Interactive R development
APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
This article shows how to use R in Azure Machine Learning studio on a compute instance that runs an R kernel in a Jupyter notebook.
The popular RStudio IDE also works. You can install RStudio or Posit Workbench in a custom container on a compute instance. However, this has limitations in reading and writing to your Azure Machine Learning workspace.
Important
The code shown in this article works on an Azure Machine Learning compute instance. The compute instance has an environment and configuration file necessary for the code to run successfully.
Prerequisites
- If you don't have an Azure subscription, create a free account before you begin. Try the free or paid version of Azure Machine Learning today
- An Azure Machine Learning workspace and a compute instance
- A basic understand of using Jupyter notebooks in Azure Machine Learning studio. Visit the Model development on a cloud workstation resource for more information.
Run R in a notebook in studio
You'll use a notebook in your Azure Machine Learning workspace, on a compute instance.
Sign in to Azure Machine Learning studio
Open your workspace if it isn't already open
On the left navigation, select Notebooks
Create a new notebook, named RunR.ipynb
Tip
If you're not sure how to create and work with notebooks in studio, review Run Jupyter notebooks in your workspace
Select the notebook.
On the notebook toolbar, make sure your compute instance is running. If not, start it now.
On the notebook toolbar, switch the kernel to R.
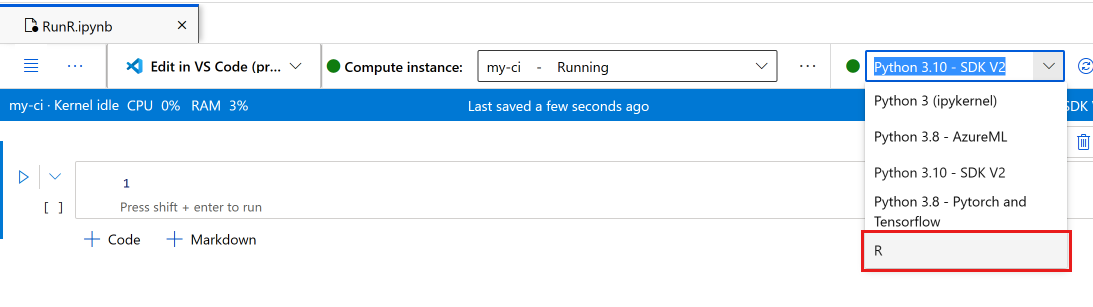

Your notebook is now ready to run R commands.
Access data
You can upload files to your workspace file storage resource, and then access those files in R. However, for files stored in Azure data assets or data from datastores, you must install some packages.
This section describes how to use Python and the reticulate package to load your data assets and datastores into R, from an interactive session. You use the azureml-fsspec Python package and the reticulate R package to read tabular data as Pandas DataFrames. This section also includes an example of reading data assets and datastores into an R data.frame.
To install these packages:
Create a new file on the compute instance, called setup.sh.
Copy this code into the file:
#!/bin/bash set -e # Installs azureml-fsspec in default conda environment # Does not need to run as sudo eval "$(conda shell.bash hook)" conda activate azureml_py310_sdkv2 pip install azureml-fsspec conda deactivate # Checks that version 1.26 of reticulate is installed (needs to be done as sudo) sudo -u azureuser -i <<'EOF' R -e "if (packageVersion('reticulate') >= 1.26) message('Version OK') else install.packages('reticulate')" EOFSelect Save and run script in terminal to run the script
The install script handles these steps:
pipinstallsazureml-fsspecin the default conda environment for the compute instance- Installs the R
reticulatepackage if necessary (version must be 1.26 or greater)
Read tabular data from registered data assets or datastores
For data stored in a data asset created in Azure Machine Learning, use these steps to read that tabular file into a Pandas DataFrame or an R data.frame:
Note
Reading a file with reticulate only works with tabular data.
Ensure you have the correct version of
reticulate. For a version less than 1.26, try to use a newer compute instance.packageVersion("reticulate")Load
reticulateand set the conda environment whereazureml-fsspecwas installedlibrary(reticulate) use_condaenv("azureml_py310_sdkv2") print("Environment is set")Find the URI path to the data file.
First, get a handle to your workspace
py_code <- "from azure.identity import DefaultAzureCredential from azure.ai.ml import MLClient credential = DefaultAzureCredential() ml_client = MLClient.from_config(credential=credential)" py_run_string(py_code) print("ml_client is configured")Use this code to retrieve the asset. Make sure to replace
<MY_NAME>and<MY_VERSION>with the name and number of your data asset.Tip
In studio, select Data in the left navigation to find the name and version number of your data asset.
# Replace <MY_NAME> and <MY_VERSION> with your values py_code <- "my_name = '<MY_NAME>' my_version = '<MY_VERSION>' data_asset = ml_client.data.get(name=my_name, version=my_version) data_uri = data_asset.path"To retrieve the URI, run the code.
py_run_string(py_code) print(paste("URI path is", py$data_uri))
Use Pandas read functions to read the file or files into the R environment.
pd <- import("pandas") cc <- pd$read_csv(py$data_uri) head(cc)
You can also use a Datastore URI to access different files on a registered Datastore, and read these resources into an R data.frame.
In this format, create a Datastore URI, using your own values:
subscription <- '<subscription_id>' resource_group <- '<resource_group>' workspace <- '<workspace>' datastore_name <- '<datastore>' path_on_datastore <- '<path>' uri <- paste0("azureml://subscriptions/", subscription, "/resourcegroups/", resource_group, "/workspaces/", workspace, "/datastores/", datastore_name, "/paths/", path_on_datastore)Tip
Instead of remembering the datastore URI format, you can copy-and-paste the datastore URI from the Studio UI, if you know the datastore where your file is located:
- Navigate to the file/folder you want to read into R
- Select the elipsis (...) next to it.
- Select from the menu Copy URI.
- Select the Datastore URI to copy into your notebook/script.
Note that you must create a variable for
<path>in the code.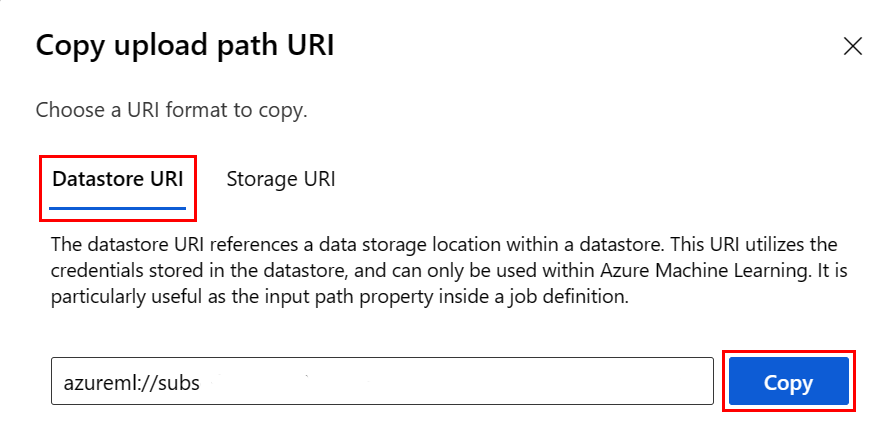
Create a filestore object using the previously mentioned URI:
fs <- azureml.fsspec$AzureMachineLearningFileSystem(uri, sep = "")
- Read into an R
data.frame:
df <- with(fs$open("<path>)", "r") %as% f, {
x <- as.character(f$read(), encoding = "utf-8")
read.csv(textConnection(x), header = TRUE, sep = ",", stringsAsFactors = FALSE)
})
print(df)
Install R packages
A compute instance has many preinstalled R packages.
To install other packages, you must explicitly state the location and dependencies.
Tip
When you create or use a different compute instance, you must re-install any packages you've installed.
For example, to install the tsibble package:
install.packages("tsibble",
dependencies = TRUE,
lib = "/home/azureuser")
Note
If you install packages within an R session that runs in a Jupyter notebook, dependencies = TRUE is required. Otherwise, dependent packages will not automatically install. The lib location is also required to install in the correct compute instance location.
Load R libraries
Add /home/azureuser to the R library path.
.libPaths("/home/azureuser")
Tip
You must update the .libPaths in each interactive R script to access user installed libraries. Add this code to the top of each interactive R script or notebook.
Once the libPath is updated, load libraries as usual.
library('tsibble')
Use R in the notebook
Beyond the issues described earlier, use R as you would in any other environment, including your local workstation. In your notebook or script, you can read and write to the path where the notebook/script is stored.
Note
- From an interactive R session, you can only write to the workspace file system.
- From an interactive R session, you cannot interact with MLflow (such as log model or query registry).