Use external packages with Jupyter Notebooks in Apache Spark clusters on HDInsight
Learn how to configure a Jupyter Notebook in Apache Spark cluster on HDInsight to use external, community-contributed Apache maven packages that aren't included out-of-the-box in the cluster.
You can search the Maven repository for the complete list of packages that are available. You can also get a list of available packages from other sources. For example, a complete list of community-contributed packages is available at Spark Packages.
In this article, you'll learn how to use the spark-csv package with the Jupyter Notebook.
Prerequisites
An Apache Spark cluster on HDInsight. For instructions, see Create Apache Spark clusters in Azure HDInsight.
Familiarity with using Jupyter Notebooks with Spark on HDInsight. For more information, see Load data and run queries with Apache Spark on HDInsight.
The URI scheme for your clusters primary storage. This would be
wasb://for Azure Storage,abfs://for Azure Data Lake Storage Gen2. If secure transfer is enabled for Azure Storage or Data Lake Storage Gen2, the URI would bewasbs://orabfss://, respectively See also, secure transfer.
Use external packages with Jupyter Notebooks
Navigate to
https://CLUSTERNAME.azurehdinsight.net/jupyterwhereCLUSTERNAMEis the name of your Spark cluster.Create a new notebook. Select New, and then select Spark.
A new notebook is created and opened with the name Untitled.pynb. Select the notebook name at the top, and enter a friendly name.
You'll use the
%%configuremagic to configure the notebook to use an external package. In notebooks that use external packages, make sure you call the%%configuremagic in the first code cell. This ensures that the kernel is configured to use the package before the session starts.Important
If you forget to configure the kernel in the first cell, you can use the
%%configurewith the-fparameter, but that will restart the session and all progress will be lost.HDInsight version Command For HDInsight 3.5 and HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}For HDInsight 3.3 and HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }The snippet above expects the maven coordinates for the external package in Maven Central Repository. In this snippet,
com.databricks:spark-csv_2.11:1.5.0is the maven coordinate for spark-csv package. Here's how you construct the coordinates for a package.a. Locate the package in the Maven Repository. For this article, we use spark-csv.
b. From the repository, gather the values for GroupId, ArtifactId, and Version. Make sure that the values you gather match your cluster. In this case, we're using a Scala 2.11 and Spark 1.5.0 package, but you may need to select different versions for the appropriate Scala or Spark version in your cluster. You can find out the Scala version on your cluster by running
scala.util.Properties.versionStringon the Spark Jupyter kernel or on Spark submit. You can find out the Spark version on your cluster by runningsc.versionon Jupyter Notebooks.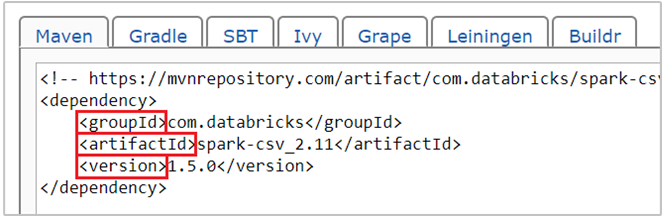
c. Concatenate the three values, separated by a colon (:).
com.databricks:spark-csv_2.11:1.5.0Run the code cell with the
%%configuremagic. This will configure the underlying Livy session to use the package you provided. In the subsequent cells in the notebook, you can now use the package, as shown below.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")For HDInsight 3.4 and below, you should use the following snippet.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")You can then run the snippets, like shown below, to view the data from the dataframe you created in the previous step.
df.show() df.select("Time").count()
See also
Scenarios
- Apache Spark with BI: Perform interactive data analysis using Spark in HDInsight with BI tools
- Apache Spark with Machine Learning: Use Spark in HDInsight for analyzing building temperature using HVAC data
- Apache Spark with Machine Learning: Use Spark in HDInsight to predict food inspection results
- Website log analysis using Apache Spark in HDInsight
Create and run applications
- Create a standalone application using Scala
- Run jobs remotely on an Apache Spark cluster using Apache Livy
Tools and extensions
- Use external Python packages with Jupyter Notebooks in Apache Spark clusters on HDInsight Linux
- Use HDInsight Tools Plugin for IntelliJ IDEA to create and submit Spark Scala applications
- Use HDInsight Tools Plugin for IntelliJ IDEA to debug Apache Spark applications remotely
- Use Apache Zeppelin notebooks with an Apache Spark cluster on HDInsight
- Kernels available for Jupyter Notebook in Apache Spark cluster for HDInsight
- Install Jupyter on your computer and connect to an HDInsight Spark cluster