Recipe: Azure-tekoälypalvelut – monivariaatio poikkeamien tunnistaminen
Tämä resepti näyttää, miten voit käyttää SynapseML- ja Azure AI -palveluita Apache Sparkissä monivariaatioiden poikkeamien tunnistamiseen. Monivariaatiopoikkeamien tunnistuksen avulla poikkeavuudet voidaan tunnistaa useiden muuttujien tai aikasarjojen välillä ottaen huomioon kaikki eri muuttujien väliset korrelaatiot ja riippuvuudet. Tässä skenaariossa käytämme SynapseML-funktiota mallin kouluttamiseen monivariaatioiden tunnistamiseen Azure-tekoälypalveluiden avulla, ja käytämme sitten mallia poikkeamien päättelemiseen tietojoukossa, joka sisältää synteettisiä mittauksia kolmesta IoT-anturista.
Tärkeä
Syyskuun 20. päivästä 2023 alkaen et voi luoda uusia Poikkeamien tunnistus resursseja. Poikkeamien tunnistus -palvelu poistetaan käytöstä 1.10.2026.
Lisätietoja AzureN tekoälyn Poikkeamien tunnistus on tällä dokumentaatiosivulla.
Edellytykset
- Azure-tilaus – luo sellainen ilmaiseksi
- Liitä muistikirjasi Lakehouseen. Valitse vasemmalla puolella Lisää lisätäksesi aiemmin luodun lakehousen tai luodaksesi lakehousen.
Asetusten määrittäminen
Noudata ohjeita resurssin Anomaly Detector luomiseksi Azure-portaali avulla. Vaihtoehtoisesti voit myös luoda tämän resurssin Azure CLI:n avulla.
Kun olet määrittänyt - Anomaly Detectorkohteen, voit tutkia eri lomakkeiden tietojen käsittelytapoja. Azure AI:n palveluhakemisto tarjoaa useita vaihtoehtoja: vision, puheen, kielen, verkkohaun, päätöksen, käännöksen ja asiakirjan hallinnan.
Poikkeamien tunnistus resurssin luominen
- Valitse Azure-portaali Luo resurssiryhmässä ja kirjoita sitten Poikkeamien tunnistus. Valitse Poikkeamien tunnistus resurssi.
- Anna resurssille nimi ja käytä ihannetapauksessa samaa aluetta kuin muutkin resurssiryhmäsi. Käytä muiden oletusasetuksia, ja valitse sitten Review + Create ja sitten Luo.
- Kun Poikkeamien tunnistus resurssi on luotu, avaa se ja valitse vasemman siirtymisruudun
Keys and Endpointspaneeli. Kopioi Poikkeamien tunnistus resurssin avain ympäristömuuttujaanANOMALY_API_KEYtai tallenna se muuttujaananomalyKey.
Tallennustilin resurssin luominen
Jos haluat tallentaa välitiedot, sinun on luotava Azure Blob -säilötili. Luo kyseisellä tallennustilillä säilö välitietojen tallentamista varten. Kirjaa säilön nimi muistiin ja kopioi yhteysmerkkijono kyseiseen säilöön. Tarvitset sitä myöhemmin, jotta voit täyttää muuttujan containerName ja ympäristömuuttujan BLOB_CONNECTION_STRING .
Anna palveluavaimesi
Aloitetaan määrittämällä ympäristömuuttujat palveluavaimille. Seuraava solu määrittää - ANOMALY_API_KEY ja BLOB_CONNECTION_STRING -ympäristömuuttujat Azure Key Vaultiin tallennettujen arvojen perusteella. Jos suoritat tätä opetusohjelmaa omassa ympäristössäsi, varmista, että määrität nämä ympäristömuuttujat, ennen kuin jatkat.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Seuraavaksi voidaan lukea - ja BLOB_CONNECTION_STRING -ANOMALY_API_KEYympäristömuuttujat ja määrittää - ja location -containerNamemuuttujat.
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Ensin yhdistämme tallennustiliimme, jotta poikkeamien tunnistaminen voi tallentaa välituloksia:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Tuodaanpa kaikki tarvittavat moduulit.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
Seuraavaksi luemme mallitietomme Spark DataFrame -kehykseen.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Voimme nyt luoda objektin estimator , jota käytetään mallimme harjoittamiseen. Määritämme harjoitustietojen alkamis- ja päättymisajat. Määritämme myös käytettävät syötesarakkeet ja aikaleimat sisältävän sarakkeen nimen. Lopuksi määritämme poikkeamien tunnistamisen liukumisikkunassa käytettävien arvopisteiden määrän ja määritämme yhteysmerkkijonon Azure Blob -säilön tilille.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Nyt kun olemme luoneet - estimatorsovelluksen, sovitetaan se tietoihin:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Kun edellisessä solussa soitimme .show(5) , se näytti meille tietokehyksen viisi ensimmäistä riviä. Tulokset olivat kaikki null , koska ne eivät olleet pääteikkunan sisällä.
Jos haluat näyttää tulokset vain päätetyille tiedoille, valitse tarvitsemamme sarakkeet. Voimme sitten järjestystä tietokehyksen rivit nousevassa järjestyksessä ja suodattaa tuloksen näyttämään vain rivit, jotka ovat tulosikkunan alueella. Tässä tapauksessa inferenceEndTime se on sama kuin tietokehyksen viimeinen rivi, joten se voidaan ohittaa.
Lopuksi, jotta tulokset voidaan piirtää paremmin, voidaan muuntaa Spark-tietokehys Pandas-tietokehykseksi.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
contributors Muotoile sarake, joka tallentaa kunkin anturin osallistumispisteet havaittuihin poikkeavuuksiin. Seuraava solu muotoilee nämä tiedot ja jakaa kunkin anturin osallistumispisteet omaan sarakkeeseensa.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Hienoa! Antureiden 1, 2 ja 3 osallistumispisteet ovat nyt sarakkeissa series_0, series_1ja series_2 .
Suorita seuraava solu tulosten tulostamiseksi. minSeverity Parametri määrittää piirrettyjen poikkeamien vähimmäisvakavuusasteen.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
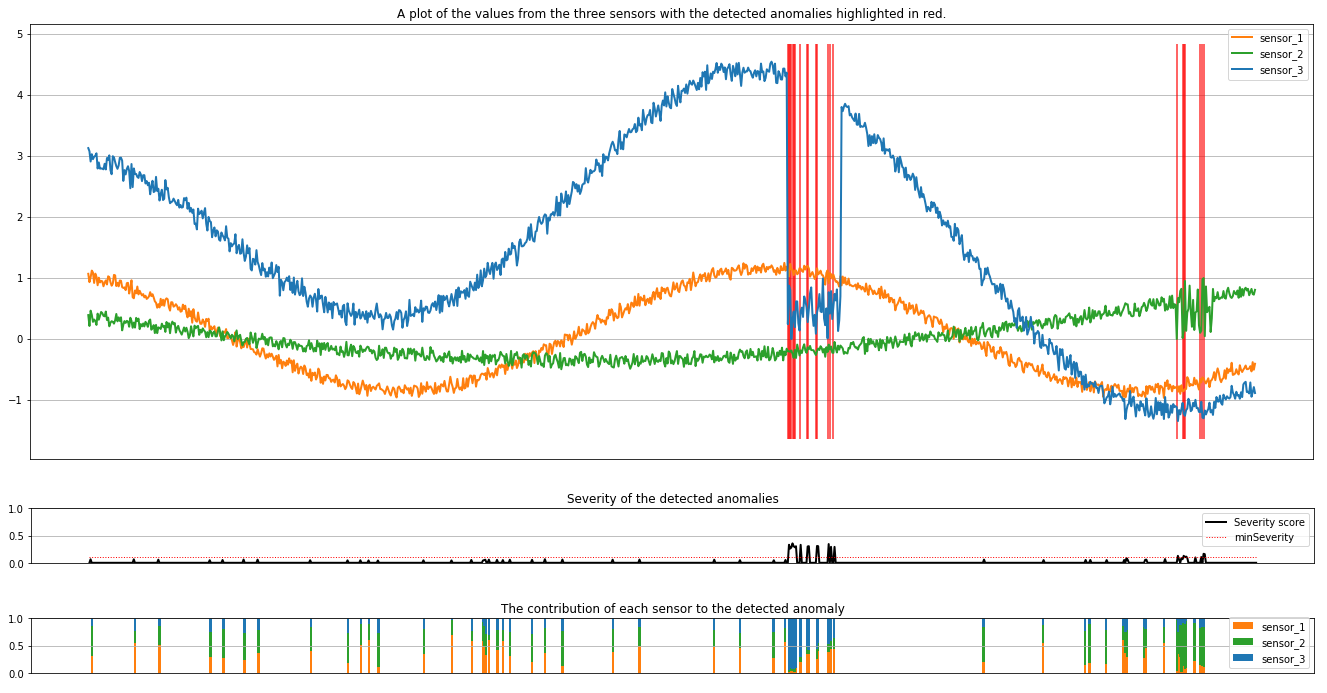
Kaaviot näyttävät antureiden raakatiedot (pääteikkunan sisällä) oranssilla, vihreällä ja sinisellä. Ensimmäisen kuvan punaiset pystyviivat näyttävät havaitut poikkeavuudet, joiden vakavuus on suurempi tai yhtä suuri minSeveritykuin .
Toinen kaavio näyttää kaikkien havaittujen poikkeamien vakavuuspisteet niin, että minSeverity kynnysarvo näkyy pisteviivalla.
Lopuksi viimeinen piirto näyttää kunkin anturin tietojen osuuden havaituista poikkeamista. Se auttaa meitä diagnosoimaan ja ymmärtämään kunkin poikkeaman todennäköisimmän syyn.