Vector index size and staying under limits
For each vector field, Azure AI Search constructs an internal vector index using the algorithm parameters specified on the field. Because Azure AI Search imposes quotas on vector index size, you should know how to estimate and monitor vector size to ensure you stay under the limits.
Note
A note about terminology. Internally, the physical data structures of a search index include raw content (used for retrieval patterns requiring non-tokenized content), inverted indexes (used for searchable text fields), and vector indexes (used for searchable vector fields). This article explains the limits for the internal vector indexes that back each of your vector fields.
Tip
Vector optimization techniques are now generally available. Use capabilities like narrow data types, scalar and binary quantization, and elimination of redundant storage to stay under vector quota and storage quota.
Key points about quota and vector index size
Vector index size is measured in bytes.
Vector quotas are based on memory constraints. For vector indexes created using the Hierarchical Navigable Small World (HNSW) algorithm, searchable vector indexes reside in memory. At the same time, there must also be sufficient memory for other runtime operations. Vector quotas exist to ensure that the overall system remains stable and balanced for all workloads. If you use exhaustive KNN algorithm, indexes are loaded into memory only at query time.
Vector indexes are also subject to disk quota, in the sense that all indexes are subject disk quota. There's no separate disk quota for vector indexes.
Vector quotas are enforced on the search service as a whole, per partition, meaning that if you add partitions, vector quota goes up. Per-partition vector quotas are higher on newer services. For more information, see Vector index size limits.
How to check partition size and quantity
If you aren't sure what your search service limits are, here are two ways to get that information:
In the Azure portal, in the search service Overview page, both the Properties tab and Usage tab show partition size and storage, and also vector quota and vector index size.
In the Azure portal, in the Scale page, you can review the number and size of partitions.
How to check service creation date
Newer services created after April 3, 2024 offer five to ten times more vector storage as older ones at the same tier billing rate. If your service is older, consider creating a new service and migrating your content.
In Azure portal, open the resource group that contains your search service.
On the leftmost pane, under Settings, select Deployments.
Locate your search service deployment. If there are many deployments, use the filter to look for "search".
Select the deployment. If you have more than one, click through to see if it resolves to your search service.
Expand deployment details. You should see Created and the creation date.
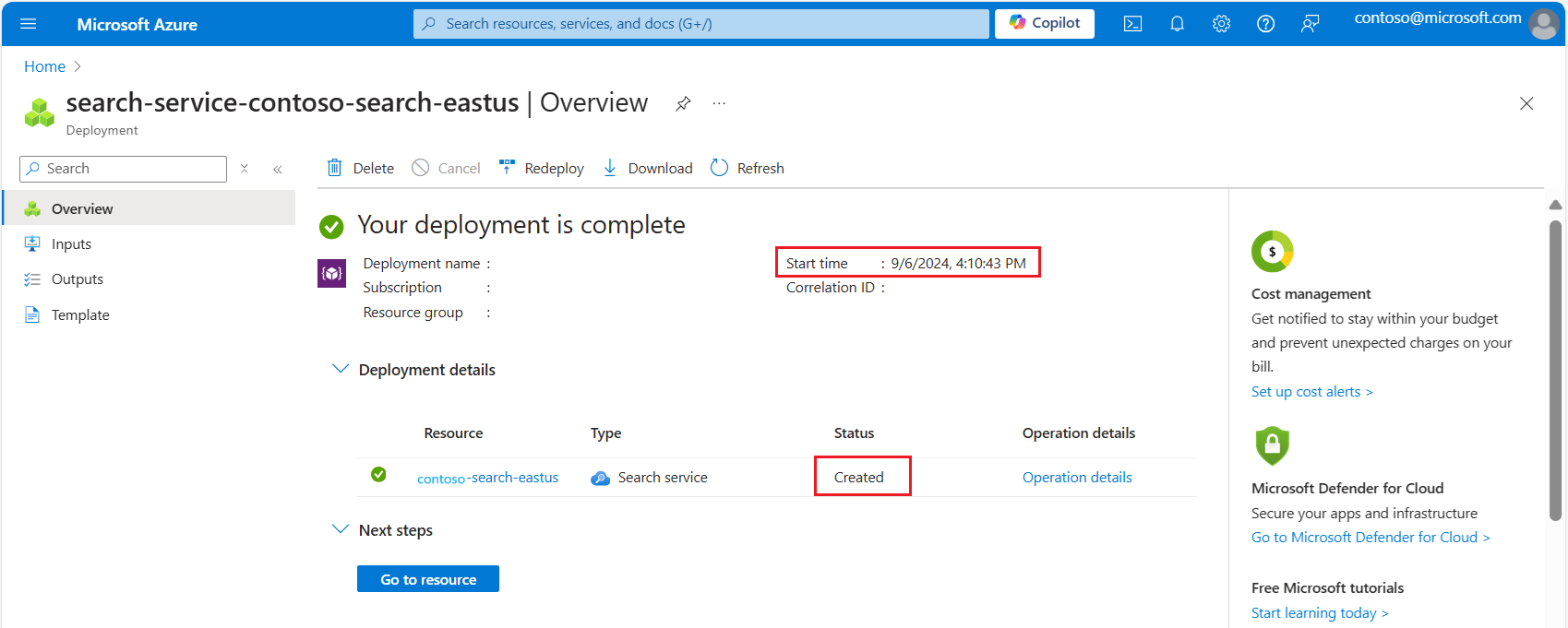
Now that you know the age of your search service, review the vector quota limits based on service creation: Vector index size limits.


How to get vector index size
A request for vector metrics is a data plane operation. You can use the Azure portal, REST APIs, or Azure SDKs to get vector usage at the service level through service statistics and for individual indexes.
Vector size per index
To get vector index size per index, select Search management > Indexes to view a list of indexes and the document count, the size of in-memory vector indexes, and total index size as stored on disk.
Recall that vector quota is based on memory constraints. For vector indexes created using the HNSW algorithm, all searchable vector indexes are permanently loaded into memory. For indexes created using the exhaustive KNN algorithm, vector indexes are loaded in chunks, sequentially, during query time. There's no memory residency requirement for exhaustive KNN indexes. The lifetime of the loaded pages in memory is similar to text search and there are no other metrics applicable to exhaustive KNN indexes other than total storage.
The following screenshot shows two versions of the same vector index. One version is created using HNSW algorithm, where the vector graph is memory resident. Another version is created using exhaustive KNN algorithm. With exhaustive KNN, there's no specialized in-memory vector index, so the portal shows 0 MB for vector index size. Those vectors still exist and are counted in overall storage size, but they don’t occupy the in-memory resource that the vector index size metric is tracking.

Vector size per service
To get vector index size for the search service as a whole, select the Overview page's Usage tab. Portal pages refresh every few minutes so if you recently updated an index, wait a bit before checking results.
The following screenshot is for an older Standard 1 (S1) search service, configured for one partition and one replica.
Storage quota is a disk constraint, and it's inclusive of all indexes (vector and nonvector) on a search service.
Vector index size quota is a memory constraint. It's the amount of memory required to load all internal vector indexes created for each vector field on a search service.
The screenshot indicates that indexes (vector and nonvector) consume almost 460 megabytes of available disk storage. Vector indexes consume almost 93 megabytes of memory at the service level.

Quotas for both storage and vector index size increase or decrease as you add or remove partitions. If you change the partition count, the tile shows a corresponding change in storage and vector quota.
Note
On disk, vector indexes aren't 93 megabytes. Vector indexes on disk take up about three times more space than vector indexes in memory. See How vector fields affect disk storage for details.
Factors affecting vector index size
There are three major components that affect the size of your internal vector index:
- Raw size of the data
- Overhead from the selected algorithm
- Overhead from deleting or updating documents within the index
Raw size of the data
Each vector is usually an array of single-precision floating-point numbers, in a field of type Collection(Edm.Single).
Vector data structures require storage, represented in the following calculation as the "raw size" of your data. Use this raw size to estimate the vector index size requirements of your vector fields.
The storage size of one vector is determined by its dimensionality. Multiply the size of one vector by the number of documents containing that vector field to obtain the raw size:
raw size = (number of documents) * (dimensions of vector field) * (size of data type)
| EDM data type | Size of the data type |
|---|---|
Collection(Edm.Single) |
4 bytes |
Collection(Edm.Half) |
2 bytes |
Collection(Edm.Int16) |
2 bytes |
Collection(Edm.SByte) |
1 byte |
Memory overhead from the selected algorithm
Every approximate nearest neighbor (ANN) algorithm generates extra data structures in memory to enable efficient searching. These structures consume extra space within memory.
For the HNSW algorithm, the memory overhead ranges between 1% and 20%.
The memory overhead is lower for higher dimensions because the raw size of the vectors increases, while the extra data structures remain a fixed size since they store information on the connectivity within the graph. Consequently, the contribution of the extra data structures constitutes a smaller portion of the overall size.
The memory overhead is higher for larger values of the HNSW parameter m, which determines the number of bi-directional links created for every new vector during index construction. This is because m contributes approximately 8 bytes to 10 bytes per document multiplied by m.
The following table summarizes the overhead percentages observed in internal tests:
| Dimensions | HNSW Parameter (m) | Overhead Percentage |
|---|---|---|
| 96 | 4 | 20% |
| 200 | 4 | 8% |
| 768 | 4 | 2% |
| 1536 | 4 | 1% |
| 3072 | 4 | 0.5% |
These results demonstrate the relationship between dimensions, HNSW parameter m, and memory overhead for the HNSW algorithm.
Overhead from deleting or updating documents within the index
When a document with a vector field is either deleted or updated (updates are internally represented as a delete and insert operation), the underlying document is marked as deleted and skipped during subsequent queries. As new documents are indexed and the internal vector index grows, the system cleans up these deleted documents and reclaims the resources. This means you'll likely observe a lag between deleting documents and the underlying resources being freed.
We refer to this as the deleted documents ratio. Since the deleted documents ratio depends on the indexing characteristics of your service, there's no universal heuristic to estimate this parameter, and there's no API or script that returns the ratio in effect for your service. We observe that half of our customers have a deleted documents ratio less than 10%. If you tend to perform high-frequency deletions or updates, then you might observe a higher deleted documents ratio.
This is another factor impacting the size of your vector index. Unfortunately, we don't have a mechanism to surface your current deleted documents ratio.
Estimating the total size for your data in memory
Taking the previously described factors into account, to estimate the total size of your vector index, use the following calculation:
(raw_size) * (1 + algorithm_overhead (in percent)) * (1 + deleted_docs_ratio (in percent))
For example, to calculate the raw_size, let's assume you're using a popular Azure OpenAI model, text-embedding-ada-002 with 1,536 dimensions. This means one document would consume 1,536 Edm.Single (floats), or 6,144 bytes since each Edm.Single is 4 bytes. 1,000 documents with a single, 1,536-dimensional vector field would consume in total 1000 docs x 1536 floats/doc = 1,536,000 floats, or 6,144,000 bytes.
If you have multiple vector fields, you need to perform this calculation for each vector field within your index and add them all together. For example, 1,000 documents with two 1,536-dimensional vector fields, consume 1000 docs x 2 fields x 1536 floats/doc x 4 bytes/float = 12,288,000 bytes.
To obtain the vector index size, multiply this raw_size by the algorithm overhead and deleted document ratio. If your algorithm overhead for your chosen HNSW parameters is 10% and your deleted document ratio is 10%, then we get: 6.144 MB * (1 + 0.10) * (1 + 0.10) = 7.434 MB.
How vector fields affect disk storage
Most of this article provides information about the size of vectors in memory. If you want to know about vector size on disk, the disk consumption for vector data is roughly three times the size of the vector index in memory. For example, if your vectorIndexSize usage is at 100 megabytes (10 million bytes), you would have used least 300 megabytes of storageSize quota to accommodate your vector indexes.