Chunk large documents for vector search solutions in Azure AI Search
Partitioning large documents into smaller chunks can help you stay under the maximum token input limits of embedding models. For example, the maximum length of input text for the Azure OpenAI text-embedding-ada-002 model is 8,191 tokens. Given that each token is around four characters of text for common OpenAI models, this maximum limit is equivalent to around 6,000 words of text. If you're using these models to generate embeddings, it's critical that the input text stays under the limit. Partitioning your content into chunks helps you meet embedding model requirements and prevents data loss due to truncation.
We recommend integrated vectorization for built-in data chunking and embedding. Integrated vectorization takes a dependency on indexers and skillsets that split text and generate embeddings. If you can't use integrated vectorization, this article describes some alternative approaches for chunking your content.
Common chunking techniques
Chunking is only required if the source documents are too large for the maximum input size imposed by models. Here are some common chunking techniques, associated with built-in features if you use indexers and skills.
| Approach | Usage | Built-in functionality |
|---|---|---|
| Fixed-size chunks | Define a fixed size that's sufficient for semantically meaningful paragraphs (for example, 200 words or 600 characters) and allows for some overlap (for example, 10-15% of the content) can produce good chunks as input for embedding vector generators. | Text Split skill, splitting by pages (defined by character length) |
| Variable-sized chunks based on content characteristics | Partition your data based end-of-sentence punctuation marks, end-of-line markers, or using features in the Natural Language Processing (NLP) libraries that detect document structure. Embedded markup, like HTML or Markdown, have heading syntax that can be used to chunk data by sections. | Document Layout skill or Text Split skill, splitting by sentences. |
| Custom combinations | Use a combination of fixed and variable sized chunking, or extend an approach. For example, when dealing with large documents, you might use variable-sized chunks, but also append the document title to chunks from the middle of the document to prevent context loss. | None |
| Document parsing | Indexers can parse larger source documents into smaller search documents for indexing. Strictly speaking, this approach isn't chunking but it can sometimes achieve the same objective. | Index Markdown blobs and files or one-to-many indexing or Index JSON blobs and files |
Content overlap considerations
When you chunk data based on fixed size, overlapping a small amount of text between chunks can help preserve context. We recommend starting with an overlap of approximately 10%. For example, given a fixed chunk size of 256 tokens, you would begin testing with an overlap of 25 tokens. The actual amount of overlap varies depending on the type of data and the specific use case, but we find that 10-15% works for many scenarios.
Factors for chunking data
When it comes to chunking data, think about these factors:
Shape and density of your documents. If you need intact text or passages, larger chunks and variable chunking that preserves sentence structure can produce better results.
User queries: Larger chunks and overlapping strategies help preserve context and semantic richness for queries that target specific information.
Large Language Models (LLM) have performance guidelines for chunk size. Find a chunk size that works best for all of the models you're using. For instance, if you use models for summarization and embeddings, choose an optimal chunk size that works for both.
How chunking fits into the workflow
If you have large documents, insert a chunking step into indexing and query workflows that breaks up large text. When using integrated vectorization, a default chunking strategy using the Text Split skill is common. You can also apply a custom chunking strategy using a custom skill. Some external libraries that provide chunking include:
Most libraries provide common chunking techniques for fixed size, variable size, or a combination. You can also specify an overlap that duplicates a small amount of content in each chunk for context preservation.
Chunking examples
The following examples demonstrate how chunking strategies are applied to NASA's Earth at Night e-book PDF file:
Text Split skill example
Integrated data chunking through Text Split skill is generally available.
This section describes built-in data chunking using a skills-driven approach and Text Split skill parameters.
A sample notebook for this example can be found on the azure-search-vector-samples repository.
Set textSplitMode to break up content into smaller chunks:
pages(default). Chunks are made up of multiple sentences.sentences. Chunks are made up of single sentences. What constitutes a "sentence" is language dependent. In English, standard sentence ending punctuation such as.or!is used. The language is controlled by thedefaultLanguageCodeparameter.
The pages parameter adds extra parameters:
maximumPageLengthdefines the maximum number of characters 1 or tokens 2 in each chunk. The text splitter avoids breaking up sentences, so the actual character count depends on the content.pageOverlapLengthdefines how many characters from the end of the previous page are included at the start of the next page. If set, this must be less than half the maximum page length.maximumPagesToTakedefines how many pages / chunks to take from a document. The default value is 0, which means to take all pages or chunks from the document.
1 Characters don't align to the definition of a token. The number of tokens measured by the LLM might be different than the character size measured by the Text Split skill.
2 Token chunking is available in the 2024-09-01-preview and includes extra parameters for specifying a tokenizer and any tokens that shouldn't be split up during chunking.
The following table shows how the choice of parameters affects the total chunk count from the Earth at Night e-book:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Total Chunk Count |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
N/A | N/A | 13361 |
Using a textSplitMode of pages results in most chunks having total character counts close to maximumPageLength. Chunk character count varies due to differences on where sentence boundaries fall inside the chunk. Chunk token length varies due to differences in the contents of the chunk.
The following histograms show how the distribution of chunk character length compares to chunk token length for gpt-35-turbo when using a textSplitMode of pages, a maximumPageLength of 2000, and a pageOverlapLength of 500 on the Earth at Night e-book:
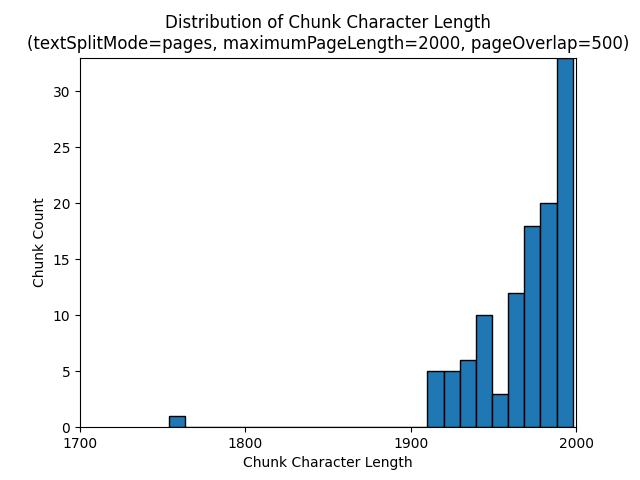
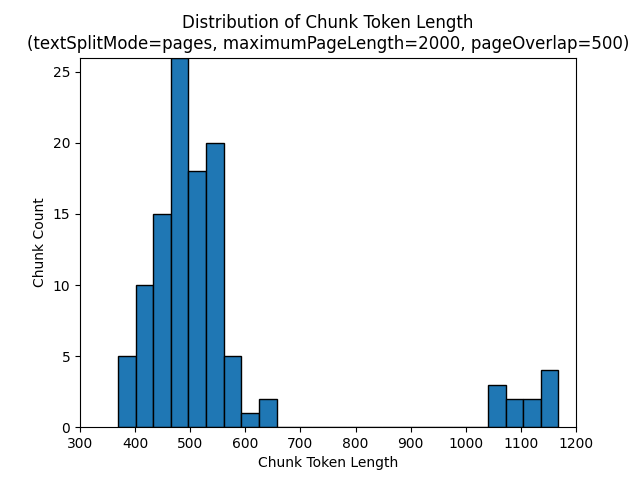
Using a textSplitMode of sentences results in a large number of chunks consisting of individual sentences. These chunks are smaller than those produced by pages, and the token count of the chunks more closely matches the character counts.
The following histograms show how the distribution of chunk character length compares to chunk token length for gpt-35-turbo when using a textSplitMode of sentences on the Earth at Night e-book:
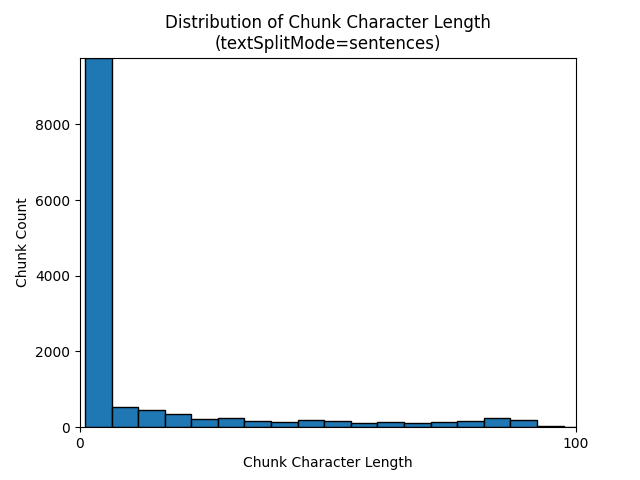
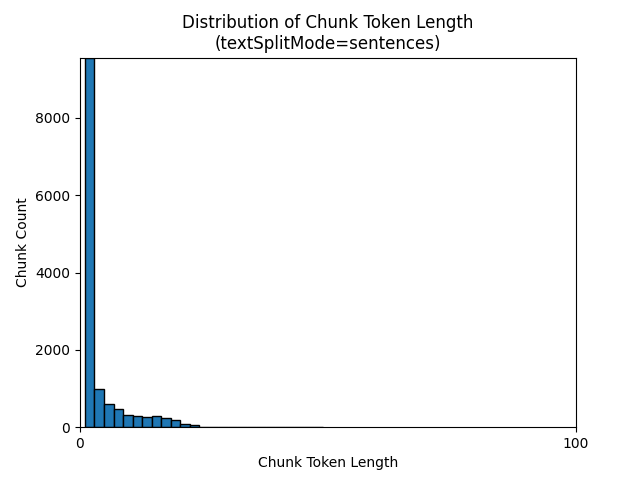
The optimal choice of parameters depends on how the chunks are used. For most applications, it's recommended to start with the following default parameters:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
LangChain data chunking example
LangChain provides document loaders and text splitters. This example shows you how to load a PDF, get token counts, and set up a text splitter. Getting token counts helps you make an informed decision on chunk sizing.
A sample notebook for this example can be found on the azure-search-vector-samples repository.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
Output indicates 200 documents or pages in the PDF.
To get an estimated token count for these pages, use TikToken.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
Output indicates that no pages have zero tokens, the average token length per page is 189 tokens, and the maximum token count of any page is 1,583.
Knowing the average and maximum token size gives you insight into setting chunk size. Although you could use the standard recommendation of 2,000 characters with a 500 character overlap, in this case it makes sense to go lower given the token counts of the sample document. In fact, setting an overlap value that's too large can result in no overlap appearing at all.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
Output for two consecutive chunks shows the text from the first chunk overlapping onto the second chunk. Output is lightly edited for readability.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Custom skill
A fixed-sized chunking and embedding generation sample demonstrates both chunking and vector embedding generation using Azure OpenAI embedding models. This sample uses an Azure AI Search custom skill in the Power Skills repo to wrap the chunking step.