Configure streaming ingestion on your Azure Synapse Data Explorer pool (Preview)
Streaming ingestion is useful for loading data when you need low latency between ingestion and query. Consider using streaming ingestion in the following scenarios:
- Latency of less than a second is required.
- To optimize operational processing of many tables where the stream of data into each table is relatively small (a few records per second), but the overall data ingestion volume is high (thousands of records per second).
If the stream of data into each table is high (over 4 GB per hour), consider using batch ingestion.
To learn more about different ingestion methods, see data ingestion overview.
Choose the appropriate streaming ingestion type
Two streaming ingestion types are supported:
| Ingestion type | Description |
|---|---|
| Event Hub or IoT Hub | Hubs are configured as table streaming data sources. For information about setting these up, see Event Hub. |
| Custom ingestion | Custom ingestion requires you to write an application that uses one of the Azure Synapse Data Explorer client libraries. Use the information in this topic to configure custom ingestion. You may also find the C# streaming ingestion sample application helpful. |
Use the following table to help you choose the ingestion type that's appropriate for your environment:
| Criterion | Event Hub / IoT Hub | Custom Ingestion |
|---|---|---|
| Data delay between ingestion initiation and the data available for query | Longer delay | Shorter delay |
| Development overhead | Fast and easy setup, no development overhead | High development overhead to create an application ingest the data, handle errors, and ensure data consistency |
Note
Ingesting data from an Event Hub into Data Explorer pools will not work if your Synapse workspace uses a managed virtual network with data exfiltration protection enabled.
Prerequisites
An Azure subscription. Create a free Azure account.
Create a Data Explorer pool using Synapse Studio or the Azure portal
Create a Data Explorer database.
In Synapse Studio, on the left-side pane, select Data.
Select + (Add new resource) > Data Explorer pool, and use the following information:
Setting Suggested value Description Pool name contosodataexplorer The name of the Data Explorer pool to use Name TestDatabase The database name must be unique within the cluster. Default retention period 365 The time span (in days) for which it's guaranteed that the data is kept available to query. The time span is measured from the time that data is ingested. Default cache period 31 The time span (in days) for which to keep frequently queried data available in SSD storage or RAM, rather than in longer-term storage. Select Create to create the database. Creation typically takes less than a minute.
- Get the Query and Data Ingestion endpoints.
In Synapse Studio, on the left-side pane, select Manage > Data Explorer pools.
Select the Data Explorer pool you want to use to view its details.
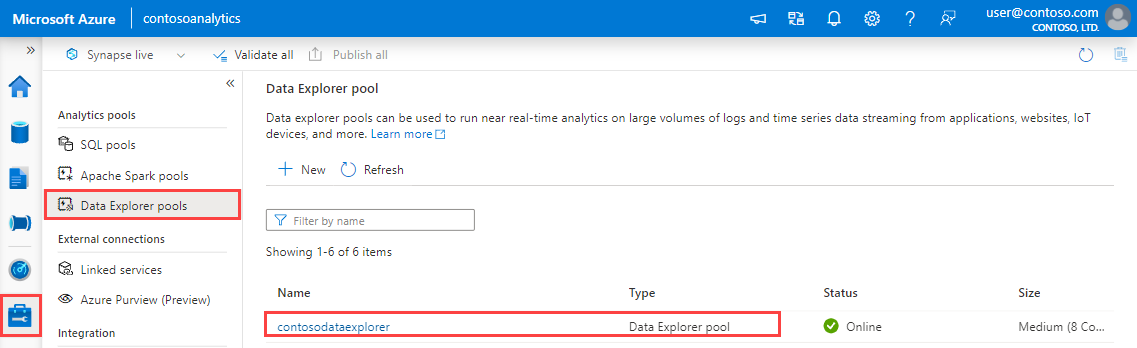
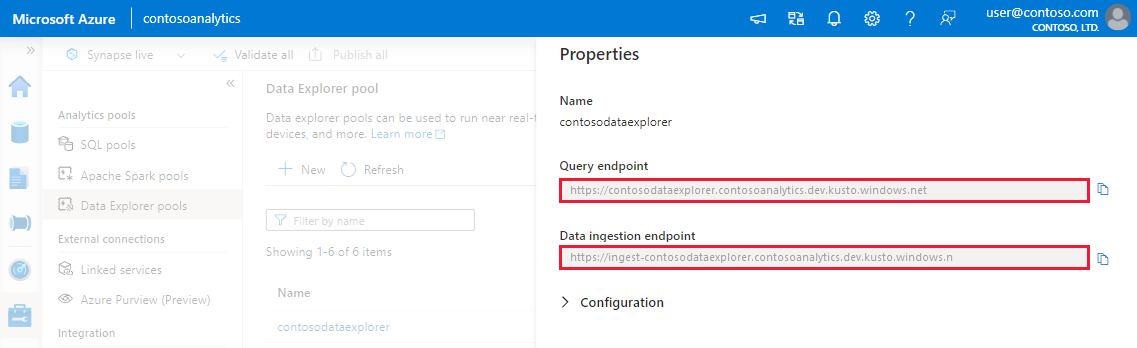
Make a note of the Query and Data Ingestion endpoints. Use the Query endpoint as the cluster when configuring connections to your Data Explorer pool. When configuring SDKs for data ingestion, use the data ingestion endpoint.
Performance and operational considerations
The main contributors that can impact streaming ingestion are:
- Compute Specification: Streaming ingestion performance and capacity scales with increased Data Explorer pool sizes. The number of concurrent ingestion requests is limited to six per core. For example, for 16 core workload type, such as Compute Optimized (Large) and Storage Optimized (Large), the maximal supported load is 96 concurrent ingestion requests. For two core workload type, such as Compute Optimized (Extra Small), the maximal supported load is 12 concurrent ingestion requests.
- Data size limit: The data size limit for a streaming ingestion request is 4 MB.
- Schema updates: Schema updates, such as creation and modification of tables and ingestion mappings, may take up to five minutes for the streaming ingestion service. For more information see Streaming ingestion and schema changes.
- SSD capacity: Enabling streaming ingestion on a Data Explorer pool, even when data isn't ingested via streaming, uses part of the local SSD disk of the Data Explorer pool machines for streaming ingestion data and reduces the storage available for hot cache.
Enable streaming ingestion on your Data Explorer pool
Before you can use streaming ingestion, you must enable the capability on your Data Explorer pool and define a streaming ingestion policy. You can enable the capability when creating the Data Explorer pool, or add it to an existing Data Explorer pool.
Warning
Review the limitations prior to enabling streaming ingestion.
Enable streaming ingestion while creating a new Data Explorer pool
You can enable streaming ingestion while creating a new Data Explorer pool using Azure Synapse Studio or the Azure portal.
While creating a Data Explorer pool using the steps in Create a Data Explorer pool using Synapse Studio, in the Additional settings tab, select Streaming ingestion > Enabled.
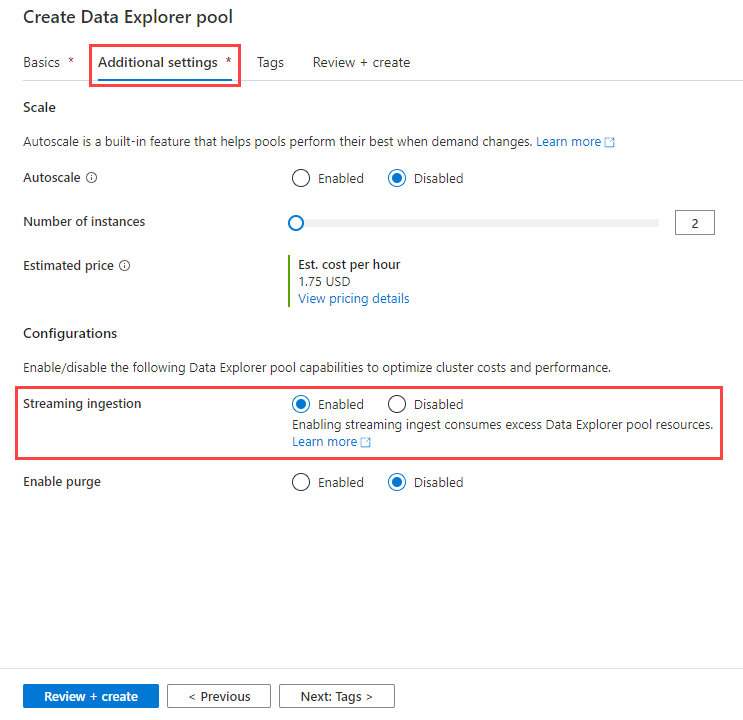
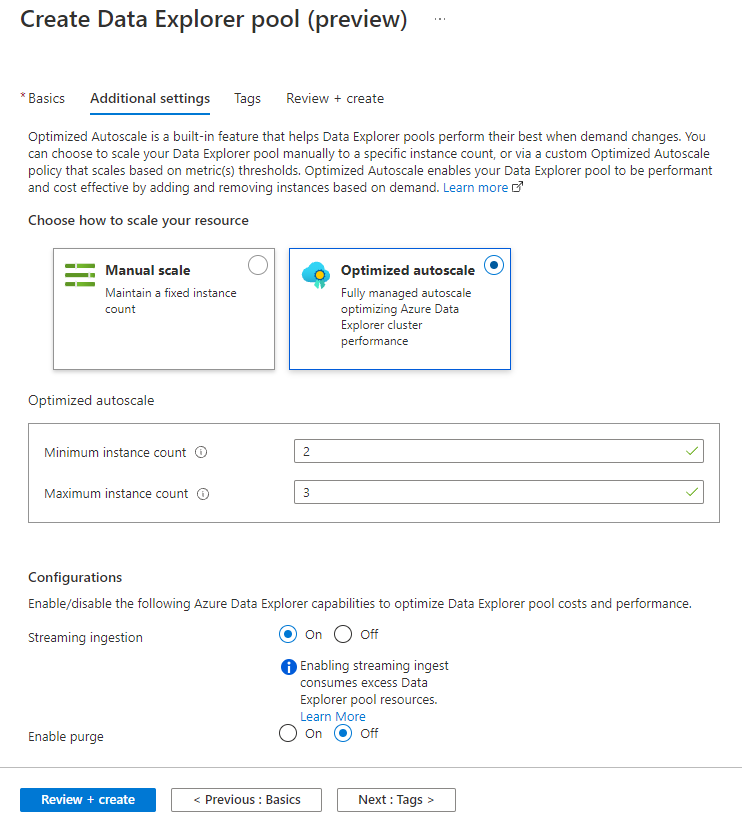
Enable streaming ingestion on an existing Data Explorer pool
If you have an existing Data Explorer pool, you can enable streaming ingestion using the Azure portal.
- In the Azure portal, go to your Data Explorer pool.
- In Settings, select Configurations.
- In the Configurations pane, select On to enable Streaming ingestion.
- Select Save.
Create a target table and define the policy
Create a table to receive the streaming ingestion data and define its related policy using Azure Synapse Studio or the Azure portal.
In Synapse Studio, on the left-side pane, select Develop.
Under KQL scripts, Select + (Add new resource) > KQL script. On the right-side pane, you can name your script.
In the Connect to menu, select contosodataexplorer.
In the Use database menu, select TestDatabase.
Paste in the following command, and select Run to create the table.
.create table TestTable (TimeStamp: datetime, Name: string, Metric: int, Source:string)Copy one of the following commands into the Query pane and select Run. This defines the streaming ingestion policy on the table you created or on the database that contains the table.
Tip
A policy that is defined at the database level applies to all existing and future tables in the database.
To define the policy on the table you created, use:
.alter table TestTable policy streamingingestion enableTo define the policy on the database containing the table you created, use:
.alter database StreamingTestDb policy streamingingestion enable
Create a streaming ingestion application to ingest data to your Data Explorer pool
Create your application for ingesting data to your Data Explorer pool using your preferred language. For the poolPath variable, use the Query endpoint you made a note of in the Prerequisites.
using Kusto.Data;
using Kusto.Ingest;
using System.IO;
using Kusto.Data.Common;
namespace StreamingIngestion
{
class Program
{
static void Main(string[] args)
{
string poolPath = "https://<Poolname>.<WorkspaceName>.kusto.windows.net";
string appId = "<appId>";
string appKey = "<appKey>";
string appTenant = "<appTenant>";
string dbName = "<dbName>";
string tableName = "<tableName>";
// Create Kusto connection string with App Authentication
var csb =
new KustoConnectionStringBuilder(poolPath)
.WithAadApplicationKeyAuthentication(
applicationClientId: appId,
applicationKey: appKey,
authority: appTenant
);
// Create a disposable client that will execute the ingestion
using (IKustoIngestClient client = KustoIngestFactory.CreateStreamingIngestClient(csb))
{
// Initialize client properties
var ingestionProperties =
new KustoIngestionProperties(
databaseName: dbName,
tableName: tableName
);
// Ingest from a compressed file
var fileStream = File.Open("MyFile.gz", FileMode.Open);
// Create source options
var sourceOptions = new StreamSourceOptions()
{
CompressionType = DataSourceCompressionType.GZip,
};
// Ingest from stream
var status = client.IngestFromStreamAsync(fileStream, ingestionProperties, sourceOptions).GetAwaiter().GetResult();
}
}
}
}
Disable streaming ingestion on your Data Explorer pool
Warning
Disabling streaming ingestion may take a few hours.
Before disabling streaming ingestion on your Data Explorer pool, drop the streaming ingestion policy from all relevant tables and databases. The removal of the streaming ingestion policy triggers data rearrangement inside your Data Explorer pool. The streaming ingestion data is moved from the initial storage to permanent storage in the column store (extents or shards). This process can take between a few seconds to a few hours, depending on the amount of data in the initial storage.
Drop the streaming ingestion policy
You can drop the streaming ingestion policy using Azure Synapse Studio or the Azure portal.
In Synapse Studio, on the left-side pane, select Develop.
Under KQL scripts, Select + (Add new resource) > KQL script. On the right-side pane, you can name your script.
In the Connect to menu, select contosodataexplorer.
In the Use database menu, select TestDatabase.
Paste in the following command, and select Run to create the table.
.delete table TestTable policy streamingingestionIn the Azure portal, go to your Data Explorer pool.
In Settings, select Configurations.
In the Configurations pane, select On to enable Streaming ingestion.
Select Save.
Limitations
- Database cursors aren't supported for a database if the database itself or any of its tables have the Streaming ingestion policy defined and enabled.
- Data mappings must be pre-created for use in streaming ingestion. Individual streaming ingestion requests don't accommodate inline data mappings.
- Extent tags can't be set on the streaming ingestion data.
- Update policy. The update policy can reference only the newly-ingested data in the source table and not any other data or tables in the database.
- If streaming ingestion is used on any of the tables of the database, this database cannot be used as leader for follower databases or as a data provider for Azure Synapse Analytics Data Share.