Livy-ohjelmointirajapinnan avulla voit lähettää ja suorittaa Livy-erätöitä
Muistiinpano
Fabric Data Engineeringin Livy-ohjelmointirajapinta on esikatselussa.
Koskee seuraavia:✅ Microsoft Fabricin tietotekniikka ja datatiede
Lähetä Spark-erätöitä Fabric Data Engineeringin Livy-ohjelmointirajapinnan avulla.
Edellytykset
Fabric Premium - tai kokeiluversion kapasiteetti Lakehousella.
Etäasiakas, kuten Visual Studio Code , jossa on Jupyter Notebooks, PySpark ja Microsoft Authentication Library (MSAL) for Python.
Fabric Rest -ohjelmointirajapinnan käyttämiseen vaaditaan Microsoft Entra -sovellustunnus. Rekisteröi sovellus Microsoftin käyttäjätietoympäristössä.
Jotkin tiedot lakehousessa, tässä esimerkissä käytetään NEWC Taxi & Limousine Commission green_tripdata_2022_08 lakehouseen ladattua parquet-tiedostoa.
Livy-ohjelmointirajapinta määrittää toimintojen yhtenäisen päätepisteen. Korvaa paikkamerkit {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} ja {Fabric_LakehouseID} sopivilla arvoilla, kun noudatat tämän artikkelin esimerkkejä.
Visual Studio Coden määrittäminen Livy-ohjelmointirajapintaerälle
Valitse Lakehouse-asetukset Fabric Lakehouse -kohteessasi.

Siirry Livy-päätepisteosioon.
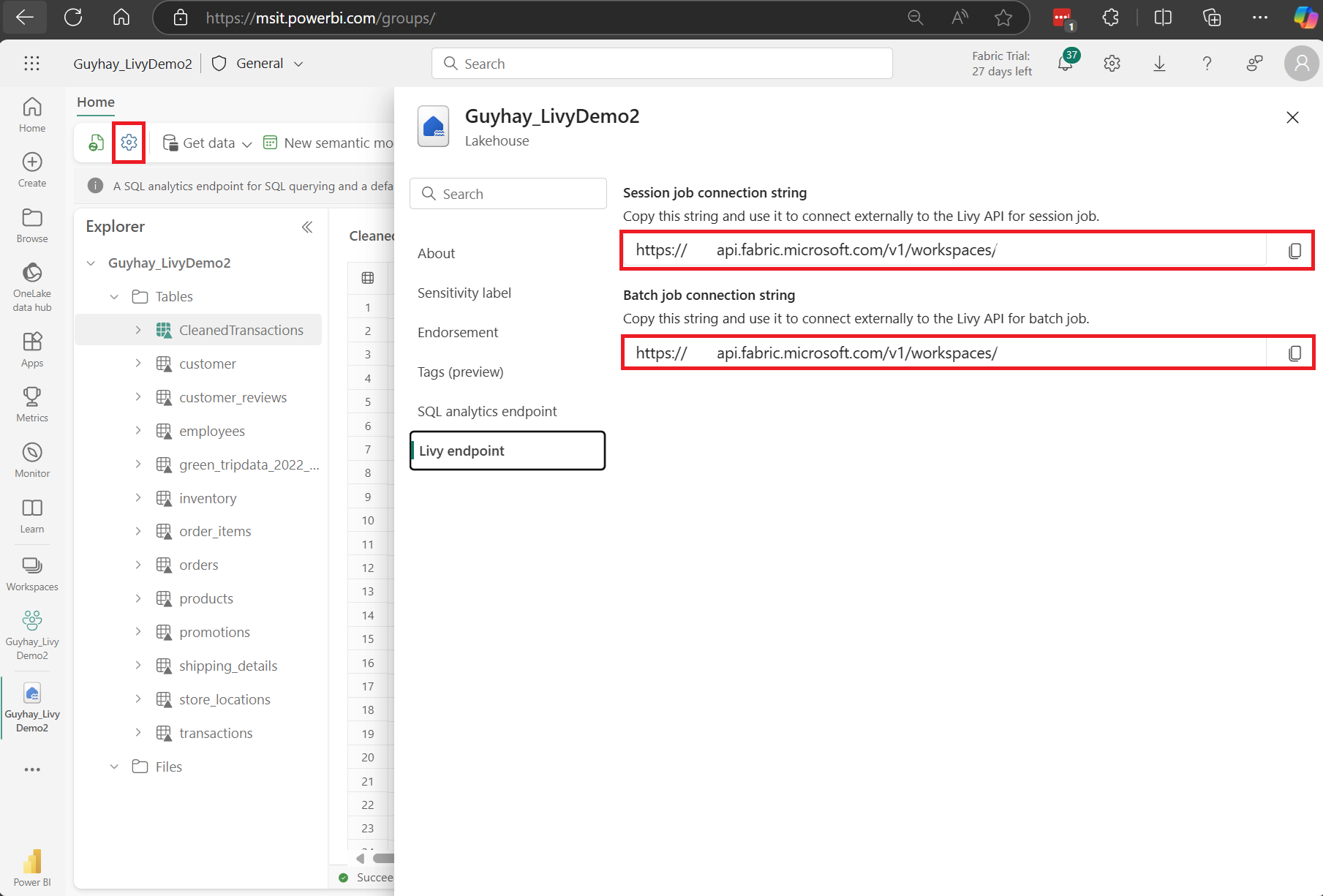
Kopioi erätyön yhteysmerkkijono (kuvan toinen punainen ruutu) koodiin.
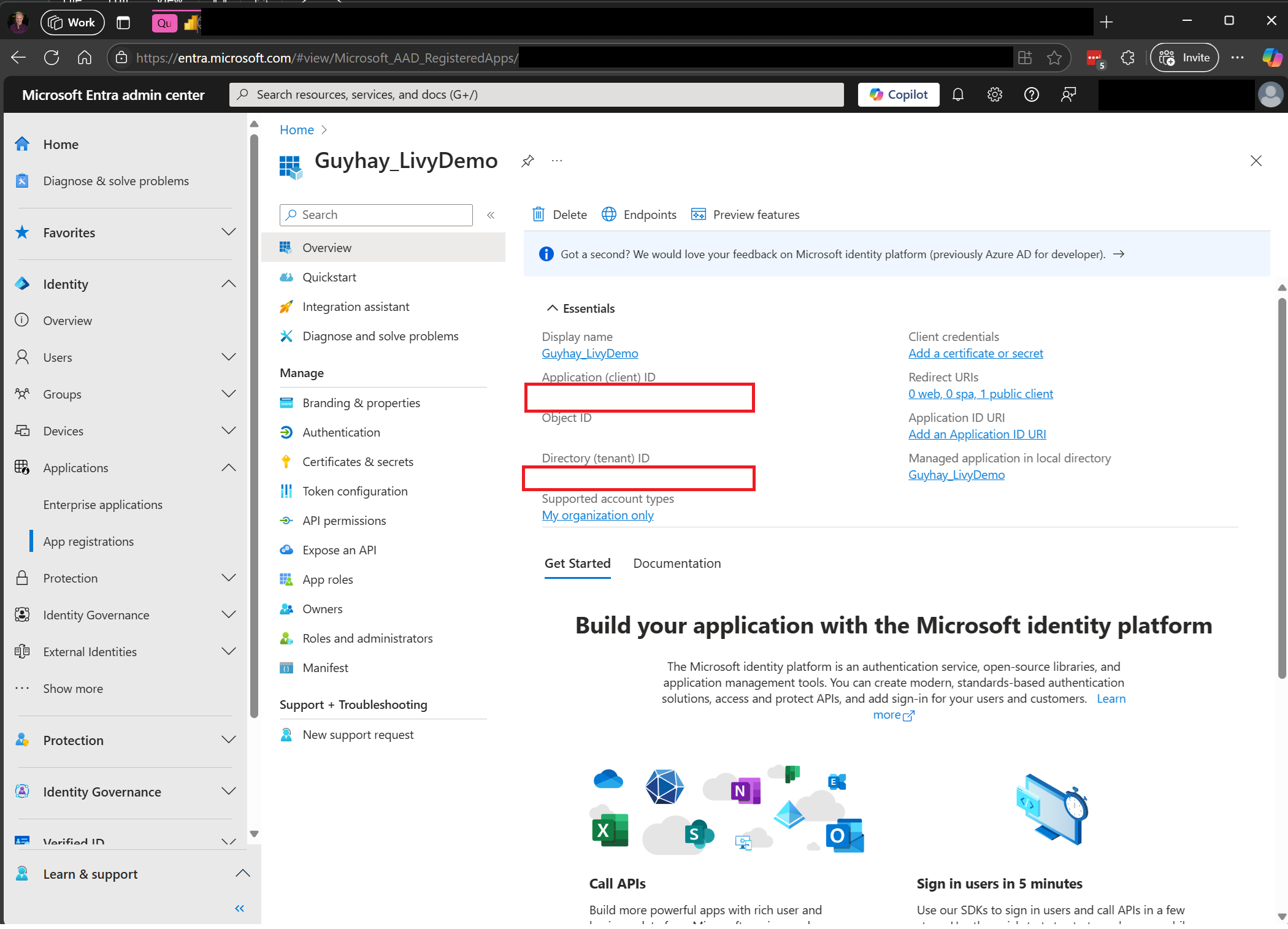
Siirry Microsoft Entra -hallintakeskukseen ja kopioi sekä Sovelluksen (asiakkaan) että hakemiston (vuokraajan) tunnus koodiin.



Luo Spark-hyötykuorma ja lataa se Lakehouse-palvelimeesi
.ipynbLuo muistikirja Visual Studio Codessa ja lisää seuraava koodiimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Tallenna Python-tiedosto paikallisesti. Tämä Python-koodin tiedot sisältää kaksi Spark-laskelmaa, jotka käsittelevät Lakehousessa olevia tietoja ja jotka on ladattava Lakehouse-palvelimeesi. Tarvitset hyötykuorman ABFS-polun, johon viitataan Livy-ohjelmointirajapinnan erätyössä Visual Studio Codessa, ja Lakehouse-taulukon nimen Kohdassa Valitse SQL-lauseke..

Lataa Python-tiedot Lakehousen tiedostot-osioon. > Nouda tiedot > Lataa tiedostot > napsauta tiedostot/syöte-ruudussa.
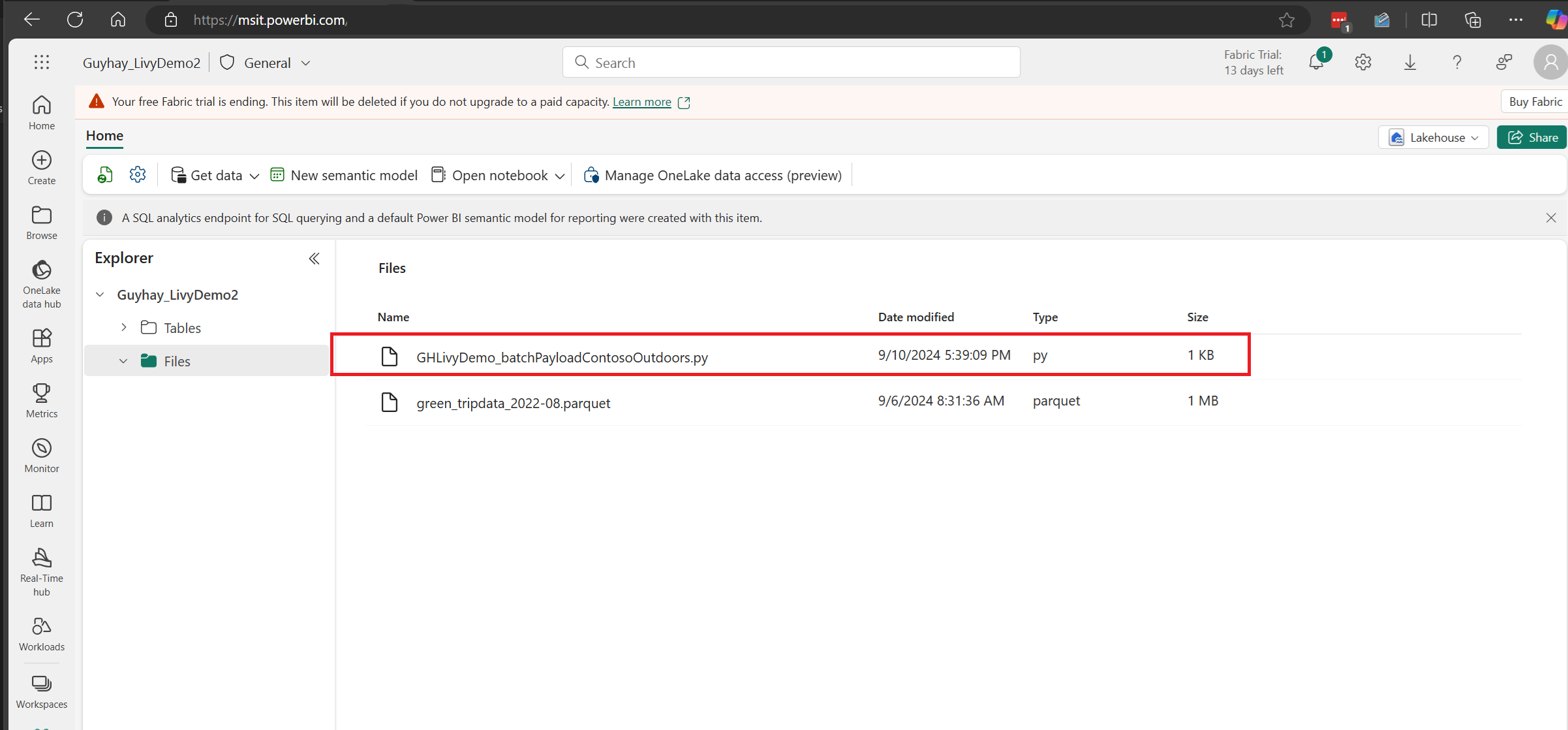
Kun tiedosto on Lakehousen Tiedostot-osassa, napsauta kolmea pistettä hyötykuormatiedoston nimen oikealla puolella ja valitse Ominaisuudet.
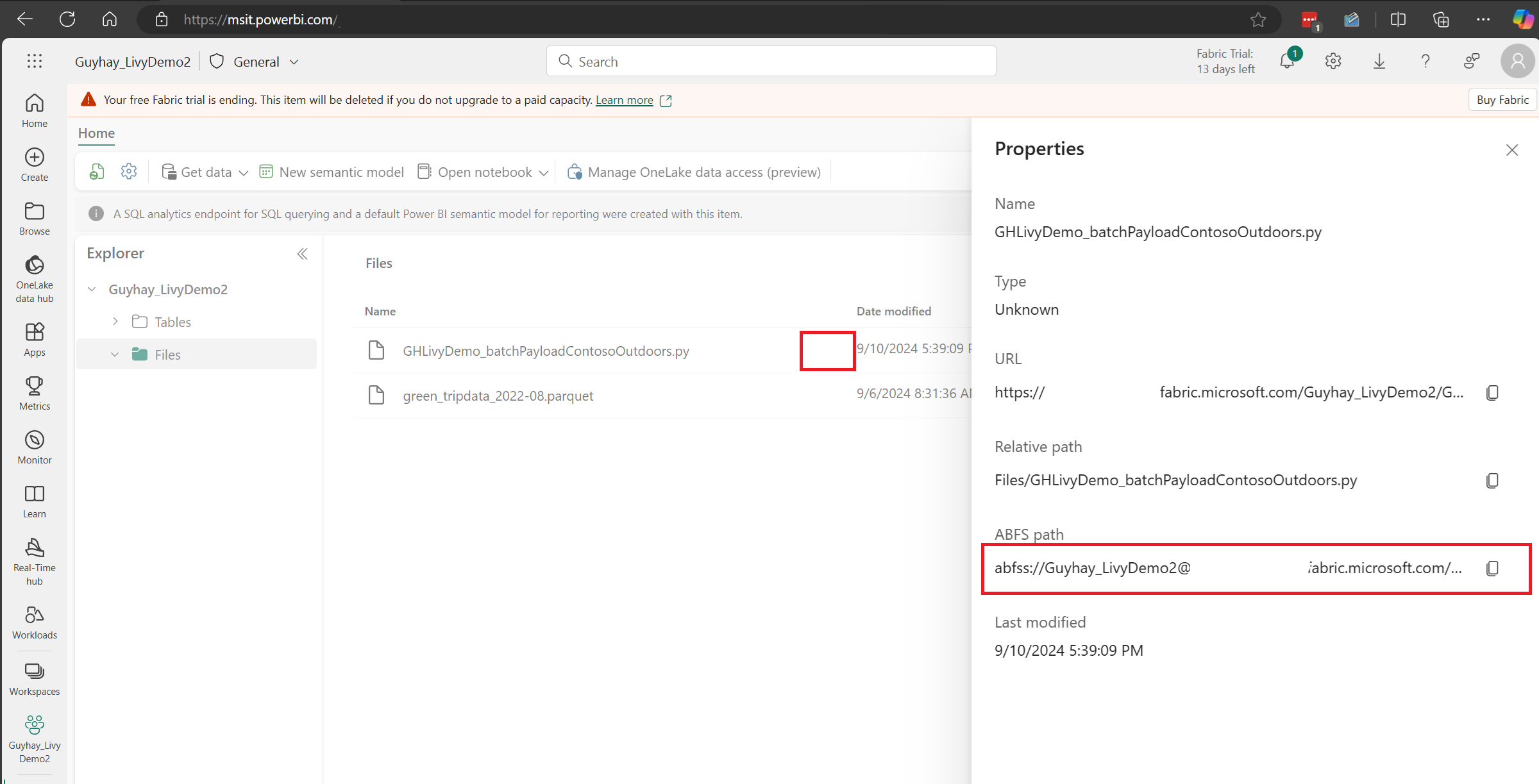
Kopioi tämä ABFS-polku muistikirjan soluun vaiheessa 1.



Livy-ohjelmointirajapinnan Spark-eräistunnon luominen
.ipynbLuo muistikirja Visual Studio Codessa ja lisää seuraava koodi.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Suorita muistikirjasolu. Selaimeen pitäisi ilmestyä ponnahdusikkuna, jonka avulla voit valita kirjautumisen käyttäjätiedot.
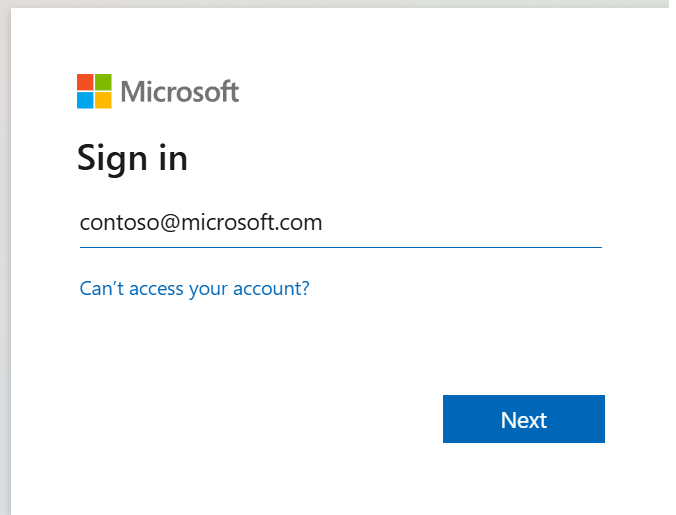
Kun olet valinnut käyttäjätiedot, joilla kirjaudut sisään, sinua pyydetään myös hyväksymään Microsoft Entra -sovelluksen rekisteröinnin ohjelmointirajapinnan käyttöoikeudet.
Sulje selainikkuna todentamisen suorittamisen jälkeen.

Sinun pitäisi nähdä Microsoft Entra -tunnus Visual Studio Codessa.
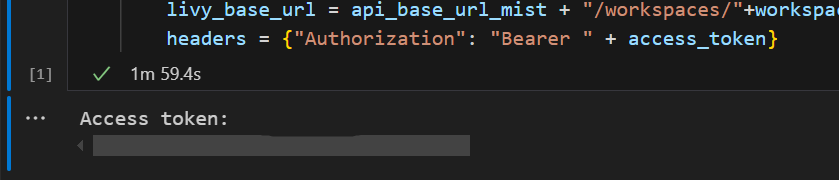
Lisää toinen muistikirjasolu ja lisää tämä koodi.
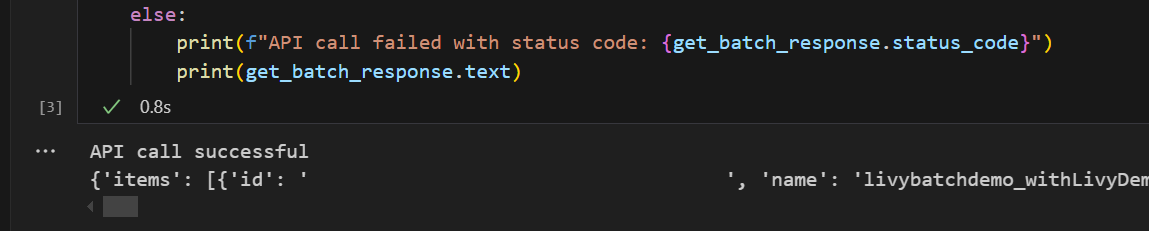
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Suorita muistikirjan solu. Kahden rivin pitäisi näkyä tulostettuina Livy-erätyönä.





spark.sql-lausekkeen lähettäminen Livy-ohjelmointirajapinnan eräistunnon avulla
Lisää toinen muistikirjasolu ja lisää tämä koodi.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Suorita muistikirjasolu. Livy Batch -työn luomisen ja suorittamisen aikana pitäisi näkyä useita rivejä.

Siirry takaisin Lakehouseen, jotta näet muutokset.

Tarkastele töitäsi valvontakeskuksessa
Voit käyttää valvontakeskusta tarkastelemaan erilaisia Apache Spark -toimintoja valitsemalla Vasemmanpuoleisten siirtymislinkkien Valvonta.
Kun erätyö on suoritettu, voit tarkastella istunnon tilaa siirtymällä kohtaan Valvonta.
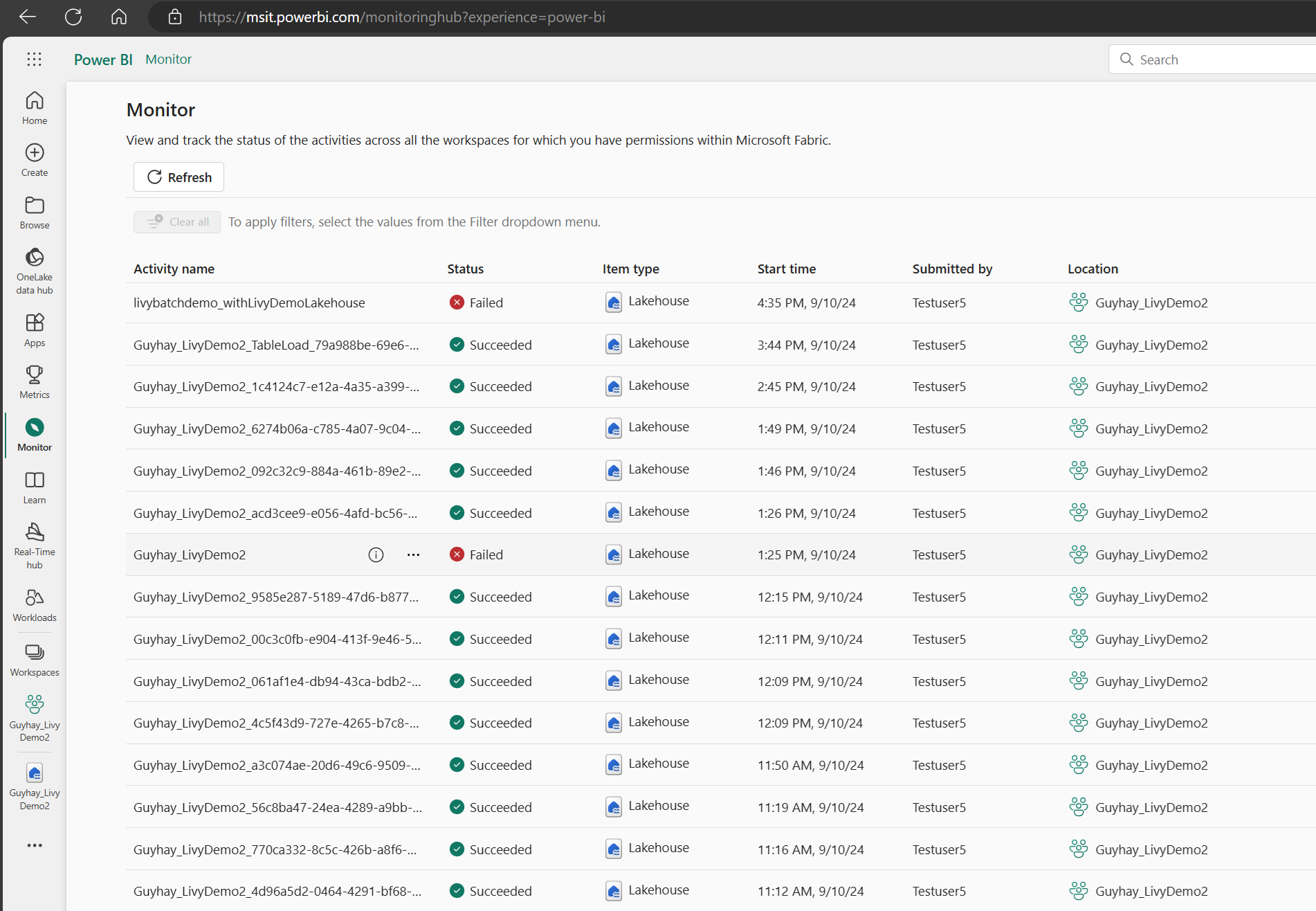
Valitse ja avaa viimeisimmän toiminnon nimi.
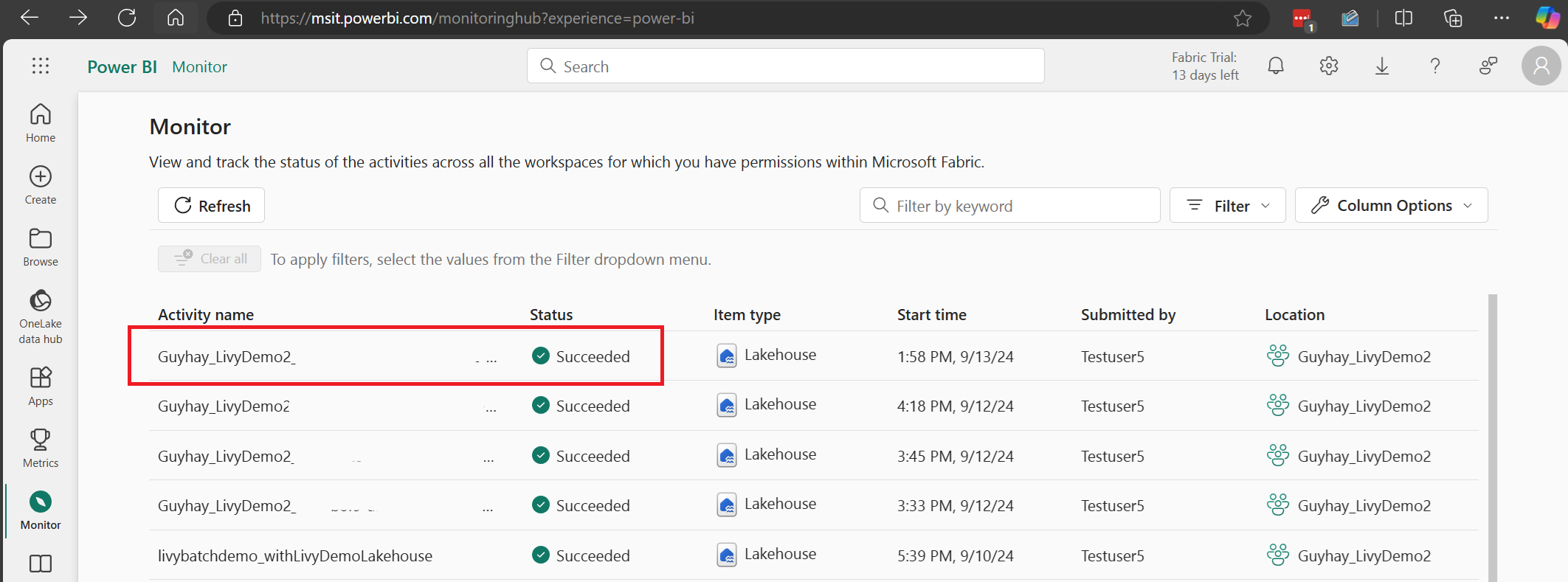
Tässä Livy-ohjelmointirajapinta-istunnon tapauksessa voit tarkastella edellisen erän lähettämistä, suoritustietoja, Spark-versioita ja määritystä. Huomaa pysäytetty tila oikeassa yläkulmassa.
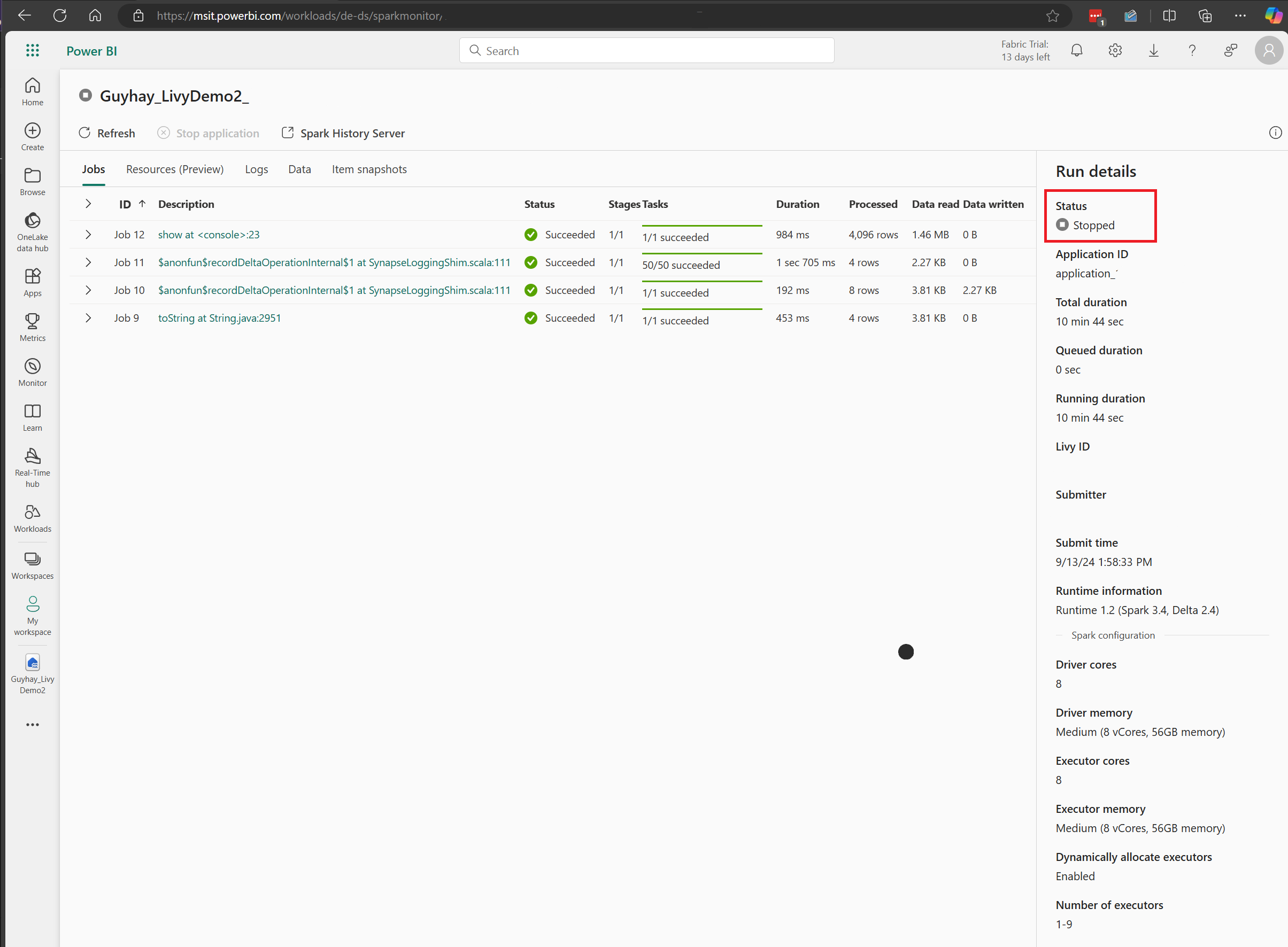



Jotta voit tiivistää koko prosessin, tarvitset etäasiakkaan, kuten Visual Studio Coden, Microsoft Entra -sovellustunnuksen, Livy-ohjelmointirajapinnan päätepisteen URL-osoitteen, todennuksen Lakehousea vastaan, Spark-hyötykuorman Lakehousessa ja lopuksi erän Livy API -istunnon.