Tietojen muuntaminen suorittamalla Azure Databricks -toiminto
Azure Databricks -toiminnon Data Factory for Microsoft Fabricin avulla voit järjestää seuraavat Azure Databricks -työt:
- Muistikirja
- Purkki
- Python
Tässä artikkelissa annetaan vaiheittaiset ohjeet Azure Databricks -aktiviteetin luomiseen Data Factory -käyttöliittymän avulla.
Edellytykset
Jotta voit aloittaa, sinun on täytettävä seuraavat edellytykset:
- Vuokraajatili, jolla on aktiivinen tilaus. Luo ilmainen tili.
- Luodaan työtila.
Azure Databricks -aktiviteetin määrittäminen
Jos haluat käyttää Azure Databricks -toimintoa putkessa, suorita seuraavat vaiheet:
Yhteyden määrittäminen
Luo uusi putki työtilaasi.
Valitse Lisää putki-toiminto ja etsi Azure Databricks.
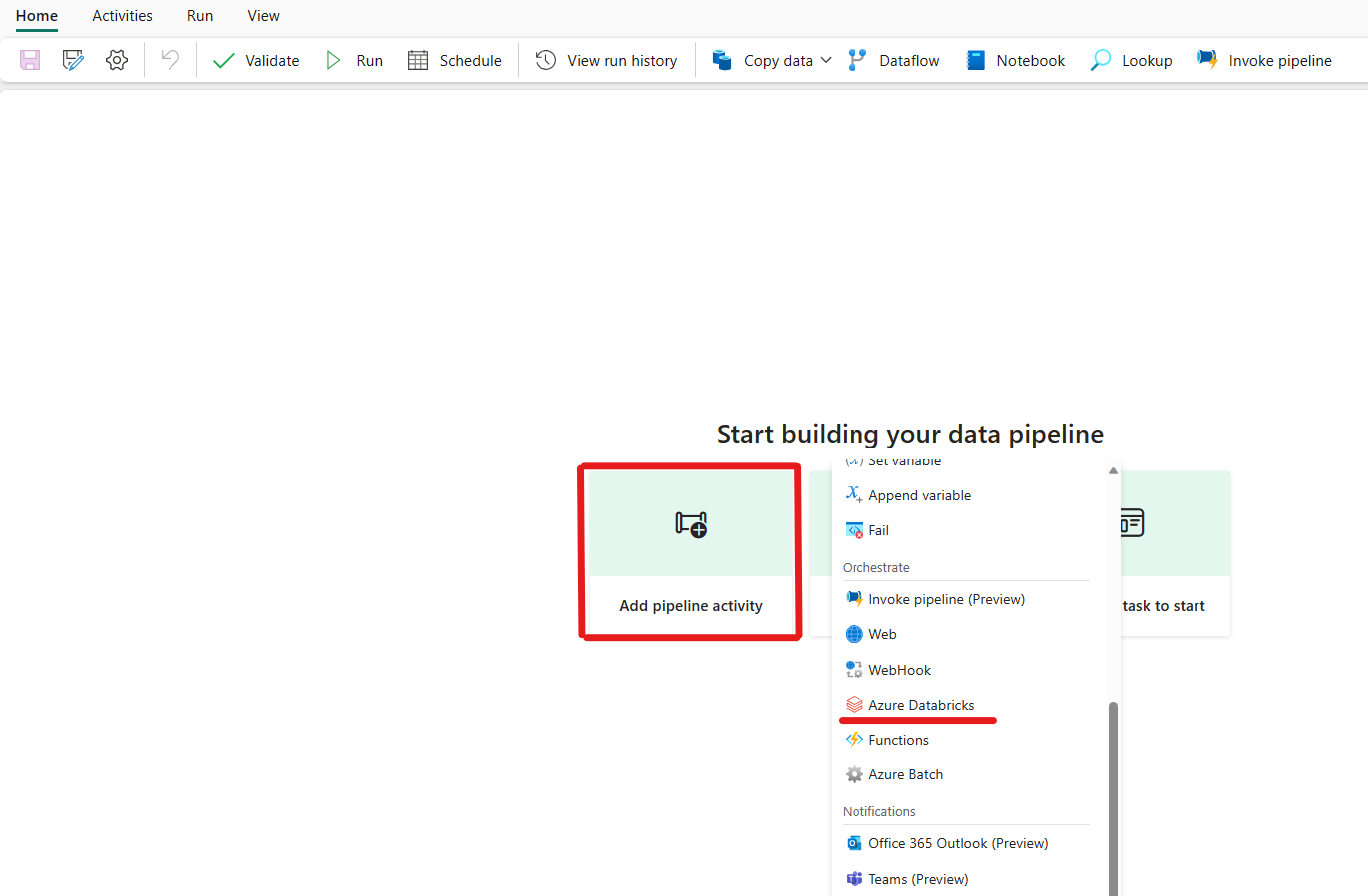
Vaihtoehtoisesti voit hakea Azure Databricksin putken Aktiviteetit-ruudusta ja valita sen lisätäksesi sen putken pohjaan.
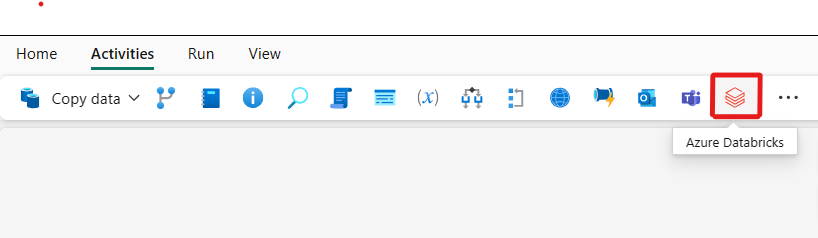
Valitse uusi Azure Databricks -toiminto pohjalta, jos sitä ei ole vielä valittu.
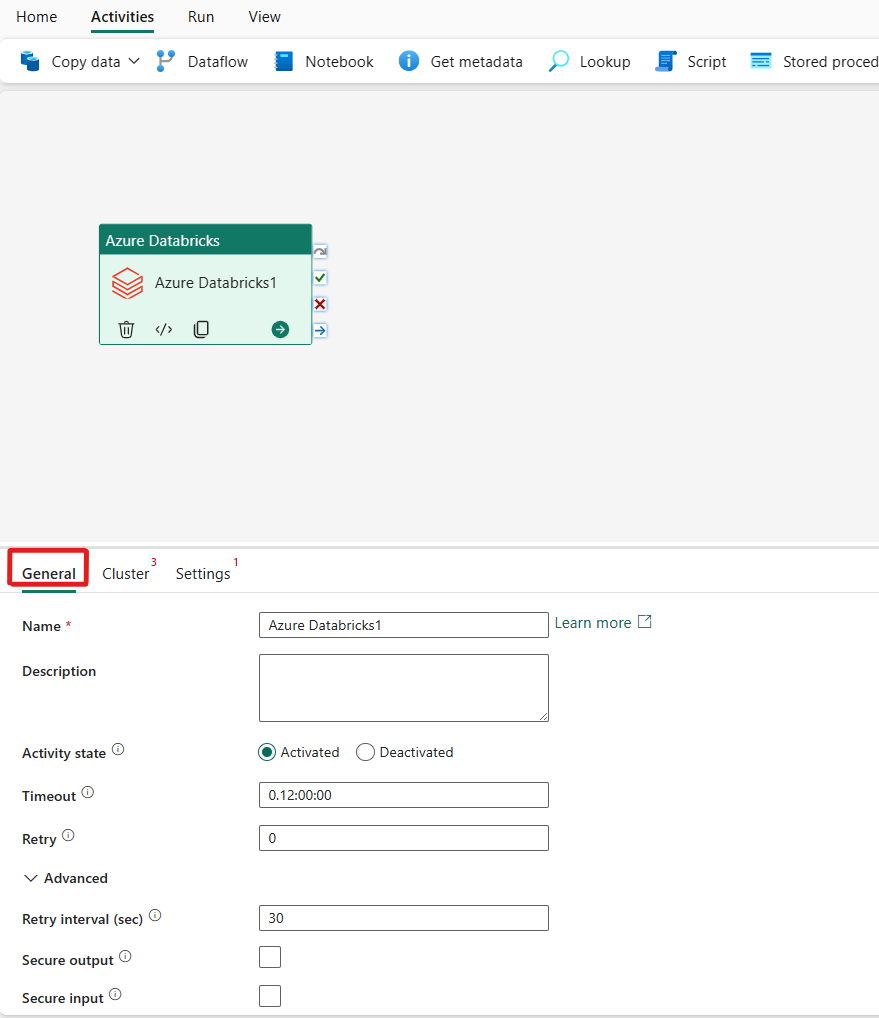
Yleiset asetukset -välilehden määrittäminen on yleisissä asetuksissa.
Klustereiden määrittäminen
Valitse Klusteri-välilehti. Sen jälkeen voit valita olemassa olevan tai luoda uuden Azure Databricks -yhteyden ja sitten valita uuden työklusterin, aiemmin luodun vuorovaikutteisen klusterin tai olemassa olevan esiintymävarannon.
Täytä vastaavat kentät esitetyllä tavalla sen mukaan, mitä klusteria varten valitaan.
- Uudessa työklusterissa ja olemassa olevassa esiintymävarannossa voit myös määrittää työntekijöiden määrän ja ottaa käyttöön paikkaesiintymiä.
Voit myös määrittää muita klusteriasetuksia, kuten klusterikäytännön, Spark-määrityksen, Spark-ympäristömuuttujat ja mukautetut tunnisteet, joita tarvitaan yhdistettävässä klusterissa. Tietobricksin init-komentosarjat ja klusterilokin kohdepolku voidaan myös lisätä klusterin lisäasetuksissa.
Muistiinpano
Kaikkia azure data factory Azure Databricksin linkitetyssä palvelussa tuettuja kehittyneitä klusteriominaisuuksia ja dynaamisia lausekkeita tuetaan nyt myös Azure Databricks -toiminnossa Microsoft Fabricissa käyttöliittymän Lisäklusterimääritykset-osiossa. Koska nämä ominaisuudet sisältyvät nyt toiminnon käyttöliittymään; Niitä voi käyttää helposti lausekkeen (dynaamisen sisällön) kanssa ilman kehittyneitä JSON-määrityksiä Azure Data Factory Azure Databricks -linkitetyssä palvelussa.
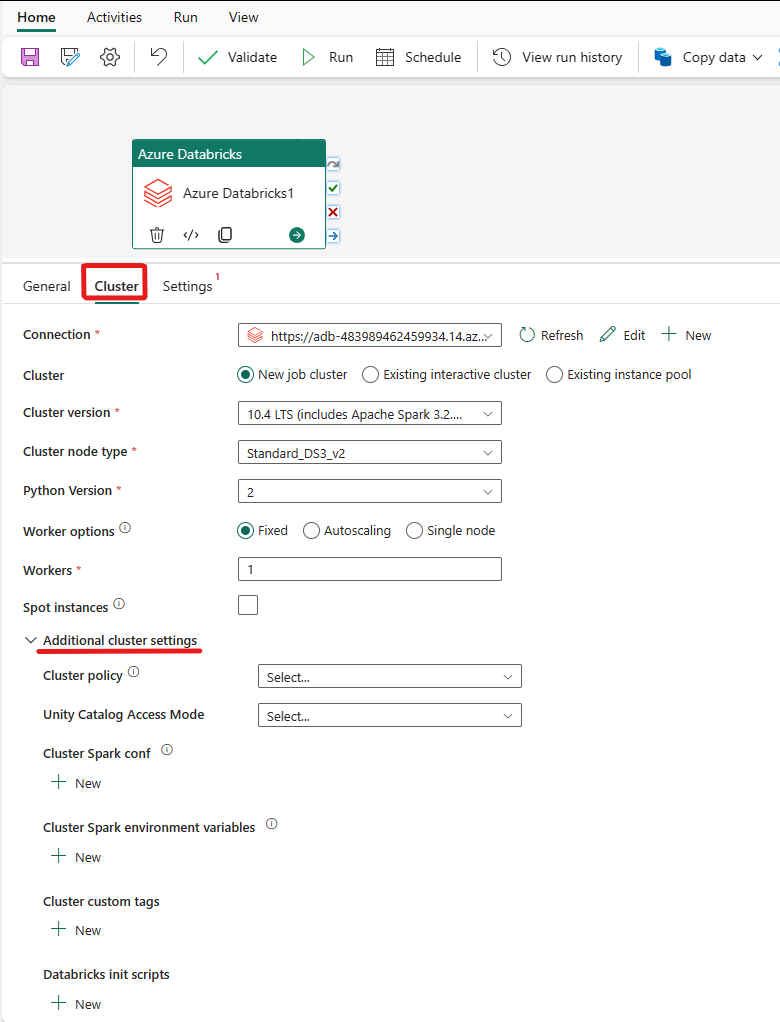
Azure Databricks Activity tukee nyt myös klusterikäytäntöä ja Unity Catalog -tukea.
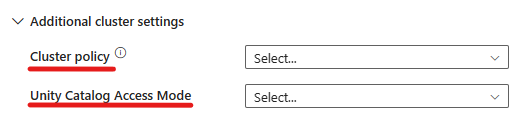
- Lisäasetuksissa voit valita klusterikäytännön, jotta voit määrittää sallitut klusterimääritykset.
- Lisäasetuksissa voit myös määrittää Unityn hakemiston käyttöoikeustilan suojauksen lisäämistä varten. Käytettävissä olevat käyttötilatyypit ovat seuraavat:
- Yhden käyttäjän käyttöoikeustila Tämä tila on suunniteltu tilanteisiin, joissa yksittäinen käyttäjä käyttää kutakin klusteria. Se varmistaa, että klusterin tietojen käyttö on rajoitettu vain kyseiselle käyttäjälle. Tästä tilasta on hyötyä eristämistä ja yksittäisten tietojen käsittelyä edellyttävillä tehtävillä.
- Jaettu käyttöoikeustila Tässä tilassa useat käyttäjät voivat käyttää samaa klusteria. Siinä yhdistyvät Unity Catalogin tietohallinto ja vanhojen taulukoiden käyttöoikeuksien hallintaluettelot. Tämä tila mahdollistaa tietojen yhteiskäyttöoikeuden ja samalla hallinto- ja suojausprotokollien ylläpidon. Sillä on kuitenkin tiettyjä rajoituksia, jotka eivät tue Databricks Runtime ML:ää, Spark-submit-töitä ja tiettyjä Spark-ohjelmointirajapintoja ja UDF:iä.
- Ei käyttötilaa Tämä tila poistaa käytöstä vuorovaikutuksen Unity Catalogn kanssa, mikä tarkoittaa, että klustereilla ei ole käyttöoikeutta Unity Catalogn hallitsemiin tietoihin. Tästä tilasta on hyötyä kuormituksille, jotka eivät edellytä Unity Catalogn hallinto-ominaisuuksia.
Asetusten määrittäminen
Valitsemalla Asetukset-välilehden voit valita kolme vaihtoehtoa, jotka Azure Databricks -tyyppinen haluat järjestää.
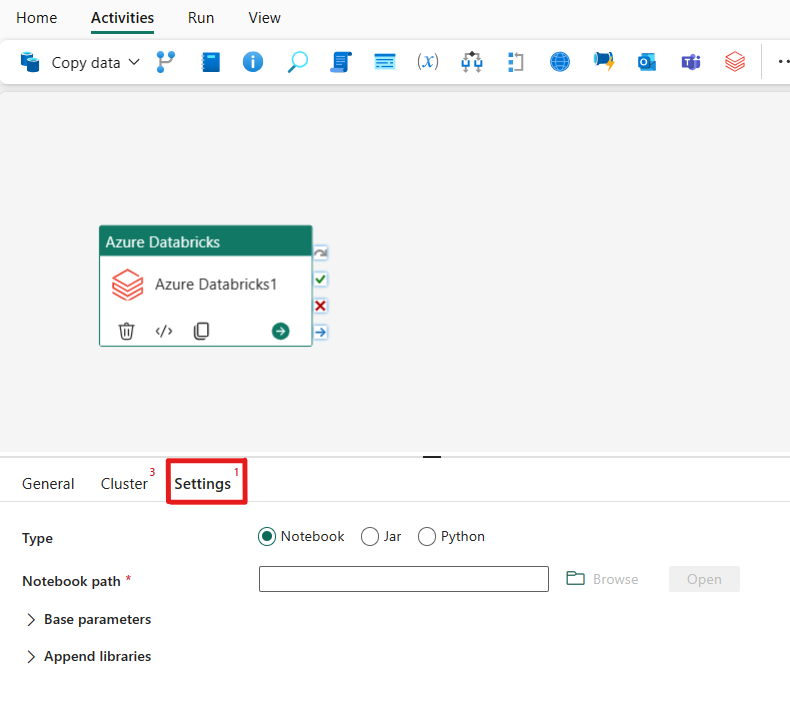
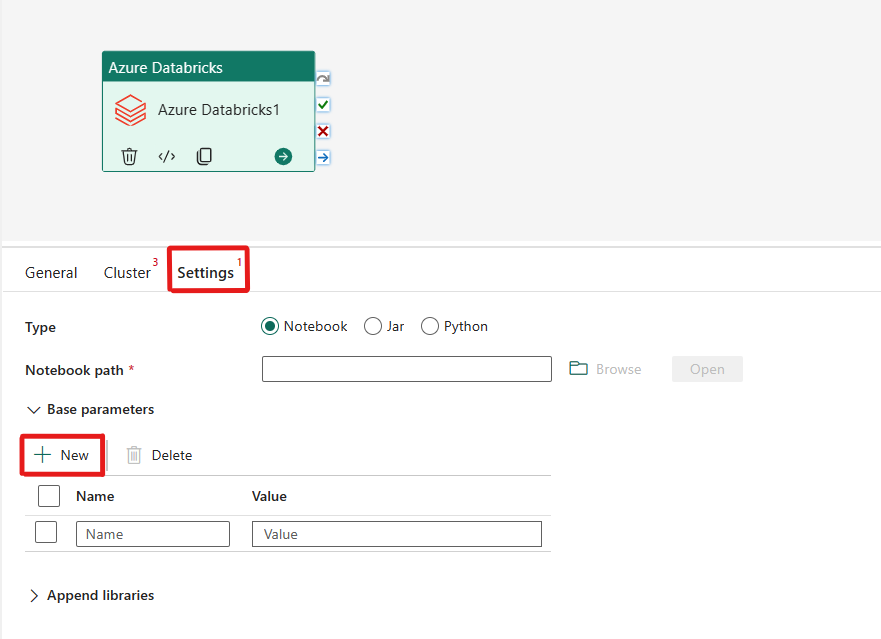
Muistikirjatyypin järjestäminen Azure Databricks -aktiviteetissa:
Asetukset-välilehdessä voit suorittaa muistikirjan valitsemalla Muistikirja-valintanapin. Sinun on määritettävä muistikirjapolku, joka suoritetaan Azure Databricksissä, valinnaiset perusparametrit välitettäväksi muistikirjaan ja mahdolliset lisäkirjastot, jotka on asennettava klusteriin työn suorittamiseksi.
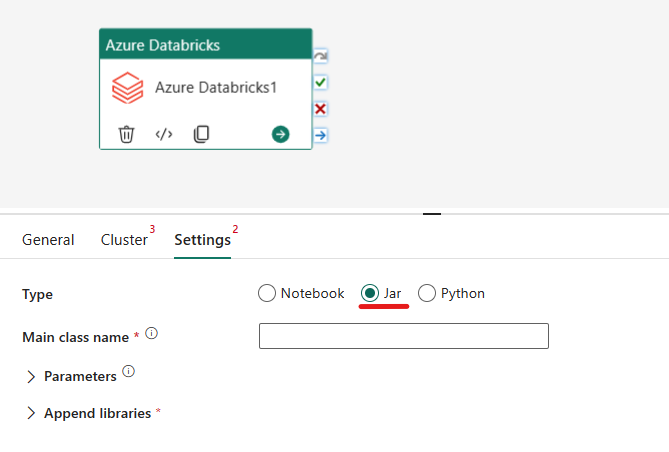
Jar-tyypin järjestäminen Azure Databricks -aktiviteetissa:
Asetukset-välilehdessä voit suorittaa Jar-painikkeen. Sinun on määritettävä Luokan nimi, joka suoritetaan Azure Databricksissä, jarille välitettävät valinnaiset perusparametrit ja mahdolliset lisäkirjastot, jotka on asennettava klusteriin työn suorittamiseksi.
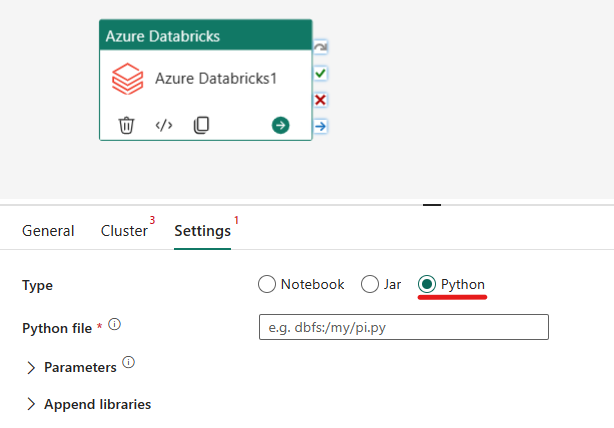
Python-tyypin järjestäminen Azure Databricks -toiminnassa:
Asetukset-välilehdessä voit valita Python-valintanapin Python-tiedoston suorittamiseksi. Sinun on määritettävä Azure Databricksin polku Python-tiedostoon suoritettavaksi, välitettävät valinnaiset perusparametrit ja klusteriin asennettavat lisäkirjastot työn suorittamiseksi.
Azure Databricks -toiminnon tuetut kirjastot
Yllä olevassa Databricks-toiminnan määrityksessä voit määrittää nämä kirjastotyypit: purkki, muna, whl, maven, pypi, cran.
Saat lisätietoja kirjastotyyppien Databricks-dokumentaatiosta .
Parametrien välittäminen Azure Databricksin toimintojen ja jaksojen välillä
Voit välittää parametrit muistikirjoihin käyttämällä baseParameters-ominaisuutta databricks-toiminnassa.
Joissakin tapauksissa saatat joutua siirtämään joitakin arvoja muistikirjasta takaisin palveluun, jota voidaan käyttää työnkulun hallintaan (ehdolliset tarkastukset) palvelussa tai jatkotoimintoihin (kokorajoitus on 2 Mt).
Muistikirjassasi voit esimerkiksi kutsua dbutils.notebook.exit ("returnValue") ja vastaava "returnValue" palautetaan palveluun.
Voit käyttää palvelun tulosta käyttämällä lauseketta, kuten
@{activity('databricks activity name').output.runOutput}.
Putken tallentaminen ja suorittaminen tai ajoittaminen
Kun olet määrittänyt putkelle tarvittavat muut toiminnot, siirry putkieditorin yläreunassa olevaan Aloitus-välilehteen ja tallenna putki valitsemalla Tallenna-painike. Valitse Suorita , jos haluat suorittaa sen suoraan, tai Ajoita se. Voit myös tarkastella suoritushistoriaa täällä tai määrittää muita asetuksia.
