High availability (Reliability) in Azure Database for PostgreSQL - Flexible Server
APPLIES TO:  Azure Database for PostgreSQL - Flexible Server
Azure Database for PostgreSQL - Flexible Server
This article describes high availability in Azure Database for PostgreSQL - Flexible Server, which includes availability zones and cross-region recovery and business continuity. For a more detailed overview of reliability in Azure, see Azure reliability.
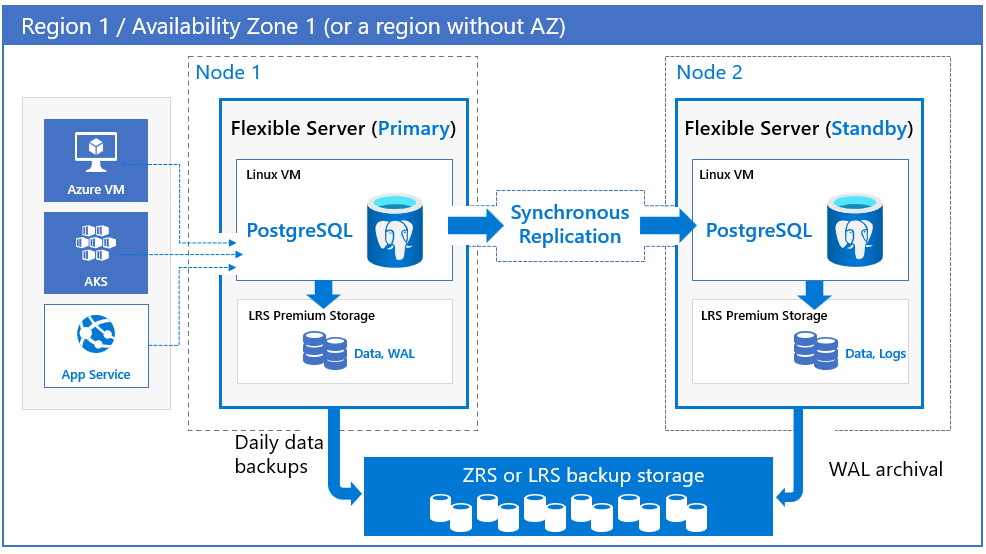
Azure Database for PostgreSQL - Flexible Server offers high availability support by provisioning physically separated primary and standby replicas, either within the same availability zone (zonal) or across availability zones (zone-redundant). This high availability model is designed to ensure that committed data is never lost in the case of failures. In a high availability (HA) setup, data is synchronously committed to both the primary and standby servers. The model is designed so that the database doesn't become a single point of failure in your software architecture. For more information on high availability and availability zone support, see Availability zone support.
Availability zone support
Availability zones are physically separate groups of datacenters within each Azure region. When one zone fails, services can fail over to one of the remaining zones.
For more information on availability zones in Azure, see What are availability zones?
Azure Database for PostgreSQL - Flexible Server supports both zone-redundant and zonal models for high availability configurations. Both high availability configurations enable automatic failover capability with zero data loss during both planned and unplanned events.
Zone-redundant. Zone redundant high availability deploys a standby replica in a different zone with automatic failover capability. Zone redundancy provides the highest level of availability, but requires you to configure application redundancy across zones. For that reason, choose zone redundancy when you want protection from availability zone level failures and when latency across the availability zones is acceptable. While there can be some latency impact on writes and commits due to synchronous replication, it doesn't affect read queries. This impact is very specific to your workloads, the SKU type you select, and the region.
You can choose the region and the availability zones for both primary and standby servers. The standby replica server is provisioned in the chosen availability zone in the same region with a similar compute, storage, and network configuration as the primary server. Data files and transaction log files (write-ahead logs, a.k.a WAL) are stored on locally redundant storage (LRS) within each availability zone, automatically storing three data copies. A zone-redundant configuration provides physical isolation of the entire stack between primary and standby servers.

Zonal. Choose a zonal deployment when you want to achieve the highest level of availability within a single availability zone, but with the lowest network latency. You can choose the region and the availability zone to deploy both your primary database server. A standby replica server is automatically provisioned and managed in the same availability zone - with similar compute, storage, and network configuration - as the primary server. A zonal configuration protects your databases from node-level failures and also helps with reducing application downtime during planned and unplanned downtime events. Data from the primary server is replicated to the standby replica in synchronous mode. In the event of any disruption to the primary server, the server is automatically failed over to the standby replica.


Note
Both zonal and zone-redundant deployment models architecturally behave the same. Various discussions in the following sections apply to both unless called out otherwise.
Prerequisites
Zone redundancy:
The zone-redundancy option is only available in regions that support availability zones.
Zone-redundancy is not supported for:
- Azure Database for PostgreSQL – Single Server SKU.
- Burstable compute tier.
- Regions with single-zone availability.
Zonal:
- The zonal deployment option is available in all Azure regions where you can deploy Flexible Server.
High availability features
A standby replica is deployed in the same VM configuration - including vCores, storage, network settings - as the primary server.
You can add availability zone support for an existing database server.
You can remove the standby replica by disabling high availability.
You can choose availability zones for your primary and standby database servers for zone-redundant availability.
Operations such as stop, start, and restart are performed on both primary and standby database servers at the same time.
In zone-redundant and zonal models, automatic backups are performed periodically from the primary database server. At the same time, the transaction logs are continuously archived in the backup storage from the standby replica. If the region supports availability zones, backup data is stored on zone-redundant storage (ZRS). In regions that don't support availability zones, backup data is stored on local redundant storage (LRS).
Clients always connect to the end hostname of the primary database server.
Any changes to the server parameters are also applied to the standby replica.
Ability to restart the server to pick up any static server parameter changes.
Periodic maintenance activities such as minor version upgrades happen at the standby first and, to reduce downtime, the standby is promoted to primary so that workloads can keep on, while the maintenance tasks are applied on the remaining node.
Monitor High-Availability Health
High Availability (HA) health status monitoring in Azure Database for PostgreSQL - Flexible Server provides a continuous overview of the health and readiness of HA-enabled instances. This monitoring feature leverages Azure’s Resource Health Check (RHC) framework to detect and alert on any issues that may impact your database's failover readiness or overall availability. By assessing key metrics like connection status, failover state, and data replication health, HA health status monitoring enables proactive troubleshooting and helps maintain your database’s uptime and performance.
Customers can use HA health status monitoring to:
- Gain real-time insights into the health of both primary and standby replicas, with status indicators that reveal potential issues, such as degraded performance or network blocking.
- Configure alerts for timely notifications on any changes in HA status, ensuring immediate action to address potential disruptions.
- Optimize failover readiness by identifying and addressing issues before they impact database operations.
For a detailed guide on configuring and interpreting HA health statuses, refer to the main article High Availability (HA) health status monitoring for Azure Database for PostgreSQL - Flexible Server.
High availability limitations
Due to synchronous replication to the standby server, especially with a zone-redundant configuration, applications can experience elevated write and commit latency.
Standby replica can't be used for read queries.
Depending on the workload and activity on the primary server, the failover process might take longer than 120 seconds due to the recovery involved at the standby replica before it can be promoted.
The standby server typically recovers WAL files at 40 MB/s. For larger SKUs, this rate can increase to as much as 200 MB/s. If your workload exceeds this limit, you can encounter extended time for the recovery to complete either during the failover or after establishing a new standby.
Restarting the primary database server also restarts the standby replica.
Configuring an extra standby isn't supported.
Configuring customer-initiated management tasks can't be scheduled during the managed maintenance window.
Planned events such as scale computing and scale storage happens on the standby first and then on the primary server. Currently, the server doesn't failover for these planned operations.
If logical decoding or logical replication is configured with an availability-configured Flexible Server, in the event of a failover to the standby server, the logical replication slots aren't copied over to the standby server. To maintain logical replication slots and ensure data consistency after a failover, it is recommended to use the PG Failover Slots extension. For more information on how to enable this extension, please refer to the documentation.
Configuring availability zones between private (VNET) and public access with private endpoints isn't supported. You must configure availability zones within a VNET (spanned across availability zones within a region) or public access with private endpoints.
Availability zones are configured only within a single region. Availability zones can't be configured across regions.
SLA
Zonal model offers uptime SLA of 99.95%.
Zone-redundancy model offers uptime SLA of 99.99%.
Create an Azure Database for PostgreSQL - Flexible Server with availability zone enabled
To learn how to create an Azure Database for PostgreSQL - Flexible Server for high availability with availability zones, see Quickstart: Create an Azure Database for PostgreSQL - Flexible Server in the Azure portal.
Availability zone redeployment and migration
To learn how to enable or disable high availability configuration in your flexible server in both zone-redundant and zonal deployment models see Manage high availability in Flexible Server.
High availability components and workflow
Transaction completion
Application transaction-triggered writes and commits are first logged to the WAL on the primary server. These are then streamed to the standby server using the Postgres streaming protocol. Once the logs are persisted on the standby server storage, the primary server is acknowledged for write completion. Only then the application is confirmed the commit of its transaction. This additional round-trip adds more latency to your application. The percentage of impact depends on the application. This acknowledgment process doesn't wait for the logs to be applied to the standby server. The standby server is permanently in recovery mode until it's promoted.
Health check
Flexible server health monitoring periodically checks for both the primary and standby health. After multiple pings, if health monitoring detects that a primary server isn't reachable, the service then initiates an automatic failover to the standby server. The health monitoring algorithm is based on multiple data points to avoid false positive situations.
Failover modes
Flexible server supports two failover modes, Planned failover and Unplanned failover. In both modes, once the replication is severed, the standby server runs the recovery before being promoted as a primary and opens for read/write. With automatic DNS entries updated with the new primary server endpoint, applications can connect to the server using the same endpoint. A new standby server is established in the background, so that your application can maintain connectivity.
High availability status
The health of primary and standby servers are continuously monitored, and appropriate actions are taken to remediate issues, including triggering a failover to the standby server. The table below lists the possible high availability statuses:
| Status | Description |
|---|---|
| Initializing | In the process of creating a new standby server. |
| Replicating Data | After the standby is created, it's catching up with the primary. |
| Healthy | Replication is in steady state and healthy. |
| Failing Over | The database server is in the process of failing over to the standby. |
| Removing Standby | In the process of deleting standby server. |
| Not Enabled | High availability isn't enabled. |
Note
You can enable high availability during server creation or at a later time as well. If you are enabling or disabling high availability during the post-create stage, operating when the primary server activity is low is recommended.
Steady-state operations
PostgreSQL client applications are connected to the primary server using the DB server name. Application reads are served directly from the primary server. At the same time, commits and writes are confirmed to the application only after the log data is persisted on both the primary server and the standby replica. Due to this extra round-trip, applications can expect elevated latency for writes and commits. You can monitor the health of the high availability on the portal.
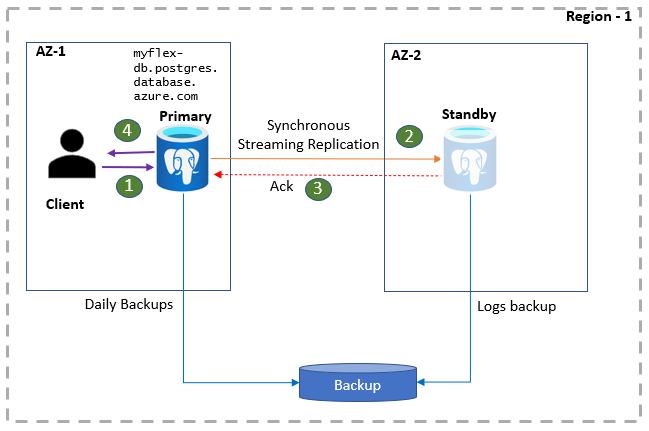
- Clients connect to the flexible server and perform write operations.
- Changes are replicated to the standby site.
- Primary receives an acknowledgment.
- Writes/commits are acknowledged.
Point-in-time restore of high availability servers
For flexible servers configured with high availability, log data is replicated in real-time to the standby server. Any user errors on the primary server - such as an accidental drop of a table or incorrect data updates, are replicated to the standby replica. So, you can't use standby to recover from such logical errors. To recover from such errors, you have to perform a point-in-time restore from the backup. Using a flexible server's point-in-time restore capability, you can restore to the time before the error occurred. A new database server is restored as a single-zone flexible server with a new user-provided server name for databases configured with high availability. You can use the restored server for a few use cases:
You can use the restored server for production and optionally enable high availability with standby replica on either same zone or another zone in the same region.
If you want to restore an object, export it from the restored database server and import it to your production database server.
If you want to clone your database server for testing and development purposes or to restore for any other purposes, you can perform the point-in-time restore.
To learn how to do a point-in-time restore of a flexible server, see Point-in-time restore of a flexible server.
Failover Support
Planned failover
Planned downtime events include Azure scheduled periodic software updates and minor version upgrades. You can also use a planned failover to return the primary server to a preferred availability zone. When configured in high availability, these operations are first applied to the standby replica while the applications continue to access the primary server. Once the standby replica is updated, primary server connections are drained, and a failover is triggered, which activates the standby replica to be the primary with the same database server name. Client applications have to reconnect with the same database server name to the new primary server and can resume their operations. A new standby server is established in the same zone as the old primary.
For other user-initiated operations such as scale-compute or scale-storage, the changes are applied on the standby first, followed by the primary. Currently, the service isn't failed over to the standby, and hence while the scale operation is carried out on the primary server, applications encounter a short downtime.
You can also use this feature to failover to the standby server with reduced downtime. For example, your primary could be on a different availability zone than the application, after an unplanned failover. You want to bring the primary server back to the previous zone to colocate with your application.
When executing this feature, the standby server is first prepared to ensure it's caught up with recent transactions, allowing the application to continue performing reads/writes. The standby is then promoted, and the connections to the primary are severed. Your application can continue to write to the primary while a new standby server is established in the background. The following are the steps involved with planned failover:
| Step | Description | App downtime expected? |
|---|---|---|
| 1 | Wait for the standby server to have caught-up with the primary. | No |
| 2 | Internal monitoring system initiates the failover workflow. | No |
| 3 | Application writes are blocked when the standby server is close to the primary log sequence number (LSN). | Yes |
| 4 | Standby server is promoted to be an independent server. | Yes |
| 5 | DNS record is updated with the new standby server's IP address. | Yes |
| 6 | Application to reconnect and resume its read/write with new primary. | No |
| 7 | A new standby server in another zone is established. | No |
| 8 | Standby server starts to recover logs (from Azure Blob) that it missed during its establishment. | No |
| 9 | A steady state between the primary and the standby server is established. | No |
| 10 | Planned failover process is complete. | No |
Application downtime starts at step #3 and can resume operation post step #5. The rest of the steps happen in the background without affecting application writes and commits.
Tip
With flexible server, you can optionally schedule Azure-initiated maintenance activities by choosing a 60-minute window on a day of your preference where the activities on the databases are expected to be low. Azure maintenance tasks such as patching or minor version upgrades would happen during that window. If you don't choose a custom window, a system allocated 1-hr window between 11 pm - 7 am local time is selected for your server. These Azure-initiated maintenance activities are also performed on the standby replica for flexible servers that are configured with availability zones.
For a list of possible planned downtime events, see Planned downtime events.
Unplanned failover
Unplanned downtimes can occur as a result of unforeseen disruptions such as underlying hardware fault, networking issues, and software bugs. If the database server configured with high availability goes down unexpectedly, then the standby replica is activated and the clients can resume their operations. If not configured with high availability (HA), then if the restart attempt fails, a new database server is automatically provisioned. While an unplanned downtime can't be avoided, flexible server helps mitigating the downtime by automatically performing recovery operations without requiring human intervention.
For information on unplanned failovers and downtime, including possible scenarios, see Unplanned downtime mitigation.
Failover testings (forced failover)
With a forced failover, you can simulate an unplanned outage scenario while running your production workload and observe your application downtime. You can also use a forced failover when your primary server becomes unresponsive.
A forced failover brings the primary server down and initiates the failover workflow in which the standby promote operation is performed. Once the standby completes the recovery process till the last committed data, it's promoted to be the primary server. DNS records are updated, and your application can connect to the promoted primary server. Your application can continue to write to the primary while a new standby server is established in the background, which doesn't impact the uptime.
The following are the steps during forced failover:
| Step | Description | App downtime expected? |
|---|---|---|
| 1 | Primary server is stopped shortly after receiving the failover request. | Yes |
| 2 | Application encounters downtime as the primary server is down. | Yes |
| 3 | Internal monitoring system detects the failure and initiates a failover to the standby server. | Yes |
| 4 | Standby server enters recovery mode before being fully promoted as an independent server. | Yes |
| 5 | The failover process waits for the standby recovery to complete. | Yes |
| 6 | Once the server is up, the DNS record is updated with the same hostname but using the standby's IP address. | Yes |
| 7 | Application can reconnect to the new primary server and resume the operation. | No |
| 8 | A standby server in the preferred zone is established. | No |
| 9 | Standby server starts to recover logs (from Azure Blob) that it missed during its establishment. | No |
| 10 | A steady state between the primary and the standby server is established. | No |
| 11 | Forced failover process is complete. | No |
Application downtime is expected to start after step #1 and persists until step #6 is completed. The rest of the steps happen in the background without affecting the application writes and commits.
Important
The end-to-end failover process includes (a) failing over to the standby server after the primary failure and (b) establishing a new standby server in a steady state. As your application incurs downtime until the failover to the standby is complete, please measure the downtime from your application/client perspective instead of the overall end-to-end failover process.
Considerations while performing forced failovers
The overall end-to-end operation time can be seen as longer than the actual downtime experienced by the application.
Important
Always observe the downtime from the application perspective!
Don't perform immediate, back-to-back failovers. Wait for at least 15-20 minutes between failovers, allowing the new standby server to be fully established.
It's recommended that you perform a forced failover during a low-activity period to reduce downtime.
Best practices for PostgreSQL statistics after failover
After a PostgreSQL failover, the primary mechanism for maintaining optimal database performance involves understanding the distinct roles of pg_statistic and the pg_stat_* tables. The pg_statistic table houses optimizer statistics, which are crucial for the query planner. These statistics include data distributions within tables and remain intact after a failover, ensuring that the query planner can continue to optimize query execution effectively based on accurate, historical data distribution information.
In contrast, the pg_stat_* tables, which record activity statistics such as the number of scans, tuples read, and updates, are reset upon failover. An example of such a table is pg_stat_user_tables, which tracks activity for user-defined tables. This reset is designed to accurately reflect the new primary's operational state but also means the loss of historical activity metrics that could inform the autovacuum process and other operational efficiencies.
Given this distinction, the best practice following a PostgreSQL failover is to run ANALYZE. This action updates the pg_stat_* tables, like pg_stat_user_tables, with fresh activity statistics, helping the autovacuum process and ensuring that the database performance remains optimal in its new role. This proactive step bridges the gap between preserving essential optimizer statistics and refreshing activity metrics to align with the database's current state.
Zone-down experience
Zonal: To recover from a zone-level failure, you can perform point-in-time restore using the backup. You can choose a custom restore point with the latest time to restore the latest data. A new flexible server is deployed in another nonaffected zone. The time taken to restore depends on the previous backup and the volume of transaction logs to recover.
For more information on point-in-time restore, see Backup and restore in Azure Database for PostgreSQL-Flexible Server.
Zone-redundant: Flexible server is automatically failed over to the standby server within 60-120 seconds with zero data loss.
Configurations without availability zones
Although it's not recommended, you can configure your flexible server without high availability enabled. For flexible servers configured without high availability, the service provides local redundant storage with three copies of data, zone-redundant backup (in regions where it's supported), and built-in server resiliency to automatically restart a crashed server and relocate the server to another physical node. Uptime SLA of 99.9% is offered in this configuration. During planned or unplanned failover events, if the server goes down, the service maintains the availability of the servers using the following automated procedure:
- A new compute Linux VM is provisioned.
- The storage with data files is mapped to the new virtual machine.
- PostgreSQL database engine is brought online on the new virtual machine.
The picture below shows the transition between VM and storage failure.

Cross-region disaster recovery and business continuity
In the case of a region-wide disaster, Azure can provide protection from regional or large geography disasters with disaster recovery by making use of another region. For more information on Azure disaster recovery architecture, see Azure to Azure disaster recovery architecture.
Flexible server provides features that protect data and mitigates downtime for your mission-critical databases during planned and unplanned downtime events. Built on top of the Azure infrastructure that offers robust resiliency and availability, flexible server offers business continuity features that provide fault-protection, address recovery time requirements, and reduce data loss exposure. As you architect your applications, you should consider the downtime tolerance - the recovery time objective (RTO), and data loss exposure - the recovery point objective (RPO). For example, your business-critical database requires stricter uptime than a test database.
Disaster recovery in multi-region geography
Geo-redundant backup and restore
Geo-redundant backup and restore provide the ability to restore your server in a different region in the event of a disaster. It also provides at least 99.99999999999999 percent (16 nines) durability of backup objects over a year.
Geo-redundant backup can be configured only at the time of server creation. When the server is configured with geo-redundant backup, the backup data and transaction logs are copied to the paired region asynchronously through storage replication.
For more information on geo-redundant backup and restore, see geo-redundant backup and restore.
Read replicas
Cross region read replicas can be deployed to protect your databases from region-level failures. Read replicas are updated asynchronously using PostgreSQL's physical replication technology, and can lag the primary. Read replicas are supported in general purpose and memory optimized compute tiers.
For more information on read replica features and considerations, see Read replicas.
Outage detection, notification, and management
If your server is configured with geo-redundant backup, you can perform geo-restore in the paired region. A new server is provisioned and recovered to the last available data that was copied to this region.
You can also use cross region read replicas. In the event of region failure you can perform disaster recovery operation by promoting your read replica to be a standalone read-writeable server. RPO is expected to be up to 5 minutes (data loss possible) except in the case of severe regional failure when the RPO can be close to the replication lag at the time of failure.
For more information on unplanned downtime mitigation and recovery after regional disaster, see Unplanned downtime mitigation.