Lataa tietoja Lakehouse-järveen muistikirjan avulla
Tässä opetusohjelmassa opit lukemaan ja kirjoittamaan tietoja Fabric Lakehouse -tallennustilaan muistikirjalla. Fabric tukee Spark-ohjelmointirajapintaa ja Pandas-ohjelmointirajapintaa tämän tavoitteen saavuttamiseksi.
Tietojen lataaminen Apache Spark -ohjelmointirajapinnalla
Käytä muistikirjan koodisolussa seuraavaa koodiesimerkkiä tietojen lukemiseen lähteestä ja sen lataamiseen Lakehousen Tiedostoihin, taulukoihin tai molempiin osiin.
Voit määrittää luettavan sijainnin suhteellisen polun avulla, jos tiedot ovat nykyisen muistikirjasi oletusjärvitalosta. Tai jos tiedot ovat peräisin eri lakehousesta, voit käyttää absoluuttista Azure Blob File System (ABFS) -polkua. Kopioi tämä polku tietojen pikavalikosta.
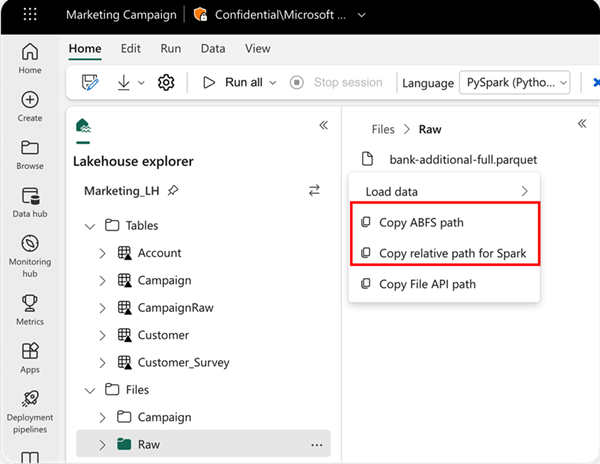
Kopioi ABFS-polku: Tämä asetus palauttaa tiedoston absoluuttisen polun.
Kopioi suhteellinen polku Sparkille: Tämä vaihtoehto palauttaa tiedoston suhteellisen polun oletusjärventalossa.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Tietojen lataaminen Pandas-ohjelmointirajapinnan avulla
Pandas-ohjelmointirajapinnan tukemiseksi oletusjärvitalo asennetaan automaattisesti muistikirjaan. Kiinnityskohta on /Lakehouse/default/. Voit käyttää tätä käyttöönottopistettä tietojen lukemiseen/kirjoittamiseen oletusasemasta tai oletustaloon. Pikavalikon Kopioi tiedoston ohjelmointirajapintapolku -vaihtoehto palauttaa Tiedoston ohjelmointirajapinnan polun kyseisestä asennuspisteestä. Kopioi ABFS -polusta palautettu polku toimii myös Pandas-ohjelmointirajapinnan kanssa.
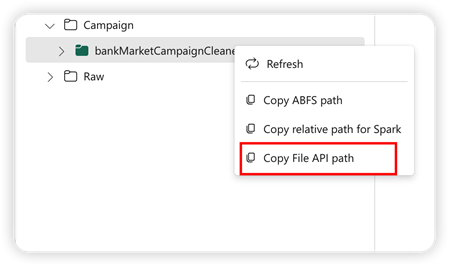
Kopioi tiedoston ohjelmointirajapinnan polku: Tämä vaihtoehto palauttaa polun oletusjärven asennuskohdan alapuolella.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Vihje
Spark-ohjelmointirajapinnan tapauksessa saat tiedoston polun valitsemalla Kopioi ABFS-polku tai Kopioi suhteellinen polku Sparkille . Jos kyseessä on Pandas-ohjelmointirajapinta, käytä vaihtoehtoa Kopioi ABFS-polku tai Kopioi tiedoston ohjelmointirajapinta -polku tiedoston polun saamiseksi.
Nopein tapa saada koodi toimimaan Spark-ohjelmointirajapinnan tai Pandas-ohjelmointirajapinnan kanssa on käyttää Lataa tiedot -vaihtoehtoa ja valita ohjelmointirajapinta, jota haluat käyttää. Koodi luodaan automaattisesti muistikirjan uuteen koodisoluun.
