Poikkeamien tunnistaminen monivariaatiolla
Yleisiä tietoja poikkeamien tunnistamisesta reaaliaikaisessa älykkyydessä on artikkelissa Poikkeamien tunnistuksen monimuuttujan tunnistaminen Microsoft Fabricissa – yleiskatsaus. Tässä opetusohjelmassa käytät mallitietoja monimuuttujan poikkeamien tunnistusmallin harjoittamiseen Python-muistikirjan Spark-moduulilla. Sen jälkeen voit ennustaa poikkeamia käyttämällä harjoitetulla mallilla uusia tietoja Eventhouse-moduulin avulla. Ensimmäisissä vaiheissa määrität ympäristösi ja harjoitat mallia ja ennustat poikkeamia seuraavien vaiheiden avulla.
Edellytykset
- Työtila, jossa on Microsoft Fabric -yhteensopiva kapasiteetti
- Järjestelmänvalvojan, osallistujan tai jäsenenrooli työtilassa. Tätä käyttöoikeustasoa tarvitaan ympäristökohteiden luomiseen.
- Tapahtumatalo työtilassasi, jossa on tietokanta.
- Lataa mallitiedot GitHub-säilöstä
- Lataa muistikirja GitHub-säilöstä
Osa 1– OneLaken käytettävyyden ottaminen käyttöön
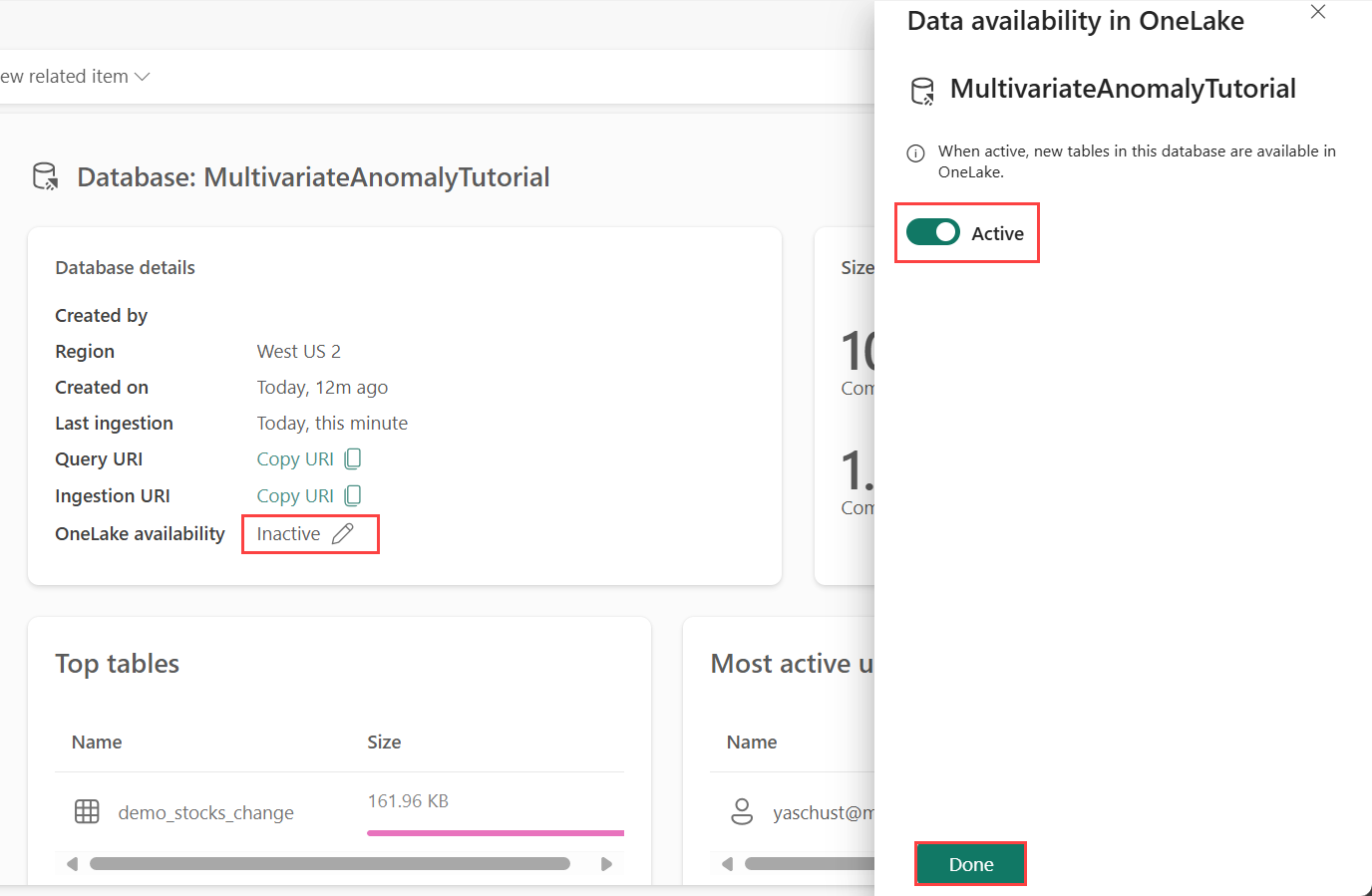
OneLake-käytettävyys on otettava käyttöön , ennen kuin saat tietoja Eventhousesta. Tämä vaihe on tärkeä, koska se mahdollistaa niiden tietojen käytön, jotka saat käyttöön OneLakessa. Myöhemmässä vaiheessa käytät näitä samoja tietoja Spark Notebookista mallin harjoittamiseksi.
Valitse työtilastasi edellytyksien mukaan luomasi Tapahtumatalo. Valitse tietokanta, johon haluat tallentaa tiedot.
Valitse Tietokannan tiedot -ruudussa Kynäkuvake OneLake-käytettävyyden vieressä
Vaihda oikeanpuoleisessa ruudussa painikkeen arvoksi Aktiivinen.
Valitse Valmis.
Osa 2– Ota KQL Python -laajennus käyttöön
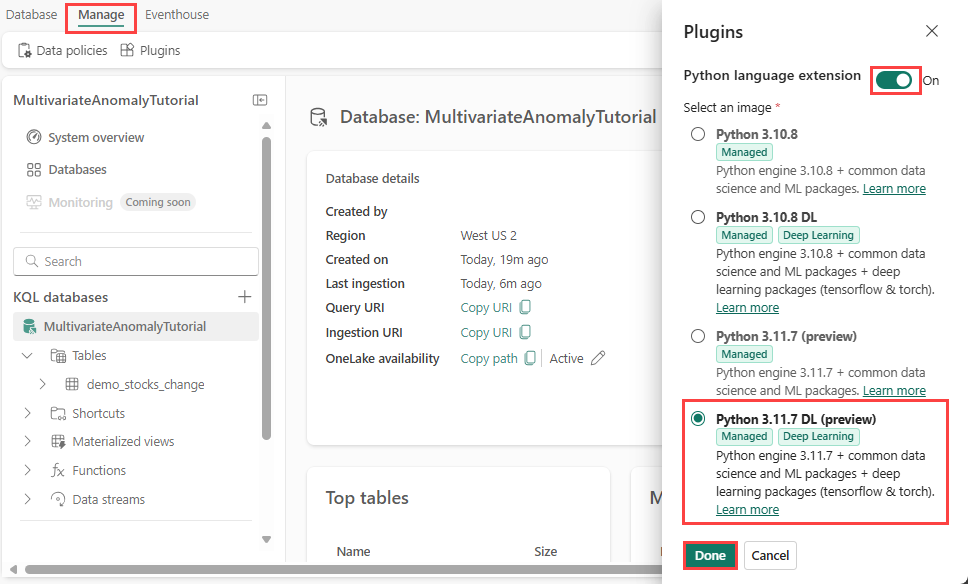
Tässä vaiheessa otat Python-laajennuksen käyttöön Eventhousessa. Tämä vaihe on pakollinen Python-koodien ennakointivaiheiden suorittamiseksi KQL-kyselyjoukossa. On tärkeää valita oikea paketti, joka sisältää time-series-anomaly-detector-paketin .
Valitse Eventhouse-näytössä tietokantasi ja valitse sitten valintanauhasta Hallitse>laajennuksia.
Vaihda Laajennukset-ruudussa Python-kielilaajennuksen arvoksiKäytössä.
Valitse Python 3.11.7 DL (esikatselu).
Valitse Valmis.
Osa 3 – Luo Spark-ympäristö
Tässä vaiheessa luot Spark-ympäristön, jossa suoritetaan Python-muistikirja, joka kouluttaa monimuuttujan poikkeamien tunnistusmallin Spark-moduulin avulla. Lisätietoja ympäristöjen luomisesta on kohdassa Ympäristöjen luominen ja hallinta.
Valitse työtilassa + Uusi kohde - ja sitten Environment.
Anna MVAD_ENV nimi ympäristölle.
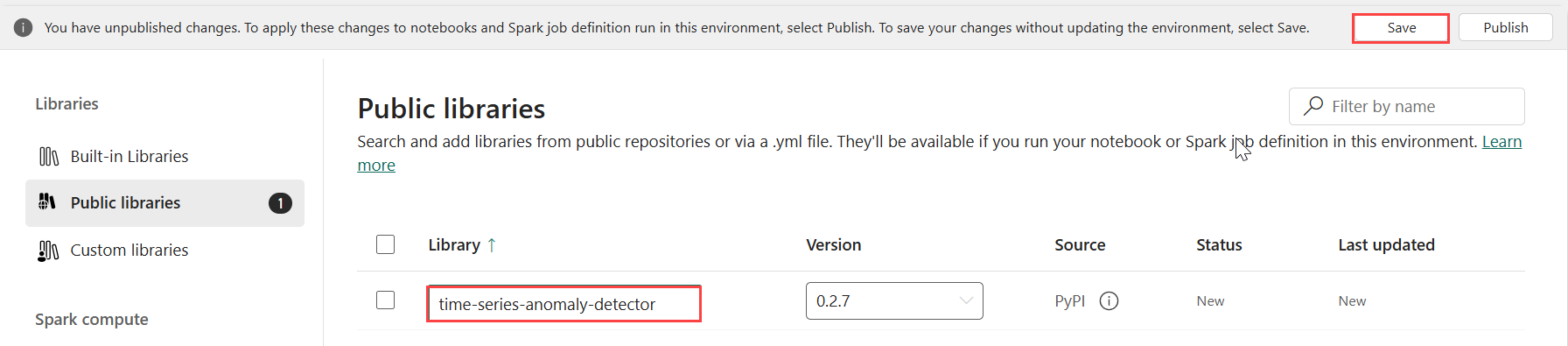
Valitse Kirjastot-kohdasta Julkiset kirjastot.
Valitse Lisää PyPI:stä.
Kirjoita hakuruutuun time-series-anomaly-detector. Versio täyttyy automaattisesti uusimmalla versiolla. Tämä opetusohjelma luotiin käyttämällä versiota 0.2.7, joka on Kusto Python 3.11.7 DL:ään sisältyvä versio.
Valitse Tallenna.
Valitse ympäristön Aloitus-välilehti .
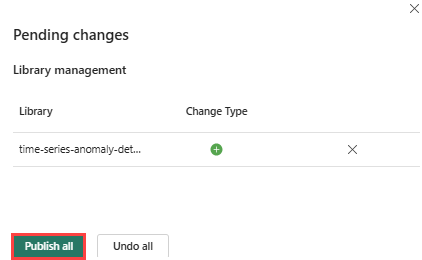
Valitse valintanauhasta Julkaise-kuvake .

Valitse Julkaise kaikki. Tämän vaiheen suorittaminen voi kestää useita minuutteja.
Osa 4 – Tietojen noutaminen Eventhouse-alueelle
Vie hiiren osoitin sen KQL-tietokannan päälle, johon haluat tallentaa tietosi. Valitse Lisää valikko [...]>Nouda tiedot>Paikallinen tiedosto.
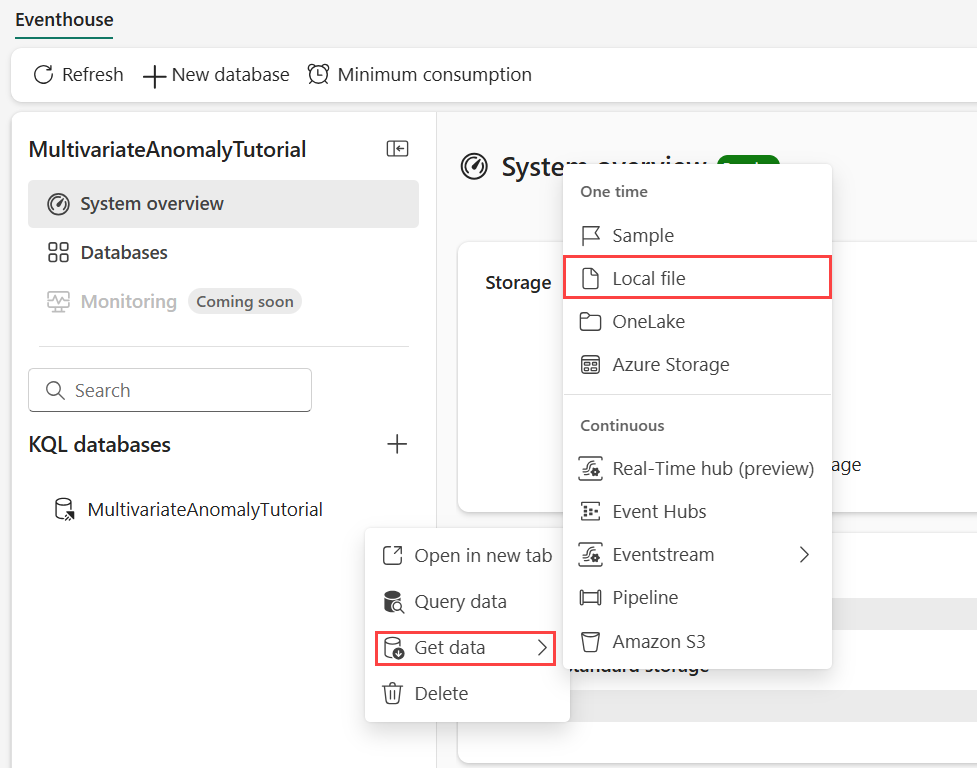
Valitse + Uusi taulukko ja kirjoita taulukon nimeksi demo_stocks_change .
Valitse Lataa tiedot -valintaikkunassa Etsi tiedostoja selaamalla ja lataa edellytykset -kohdassa ladattu mallitietotiedosto.
Valitse Seuraava.
Vaihda Tarkista tiedot -osiossa Ensimmäinen rivi on sarake -otsikko päälle.
Valitse Valmis.
Kun tiedot ladataan, valitse Sulje.
Osa 5 – OneLake-polun kopioiminen taulukkoon
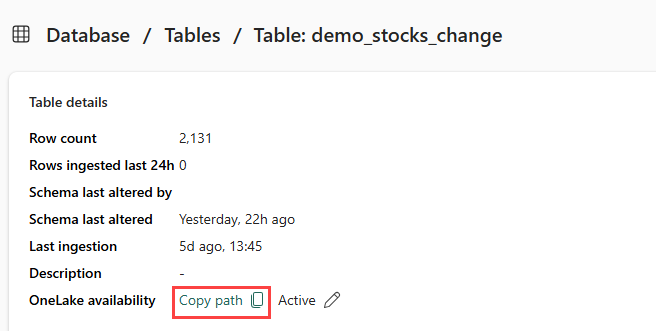
Varmista, että valitset demo_stocks_change taulukon. Kopioi OneLake-polku leikepöydälle valitsemalla Taulukon tiedot -ruudussa Kopioi polku. Tallenna tämä kopioitu teksti tekstieditoriin jossakin paikassa, jota voidaan käyttää myöhemmin.
Osa 6 - Muistikirjan valmisteleminen
Valitse työtilasi.
Valitse Tuo, Muistikirja, ja sitten Tästä tietokoneesta.
Valitse Lataa ja valitse sitten muistikirja, jonka latasit edellytyksien mukaan.
Kun muistikirja on ladattu, voit etsiä ja avata muistikirjasi työtilastasi.
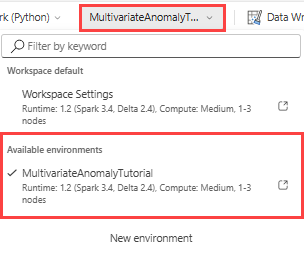
Valitse yläreunan valintanauhasta Avattava Työtilan oletus -valikko ja valitse ympäristö, jonka loit edellisessä vaiheessa.
Osa 7 - Suorita muistikirja
Tuo vakiopaketit.
import numpy as np import pandas as pdSpark tarvitsee ABFSS URI:n, jotta se voi turvallisesti muodostaa yhteyden OneLake-tallennustilaan, joten seuraavassa vaiheessa määritetään tämä funktio OneLake-URI:n muuntamiseksi ABFSS-URI:ksi.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriSyötä onelake-URI-osoitteesi, joka on kopioitu osasta 5 – OneLake-polku taulukkoon , jotta voit ladata demo_stocks_change taulukon pandas-tietokehykseen.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Valmistele harjoitus- ja ennustetietokehykset suorittamalla seuraavat solut.
Muistiinpano
Tapahtumatalo suorittaa todelliset ennusteet tiedoille osassa 9- Predict-anomalies-in-the-kql-queryset. Tuotantoskenaariossa, jos tietoja virtautettaisiin tapahtumataloon, ennusteita tehtäisiin uusista suoratoistettavasta datasta. Opetusohjelmaa varten tietojoukko on jaettu päivämäärän mukaan kahteen osioon harjoittamista ja ennustamista varten. Tämä on historiallisten tietojen ja uusien virtautettavien tietojen simulointia.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Suorita solut mallin harjoittamiseksi ja tallenna se Fabric MLflow -mallien rekisteriin.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )# Extract the registered model path to be used for prediction using Kusto Python sandbox mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)Kopioi mallin URI viimeisen solun tuloste käytettäväksi myöhemmässä vaiheessa.
Osa 8– KQL-kyselyjoukon määrittäminen
Yleisiä tietoja on kohdassa KQL-kyselyjoukon luominen.
- Valitse työtilasta +Uusi kohde>KQL-kyselyjoukon.
- Anna nimi MultivariateAnomalyDetectionTutorial, ja valitse sitten Luo.
- Valitse OneLake-tietokeskusikkunassa KQL-tietokanta, johon tallensit tiedot.
- Valitse Yhdistä.
Osa 9 – Ennakoi poikkeamia KQL-kyselyjoukossa
Kopioi/liitä ja suorita seuraava .create-or-alter-funktio-kysely tallennetun funktion
predict_fabric_mvad_fl()määrittämiseksi:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Kopioi ja liitä seuraava ennustekysely.
- Korvaa vaiheen 7 lopussa kopioitu tulosmallin URI.
- Suorita kysely. Se havaitsee viiden varaston monivariaatiopoikkeamat harjoitetun mallin perusteella ja hahmontaa tulokset muotoon
anomalychart. Ensimmäiseen kantaan (AAPL) merkitään poikkeavuuksia, vaikka ne edustavat monivariaatiopoikkeamia (toisin sanoen viiden osakkeen yhteisen muutoksen poikkeavuuksia tiettynä ajankohtana).
let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
Tuloksena saatavan poikkeamakaavion pitäisi näyttää samalta kuin seuraavassa kuvassa:

Resurssien puhdistaminen
Kun olet suorittanut opetusohjelman, voit poistaa resurssit, jotka loit, jotta siitä ei aiheutuisi muita kustannuksia. Jos haluat poistaa resursseja, toimi seuraavasti:
- Siirry työtilan aloitussivulle.
- Poista tässä opetusohjelmassa luotu ympäristö.
- Poista tässä opetusohjelmassa luotu muistikirja.
- Poista tässä opetusohjelmassa käytetty Eventhouse tai tietokanta .
- Poista tässä opetusohjelmassa luotu KQL-kyselyjoukko.