Data architecture and management in healthcare data solutions in Microsoft Fabric
The healthcare data solutions framework uses a specialized medallion architecture to streamline data organization and processing. This design ensures continuous improvement in data quality and structure, enabling you to manage healthcare data more effectively. This article explores the key features and benefits of this architecture and provides a comprehensive overview of how data is managed within this framework.
Medallion lakehouse design
As explained in the solution architecture, healthcare data solutions use the medallion lakehouse architecture to organize and process data across multiple layers. As data moves through each layer, its structure and quality continuously improve. At its core, the medallion lakehouse design in healthcare data solutions consists of the following key lakehouses:
Bronze lakehouse: Also called the raw zone, the bronze lakehouse is the first layer that organizes source data in its original file format. It ingests source files into OneLake and/or creates shortcuts from native storage sources. It also stores structured and semi-structured data from the source in delta tables, also referred to as staging tables. These tables are compressed and columnar-indexed to support efficient transformations and data processing. The data in this layer is typically append-only and immutable.
Files in the bronze lakehouse (whether persisted or shortcuts) serve as the source of truth. They lay the foundation for data lineage across the entire data estate in healthcare data solutions. Staging tables in the bronze layer generally consist of a few columns and are designed to hold each data modality and format in a single table (for example, ClinicalFhir and ImagingDicom tables). You shouldn't extend, customize, or build dependencies on these staging tables in the bronze lakehouse for the following reasons:
- Internal implementation: The staging tables are internally implemented specific to healthcare data solutions in Microsoft Fabric. Their schema is purpose-built for healthcare data solutions and doesn't follow any industry or community data standard.
- Transient store: After data is processed and transformed from the bronze lakehouse staging tables to the flattened and normalized delta tables in the silver lakehouse, the bronze staging table data is considered ready to be purged. This model ensures cost and storage efficiency and reduces data redundancy between source files and staging tables in the bronze lakehouse.
Silver lakehouse: Also called the enriched zone, the silver lakehouse refines data from the bronze lakehouse. It includes validation checks and enrichment techniques to improve data accuracy for downstream analytics. Unlike the bronze layer, the silver lakehouse data uses rules based on deterministic IDs and modification timestamps to manage record inserts and updates.
Gold lakehouse: Also called the curated zone, the gold lakehouse further refines data from the silver lakehouse to meet specific business and analytical requirements. This layer serves as the primary source for high-quality, aggregated datasets ready for comprehensive analysis and insights extraction. While healthcare data solutions deploy one bronze and one silver lakehouse per deployment, you can have multiple gold lakehouses to serve various business units and personas.
Admin lakehouse: The admin lakehouse contains files for data governance and traceability across the lakehouse layers, including global configuration and validation errors stored in the BusinessEvent table. For more information, see Admin lakehouse.
Unified folder structure
Healthcare and life sciences customers deal with vast amounts of data from different source systems, across multiple data modalities and file formats, including the following formats:
- Clinical modality: FHIR NDJSON files, FHIR bundles, and HL7.
- Imaging modality: DICOM, NIFTI, and NDPI.
- Genomics modality: BAM, BCL, FASTQ, and VCF.
- Claims: CCLF and CSV.
Where:
- FHIR: Fast Healthcare Interoperability Resources
- HL7: Health Level Seven International
- DICOM: Digital Imaging and Communications in Medicine
- NIFTI: Neuroimaging Informatics Technology Initiative
- NDPI: Nano-dimensional Pathology Imaging
- BAM: Binary Alignment Map
- BCL: Base Call
- FASTQ: A text-based format for storing a biological sequence and its corresponding quality scores
- VCF: Variant Call Format
- CCLF: Claim and Claim Line Feed
- CSV: Comma-separated values
OneLake in Microsoft Fabric offers a logical data lake for your organization. Healthcare data solutions in Microsoft Fabric provide a unified folder structure that helps organize data across different modalities and formats. This structure streamlines data ingestion and processing while maintaining data lineage at the source file and source system levels in the bronze lakehouse.
The six top-level folders include:
- External
- Failed
- Ingest
- Inventory
- Process
- ReferenceData
- SampleData
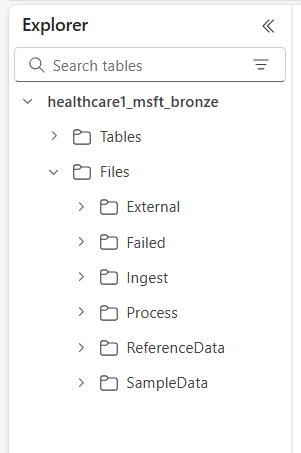
The subfolders are organized as follows:
- Files\Ingest[DataModality][DataFormat][Namespace]
- *Files\External[DataModality][DataFormat][Namespace][BYOSShortcutname]*
- *Files\SampleData[DataModality][DataFormat][Namespace]*
- *Files\ReferenceData[DataModality][DataFormat][Namespace]*
- Files\Failed[DataModality][DataFormat][Namespace]\YYYY\MM\DD
- Files\Process[DataModality][DataFormat][Namespace]\YYYY\MM\DD
- Files\Inventory[DataModality][DataFormat][Namespace][ShortcutToDcmFiles]
- Files\Inventory[DataModality][DataFormat][Namespace]\InventoryFiles[ShortcutToInventoryFiles]
Folder descriptions
Namespace (required): Identifies the source system for received files, crucial for ensuring ID uniqueness for each source system.
Ingest folder: Functions as a drop or queue folder. This folder lets you drop the files to be ingested in the appropriate modality and format subfolders. After ingestion begins, the files transfer to the respective Process folder or the Failed folder for failures.
Process folder: The final destination for all successfully processed files within each modality and format combination. This folder follows the
YYYY/MM/DDpattern based on the processing date. The folder partitioning follows best practices for using Azure Data Lake Storage for improved organization, filtered searches, automation, and potential parallel processing.External folder: Serves as the parent folder for the Bring Your Own Storage (BYOS) shortcut folders. The default deployment provides a suggested folder structure for claims, clinical, genomics, and imaging modalities. The imaging and clinical modalities have default formats and namespaces configured to support DICOM and FHIR services in Azure Health Data Services. This format applies only if you intend to shortcut data into OneLake. Healthcare data solutions in Microsoft Fabric have read-only access to files within these shortcut folders.
Failed folder: If a failure occurs while moving or processing files in the Ingest or Process folders, the affected files move to the Failed folder corresponding to their modality and format combination. An error is logged to the BusinessEvent table in the admin lakehouse. This folder uses the
YYYY/MM/DDpattern based on the processing or failure date. Files in this folder aren't purged and remain here until you fix and reingest them using the same initial ingestion pattern.Inventory folder: Serves as the parent folder for inventory-based ingestion, which supports ingesting large-scale imaging data (typically exceeding 50 million DICOM files). The default deployment provides a suggested folder structure for claims, clinical, genomics, and imaging capabilities.
Sample data folder: Includes synthetic, referential, and public datasets. The default deployment provides sample data for several modality and format combinations to facilitate immediate execution of notebooks and pipelines after deployment. This folder doesn't create any
YYYY/MM/DDsubfolders.Reference data folder: Contains referential and parent datasets from public or user-specific sources. This folder doesn't create any
YYYY/MM/DDsubfolders. The default deployment provides a suggested folder structure for OMOP (Observational Medical Outcomes Partnership) vocabularies.
Data ingestion patterns
Based on the unified folder structure outlined previously, healthcare data solutions in Microsoft Fabric support two distinct ingestion patterns. In both cases, the solutions use structured streaming in Spark to process incoming files in the respective folders.
Ingest pattern
This pattern is a simple approach where files to be ingested are dropped into the Ingest folder under the appropriate modality, format, and namespace. The ingestion pipelines monitor this folder for newly dropped files and move them to the corresponding Process folder for processing. If the ingestion of file data into the bronze lakehouse staging table is successful, the file is compressed and saved with a timestamp prefix in the Process folder, following the YYYY/MM/DD pattern based on when processing occurs. This prefix ensures unique file names. You can configure or disable compression as needed.
If file processing fails, the failed files are moved from the Ingest folder to the Failed folder for each modality and format combination, and an error is logged in the BusinessEvent table in the admin lakehouse.
This ingestion pattern is ideal for daily incremental ingestions or when physically moving data to Azure Data Lake Storage or OneLake.
Bring Your Own Storage (BYOS) pattern
You might sometimes have data and files already present in Azure or other cloud storage services, with existing downstream implementations and dependencies on those files. In healthcare and life sciences, data volumes can reach multiple terabytes or even petabytes, especially for medical imaging and genomics. For these reasons, the direct ingestion pattern isn't feasible.
We recommend using the BYOS pattern for historical data ingestion when you have substantial data volumes already available in Azure or other cloud and on-premises storage supporting the S3 protocol. This pattern uses OneLake shortcuts in Fabric and the External folder in the bronze lakehouse to enable in-place processing of source files. It eliminates the need to move or copy files and avoids incurring egress charges and data duplication.
Despite the efficiencies offered by the BYOS ingestion pattern, you should note the following considerations:
- In-place file updates (content updates within the file) aren't monitored. You're expected to create a new file (with a different name) for any updates because the ingestion pipeline only monitors new files. This limitation is associated with structured streaming in Spark.
- Data compressions aren't applied.
- The BYOS pattern doesn't create any optimized folder structure based on the
YYYY/MM/DDpattern. - If file processing fails, the failed files aren't moved to the Failed folder. However, an error is logged in the BusinessEvent table in the admin lakehouse.
- The source data is assumed to be read-only.
- There's no control over the lineage or availability of the source data after ingestion.
Data compression
Healthcare data solutions in Microsoft Fabric support compression by design across the medallion lakehouse design. Data ingested into the delta tables across the medallion lakehouse are stored in a compressed, columnar format using parquet files. In the ingest pattern, when the files move from the Ingest folder to the Process folder, they're compressed by default after successful processing. You can configure or disable the compression as needed. For the imaging and claims capabilities, the ingestion pipelines can also process raw files in a ZIP compressed format.
Healthcare data model
As described in medallion lakehouse design, the bronze lakehouse staging tables internally implement purpose-built tables for healthcare data solutions and don't follow any industry or community data standards.
The healthcare data model in the silver lakehouse is based on the FHIR R4 standard. It provides a common data language for data analysts, data scientists, and developers to collaborate and build data-driven solutions that improve patient outcomes and business performance. It supports data across different healthcare domains such as clinical, administrative, financial, and social. The healthcare data model captures data defined by the FHIR standard and organizes the FHIR resources using tables and columns within the lakehouse.
By flattening FHIR data into delta parquet tables, you can use familiar tools such as T-SQL and Spark SQL for data exploration and analysis. For nonclinical data outside the scope of FHIR, we use schemas from the Azure Synapse database templates. This implementation lets you integrate nonclinical information, such as patient engagement data, into the patient profile.
The healthcare data model in the silver lakehouse is designed to represent an end-to-end enterprise view of healthcare data across business units and research domains.

Data lineage and traceability
To ensure lineage and traceability at the record and file level, the healthcare data model tables include the following columns:
| Column | Description |
|---|---|
msftCreatedDatetime |
Timestamp when the record is first created in the silver lakehouse. |
msftModifiedDatetime |
Timestamp of the last modification to the record. |
msftFilePath |
Full path to the source file in the bronze lakehouse, including shortcuts. |
msftSourceSystem |
The source system of the record, corresponding to the Namespace specified in the unified folder structure. |
If a field is normalized, flattened, or modified, the original value is preserved in an {columnName}Orig column. For example, in the silver lakehouse Patient table, you find these columns:
| Column | Description |
|---|---|
meta_lastUpdatedOrig |
Preserves the original value in its raw format (string or date) and stores it as a datetime. |
idOrig and identifierOrig |
IDs and identifiers harmonized in the silver lakehouse. |
birthdateOrig and deceasedDateTimeOrig |
Preserves the original date values with a different timestamp formatting. |
If a column flattens (for example, meta_lastUpdated) or converts to a string (for example, meta_string), it's denoted using a suffix beginning with an underscore (_).
The gold lakehouse tables include the following columns to ensure record lineage and traceability back to the silver lakehouse:
| Column | Description |
|---|---|
msftSourceTableName |
The record's source table in the silver lakehouse. |
msftSourceRecordId |
The source record's ID in the source table within the silver lakehouse. |
msftModifiedDatetime |
Timestamp of the last modification to the record. |
Update handling
When new data ingests from the bronze to the silver lakehouse, an update operation compares the incoming records with the target tables in the silver lakehouse for each resource and table type. For FHIR tables in the silver lakehouse, this comparison checks both the {FHIRResource}.id and {FHIRResource}.meta_lastUpdated values against the id and lastUpdated columns in the ClinicalFhir bronze lakehouse staging table.
- If a match is identified and the incoming record is new, the silver record is updated.
- If the incoming record is old, the silver record is ignored.
- If no match is found, the new record is inserted into the silver lakehouse.
Admin lakehouse
The admin lakehouse manages cross-lakehouse configuration, global configuration, status reporting, and tracking for healthcare data solutions in Microsoft Fabric.
Global configuration
The admin lakehouse system-configurations folder centralizes the global configuration parameters. The three configuration files contain preconfigured values for the default deployment of all healthcare data solutions capabilities. You don't have to reconfigure any of these values to run the sample data or data pipelines for any capability. If you need to modify or reconfigure these values for a specific use case, use OneLake file explorer or Azure Storage Explorer.

The deploymentParametersConfiguration.json file contains global parameters under activitiesGlobalParameters and activity-specific parameters for notebooks and pipelines under activities. The respective capability guidance covers specific configuration details for each capability. The validation_config.json file parameters are explained in Data validation.
The following table lists all the global configuration parameters.
| Section | Configuration parameters |
|---|---|
activitiesGlobalParameters |
•administration_lakehouse_id: Admin lakehouse identifier.• bronze_lakehouse_id: Bronze lakehouse identifier.• silver_lakehouse_id: Silver lakehouse identifier.• keyvault_name: Azure Key Vault value when deployed with the Azure Marketplace offer.• enable_hds_logs: Enables logging; default value set to true.• movement_config_path: Path to the file_orchestration_config file.• bronze_imaging_delta_table_path: Fabric path for the imaging modality table (if deployed).• bronze_imaging_table_schema_path: Fabric path for the imaging modality schema (if deployed).• omop_lakehouse_id: Gold lakehouse identifier (if deployed). |
| Activities for healthcare#_msft_fhir_ndjson_bronze_ingestion | •source_path_pattern: OneLake path to the Process folder.• move_failed_files_enabled: Flag to determine if a failed file should move from the Ingest folder to the Failed folder.• compression_enabled: Flag to determine if the raw NDJSON files will be compressed after processing.• target_table_name: Name of the clinical ingestion table in the bronze lakehouse.• target_tables_path: OneLake path for all delta tables in the bronze lakehouse.• max_files_per_trigger: Number of files processed with each run.• max_structured_streaming_queries: Number of processing queries that can run in parallel.• checkpoint_path: OneLake path for the checkpoint folder.• schema_dir_path: OneLake path for the bronze schema folder.• validation_config_key: Parent-level validation configuration. For more information, see Data validation.• file_extension: The extension of the ingested raw file. |
| Activities for healthcare#_msft_bronze_silver_flatten | •source_table_name: Name of the clinical ingestion table in the bronze lakehouse.• config_path: OneLake path to the flattened config file.• source_tables_path: OneLake path to the source delta tables in the bronze lakehouse.• target_tables_path: OneLake path to the target delta tables in the silver lakehouse.• checkpoint_path: OneLake path for the checkpoint folder.• schema_dir_path: OneLake path for the bronze schema folder.• max_files_per_trigger: Number of files processed within each run.• max_bytes_per_trigger: Number of bytes processed within each run.• max_structured_streaming_queries: Number of processing queries that can run in parallel. |
| Activities for healthcare#_msft_imaging_dicom_extract_bronze_ingestion | •byos_enabled: Flag that determines if the ingestion of the DICOM imaging dataset in the bronze lakehouse is sourced from an external storage location through OneLake shortcuts. In this case, the files aren't moved to the Process folder as they would be otherwise.• external_source_path: OneLake path for the shortcut External folder in the bronze lakehouse.• process_source_path: OneLake path for the Process folder in the bronze lakehouse.• checkpoint_path: OneLake path for the checkpoint folder.• move_failed_files: Flag that determines if a failed file is moved from the Ingest to the Failed folder.• compression_enabled: Flag that determines if the raw NDJSON files are compressed after processing.• max_files_per_trigger: Number of files processed within each run.• num_retries: Number of retries for each file processing before an error. |
| Activities for healthcare#_msft_imaging_dicom_fhir_conversion | •fhir_ndjson_files_root_path: OneLake path to the Process folder.• avro_schema_path: OneLake path for the silver schema folder.• dicom_to_fhir_config_path: OneLake path for mapping configuration from DICOM metatags to the FHIR ImagingStudy resource.• checkpoint_path: OneLake path for the checkpoint folder.• max_records_per_ndjson: Number of records processed within a single NDJSON file in each run.• subject_id_type_code: Value code for the patient's medical number in the DICOM metadata. The default value is set to MR, which corresponds to Medical Record Number in FHIR.• subject_id_type_code_system: The code system for the patient's medical number in the DICOM metadata.• subject_id_system: The object ID for the code system for the patient's medical number in the DICOM metadata. |
| Activities for healthcare#_msft_omop_silver_gold_transformation | •vocab_path: OneLake path to the reference data folder in the bronze lakehouse where the OMOP vocabulary datasets are stored.• vocab_checkpoint_path: OneLake path for the checkpoint folder.• omop_config_path: OneLake path for mapping configuration from the silver lakehouse to the gold OMOP lakehouse. |
BusinessEvents table
The BusinessEvents delta table captures all the validation errors, warnings, and other notifications or exceptions that might occur during ingestion and transformation processes. Use this table for monitoring ingestion execution progress at both the user and functional levels, rather than solely at the system-log level. For instance, it identifies which raw files introduced validation errors or warnings during ingestion. For system-level logs and to monitor Apache Spark activities across all lakehouses, you can use the Fabric Monitoring hub, with the option to integrate Azure Log Analytics.
The following table lists the columns in the BusinessEvent table:
| Column | Description |
|---|---|
id |
Unique identifier (GUID) for each row in the table. |
activityName |
Name of the activity/notebook that generated the failure and/or the validation error or warning. |
targetTableName |
Target table for the data activity that generated the event. |
targetFilePath |
Path for the target file for the data activity that generated the event. |
sourceTableName |
Source table for the data activity that generated the event. |
sourceLakehouseName |
Source lakehouse for the data activity that generated the event. |
targetLakehouseName |
Target lakehouse for the data activity that generated the event. |
sourceFilePath |
Path for the source file for the data activity that generated the event. |
runId |
Run ID for the data activity that generated the event. |
severity |
Severity level of the event, which might have one of the following two values: Error or Warning. Error signifies that you must resolve this event before continuing with the data activity. Warning serves as a passive notification, generally requiring no immediate action. |
eventType |
Distinguishes between events generated by the validation engine and generic events generated by users or unhandled/system exceptions that users want to surface to the BusinessEvent table. |
recordIdentifier |
Identifier for the source record. This column differs from the id column, as it represents a fresh and unique identifier for each event in the BusinessEvents table. |
recordIdentifierSource |
Source system for the identifier of the source record. For example, if the source system is the EMR, then the EMR name or URL serves as the source. |
active |
Flag indicating whether the event (error or warning) is resolved. |
message |
Descriptive message for the event error or warning. |
exception |
Unhandled/system exception message. |
customDimensions |
Applicable when the source data of the validation or exception isn't a discrete column in a table. For example, when the source data is an attribute within a JSON object saved as a string within a single column, the full JSON object is provided as the custom dimension. |
eventDateTime |
Timestamp at which the event or exception generates. |
Data validation
The data validation engine within healthcare data solutions in Microsoft Fabric ensures that raw data meets predefined criteria before ingestion into the bronze lakehouse. You can configure the validation rules at the table and column levels within the bronze lakehouse. Currently, these rules are implemented exclusively during the ingestion process, from raw files to delta tables in the bronze lakehouse.
When a raw file is processed, the validation rules apply at the ingestion level. There are two severity levels for validation: Error and Warning. If a validation rule is set to Error, the pipeline stops when the rule is violated, and the faulty file moves to the Failed folder. If the severity is set to Warning, the pipeline continues processing, and the file moves to the Process folder. In both cases, entries reflecting the errors or warnings are created in the BusinessEvents table within the admin lakehouse.
The BusinessEvents table captures business-level logs and events across all lakehouses for any activity, notebook, or data pipeline within healthcare data solutions. However, the current configuration only enforces validation rules during ingestion, which might result in some columns in the BusinessEvents table remaining unpopulated for validation errors and warnings.
You can configure the data validation rules in the validation_config.json file in the admin lakehouse. By default, the meta.lastUpdated and id columns in the ClinicalFhir table of the bronze lakehouse are set as required. These columns are critical for determining how updates and inserts are managed in the silver lakehouse, as explained in Update handling.
The following table lists the configuration parameters for data validation:
| Configuration type | Parameters |
|---|---|
| Lakehouse level | bronze: The scope of the validations and record identifier nodes. In this case, the value is set to the bronze lakehouse. |
| Validations | •validationType: The exists validation type checks whether a value for the configured attribute is provided in the raw file (source data).• attributeName: Name of the attribute being validated.• validationMessage: Message describing the validation error or warning.• severity: Indicates the level of the issue, which can be either Error or Warning.• tableName: Name of the table being validated. An asterisk (*) denotes that this rule applies to all tables within the scope of that lakehouse. |
recordIdentifier |
•attributeName: Record identifier of the source/raw file placed in the recordIdentifier column in the BusinessEvent table.• jsonPath: Optional value that represents the JSON path of a column or attribute for the value to be placed in the recordIdentifier column in the BusinessEvent table. This value applies when the source data for the validation isn't a discrete column in a table. For example, if the source data is an attribute within a JSON object stored as a string within a single column, the JSON path directs to the specific attribute that serves as the record identifier. |