Data migration, ETL, and load for Oracle migrations
This article is part two of a seven-part series that provides guidance on how to migrate from Oracle to Azure Synapse Analytics. The focus of this article is best practices for ETL and load migration.
Data migration considerations
There are many factors to consider when migrating data, ETL, and loads from a legacy Oracle data warehouse and data marts to Azure Synapse.
Initial decisions about data migration from Oracle
When you're planning a migration from an existing Oracle environment, consider the following data-related questions:
Should unused table structures be migrated?
What's the best migration approach to minimize risk and impact for users?
When migrating data marts: stay physical or go virtual?
The next sections discuss these points within the context of a migration from Oracle.
Migrate unused tables?
It makes sense to only migrate tables that are in use. Tables that aren't active can be archived rather than migrated, so that the data is available if needed in the future. It's best to use system metadata and log files rather than documentation to determine which tables are in use, because documentation can be out of date.
Oracle system catalog tables and logs contain information that can be used to determine when a given table was last accessed—which in turn can be used to decide whether or not a table is a candidate for migration.
If you've licensed the Oracle Diagnostic Pack, then you have access to Active Session History, which you can use to determine when a table was last accessed.
Tip
In legacy systems, it's not unusual for tables to become redundant over time—these don't need to be migrated in most cases.
Here's an example query that looks for the usage of a specific table within a given time window:
SELECT du.username,
s.sql_text,
MAX(ash.sample_time) AS last_access ,
sp.object_owner ,
sp.object_name ,
sp.object_alias as aliased_as ,
sp.object_type ,
COUNT(*) AS access_count
FROM v$active_session_history ash
JOIN v$sql s ON ash.force_matching_signature = s.force_matching_signature
LEFT JOIN v$sql_plan sp ON s.sql_id = sp.sql_id
JOIN DBA_USERS du ON ash.user_id = du.USER_ID
WHERE ash.session_type = 'FOREGROUND'
AND ash.SQL_ID IS NOT NULL
AND sp.object_name IS NOT NULL
AND ash.user_id <> 0
GROUP BY du.username,
s.sql_text,
sp.object_owner,
sp.object_name,
sp.object_alias,
sp.object_type
ORDER BY 3 DESC;
This query may take a while to run if you have been running numerous queries.
What's the best migration approach to minimize risk and impact on users?
This question comes up frequently because companies may want to lower the impact of changes on the data warehouse data model to improve agility. Companies often see an opportunity to further modernize or transform their data during an ETL migration. This approach carries a higher risk because it changes multiple factors simultaneously, making it difficult to compare the outcomes of the old system versus the new. Making data model changes here could also affect upstream or downstream ETL jobs to other systems. Because of that risk, it's better to redesign on this scale after the data warehouse migration.
Even if a data model is intentionally changed as part of the overall migration, it's good practice to migrate the existing model as-is to Azure Synapse, rather than do any re-engineering on the new platform. This approach minimizes the effect on existing production systems, while benefiting from the performance and elastic scalability of the Azure platform for one-off re-engineering tasks.
Tip
Migrate the existing model as-is initially, even if a change to the data model is planned in the future.
Data mart migration: stay physical or go virtual?
In legacy Oracle data warehouse environments, it's common practice to create many data marts that are structured to provide good performance for ad hoc self-service queries and reports for a given department or business function within an organization. A data mart typically consists of a subset of the data warehouse that contains aggregated versions of the data in a form that enables users to easily query that data with fast response times. Users can use user-friendly query tools like Microsoft Power BI, which supports business user interactions with data marts. The form of the data in a data mart is generally a dimensional data model. One use of data marts is to expose the data in a usable form even if the underlying warehouse data model is something different, such as a data vault.
You can use separate data marts for individual business units within an organization to implement robust data security regimes. Restrict access to specific data marts that are relevant to users, and eliminate, obfuscate, or anonymize sensitive data.
If these data marts are implemented as physical tables, they'll require extra storage resources and processing to build and refresh them regularly. Also, the data in the mart will only be as up to date as the last refresh operation, and so may be unsuitable for highly volatile data dashboards.
Tip
Virtualizing data marts can save on storage and processing resources.
With the advent of lower-cost scalable MPP architectures, such as Azure Synapse, and their inherent performance characteristics, you can provide data mart functionality without instantiating the mart as a set of physical tables. One method is to effectively virtualize the data marts via SQL views onto the main data warehouse. Another way is to virtualize the data marts via a virtualization layer using features like views in Azure or third-party virtualization products. This approach simplifies or eliminates the need for extra storage and aggregation processing and reduces the overall number of database objects to be migrated.
There's another potential benefit of this approach. By implementing the aggregation and join logic within a virtualization layer, and presenting external reporting tools via a virtualized view, the processing required to create these views is pushed down into the data warehouse. The data warehouse is generally the best place to run joins, aggregations, and other related operations on large data volumes.
The primary drivers for implementing a virtual data mart over a physical data mart are:
More agility: a virtual data mart is easier to change than physical tables and the associated ETL processes.
Lower total cost of ownership: a virtualized implementation requires fewer data stores and copies of data.
Elimination of ETL jobs to migrate and simplify data warehouse architecture in a virtualized environment.
Performance: although physical data marts have historically performed better, virtualization products now implement intelligent caching techniques to mitigate this difference.
Tip
The performance and scalability of Azure Synapse enables virtualization without sacrificing performance.
Data migration from Oracle
Understand your data
As part of migration planning, you should understand in detail the volume of data to be migrated since that can affect decisions about the migration approach. Use system metadata to determine the physical space taken up by the raw data within the tables to be migrated. In this context, raw data means the amount of space used by the data rows within a table, excluding overhead such as indexes and compression. The largest fact tables will typically comprise more than 95% of the data.
This query will give you the total database size in Oracle:
SELECT
( SELECT SUM(bytes)/1024/1024/1024 data_size
FROM sys.dba_data_files ) +
( SELECT NVL(sum(bytes),0)/1024/1024/1024 temp_size
FROM sys.dba_temp_files ) +
( SELECT SUM(bytes)/1024/1024/1024 redo_size
FROM sys.v_$log ) +
( SELECT SUM(BLOCK_SIZE*FILE_SIZE_BLKS)/1024/1024/1024 controlfile_size
FROM v$controlfile ) "Size in GB"
FROM dual
The database size equals the size of (data files + temp files + online/offline redo log files + control files). Overall database size includes used space and free space.
The following example query gives a breakdown of the disk space used by table data and indexes:
SELECT
owner, "Type", table_name "Name", TRUNC(sum(bytes)/1024/1024) Meg
FROM
( SELECT segment_name table_name, owner, bytes, 'Table' as "Type"
FROM dba_segments
WHERE segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION' )
UNION ALL
SELECT i.table_name, i.owner, s.bytes, 'Index' as "Type"
FROM dba_indexes i, dba_segments s
WHERE s.segment_name = i.index_name
AND s.owner = i.owner
AND s.segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.segment_name
AND s.owner = l.owner
AND s.segment_type IN ('LOBSEGMENT','LOB PARTITION','LOB SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB Index' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.index_name
AND s.owner = l.owner
AND s.segment_type = 'LOBINDEX')
WHERE owner in UPPER('&owner')
GROUP BY table_name, owner, "Type"
HAVING SUM(bytes)/1024/1024 > 10 /* Ignore really small tables */
ORDER BY SUM(bytes) desc;
In addition, the Microsoft database migration team provides many resources, including the Oracle Inventory Script Artifacts. The Oracle Inventory Script Artifacts tool includes a PL/SQL query that accesses Oracle system tables and provides a count of objects by schema type, object type, and status. The tool also provides a rough estimate of raw data in each schema and the sizing of tables in each schema, with results stored in a CSV format. An included calculator spreadsheet takes the CSV as input and provides sizing data.
For any table, you can accurately estimate the volume of data that needs to be migrated by extracting a representative sample of the data, such as one million rows, to an uncompressed delimited flat ASCII data file. Then, use the size of that file to get an average raw data size per row. Finally, multiply that average size by the total number of rows in the full table to give a raw data size for the table. Use that raw data size in your planning.
Use SQL queries to find data types
By querying the Oracle static data dictionary DBA_TAB_COLUMNS view, you can determine which data types are in use in a schema and whether any of those data types need to be changed. Use SQL queries to find the columns in any Oracle schema with data types that don't map directly to data types in Azure Synapse. Similarly, you can use queries to count the number of occurrences of each Oracle data type that doesn't map directly to Azure Synapse. By using the results from these queries in combination with the data type comparison table, you can determine which data types need to be changed in an Azure Synapse environment.
To find the columns with data types that don't map to data types in Azure Synapse, run the following query after you replace <owner_name> with the relevant owner of your schema:
SELECT owner, table_name, column_name, data_type
FROM dba_tab_columns
WHERE owner in ('<owner_name>')
AND data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
ORDER BY 1,2,3;
To count the number of non-mappable data types, use the following query:
SELECT data_type, count(*)
FROM dba_tab_columns
WHERE data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
GROUP BY data_type
ORDER BY data_type;
Microsoft offers SQL Server Migration Assistant (SSMA) for Oracle to automate migration of data warehouses from legacy Oracle environments, including the mapping of data types. You can also use Azure Database Migration Services to help plan and perform a migration from environments like Oracle. Third-party vendors also offer tools and services to automate migration. If a third-party ETL tool is already in use in the Oracle environment, you can use that tool to implement any required data transformations. The next section explores migration of existing ETL processes.
ETL migration considerations
Initial decisions about Oracle ETL migration
For ETL/ELT processing, legacy Oracle data warehouses often use custom-built scripts, third-party ETL tools, or a combination of approaches that has evolved over time. When you're planning a migration to Azure Synapse, determine the best way to implement the required ETL/ELT processing in the new environment while also minimizing cost and risk.
Tip
Plan the approach to ETL migration ahead of time and leverage Azure facilities where appropriate.
The following flowchart summarizes one approach:
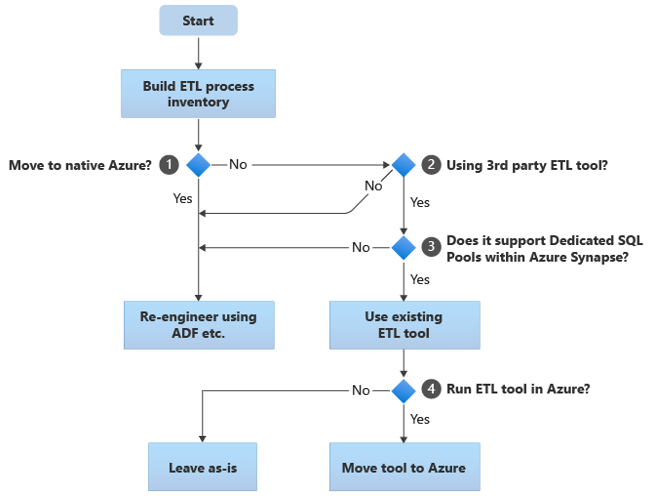
As shown in the flowchart, the initial step is always to build an inventory of ETL/ELT processes that need to be migrated. With the standard built-in Azure features, some existing processes might not need to move. For planning purposes, it's important that you understand the scale of the migration. Next, consider the questions in the flowchart decision tree:
Move to native Azure? Your answer depends on whether you're migrating to a completely Azure-native environment. If so, we recommend that you re-engineer the ETL processing using Pipelines and activities in Azure Data Factory or Azure Synapse pipelines.
Using a third-party ETL tool? If you're not moving to a completely Azure-native environment, then check whether an existing third-party ETL tool is already in use. In the Oracle environment, you might find that some or all of the ETL processing is performed by custom scripts using Oracle-specific utilities such as Oracle SQL Developer, Oracle SQL*Loader, or Oracle Data Pump. The approach in this case is to re-engineer using Azure Data Factory.
Does the third-party support dedicated SQL pools within Azure Synapse? Consider whether there's a large investment in skills in the third-party ETL tool, or if existing workflows and schedules use that tool. If so, determine whether the tool can efficiently support Azure Synapse as a target environment. Ideally, the tool will include native connectors that can use Azure facilities like PolyBase or COPY INTO for the most efficient data loading. But even without native connectors, there's generally a way that you can call external processes, such as PolyBase or
COPY INTO, and pass in applicable parameters. In this case, use existing skills and workflows, with Azure Synapse as the new target environment.If you're using Oracle Data Integrator (ODI) for ELT processing, then you need ODI Knowledge Modules for Azure Synapse. If those modules aren't available to you in your organization, but you have ODI, then you can use ODI to generate flat files. Those flat files can then be moved to Azure and ingested into Azure Data Lake Storage for loading into Azure Synapse.
Run ETL tools in Azure? If you decide to retain an existing third-party ETL tool, you can run that tool within the Azure environment (rather than on an existing on-premises ETL server) and have Data Factory handle the overall orchestration of the existing workflows. So, decide whether to leave the existing tool running as-is or move it into the Azure environment to achieve cost, performance, and scalability benefits.
Tip
Consider running ETL tools in Azure to leverage performance, scalability, and cost benefits.
Re-engineer existing Oracle-specific scripts
If some or all of the existing Oracle warehouse ETL/ELT processing is handled by custom scripts that use Oracle-specific utilities, such as Oracle SQL*Plus, Oracle SQL Developer, Oracle SQL*Loader, or Oracle Data Pump, then you need to recode these scripts for the Azure Synapse environment. Similarly, if ETL processes have been implemented using stored procedures in Oracle, then you need to recode those processes.
Some elements of the ETL process are easy to migrate, for example, by simple bulk data load into a staging table from an external file. It may even be possible to automate those parts of the process, for example, by using Azure Synapse COPY INTO or PolyBase instead of SQL*Loader. Other parts of the process that contain arbitrary complex SQL and/or stored procedures will take more time to re-engineer.
Tip
The inventory of ETL tasks to be migrated should include scripts and stored procedures.
One way of testing Oracle SQL for compatibility with Azure Synapse is to capture some representative SQL statements from a join of Oracle v$active_session_history and v$sql to get sql_text, then prefix those queries with EXPLAIN. Assuming a like-for-like migrated data model in Azure Synapse, run those EXPLAIN statements in Azure Synapse. Any incompatible SQL will give an error. You can use this information to determine the scale of the recoding task.
Tip
Use EXPLAIN to find SQL incompatibilities.
In the worst case, manual recoding may be necessary. However, there are products and services available from Microsoft partners to assist with re-engineering Oracle-specific code.
Tip
Partners offer products and skills to assist in re-engineering Oracle-specific code.
Use existing third-party ETL tools
In many cases, the existing legacy data warehouse system will already be populated and maintained by a third-party ETL product. See Azure Synapse Analytics data integration partners for a list of current Microsoft data integration partners for Azure Synapse.
The Oracle community frequently uses several popular ETL products. The following paragraphs discuss the most popular ETL tools for Oracle warehouses. You can run all of those products within a VM in Azure and use them to read and write Azure databases and files.
Tip
Leverage investment in existing third-party tools to reduce cost and risk.
Data loading from Oracle
Choices available when loading data from Oracle
When you're preparing to migrate data from an Oracle data warehouse, decide how data will be physically moved from the existing on-premises environment into Azure Synapse in the cloud, and which tools will be used to perform the transfer and load. Consider the following questions, which are discussed in the following sections.
Will you extract the data to files, or move it directly via a network connection?
Will you orchestrate the process from the source system, or from the Azure target environment?
Which tools will you use to automate and manage the migration process?
Transfer data via files or network connection?
Once the database tables to be migrated have been created in Azure Synapse, you can move the data that populates those tables out of the legacy Oracle system and into the new environment. There are two basic approaches:
File Extract: extract the data from the Oracle tables to flat delimited files, normally in CSV format. You can extract table data in several ways:
- Use standard Oracle tools such as SQL*Plus, SQL Developer, and SQLcl.
- Use Oracle Data Integrator (ODI) to generate flat files.
- Use Oracle connector in Data Factory to unload Oracle tables in parallel to enable data loading by partitions.
- Use a third-party ETL tool.
For examples of how to extract Oracle table data, see the article appendix.
This approach requires space to land the extracted data files. The space could be local to the Oracle source database if sufficient storage is available, or remote in Azure Blob Storage. The best performance is achieved when a file is written locally since that avoids network overhead.
To minimize storage and network transfer requirements, compress the extracted data files using a utility like gzip.
After extraction, move the flat files into Azure Blob Storage. Microsoft provides various options to move large volumes of data, including:
- AzCopy for moving files across the network into Azure Storage.
- Azure ExpressRoute for moving bulk data over a private network connection.
- Azure Data Box for moving files to a physical storage device that you ship to an Azure data center for loading.
For more information, see Transfer data to and from Azure.
Direct extract and load across network: the target Azure environment sends a data extract request, normally via a SQL command, to the legacy Oracle system to extract the data. The results are sent across the network and loaded directly into Azure Synapse, with no need to land the data into intermediate files. The limiting factor in this scenario is normally the bandwidth of the network connection between the Oracle database and the Azure environment. For exceptionally large data volumes, this approach may not be practical.
Tip
Understand the data volumes to be migrated and the available network bandwidth, because these factors influence the migration approach decision.
There's also a hybrid approach that uses both methods. For example, you can use the direct network extract approach for smaller dimension tables and samples of the larger fact tables to quickly provide a test environment in Azure Synapse. For large-volume historical fact tables, you can use the file extract and transfer approach using Azure Data Box.
Orchestrate from Oracle or Azure?
The recommended approach when moving to Azure Synapse is to orchestrate data extraction and loading from the Azure environment using SSMA or Data Factory. Use the associated utilities, such as PolyBase or COPY INTO, for the most efficient data loading. This approach benefits from built-in Azure capabilities and reduces the effort to build reusable data load pipelines. You can use metadata-driven data load pipelines to automate the migration process.
The recommended approach also minimizes the performance hit on the existing Oracle environment during the data load process, because the management and load process runs in Azure.
Existing data migration tools
Data transformation and movement is the basic function of all ETL products. If a data migration tool is already in use in the existing Oracle environment and it supports Azure Synapse as a target environment, then consider using that tool to simplify data migration.
Even if an existing ETL tool isn't in place, Azure Synapse Analytics data integration partners offer ETL tools to simplify the task of data migration.
Finally, if you plan to use an ETL tool, consider running that tool within the Azure environment to take advantage of Azure cloud performance, scalability, and cost. This approach also frees up resources in the Oracle data center.
Summary
To summarize, our recommendations for migrating data and associated ETL processes from Oracle to Azure Synapse are:
Plan ahead to ensure a successful migration exercise.
Build a detailed inventory of data and processes to be migrated as soon as possible.
Use system metadata and log files to get an accurate understanding of data and process usage. Don't rely on documentation since it may be out of date.
Understand the data volumes to be migrated, and the network bandwidth between the on-premises data center and Azure cloud environments.
Consider using an Oracle instance in an Azure VM as a stepping stone to offload migration from the legacy Oracle environment.
Use standard built-in Azure features to minimize the migration workload.
Identify and understand the most efficient tools for data extraction and load in both Oracle and Azure environments. Use the appropriate tools in each phase of the process.
Use Azure facilities, such as Data Factory, to orchestrate and automate the migration process while minimizing impact on the Oracle system.
Appendix: Examples of techniques to extract Oracle data
You can use several techniques to extract Oracle data when migrating from Oracle to Azure Synapse. The next sections demonstrate how to extract Oracle data using Oracle SQL Developer and the Oracle connector in Data Factory.
Use Oracle SQL Developer for data extraction
You can use the Oracle SQL Developer UI to export table data to many formats, including CSV, as shown in the following screenshot:

Other export options include JSON and XML. You can use the UI to add a set of table names to a "cart", then apply the export to the entire set in the cart:

You can also use Oracle SQL Developer Command Line (SQLcl) to export Oracle data. This option supports automation using a shell script.
For relatively small tables, you might find this technique useful if you run into problems extracting data through a direct connection.
Use the Oracle connector in Azure Data Factory for parallel copy
You can use the Oracle connector in Data Factory to unload large Oracle tables in parallel. The Oracle connector provides built-in data partitioning to copy data from Oracle in parallel. You can find the data partitioning options in the Source tab of the copy activity.

For information on how to configure the Oracle connector for parallel copy, see Parallel copy from Oracle.
For more information on Data Factory copy activity performance and scalability, see Copy activity performance and scalability guide.
Next steps
To learn about security access operations, see the next article in this series: Security, access, and operations for Oracle migrations.