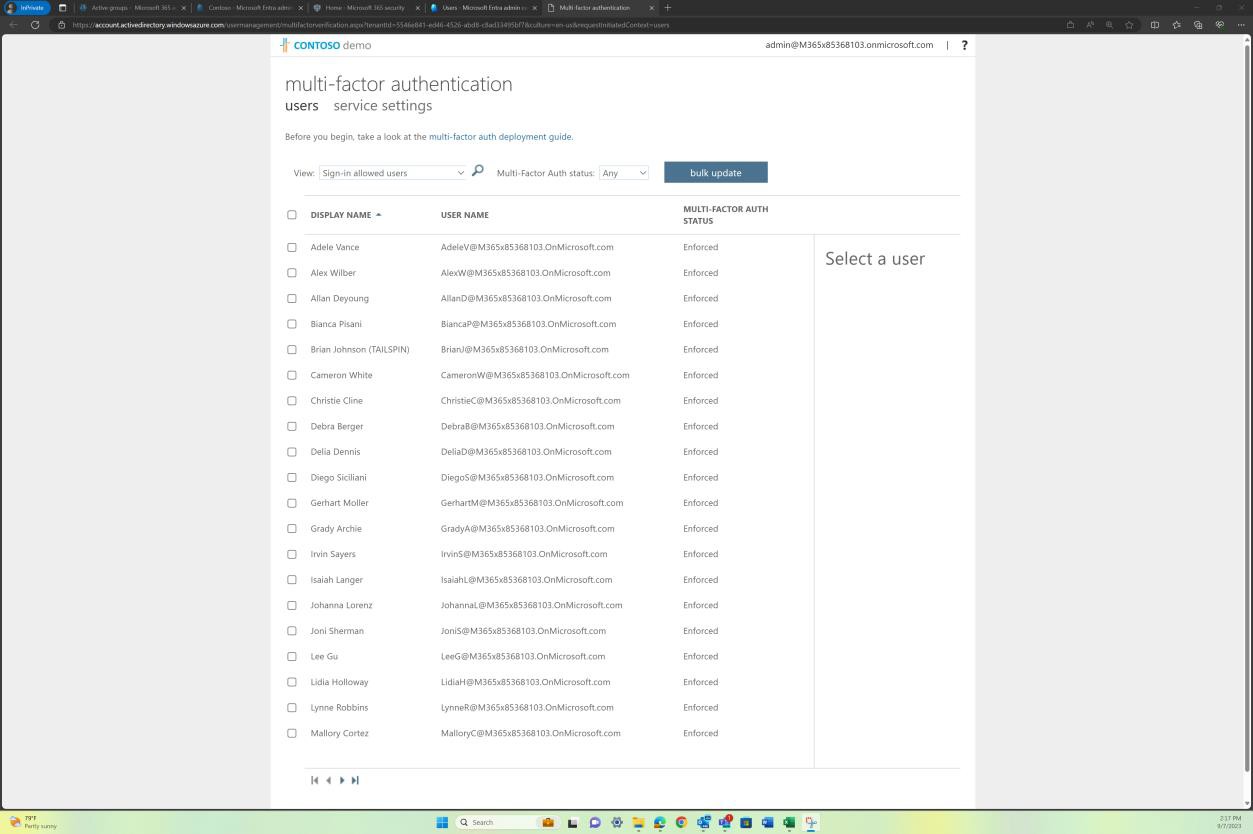
If the code repositories are stored and maintained in Azure DevOps, then depending on how MFA was setup at the tenant level, evidence can be provided from AAD e.g., “Per user MFA”. The next screenshot shows that MFA is enforced for all users in AAD, and this will also apply to Azure DevOps.
Example evidence: MFA
If the organization uses a platform such as GitHub, you can demonstrate that 2FA is enabled by sharing the evidence from the ‘Organization’ account as shown in the next screenshots.
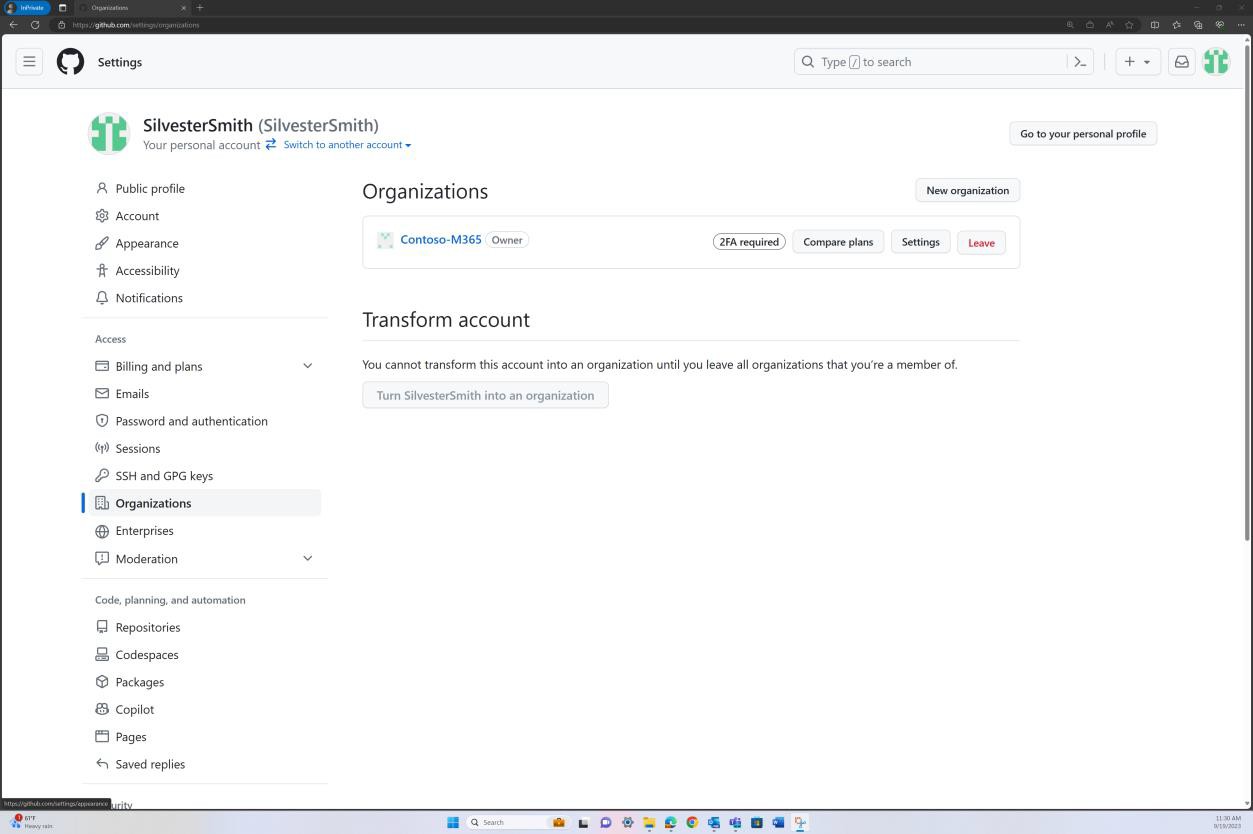
To view whether 2FA is enforced for all members of your organization on GitHub, you can navigate to the organization’s settings tab, as in the next screenshot.
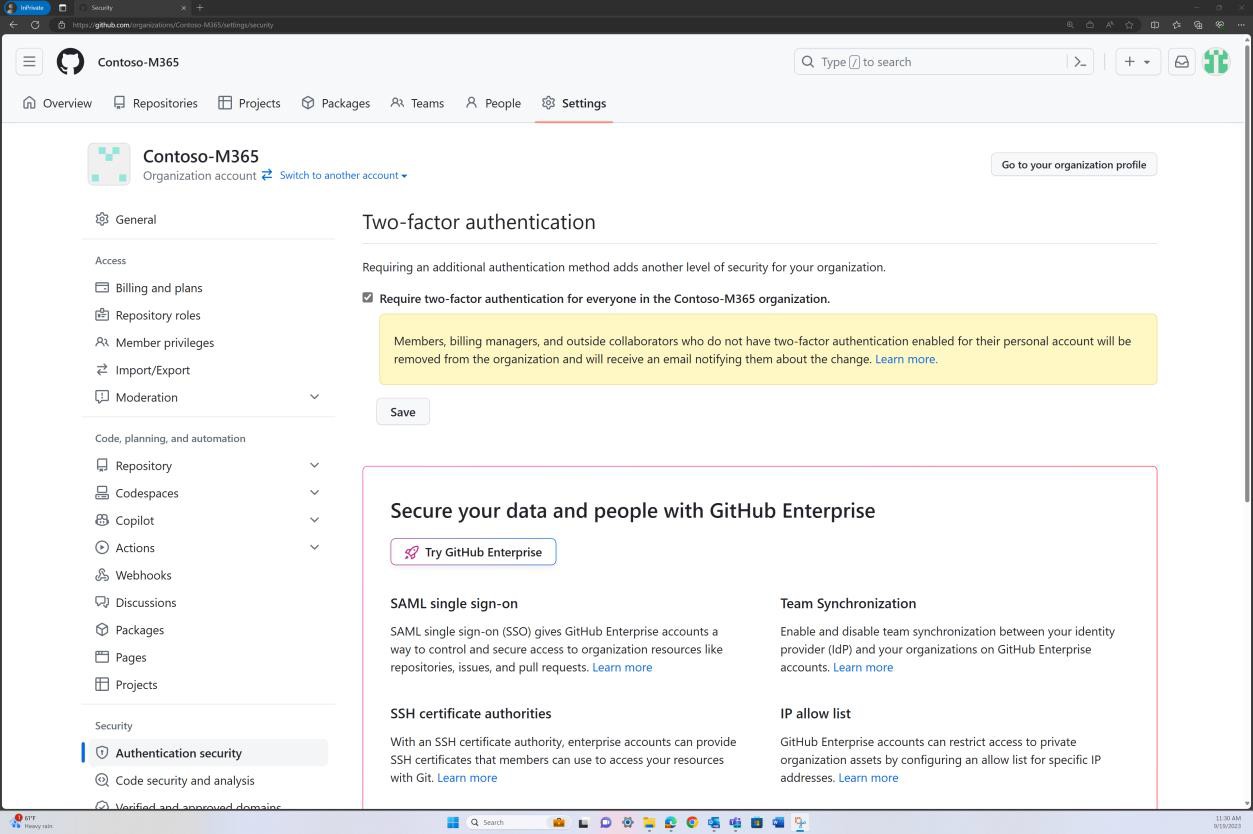
Navigating to the “People” tab in GitHub, it can be established that “2FA” is enabled for all users within the organization as shown in the next screenshot.
Intent: reviews
The intent with this control is to perform a review of the release into a development environment by another developer to help identify any coding mistakes, as well as misconfigurations which could introduce a vulnerability. Authorization should be established to ensure release reviews are carried out, testing is done, etc. prior to deployment in production. The authorization. step can validate that the correct processes have been followed which underpins the SDLC principles.
Guidelines
Provide evidence that all releases from the test/development environment into the production environment are being reviewed by a different person/developer than the initiator. If this is achieved via a Continuous Integration/Continuous Deployment pipeline, then evidence supplied must show (same as with code reviews ) that reviews are enforced.
Example evidence
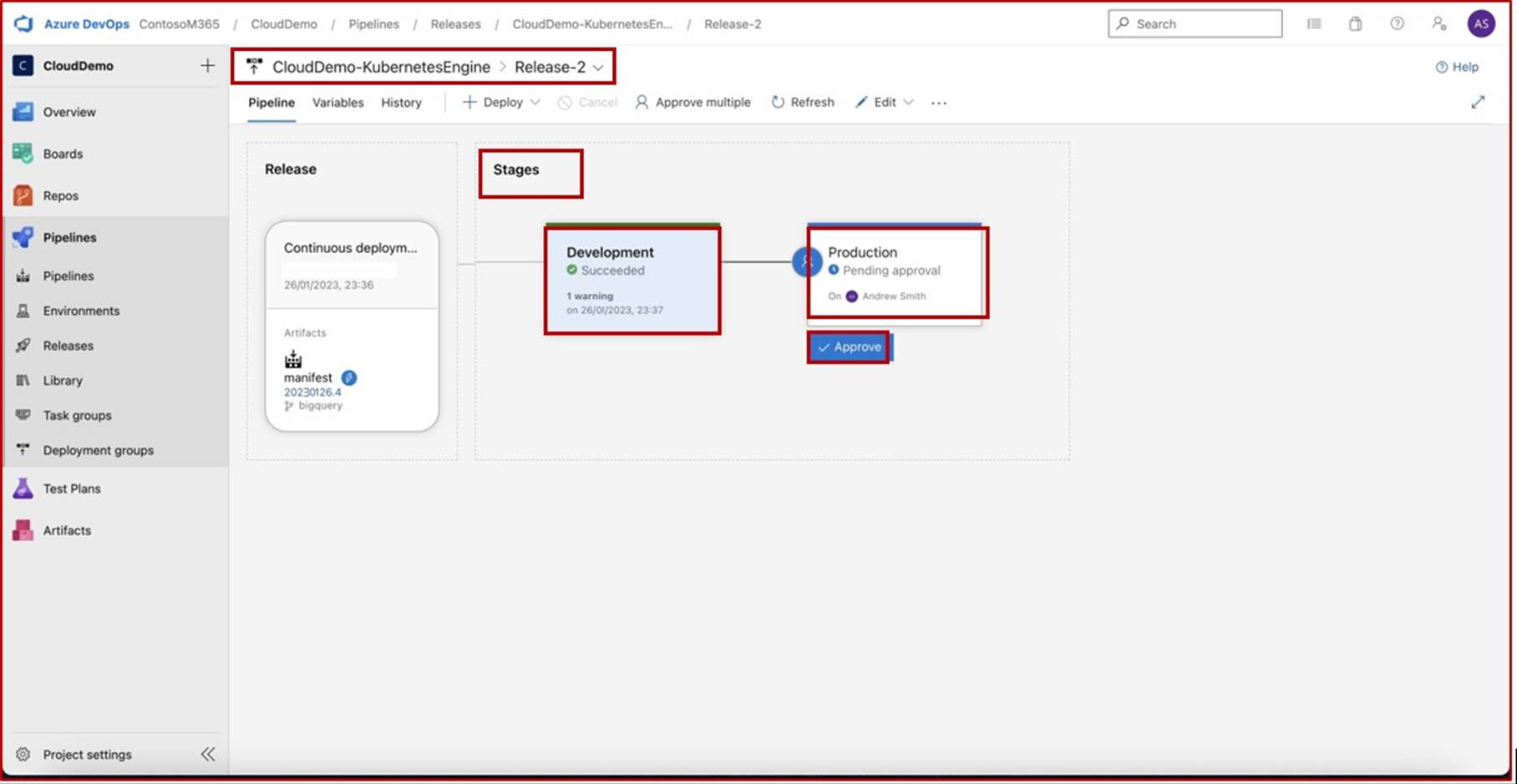
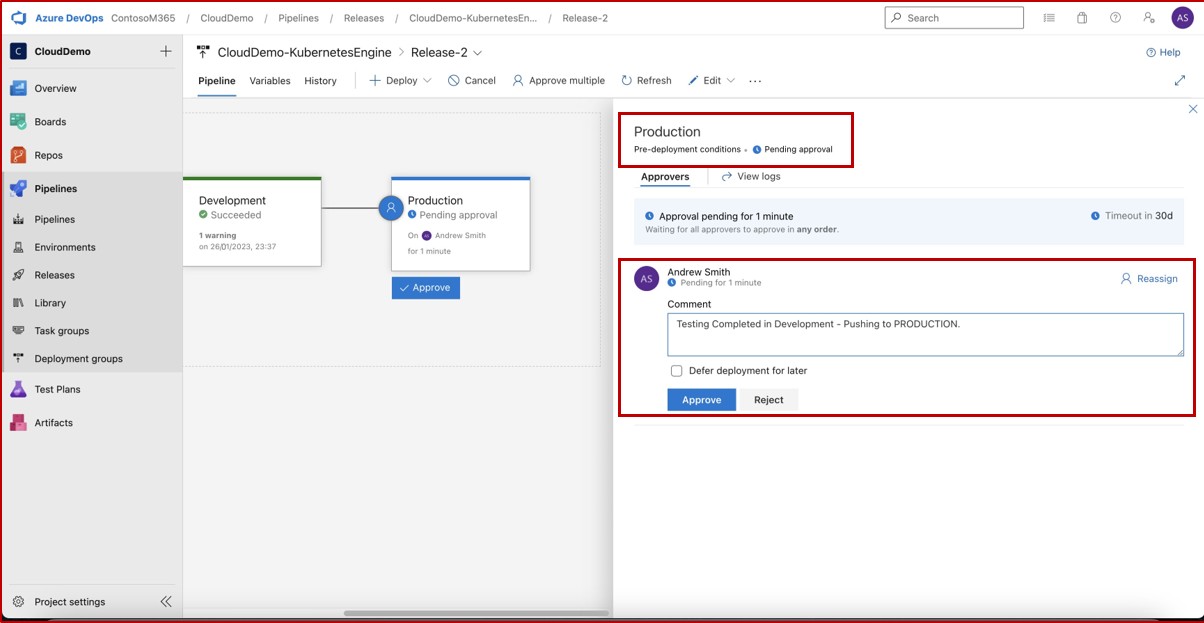
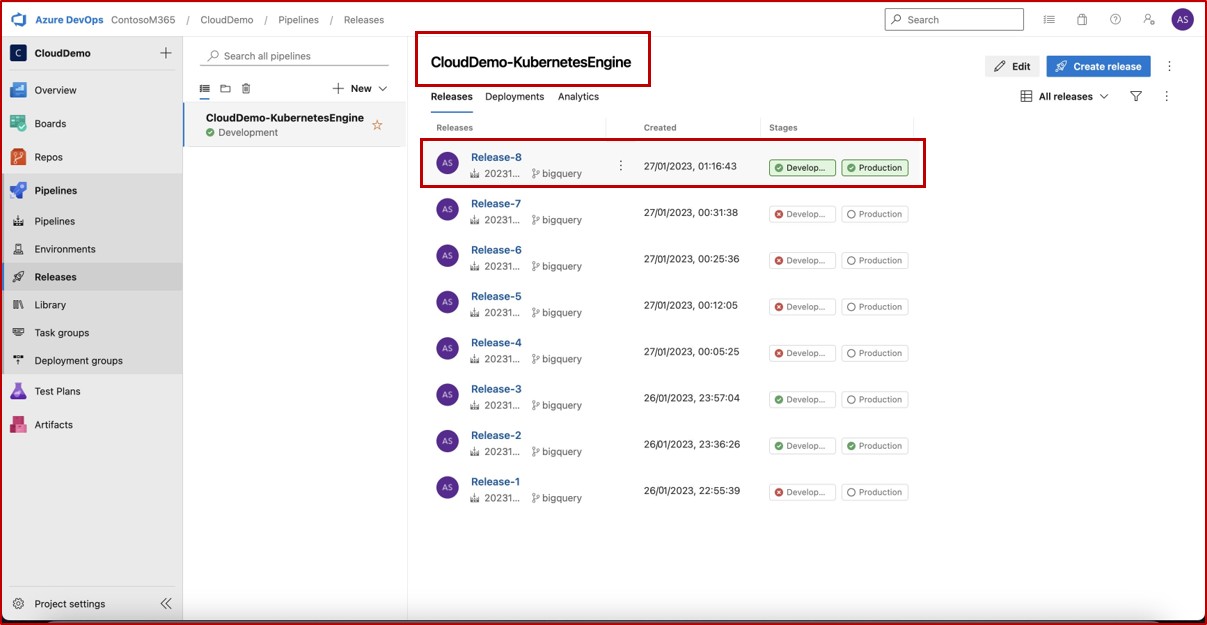
In the next screenshot we can see that a CI/CD pipeline is in use in Azure DevOps, the pipeline contains two stages: Development and Production. A release was triggered and successfully deployed into the Development environment but has not yet propagated into the second stage (Production) and that is pending approval from Andrew Smith.
The expectation is that once deployed to development, security testing occurs by the relevant team and only when the assigned individual with the right authority to review the deployment has performed a secondary review, and is satisfied that all conditions are met, will then grant approval which will allow the release to be made into production.
The email alert that would normally be received by the assigned reviewer informing that a pre-deployment condition was triggered and that a review and approval is pending.
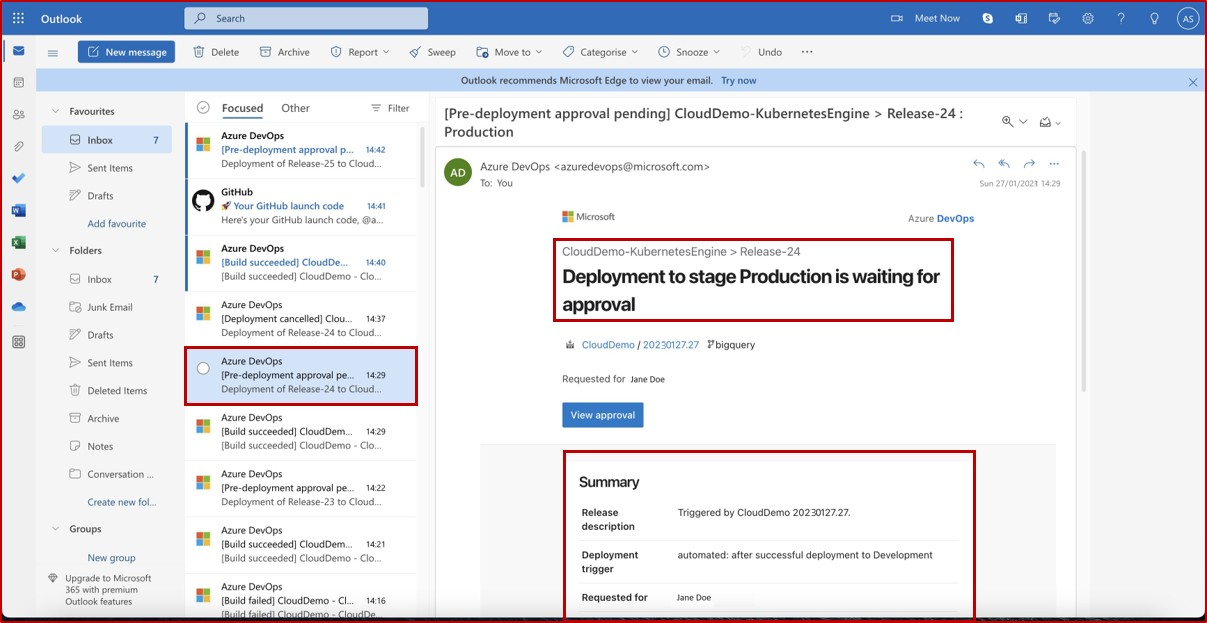
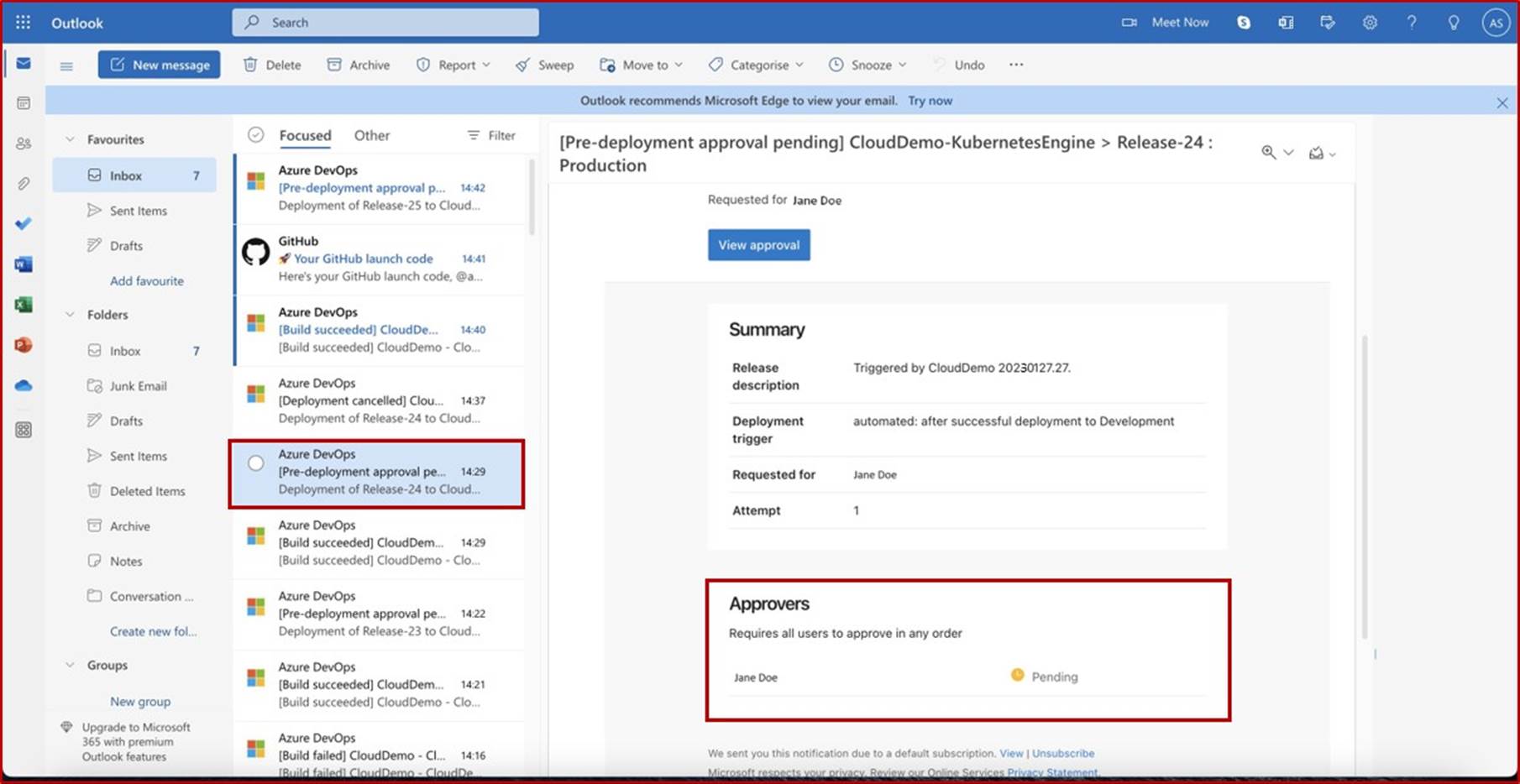
Using the email notification, the reviewer can navigate to the release pipeline in DevOps and grant approval. We can see following that comments are added justifying the approval.
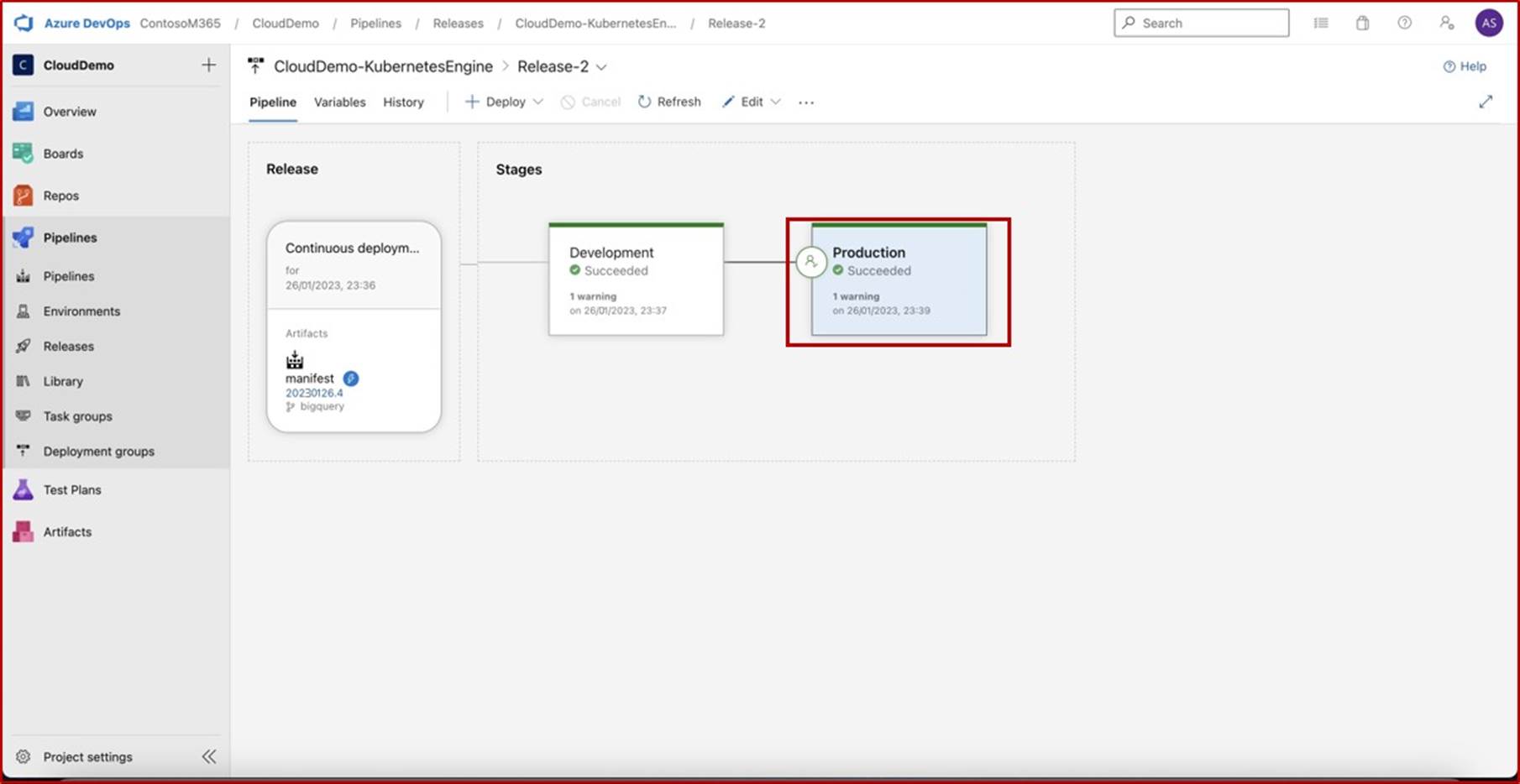
In the second screenshot it is shown that the approval was granted and that the release into production was successful.
The next two screenshots show a sample of the evidence that would be expected.
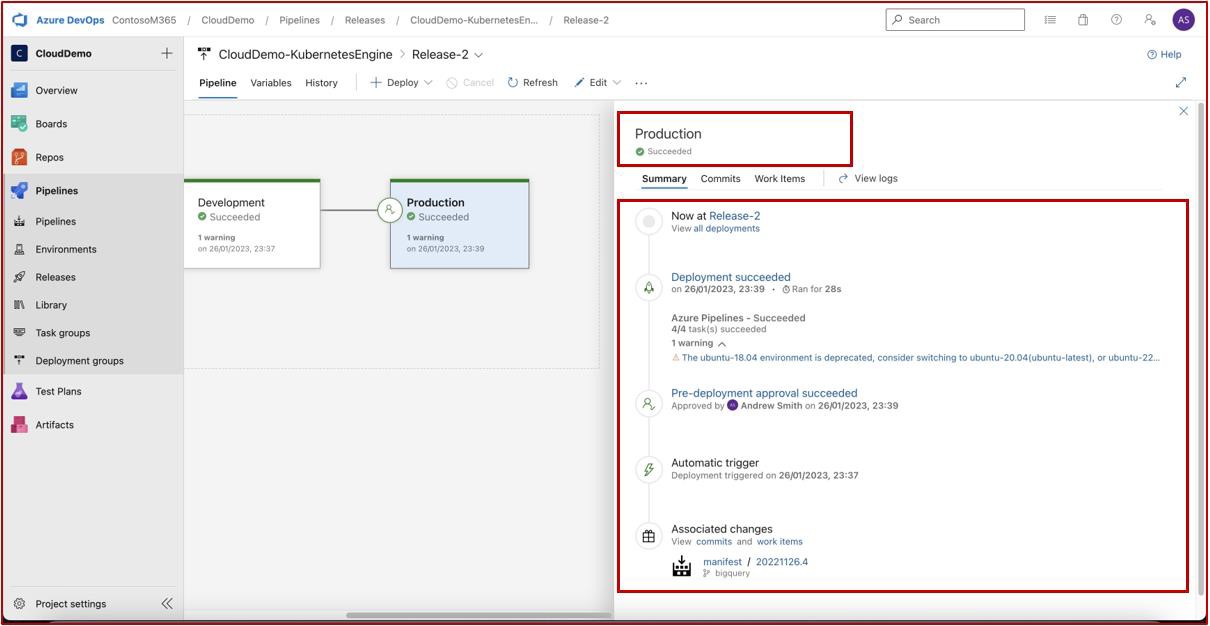
The evidence shows historical releases and that pre-deployment conditions are enforced, and a review and approval are required before deployment can be made to the Production environment.
Next screenshot shows history of releases including the recent release which we can see was successful deployed on both development and production.
Note: In the previous examples a full screenshot was not used, however ALL ISV submitted evidence screenshots must be full screenshots showing URL, any logged in user and system time and date.
Account management
Secure account management practices are important as user accounts form the basis of allowing access to information systems, system environments and data. User accounts need to be properly secured as a compromise of the user's credentials can provide not only a foothold into the environment and access to sensitive data but may also provide administrative control over the entire environment or key systems if the user's credentials have administrative privileges.
Control No. 14
Provide evidence that:
Default credentials are either disabled, removed, or changed across the sampled system components.
A process is in place to secure (harden) service accounts and that this process has been followed.
Intent: default credentials
Although this is becoming less popular, there are still instances where threat actors can leverage default and well documented user credentials to compromise production system components. A popular example of this is with Dell iDRAC (Integrated Dell Remote Access Controller). This system can be used to remotely manage a Dell Server, which could be leveraged by a threat actor to gain control over the Server’s operating system. The default credential of root::calvin is documented and can often be leveraged by threat actors to gain access to systems used by organizations. The intent of this control is to ensure that default credentials are either disabled or removed to enhance security.
Guidelines: default credentials
There are various ways in which evidence can be collected to support this control. Screenshots of configured users across all system components can help, i.e., screenshots of the Windows default accounts through command prompt (CMD) and for Linux /etc/shadow and /etc/passwd files will help to demonstrate if accounts have been disabled.
Example evidence: default credentials
The next screenshot shows the /etc/shadow file to demonstrate that default accounts have a locked password, and the new created/active accounts have a usable password.
Note, that the /etc/shadow file would be needed to demonstrate accounts are truly disabled by observing that the password hash starts with an invalid character such as '!' indicating that the password is unusable. In the next screenshots the “L” means lock the password of the named account. This option disables a password by changing it to a value which matches no possible encrypted value (it adds a! at the beginning of the password). The “P” means it is a usable password.
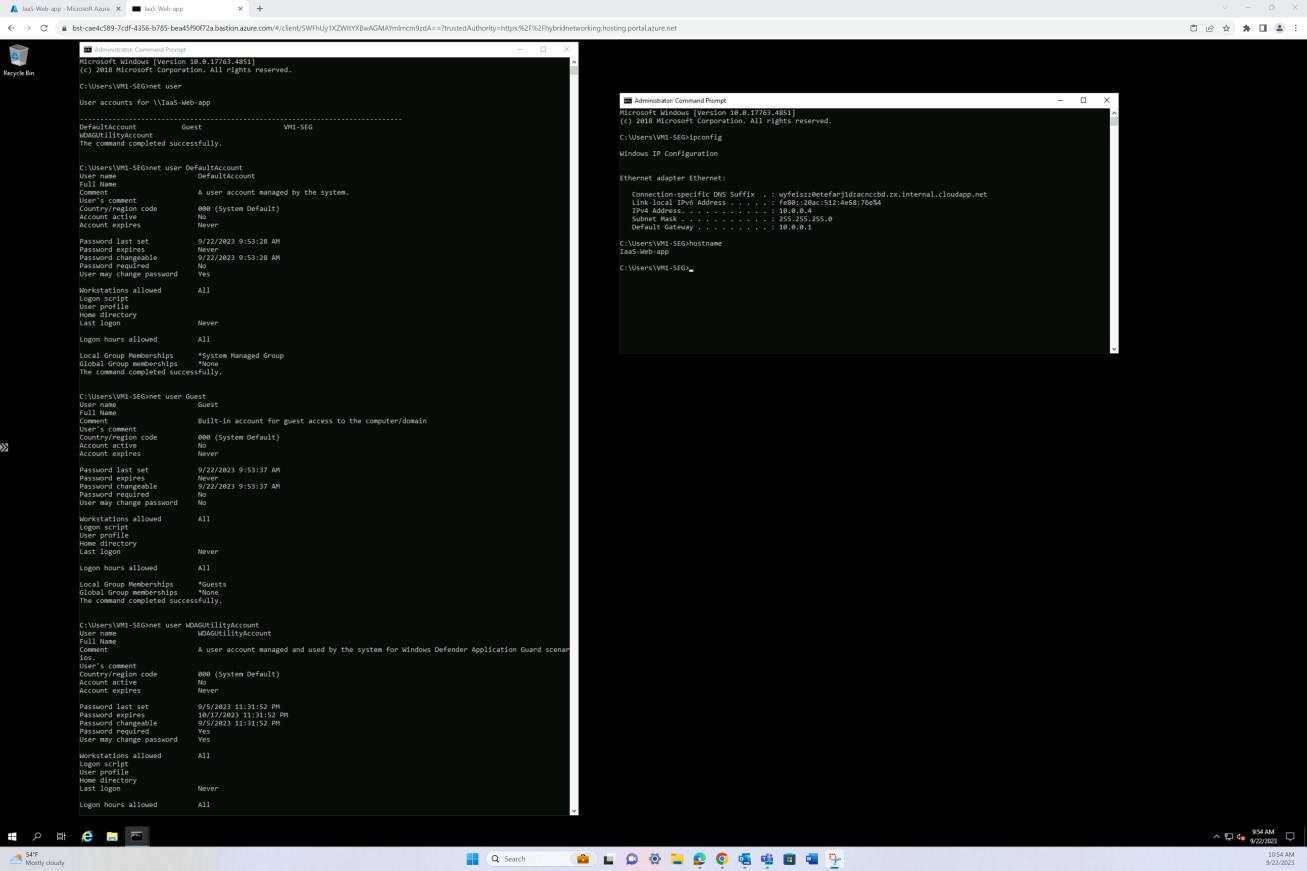
The second screenshot demonstrates that on the Windows server, all default accounts have been disabled. By using the ‘net user’ command on a terminal (CMD), you can list details of each of the existing accounts, observing that all these accounts are not active.
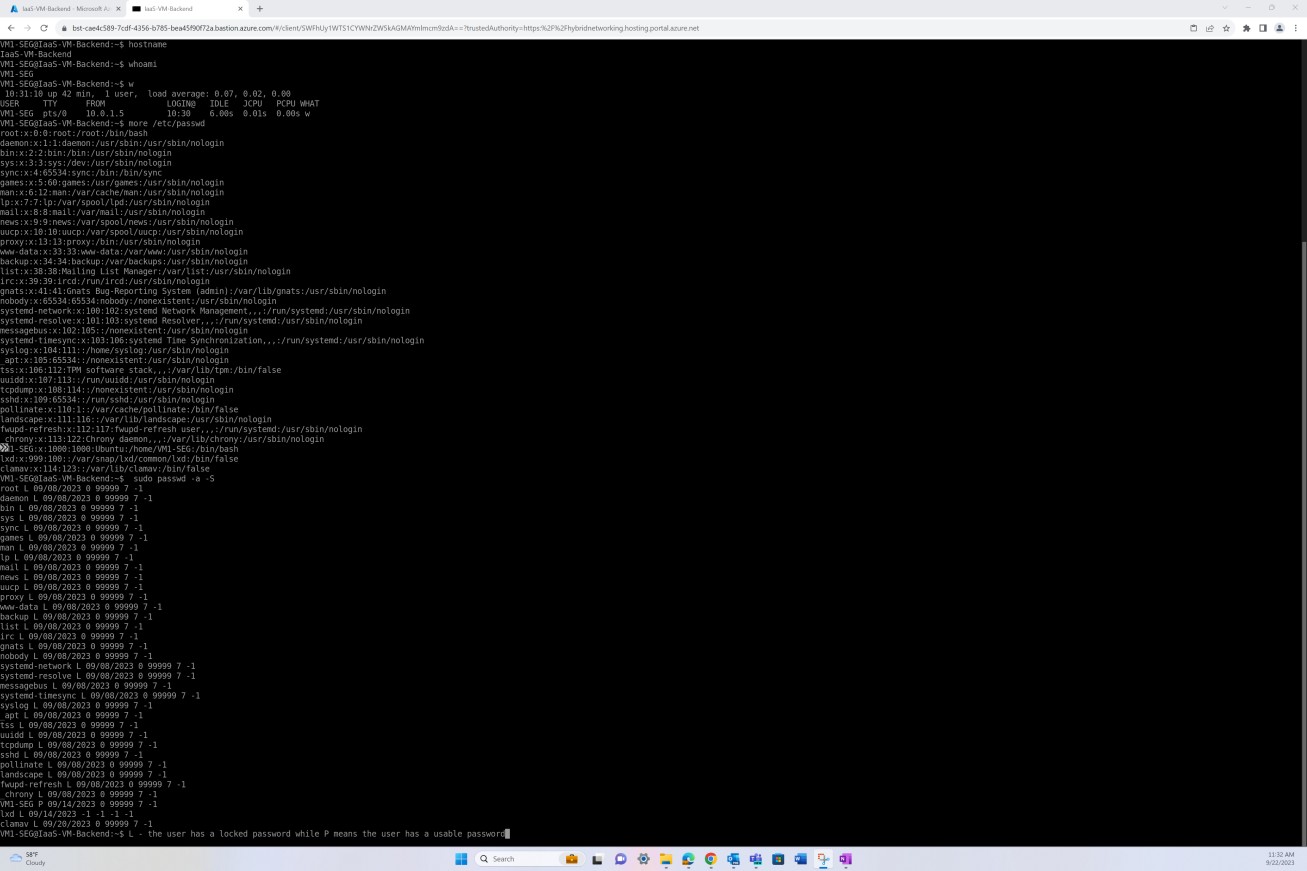
By using the net user command in CMD, you can display all accounts and observe that all default accounts are not active.
Intent: default credentials
Service accounts will often be targeted by threat actors because they are often configured with elevated privileges. These accounts may not follow the standard password policies because expiration of service account passwords often breaks functionality. Therefore, they may be configured with weak passwords or passwords that are reused within the organization. Another potential issue, particularly within a Windows environment, may be that the operating system caches the password hash. This can be a big problem if either:
the service account is configured within a directory service, since this account can be used access across multiple systems with the level of privileges configured, or
the service account is local, the likelihood is that the same account/password will be used across multiple systems within the environment.
The previous problems can lead to a threat actor gaining access to more systems within the environment and can lead to a further elevation of privilege and/or lateral movement. The intent therefore is to ensure that service accounts are properly hardened and secured to help protect them from being taken over by a threat actor, or by limiting the risk should one of these service accounts be compromised. The control requires that a formal process be in place for the hardening of these accounts, which may include restricting permissions, using complex passwords, and regular credential rotation.
Guidelines
There are many guides on the Internet to help harden service accounts. Evidence can be in the form of screenshots which demonstrate how the organization has implemented a secure hardening of the account. A few examples (the expectation is that multiple techniques would be used) include:
Restricting the accounts to a set of computers within Active Directory,
Setting the account so interactive sign in is not permitted,
Setting an extremely complex password,
For Active Directory, enable the "Account is sensitive and can't be delegated" flag.
Example evidence
There are multiple ways to harden a service account that will be dependent upon each individual environment. Following are some of the mechanisms that may be employed:
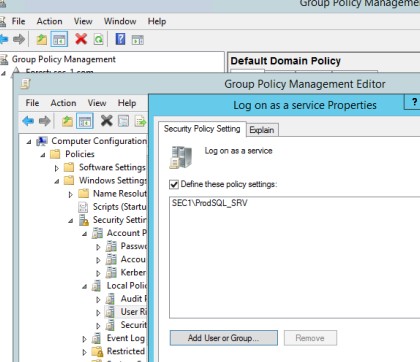
The next screenshot shows the 'Account is sensitive and connect be delegated' option is selected on the service account "_Prod SQL Service Account".
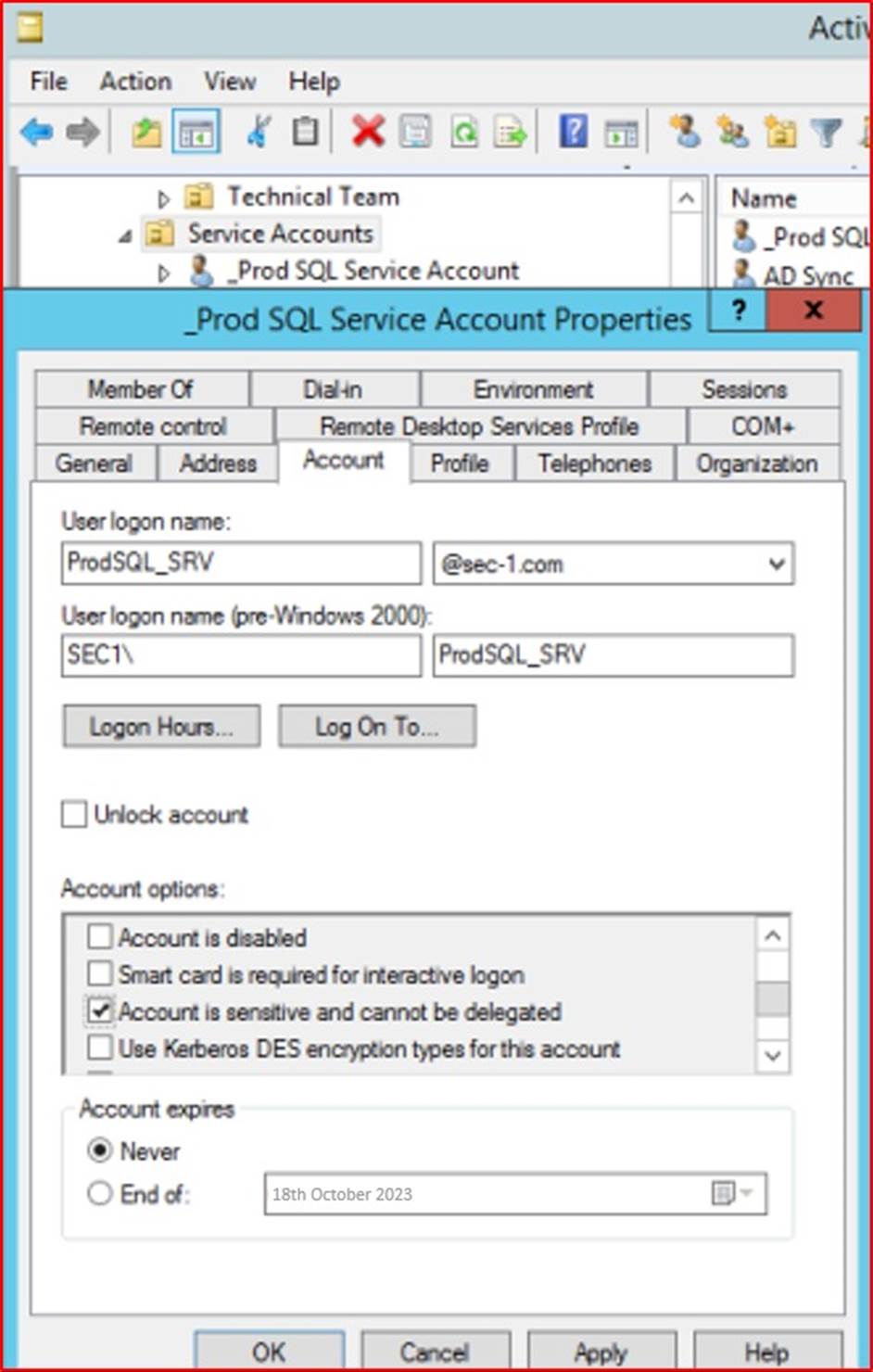
This second screenshot shows that the service account "_Prod SQL Service Account" is locked down to the SQL Server and can only sign in that server.
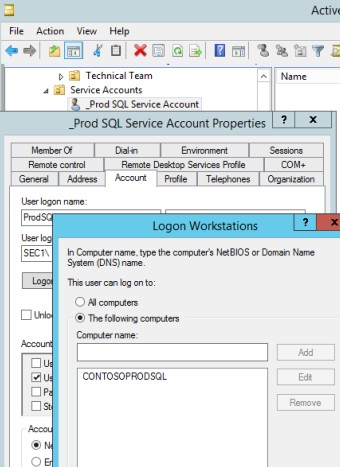
This next screenshot shows that the service account "_Prod SQL Service Account" is only allowed to sign in as a service.
Note: In the previous examples a full screenshot was not used, however ALL ISV submitted evidence screenshots must be full screenshots showing URL, any logged in user and system time and date.
Control No. 15
Provide evidence that:
Unique user accounts are issued to all users.
User least privilege principles are being followed within the environment.
A strong password/ passphrase policy or other suitable mitigations are in place.
A process is in place and followed at least every three months to either disable or delete accounts not used within 3 months.
Intent: secure service accounts
The intent of this control is accountability. By issuing users with their own unique user accounts, users will be accountable for their actions as user activity can be tracked to an individual user.
Guidelines: secure service accounts
Evidence would be by way of screenshots showing configured user accounts across the in-scope system components which may include servers, code repositories, cloud management platforms, Active Directory, Firewalls, etc.
Example evidence: secure service accounts
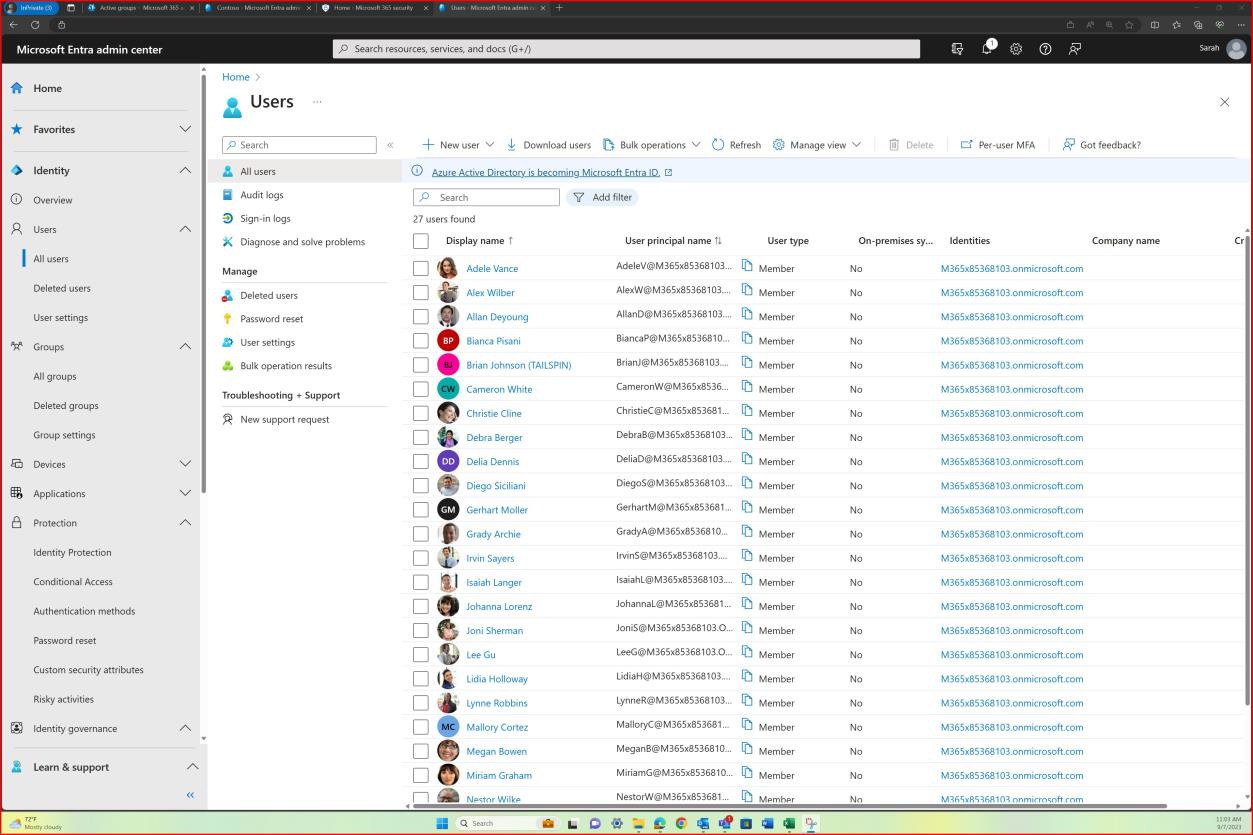
The next screenshot shows user accounts configured for the in-scope Azure environment and that all accounts are unique.
Intent: privileges
Users should only be provided with the privileges necessary to fulfil their job function. This is to limit the risk of a user intentionally or unintentionally accessing data they should not or carrying out a
malicious act. By following this principle, it also reduces the potential attack surface (i.e., privileged accounts) that can be targeted by a malicious threat actor.
Guidelines: privileges
Most organizations will utilize groups to assign privileges based upon teams within the organization. Evidence could be screenshots showing the various privileged groups and only user accounts from the teams that require these privileges. Usually, this would be backed up with supporting policies/processes defining each defined group with the privileges required and business justification and a hierarchy of team members to validate group membership is configured correctly.
For example: Within Azure, the Owners group should be very limited, so this should be documented and should have a limited number of people assigned to that group. Another example could be a limited number of staff with the ability to make code changes, a group may be setup with this privilege with the members of staff deemed as needing this permission configured. This should be documented so the certification analyst can cross reference the document with the configured groups, etc.
Example evidence: privileges
The next screenshots demonstrate the principle of least privilege in an Azure environment.
The next screenshot highlights the use of various groups in Azure Active Directory (AAD)/Microsoft Entra. Observe that there are three security groups, Developers, Lead Engineers, Security Operations.
Navigating to the “Developers” group, at group level the only assigned roles are “Application Developer” and “Directory readers”.
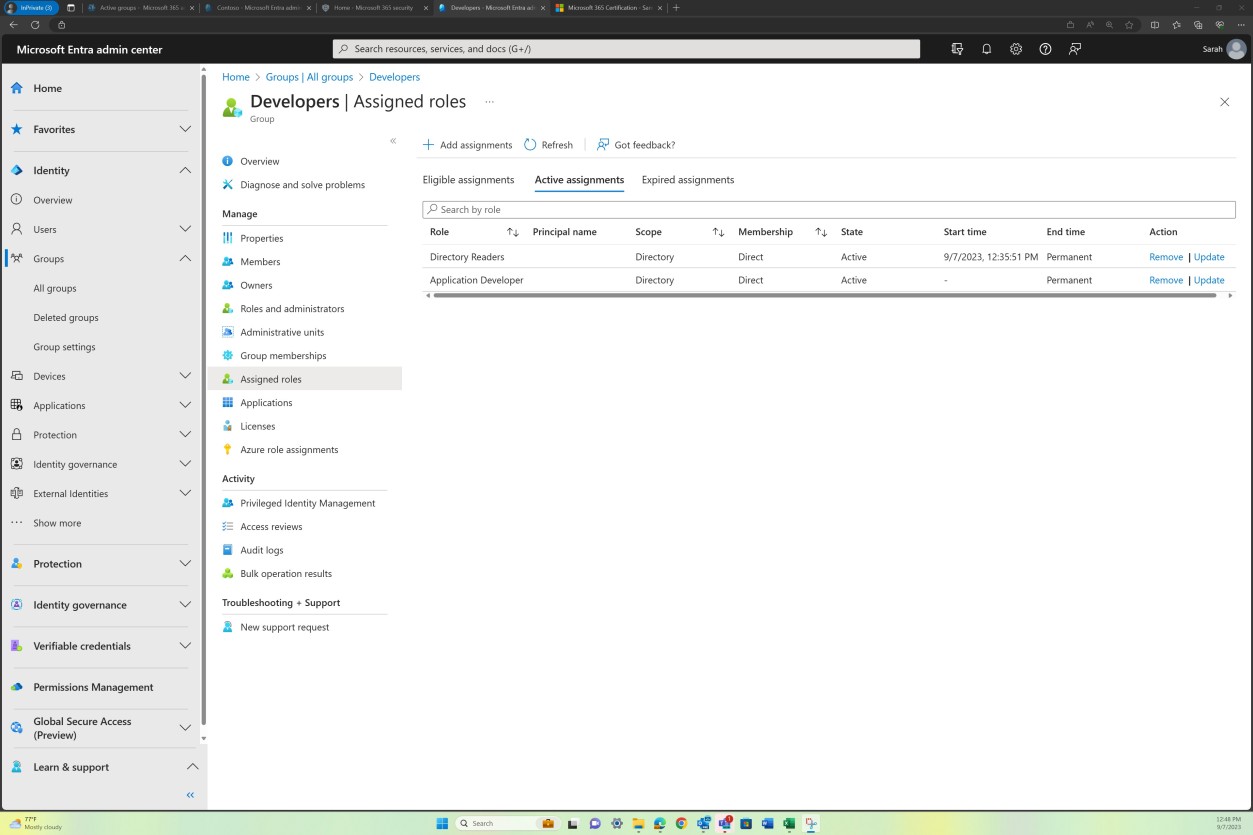
The next screenshot shows the members of the “Developers” group.
Finally, the next screenshot shows the Owner of the group.
In contrast with the “Developers” group the “Security Operations” has different roles assigned i.e., “Security Operator” which is in line with the job requirement.
The next screenshot shows that there are different members who are part of the “Security Operations” group.
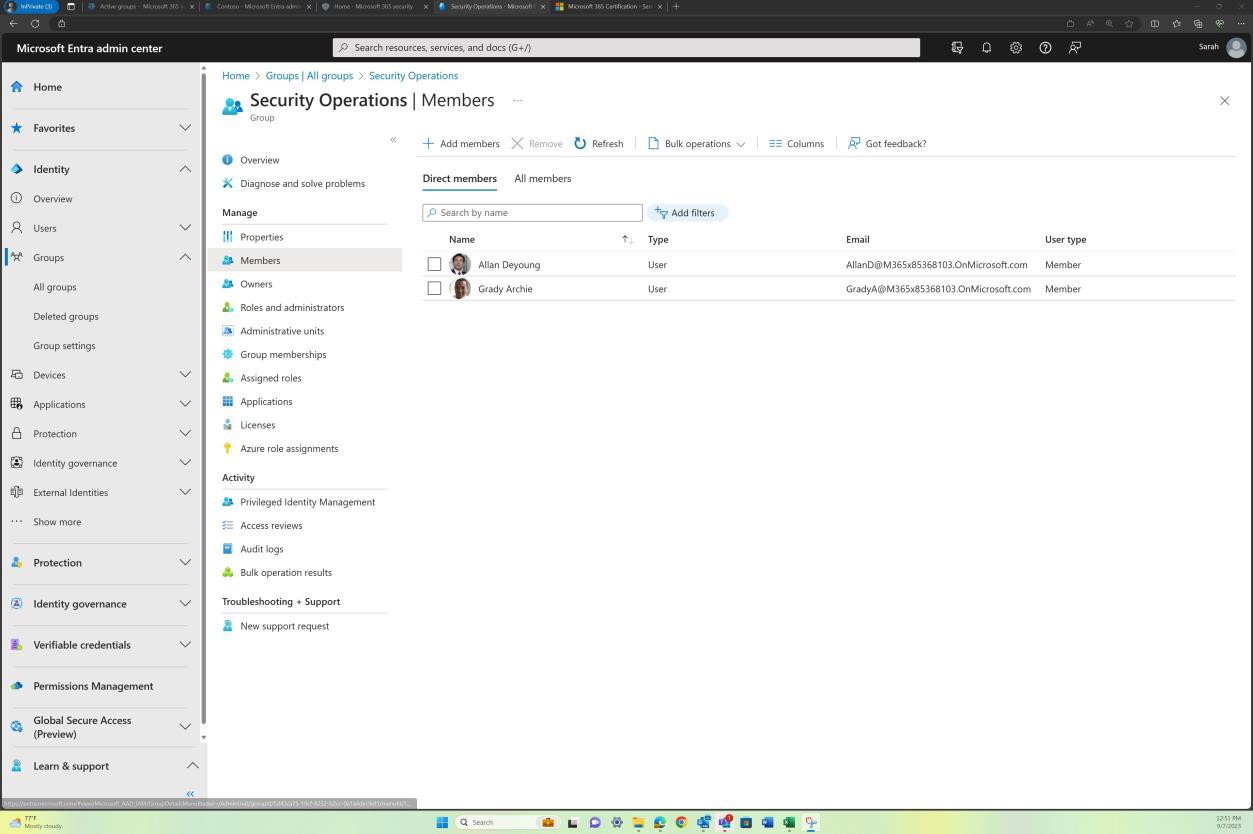
Finally, the group has a different Owner.
Global administrators are a highly privileged role and organizations must decide the level of risk they want to accept when providing this type of access. In the example provided there are only two users who have this role. This is to ensure that the attack surface and the impact is decreased.
Intent: password policy
User credentials are often the target of attack by threat actors attempting to gain access to an organization’s environment. The intent of a strong password policy is to try and force users into picking strong passwords to mitigate the chances of threat actors being able to brute force them. The intention of adding the “or other suitable mitigations” is to recognize that organizations may implement other security measures to help protect user credentials based on industry developments such as NIST Special Publication 800-63B.
Guidelines: password policy
Evidence to demonstrate a strong password policy may be in the form of a screenshot of an organizations Group Policy Object or Local Security Policy “Account Policies → Password Policy” and “Account Policies → Account Lockout Policy” settings. The evidence depends on the technologies being used, i.e., for Linux it could be the /etc/pam.d/common-password config file, for Bitbucket the “Authentication Policies” section within the Admin Portal [Manage your password policy | Atlassian Support, etc.
Example evidence: password policy
The evidence following shows the password policy configured within the “Local Security Policy” of the in- scope system component “CONTOSO-SRV1”.
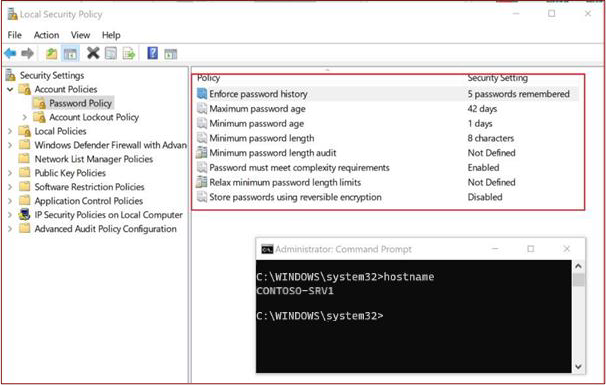
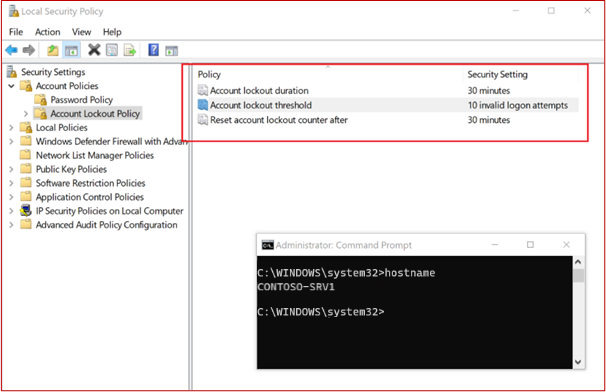
The next screenshot shows Account Lockout settings for a WatchGuard Firewall.
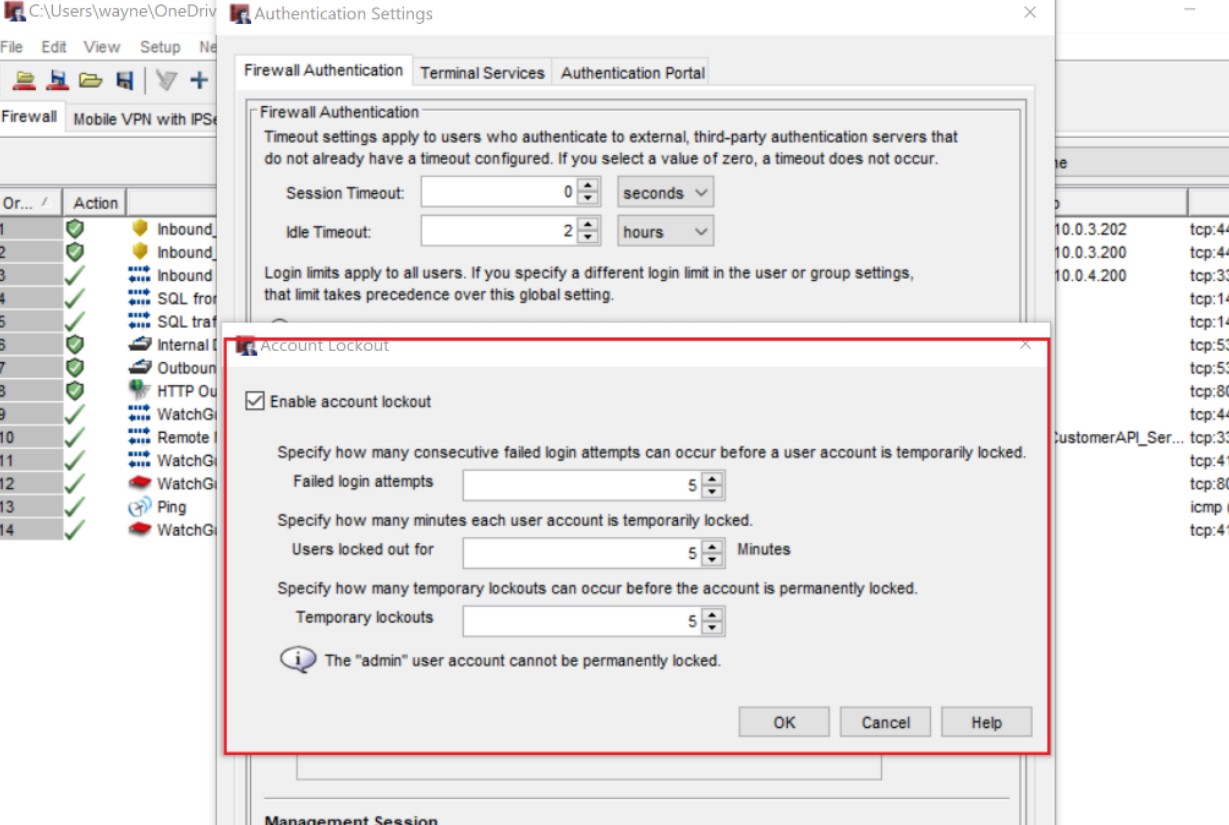
Following is an example of a minimum passphrase length for the WatchGuard Firewall.
Please Note: In the previous examples a full screenshot was not used, however ALL ISV submitted evidence screenshots must be full screenshots showing URL, any logged in user and system time and date.
Intent: inactive accounts
Inactive accounts can sometimes become compromised either because they are targeted in brute force attacks which may not be flagged as the user will not be trying to log into the accounts, or by way of a password database breach where a user’s password has been reused and is available within a username/password dump on the Internet. Unused accounts should be disabled/removed to reduce the attack surface a threat actor has to carry out account compromise activities. These accounts may be due to a leavers process not being carried out properly, a staff member going on long term sickness or a staff member going on maternity/paternity leave. By implementing a quarterly process to identify these accounts, organizations can minimize the attack surface.
This control mandates that a process must be in place and followed at least every three months to either disable or delete accounts that have not been used within the past three months aiming to reduce the risk by ensuring regular account reviews and timely deactivation of unused accounts.
Guidelines: inactive accounts
Evidence should be two-fold:
First, a screenshot or file export showing the “last logon” of all user accounts within the in- scope environment. This may be local accounts as well as accounts within a centralized directory service, such as AAD (Azure Active Directory). This will demonstrate that no accounts older than 3 months are enabled.
Second, evidence of the quarterly review process which may be documentary evidence of the task being completed within ADO (Azure DevOps) or JIRA tickets, or through paper records which should be signed off.
Example evidence: inactive accounts
The next screenshot demonstrates that a cloud platform has been utilized to perform access reviews. This has been accomplished by using the Identity Governance feature in Azure.
The next screenshot demonstrates the review history, review period and the status.
The dashboard and metrics form the review provide additional details such as the scope which is all users of the organization and the outcome of the review, as well as the frequency which is quarterly.
When assessing the results of the review, the image indicates a recommended action has been provided, which is based on pre-configured conditions. Additionally, it requires an assigned individual to manually apply the decisions of the review.
You can observe in the following that for every employee there is a recommendation and a justification provided. As mentioned a decision to accept the recommendation or ignore it before applying the review is required by an assigned individual. If the final decision is against the recommendation, then the expectation will be that evidence will be provided towards explaining why.
Control No. 16
Validate that multi-factor authentication (MFA) is configured for all remote access connections and all non-console administrative interfaces, including access to any code repositories and Cloud management interfaces.
Meaning of these terms
Remote Access – This refers to technologies used to access the supporting environment. For example, Remote Access IPSec VPN, SSL VPN or Jumpbox/Bastian Host.
Non-console Administrative Interfaces – This refers to the network administrative connections to system components. This could be over Remote Desktop, SSH or a web interface.
Code Repositories – The code base of the app needs to be protected against malicious modification which could introduce malware into the app. MFA needs to be configured on the code repositories.
Cloud Management Interfaces – Where some or all the environment is hosted within the Cloud Service Provider (CSP). The administrative interface for cloud management is included here.
Intent: MFA
The intent of this control is to provide mitigations against brute force attacks on privileged accounts with secure access into the environment by implementing multi-factor authentication (MFA). Even if a password is compromised, the MFA mechanism should still be secured ensuring that all access and administrative actions are only carried out by authorized and trusted staff members.
To enhance security, it is important to add an extra layer of security for both remote access connections and non-console administrative interfaces using MFA. Remote access connections are particularly vulnerable to unauthorized entry, and administrative interfaces control high-privilege functions, making both critical areas that require heightened security measures. Additionally, code repositories contain sensitive developmental work, and cloud management interfaces provide broad access to an organization’s cloud resources, making them additional critical points that should be secured with MFA.
Guidelines: MFA
Evidence needs to show MFA is enabled on all technologies that fit in the previous categories. This may be through a screenshot showing that MFA is enabled at the system level. By system level, we need evidence that it is enabled for all users and not just an example of an account with MFA enabled. Where the technology is backed off to an MFA solution, we need the evidence to demonstrate that it is enabled and in use. What is meant by this is; where the technology is setup for Radius Authentication, which points to an MFA provider, you also need to evidence that the Radius Server it is pointing to, is an MFA solution and that accounts are configured to utilize it.
Example evidence: MFA
The next screenshots demonstrate how an MFA Conditional policy can be implemented in AAD/Entra to enforce the two-factor authentication requirement across the organization. We can see in the following the policy is “on”.
The next screenshot shows that the MFA policy is to be applied to all users within the organization and that this is enabled.
The next screenshot demonstrates that access is granted upon meeting the MFA condition. On the right side of the screenshot, we can see that access will only be granted to a user once MFA is implemented.
Example evidence: MFA
Additional controls can be implemented such as an MFA registration requirement which ensures that upon registration users will be required to configure MFA before access is given to their new account. You can observe below the configuration of an MFA registration policy which is applied to all users.
In continuation of the screenshot previously which shows the policy to be applied without exclusions, the next screenshot demonstrates that all users are included in the policy.
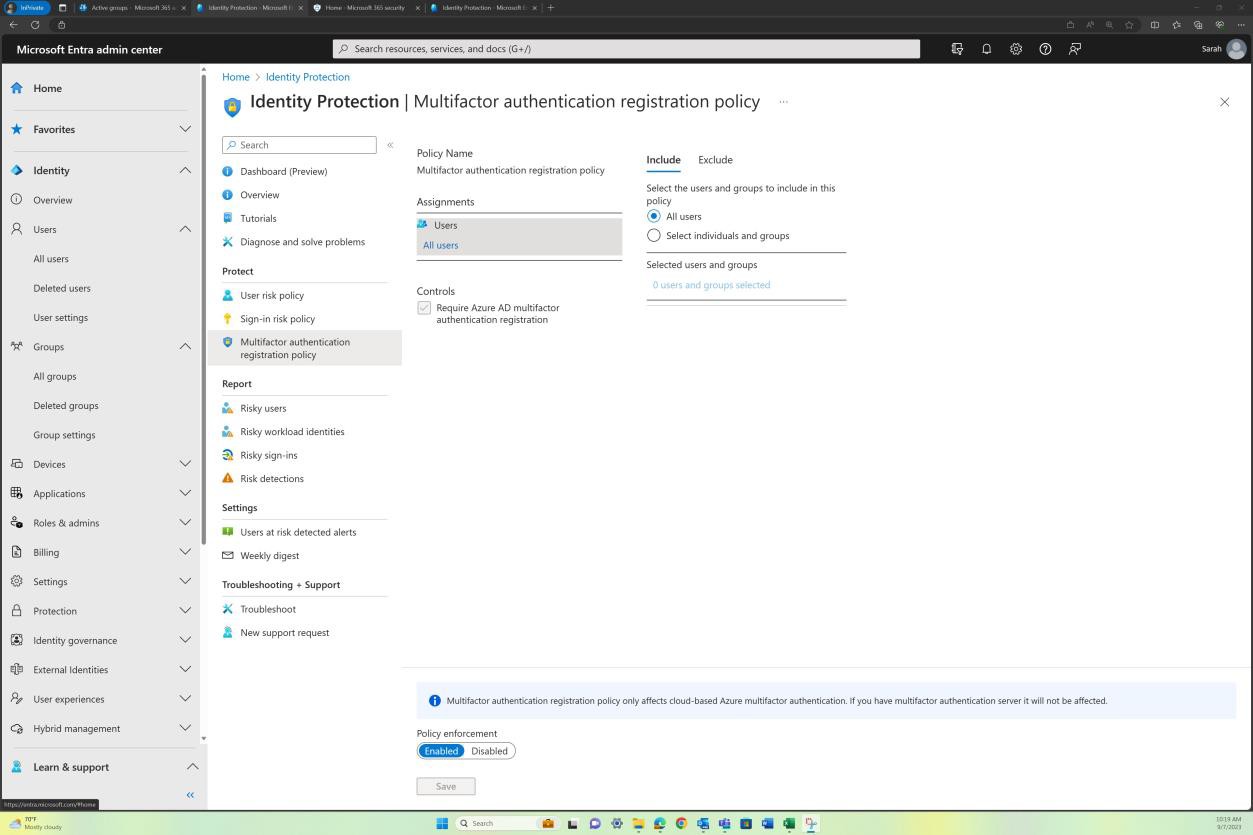
Example evidence: MFA
The next screenshot shows that the “per-user MFA” page is demonstrating that MFA is enforced for all users.
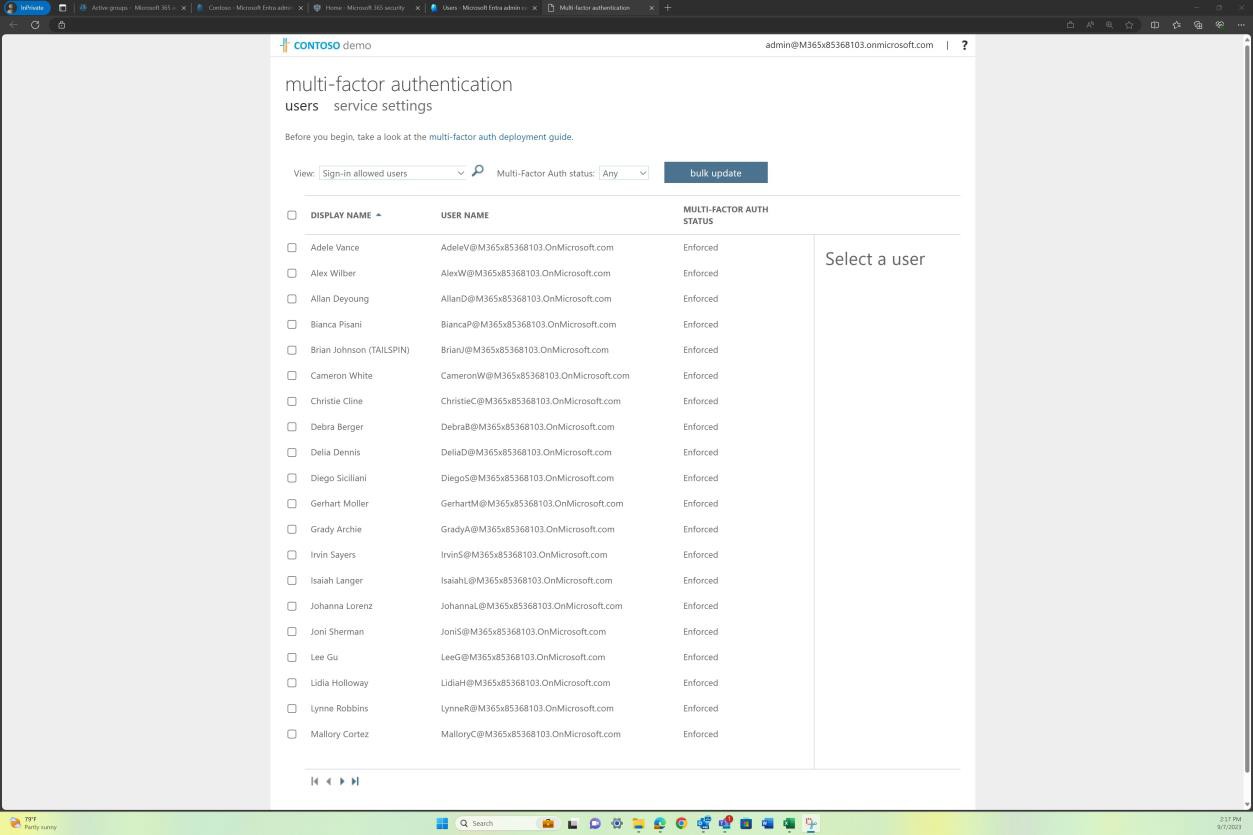
Example evidence: MFA
The next screenshots show the authentication realms configured on Pulse Secure which is used for remote access into the environment. Authentication is backed off by the Duo SaaS Service for MFA Support.
This screenshot demonstrates that an additional authentication server is enabled which is pointing to "Duo-LDAP" for the 'Duo - Default Route' authentication realm.
This final screenshot shows the configuration for the Duo-LDAP authentication server which demonstrates that this is pointing to the Duo SaaS service for MFA.
Note: In the previous examples a full screenshot was not used, however ALL ISV submitted evidence screenshots must be full screenshots showing URL, any logged in user and system time and date.
Security event logging, reviewing and alerting
Security event logging is an integral part of an organization’s security program. Adequate logging of security events coupled with tuned alerting and review processes help organizations to identify breaches or attempted breaches which can be used by the organization to enhance security and defensive security strategies. Additionally, adequate logging will be instrumental to an organizations incident response capability which can feed into other activities such as being able to accurately identify what and who's data has been compromised, the period of compromise, provide detailed analysis reports to government agencies, etc.
Reviewing security logs is an important function in helping organizations identify security events that may be indicative of a security breach or reconnaissance activities that may be an indication of something to come. This can either be done through a manual process daily, or by using a SIEM (Security Information and Event Management) solution which helps by analyzing audit logs, looking for correlations and anomalies which can be flagged for a manual inspection.
Critical security events need to be immediately investigated to minimize the impact to the data and operational environment. Alerting helps to immediately highlight potential security breaches to staff to ensure a timely response so the organization can contain the security event as quickly as possible. By ensuring alerting is working effectively, organizations can minimize the impact of a security breach, thus reducing the chance of a serious breach which could damage the organizations brand and impose financial losses through fines and reputational damage.
Control No. 17
Please provide evidence that security event logging is setup across the in-scope environment to log events where applicable such as:
User/s access to system components and the application.
All actions taken by a high-privileged user.
Invalid logical access attempts.
Privileged account creation / modification.
Event log tampering.
Disabling of security tools; for example, event logging.
Anti-Malware logging; for example, updates, malware detection, scan failures.
Intent: event logging
To identify attempted and actual breaches, it is important that adequate security event logs are being collected by all systems that make up the environment. The intent of this control is to ensure the correct types of security events are being captured which can then feed into review and alerting processes to help identify and respond to these events.
This subpoint requires an ISV to have set up security event logging to capture all instances of user access to system components and applications. This is critical for monitoring who is accessing the system components and applications within the organization and is essential for both security and audit purposes.
This subpoint requires that all actions taken by users with high-level privileges are logged. High- privileged users can make significant changes that could impact the security posture of the organization. Therefore, it is critical to maintain a record of their actions.
This subpoint requires the logging of any invalid attempts to gain logical access to system components or applications. Such logging is a primary way to detect unauthorized access attempts and potential security threats.
This subpoint requires logging any creation or modification of accounts with privileged access. This type of logging is crucial for tracking changes to accounts that have a high level of system access and could be targeted by attackers.
This subpoint requires logging of any attempts to tamper with event logs. Tampering with logs can be a way to hide unauthorized activities, and therefore it is vital that such actions are logged and acted upon.
This subpoint requires logging of any actions that disable security tools, including event logging itself. Disabling security tools can be a red flag indicating an attack or internal threat.
This subpoint requires the logging of activities related to anti-malware tools, including updates, malware detection, and scan failures. Proper functioning and updating of anti-malware tools are essential for an organization’s security and logs related to these activities help with the monitoring.
Guidelines: event logging
Evidence by way of screenshots or configuration settings should be provided across all the sampled devices and any system components of relevance to demonstrate how logging is configured to provide assurance that these types of security events are captured.
Example evidence
The next screenshots show the configurations of logs and metrics generated by different resources in Azure, which are then ingested into the centralized Log Analytic workspace.
We can see in the first screenshot that the log storage location is “PaaS-web-app-log-analytics”.
In Azure, diagnostic settings can be enabled on Azure resources for access to audit, security, and diagnostic logs as demonstrated below. Activity logs, which are automatically available, include event source, date, user, timestamp, source addresses, destination addresses, and other useful elements.
Please note: The following examples show a type of evidence that can be provided to meet this control. This is dependent on how your organization has setup the security event logging across the in-scope environment. Other examples can include Azure Sentinel, Datadog, etc.
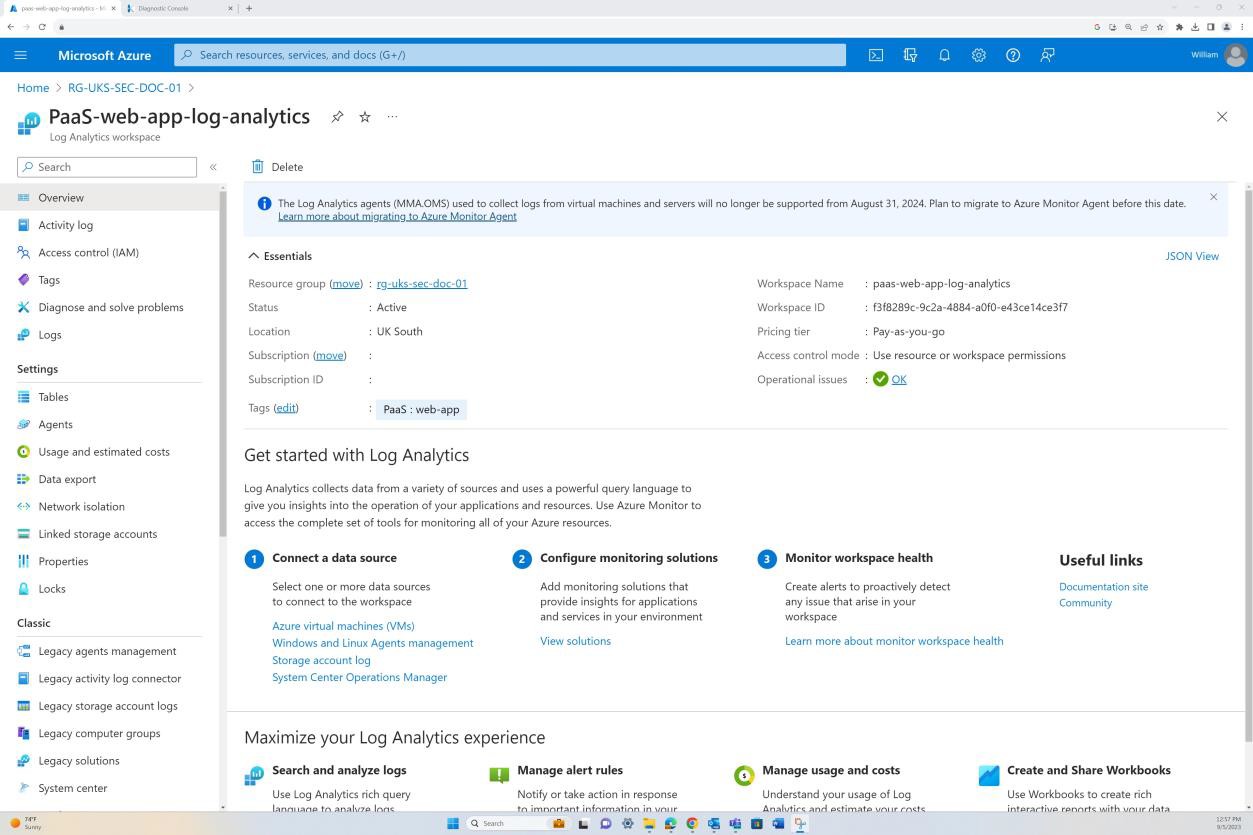
Using the “Diagnostic Settings” option for the web app hosted on Azure App Services you can configure what logs are generated and where those are sent for storage and analysis.
In the following screenshot ‘Access Audit logs’ and ‘IPSecurity Audit Logs’ are configured to be generated and captured to the Log Analytic workspace.
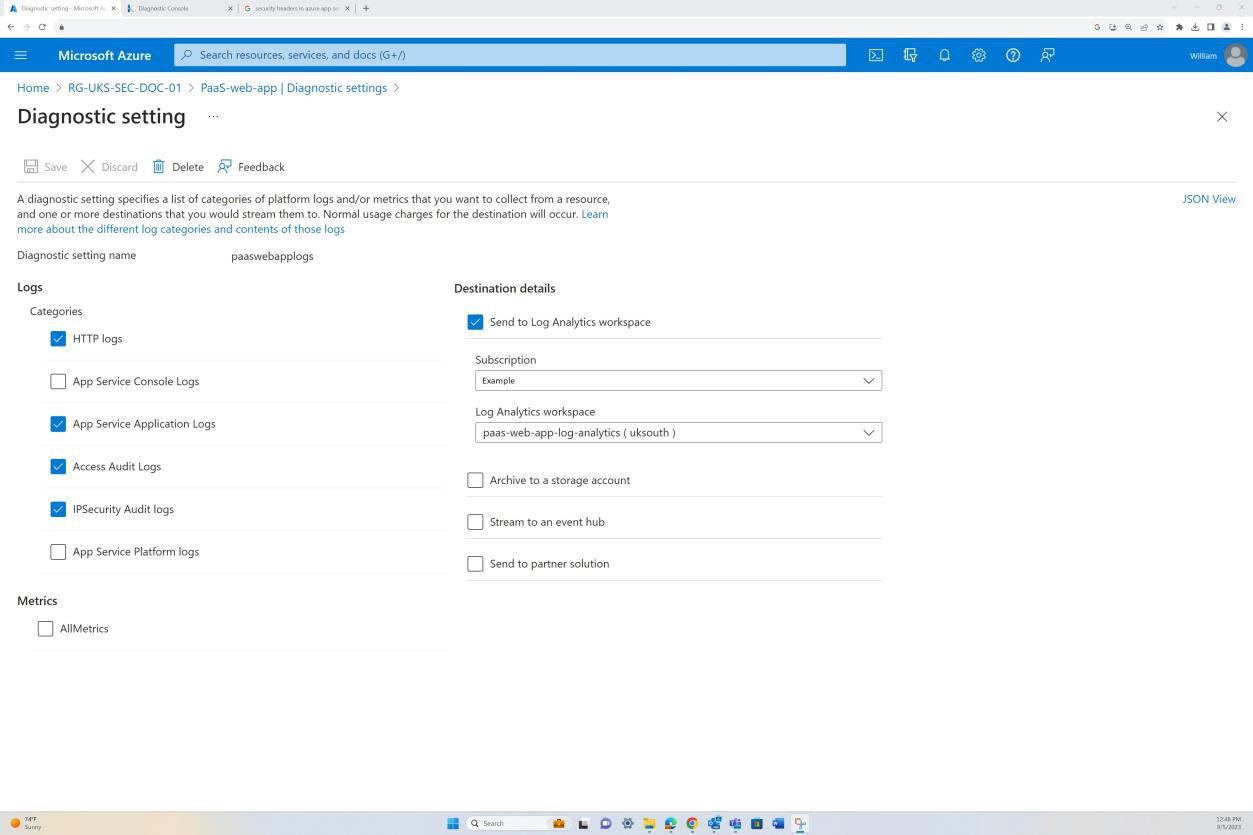
Another example is for Azure Front Door which is configured to send logs generated to the same centralized Log Analytic workspace.
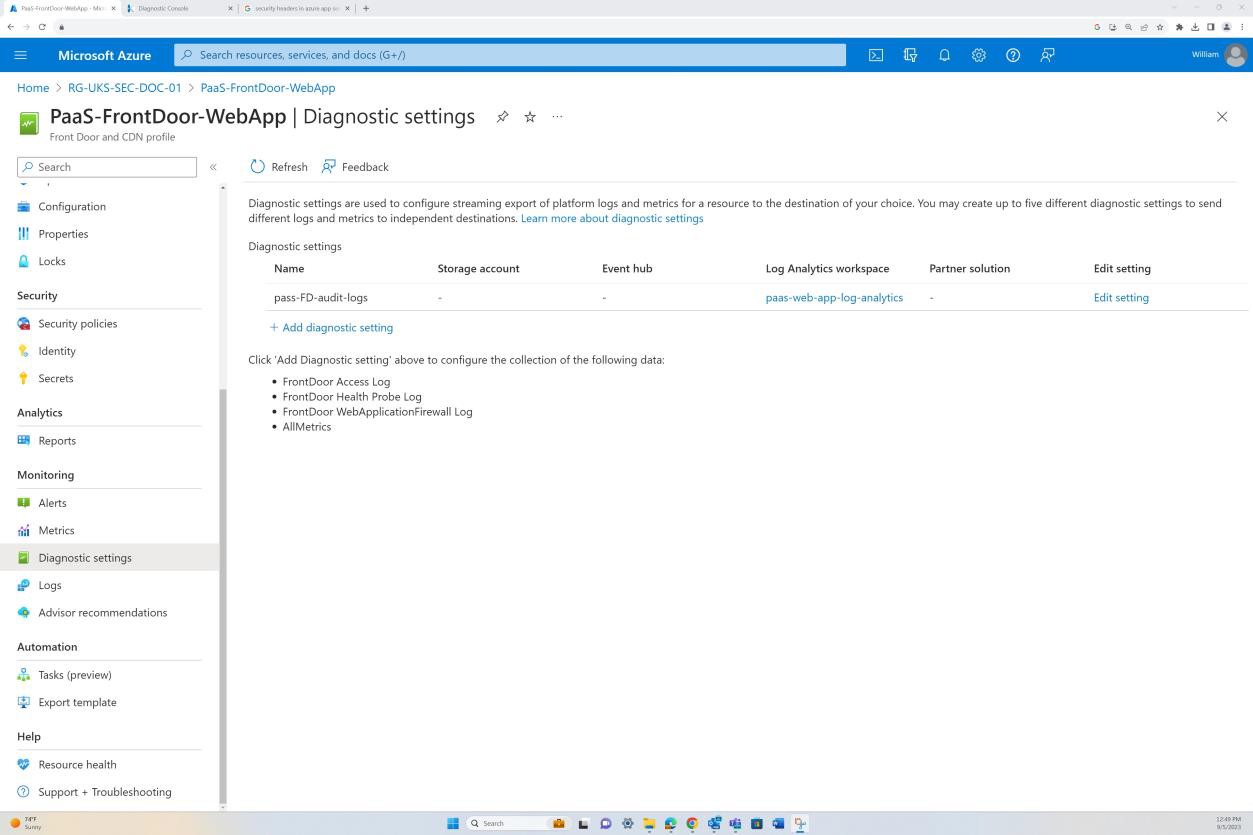
As before using the “Diagnostic Settings” option, configure what logs are generated and where those are sent for storage and analysis. The next screenshot demonstrates that ‘Access logs’ and ‘WAF logs’ have been configured.
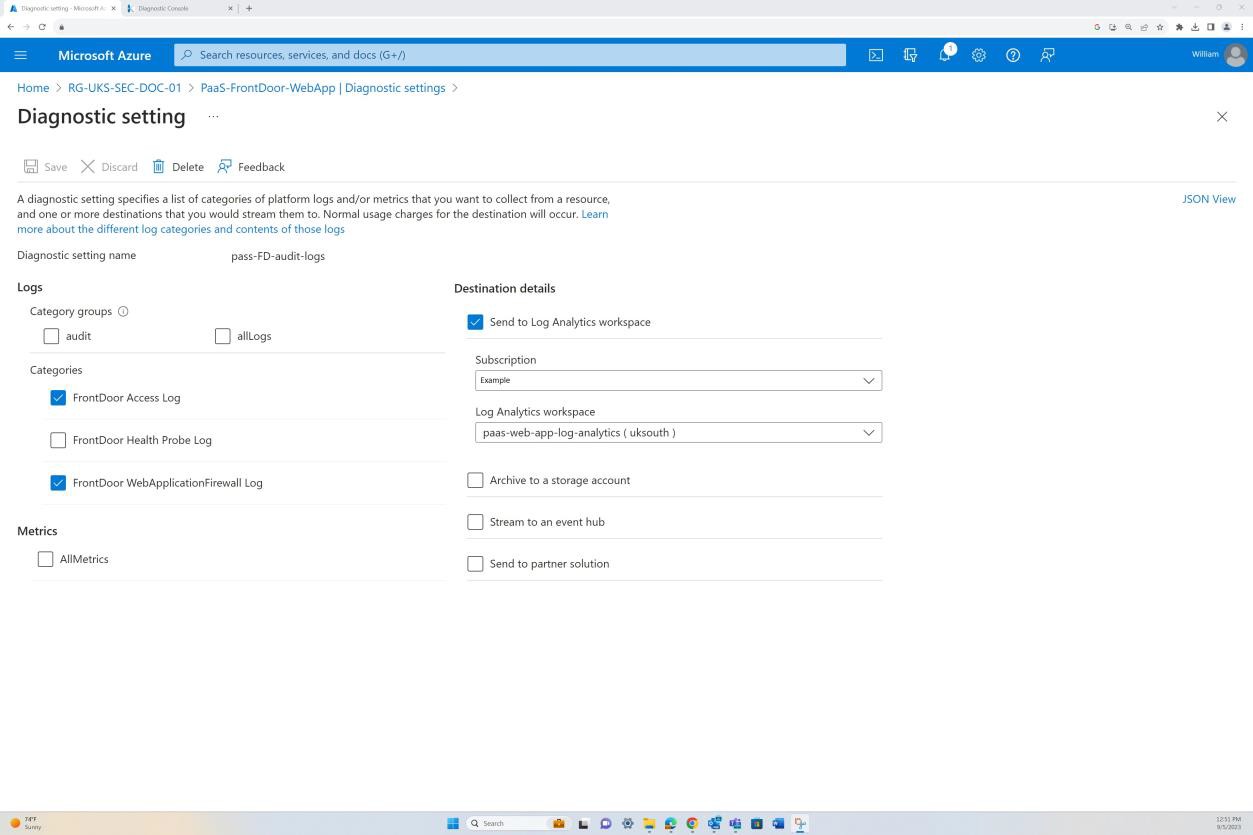
Similarly, for the Azure SQL Server, the “Diagnostic Settings” can configure what logs are generated and where those are sent for storage and analysis.
The following screenshot demonstrates that ‘audit’ logs for the SQL server are generated and sent to the Log Analytics workspace.
Example evidence
The following screenshot from AAD/Entra demonstrates that audit logs are being generated for privileged roles and administrators. The information includes status, activity, service, target, and initiator.
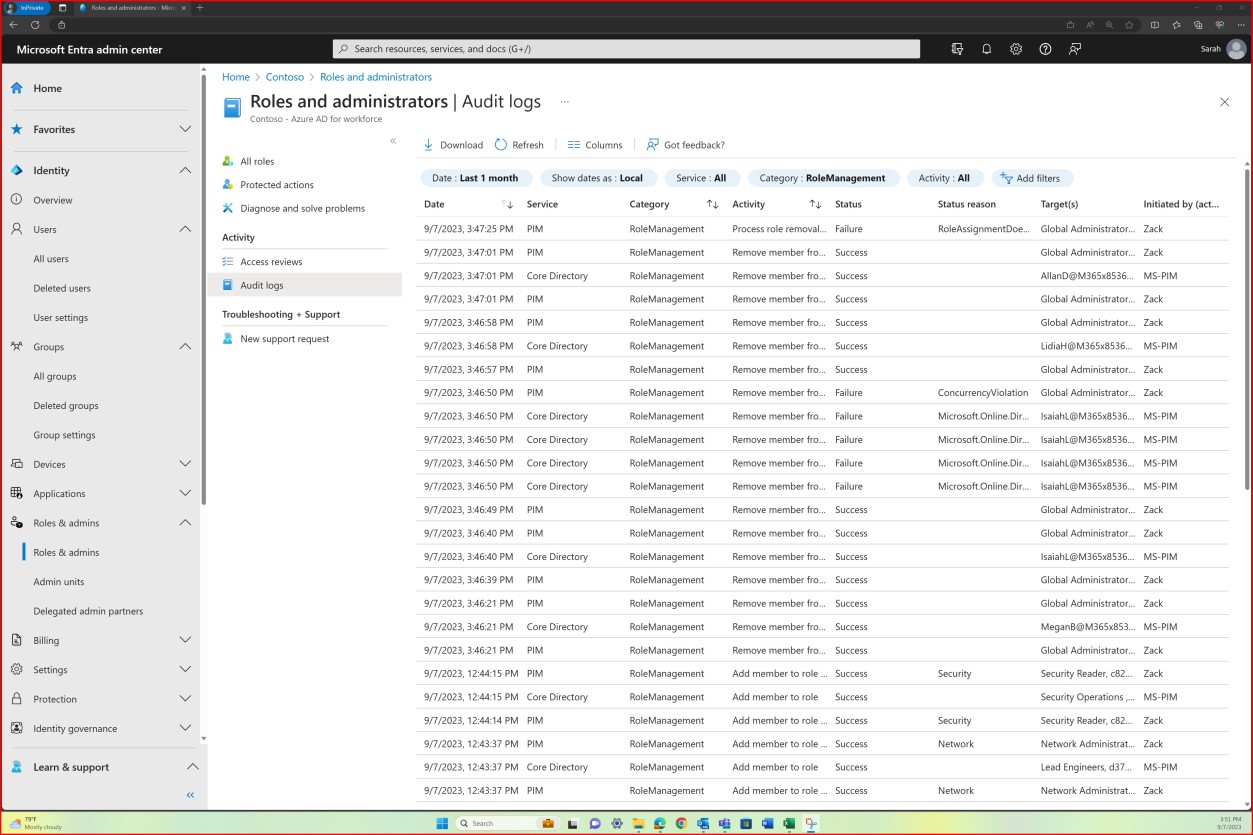
The following screenshot shows the sign-in logs. The log information includes IP address, Status, Location, and Date.
Example evidence
The next example focuses on logs generated for compute instances such as Virtual Machines (VMs). A data collection rule has been implemented and Windows event logs, including Security Audit logs are captured.
The following screenshot shows another example of configuration settings from a sampled device called "Galaxy-Compliance". The settings demonstrate the various auditing settings enabled within the ‘Local Security Policy’.
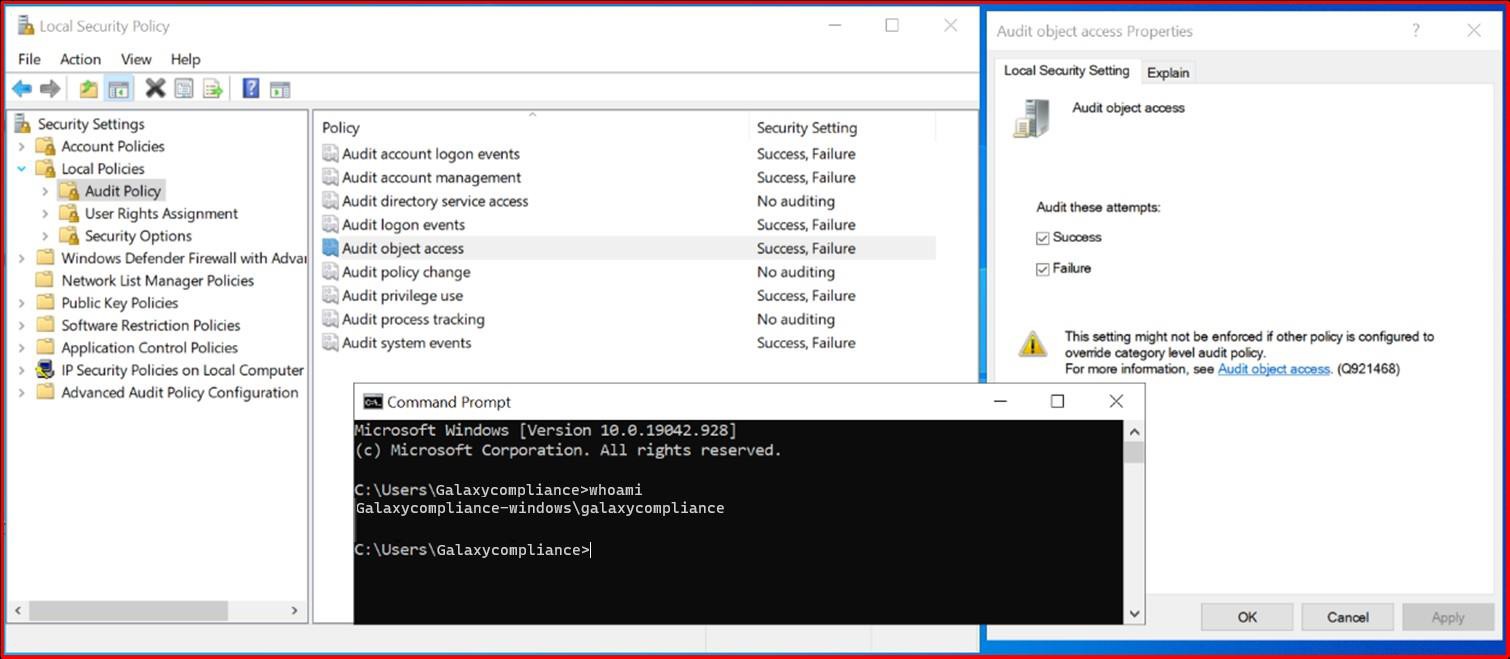
This next screenshot shows an event where a user has cleared the event log from the sampled device "Galaxy-Compliance".
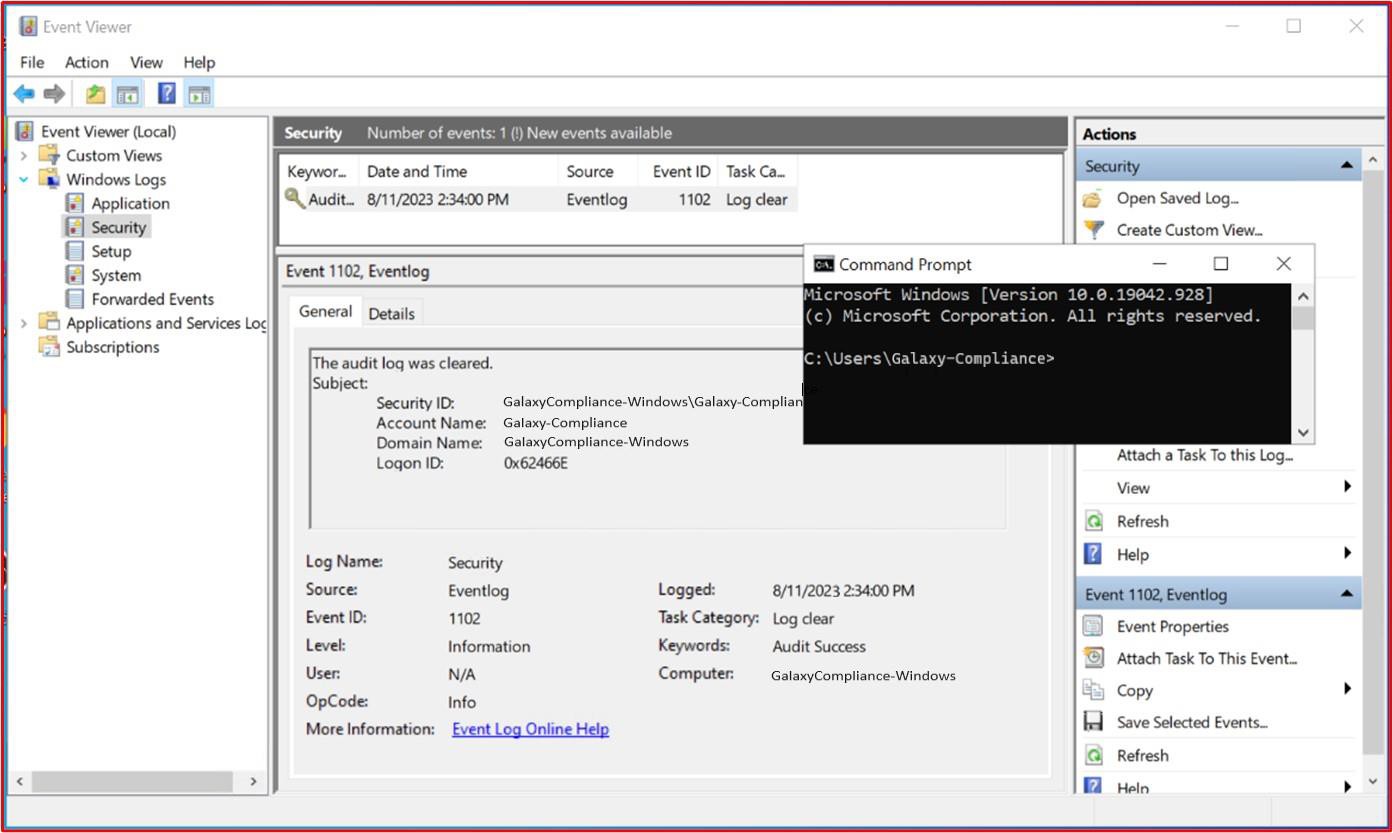
Please note: that the previous examples are not full screen screenshots, you will be required to submit full screen screenshots with any URL, logged in user and the time and date stamp for evidence review. If you are a Linux user this can be done via the command prompt.
Control No. 18
Provide evidence that a minimum of 30 days’ worth of security event logging data is immediately available, with 90 days of security event logs being retained.
Intent: event logging
Sometimes there is a gap in time between a compromise or security event and an organization identifying it. The intent of this control is to ensure the organization has access to historic event data to help with the incident response and any forensic investigation work that may be required. Ensuring the organization retains a minimum of 30 days' worth of security event logging data which is immediately available for analysis to facilitate rapid investigation and response to security incidents. Additionally, a total of 90 days’ worth of security event logs is retained to allow for an in-depth analysis.
Guidelines: event logging
Evidence will usually be by means of showing the centralized logging solution’s configuration settings, showing how long data is kept. 30 days’ worth of security event logging data needs to be immediately available within the solution. However, where data is archived needs to demonstrate that 90 days’ worth is available. This could be by showing archive folders with dates of exported data.
Example evidence: event logging
Following on from the previous example in Control 17 where a centralized Log Analytic workspace is in use to store all logs generated by the cloud resources, you can observe below that logs are being stored in individual tables for each log category. Additionally, the interactive retention for all tables is 90 days.
The next screenshot provides additional evidence demonstrating the configuration settings for the retention period of the Log Analytic workspace.
Example evidence
The following screenshots demonstrate that 30 days’ worth of logs are available within AlienVault.
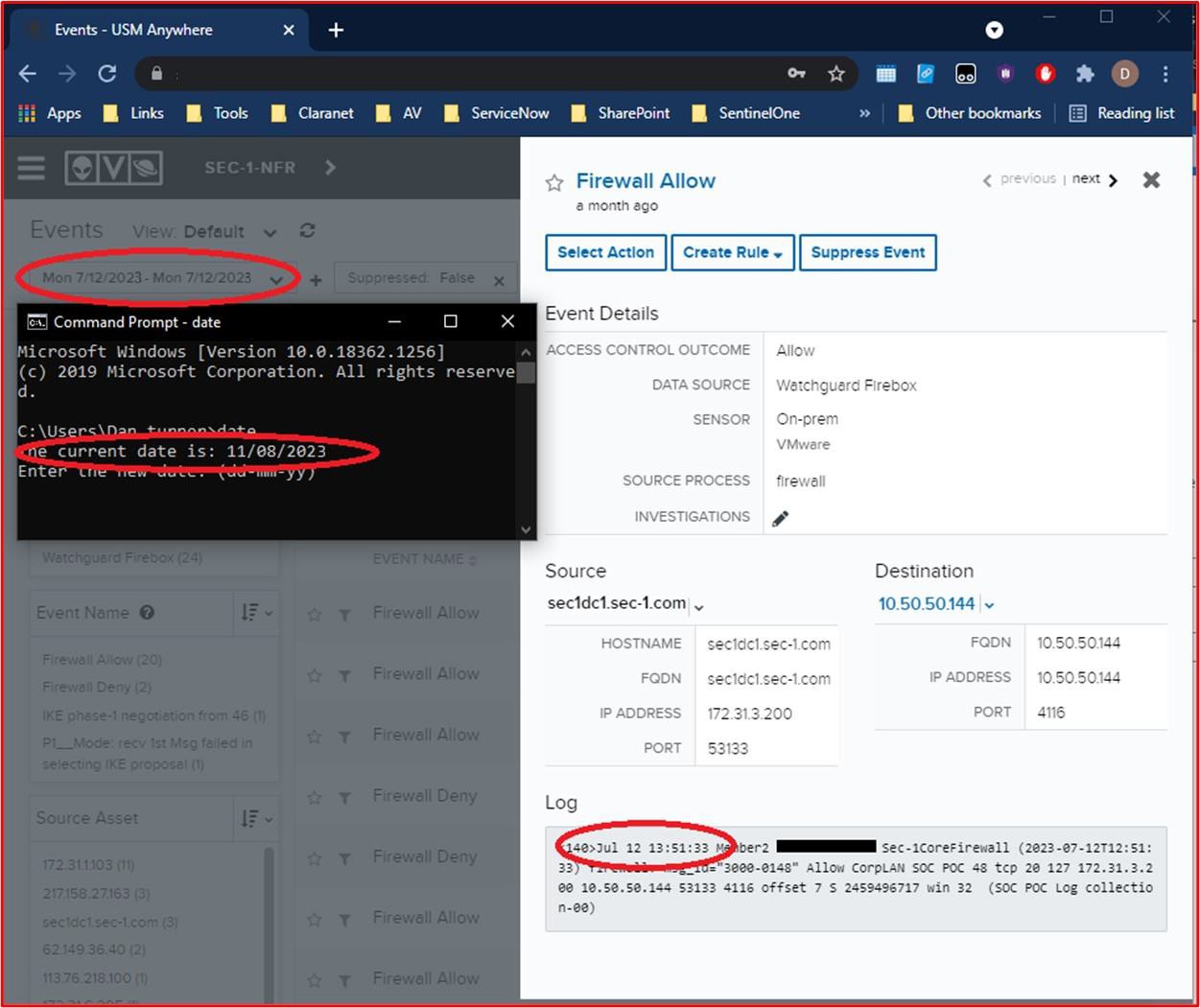
Note: Since this is a public facing document, the firewall serial number has been redacted, however, ISVs will be required to submit this information without redactions, unless it contains Personally Identifiable Information (PII) which must be disclosed to their analyst.
This next screenshot shows that logs are available by showing a log extract going back five months.
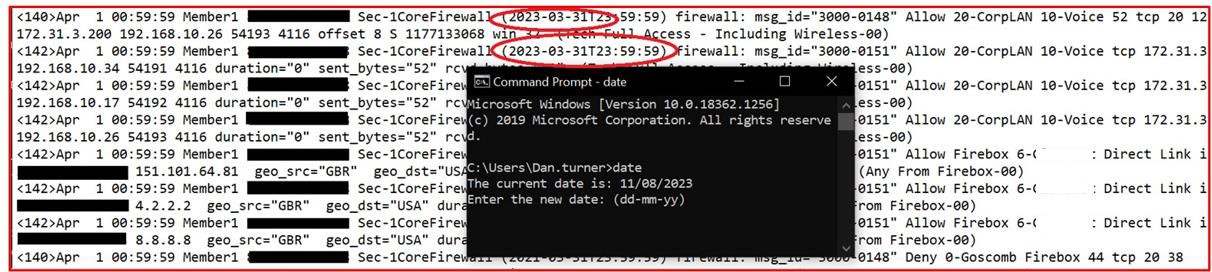
Note: Since this is a public facing document, the Public IP Addresses have been redacted, however, ISVs will be required to submit this information without any redactions, unless it contains Personally Identifiable Information (PII) which they must discuss with their analyst first.
Note: The previous examples are not full screen screenshots, you will be required to submit full screen screenshots with any URL, logged in user and the time and date stamp for evidence review. If you are a Linux user this can be done via the command prompt.
Example evidence
The next screenshot shows that log events are kept for 30 days available live and 90 days in cold storage within Azure.
Please note: The expectation will be that besides any configuration settings demonstrating the retention configured, a sample of logs from the 90-day period is supplied to validate that logs are retained for 90 days.
Please note: These examples are not full screen screenshots, you will be required to submit full screen screenshots with any URL, logged in user and the time and date stamp for evidence review. If you are a Linux user this can be done via the command prompt.
Control No. 19
Please provide evidence demonstrating that:
Logs are being reviewed periodically and any potential security events/anomalies identified during the review process are investigated and addressed.
Intent: event logging
The intent of this control is to ensure that periodic log reviews are being carried out. This is important to identify any anomalies that may not be picked up by the alerting scripts/queries that are configured to provide security event alerts. Also, any anomalies that are identified during the log reviews are investigated, and appropriate remediation or action is carried out. This will usually involve a triage process to identify if the anomalies require action and then may need to invoke the incident response process.
Guidelines: event logging
Evidence would be provided by screenshots, demonstrating that log reviews are being conducted. This may be by way of forms which are completed each day, or by way of a JIRA or DevOps ticket with
relevant comments being posted to show this is carried out. If any anomalies are flagged, this can be documented within this same ticket to demonstrate that anomalies identified as part of the log review are followed up on and then detailing what activities were carried out afterwards. This may prompt a specific JIRA ticket being raised to track all activities being carried out, or it may just be documented within the log review ticket. If an incident response action is required, then this should be documented as part of the incident response process and evidence should be provided to demonstrate this.
Example evidence: event logging
This first screenshot identifies where a user has been added to the ‘Domain Admins’ group.

This next screenshot identifies where multiple failed logon attempts are then followed by a successful login which may highlight a successful brute force attack.

This final screenshot identifies where a password policy change has occurred setting the policy, so account passwords don’t expire.

This next screenshot shows that a ticket is automatically raised within the SOC’s ServiceNow tool, triggering the previous rule above.
Please note: These examples are not full screen screenshots, you will be required to submit full screen screenshots with any URL, logged in user and the time and date stamp for evidence review. If you are a Linux user this can be done via the command prompt.
Control No. 20
Please provide evidence demonstrating that:
Alert rules are configured so that alerts are triggered for investigation for the following security events where applicable:
Privileged account creation/ modifications.
Privileged/High risk activities or operations.
Malware events.
Event log tampering.
IDPS/WAF events (if configured).
Intent: alerts
These are some types of security events which could highlight a security event has occurred which may point to an environment breach and/or data breach.
This subpoint is to ensure that alert rules are specifically configured to trigger investigations upon the creation or modification of privileged accounts. In the case of privileged account creation or modifications, logs should be generated, and alerts should be triggered whenever a new privileged account is created, or existing privileged account permissions are altered. This helps in tracking any unauthorized or suspicious activities.
This subpoint aims to have alert rules set to notify appropriate personnel when privileged or high- risk activities or operations are conducted. For privileged or high-risk activities or operations, alerts must be set up to notify appropriate personnel when such activities are initiated. This could include changes to firewall rules, data transfers, or access to sensitive files.
The intent of this subpoint is to mandate the configuration of alert rules that are triggered by malware-related events. Malware events should not only be logged but should also trigger an immediate alert for investigation. These alerts should be designed to include details like origin, nature of malware, and affected system components to expedite the response time.
This subpoint is designed to ensure that any tampering with event logs triggers an immediate alert for investigation. Regarding event log tampering, the system should be configured to trigger alerts when unauthorized access to logs or modifications of logs are detected. This ensures the integrity of event logs, which are crucial for forensic analysis and compliance audits.
This subpoint intends to ensure that, if Intrusion Detection and Prevention Systems (IDPS) or Web Application Firewalls (WAF) are configured, they are set to trigger alerts for investigation. If Intrusion Detection and Prevention Systems (IDPS) or Web Application Firewalls (WAF) are configured, they should also be set to trigger alerts for suspicious activities such as repeated login failures, SQL injection attempts, or patterns suggesting a denial-of-service attack.
Guidelines: alerts
Evidence should be provided by means of screenshots of the alerting configuration AND evidence of the alerts being received. The configuration screenshots should show the logic that is triggering the alerts and how the alerts are sent. Alerts can be sent via SMS, Email, Teams channels, Slack channels, etc.…
Example evidence: alerts
The next screenshot shows an example of alerts being configured in Azure. We can observe on the first screenshot that an alert was fired when the VM was stopped and deallocated. Please note this depicts an example of alerts being configured in Azure and the expectation will be that evidence is provided to demonstrate that alerts are generated for all the events specified in the control description.
The following screenshot shows alerts configured for any administrative actions taken at Azure App Service level as well as Azure Resource Group level.
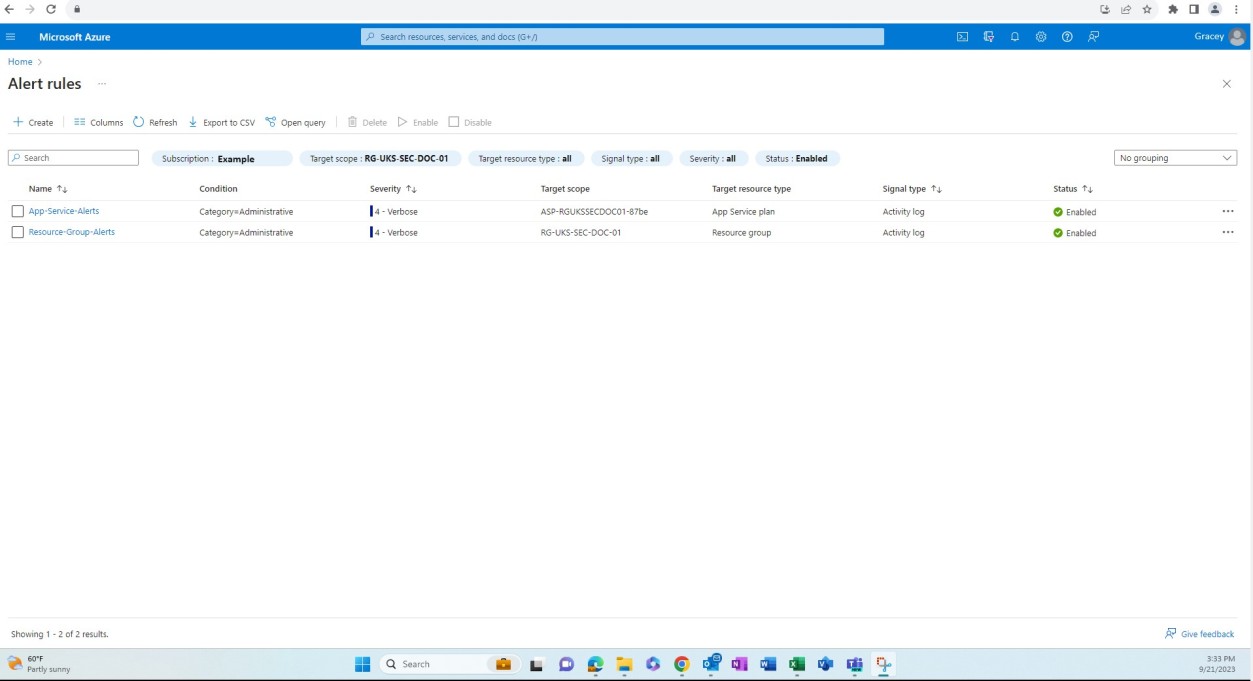
Example evidence
Contoso utilizes a third-party Security Operations Center(SOC) provided by Contoso Security. The example shows that alerting within AlienVault, utilized by the SOC, is configured to send an alert to a member of the SOC Team, Sally Gold at Contoso Security.
This next screenshot shows an alert being received by Sally.
Please note: These examples are not full screen screenshots, you will be required to submit full screen screenshots with any URL, logged in user and the time and date stamp for evidence review. If you are a Linux user this can be done via the command prompt.
Information security risk management
Information Security Risk Management is an important activity that all organizations should carry out at least annually. Organizations must understand their risks to effectively mitigate threats. Without effective risk management, organizations may implement security resources in areas they perceive to be important, when other threats may be more likely. Effective risk management will help organizations to focus on risks that pose the most threat to the business. This should be carried out annually as the security landscape is ever changing and therefore threats and risks can change overtime. For example, during the recent COVID-19 lockdown there was a large increase of phishing attacks with the move to remote work.
Control No. 21
Provide evidence that a ratified formal information security risk management policy/process is documented and established.
Intent: risk management
A robust information security risk management process is important to help organizations manage risks effectively. This will help organizations plan effective mitigations against threats to the environment. The intent of this control is to confirm that the organization has a formally ratified information security risk management policy or process that is comprehensively documented. The policy should outline how the organization identifies, assesses, and manages information security risks. It should include roles and responsibilities, methodologies for risk assessment, criteria for risk acceptance, and procedures for risk mitigation.
Note: The risk assessment must focus on information-security risks, not just general business risks.
Guidelines: risk management
The formally documented risk assessment management process should be supplied.
Example evidence: risk management
The following evidence is a screenshot of part of Contoso’s risk assessment process.
Note: The expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.
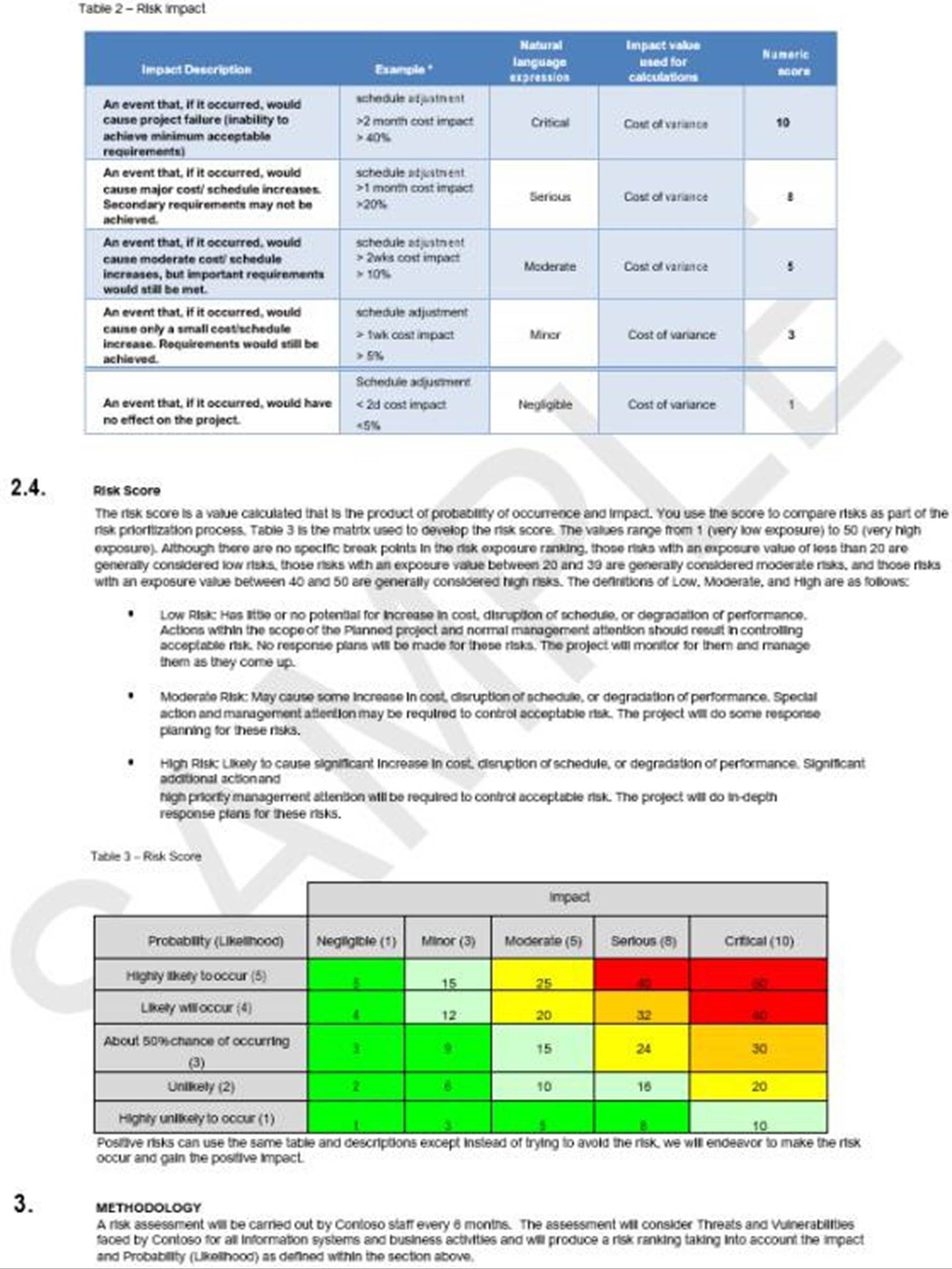
Note: The expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.
Control No. 22
Please provide evidence demonstrating that:
- A formal company-wide information security risk assessment is carried out at least annually.
OR For targeted risk analysis:
A targeted risk analysis is documented and performed:
At a minimum every 12 months for every instance where a traditional control or industry best practice is not in place.
Where a design/technological limitation creates a risk of introducing a vulnerability into the environment/puts users and data at risk.
Upon suspicion or confirmation of compromise.
Intent: annual assessment
Security threats are constantly changing based on changes to the environment, changes to the services offered, external influences, evolution of the security threat landscape, etc. Organizations need to go through the risk assessment process at least annually. It is recommended that this process is also carried out upon significant changes, as threats can change.
The intent of this control is to ascertain that the organization conducts a formal company-wide information security risk assessment at least once a year and/or a targeted risk analysis during system changes or upon incidents, vulnerability discovery, infrastructure changes, etc. This assessment should encompass all organizational assets, processes, and data, aiming to identify and evaluate potential vulnerabilities and threats.
For the targeted risk analysis, this control emphasizes the need to perform risk analysis on specific scenarios, this is focused on a narrower scope, such as an asset, a threat, system, or a control. The intent of this is to ensure that organizations continuously assess and identify risks introduced by deviations from security best practices or system design limitations. By performing targeted risk analyses at least annually where controls are lacking, when technological constraints create vulnerabilities, and in response to suspected or confirmed security incidents, the organization can pinpoint weaknesses and exposures. This allows for informed risk-based decisions on prioritizing remediation efforts and implementing compensating controls to minimize the likelihood and impact of exploitation. The goal is to provide ongoing due diligence, guidance, and evidence that known gaps are being addressed in a risk-aware manner rather than being ignored indefinitely. Performing these targeted risk assessments demonstrates organizational commitment to proactively improving security posture over time.
Guidelines: annual assessment
Evidence may be by way of version tracking or dated evidence. Evidence should be provided which shows the output of the information security risk assessment and NOT dates on the information security risk assessment process itself.
Example evidence: annual assessment
The next screenshot shows a risk assessment meeting being scheduled every six months.
These next two screenshots show an example of meeting minutes from two risk assessments. The expectation is that a report/meeting minutes, or report of the risk assessment is provided.

Note: This screenshot shows a policy/process document. The expectation is for ISVs to share the actual supporting policy/procedure documentation and not just provide a screenshot.
Note: This screenshot shows a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.
Control No. 23
Validate that the information security risk assessment includes:
System component or resource affected.
Threats and vulnerabilities, or equivale.
Impact and likelihood matrices or equivalent.
The creation of a risk register / risk treatment plan.
Intent: risk assessment
The intent is that the risk assessment includes system components and resources as it helps to identify the most critical IT assets and their value. By identifying and analyzing potential threats to the business, the organization can focus first on the risks that have the highest potential impact and the highest probability. By understanding the potential impact on the IT infrastructure and associated costs can help management make informed decisions on budget, policies, procedures, and more. A list of system components or resources that can be included in the security risk assessment are:
Servers
Databases
Applications
Networks
Data storage devices
People
To effectively manage information security risks, organizations should conduct risk assessments against threats to the environment and data, and against possible vulnerabilities that may be present. This will help organizations identify the myriad of threats and vulnerabilities that can pose a significant risk. Risk assessments should document impact and likelihood ratings, which can be used to identify the risk value. This can be used to prioritize the risk treatment and help reduce the overall risk value. Risk assessments need to be properly tracked to provide a record of one of the four risk treatments being applied. These risk treatments are:
Avoid/Terminate: The business may determine that the cost of dealing with the risk is more than the revenue generated from the service. The business may therefore choose to stop performing the service.
Transfer/Share: The business may choose to transfer the risk to a third-party by moving processing to a third-party.
Accept/Tolerate/Retain: The business may decide the risk is acceptable. This depends very much on the businesses risk appetite and can vary by organization.
Treat/Mitigate/Modify: The business decides to implement mitigation controls to reduce the risk to an acceptable level.
Guidelines: risk assessment
Evidence should be provided by way of not only the information security risk assessment process already supplied, but also the output of the risk assessment (by way of a risk register / risk treatment plan) to demonstrate that the risk assessment process is being carried out properly. The risk register should include risks, vulnerabilities, impact, and likelihood ratings.
Example evidence: risk assessment
The next screenshot shows the risk register which demonstrates threats and vulnerabilities are included. It also demonstrates that impact and likelihoods are included.
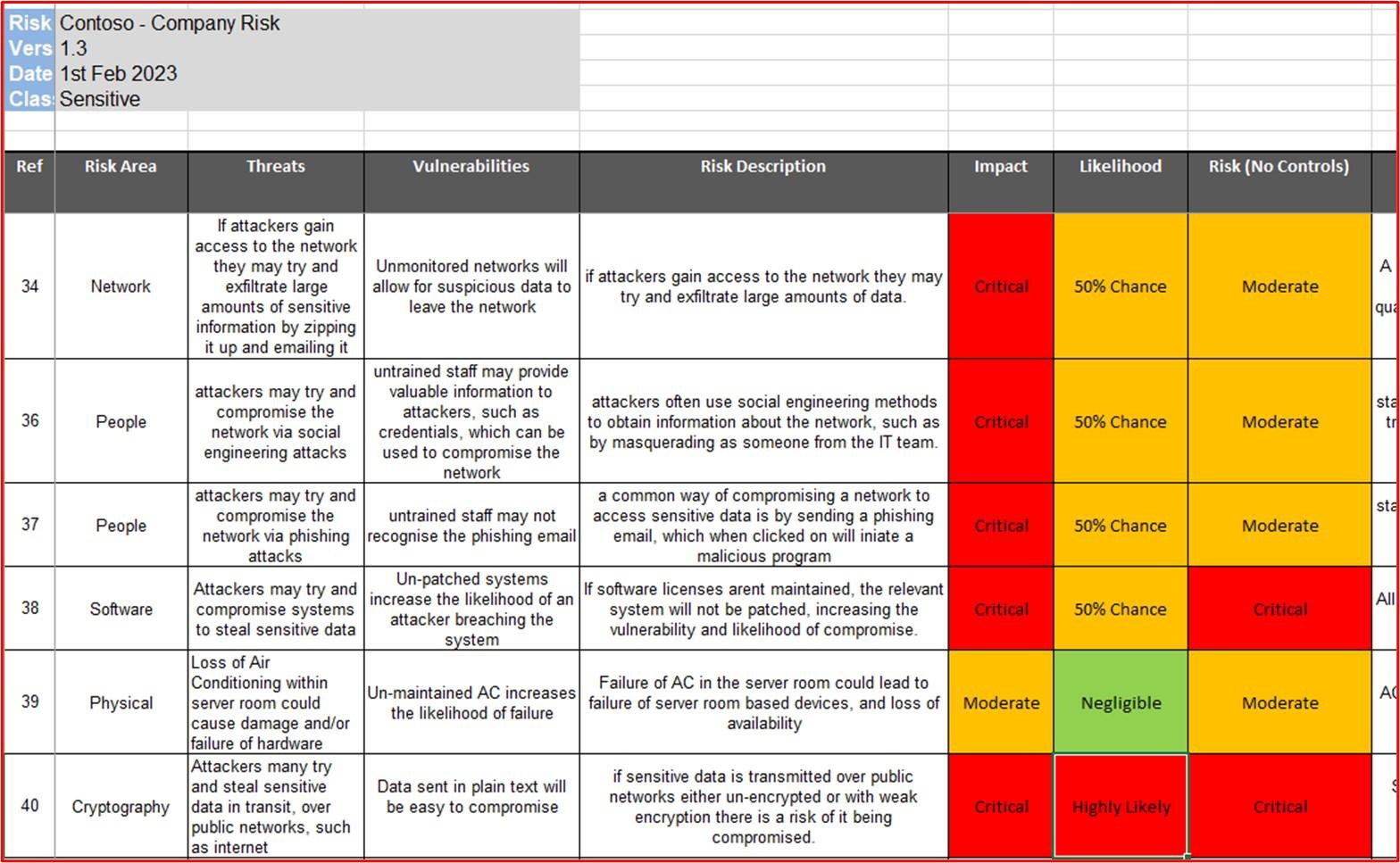
Note: The full risk assessment documentation should be provided instead of a screenshot. The next screenshot demonstrates a risk treatment plan.
Control No. 24
Please provide evidence that:
You (ISV) have risk management processes in place that assesses and manages risks associated with vendors and business partners.
You (ISV) can identify and assess changes and risks that could impact your system of internal controls.
Intent: vendors and partners
Vendor risk management is the practice of evaluating the risk postures of business partners, suppliers, or third-party vendors both before a business relationship is established and throughout the duration of the relationship. By managing vendor risks, organizations can avoid disruptions to business continuity, prevent financial impacts, protect their reputation, comply with regulations, and identify and minimize risks associated with collaborating with a vendor. To effectively manage vendor risks, it is important to have processes in place that include due diligence assessments, contractual obligations related to security, and continuous monitoring of vendor compliance.
Guidelines: vendors and partners
Evidence can be provided to demonstrate the vendor risk assessment process such as the procurement and vetting established documentation, checklists and questionnaires for onboarding new vendors and contractors, assessments performed, compliance checks, etc.
Example evidence: vendors and partners
The next screenshot demonstrates that the vendor onboarding and vetting process is maintained in Confluence as a JIRA task. For each new vendor an initial risk assessment occurs to review the compliance posture. During the procurement process a risk assessment questionnaire is filled in, and overall risk is determined based on the level of access to systems and data that is provided to the vendor.
The following screenshot demonstrates the outcome of the assessment and the overall risk that was identified based on the initial review.
Intent: internal controls
The focus of this subpoint is to recognize and evaluate changes and risks that could impact an organization’s internal control systems to ensure that the internal controls remain effective over time. As business operations change, your internal controls may no longer be effective. Risks evolve over time, and new risks may emerge that were not previously considered. By identifying and assessing these risks, you can ensure that your internal controls are designed to address them. This helps to prevent fraud and errors, maintain business continuity, and ensure regulatory compliance.
Guidelines: internal controls
Evidence can be provided such as review meeting minutes and reports which can demonstrate that the vendor risk assessment process is refreshed at a defined period to ensure that potential vendor changes are accounted for and assessed.
Example evidence: internal controls
The following screenshots demonstrate that a three-month review of the approved vendor and contractor’s list is undertaken to ensure that their compliance standards and level of compliance is consistent with the initial assessment during onboarding.
The first screenshot shows the established guidelines for performing the assessment and the risk questionnaire.
The following screenshots show the actual vendor approved list and their level of compliance, the assessment performed, the assessor, approver, etc. Please note this is just an example of a rudimentary vendor risk assessment designed to provide a baseline scenario for understanding the control requirement and to show the format of the evidence expected. As an ISV you should supply your own established vendor risk assessment as applicable to your organization.
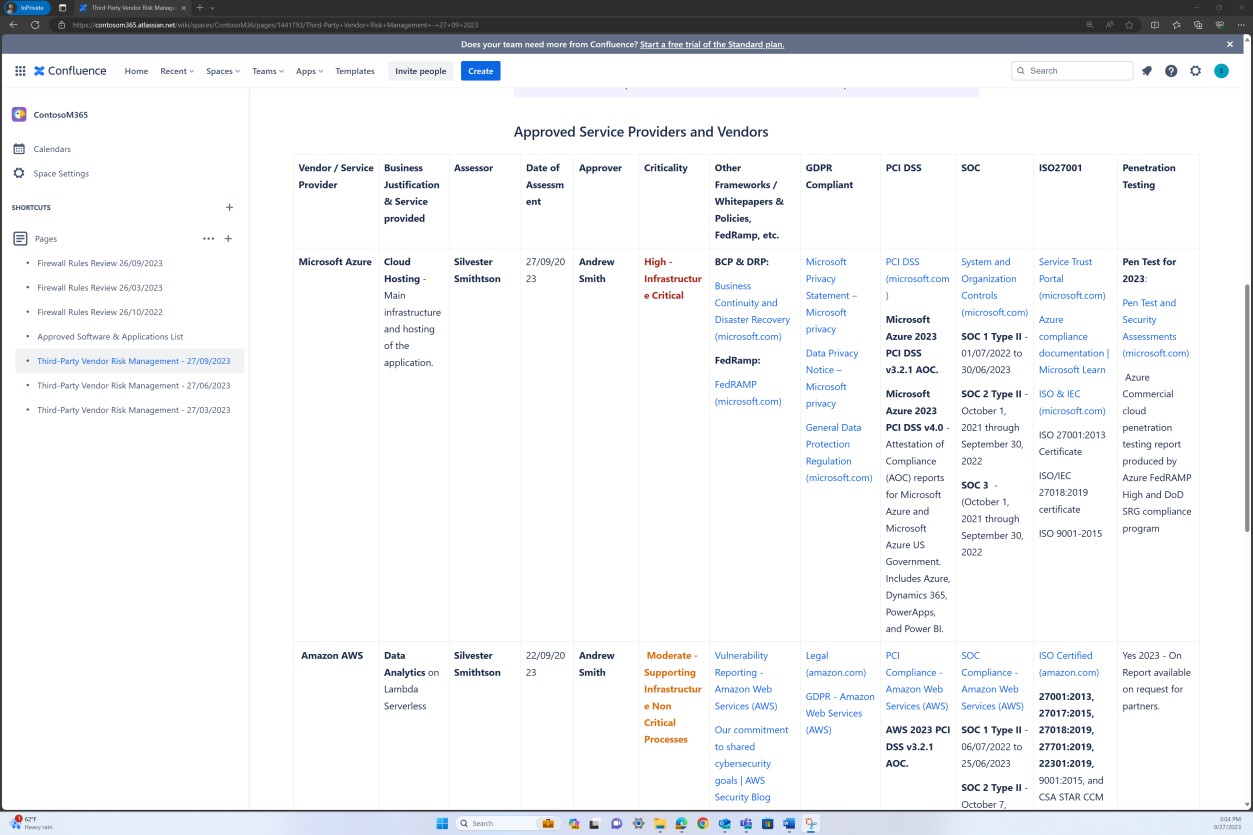
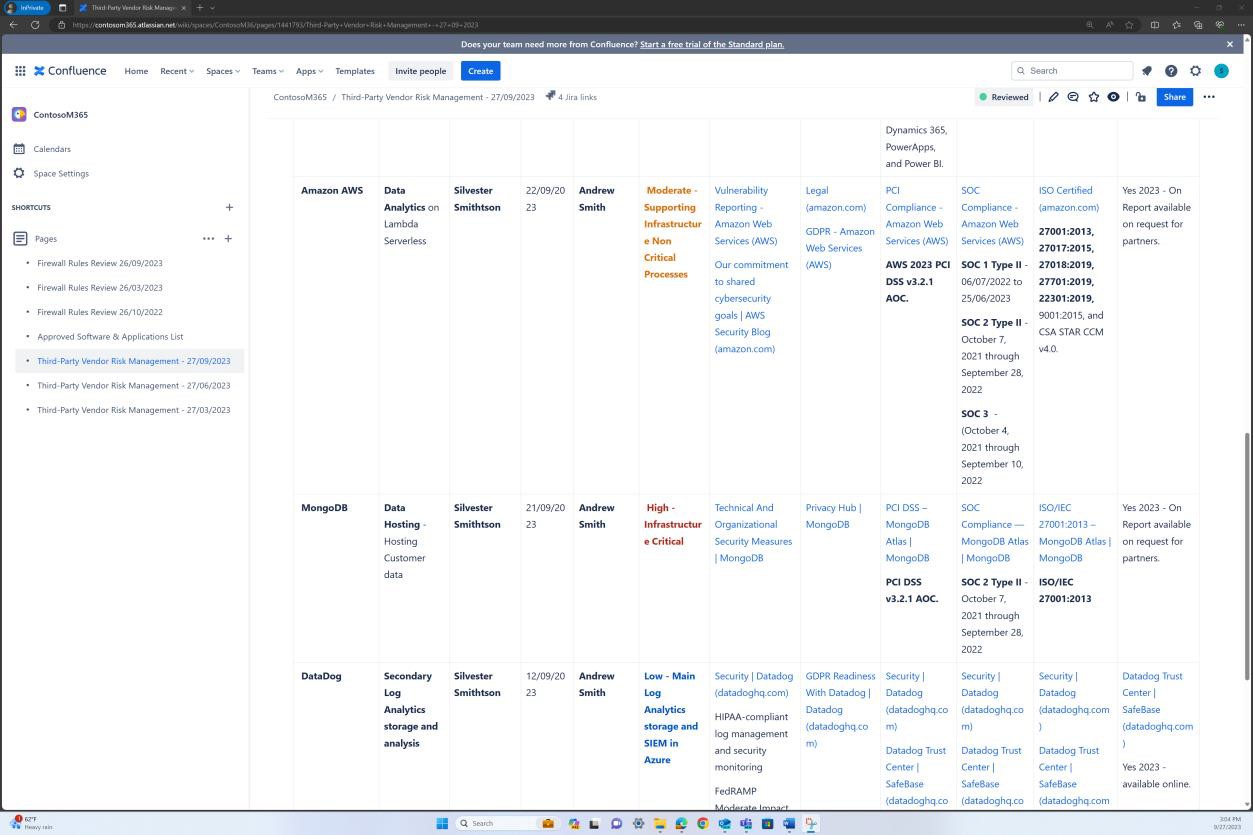
Security incident response
Security incident response is important for all organizations since this can reduce the time spent by an organization containing a security incident and limit the organization’s level of exposure to data exfiltration. By developing a comprehensive and detailed security incident response plan, this exposure can be reduced from the time of identification to the time of containment.
A report by IBM entitled "Cost of a data breach Report 2020" highlights that on average, the time taken to contain a breach was 73 days. Additionally, the same report identifies the biggest cost saver for organization’s that suffered a breach, was incident response preparedness, providing an average of
$2,000,000 cost saving. Organizations should be following best practices for security compliance using industry standard frameworks such as ISO 27001, NIST, SOC 2, PCI DSS etc...
Control No. 25
Please provide your ratified security incident response plan/procedure (IRP) outlining how your organization responds to incidents, showing how it is maintained, and that it includes:
details of the incident response team including contact information,
an internal communication plan during the incident and external communication to relevant parties such as key stakeholders, payment brands and acquirers, regulatory bodies (for example 72 hours for GDPR), supervisory authorities, directors, customers,
steps for activities such as incident classification, containment, mitigation, recovery and returning to normal business operations depending on the type of incident.
Intent: Incedent Response Plan (IRP)
The intent of this control is to ensure that there is a formally documented incident response plan (IRP) in place which includes a designated incident response team with clearly documented roles, responsibilities, and contact information. The IRP should provide a structured approach for managing security incidents from detection to resolution, including classifying the nature of the incident, containing the immediate impact, mitigating the risks, recovering from the incident, and restoring normal business operations. Each step should be well-defined, with clear protocols, to ensure that actions taken are aligned with the organization’s risk management strategies and compliance obligations.
The incident response team’s detailed specification within the IRP ensures that each team member understands their role in managing the incident, enabling a coordinated and efficient response. By having an IRP in place, an organization can manage a security incident response more efficiently, which can ultimately limit the organization’s data loss exposure and reduce the costs of the compromise.
Organizations may have breach notification obligations based upon the country/countries they operate in (e.g., the General Data Protection Regulation GDPR), or based upon functionality being offered (e.g., PCI DSS if payment data is handled). Failure of timely notification can carry serious ramifications; therefore, to ensure notification obligations are met, incident response plans should include a communication process including communication with all stakeholders, media communication processes and who can and cannot speak to the media.
Guidelines: internal controls
Provide the full version of the incident response plan/procedure. The incident response plan should include a section covering the process for handling incidents from identification to resolution and a documented communications process.
Example evidence: internal controls
The next screenshot shows the start of Contoso’s incident response plan.
Note: As part of your evidence submission, you must supply the entire incident response plan.

Example evidence: internal controls
The next screenshot shows an extract from the incident response plan showing the communication process.
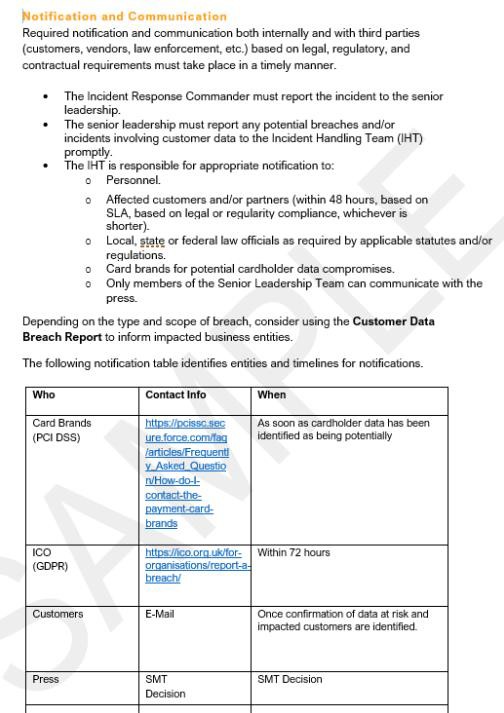
Control No. 26
Please provide evidence which shows that:
All members of the incident response team have received annual training that enables them to respond to incidents.
Intent: training
The longer it takes for an organization to contain a compromise, the greater the risk of data exfiltration, potentially resulting in a larger volume of exfiltrated data and the greater the overall cost of the compromise. It is important that organization’s incident response teams are equipped to respond to security incidents in a timely manner. By undertaking regular training and carrying out tabletop exercises, the team is prepared to handle security incidents quickly and efficiently. This training should cover various aspects such as identification of potential threats, initial response actions, escalation procedures, and long-term mitigation strategies.
The recommendation is to carry out both internal incident response training for the incident response team AND to carry out regular tabletop exercises, which should link to the information security risk
assessment to identify the security incidents that are most likely to occur. The tabletop exercise should simulate real-world scenarios to test and hone the team's abilities to react under pressure. By doing so, the organization can ensure that its staff knows how to handle a security breach or cyberattack properly. And the team will know what steps to take to contain and investigate the most likely security incidents, quickly.
Guidelines: training
Evidence should be provided which demonstrates training has been carried out by means of sharing the training content, and records showing who attended (which should include all the incident response team). Alternatively, or as well as, records showing that a tabletop exercise has been carried out. All this must have been completed within a 12-month period from when the evidence is submitted.
Example evidence: training
Contoso carried out an incident response tabletop exercise using an external security company. Following is a sample of the report generated as part of the consultancy.

Note: The full report would need to be shared. This exercise could also be carried out internally as there is no Microsoft 365 requirement for this to be carried out by a third-party company.
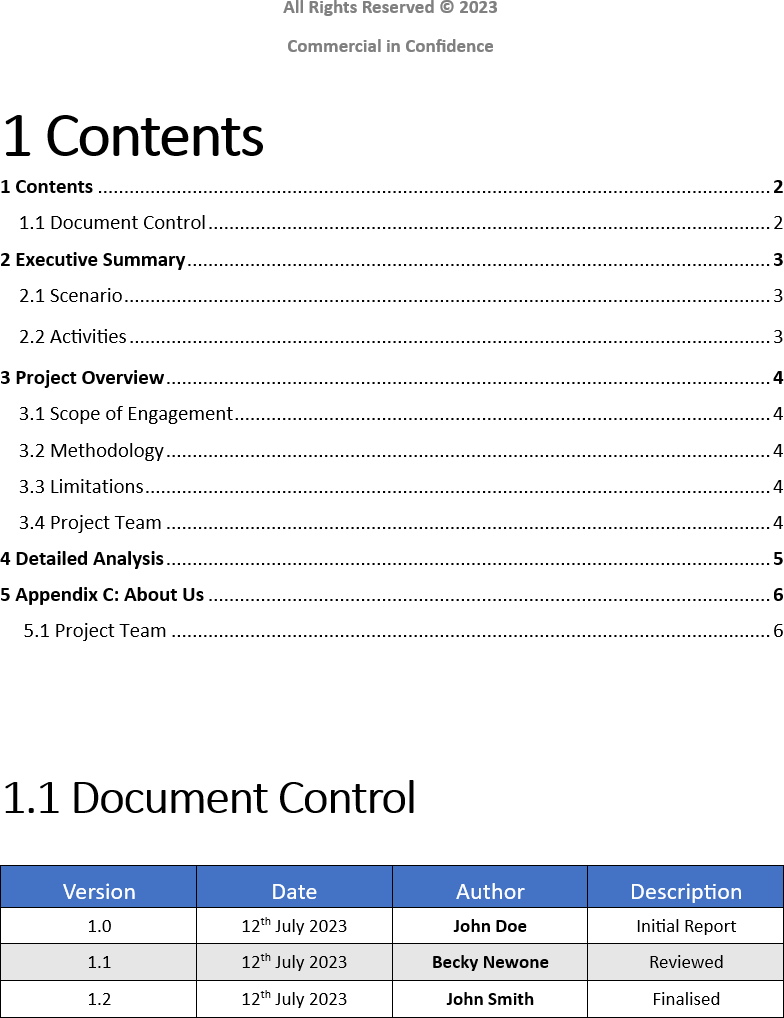
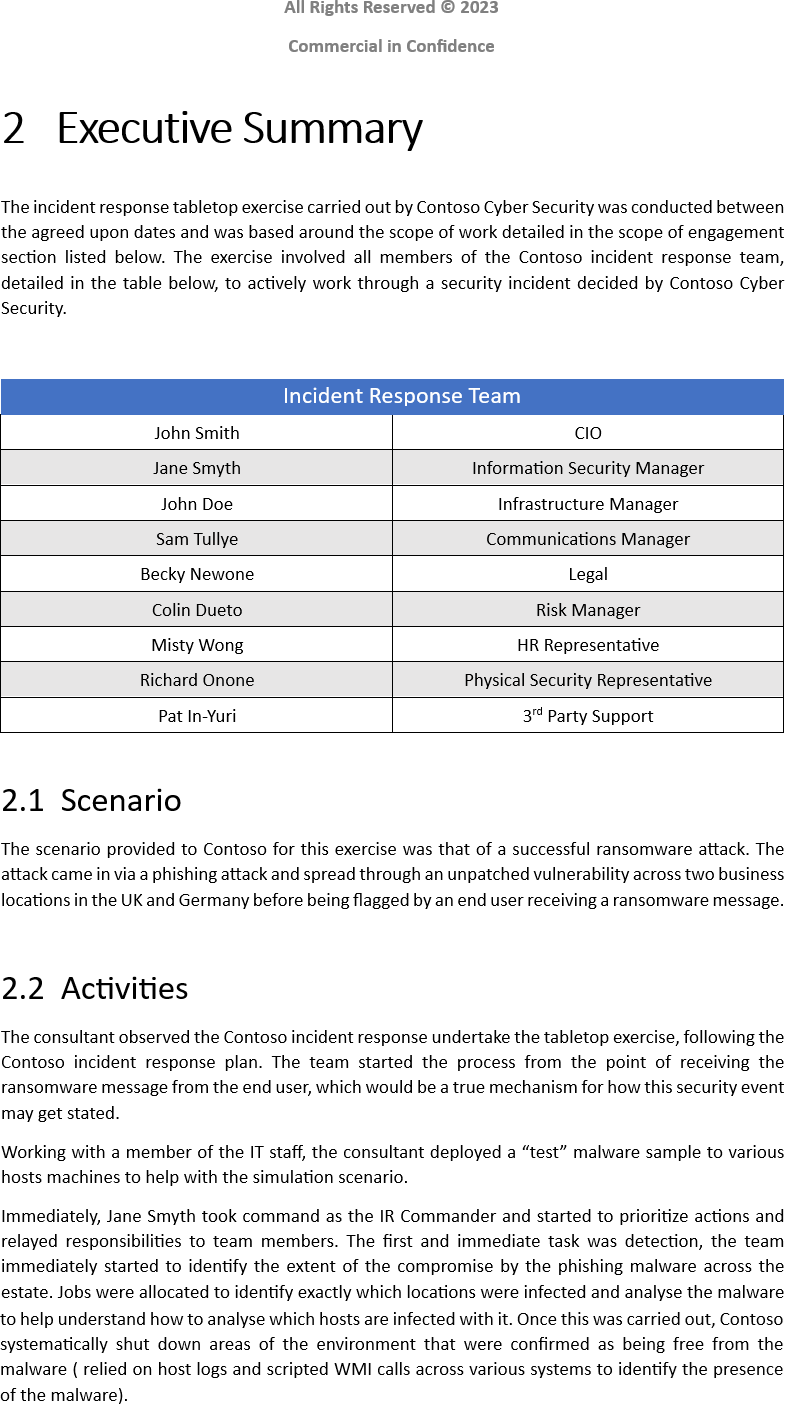
Note: The full report would need to be shared. This exercise could also be carried out internally as there's no Microsoft 365 requirement for this to be carried out by a third-party company.
Control No. 27
Please provide evidence that:
The incident response strategy and supporting documentation is reviewed and updated based on either:
lessons learned from a tabletop exercise
lessons learned from responding to an incident
organizational changes
Intent: plan reviews
Over time, the incident response plan should evolve based upon organizational changes or based upon lessons learned when enacting the plan. Changes to the operating environment may require changes to the incident response plan as the threats may change, or regulatory requirements may change. Additionally, as tabletop exercises and actual security incidents responses are carried out, this can often identify areas of the plan that can be improved. This needs to be built into the plan and the intent of this control is to ensure that this process is included. The objective of this control is to mandate the review and update of the organization’s incident response strategy and supporting documentation based on three distinct triggers:
After the simulated exercises to test the effectiveness of its incident response strategy have been carried out, any identified gaps or areas for improvement should be immediately incorporated into the existing incident response plan.
An actual incident provides invaluable insights into the strengths and weaknesses of the current response strategy. If an incident occurs, a post-incident review should be carried out to capture these lessons, which should then be used to update the response strategy and procedures.
Any significant changes within the organization, such as mergers, acquisitions, or changes in key personnel, should trigger a review of the incident response strategy. These organizational changes might introduce new risks or shift existing ones, and the incident response plan should be updated accordingly to remain effective.
Guidelines: plan reviews
This will often be evidenced by reviewing the results of security incidents or tabletop exercises where lessons learned have been identified and resulted in an update to the incident response plan. The plan should maintain a changelog, which should also reference changes which were implemented based on lessons learned, or organizational changes.
Example evidence: plan reviews
The next screenshots are from the supplied incident response plan which includes a section on updating based on lessons learned and/or organization changes.



Note: These examples are not full screen screenshots, you will be required to submit full screen screenshots with any URL, logged in user and the time and date stamp for evidence review. If you are a Linux user this can be done via the command prompt.
Business continuity plan and disaster recovery plan
Business continuity planning and disaster recovery planning are two critical components of an organization’s risk management strategy. Business continuity planning is the process of creating a plan to ensure that essential business functions can continue to operate during and after a disaster, while disaster recovery planning is the process of creating a plan to recover from a disaster and restore normal business operations as quickly as possible. Both plans complement each other—you must have both to withstand operational challenges brought about by disasters or unexpected interruptions. These plans are important because they help ensure that an organization can continue operating during a disaster, protect its reputation, comply with legal requirements, maintain customer confidence, manage risks effectively, and keep employees safe.
Control No. 28
Please provide evidence demonstrating that:
Documentation exists, and is maintained, which outlines the business continuity plan and includes:
details of relevant personnel including their roles and responsibilities
business functions with associated contingency requirements and objectives
system and data backup procedures, configuration, and scheduling/retention
recovery priority and timeframe targets
a contingency plan detailing actions, steps, and procedures to be followed to return critical information systems, business functions and services to operation in the event of an unexpected and unscheduled interruption
an established process that covers the eventual full system restoration and return to the original state
Intent: business continuity plan
The intent behind this control is to ensure that a clearly defined list of personnel with assigned roles and responsibilities is included in the business continuity plan. These roles are crucial for effective activation and execution of the plan during an incident.
Guidelines: business continuity plan
Please provide the full version of the disaster recovery plan/procedure which should include sections covering the processed outline in the control description. Supply the actual PDF/WORD document if in a digital version, alternatively if the process is maintained through an online platform provide an export or screenshots of the processes.
Example evidence: business continuity plan
The next screenshots show an extract of a business continuity plan and that it exists and is maintained.
Note: This screenshot(s) shows snapshots of a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.
The next screenshots show an extract of the policy where the ‘Key staff’ section is outlined including relevant team, contact details and steps to be taken.
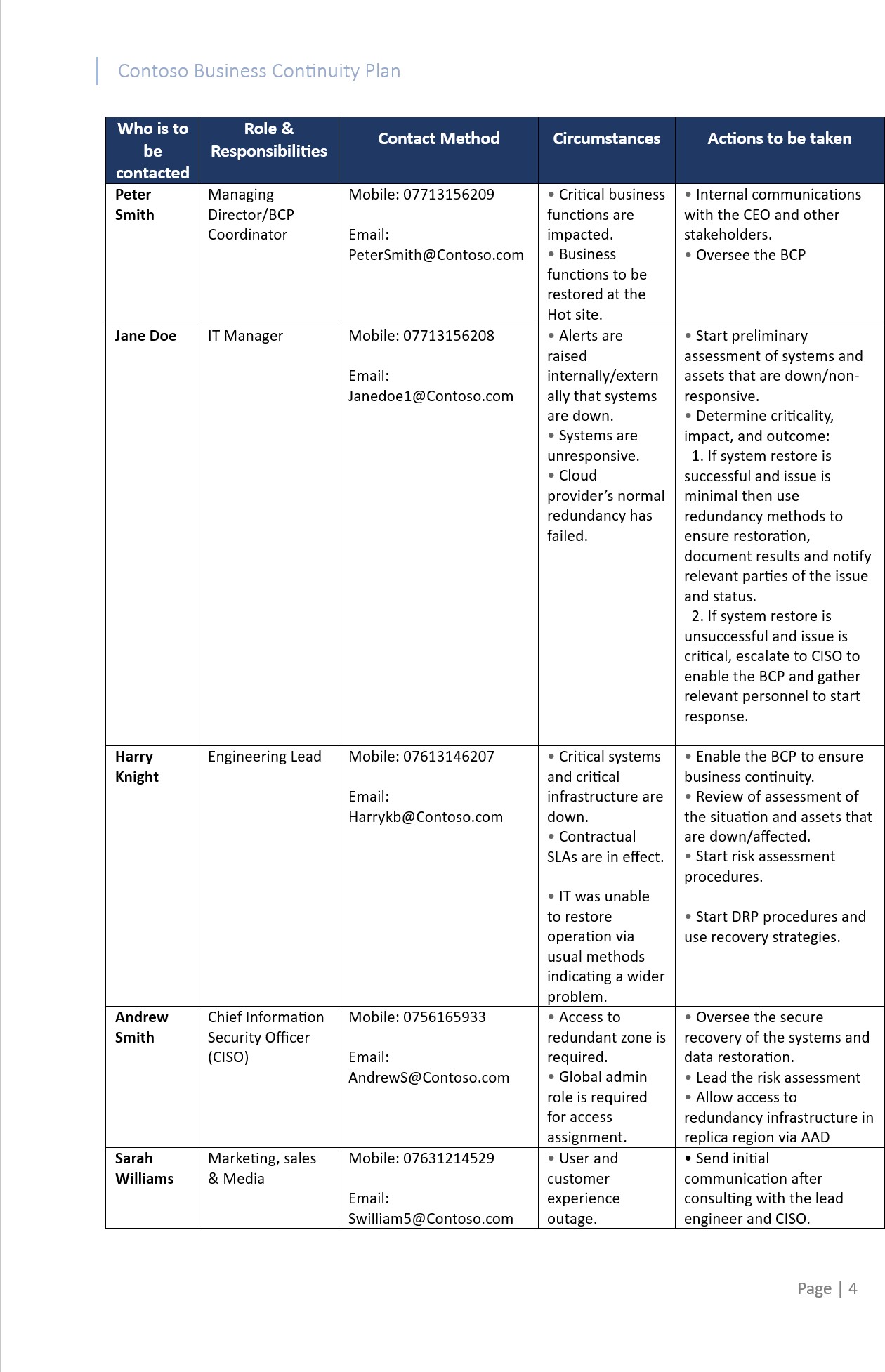
Intent: prioritization
The purpose of this control is to document and prioritize business functions according to their criticality. This should be accompanied by an outline of the corresponding contingency requirements needed to sustain or quickly restore each function during an unplanned interruption.
Guidelines: prioritization
Please provide the full version of the disaster recovery plan/procedure which should include sections covering the processed outline in the control description. Supply the actual PDF/WORD document if in a digital version, alternatively if the process is maintained through an online platform provide an export or screenshots of the processes.
Example evidence: prioritization
The next screenshots show an extract of a business continuity plan and an outline of business functions and their criticality level, as well as if any contingency plans exist.
Note: This screenshot(s) shows a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.

Intent: backups
The objective of this subpoint is to maintain documented procedures for backing up essential systems and data. The documentation should also specify the configuration settings, as well as backup scheduling and retention policies, to ensure that data is both current and retrievable.
Guidelines: backups
Please provide the full version of the disaster recovery plan/procedure which should include sections covering the processed outline in the control description. Supply the actual PDF/WORD document if in a digital version, alternatively if the process is maintained through an online platform provide an export or screenshots of the processes.
Example evidence: backups
The next screenshots show the extract of Contoso’s disaster recovery plan and that a documented backup configuration exist for every system. Please note that in the next screenshot that the backup schedule is also outlined, please note that for this example the backup configuration is outlined as part of the disaster recovery plan as business continuity and disaster recovery plans work together.
Note: This screenshot(s) shows a snapshot of a policy/procedure document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.
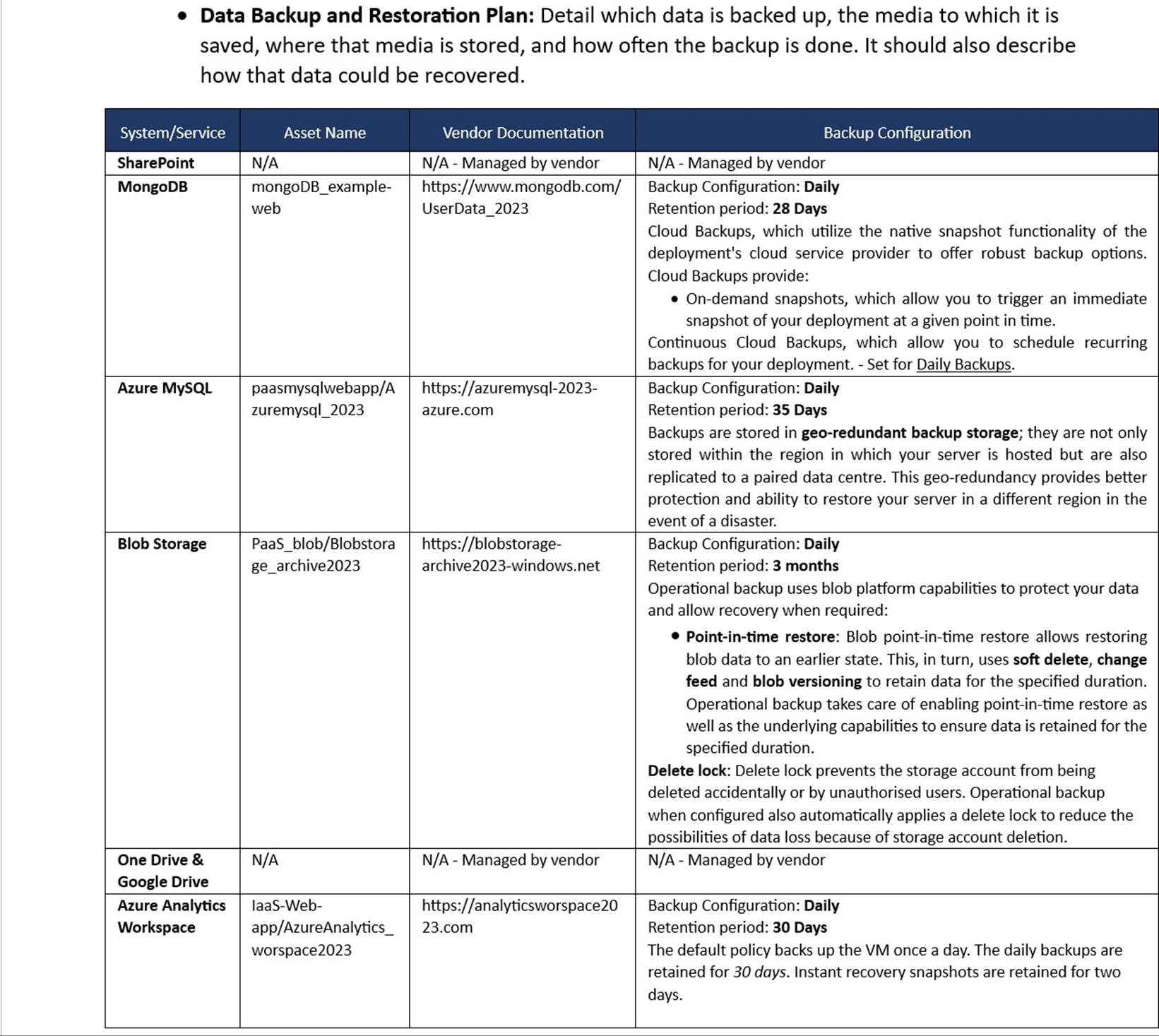
Intent: timelines
This control aims to establish prioritized timelines for recovery actions. These recovery time objectives (RTOs) should be aligned with the business impact analysis and must be clearly defined so that personnel understand which systems and functions must be restored first.
Guidelines: timelines
Please provide the full version of the disaster recovery plan/procedure which should include sections covering the processed outline in the control description. Supply the actual PDF/WORD document if in a digital version, alternatively if the process is maintained through an online platform provide an export or screenshots of the processes.
Example evidence: timelines
The following screenshot showing the continuation of the business functions and classification of criticality as well as the established Recovery Time Objective (RTO).
Note: This screenshot(s) shows a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.


Intent: recovery
This control intends to provide a step-by-step procedure that is to be followed to return critical information systems, business functions, and services to operational status. This should be detailed enough to guide decision-making during high-pressure situations, where rapid and effective actions are essential.
Guidelines: recovery
Please provide the full version of the disaster recovery plan/procedure which should include sections covering the processed outline in the control description. Supply the actual PDF/WORD document if in a digital version, alternatively if the process is maintained through an online platform provide an export or screenshots of the processes.
Example evidence: recovery
The next screenshots show the extract of our disaster recovery plan and that a documented recovery plan exists for every system and business function, please note that for this example the system recovery procedure is part of the disaster recovery plan as business continuity and disaster recovery plans work together to achieve full recovery/restoration.
Note: This screenshot(s) shows a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.
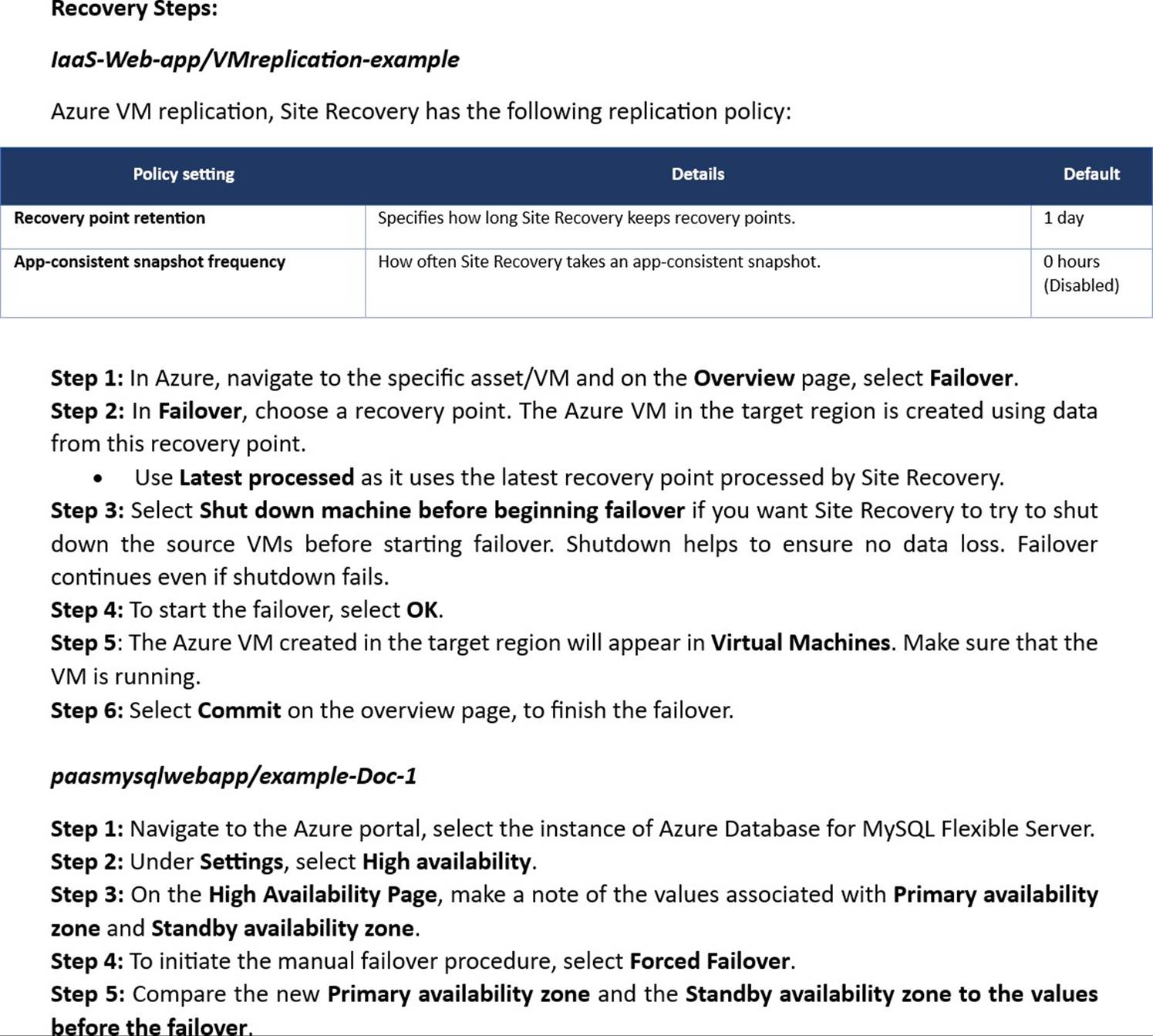
Intent: validation
This control point aims to ensure that the business continuity plan includes a structured process to guide the organization in restoring systems to their original state once the crisis has been managed. This includes validation steps to ensure that systems are fully operational and have retained their integrity.
Guidelines: validation
Please provide the full version of the disaster recovery plan/procedure which should include sections covering the processed outline in the control description. Supply the actual PDF/WORD document if in a digital version, alternatively if the process is maintained through an online platform provide an export or screenshots of the processes.
Example evidence: validation
The following screenshot shows the recovery process outlined in the business continuity plan policy and the steps/action to be undertaken.
Note: This screenshot(s) shows a snapshot of a policy/procedure document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.

Control No. 29
Please provide evidence demonstrating that:
Documentation exists, and is maintained, which outlines the disaster recovery plan and includes at a minimum:
details of relevant personnel including their roles and responsibilities
business functions with associated contingency requirements and objectives
system and data backup procedures, configuration, and scheduling/retention
recovery priority and timeframe targets
a contingency plan detailing actions, steps, and procedures to be followed to return critical information systems, business functions and services to operation in the event of an unexpected and unscheduled interruption
an established process that covers the eventual full system restoration and return to the original state
Intent: DRP
The objective of this control is to have well-documented roles and responsibilities for each member of the disaster recovery team. An escalation process should also be outlined to ensure that issues are quickly elevated and resolved by appropriate personnel during a disaster scenario.
Guidelines: DRP
Please provide the full version of the disaster recovery plan/procedure which should include sections covering the processed outline in the control description. Supply the actual PDF/WORD document if in a digital version, alternatively if the process is maintained through an online platform provide an export or screenshots of the processes.
Example evidence: DRP
The next screenshots show the extract of a disaster recovery plan and that it exists and is maintained.
Note: This screenshot(s) shows a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.
The next screenshot shows an extract of the policy where the ‘Contingency Plan’ is outlined including relevant team, contact details and escalation steps.
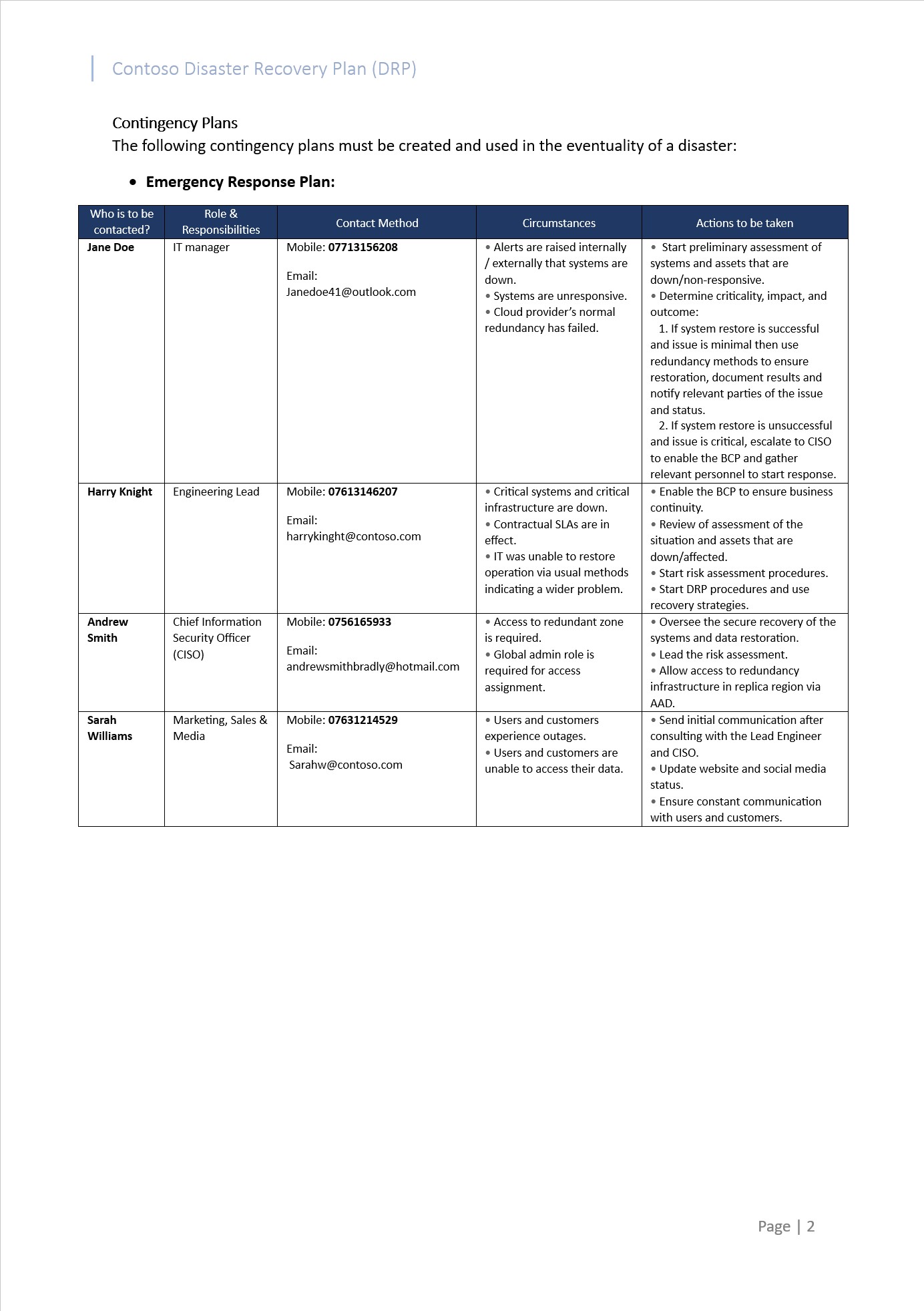
Intent: inventory
The intention behind this control is to maintain an up-to-date inventory list of all information systems that are crucial for supporting business operations. This list is fundamental for understanding which systems must be prioritized during a disaster recovery effort.
Guidelines: inventory
Please provide the full version of the disaster recovery plan/procedure which should include sections covering the processed outline in the control description. Supply the actual PDF/WORD document if in a digital version, alternatively if the process is maintained through an online platform provide an export or screenshots of the processes.
Example evidence: inventory
The next screenshots show the extract of a DRP and that an inventory of critical systems and their criticality level, as well as system functions exists.
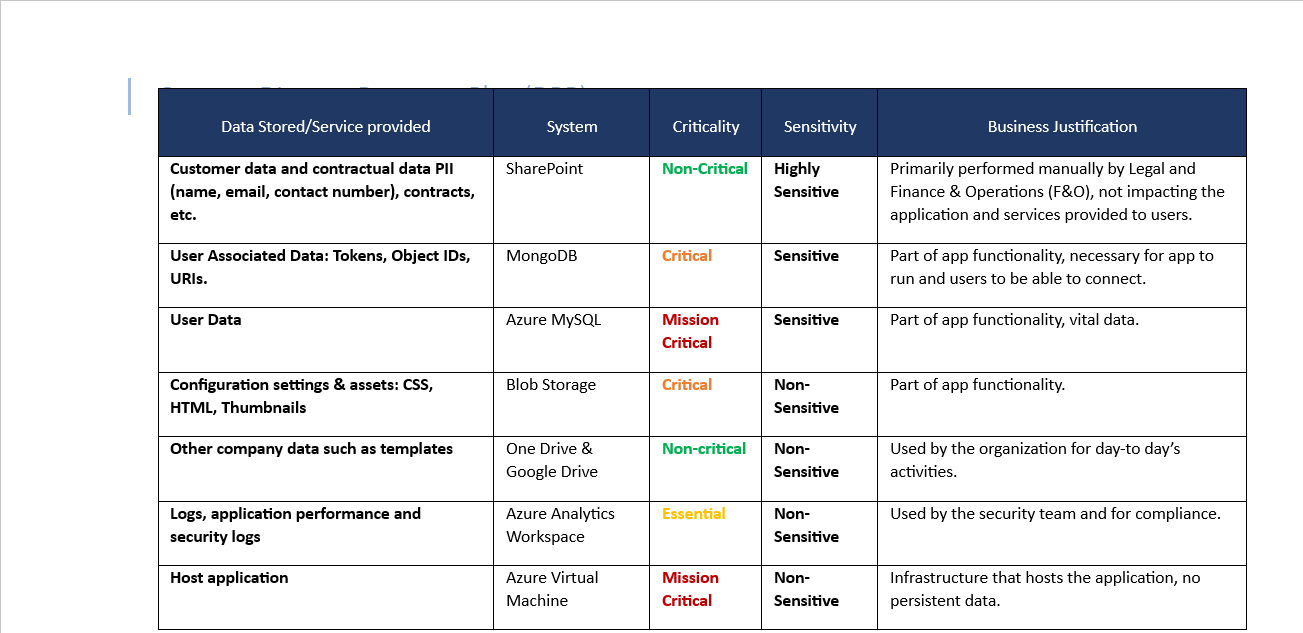
Note: This screenshot(s) shows a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.
The next screenshot shows the classification and service criticality definition.
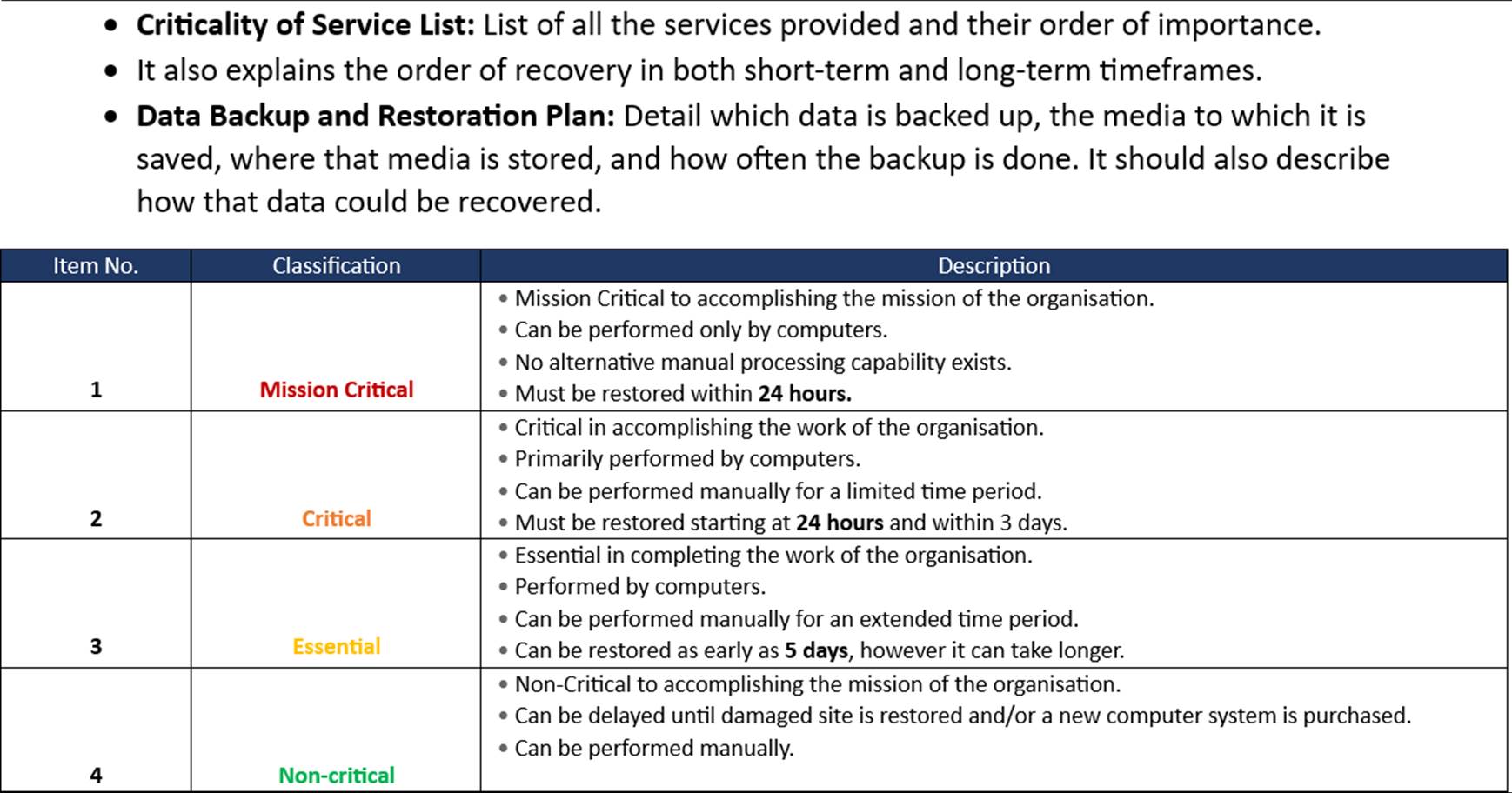
Note: This screenshot(s) shows a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.
Intent: backups
This control requires that well-defined procedures for system and data backups are in place. These procedures should outline the frequency, configuration, and locations of backups to ensure that all critical data can be restored in case of a failure or disaster.
Guidelines: backups
Please provide the full version of the disaster recovery plan/procedure which should include sections covering the processed outline in the control description. Supply the actual PDF/WORD document if in a digital version, alternatively if the process is maintained through an online platform provide an export or screenshots of the processes.
Example evidence: backups
The next screenshots show the extract of a disaster recovery plan and that a documented backup configuration exists for every system. Observe below that the backup schedule is also outlined.
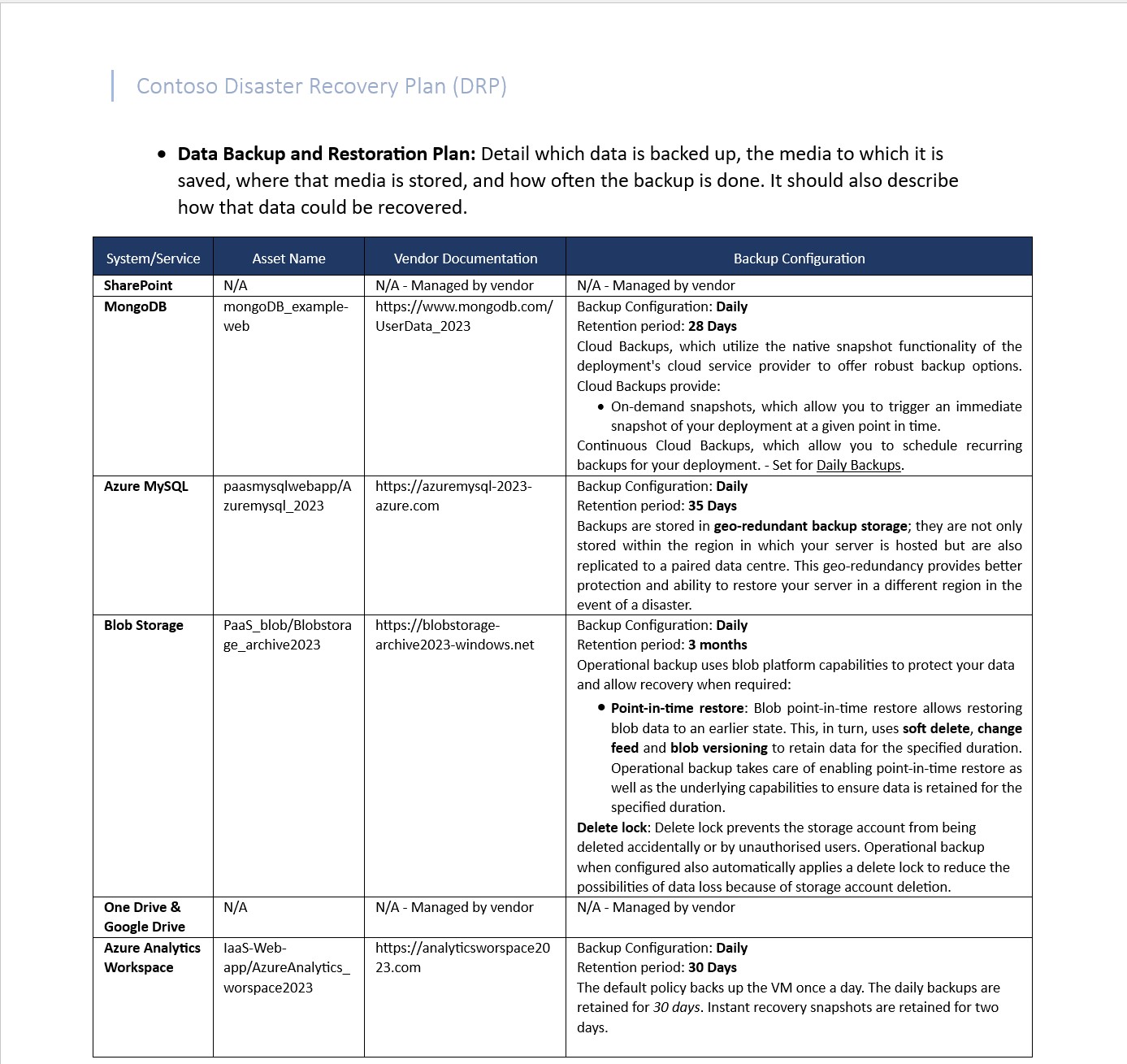
Note: This screenshot(s) shows a snapshot of a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.
Intent: recovery
This control calls for a comprehensive recovery plan that outlines step-by-step procedures to restore vital systems and data. This serves as a roadmap for the disaster recovery team and ensures that all recovery actions are premeditated and effective in restoring business operations.
Guidelines: recovery
Please provide the full version of the disaster recovery plan/procedure which should include sections covering the processed outline in the control description. Supply the actual PDF/WORD document if in a digital version, alternatively if the process is maintained through an online platform provide an export or screenshots of the processes.
Example evidence: recovery
The next screenshots show the extract of a disaster recovery plan and that an equipment replacement and system recovery steps and instructions exist and are documented, as well as the recovery procedure which includes recovery timeframes, actions to be taken to restore the cloud infrastructure, etc.

Note: This screenshot(s) shows a snapshot of a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.
Control No. 30
Please provide evidence demonstrating that:
The business continuity plan and the disaster recovery plan are being reviewed at least every 12 months to ensure that it remains valid and effective during adverse situations, and is updated based on:
Annual review of the plan.
All relevant personnel receive training on their roles and responsibilities assigned in the contingency plans.
The plan/s are tested through business continuity or disaster recovery exercises.
Test results are documented including lessons learned from exercises or organizational changes.
Intent: annual review
The purpose of this control is to ensure that the business continuity and disaster recovery plans are reviewed annually. The review should confirm that the plans are still effective, accurate, and aligned with current business objectives and technological architectures.
Intent: annual training
This control mandates that all individuals with designated roles in either the business continuity and disaster recovery plans receive appropriate training annually. The goal is to ensure that they are aware of their responsibilities and capable of executing them effectively in the event of a disaster or business interruption.
Intent: exercises
The intent here is to validate the effectiveness of the business continuity and disaster recovery plans through real-world exercises. These exercises should be designed to simulate various adverse conditions to test how well the organization can sustain or restore business operations.
Intent: analysis
The final control point aims for thorough documentation of all test results, including an analysis of what worked well and what did not. Lessons learned should be integrated back into the plans, and any shortcomings should be addressed immediately to improve the organization’s resiliency.
Guidelines: reviews
Evidence such as reports, meeting notes, and outputs of the yearly business continuity and disaster recovery plans exercises should be supplied for review.
Example evidence: reviews
The next screenshots show a report output of a business continuity and disaster recovery plan drill (exercise) in which a scenario was established to allow the team to enact the business continuity and disaster recovery plan and walkthrough the situation up to successful restoration of business functions and system operation.
Note: These screenshots show a snapshot(s) of a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.





Note: These screenshots show a snapshot(s) of a policy/process document, the expectation is for ISVs to share the actual supporting policy/procedure documentation and not simply provide a screenshot.