Apache Spark -neuvonantaja reaaliaikaisille neuvoille muistikirjoissa
Apache Spark -neuvonantaja analysoi Apache Sparkin suorittamia komentoja ja koodia ja näyttää reaaliaikaisia neuvoja notebook-suorituksia varten. Apache Spark -neuvonantajalla on sisäänrakennettuja malleja, jotka auttavat käyttäjiä välttämään yleisiä virheitä. Se tarjoaa suosituksia koodin optimoinnille, suorittaa virheanalyysin ja paikantaa virheiden perimmäisen syyn.
Sisäänrakennetut neuvot
Impulssiin integroitu Spark-työkalu tarjoaa sisäisiä malleja Apache Spark -sovellusten ongelmien tunnistamiseen ja ratkaisemiseen. Tässä artikkelissa kerrotaan joistakin työkaluun sisältyvistä malleista.
Voit avata Viimeisimmät suoritukset -ruudun tarvitsemasi neuvojen tyypin perusteella.
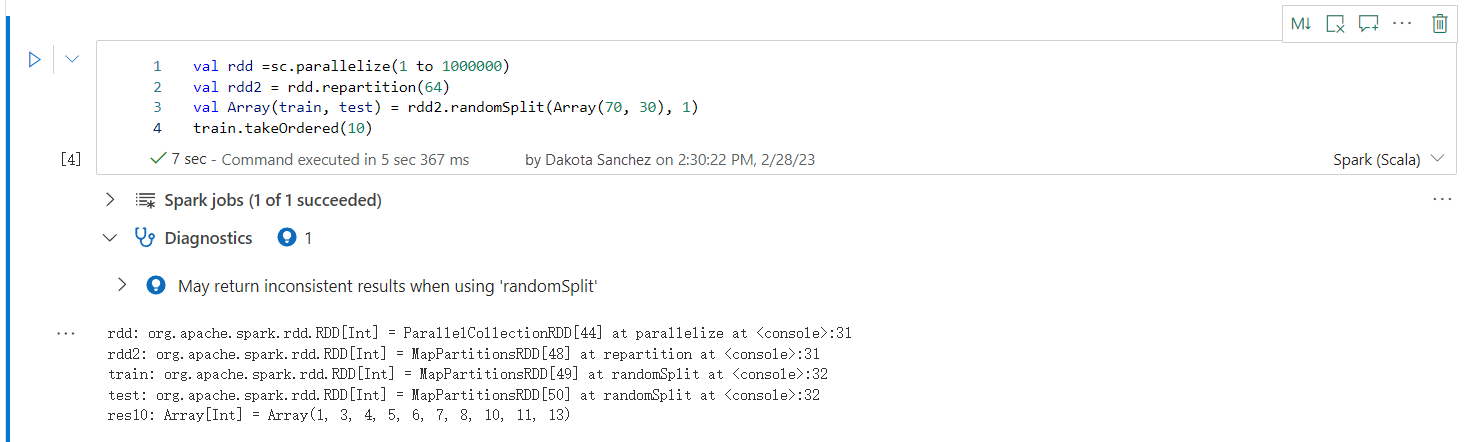
Saattavat palauttaa epäyhtenäisiä tuloksia käytettäessä randomSplit-funktiota
Epäyhtenäisiä tai epätarkkoja tuloksia voidaan palauttaa, kun käytät randomSplit-menetelmää . Käytä Apache Spark (RDD) -välimuistitallennusta ennen randomSplit()-menetelmän käyttämistä.
Method randomSplit() vastaa näytteen() suorittamista tiedoistasi useita kertoja. Jossa kukin malli muotoilee uudelleen, osioi ja lajittelee tietokehyksen osioiden sisälle. Tietojen jakautuminen osioiden välillä ja lajittelujärjestys ovat tärkeitä sekä satunnaiselleSplit()- että sample()-lle. Jos jompikumpi tietojen refet-toiminnosta muuttuu, arvojen välillä voi olla kaksoiskappaleita tai puuttuvia arvoja. Sama samaa siementä käyttävä malli voi tuottaa erilaisia tuloksia.
Näitä epäyhtenäisyksiä ei välttämättä tapahdu jokaisessa ajossa, mutta niiden poistamiseksi kokonaan voit poistaa tietokehyksen välimuistista, suorittaa uudelleen sarakkeen tai sarakkeisiin tai käyttää koostefunktioita, kuten groupBy.
Taulukon/näkymän nimi on jo käytössä
Näkymä on jo olemassa samalla nimellä kuin luotu taulukko tai taulukko, jolla on jo sama nimi kuin luotulla näkymällä. Kun tätä nimeä käytetään kyselyissä tai sovelluksissa, vain näkymä palautetaan riippumatta siitä, mikä niistä luotiin ensin. Voit välttää ristiriidat nimeämällä taulukon tai näkymän uudelleen.
Vihjettä ei tunnisteta
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
Määritettyä suhteen nimeä tai määritettyjä relaationimiä ei löydy
Vihjeessä määritettyjä relaatioita ei löydy. Varmista, että suhteet on kirjoitettu oikein ja että ne ovat käytettävissä vihjeen laajuudessa.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Kyselyn vihje estää toisen vihjeen käytön
Valittu kysely sisältää vihjeen, joka estää toisen vihjeen käytön.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Ota käyttöön 'spark.advise.divisionExprConvertRule.enable' pyöristysvirheiden leviämisen vähentämiseksi
Tämä kysely sisältää lausekkeen, jonka tyyppi on Double. Suosittelemme, että otat käyttöön määrityksen 'spark.advise.divisionExprConvertRule.enable', joka voi auttaa pienentämään jakolausekkeita ja pienentämään pyöristysvirheen levittämistä.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
Ota käyttöön spark.advise.nonEqJoinConvertRule.enable kyselyjen suorituskyvyn parantamiseksi
Tämä kysely sisältää aikaa vievää liitosta kyselyn Or-ehdon vuoksi. Suosittelemme, että otat käyttöön määrityksen 'spark.advise.nonEqJoinConvertRule.enable', joka voi auttaa muuntamaan Or-ehdon käynnistämän liitosten SMJ: lle tai BHJ: lle tämän kyselyn nopeuttamiseksi.
Käyttäjäkokemus
Apache Spark -neuvonantaja näyttää ohjeen, mukaan lukien tiedot, varoitukset ja virheet, Notebookin solutulosteessa reaaliaikaisesti.
Info
Varoitus
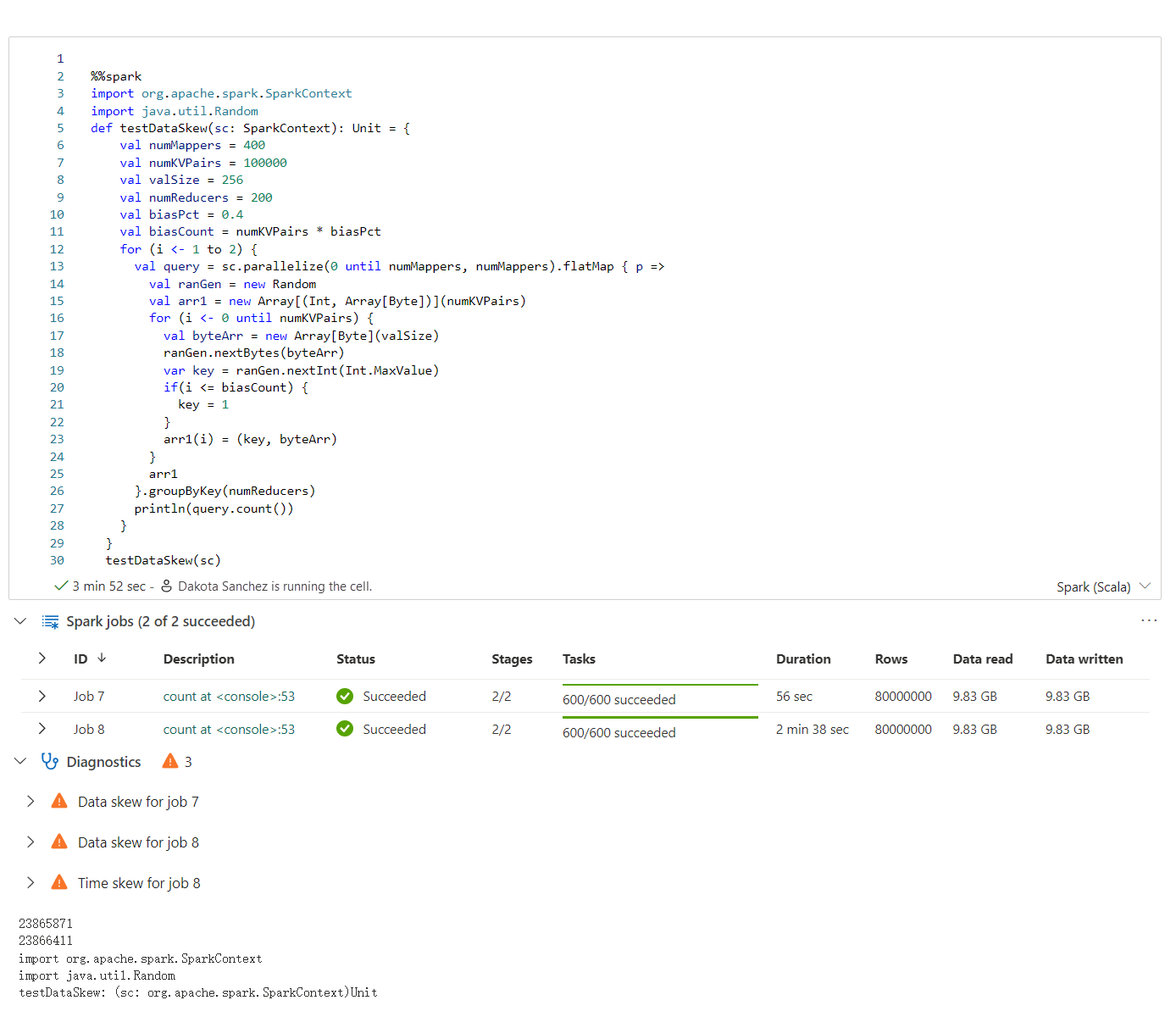
Virhe
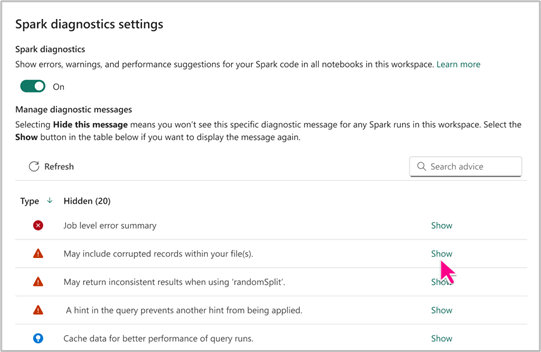
Spark Advisor -asetus
Spark-neuvonantaja-asetuksen avulla voit valita, haluatko näyttää tai piilottaa tietyntyyppisiä Spark-neuvoja tarpeidesi mukaan. Voit halutessasi ottaa spark advisorin käyttöön tai poistaa sen käytöstä työtilassa.
Saat käyttöösi Spark Advisor -asetukset Fabric Notebook -tasolla, jolloin voit nauttia sen eduista ja varmistaa tuottavan muistikirjan luontikokemuksen.