Tutorial: Index nested Markdown blobs from Azure Storage using REST
Note
This feature is currently in public preview. This preview is provided without a service-level agreement, and is not recommended for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Azure AI Search can index Markdown documents and arrays in Azure Blob Storage using an indexer that knows how to read Markdown data.
This tutorial shows you to index Markdown files indexed using the oneToMany Markdown parsing mode. It uses a REST client and the Search REST APIs to perform the following tasks:
- Set up sample data and configure an
azureblobdata source - Create an Azure AI Search index to contain searchable content
- Create and run an indexer to read the container and extract searchable content
- Search the index you just created
If you don't have an Azure subscription, create a free account before you begin.
Prerequisites
Visual Studio Code with a REST client.
Azure AI Search. Create or find an existing Azure AI Search resource under your current subscription.
Note
You can use the free service for this tutorial. A free search service limits you to three indexes, three indexers, and three data sources. This tutorial creates one of each. Before starting, make sure you have room on your service to accept the new resources.
Create a Markdown document
Copy and paste the following Markdown into a file named sample_markdown.md. The sample data is a single Markdown file containing various Markdown elements. We chose one Markdown file to stay under the storage limits of the free tier.
# Project Documentation
## Introduction
This document provides a complete overview of the **Markdown Features** used within this project. The following sections demonstrate the richness of Markdown formatting, with examples of lists, tables, links, images, blockquotes, inline styles, and more.
---
## Table of Contents
1. [Headers](#headers)
2. [Introduction](#introduction)
3. [Basic Text Formatting](#basic-text-formatting)
4. [Lists](#lists)
5. [Blockquotes](#blockquotes)
6. [Images](#images)
7. [Links](#links)
8. [Tables](#tables)
9. [Code Blocks and Inline Code](#code-blocks-and-inline-code)
10. [Horizontal Rules](#horizontal-rules)
11. [Inline Elements](#inline-elements)
12. [Escaping Characters](#escaping-characters)
13. [HTML Elements](#html-elements)
14. [Emojis](#emojis)
15. [Footnotes](#footnotes)
16. [Task Lists](#task-lists)
17. [Conclusion](#conclusion)
---
## Headers
Markdown supports six levels of headers. Use `#` to create headers:
"# Project Documentation" at the top of the document is an example of an h1 header.
"## Headers" above is an example of an h2 header.
### h3 example
#### h4 example
##### h5 example
###### h6 example
This is an example of content underneath a header.
## Basic Text Formatting
You can apply various styles to your text:
- **Bold**: Use double asterisks or underscores: `**bold**` or `__bold__`.
- *Italic*: Use single asterisks or underscores: `*italic*` or `_italic_`.
- ~~Strikethrough~~: Use double tildes: `~~strikethrough~~`.
## Lists
### Ordered List
1. First item
2. Second item
3. Third item
### Unordered List
- Item A
- Item B
- Item C
### Nested List
1. Parent item
- Child item
- Child item
## Blockquotes
> This is a blockquote.
> Blockquotes are great for emphasizing important information.
>> Nested blockquotes are also possible!
## Images

## Links
[Visit Markdown Guide](https://www.markdownguide.org)
## Tables
| Syntax | Description | Example |
|-------------|-------------|---------------|
| Header | Title | Header Cell |
| Paragraph | Text block | Row Content |
## Code Blocks and Inline Code
### Inline Code
Use backticks to create `inline code`.
### Code Block
```javascript
// JavaScript example
function greet(name) {
console.log(`Hello, ${name}!`);
}
greet('World');
```
## Horizontal Rules
Use three or more dashes or underscores to create a horizontal rule.
---
___
## Inline Elements
Sometimes, it’s useful to include `inline code` to highlight code-like content.
You can also emphasize text like *this* or make it **bold**.
## Escaping Characters
To render special Markdown characters, use backslashes:
- \*Asterisks\*
- \#Hashes\#
- \[Brackets\]
## HTML Elements
You can mix HTML tags with Markdown:
<table>
<tr>
<th>HTML Table</th>
<th>With Markdown</th>
</tr>
<tr>
<td>Row 1</td>
<td>Data 1</td>
</tr>
</table>
## Emojis
Markdown supports some basic emojis:
- :smile: 😄
- :rocket: 🚀
- :checkered_flag: 🏁
## Footnotes
This is an example of a footnote[^1]. Footnotes allow you to add notes without cluttering the main text.
[^1]: This is the content of the footnote.
## Task Lists
- [x] Complete the introduction
- [ ] Add more examples
- [ ] Review the document
## Conclusion
Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.
Thank you for reviewing this example!
Copy a search service URL and API key
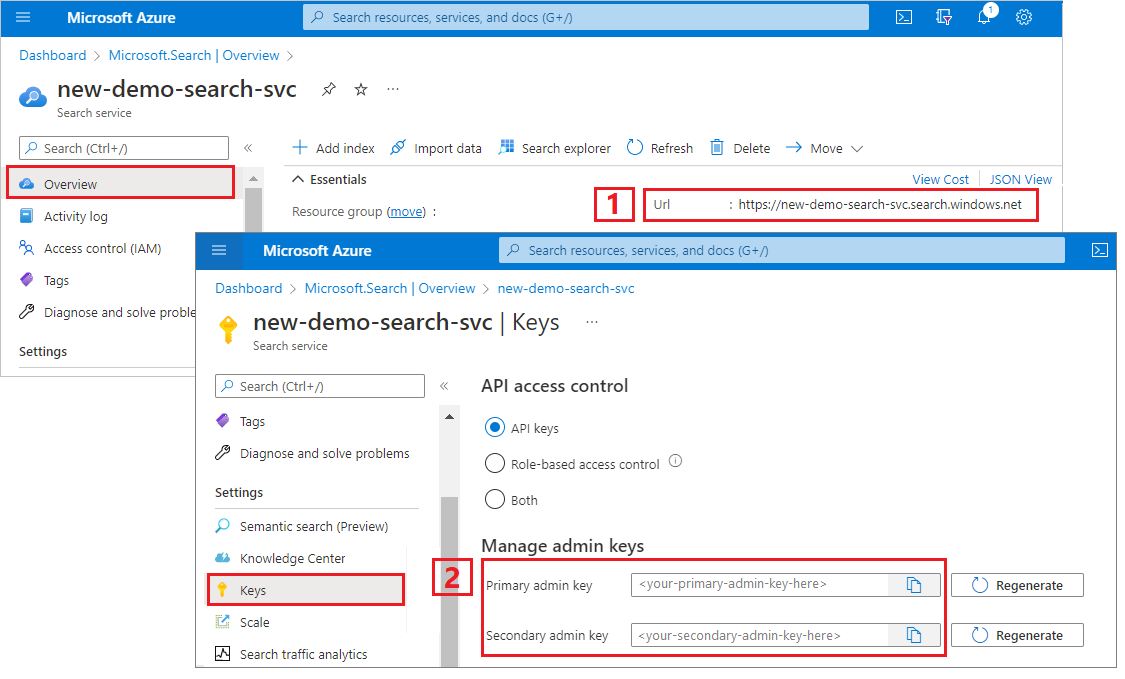
For this tutorial, connections to Azure AI Search require an endpoint and an API key. You can get these values from the Azure portal. For alternative connection methods, see managed identities.
Sign in to the Azure portal, navigate to the search service Overview page, and copy the URL. An example endpoint might look like
https://mydemo.search.windows.net.Under Settings > Keys, copy an admin key. Admin keys are used to add, modify, and delete objects. There are two interchangeable admin keys. Copy either one.
Set up your REST file
Start Visual Studio Code and create a new file.
Provide values for variables used in the request:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnectionString = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HERESave the file using a
.restor.httpfile extension.
See Quickstart: Text search using REST if you need help with the REST client.
Create a data source
Create Data Source (REST) creates a data source connection that specifies what data to index.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Send the request. The response should look like:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DCF52E926A3C76"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('sample-markdown-ds')?api-version=2024-11-01-preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 0714c187-217e-4d35-928a-5069251e5cba
elapsed-time: 204
Date: Fri, 25 Oct 2024 19:52:35 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DCF52E926A3C76\"",
"name": "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "markdown-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Create an index
Create Index (REST) creates a search index on your search service. An index specifies all the fields and their attributes.
In one-to-many parsing, the search document defines the 'many' side of the relationship. The fields you specify in the index determine the structure of the search document.
You only need fields for the Markdown elements that the parser supports. These fields are:
content: A string that contains the raw Markdown found in a specific location, based on the header metadata at that point in the document.sections: An object that contains subfields for the header metadata up to the desired header level. For example, whenmarkdownHeaderDepthis set toh3, contains string fieldsh1,h2, andh3. These fields are indexed by mirroring this structure in the index, or through field mappings in the format/sections/h1,sections/h2, etc. See index and indexer configurations in the following samples for in-context examples. The subfields contained are:h1- A string containing the h1 header value. Empty string if not set at this point in the document.- (Optional)
h2- A string containing the h2 header value. Empty string if not set at this point in the document. - (Optional)
h3- A string containing the h3 header value. Empty string if not set at this point in the document. - (Optional)
h4- A string containing the h4 header value. Empty string if not set at this point in the document. - (Optional)
h5- A string containing the h5 header value. Empty string if not set at this point in the document. - (Optional)
h6- A string containing the h6 header value. Empty string if not set at this point in the document.
ordinal_position: An integer value indicating the position of the section within the document hierarchy. This field is used for ordering the sections in their original sequence as they appear in the document, beginning with an ordinal position of 1 and incrementing sequentially for each content block.
This implementation leverages field mappings in the indexer to map from the enriched content to the index. For more information on the parsed one-to-many document structure, see index markdown blobs.
This example provides samples of how to index data both with and without field mappings. In this case, we know that h1 contains the title of the document, so we can map it to a field named title. We'll also be mapping the h2 and h3 fields to h2_subheader and h3_subheader respectively. The content and ordinal_position fields require no mapping because they are extracted from the Markdown directly into fields using those names. For an example of a full index schema that doesn't require field mappings, see the end of this section.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "title", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Index schema in a configuration with no field mappings
Field mappings allow you to manipulate and filter enriched content to fit into your desired index shape, but you may just want to take the enriched content directly. In that case, the schema would look like:
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "sections",
"type": "Edm.ComplexType",
"fields": [
{"name": "h1", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
To reiterate, we have subfields up to h3 in the sections object because markdownHeaderDepth is set to h3.
If you choose to use this schema, be sure to adjust later requests accordingly. This will require removing the field mappings from the indexer configuration and updating search queries to use the corresponding field names.
Create and run an indexer
Create Indexer creates an indexer on your search service. An indexer connects to the data source, loads and indexes data, and optionally provides a schedule to automate the data refresh.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-indexer",
"dataSourceName": "sample-markdown-ds",
"targetIndexName": "sample-markdown-index",
"parameters" : {
"configuration": {
"parsingMode": "markdown",
"markdownParsingSubmode": "oneToMany",
"markdownHeaderDepth": "h3"
}
},
"fieldMappings" : [
{
"sourceFieldName": "/sections/h1",
"targetFieldName": "title",
"mappingFunction": null
}
]
}
Key points:
The indexer will only parse headers up to
h3. Any lower-level headers (h4,h5,h6) will be treated as plain text and show up in thecontentfield. This is why the index and field mappings only exist up to a depth ofh3.The
contentandordinal_positionfields require no field mapping as they exist with those names in the enriched content.
Run queries
You can start searching as soon as the first document is loaded.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Send the request. This is an unspecified full text search query that returns all of the fields marked as retrievable in the index, along with a document count. The response should look like:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 6b94e605-55e8-47a5-ae15-834f926ddd14
elapsed-time: 77
Date: Fri, 25 Oct 2024 20:22:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 22,
"value": [
<22 search documents here>
]
}
Add a search parameter to search on a string.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "h4",
"count": true,
}
Send the request. The response should look like:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: ec5d03f1-e3e7-472f-9396-7ff8e3782105
elapsed-time: 52
Date: Fri, 25 Oct 2024 20:26:29 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 0.8744742,
"section_id": "aHR0cHM6Ly9hcmphZ2Fubmpma2ZpbGVzLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tYXJrZG93bi10dXRvcmlhbC9zYW1wbGVfbWFya2Rvd24ubWQ7NA2",
"content": "#### h4 example\r\n##### h5 example\r\n###### h6 example\r\nThis is an example of content underneath a header.\r\n",
"title": "Project Documentation",
"h2_subheader": "Headers",
"h3_subheader": "h3 example",
"ordinal_position": 4
}
]
}
Key points:
Because the
markdownHeaderDepthis set toh3, theh4,h5, andh6headers are treated as plaintext, so they appear in thecontentfield.Ordinal position here is
4. This content appears fourth out of the 22 total content sections.
Add a select parameter to limit the results to fewer fields. Add a filter to further narrow the search.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "Markdown",
"count": true,
"select": "title, content, h2_subheader",
"filter": "h2_subheader eq 'Conclusion'"
}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a6f9bd46-a064-4e28-818f-ea077618014b
elapsed-time: 35
Date: Fri, 25 Oct 2024 20:36:10 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 1.1029507,
"content": "Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.\r\n\r\nThank you for reviewing this example!",
"title": "Project Documentation",
"h2_subheader": "Conclusion"
}
]
}
For filters, you can also use Logical operators (and, or, not) and comparison operators (eq, ne, gt, lt, ge, le). String comparisons are case-sensitive. For more information and examples, see Create a query.
Note
The $filter parameter only works on fields that were marked filterable at the creation of your index.
Reset and rerun
Indexers can be reset, clearing execution history, which allows a full rerun. The following GET requests are for reset, followed by rerun.
### Reset the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/reset?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/run?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/sample-markdown-indexer/status?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
Clean up resources
When you're working in your own subscription, at the end of a project, it's a good idea to remove the resources that you no longer need. Resources left running can cost you money. You can delete resources individually or delete the resource group to delete the entire set of resources.
You can use the Azure portal to delete indexes, indexers, and data sources.
Next steps
Now that you're familiar with the basics of Azure Blob indexing, let's take a closer look at indexer configuration for Markdown blobs in Azure Storage.