Filter and ingest to Azure Data Explorer using the Stream Analytics no code editor
This article describes how you can use the no code editor to easily create a Stream Analytics job. It continuously reads from your Event Hubs, filters the incoming data, and then writes the results continuously to Azure Data Explorer.
Prerequisites
- Your Azure Event Hubs and Azure Data Explorer resources must be publicly accessible and not be behind a firewall or secured in an Azure Virtual Network
- The data in your Event Hubs must be serialized in either JSON, CSV, or Avro format.
Develop a Stream Analytics job to filter and ingest real time data
In the Azure portal, locate and select the Azure Event Hubs instance.
Select Features > Process Data and then select Start on the Filter and store data to Azure Data Explorer card.
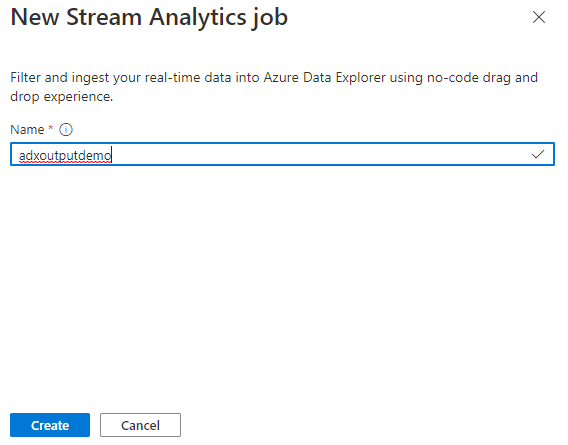
Enter a name for the Stream Analytics job, then select Create.
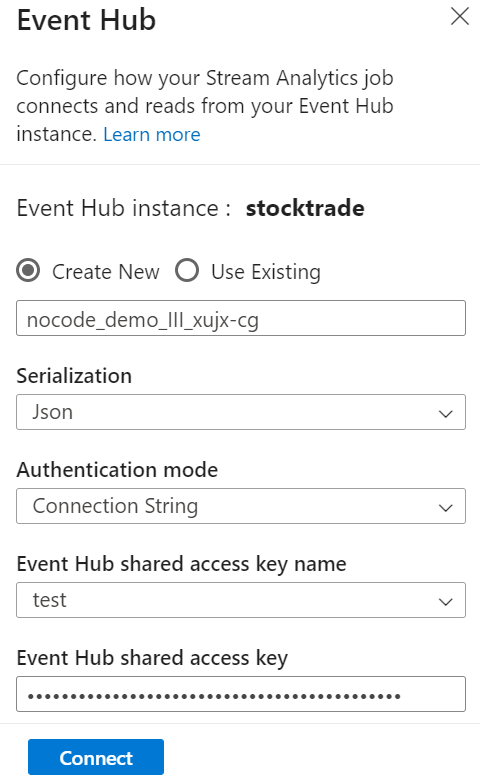
Specify the Serialization type of your data in the Event Hubs window and the Authentication method that the job will use to connect to the Event Hubs. Then select Connect.
When the connection is established successfully and you have data streams flowing into your Event Hubs instance, you'll immediately see two things:
- Fields that are present in the input data. You can choose Add field or select the three dot symbol next to a field to remove, rename, or change its type.
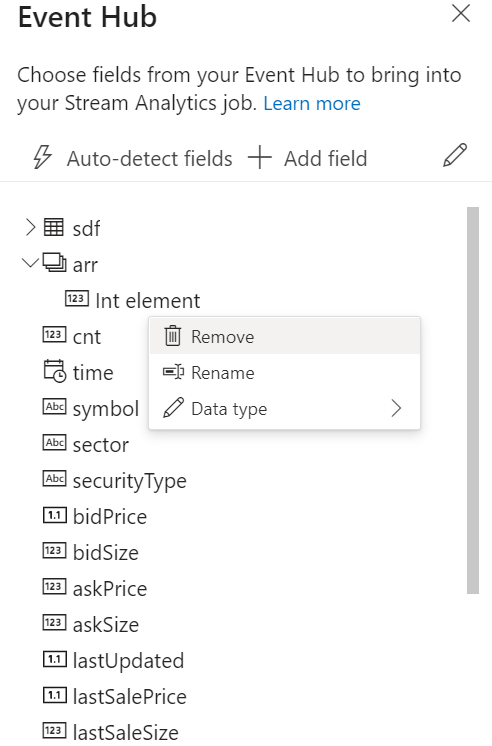
- A live sample of incoming data in the Data preview table under the diagram view. It automatically refreshes periodically. You can select Pause streaming preview to see a static view of the sample input data.

- Fields that are present in the input data. You can choose Add field or select the three dot symbol next to a field to remove, rename, or change its type.
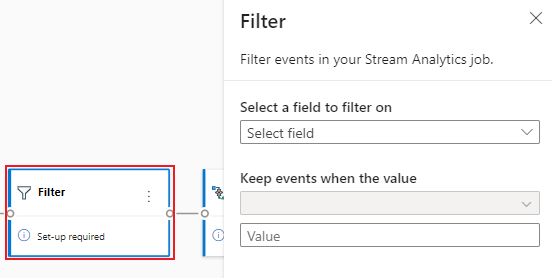
Select the Filter tile to aggregate the data. In the Filter area, select a field to filter the incoming data with a condition.
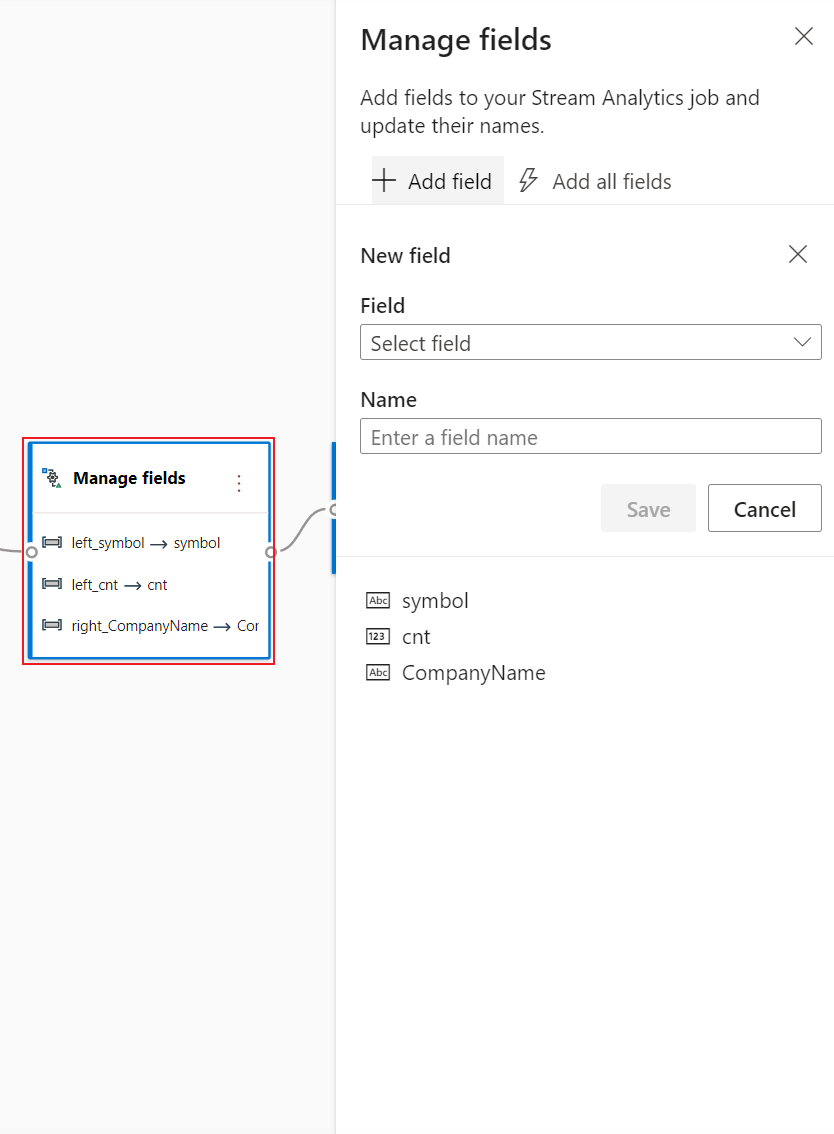
Select the Manage tile. In the Manage fields configuration panel, choose the fields you want to output to event hub. If you want to add all the fields, select Add all fields.
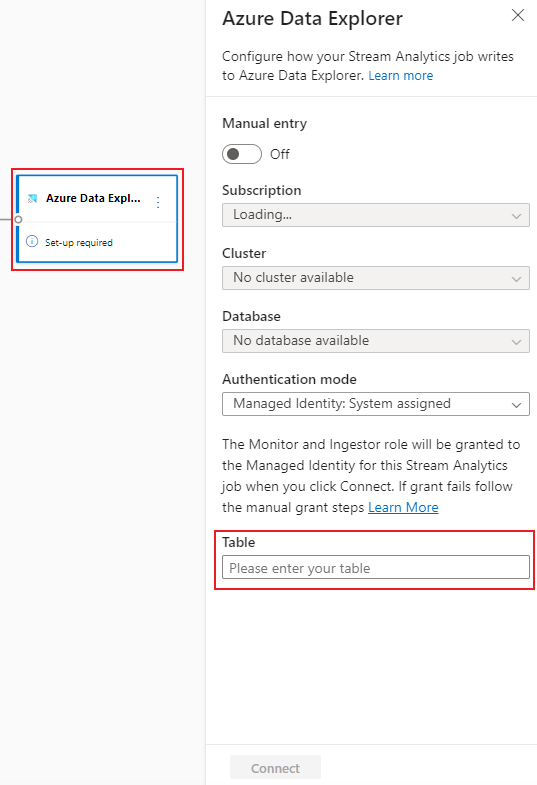
Select Azure Data Explorer tile. In the configuration panel, fill in needed parameters and connect.
Note
The table must exist in your selected database and the table schema must exactly match the number of fields and their types that your data preview generates.
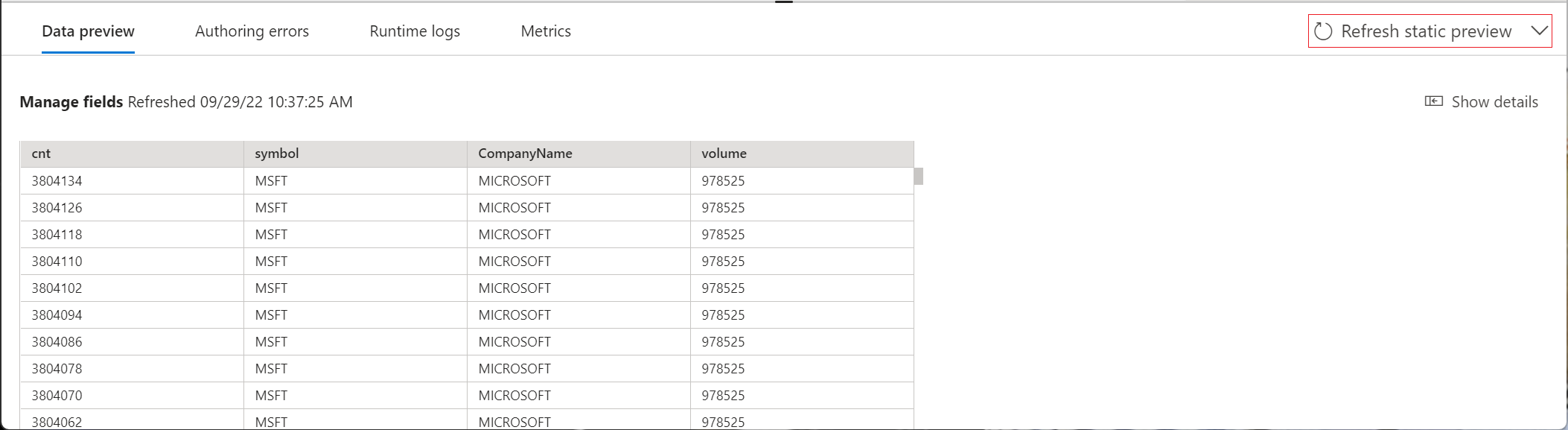
Optionally, select Get static preview/Refresh static preview to see the data preview that will be ingested in event hub.
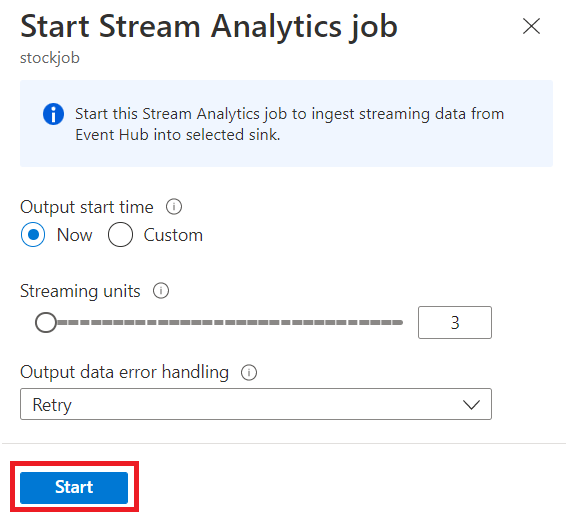
Select Save and then select Start the Stream Analytics job.
To start the job, specify:
- The number of Streaming Units (SUs) the job runs with. SUs represents the amount of compute and memory allocated to the job. We recommended that you start with three and then adjust as needed.
- Output data error handling – It allows you to specify the behavior you want when a job’s output to your destination fails due to data errors. By default, your job retries until the write operation succeeds. You can also choose to drop such output events.
After you select Start, the job starts running within two minutes, and the metrics will be open in tab section below.
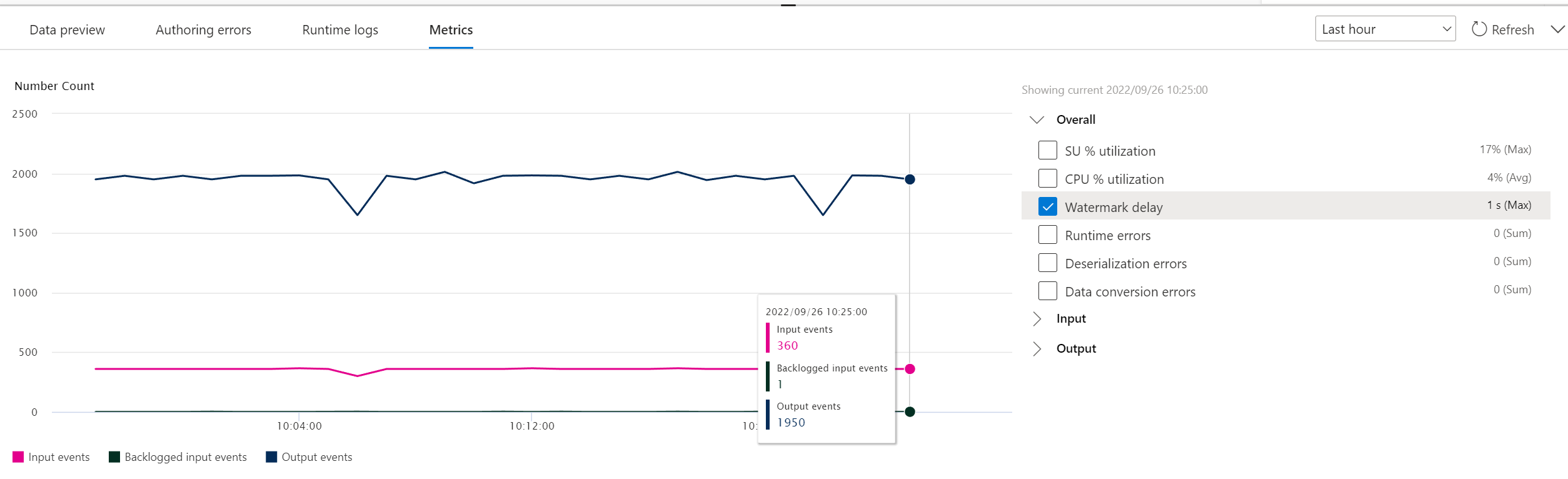
You can also see the job under the Process Data section on the Stream Analytics jobs tab. Select Open metrics to monitor it or stop and restart it, as needed.














Considerations when using the Event Hubs Geo-replication feature
Azure Event Hubs recently launched the Geo-Replication feature in public preview. This feature is different from the Geo Disaster Recovery feature of Azure Event Hubs.
When the failover type is Forced and replication consistency is Asynchronous, Stream Analytics job doesn't guarantee exactly once output to an Azure Event Hubs output.
Azure Stream Analytics, as producer with an event hub an output, might observe watermark delay on the job during failover duration and during throttling by Event Hubs in case replication lag between primary and secondary reaches the maximum configured lag.
Azure Stream Analytics, as consumer with Event Hubs as Input, might observe watermark delay on the job during failover duration and might skip data or find duplicate data after failover is complete.
Due to these caveats, we recommend that you restart the Stream Analytics job with appropriate start time right after Event Hubs failover is complete. Also, since Event Hubs Geo-replication feature is in public preview, we don't recommend using this pattern for production Stream Analytics jobs at this point. The current Stream Analytics behavior will improve before the Event Hubs Geo-replication feature is generally available and can be used in Stream Analytics production jobs.
Next steps
Learn more about Azure Stream Analytics and how to monitor the job you've created.