Model sweeping and selection for forecasting in AutoML
This article describes how automated machine learning (AutoML) in Azure Machine Learning searches for and selects forecasting models. If you're interested in learning more about the forecasting methodology in AutoML, see Overview of forecasting methods in AutoML. To explore training examples for forecasting models in AutoML, see Set up AutoML to train a time-series forecasting model with the SDK and CLI.
Model sweeping in AutoML
The central task for AutoML is to train and evaluate several models and choose the best one with respect to the given primary metric. The word "model" in this case refers to both the model class, such as ARIMA or Random Forest, and the specific hyper-parameter settings that distinguish models within a class. For instance, ARIMA refers to a class of models that share a mathematical template and a set of statistical assumptions. Training, or fitting, an ARIMA model requires a list of positive integers that specify the precise mathematical form of the model. These values are the hyper-parameters. The models ARIMA(1, 0, 1) and ARIMA(2, 1, 2) have the same class, but different hyper-parameters. These definitions can be separately fit with the training data and evaluated against each other. AutoML searches, or sweeps, over different model classes and within classes by varying the hyper-parameters.
Hyper-parameter sweeping methods
The following table shows the different hyper-parameter sweeping methods that AutoML uses for different model classes:
| Model class group | Model type | Hyper-parameter sweeping method |
|---|---|---|
| Naive, Seasonal Naive, Average, Seasonal Average | Time series | No sweeping within class due to model simplicity |
| Exponential Smoothing, ARIMA(X) | Time series | Grid search for within-class sweeping |
| Prophet | Regression | No sweeping within class |
| Linear SGD, LARS LASSO, Elastic Net, K Nearest Neighbors, Decision Tree, Random Forest, Extremely Randomized Trees, Gradient Boosted Trees, LightGBM, XGBoost | Regression | AutoML's model recommendation service dynamically explores hyper-parameter spaces |
| ForecastTCN | Regression | Static list of models followed by random search over network size, dropout ratio, and learning rate |
For a description of the different model types, see the Forecasting models in AutoML section of the forecasting methods overview article.
The amount of sweeping by AutoML depends on the forecasting job configuration. You can specify the stopping criteria as a time limit or a limit on the number of trials, or the equivalent number of models. Early termination logic can be used in both cases to stop sweeping if the primary metric isn't improving.
Model selection in AutoML
AutoML follows a three-phase process to search for and select forecasting models:
Phase 1: Sweep over time-series models and select the best model from each class by using maximum likelihood estimation methods.
Phase 2: Sweep over regression models and rank them, along with the best time-series models from phase 1, according to their primary metric values from validation sets.
Phase 3: Build an ensemble model from the top ranked models, calculate its validation metric, and rank it with the other models.
The model with the top ranked metric value at the end of phase 3 is designated the best model.
Important
In Phase 3, AutoML always calculates metrics on out-of-sample data that isn't used to fit the models. This approach helps to protect against over-fitting.
Validation configurations
AutoML has two validation configurations: cross-validation and explicit validation data.
In the cross-validation case, AutoML uses the input configuration to create data splits into training and validation folds. Time order must be preserved in these splits. AutoML uses so-called Rolling Origin Cross Validation, which divides the series into training and validation data by using an origin time point. Sliding the origin in time generates the cross-validation folds. Each validation fold contains the next horizon of observations immediately following the position of the origin for the given fold. This strategy preserves the time-series data integrity and mitigates the risk of information leakage.
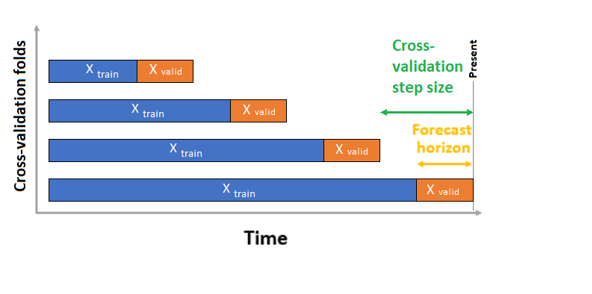
AutoML follows the usual cross-validation procedure, training a separate model on each fold and averaging validation metrics from all folds.
Cross-validation for forecasting jobs is configured by setting the number of cross-validation folds, and optionally, the number of time periods between two consecutive cross-validation folds. For more information and an example of configuring cross-validation for forecasting, see Custom cross-validation settings.
You can also bring your own validation data. For more information, see Configure training, validation, cross-validation, and test data in AutoML (SDK v1).